↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current transformer-based diffusion models struggle with balancing visual fidelity and computational costs due to the quadratic complexity of self-attention. Larger patch sizes are computationally efficient but lose fine-grained details, while smaller patch sizes are more accurate but computationally expensive. Existing time conditioning methods are also parameter-intensive, adding to model complexity.
DiMR solves these issues through a novel multi-resolution network that progressively refines features from low to high resolution, improving image detail. It also introduces Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach for incorporating time information. Through these improvements, DiMR significantly outperforms existing models on ImageNet, setting a new state-of-the-art in terms of FID scores while maintaining a reasonable model size. This is a significant contribution to the field of image generation.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on image generation and diffusion models. It directly addresses the challenge of balancing visual fidelity and computational efficiency in transformer-based diffusion models, a significant limitation of current approaches. The proposed multi-resolution network and time-dependent layer normalization offer practical solutions to improve image quality and scalability. The results establish a new state-of-the-art, making it essential reading for anyone working in this active area of AI research. The innovative methods presented open new avenues for investigation and improvements in diffusion models.
Visual Insights#

This figure shows a comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-resolution (512x512 pixels) images generated by DiMR, showcasing its ability to generate high-fidelity images. The bottom row presents lower-resolution (256x256 pixels) images from both DiMR and DiT. These lower-resolution images were selected using a classifier designed to identify images with low visual fidelity, thereby highlighting the difference in image quality and distortion between the two models. DiMR demonstrates superior performance in terms of both fidelity and reduced distortion compared to DiT.

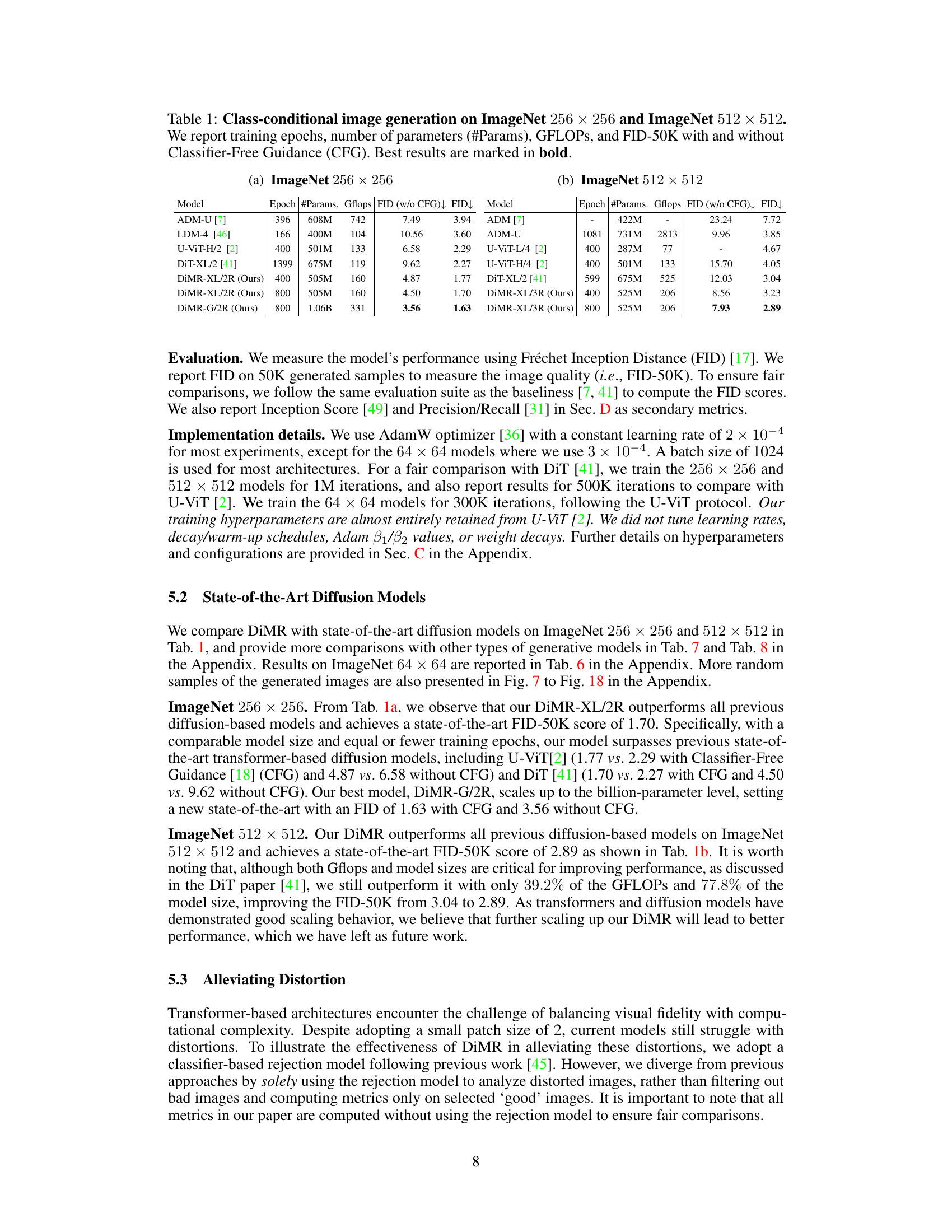
This table presents a comparison of different diffusion models on the ImageNet dataset for image generation at resolutions of 256x256 and 512x512. The models are evaluated based on training epochs, the number of parameters, computational cost (GFLOPs), and the Fréchet Inception Distance (FID) score, a metric of image quality. FID scores are reported both with and without classifier-free guidance (CFG), which is a technique to improve the quality of generated images. The best results for each metric are highlighted in bold.
In-depth insights#
Multi-res Diffusion#
Multi-resolution diffusion models represent a significant advancement in generative modeling. By processing information across multiple resolutions, they mitigate the trade-off between computational efficiency and fine-grained detail capture inherent in single-resolution approaches. This is achieved by a hierarchical or cascading structure, where lower resolutions provide a coarse representation that’s progressively refined at higher resolutions, allowing for efficient attention mechanisms at coarser levels and detailed feature extraction at finer levels. This approach enhances image fidelity, reduces artifacts, and improves overall image quality. Furthermore, time-dependent layer normalization, often incorporated in these models, dynamically adjusts feature representations, further enhancing the generation process. The multi-resolution strategy is computationally advantageous, especially for high-resolution image generation tasks, as it avoids processing the entire image at the highest resolution from the beginning. This makes it a powerful technique for generating high-fidelity images efficiently, although careful design and parameter tuning are crucial to maximize its benefits.
Time-dep Normalization#
Time-dependent layer normalization (TD-LN) offers a novel approach to enhance diffusion models by dynamically adapting normalization parameters based on the timestep. Unlike traditional layer normalization, TD-LN injects temporal information directly into the normalization process, improving performance while maintaining efficiency. This is achieved by making the scale and shift parameters functions of time, effectively learning a time-dependent transformation. This approach contrasts with parameter-heavy methods like adaLN which utilize an MLP to learn these parameters. The key advantage of TD-LN is its parameter efficiency, avoiding the computational overhead and increased memory demands of alternative time conditioning methods. The integration of TD-LN with a multi-resolution network significantly boosts the visual fidelity of generated images, reducing distortions and improving the overall quality. Experiments demonstrate the effectiveness of TD-LN in improving FID scores across different resolutions of the ImageNet benchmark, showcasing its value as a vital component in enhancing diffusion model performance and scalability.
DiMR Architecture#
The DiMR architecture is a multi-resolution network designed to enhance diffusion models by addressing the trade-off between computational efficiency and visual fidelity inherent in Transformer-based approaches. It features a feature cascade mechanism which processes the input progressively through multiple branches, starting from a low-resolution representation using Transformer blocks and gradually upsampling to higher resolutions using efficient ConvNeXt blocks. This allows the model to capture both global context and fine-grained detail. Time-Dependent Layer Normalization (TD-LN) is integrated to efficiently inject time information into the network, further improving performance. The architecture’s clever combination of Transformer and ConvNeXt blocks, along with the novel feature cascade and TD-LN, results in a model that balances computational efficiency and superior visual fidelity, leading to high-quality image generation with minimal distortion. The multi-scale loss function further enhances training effectiveness by optimizing the prediction of noise at different resolution levels.
Ablation Studies#
Ablation studies systematically assess the contribution of individual components within a model. In the context of a research paper, they are crucial for understanding model behavior and isolating the effects of specific design choices. By progressively removing or altering components, researchers can pinpoint which aspects are most impactful on the model’s performance. A well-designed ablation study is key to establishing the credibility and robustness of claims. For instance, if a new method outperforms existing approaches, ablation studies help determine whether this improvement stems from the novel components or is due to other factors. They can highlight unexpected interactions between components and reveal design choices that are essential for good performance. The results will directly affect the model’s architecture, its generalizability, and overall validity. Moreover, they often provide insights into potential avenues for improvement, suggesting areas for future research and optimization. Therefore, an ablation study’s thoroughness and clarity are vital for the overall impact of the research paper.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency of the multi-resolution network is crucial, potentially through architectural optimizations or more efficient attention mechanisms. Investigating alternative normalization techniques beyond TD-LN could further enhance performance and stability. Expanding the scope to handle unconditional image generation and text-to-image synthesis would significantly broaden the impact and applicability of DiMR. Furthermore, in-depth research on mitigating potential biases and safety risks is essential to ensure responsible deployment. Finally, scaling the model to even larger sizes while maintaining computational efficiency is a key challenge that deserves further attention to fully realize the potential of DiMR for generating high-fidelity, detailed images.
More visual insights#
More on figures

This figure illustrates the architecture of the DiMR model’s Multi-Resolution Network. It shows three branches processing the input at different resolutions. The lowest resolution branch uses Transformer blocks, while higher resolution branches use ConvNeXt blocks. A feature cascade approach progressively upsamples lower-resolution features to refine details at higher resolutions. Time-Dependent Layer Normalization (TD-LN) is used in all blocks.

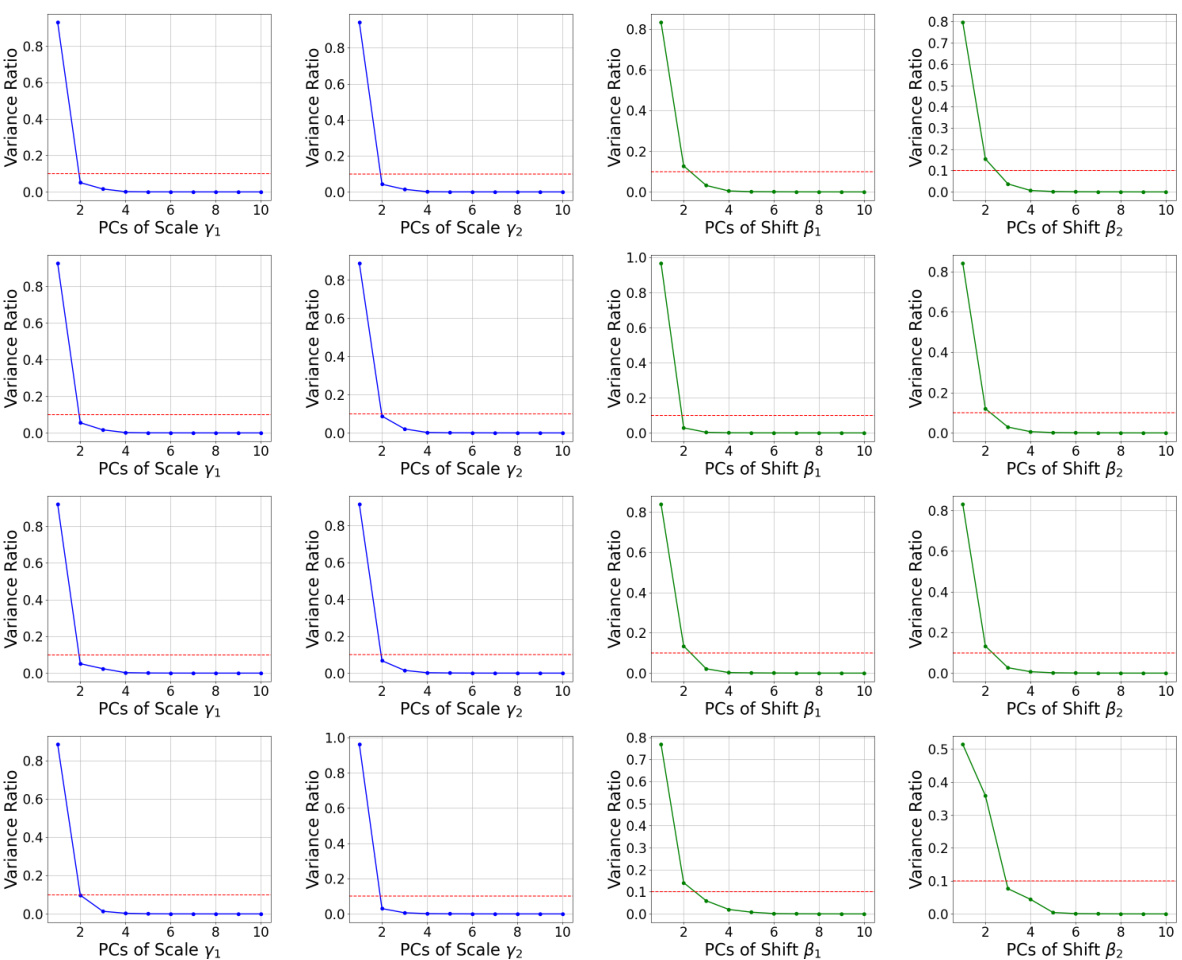
This figure shows the results of a Principal Component Analysis (PCA) performed on the learned scale and shift parameters from the adaLN-Zero method. The PCA reveals that a significant portion of the variance in these parameters can be captured by just two principal components. This observation supports the authors’ claim that a simpler function, such as their proposed TD-LN, could effectively replace the more complex MLP used in adaLN-Zero.

This figure compares two time conditioning mechanisms: adaLN-Zero and the proposed TD-LN. adaLN-Zero uses an MLP to learn time-dependent scale and shift parameters, resulting in increased parameter count. In contrast, TD-LN directly incorporates time into layer normalization with fewer parameters, improving efficiency. The left side shows adaLN-Zero’s architecture, highlighting the multi-layer perceptron (MLP) for scale and shift parameters calculation. The right side illustrates the proposed TD-LN, where time is integrated into the layer normalization’s affine transformations, resulting in a more efficient architecture.

This figure compares the image generation quality of DiMR with two baseline models (U-ViT and DiT) using a pre-trained classifier to identify low-fidelity images. It shows randomly selected examples of low-fidelity images produced by each model, along with their FID scores and distortion rates (percentage of distorted images as determined by human evaluators). DiMR shows significantly fewer distorted images and a lower FID score, indicating better visual fidelity and less distortion.
This figure shows a comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-resolution (512x512) images generated by DiMR, showcasing its ability to produce high-fidelity images. The bottom row shows lower-resolution (256x256) images from both DiMR and DiT, specifically selecting samples identified as low-fidelity by a classifier. This comparison highlights DiMR’s superior performance in generating images with higher fidelity and reduced distortion compared to DiT.

This figure shows a comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-fidelity 512x512 images generated by DiMR, while the bottom row shows lower-fidelity 256x256 images from both DiMR and DiT. A classifier is used to identify low-fidelity images, demonstrating that DiMR produces higher-quality images with less distortion.

The figure showcases image samples generated by the proposed DiMR model (top) and compares them to samples from DiT (bottom), illustrating DiMR’s superior image quality and reduced distortion. A classifier was used to identify and isolate low-fidelity images for a fair comparison.

This figure compares image samples generated by the proposed DiMR model with those from the DiT model at two different resolutions (512x512 and 256x256). The top row shows high-fidelity images produced by DiMR, while the bottom row presents lower-fidelity samples from both DiMR and DiT. A classifier is used to identify low-fidelity images for a fair comparison, demonstrating that DiMR produces images with better fidelity and less distortion compared to DiT.

This figure compares image generation results between the proposed DiMR model and the DiT model. The top row shows high-fidelity 512x512 images generated by DiMR. The bottom row shows lower-fidelity 256x256 images generated by both DiMR and DiT, selected using a classifier to ensure a fair comparison of image quality. The comparison highlights DiMR’s superior performance in generating images with less distortion and higher visual fidelity.

The figure shows the comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-fidelity 512x512 images generated by DiMR, while the bottom row shows lower-fidelity 256x256 images generated by both DiMR and DiT. A classifier is used to identify low-fidelity images, demonstrating DiMR’s superior performance in generating high-quality images with less distortion.

The figure shows a comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-quality 512x512 images generated by DiMR, while the bottom row shows lower-quality 256x256 images generated by both DiMR and DiT. A classifier was used to identify low-fidelity images for a fair comparison. DiMR demonstrates superior performance in generating higher-fidelity images with less distortion compared to DiT.

This figure shows a comparison of image generation results between the proposed DiMR model and the DiT model. The top row displays high-resolution (512x512 pixels) images generated by DiMR, demonstrating high visual fidelity. The bottom row presents lower-resolution (256x256 pixels) images from both DiMR and DiT, where a classifier was used to select examples with low visual fidelity. The comparison highlights that DiMR produces images with less distortion and higher fidelity than DiT.

This figure shows a comparison of image generation quality between the proposed DiMR model and the DiT model. The top row displays high-resolution (512x512 pixels) images generated by DiMR, showcasing its ability to produce detailed and visually appealing results. The bottom row presents lower-resolution (256x256 pixels) images produced by both DiMR and DiT. A classifier was used to identify low-fidelity images from both model outputs, and the figure demonstrates that DiMR produces significantly fewer low-quality images and achieves better visual fidelity compared to DiT.

This figure shows a comparison of image quality between the proposed DiMR model and the DiT model. The top row displays high-resolution images generated by DiMR, while the bottom row shows lower-resolution images from both DiMR and DiT, selected using a classifier to identify low-fidelity images. The comparison highlights DiMR’s ability to generate images with higher fidelity and reduced distortion.

This figure shows a comparison between images generated by the proposed DiMR model and the DiT model. The top row displays high-fidelity 512x512 images generated by DiMR, while the bottom row shows lower-resolution 256x256 images generated by both DiMR and DiT. A classifier was used to identify low-fidelity images, demonstrating DiMR’s superior performance in generating high-fidelity images with less distortion.

This figure compares image samples generated by the proposed DiMR model with those from the DiT model. The top row shows high-resolution (512x512) images generated by DiMR, showcasing its ability to produce high-fidelity images. The bottom row presents lower-resolution (256x256) images from both DiMR and DiT, where a classifier is used to identify images with low visual fidelity. This comparison highlights DiMR’s superiority in generating images with better visual quality and reduced distortion compared to DiT.

This figure compares image samples generated by the proposed DiMR model with those from DiT [41], a competing model. The top row shows high-resolution (512x512) images generated by DiMR, demonstrating high visual fidelity. The bottom row shows lower-resolution (256x256) images from both DiMR and DiT, with a classifier used to identify low-fidelity samples in both. The comparison highlights that DiMR produces significantly less distortion and higher-fidelity images than DiT.
More on tables

This table presents the ablation study results, showing the impact of different components (AdaLN-Zero, TD-LN, Multi-branch, GLU, and Multi-scale Loss) on the FID score and the number of parameters of the DiMR model. The baseline is U-ViT-M/4. Each row shows the FID and parameter count for a model that includes the checked components.
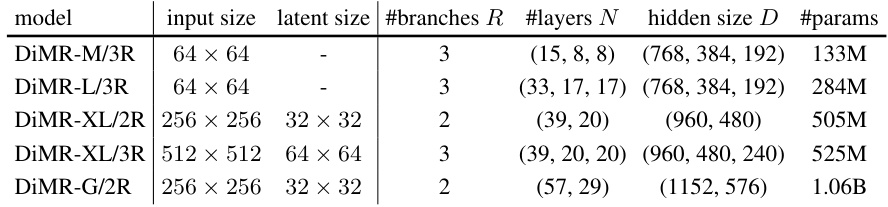
This table shows the different DiMR model variants (DiMR-M, DiMR-L, DiMR-XL, DiMR-G) and their configurations. Each variant is defined by three hyperparameters: R (the number of branches in the multi-resolution network), N (a tuple of R numbers specifying the number of layers in each branch), and D (a tuple of R numbers specifying the hidden size in each branch). The input size and latent size (for latent diffusion models) are also listed for each variant. The total number of parameters for each model is included.
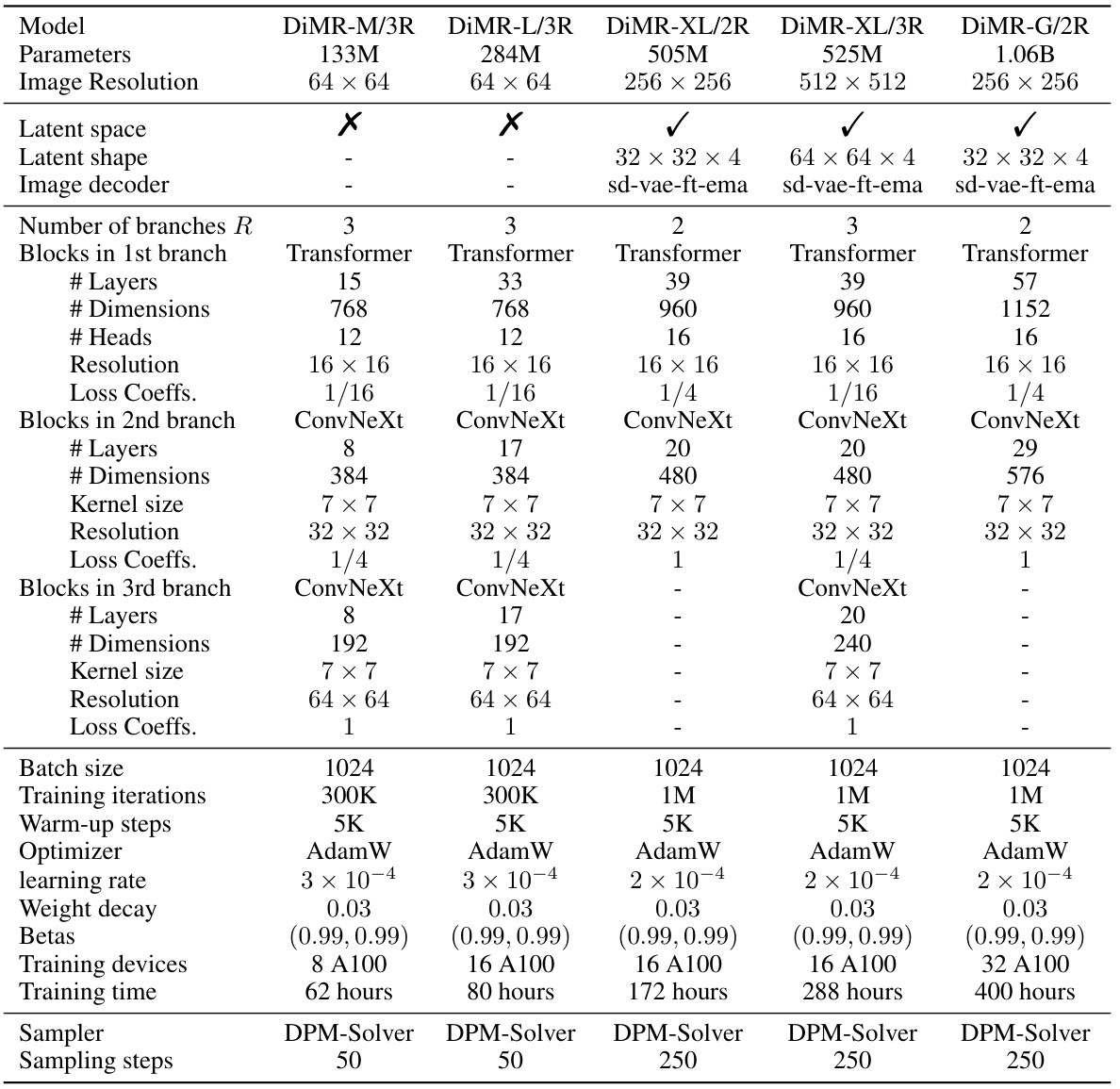
This table details the experimental setup used for different variants of the DiMR model. It covers aspects like model architecture (number of branches, layers, dimensions, etc.), training hyperparameters (batch size, optimizer, learning rate, weight decay, etc.), hardware resources (number of A100 GPUs), training time, and sampler details (sampler used and number of sampling steps). The table provides a comprehensive overview of the different configurations and parameters employed during the training process for each DiMR model variant.

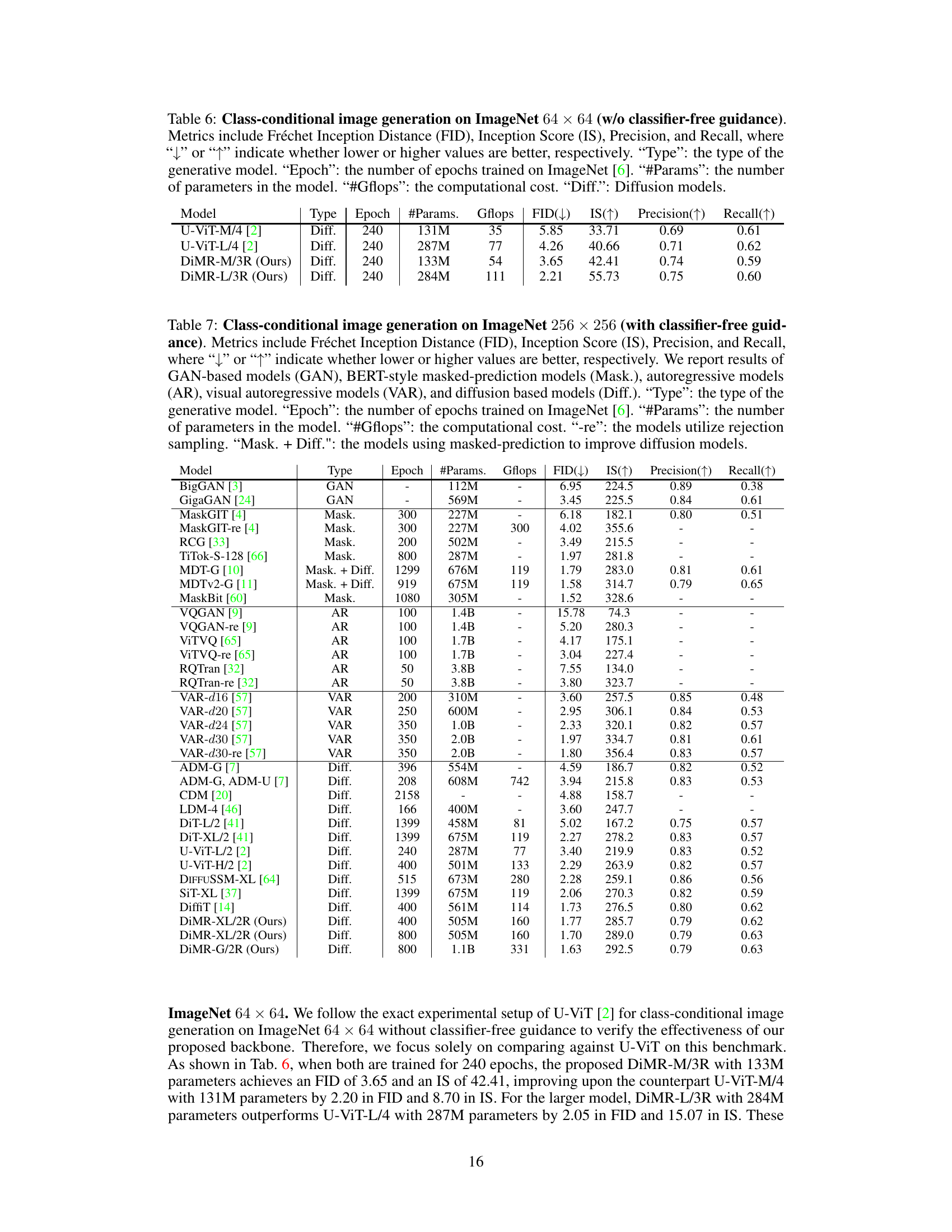
This table presents a comparison of different models’ performance on ImageNet 64x64 image generation without classifier-free guidance. It shows the FID, IS, precision, and recall scores, along with the model type, number of epochs trained, number of parameters, and computational cost (GFLOPs). Lower FID scores indicate better image quality, while higher IS, precision, and recall scores are preferred.
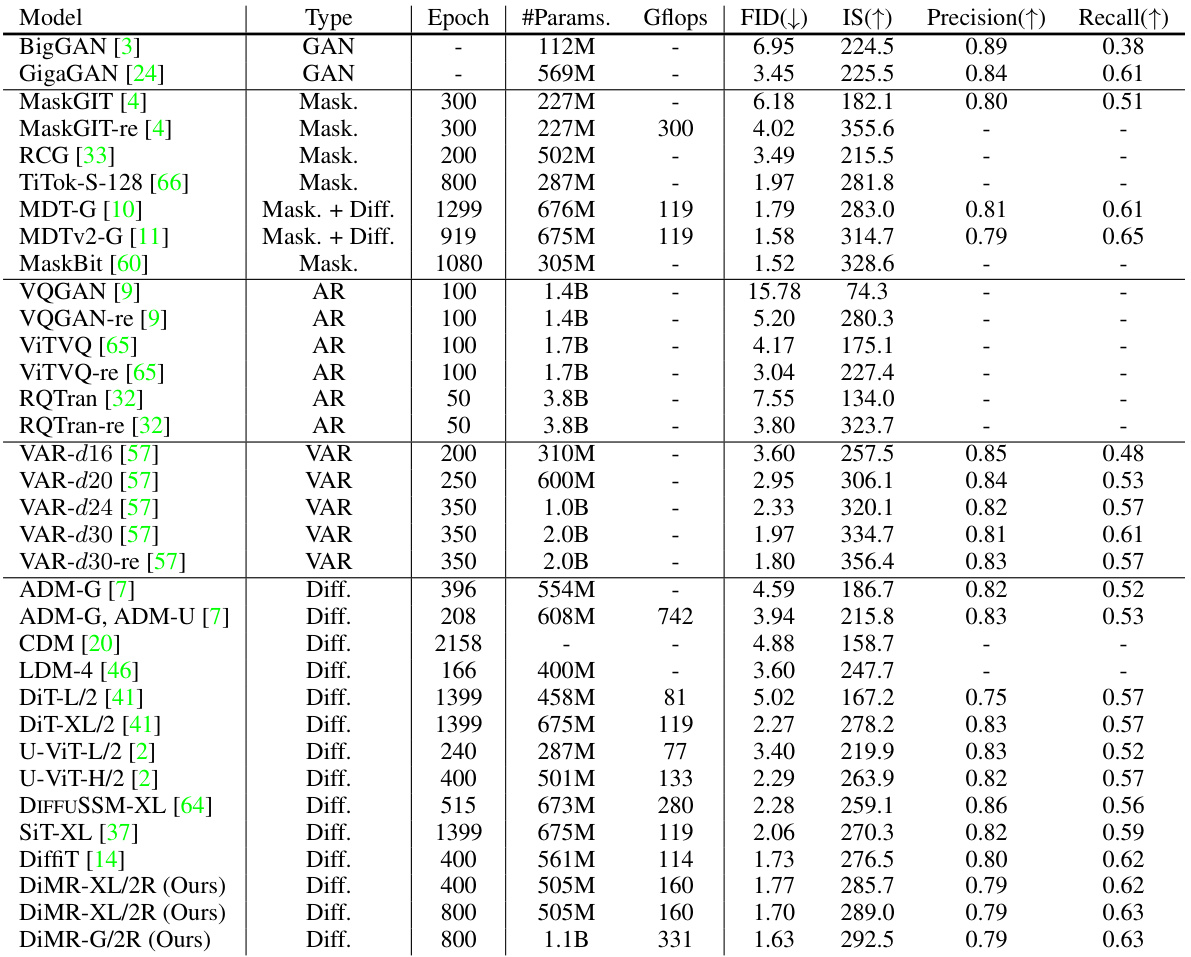
This table presents a comparison of different diffusion models on ImageNet 256x256 and 512x512 datasets in terms of FID scores (with and without classifier-free guidance), the number of parameters, and GFLOPs. It shows that the proposed DiMR models achieve state-of-the-art performance in terms of FID scores, highlighting their efficiency and effectiveness in high-fidelity image generation.

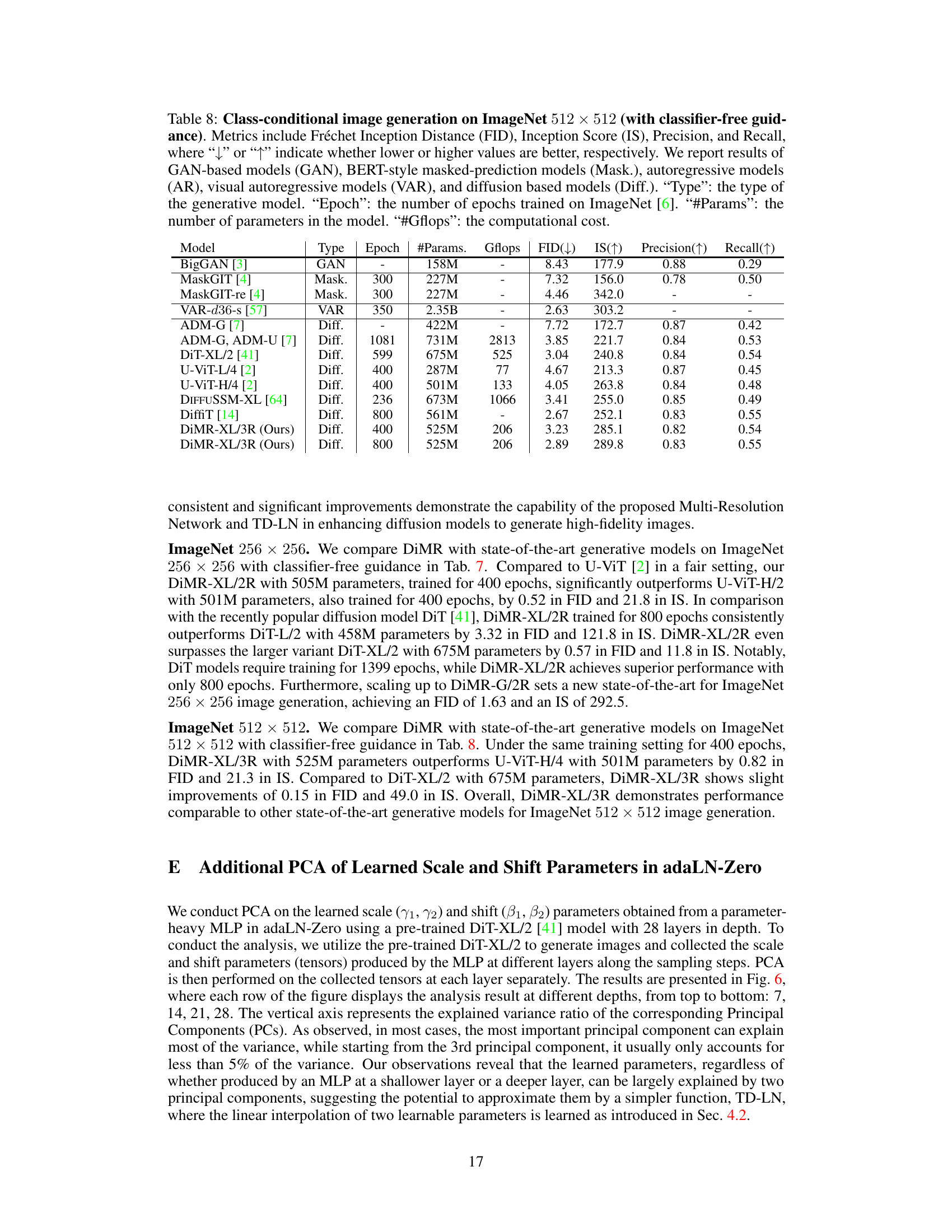
This table compares the performance of various generative models on the ImageNet 512x512 dataset when using classifier-free guidance. It presents key metrics such as FID, IS, Precision, and Recall, along with model type, training epochs, the number of parameters, and computational cost (GFLOPs). It allows for a comparison of different model architectures and training strategies on a challenging high-resolution image generation task.
Full paper#