↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Out-of-distribution (OOD) detection, crucial for safe real-world machine learning, faces challenges with current reconstruction-based methods. These methods struggle to balance strong reconstruction power with compact ID data representation, leading to ineffective OOD identification. Existing generative models often rely on pixel-level reconstruction, consuming significant time and resources.
The proposed method tackles these issues by using a diffusion model for layer-wise semantic feature reconstruction. This approach leverages the diffusion model’s intrinsic data reconstruction ability to distinguish ID and OOD samples in the latent feature space, achieving a comprehensive and discriminative representation. The multi-layer strategy ensures compact ID representation while effectively separating OOD samples. Experimental results demonstrate state-of-the-art performance, showcasing enhanced accuracy and speed compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to unsupervised out-of-distribution detection, a critical problem in machine learning. The diffusion-based layer-wise semantic reconstruction method offers a significant improvement in accuracy and speed compared to existing methods. This opens new avenues for research in OOD detection and enhances the robustness and safety of real-world machine learning systems.
Visual Insights#

This figure illustrates the proposed framework’s architecture for unsupervised out-of-distribution (OOD) detection. It consists of three main modules: 1. Multi-layer semantic feature extraction: Extracts features from different layers of the input image, providing both low-level and high-level semantic information. 2. Diffusion-based feature distortion and reconstruction: Uses a diffusion model to add Gaussian noise to the extracted features and then reconstructs them, aiming to differentiate ID and OOD samples based on reconstruction errors. 3. OOD detection head: A module that uses the reconstruction errors from the previous stage to classify the input image as either in-distribution (ID) or OOD. The overall process leverages the ability of diffusion models to reconstruct data and compact representation of ID data in feature space, improving OOD detection accuracy and speed.

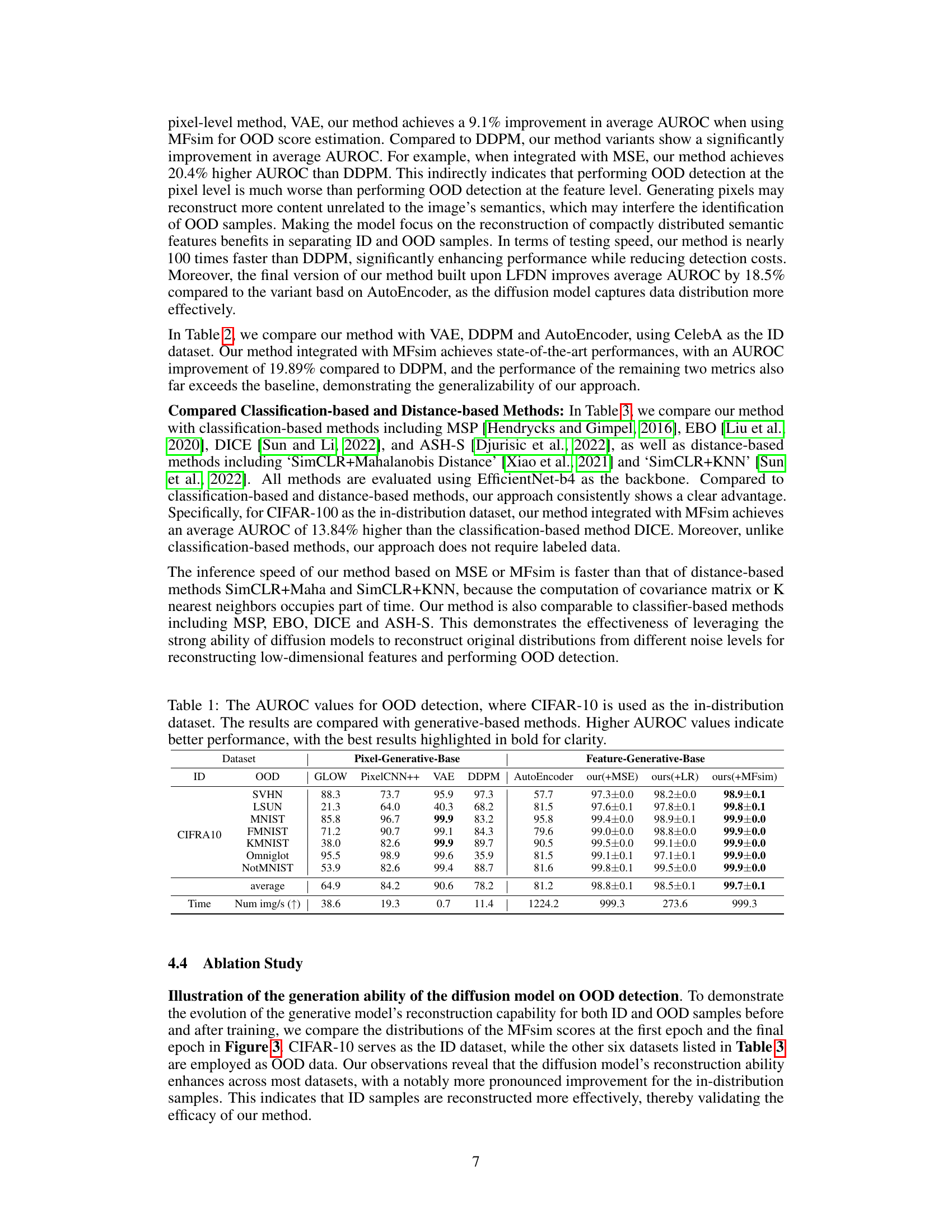
This table presents the AUROC (Area Under the Receiver Operating Characteristic) scores for out-of-distribution (OOD) detection experiments. The in-distribution (ID) dataset used is CIFAR-10. The table compares the performance of the proposed method with several existing generative-based methods (GLOW, PixelCNN++, VAE, DDPM) for various OOD datasets. Higher AUROC values indicate better performance in distinguishing between in-distribution and out-of-distribution samples. The table also includes the average AUROC across all OOD datasets and the number of images processed per second for each method.
In-depth insights#
Diffusion OOD#
Diffusion models have shown promise in out-of-distribution (OOD) detection. Their ability to model complex data distributions allows them to effectively distinguish in-distribution (ID) samples from OOD samples. However, a key challenge is balancing reconstruction quality with compact latent space representations. Methods employing diffusion models for OOD detection often focus on pixel-level reconstruction, which can be computationally expensive. A more efficient approach may be to leverage layer-wise semantic features, applying diffusion models in the latent feature space, allowing for the separation of ID and OOD data based on reconstruction errors. This approach addresses the tradeoff between representation power and compactness, leading to more efficient and effective OOD detection.
Semantic Recon#
Semantic reconstruction, in the context of unsupervised out-of-distribution (OOD) detection, aims to disentangle the meaningful semantic features of in-distribution (ID) data from irrelevant or noisy aspects. By focusing on these core semantic components, a model can better generalize and accurately distinguish between ID and OOD instances. The effectiveness of this approach hinges on the ability to learn a compact yet robust representation of ID data’s semantic content. A successful semantic reconstruction method should robustly reconstruct ID data while exhibiting poor reconstruction performance for OOD samples, thus providing a strong signal for OOD detection. The key challenges lie in defining what constitutes a ‘meaningful’ semantic representation, and designing algorithms that can capture and reconstruct these features effectively, whilst remaining computationally efficient.
Multi-layer feats#
The concept of “Multi-layer feats” suggests a deep learning approach where multiple layers of feature extractors are used to capture increasingly complex and abstract representations of the input data. This is a crucial aspect for robust out-of-distribution (OOD) detection because shallow features may not fully differentiate between in-distribution (ID) and OOD samples. By incorporating these multi-layer features, the model can learn both low-level details and high-level semantic information. Low-level layers might capture edge and texture information, while deeper layers could focus on object shapes and contextual relationships. This comprehensive representation allows the model to establish a discriminative feature space where ID data clusters tightly, enabling clear separation from OOD samples based on reconstruction errors. This approach is especially beneficial in tackling the challenge of simultaneously improving reconstruction accuracy while maintaining a compact ID representation. The effectiveness of multi-layer features hinges upon the proper design of the feature extraction architecture and how well each layer contributes to the overall discriminative power. It is essential to consider how well different layers’ features integrate to form a holistic and informative representation, ultimately leading to a more reliable OOD detection system.
LFDN Network#
The Latent Feature Diffusion Network (LFDN) is a novel architecture proposed for unsupervised out-of-distribution (OOD) detection. Its core innovation lies in operating directly on extracted multi-layer semantic features, rather than pixel-level data, improving efficiency and focusing on semantically relevant information. LFDN leverages the intrinsic data reconstruction capabilities of diffusion models to distinguish between in-distribution (ID) and OOD samples. By introducing Gaussian noise to these features and then using the LFDN to reconstruct them, the network learns a compact representation of ID features, allowing for effective separation from noisy, poorly reconstructed OOD features. The multi-layer approach enhances the discriminative power of the feature representation, leading to improved OOD detection accuracy. The use of diffusion models offers resilience to varying noise levels, enabling robust performance without dataset-specific fine-tuning, a significant advantage over traditional methods. The architecture’s effectiveness is further demonstrated by its state-of-the-art performance across various datasets.
OOD Detection#
Out-of-distribution (OOD) detection is a crucial aspect of building robust and reliable machine learning systems. The core challenge lies in identifying data points that deviate significantly from the distribution of the training data, which standard models may misclassify with high confidence. This is especially important for real-world applications where encountering unseen data is inevitable. Existing methods often employ reconstruction-based approaches, focusing on pixel-level or feature-level reconstruction errors. A key innovation in this domain is the use of diffusion models, offering powerful reconstruction capabilities and inherent ability to distinguish between in-distribution and out-of-distribution samples. This approach leverages the diffusion model’s ability to reconstruct data corrupted by noise, with larger reconstruction errors indicative of OOD samples. Multi-layer semantic feature extraction further enhances this process, providing a more comprehensive representation to distinguish subtle differences in semantic content between ID and OOD samples. The effectiveness of various metrics like MSE, LR, and MFsim in evaluating the reconstruction errors also plays a significant role in the detection performance.
More visual insights#
More on figures
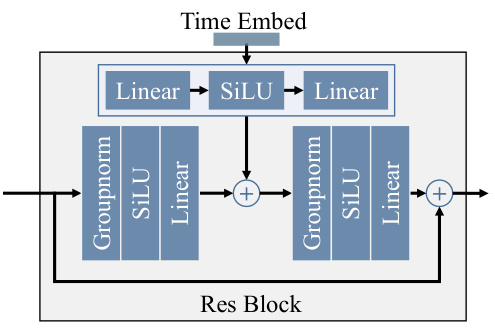
This figure shows the architecture of a residual block (ResBlock) used in the Latent Feature Diffusion Network (LFDN). The ResBlock consists of a main branch and a residual branch. The main branch includes Groupnorm, SiLU, and Linear layers. The residual branch consists of three linear layers and a SiLU activation function. The time embedding is also incorporated into the residual block. The outputs of the main and residual branches are then summed together to produce the final output of the ResBlock.
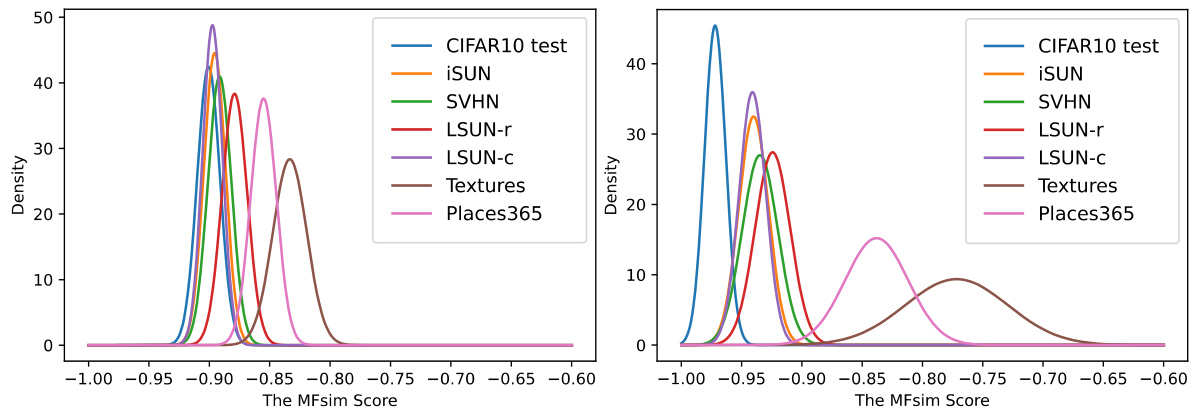
This figure shows the evolution of the MFsim score distributions for both in-distribution (ID) and out-of-distribution (OOD) samples across different datasets (CIFAR-10 as ID, others as OOD). The left panel displays the distributions at the first epoch of training, while the right panel shows the distributions after the model has been trained. The comparison highlights the model’s improved ability to distinguish between ID and OOD samples after training, as evidenced by the greater separation of distributions in the right panel. This visual representation demonstrates the effectiveness of the proposed diffusion-based layer-wise semantic reconstruction framework for unsupervised OOD detection.
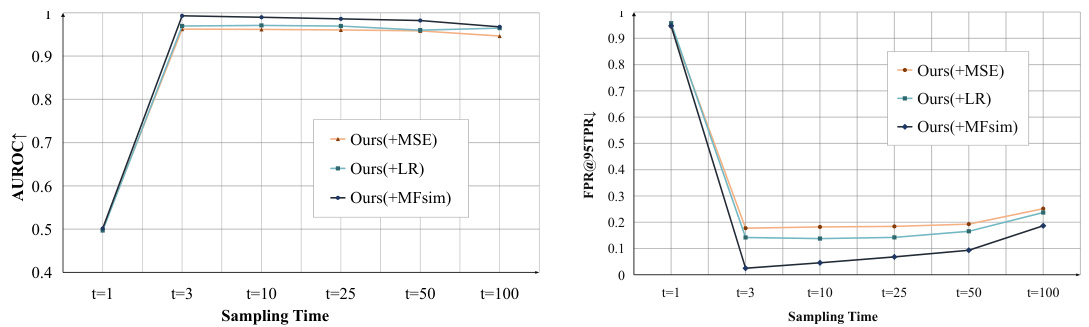
The figure shows the performance of the proposed method with different sampling time steps (t). The x-axis represents the sampling time step, while the y-axis shows AUROC and FPR@95TPR. The results demonstrate how the performance changes with different noise levels added during the feature distortion process. It helps to find the optimal noise level for better OOD detection performance.

This figure shows a schematic of the proposed diffusion-based layer-wise semantic reconstruction framework for unsupervised OOD detection. It consists of three main modules: a multi-layer semantic feature extraction module that processes the input image and extracts features at multiple levels, a diffusion-based feature distortion and reconstruction module that adds noise to the features and uses a diffusion network to reconstruct them, and an OOD detection head module that uses the reconstruction error to classify the input as either in-distribution (ID) or out-of-distribution (OOD).

This figure shows the distribution of MFsim scores for both in-distribution (ID) and out-of-distribution (OOD) samples at the beginning and end of training. The change in distribution demonstrates the model’s improved ability to distinguish between ID and OOD samples over time. The ID samples’ MFsim scores become more tightly clustered around a lower value, while the OOD samples remain more dispersed and have higher scores. This visualization supports the effectiveness of the model’s reconstruction process in separating ID and OOD data in the feature space.

This figure shows the distribution of MFsim scores for both in-distribution (ID) and out-of-distribution (OOD) samples at the beginning and end of training. The plots illustrate how the model’s ability to distinguish between ID and OOD samples improves during training. The distribution of MFsim scores for ID samples becomes more concentrated near 0, while the distribution for OOD samples remains relatively flat.
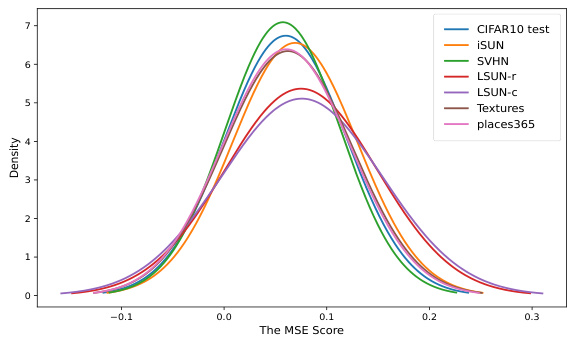
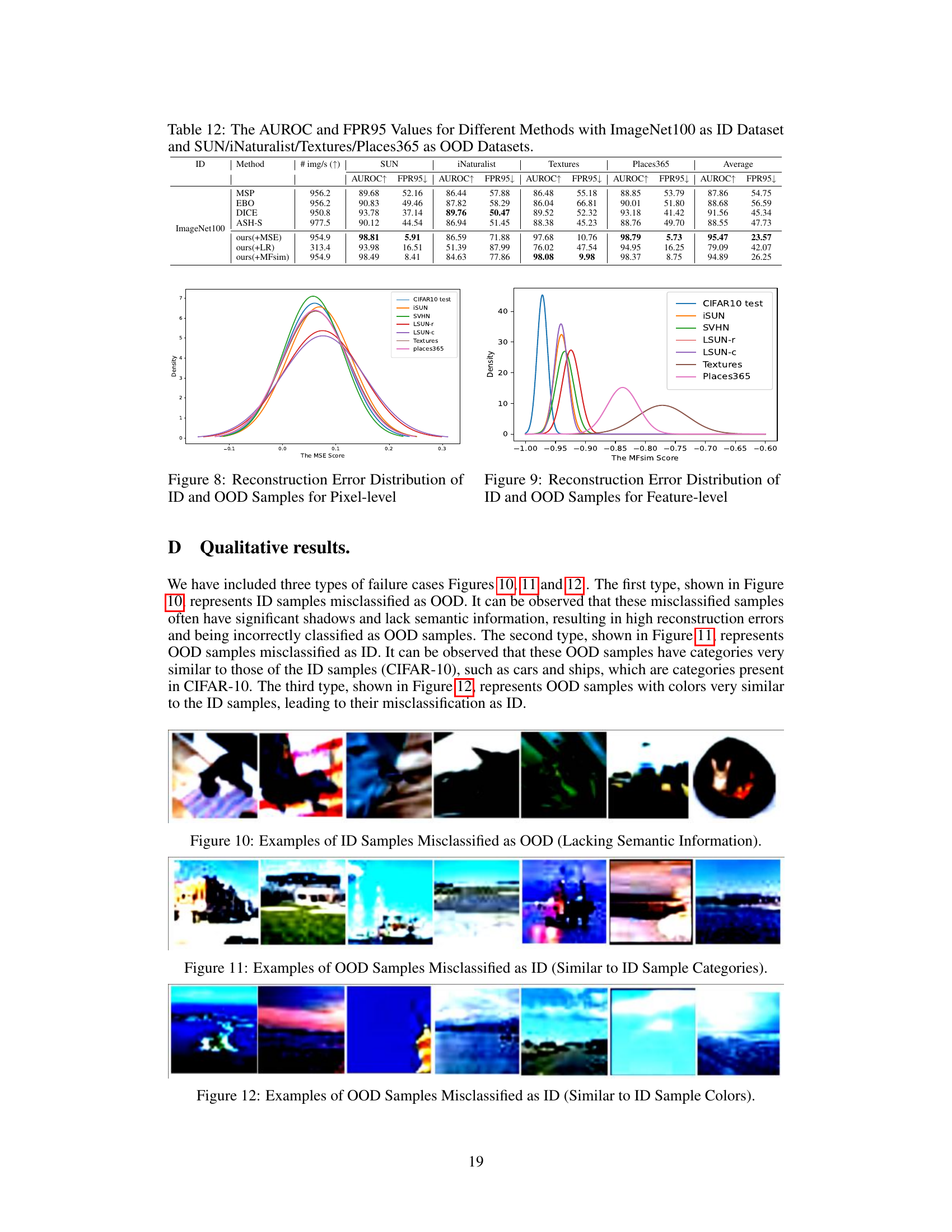
This figure shows the distribution of reconstruction errors (MSE) for both in-distribution (ID) and out-of-distribution (OOD) samples at the pixel level. The different colored curves represent different datasets. The purpose is to illustrate that at the pixel level, it is difficult to distinguish ID and OOD samples based on reconstruction error alone, as the distributions overlap significantly.
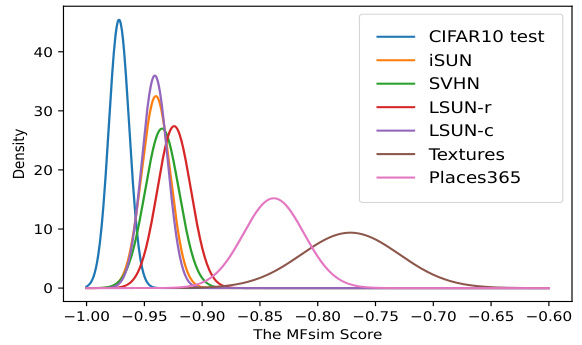
This figure shows the distribution of MFsim scores for both in-distribution (ID) and out-of-distribution (OOD) samples at the beginning and end of training. The change in distribution demonstrates the model’s improved ability to distinguish ID from OOD data over time, as the reconstruction error for ID samples decreases while that of OOD samples remains relatively stable. This illustrates the efficacy of the proposed diffusion-based layer-wise semantic reconstruction framework for unsupervised OOD detection.

This figure illustrates the proposed framework for unsupervised out-of-distribution detection. The framework consists of three main modules: 1. Multi-layer semantic feature extraction which extracts features from multiple layers of a CNN; 2. Diffusion-based feature distortion and reconstruction that applies a diffusion model for feature reconstruction after adding Gaussian noise to multi-layer semantic features; and 3. OOD detection head module which evaluates the reconstruction error for OOD detection.
More on tables
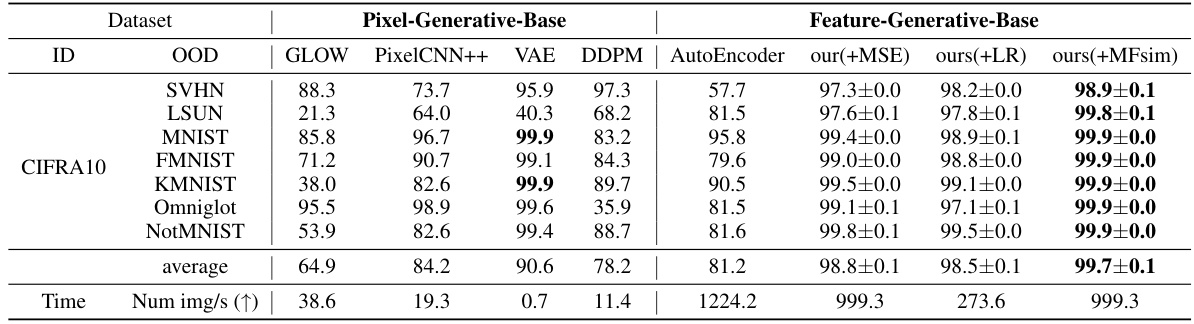
This table presents a comparison of the proposed method’s AUROC (Area Under the Receiver Operating Characteristic) scores against several pixel-level and feature-level generative baselines on various OOD (Out-of-Distribution) detection tasks. The CIFAR-10 dataset is used as the in-distribution dataset. Higher AUROC values indicate better performance in distinguishing in-distribution from out-of-distribution samples. The table also includes the number of images processed per second for each method.
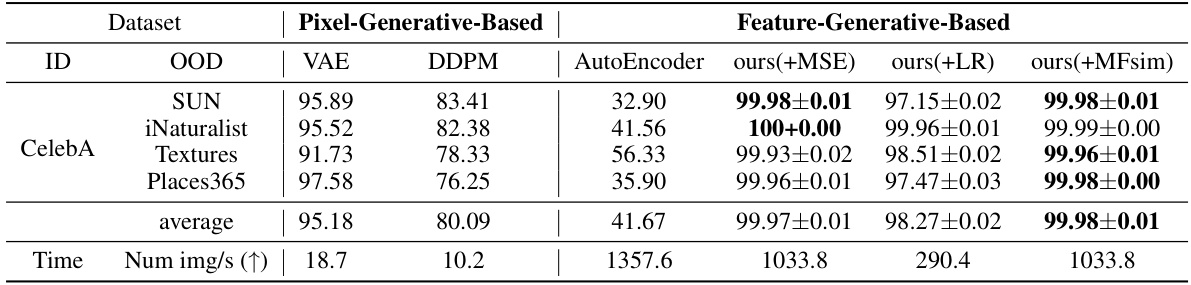
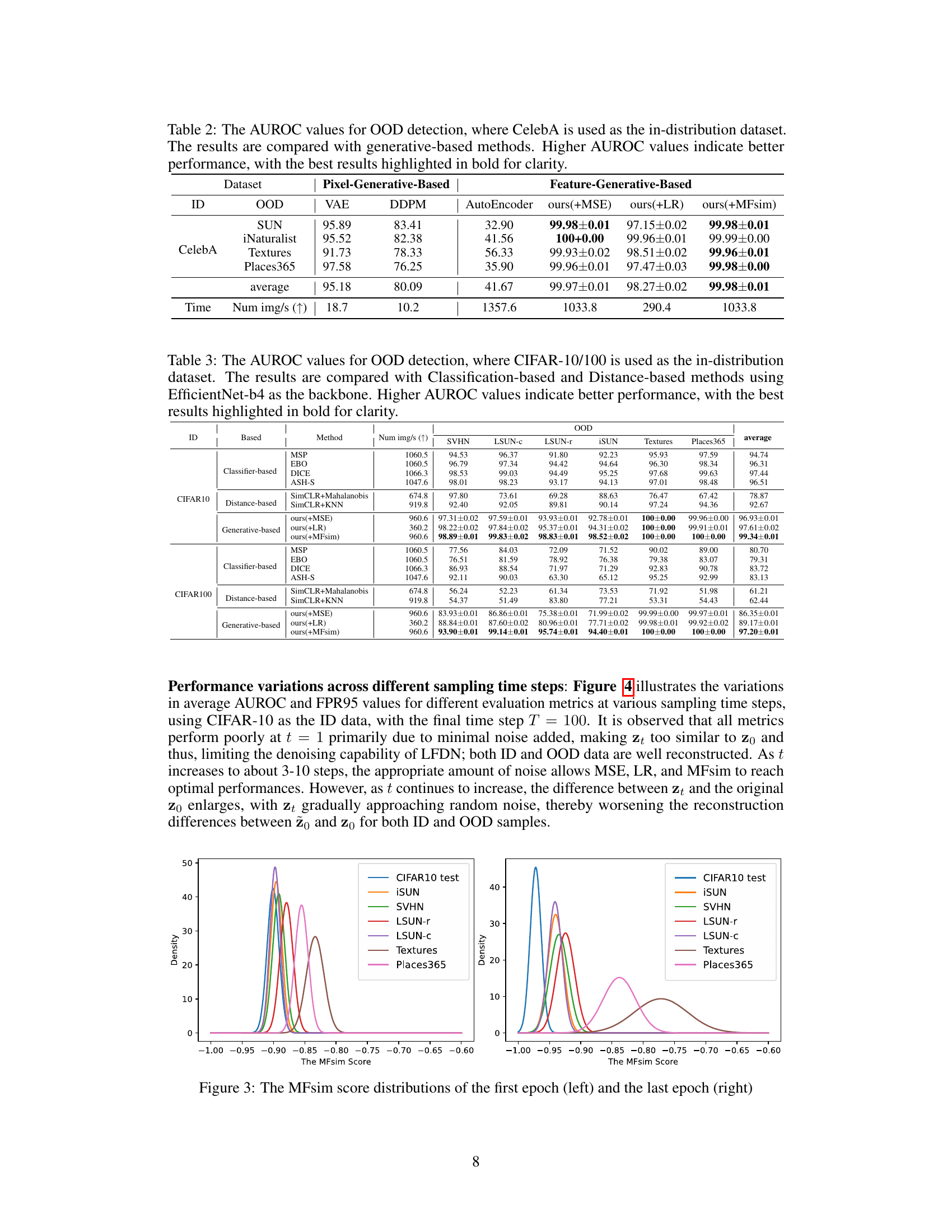
This table presents the Area Under the Receiver Operating Characteristic (AUROC) scores for out-of-distribution (OOD) detection using the CelebA dataset as the in-distribution data. It compares the performance of the proposed method with existing generative-based methods (VAE, DDPM, and AutoEncoder) across multiple OOD datasets. Higher AUROC values signify better performance in distinguishing between in-distribution and out-of-distribution samples.
This table presents the AUROC (Area Under the Receiver Operating Characteristic) scores for out-of-distribution (OOD) detection on various datasets. The in-distribution (ID) dataset used for training the models is CIFAR-10. The table compares the performance of the proposed diffusion-based layer-wise semantic reconstruction method with several existing generative-based methods, including GLOW, PixelCNN++, VAE, and DDPM. Higher AUROC scores indicate better performance in distinguishing between in-distribution and out-of-distribution samples. The table also includes the speed of processing images for each method, indicating the computational efficiency.

This table presents the ablation study results on the impact of different network parameters in LFDN on the AUROC metric. It compares the average AUROC across six datasets (SVHN, LSUN-C, LSUN-R, iSUN, Textures, Places365) using two different linear layer dimensions (Linear=720 and Linear=1440) and two different numbers of ResBlocks (Number=8 and Number=16) within the LFDN. It shows how variations in these network parameters affect the model’s performance, indicating the robustness of the MFsim metric in providing effective OOD detection capabilities even under conditions of reduced network size.

This table presents the AUROC (Area Under the Receiver Operating Characteristic) scores for out-of-distribution (OOD) detection using different generative models. The in-distribution dataset used for training is CIFAR-10. The table compares the performance of the proposed method against several baseline generative models (GLOW, PixelCNN++, VAE, DDPM) and a variant of the proposed model using an autoencoder instead of the Latent Feature Diffusion Network (LFDN). Higher AUROC values indicate better performance in distinguishing in-distribution from out-of-distribution samples. The table also includes the number of images processed per second for each method.

This table compares the AUROC (Area Under the Receiver Operating Characteristic) scores achieved by the proposed method against several pixel-level and feature-level generative baselines for out-of-distribution (OOD) detection on various datasets. CIFAR-10 is used as the in-distribution (ID) dataset, and various other datasets are used as out-of-distribution (OOD) datasets. The table highlights the superior performance of the proposed method, particularly when using the MFsim (Multi-layer Feature Similarity) metric, which demonstrates state-of-the-art results across multiple OOD datasets compared to other methods such as VAE and DDPM.

This table compares the performance of the proposed diffusion-based layer-wise semantic reconstruction method for unsupervised OOD detection against several other generative-based methods on the CIFAR-10 dataset. It shows AUROC (Area Under the Receiver Operating Characteristic) scores, a common metric for evaluating the performance of OOD detection systems. The results are broken down by dataset used for out-of-distribution (OOD) testing and the specific method used. The table also shows the inference speed of each method in images per second. Higher AUROC scores and faster inference speeds indicate better performance.
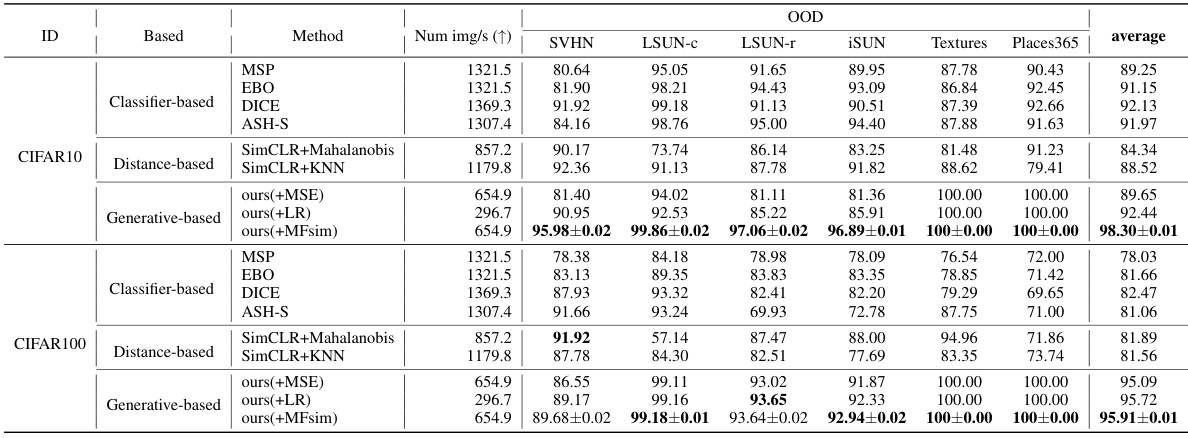
This table presents the AUROC (Area Under the Receiver Operating Characteristic) values for out-of-distribution (OOD) detection using CIFAR-10 as the in-distribution dataset. It compares the performance of the proposed method against several existing generative-based methods, including GLOW, PixelCNN++, VAE, and DDPM. Higher AUROC scores indicate better performance in distinguishing in-distribution from out-of-distribution samples. The table also shows the inference speed (images per second) for each method.

This table presents the Area Under the Receiver Operating Characteristic (AUROC) values for out-of-distribution (OOD) detection using various generative models. The in-distribution dataset used is CIFAR-10, and the results are compared against several baselines (GLOW, PixelCNN++, VAE, DDPM). The table also includes results for three variants of the proposed method (ours(+MSE), ours(+LR), ours(+MFsim)), highlighting the superior performance achieved by the proposed method.

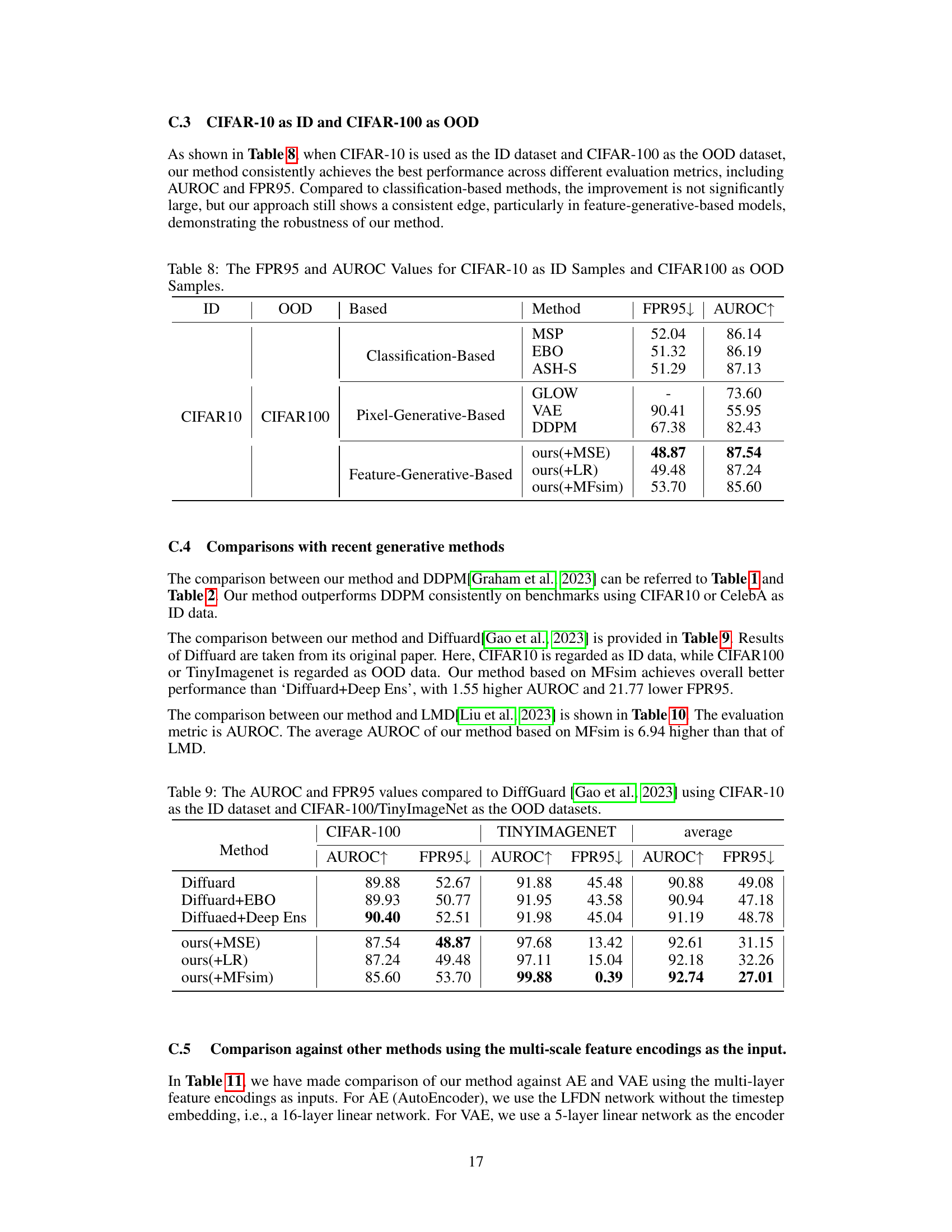
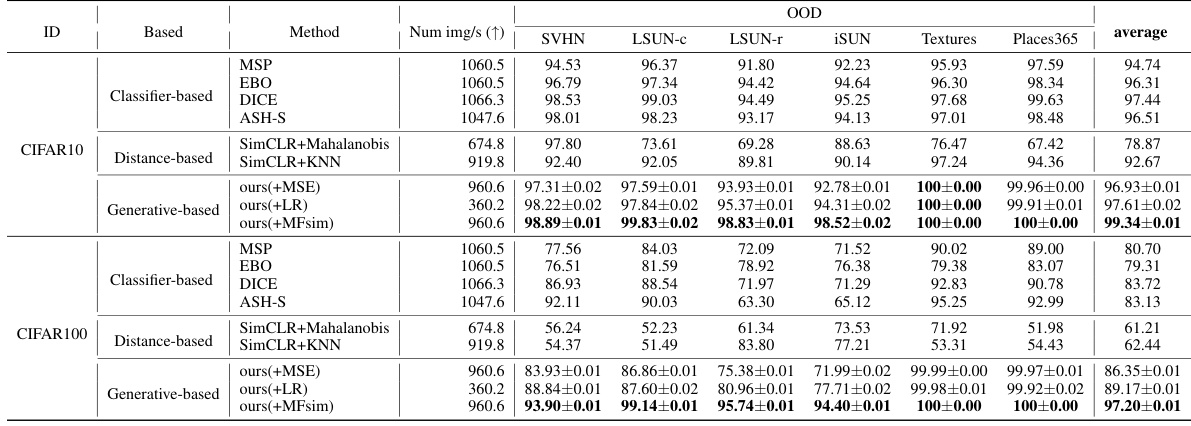
This table presents the False Positive Rate at 95% True Positive Rate (FPR95) and the Area Under the Receiver Operating Characteristic curve (AUROC) for different OOD detection methods. The in-distribution dataset is CIFAR-10, and the out-of-distribution dataset is CIFAR-100. The methods are categorized into Classification-Based, Pixel-Generative-Based, and Feature-Generative-Based. The table shows the performance of each method in terms of both FPR95 and AUROC, allowing for comparison across different approaches and identifying the best-performing method.

This table compares the performance of the proposed method against the Diffuard method for out-of-distribution (OOD) detection. The in-distribution dataset used is CIFAR-10, while the out-of-distribution datasets are CIFAR-100 and TinyImageNet. The metrics used for comparison are AUROC (Area Under the Receiver Operating Characteristic curve) and FPR95 (False Positive Rate at 95% true positive rate). Higher AUROC values and lower FPR95 values indicate better performance.

This table compares the AUROC (Area Under the Receiver Operating Characteristic) values achieved by the proposed method against the LMD (Likelihood Regret Metric) method. The comparison is done across multiple in-distribution (ID) and out-of-distribution (OOD) dataset combinations. The results show the AUROC scores for each combination and provide an average performance across all the combinations.

This table compares the AUROC (Area Under the Receiver Operating Characteristic) scores of the proposed diffusion-based method against two other generative models (AutoEncoder and Variational Autoencoder) for out-of-distribution (OOD) detection. The comparison uses CIFAR-10 as the in-distribution dataset and several other datasets as out-of-distribution datasets. The table highlights the superior performance of the diffusion-based approach, particularly in terms of AUROC scores and inference speed.

This table presents the AUROC (Area Under the Receiver Operating Characteristic) scores for out-of-distribution (OOD) detection using various generative models. The in-distribution dataset used is CIFAR-10. The table compares the performance of several pixel-level and feature-level generative methods, including GLOW, PixelCNN++, VAE, DDPM, AutoEncoder, and the proposed method (ours) using different metrics (MSE, LR, MFsim). The best results are highlighted in bold, showing the superior performance of the proposed method in terms of AUROC. Additionally, the number of images processed per second is also listed, showing a significant speed improvement for the proposed approach.
Full paper#