↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Event cameras offer advantages like low latency and high dynamic range, but reconstructing videos from their sparse event data is challenging due to the limited semantic information provided. Existing methods often produce videos with artifacts and regional blur. This is because event cameras primarily capture edge and motion information locally, leading to ambiguities in the semantics of the events.
The authors propose LaSe-E2V, a novel framework that leverages language descriptions to improve E2V reconstruction. Language provides abundant semantic information, improving semantic consistency. LaSe-E2V incorporates an Event-guided Spatiotemporal Attention (ESA) module and an event-aware mask loss to enhance spatio-temporal consistency. Extensive experiments demonstrate the superiority of LaSe-E2V over existing methods, especially in challenging scenarios, showcasing the effectiveness of the language-guided approach.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the inherent ambiguity of event data in event-to-video (E2V) reconstruction by leveraging language. This novel approach paves the way for higher-quality video reconstruction and opens new avenues for research in bridging event-based and traditional computer vision.
Visual Insights#
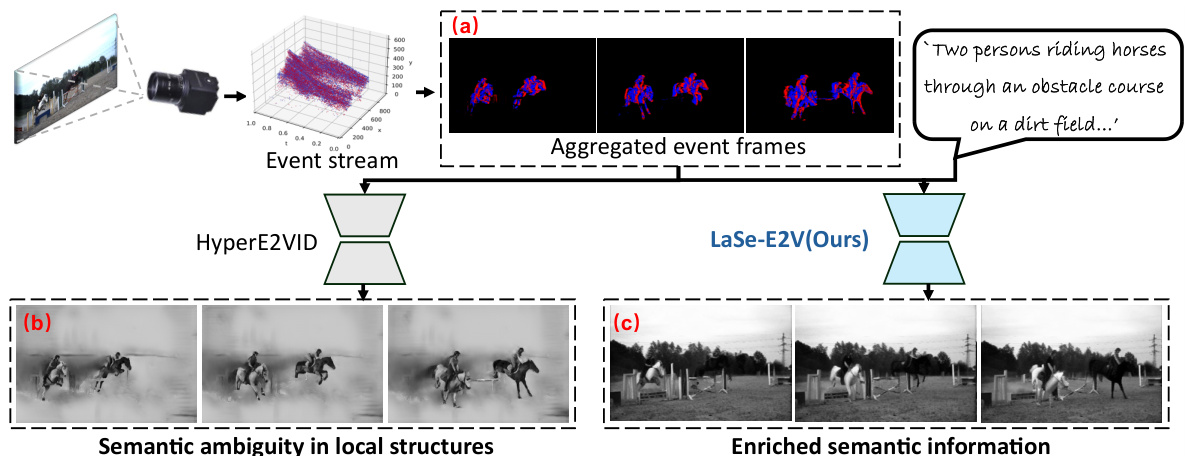
This figure compares the event-to-video (E2V) reconstruction pipelines of HyperE2VID and the proposed LaSe-E2V method. HyperE2VID, relying solely on event data, produces ambiguous and blurry results due to the lack of semantic information. LaSe-E2V, on the other hand, incorporates language descriptions to provide semantic context, leading to clearer and more coherent video reconstructions.
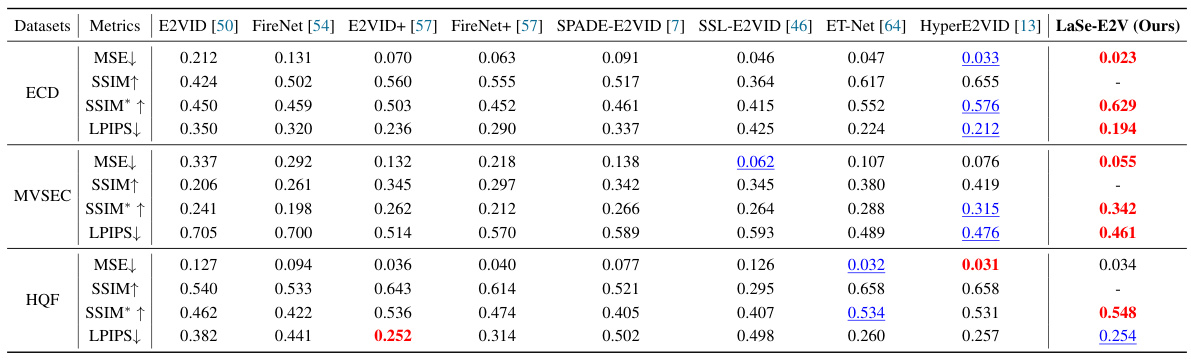
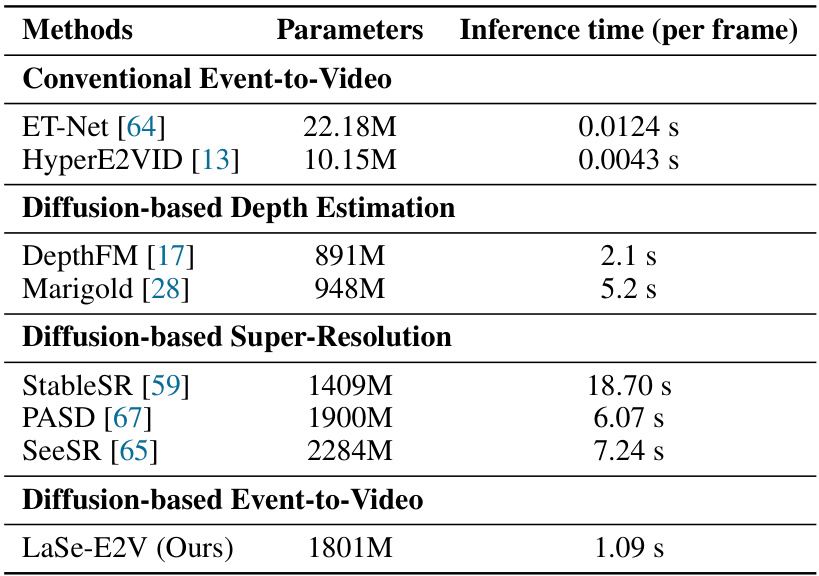
This table presents a quantitative comparison of the proposed LaSe-E2V model against eight state-of-the-art event-to-video reconstruction methods across three benchmark datasets (ECD, MVSEC, HQF). The metrics used for comparison are Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). The best and second-best results for each metric are highlighted to easily identify the superior performance of the models.
In-depth insights#
Event-Video Recon#
Event-video reconstruction (E2V) bridges the gap between event cameras and traditional video, addressing the challenge of transforming asynchronous event streams into a temporally coherent video representation. The inherent ill-posed nature of E2V, stemming from the localized, edge-and-motion focused nature of event data, makes it a complex problem. Existing methods often struggle with artifacts, blur, and inconsistencies. Recent advancements leverage deep learning, often employing sophisticated network architectures and loss functions to improve reconstruction quality. However, the lack of sufficient high-quality, large-scale training datasets remains a significant limitation. Language guidance shows promise in improving reconstruction semantic consistency by providing rich context that event data alone lacks. Future research directions may include exploring more effective training strategies with augmented datasets, innovative network designs, and integrating multimodal data to address the limitations of current approaches. The potential of E2V extends to numerous applications requiring low-latency, high-dynamic range vision systems.
Language Guidance#
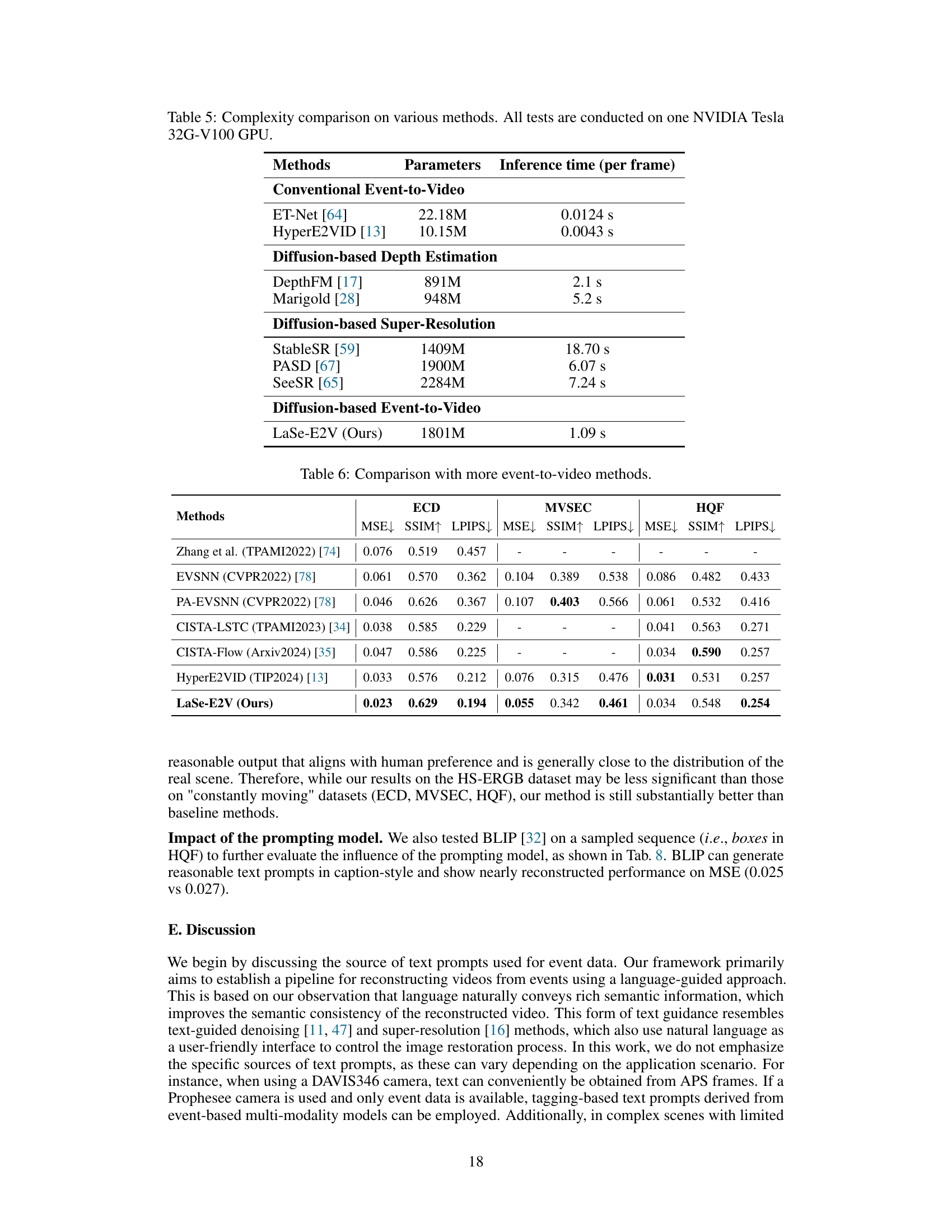
The concept of ‘Language Guidance’ in the context of event-to-video reconstruction is a novel approach that leverages the semantic richness of natural language to overcome inherent ambiguities in event data. By incorporating textual descriptions, the model gains access to high-level semantic information, significantly improving the coherence and visual quality of the reconstructed video. This addresses the ill-posed nature of event-based vision, where local edge and motion information alone is insufficient for generating high-fidelity video. The integration of language effectively acts as a powerful regularizer, guiding the spatial and temporal consistency of the generated video frames and enriching the output with more complete semantic context. The effectiveness is demonstrated by comparing results with and without language guidance, showcasing superior performance metrics like SSIM and LPIPS. It suggests a promising direction for future E2V research by bridging event data with the comprehensive semantic understanding inherent in textual descriptions. A potential limitation would be the reliance on pre-trained language models, whose biases or inaccuracies could propagate into the video reconstruction process.
ESA Attention#
The concept of “ESA Attention”, likely standing for Event-guided Spatio-temporal Attention, presents a novel approach to integrating event data into video reconstruction. It elegantly addresses the limitations of using solely event data, which often lacks semantic information and temporal coherence. By incorporating spatial and temporal attention mechanisms guided by event information, ESA Attention aims to improve both the spatial alignment between events and the reconstructed video frames and the temporal consistency across video frames. This dual attention mechanism allows the model to focus on relevant event features when generating each frame, effectively leveraging the high temporal resolution and edge-sensitive nature of event data. The design suggests a fusion of event and frame representations, resulting in a more faithful and detailed video reconstruction compared to methods relying solely on event data or generic spatio-temporal attention mechanisms. The effectiveness of ESA Attention likely hinges on its ability to bridge the semantic gap between sparse event information and rich, contextual video information.
Diffusion Models#
Diffusion models have emerged as a powerful class of generative models, capable of producing high-quality images, videos, and other data. These models work by gradually adding noise to data until it becomes pure noise, and then learning to reverse this process, generating new data from noise. A key advantage is their ability to generate diverse and high-fidelity samples. However, they often suffer from computational cost and the inherent randomness in the diffusion process can be a limitation. Further research focuses on improving efficiency, controllability, and understanding the underlying mathematical principles of diffusion models to enhance their capabilities and applications. The application of diffusion models to event-to-video reconstruction represents a novel approach, leveraging the inherent properties of event data for more effective conditioning and generation. This presents a pathway for addressing challenges in traditional E2V reconstruction that are related to temporal inconsistencies and lack of semantic information. The incorporation of textual guidance further enhances the quality and semantic coherence of reconstructed videos, pushing the boundaries of what can be achieved with event data.
Future of E2V#
The future of event-to-video (E2V) reconstruction is bright, driven by the need for robust and efficient methods to handle the unique characteristics of event cameras. Improved algorithms will likely focus on addressing inherent challenges like the ambiguous nature of event data, leading to better temporal and spatial consistency in the reconstructed video. Incorporating diverse data sources, including multimodal data (e.g., combining event streams with other sensor data), will likely become standard practice, providing richer context and information for more accurate reconstruction. The integration of advanced deep learning techniques and the exploration of novel network architectures will be key to achieving higher quality video at faster processing speeds. Addressing the limitations of existing datasets by creating larger, more diverse, and better-annotated datasets will be crucial. Finally, further development of real-world applications that leverage the advantages of event-based vision, particularly in challenging conditions (low light, high dynamic range, high-speed motion), will stimulate more research and innovation in this dynamic field.
More visual insights#
More on figures
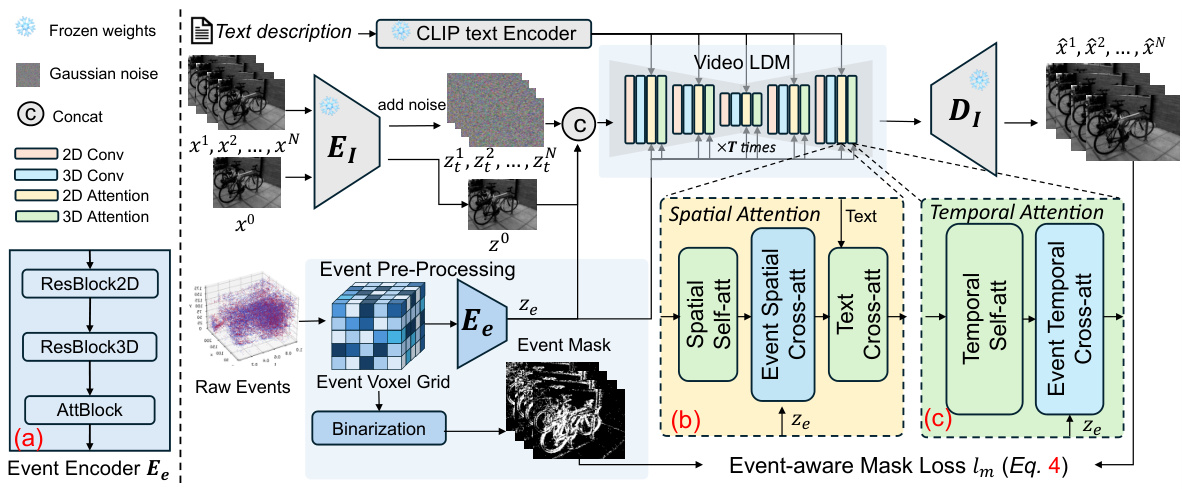
The figure shows the architecture of the LaSe-E2V framework, which consists of four main components: an image encoder (E₁), an event encoder (Eₑ), a video latent diffusion model (LDM), and a decoder (D₁). The event encoder processes raw events to create an event voxel grid, which is then fed into the LDM along with image features and text embeddings from a CLIP text encoder. The LDM incorporates an Event-guided Spatiotemporal Attention (ESA) module to better align the event data with the video generation process. Finally, a decoder generates the reconstructed video. The framework also uses an event-aware mask loss (lₘ) to ensure temporal consistency and improve the overall quality of the reconstructed video.

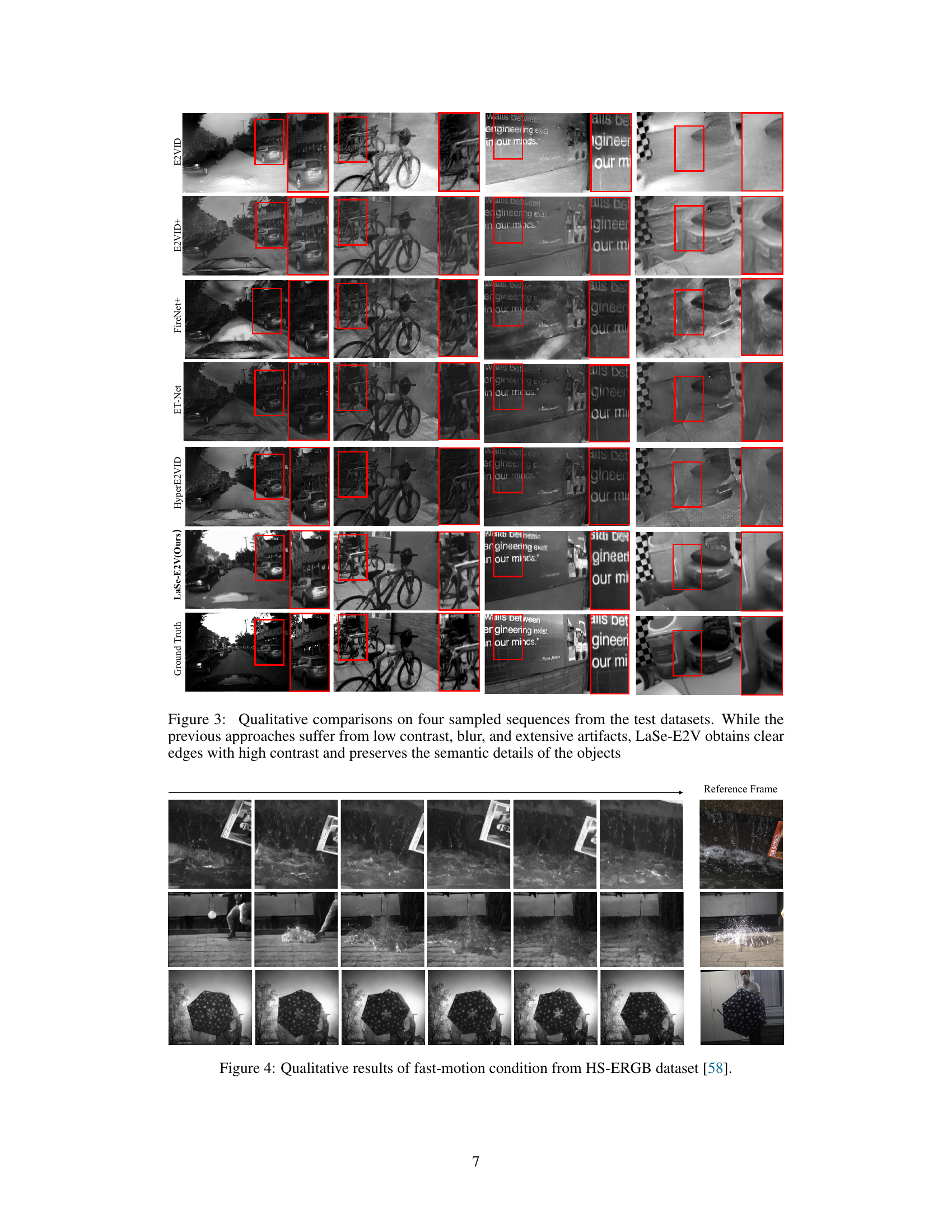
This figure shows a qualitative comparison of event-to-video (E2V) reconstruction results on four test sequences using different methods, including the proposed LaSe-E2V. The red boxes highlight specific regions for easier comparison. The results demonstrate that LaSe-E2V produces significantly clearer and sharper images, with better contrast and preservation of details, compared to other existing methods which suffer from blur, low contrast, and noticeable artifacts. The improvements showcased highlight the superior performance of LaSe-E2V in preserving image quality and semantic details.

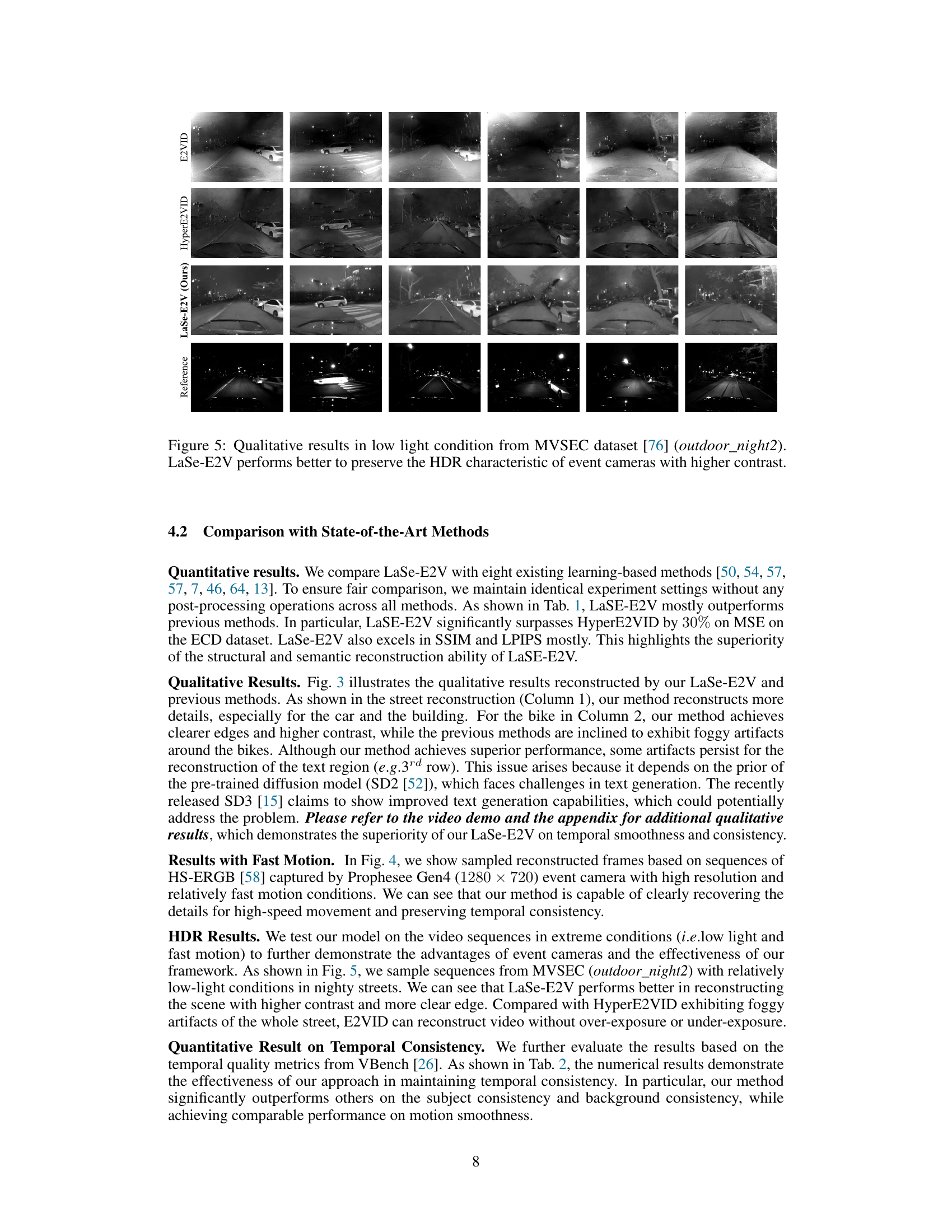
This figure shows qualitative results of the proposed LaSe-E2V model on the HS-ERGB dataset, focusing on fast motion scenarios. It visually compares the generated video frames (LaSe-E2V (Ours)) with the ground truth (Reference Frame). The comparison demonstrates the model’s ability to accurately reconstruct video sequences with fast-moving objects, preserving details and temporal consistency even under challenging conditions. The HS-ERGB dataset is particularly relevant because it offers high-quality video with events captured by Prophesee Gen4 event cameras.

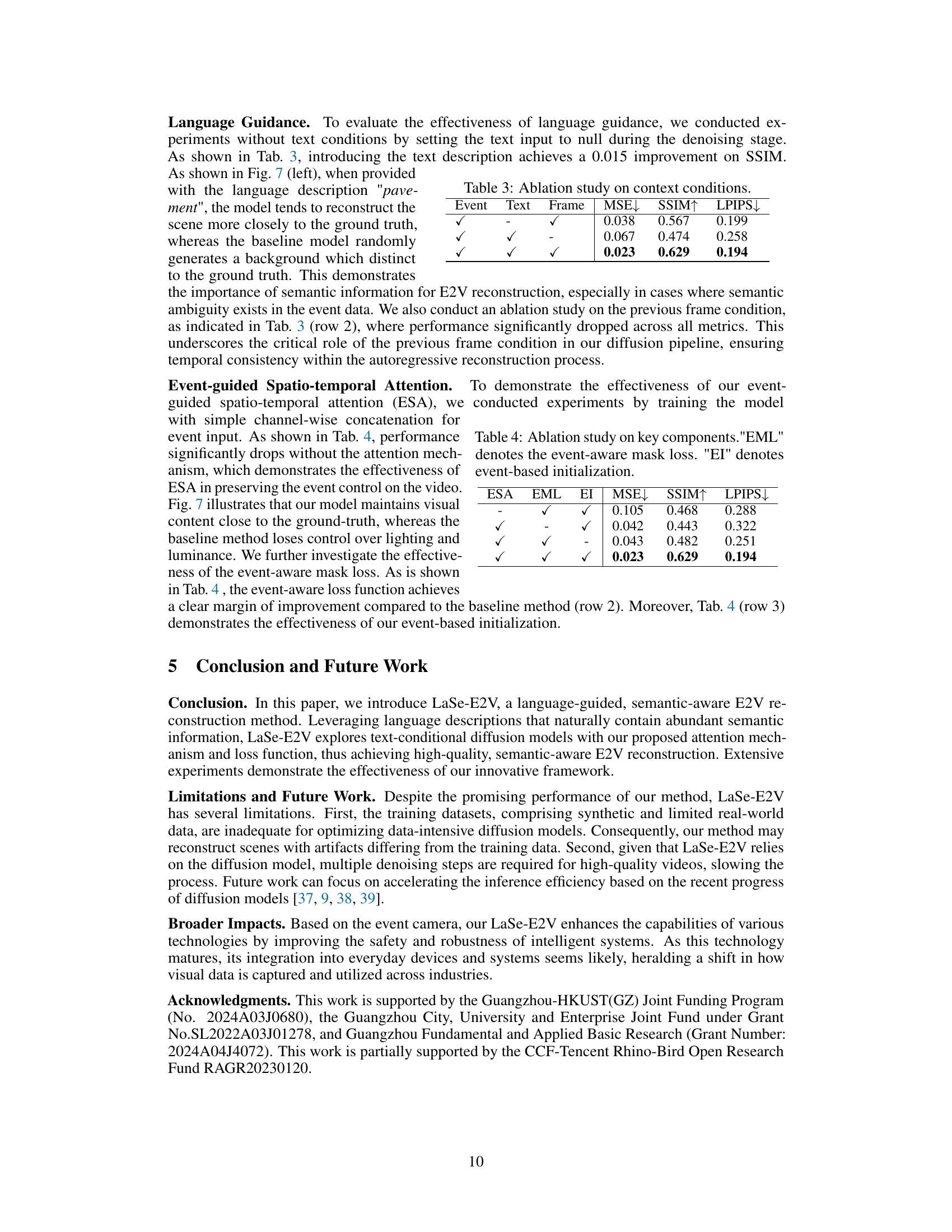
This figure presents a qualitative comparison of video reconstruction results under low-light conditions using different methods. The top row shows results from the E2VID method; the second row, from HyperE2VID; the third row, from the proposed LaSe-E2V; and the bottom row displays ground truth reference frames. Each row presents a sequence of frames to showcase the temporal evolution of the reconstruction, highlighting the performance of LaSe-E2V in maintaining high contrast and detail even in challenging low-light situations. It demonstrates LaSe-E2V’s ability to better preserve the high dynamic range (HDR) capabilities of event cameras compared to other methods.

This figure presents a qualitative comparison of event-to-video reconstruction results from different methods, including LaSe-E2V and several baselines. It demonstrates the superior performance of LaSe-E2V in terms of visual clarity, contrast, and semantic detail preservation compared to other methods. The baselines exhibit low contrast, blur, and noticeable artifacts, while LaSe-E2V produces sharper images with more accurate representation of objects and their features.

This figure presents a qualitative comparison of the results obtained from ablation studies on text guidance and the Event-guided Spatio-temporal Attention (ESA) module. It visually demonstrates the impact of both text descriptions and ESA on the quality of video reconstruction. The left side shows the effects of including or excluding text descriptions, while the right side illustrates the influence of the ESA module. Comparing the results shows the superior performance achieved with both text guidance and ESA, producing videos that more closely match the ground truth.

This figure shows the results of a video editing experiment using language guidance. The left column shows a reconstruction using the text prompt “night, dark, city street…”, resulting in a low-light scene. The middle column shows reconstruction using the prompt “bright, day light, city street…”, resulting in a bright, daytime scene. The right column shows the reference frame for comparison. This demonstrates how language can be used to modify the lighting conditions in the generated video, highlighting the ability of the LaSe-E2V framework to incorporate semantic information effectively.

This figure shows a qualitative comparison of event-to-video reconstruction results from several methods, including the proposed LaSe-E2V model. It highlights that LaSe-E2V is superior to other approaches in terms of image clarity, contrast, and preservation of semantic details. The comparison is shown for four separate video sequences, demonstrating consistent improvements.
More on tables

This table presents a quantitative comparison of the temporal consistency of different event-to-video (E2V) reconstruction methods on the Event Camera Dataset (ECD) using the VBench metric. The metric assesses three aspects of temporal quality: Subject Consistency (how well the subject is consistently reconstructed across frames), Background Consistency (how well the background is consistently reconstructed across frames), and Motion Smoothness (how smooth the motion is in the reconstructed video). The table shows the performance of various methods including E2VID, FireNet, SPADE-E2VID, SSL-E2VID, ET-Net, HyperE2VID, and the proposed LaSe-E2V method. The results are expressed as percentages, with higher percentages indicating better performance.
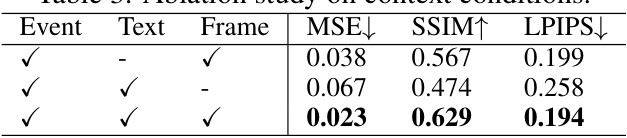
This ablation study investigates the impact of different combinations of event data, text descriptions, and previous frames on the performance of the LaSe-E2V model. The results are quantified using MSE, SSIM, and LPIPS metrics, showing that the combination of all three provides the best reconstruction results.
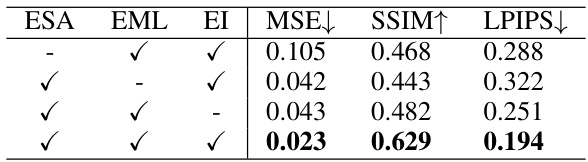
This table presents the results of ablation studies conducted on the LaSe-E2V framework. It shows the impact of the Event-guided Spatiotemporal Attention (ESA) module, the event-aware mask loss (EML), and the event-based initialization (EI) strategy on the key metrics: Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Each row represents a different combination of these components, allowing for a quantitative analysis of their individual and combined contributions to the overall performance.
This table presents a quantitative comparison of the proposed LaSe-E2V model with eight existing state-of-the-art event-to-video (E2V) reconstruction methods across three benchmark datasets (ECD, MVSEC, and HQF). The metrics used for comparison include Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Both synthetic and real-world datasets were used to evaluate performance. The table highlights the best and second-best results for each metric and dataset to showcase the superior performance of LaSe-E2V. Note that SSIM* represents a reevaluation of previous methods using a unified metric to ensure fair comparison.
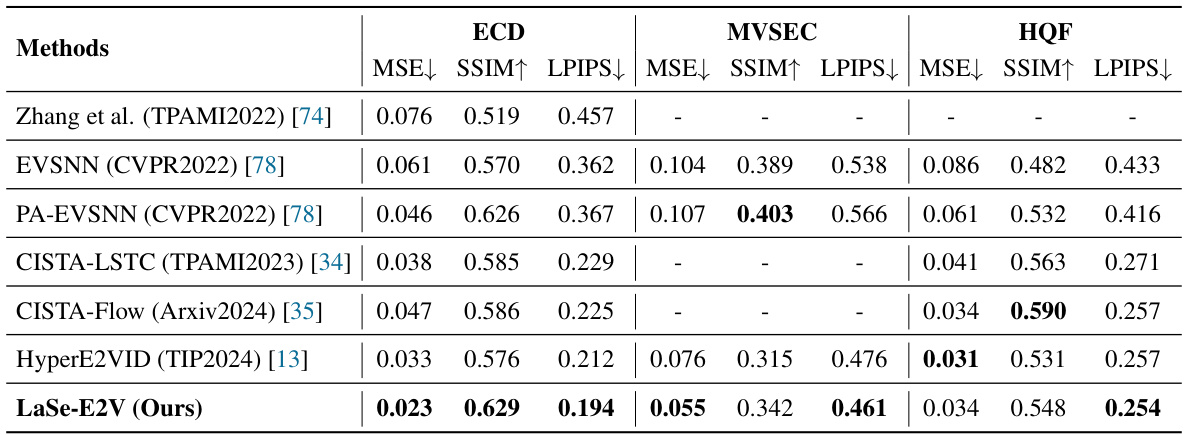
This table presents a quantitative comparison of the proposed LaSe-E2V model against eight state-of-the-art event-to-video reconstruction methods. The comparison is done across three different datasets (ECD, MVSEC, and HQF), using four evaluation metrics: Mean Squared Error (MSE), Structural Similarity Index (SSIM), LPIPS, and a recalculated SSIM* (to account for inconsistencies in previous SSIM calculations). The best and second-best results for each metric on each dataset are highlighted.
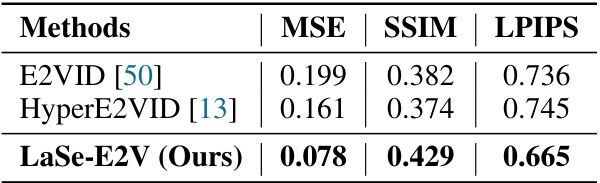
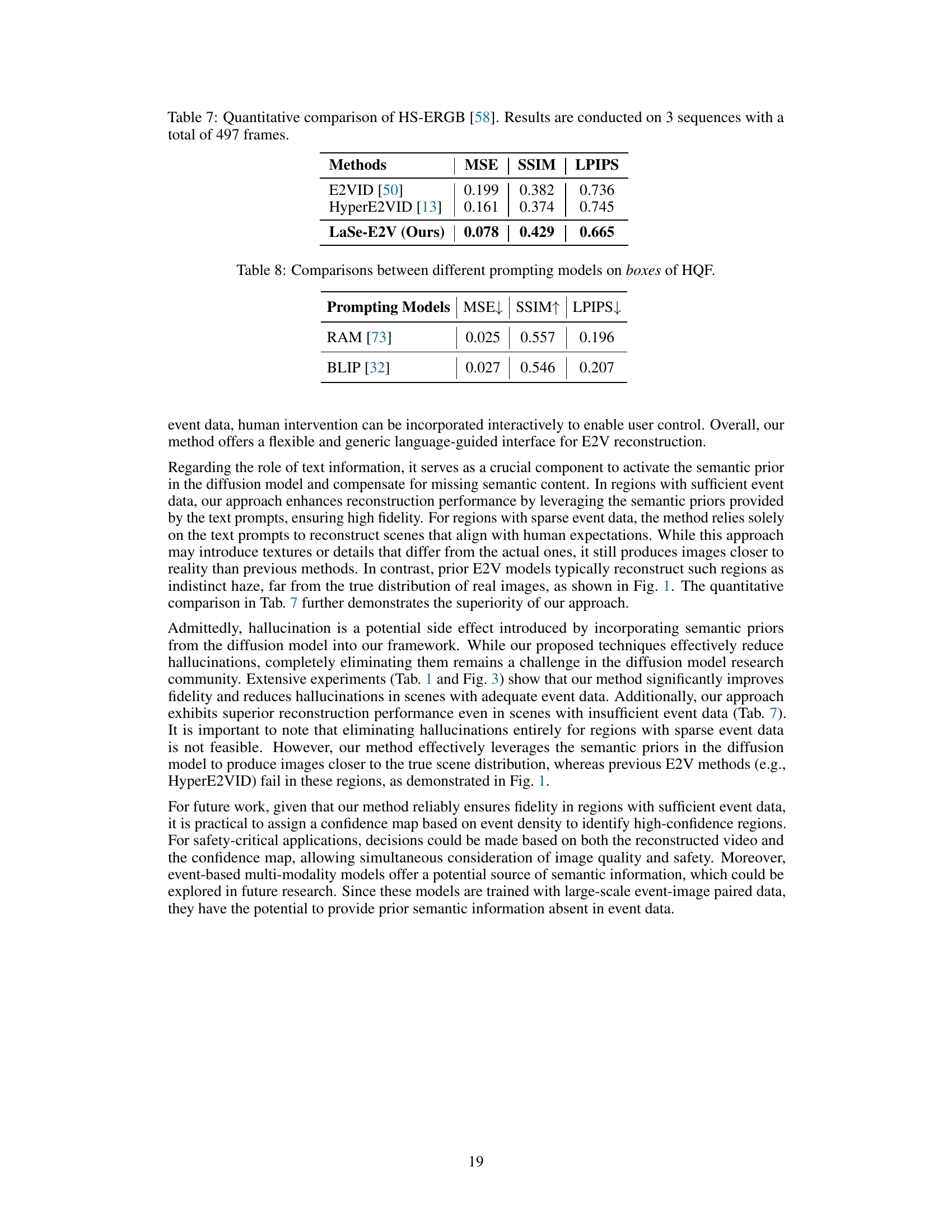
This table presents a quantitative comparison of the proposed LaSe-E2V method against existing state-of-the-art Event-to-Video (E2V) reconstruction methods on the HS-ERGB dataset. The comparison focuses on three metrics: Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Lower MSE and LPIPS values, and higher SSIM values, indicate better reconstruction quality. The table shows that LaSe-E2V significantly outperforms existing methods on all three metrics, demonstrating its improved performance in reconstructing high-quality videos from event data.
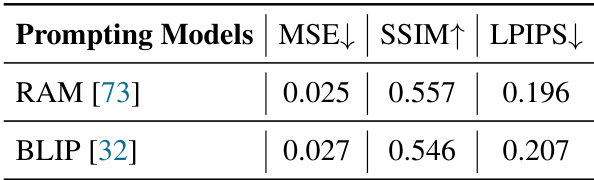
This table compares the performance of two different prompting models, RAM and BLIP, on the task of generating image captions for boxes from the High-Quality Frames (HQF) dataset. The comparison is based on three metrics: Mean Squared Error (MSE), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Lower MSE and LPIPS scores indicate better performance, while higher SSIM indicates better performance.
Full paper#