↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Cooperative multi-agent reinforcement learning (MARL) faces a significant challenge: coordination. Existing methods often struggle because agents make decisions simultaneously, leading to conflicts. Asynchronous approaches, where agents act in a predetermined order, improve the situation but may not be optimal. Also, most current methods rely solely on communicating information about observations, not actual actions.
SeqComm addresses these issues with a two-phase approach. In the negotiation phase, agents communicate hidden information to establish a priority order. Then in the launching phase, high-priority agents act first and communicate their actions to lower-priority agents. This method ensures that actions are not made in conflicting ways. The paper proves that SeqComm monotonically improves and converges, and shows empirically that it outperforms existing methods on various tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for MARL researchers focusing on cooperative multi-agent tasks. It offers a novel solution to the coordination problem, a persistent challenge in the field. The theoretical guarantees and empirical results make it a significant contribution, opening new avenues for asynchronous communication strategies and priority-based decision-making.
Visual Insights#
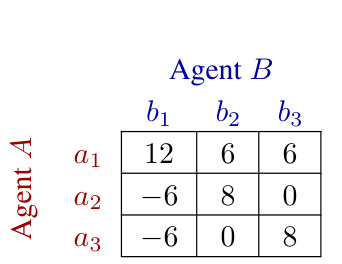
This figure demonstrates a simple one-step game with multiple local optima and compares four different decision-making methods: A decides first, B decides first, simultaneous decisions, and a learned priority policy. The graph shows the average reward and standard deviation across ten runs of each method, illustrating how the priority of decision-making impacts performance.
In-depth insights#
Async Multi-Agent#
Async multi-agent systems address the challenges of coordinating multiple agents operating independently and asynchronously. This asynchronicity introduces complexities in communication and decision-making as agents may not have access to the most up-to-date information on other agents’ actions and states. However, asynchronous models offer potential advantages in scalability and robustness, particularly in large-scale or distributed systems where synchronous communication could be a bottleneck. Effective solutions often involve sophisticated communication strategies to maintain coordination, such as partial-state sharing and prioritized decision-making. The design of asynchronous algorithms also requires careful consideration of data consistency, conflict resolution, and latency issues. Analyzing trade-offs between communication overhead and coordination efficiency is crucial when designing these systems, with a focus on achieving a balance between information availability and computational cost. Further research into asynchronous multi-agent systems could lead to significant advancements in areas such as distributed control, robotics, and machine learning.
SeqComm: A Novel Scheme#
SeqComm, as a novel multi-level communication scheme, presents a compelling approach to address the coordination challenges inherent in multi-agent reinforcement learning (MARL). Its asynchronous nature, where agents make decisions sequentially based on communicated information rather than simultaneously, effectively mitigates circular dependencies that often hinder effective collaboration. The scheme’s two-phase structure—negotiation and launching—is particularly noteworthy. The negotiation phase ingeniously leverages a world model to predict agents’ intentions, enabling them to determine the optimal decision-making order. The launching phase ensures informed action execution by communicating actions from higher-level agents to lower-level ones. This systematic approach to communication and asynchronous decision-making is supported by theoretical guarantees of monotonic improvement and convergence, providing a robust foundation for its effectiveness. Empirical results on various cooperative tasks demonstrate SeqComm’s superior performance compared to existing methods. While the assumptions underlying the world model require further investigation, the overall design of SeqComm offers a significant advance in addressing the challenges of cooperative MARL.
Theoretical Convergence#
A theoretical convergence analysis in a machine learning context, specifically within multi-agent reinforcement learning (MARL), rigorously examines the algorithm’s convergence properties. It likely involves proving that the algorithm’s learned policies monotonically improve and eventually converge to a solution, either optimal or near-optimal. The analysis would likely leverage mathematical tools such as Markov Decision Processes (MDPs) and associated theorems, potentially focusing on the convergence of value functions or policy updates. Crucially, the analysis must account for the inherent complexities of the multi-agent setting, such as partial observability, stochasticity, and the decentralized nature of the agents’ actions and information. A key aspect would be establishing conditions under which the convergence is guaranteed. These might involve constraints on the communication structure between agents, assumptions about the environment’s dynamics, or limitations on the agents’ policies. The proof would ideally demonstrate that the algorithm avoids problematic scenarios such as oscillations or divergence, ensuring a stable and reliable learning process. Finally, the analysis should clarify if the convergence holds for specific solution concepts such as Nash Equilibrium or Stackelberg Equilibrium, depending on the game-theoretic setting of the multi-agent system.
SMACv2 Experiments#
The SMACv2 experiments section of a reinforcement learning research paper would likely detail the empirical evaluation of a novel multi-agent coordination algorithm on the StarCraft II Multi-Agent Challenge environment version 2. This involves training the algorithm on several maps with varying difficulty levels, agent numbers, and unit compositions. Key aspects include a comparison against established baselines (e.g., centralized training with decentralized execution methods, communication-based algorithms) to demonstrate performance gains. Metrics used would probably be win rate or average reward, perhaps plotted over training steps to show learning curves. Ablation studies might investigate the impact of specific design choices, like the communication mechanism or the asynchronous decision-making scheme, by comparing performance against variants that exclude or modify such components. The results would ideally reveal the proposed algorithm’s effectiveness and efficiency in handling the complexities of multi-agent cooperation, particularly under conditions of partial observability and stochasticity. Statistical significance of the results would be crucial, using standard error bars or other measures of confidence, and detailed descriptions of experimental setup would enable reproducibility.
Ablation Study Insights#
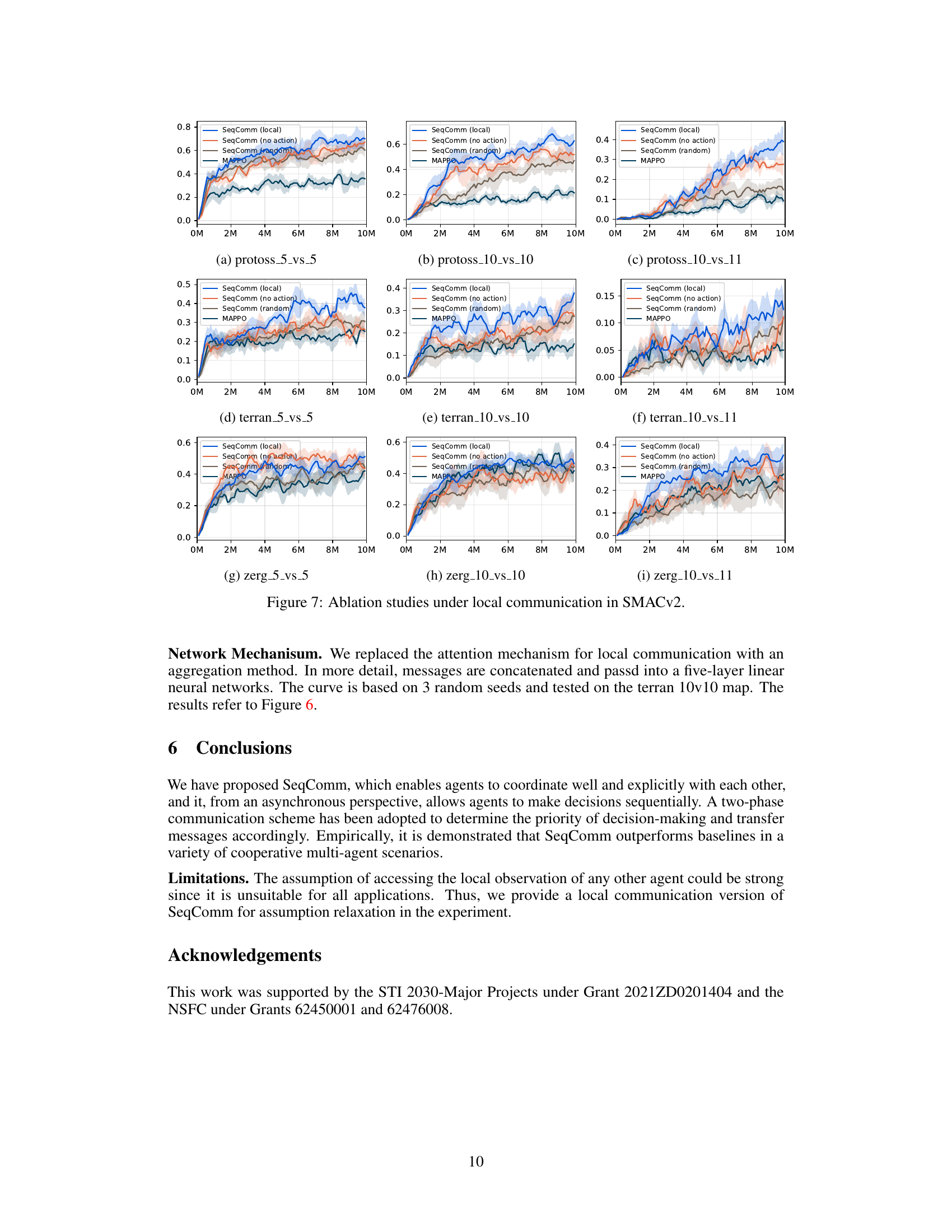
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of a multi-agent reinforcement learning (MARL) paper, such studies are crucial. Removing communication entirely would reveal the baseline performance achieved without any inter-agent information exchange. This helps assess the overall effectiveness of the proposed communication strategy. Varying communication range allows investigation into the trade-off between information richness and communication overhead. Restricting communication to only nearby agents can reveal whether local interactions suffice or global communication is essential for optimal performance. Modifying the priority mechanism helps evaluate if the algorithm’s ability to determine the order of decision-making is vital. By testing with random priorities or without prioritizing, the impact of this core component on coordination can be measured. Analyzing the attention mechanism will demonstrate its role in information selection and processing from multiple sources. Removing it reveals if the model’s effectiveness is inherent to its design or reliant on the attention mechanism to filter relevant information efficiently. Finally, combining these ablation results yields a comprehensive understanding of how the individual elements of the multi-level communication scheme contribute to the overall coordination performance in multi-agent tasks.
More visual insights#
More on figures
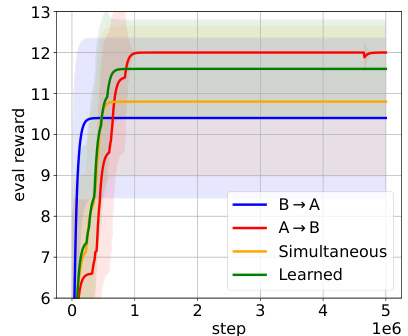
This figure shows a simple 2-agent game with multiple local optima and compares four different methods for learning the optimal strategy: Agent A decides first, Agent B decides first, both agents decide simultaneously, and a learned policy decides the order. The graph (b) displays the average reward for each method over ten runs, showing the impact of decision-making order on performance.
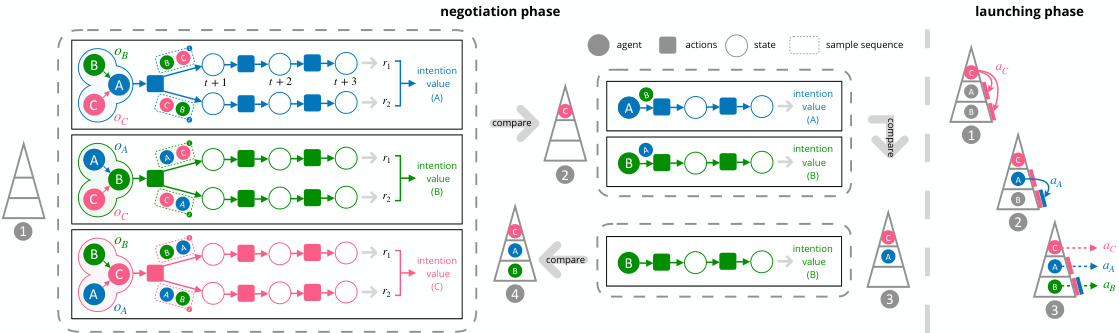
This figure illustrates the two-phase communication scheme of SeqComm. The negotiation phase shows agents communicating hidden state observations to determine decision-making priority based on intention values. The launching phase depicts upper-level agents making decisions first, communicating their actions to lower-level agents, and all agents executing actions simultaneously. The figure uses color-coding and arrows to represent information flow and decision-making order.
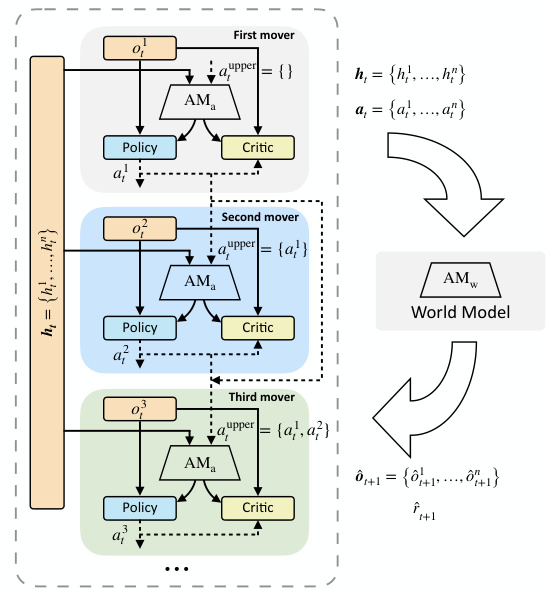
This figure illustrates the architecture of the SeqComm model. Each agent has a policy network, a critic network, and an attention module. The attention module takes in the hidden states of other agents as well as received messages from other agents. The policy network and critic network take in the agent’s own observations, as well as the information from the attention module. The output from the agent’s policy network is an action that is sent to the world model. The world model takes in the joint hidden states and predicted joint actions from all agents and outputs the next joint observations and rewards. This figure also shows that the agents’ decision-making is sequential, and the agents’ actions are executed simultaneously.
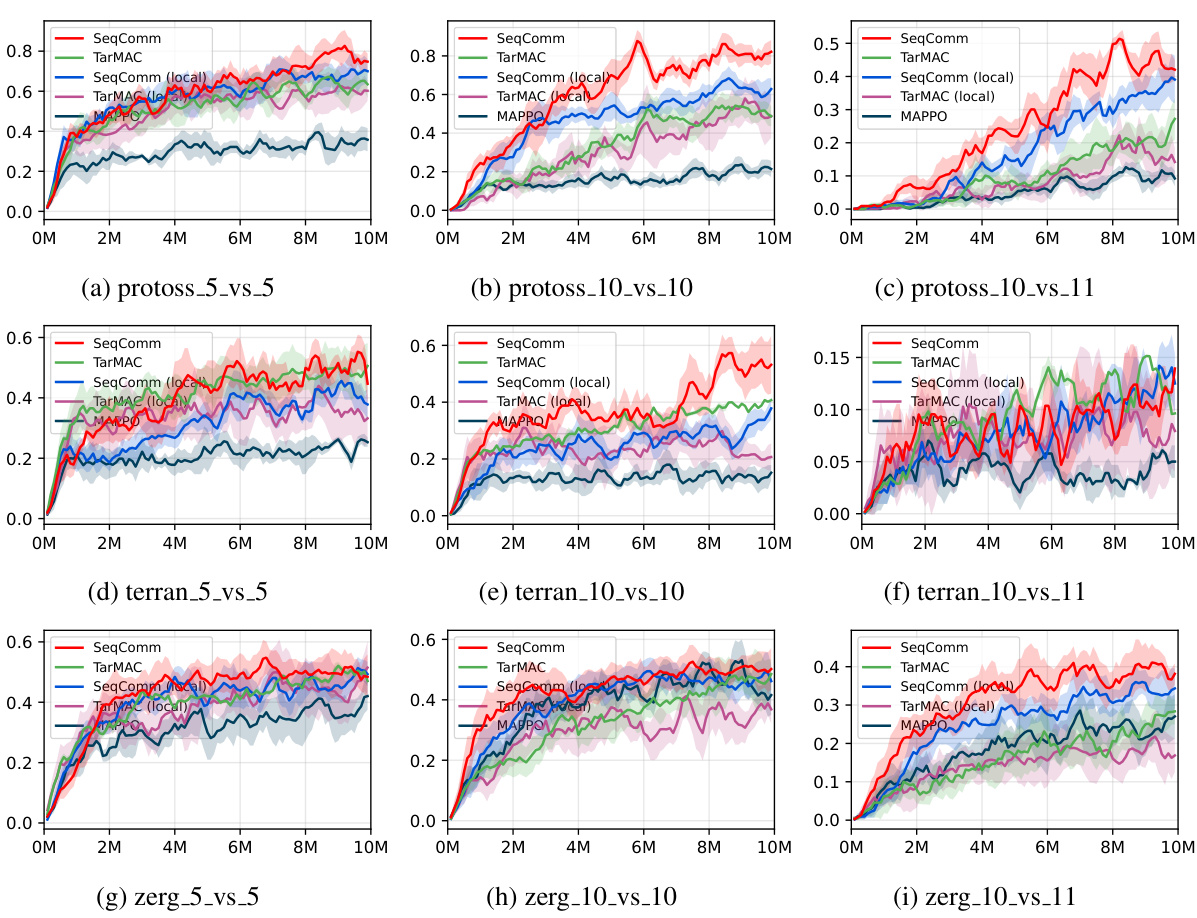
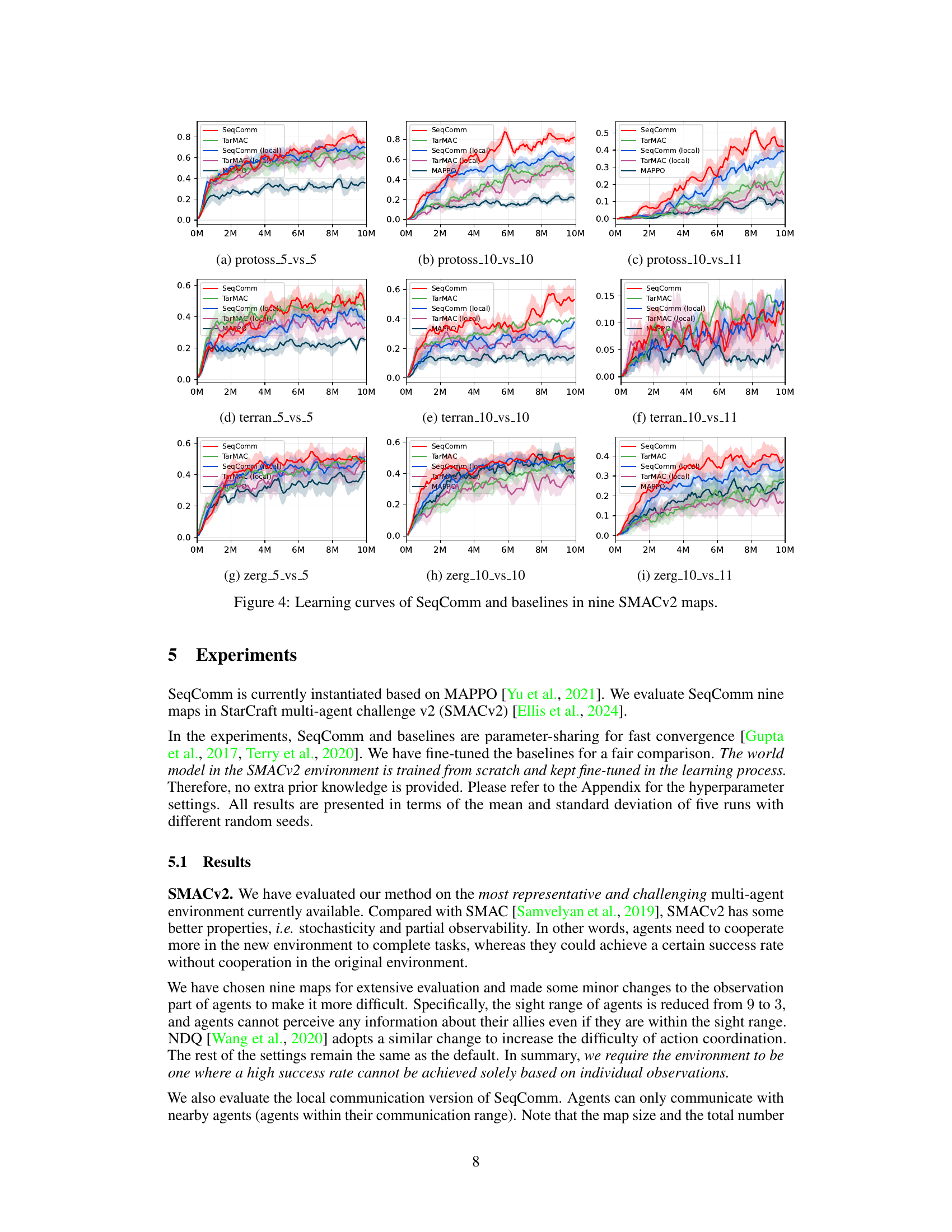
This figure presents the learning curves for SeqComm and several baseline methods across nine different maps in the StarCraft Multi-Agent Challenge v2 (SMACv2) environment. Each curve represents the average win rate over multiple training steps for a specific method on each map. The maps are categorized by race (Protoss, Terran, Zerg) and number of agents (5 vs 5, 10 vs 10, 10 vs 11). The figure helps visualize the performance of SeqComm in comparison to other methods across various scenarios within the SMACv2 environment. The shaded areas around the lines represent standard deviation.
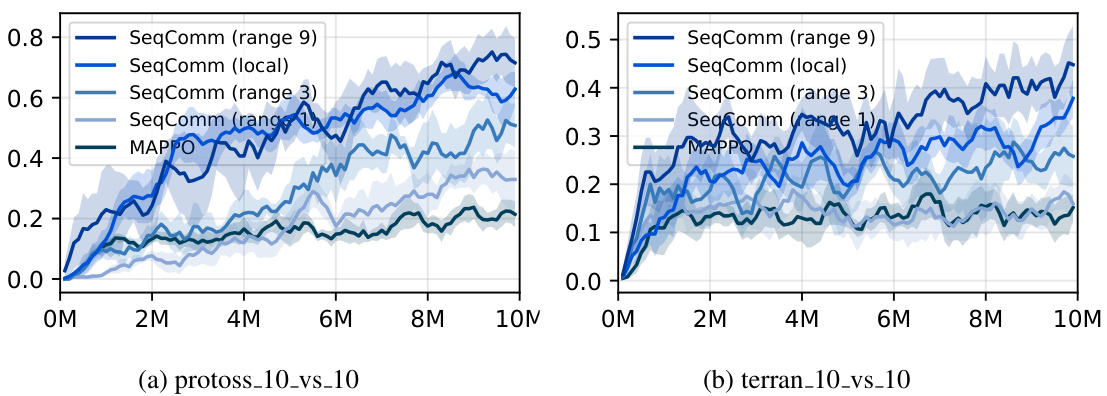
This figure shows the ablation study of communication ranges conducted on two maps: protoss_10_vs_10 and terran_10_vs_10. The performance of SeqComm is evaluated under different communication ranges (1, 3, 6, and 9), as well as the local communication version of SeqComm. The results demonstrate the impact of communication range on the performance of the model. A wider communication range generally leads to improved performance, but it also increases communication overhead. MAPPO (communication-free) is shown as a baseline for comparison.
This figure compares the performance of SeqComm against several baseline methods across nine different maps in the StarCraft Multi-Agent Challenge (SMACv2) environment. The x-axis represents the number of training steps (in millions), and the y-axis represents the average win rate. Each line represents a different algorithm or variant, and shaded areas represent standard deviations. The maps used are diverse, testing the algorithms under various scenarios and scales.

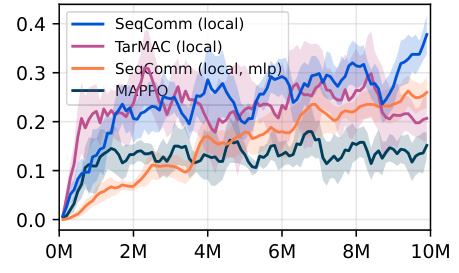
This figure presents the learning curves for different variants of SeqComm and baselines in nine SMACv2 maps. It compares the full communication version of SeqComm (SeqComm), a local communication version (SeqComm (local)), a version with random priority of decision making (SeqComm (random)), and a version with no action (SeqComm (no action)). The results show that SeqComm consistently outperforms the baselines and that the local communication version performs comparably well. The figure also demonstrates the importance of asynchronous decision making and the proper priority of decision making for achieving better coordination.
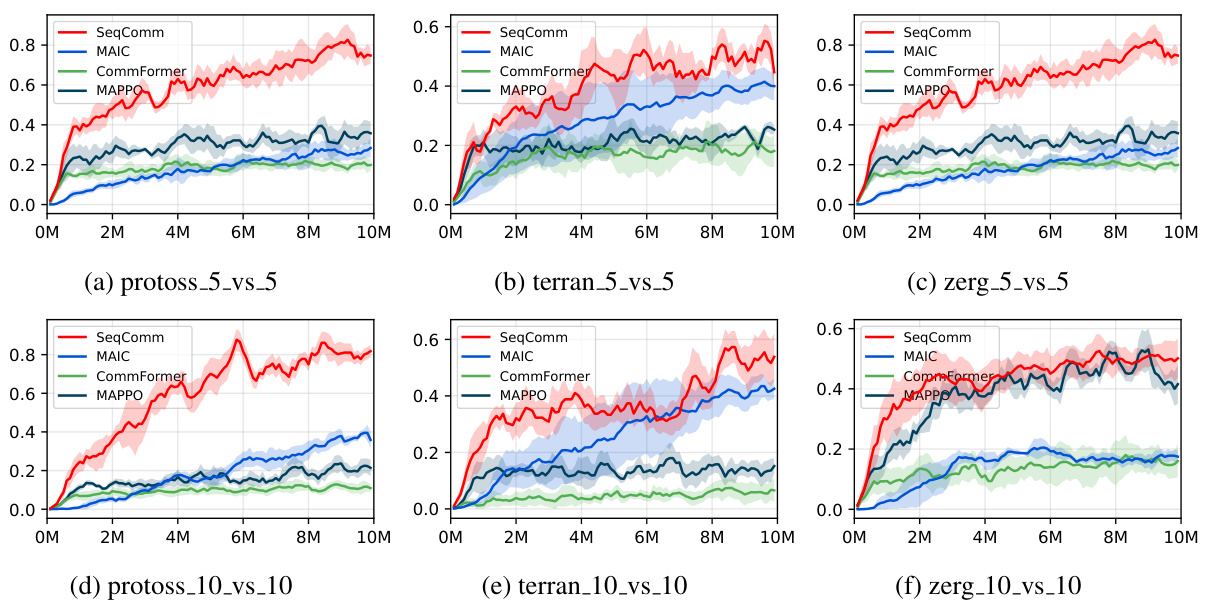
The figure compares SeqComm with MAIC and CommFormer across six different maps in StarCraft II. Each subplot represents a different map (Protoss, Terran, and Zerg, in 5v5 and 10v10 scenarios). The y-axis shows the win rate, and the x-axis shows the training steps. Error bars are included. The results demonstrate SeqComm’s superior performance compared to the baselines in various multi-agent cooperative scenarios.

This figure shows a series of screenshots from a StarCraft II game illustrating the emergent behavior of agents using the SeqComm algorithm. The screenshots show how the agents coordinate their actions over time. Initially, the agents act somewhat independently. Then, through a negotiation phase of communication, they establish a hierarchy (indicated by the levels), allowing them to coordinate and focus their attacks. The screenshots highlight the transition from chaotic behavior to coordinated attacks on the enemy units.
Full paper#