↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current state-of-the-art (SOTA) methods for fair text-to-image generation utilize prompt learning with reference images, but this approach suffers from suboptimal sample quality. The paper’s analysis reveals that the training objective of aligning embedding differences between learned prompts and reference images is inadequate, leading to distorted prompts and lower-quality outputs. This issue is further analyzed using cross-attention map analysis, revealing abnormalities in early denoising steps that perpetuate improper global structure.
To address these issues, the authors propose FairQueue, a novel method incorporating prompt queuing and attention amplification. Prompt queuing addresses early-stage denoising problems by prioritizing base prompts, ensuring proper global structure before introducing more specific prompts. Attention amplification enhances target sensitive attributes expression. Extensive experiments show that FairQueue significantly outperforms the SOTA method in terms of image generation quality while maintaining competitive fairness across multiple sensitive attributes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on fair text-to-image generation. It reveals limitations in existing prompt learning methods, proposes novel solutions to enhance image quality and fairness, and introduces valuable quantitative analysis techniques. These contributions can significantly improve the fairness and quality of AI-generated images, impacting various applications.
Visual Insights#
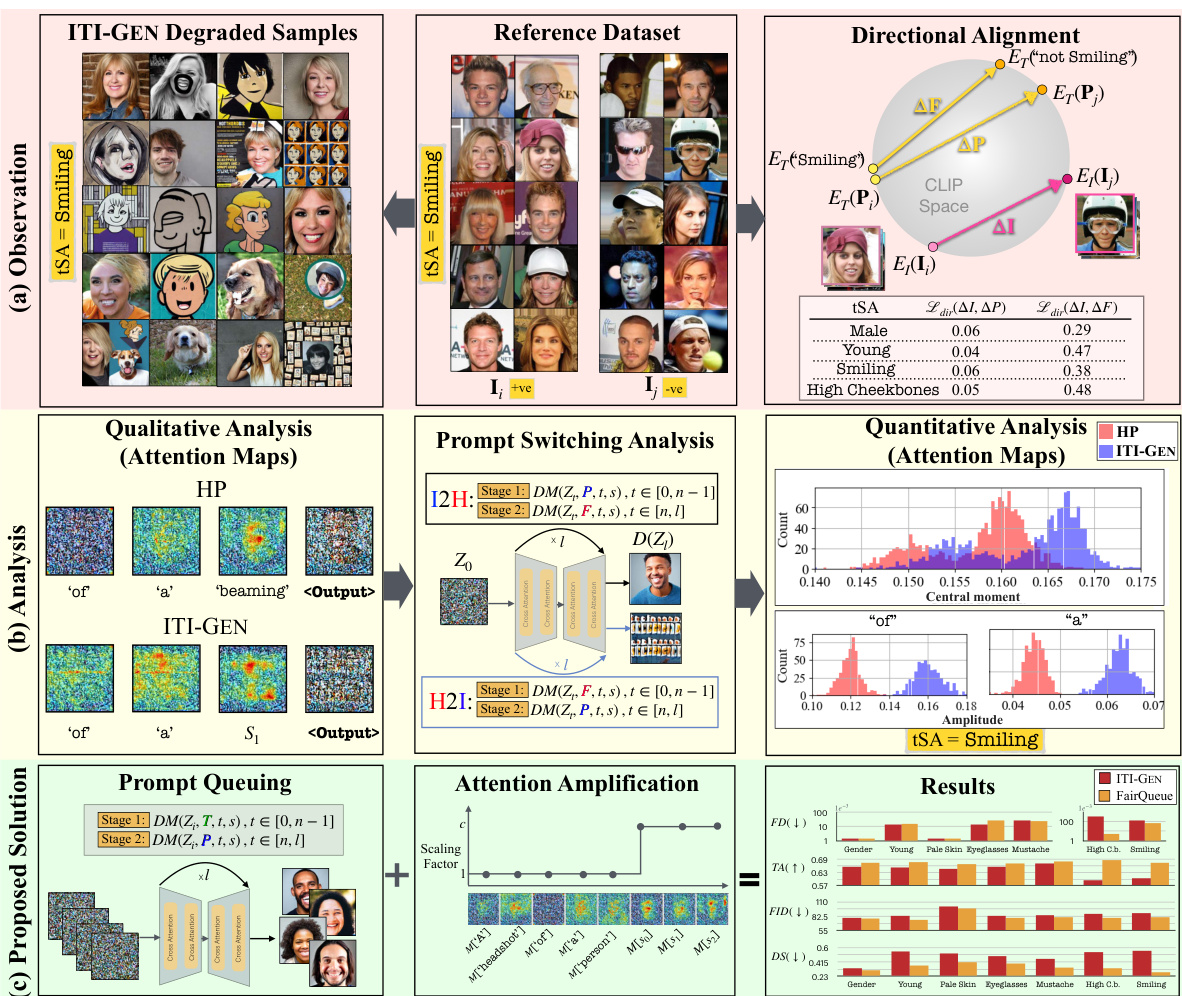
This figure shows the main idea of the paper. It starts with the observation that the state-of-the-art (SOTA) fair text-to-image (T2I) generation method, ITI-GEN, suffers from degraded image quality. The authors analyze the cross-attention maps of the ITI-GEN model to identify the root cause, which is the sub-optimal learning objective leading to distorted prompts. Based on this analysis, the authors propose a novel solution, called FairQueue, which addresses the quality issue while achieving competitive fairness.
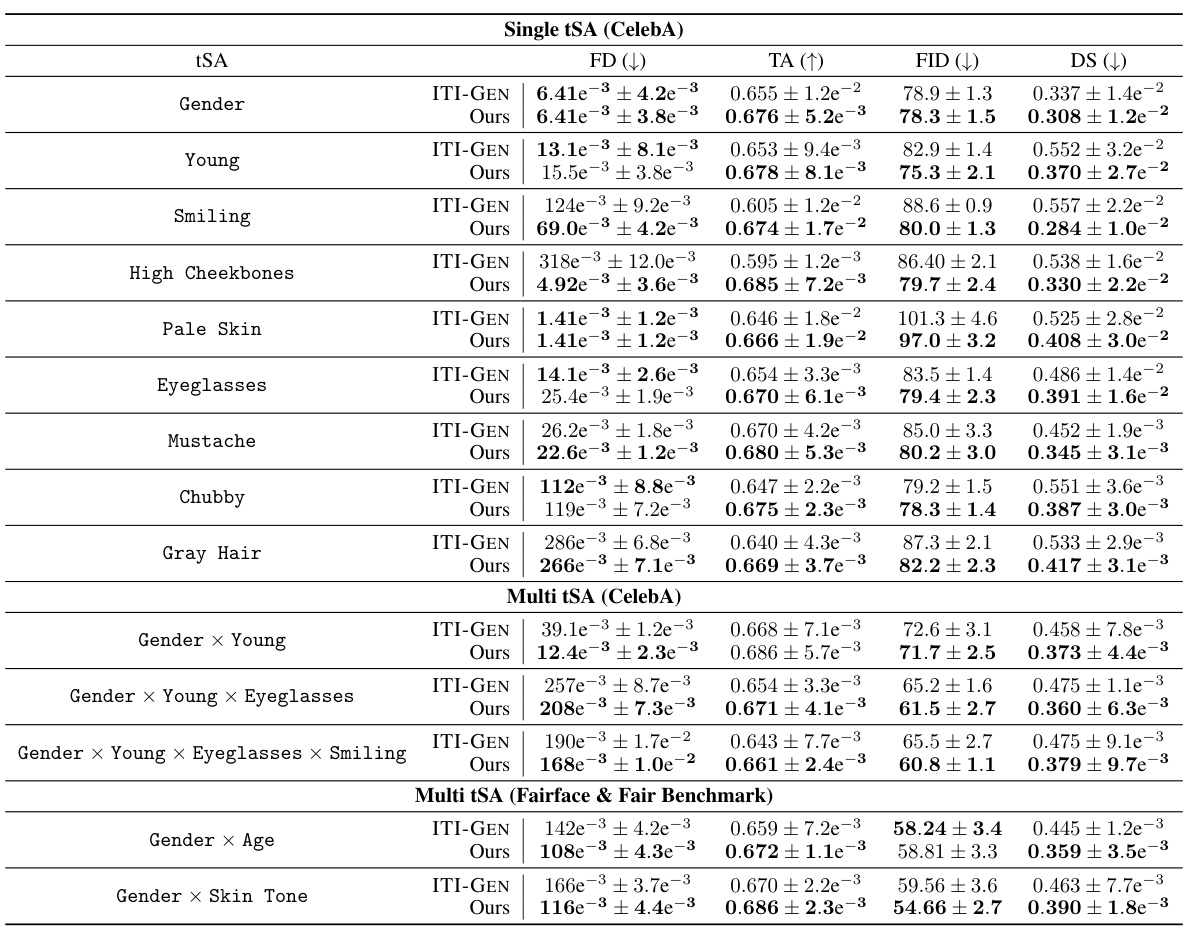
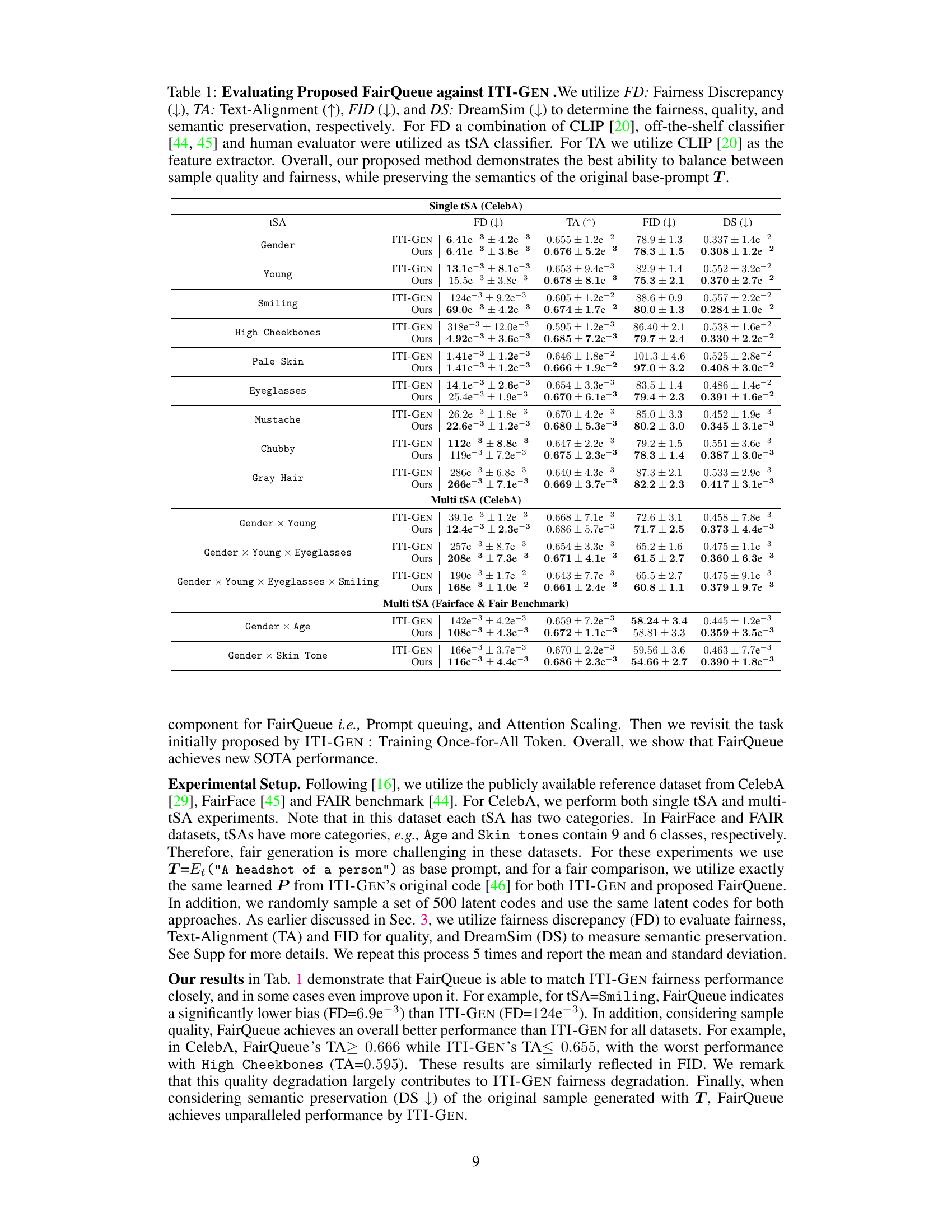
This table presents a quantitative comparison of the proposed FairQueue method against the state-of-the-art ITI-GEN method for fair text-to-image generation. It evaluates performance across various sensitive attributes (tSAs), using metrics for fairness (Fairness Discrepancy - FD), quality (Text-Alignment - TA and Fréchet Inception Distance - FID), and semantic preservation (DreamSim - DS). The results show FairQueue achieves a better balance of fairness and quality compared to ITI-GEN.
In-depth insights#
Prompt Learning Issues#
Prompt learning, while effective for fair text-to-image generation, presents significant challenges. A core issue is the sub-optimality of training objectives that aim to align prompt and reference image embeddings. This often leads to distorted prompts incorporating unrelated visual elements beyond the target sensitive attribute. This distortion manifests in degraded image quality, evidenced by artifacts and a lack of proper global structure in generated images. Analysis of cross-attention maps reveals that these learned prompts introduce abnormalities, particularly in early denoising steps, hindering proper global structure formation and perpetuating these issues into the final output. Addressing these issues requires careful consideration of prompt engineering, potential reliance on alternative training objectives that better capture semantic relationships, and exploration of techniques to mitigate the effects of noisy reference images that confound the learning process. Careful evaluation metrics are crucial to fully capture these multifaceted problems and the effectiveness of proposed solutions.
ITI-GEN Analysis#
The ITI-GEN analysis section likely delves into a critical evaluation of the Inclusive Text-to-Image Generation (ITI-GEN) model, a state-of-the-art approach for fair image generation. The analysis likely begins by observing the quality of images produced by ITI-GEN and notes a degradation in sample quality, despite achieving fairness. The core issue seems to stem from the sub-optimal prompt learning approach, which leverages reference images to learn inclusive prompts for each target sensitive attribute. The analysis likely explores this discrepancy, perhaps through detailed examination of the ITI-GEN’s training objective and its impact on prompt embeddings, revealing potential issues such as distortions in the prompts due to the inclusion of unrelated concepts from the reference images. To pinpoint the cause of quality degradation, the authors likely investigate the image generation process itself, focusing on cross-attention maps to determine the effects of distorted prompts. This likely involves visualizing and quantifying abnormalities in the attention mechanisms, particularly in the early stages of image generation. This deep dive into the denoising network provides evidence to support the claim that distorted prompts lead to degraded global structure, directly affecting the final image output. The section concludes by potentially highlighting the need for improved prompt learning strategies, suggesting modifications to overcome the quality issues without compromising fairness.
FairQueue Approach#
The FairQueue approach tackles the limitations of existing prompt learning methods for fair text-to-image generation. It addresses the problem of degraded image quality observed in previous approaches like ITI-GEN, which primarily focuses on aligning the embeddings of reference images and learned prompts, potentially incorporating unrelated concepts into the learned prompts. FairQueue cleverly introduces prompt queuing, prioritizing base prompts in early denoising stages to ensure proper global structure, then introducing ITI-GEN prompts for fine-grained details. This strategy, combined with attention amplification, which enhances the influence of the tSA tokens in the generation process, leads to improved image quality while maintaining competitive fairness. The method’s success is demonstrated through extensive experimental results, showcasing its superiority in balancing fairness and generation quality over existing SOTA models. The underlying analysis, focusing on cross-attention maps, provides valuable insights into the root causes of quality degradation in existing methods, making FairQueue a significant step towards robust and fair text-to-image generation.
Ablation Experiments#
Ablation experiments systematically remove components of a model to understand their individual contributions. In a text-to-image generation model, this could involve removing modules responsible for handling specific aspects of the process such as prompt encoding, cross-attention mechanisms, or different stages of the diffusion process. By observing how performance metrics (like FID, precision, recall) change after removing each part, researchers gain crucial insights into each component’s impact. Well-designed ablation studies are essential for isolating the sources of both success and failure, allowing for more targeted improvements in future iterations. The results could highlight, for example, the relative importance of prompt encoding techniques versus the denoising process and inform the design of more efficient and robust models. A weakness in this methodology is that removing components might lead to unexpected interactions between remaining parts, potentially underestimating a component’s actual contribution, or causing a misleading conclusion.
Future Directions#
Future directions in this research could explore several promising avenues. Extending FairQueue to handle more complex scenarios, such as those involving multiple interacting sensitive attributes or those with higher degrees of linguistic ambiguity, would significantly enhance its practical applicability. Investigating the generalizability of FairQueue across diverse T2I models is also crucial to establish its robustness and widespread utility. Furthermore, a deeper dive into the underlying mechanisms by which prompt queuing and attention amplification improve both fairness and image quality is needed to provide a stronger theoretical foundation for the approach. Finally, developing new quantitative metrics to more comprehensively evaluate the performance of fair text-to-image models beyond fairness, quality and semantic preservation alone would improve the evaluation framework and accelerate further research in the domain. Incorporating user feedback into the generation pipeline is also important to ensure the approach aligns with user expectations and real-world demands for fairness and high quality image generation.
More visual insights#
More on figures

This figure compares the performance of three methods (HP, ITI-GEN, and FairQueue) for generating images based on text prompts with minimal linguistic ambiguity. HP shows high quality and fairness, while ITI-GEN shows degraded quality and slightly lower fairness. FairQueue achieves comparable performance to HP, indicating that it successfully addresses the quality degradation issues of ITI-GEN while maintaining competitive fairness.

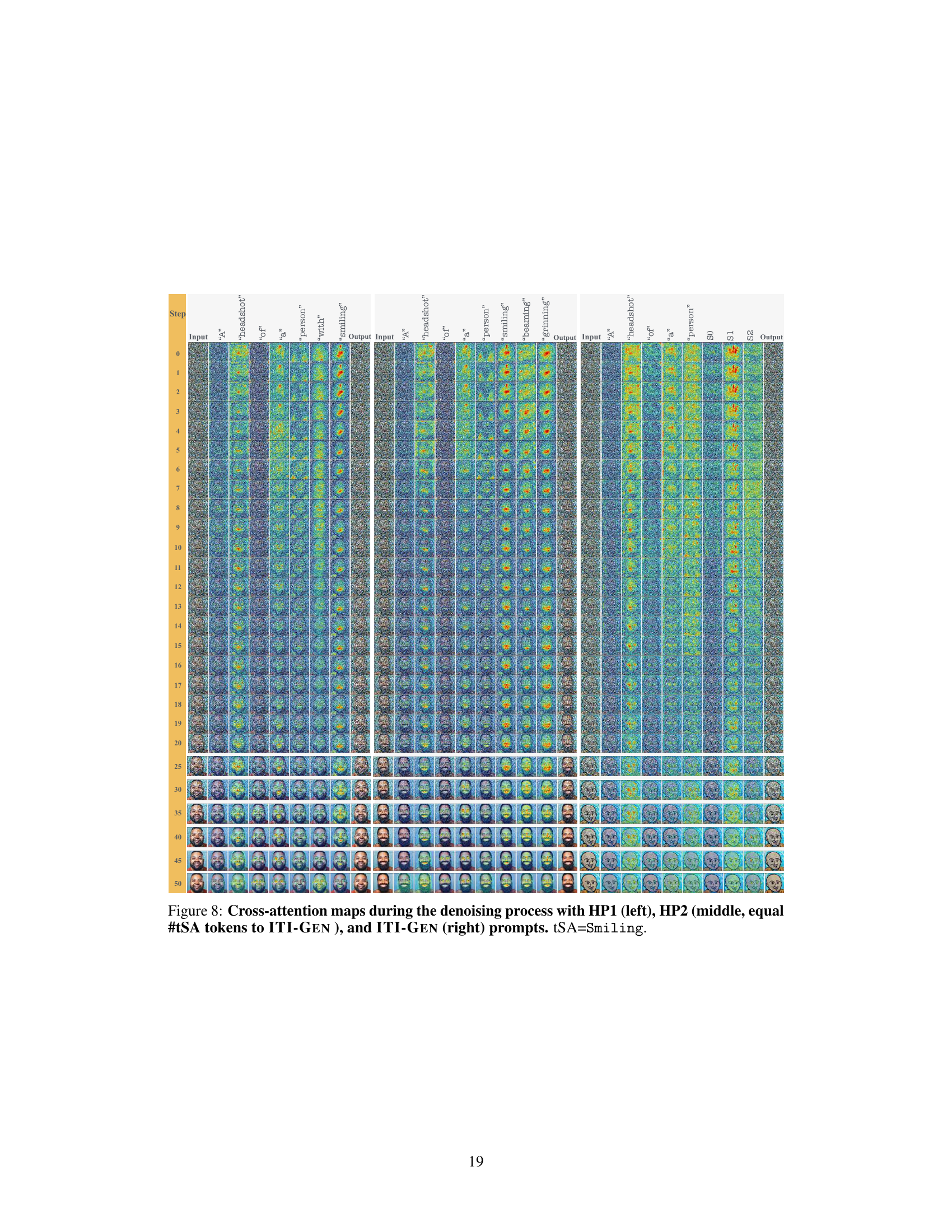
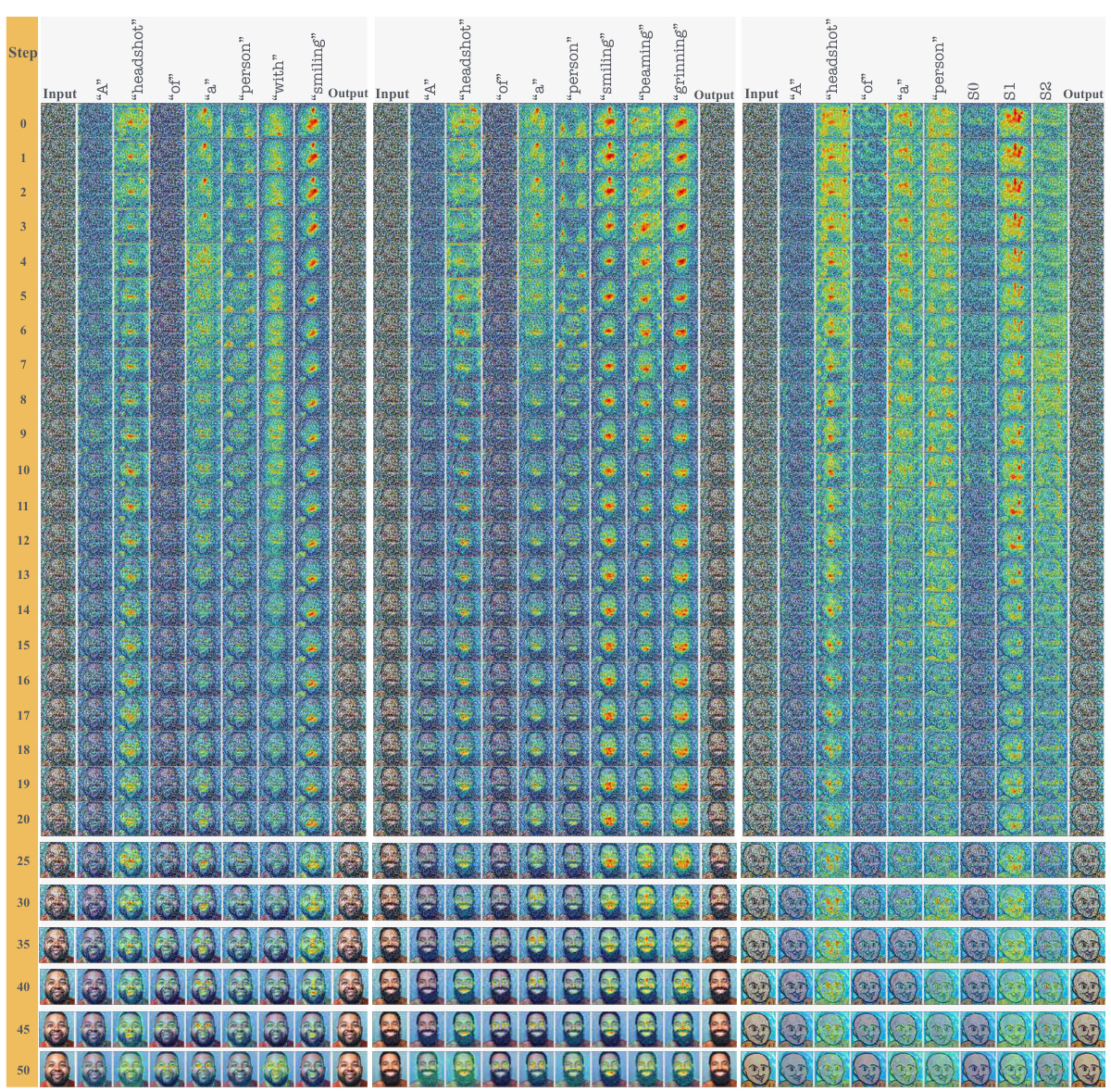
This figure compares the cross-attention maps of the denoising process between hard prompts and ITI-GEN prompts for the tSA=Smiling. It highlights that ITI-GEN tokens show abnormal attention patterns compared to the hard prompts, leading to degraded global structure in the early denoising steps.
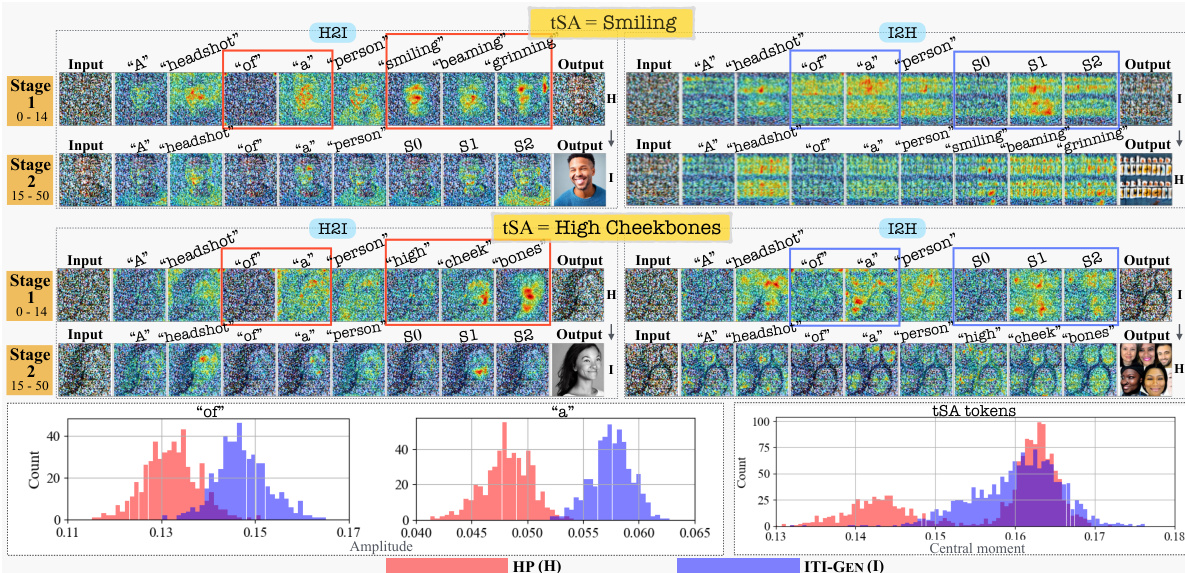
This figure visualizes the accumulated cross-attention maps during the denoising process for two tSAs (Smiling and High Cheekbones) using two proposed prompt switching analysis methods (I2H and H2I). The results show that ITI-GEN’s learned tokens negatively affect the early denoising steps, leading to degraded global structure. However, if the global structure is properly synthesized in the early steps, the ITI-GEN tokens perform adequately in later steps. The bottom part shows histograms of proposed metrics on cross-attention maps, demonstrating abnormalities in many samples.

This ablation study analyzes the effect of varying attention amplification scaling factors (c) and prompt queuing transition points on the performance of the FairQueue model for the tSA (target sensitive attribute) Smiling. The results show that increasing the attention amplification factor generally improves fairness until a saturation point is reached (c=10), beyond which quality and semantic preservation degrade. The optimal prompt queuing transition point is found to be at 0.2l (where l is the total number of denoising steps), balancing quality, fairness, and semantic preservation.

This figure compares image generation results using ITI-GEN and FairQueue when using a new base prompt. The samples show that FairQueue better maintains the semantics of the original prompt while accurately generating the target sensitive attribute. ITI-GEN struggles to maintain the original prompt’s semantics and produces some lower quality results.
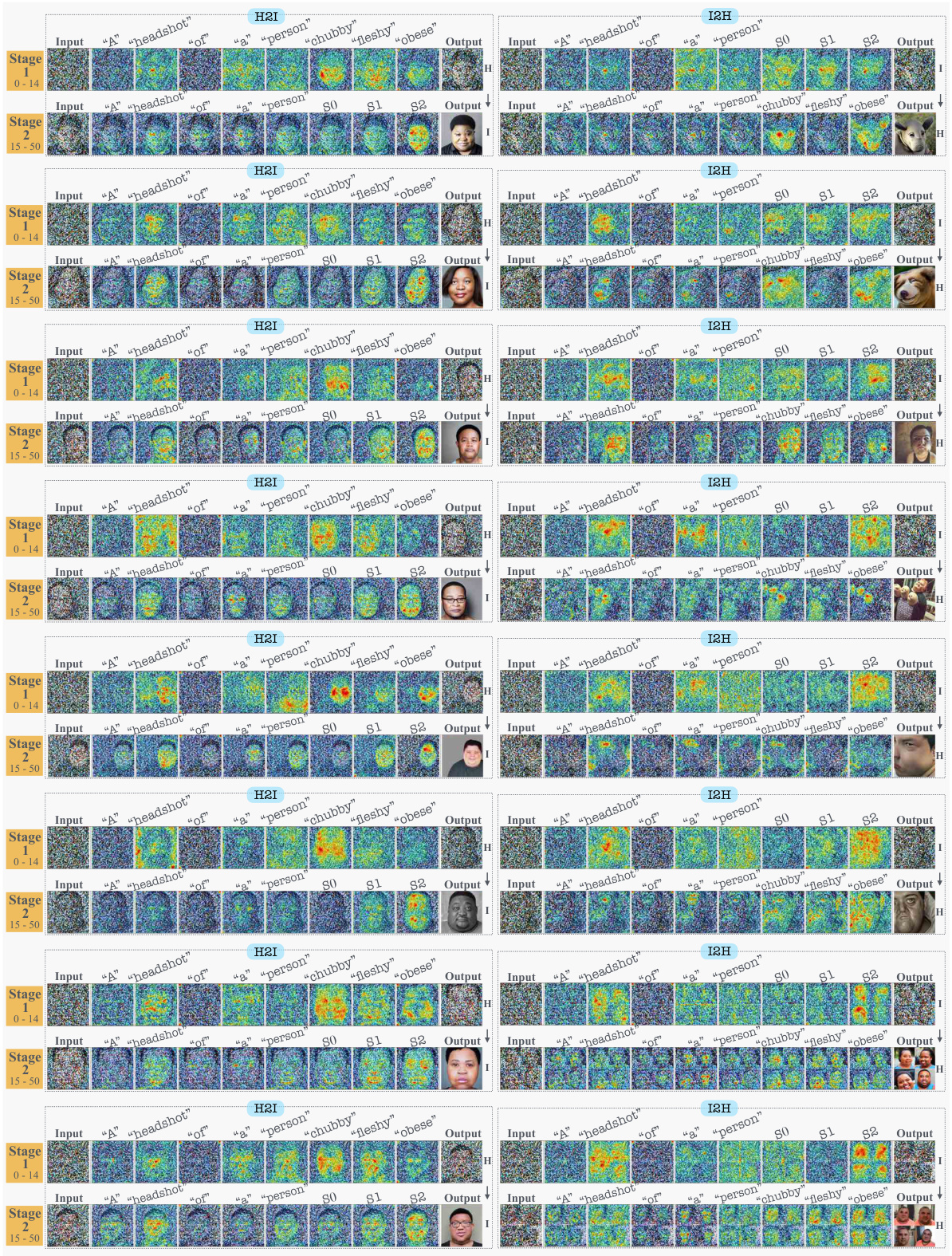
The figure compares the cross-attention maps during the denoising process between hard prompts (HP) and ITI-GEN prompts. It highlights three key observations: ITI-GEN tokens have abnormal activities, non-tSA tokens are abnormally more active, and issues created by ITI-GEN tokens degrade the global structure in the early denoising steps.
This figure compares the cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. The comparison highlights three key observations: ITI-GEN tokens show abnormal activity, non-tSA tokens are abnormally more active in the presence of ITI-GEN tokens, and ITI-GEN tokens degrade the global structure in early denoising steps.

The figure compares cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. It highlights the abnormalities in ITI-GEN prompts, showing how they lead to degraded global structures in the generated images.

This figure compares cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. Three key observations highlight the abnormalities in ITI-GEN’s attention maps: unrelated regions are attended to, non-tSA tokens show abnormally high activity, and global structure degrades in the early stages of denoising.
The figure compares cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. It highlights three key observations showing that ITI-GEN prompts have abnormal activities, non-tSA tokens are abnormally more active, and that ITI-GEN tokens degrade global structure in the early denoising steps, compared to HP.
This figure compares the cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. It highlights abnormalities in ITI-GEN’s cross-attention maps, particularly in the early steps, indicating that ITI-GEN tokens attend to unrelated regions and non-tSA tokens are abnormally active. This leads to degraded global structure in the generated images.

This figure compares cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. Three key observations highlight abnormalities in ITI-GEN’s attention maps compared to HP: abnormal activity of ITI-GEN tokens, higher activity of non-tSA tokens, and degradation of global image structure in early stages.

The figure compares cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. It highlights three key observations: 1) ITI-GEN tokens show abnormal activity; 2) non-tSA tokens are abnormally active with ITI-GEN tokens; 3) ITI-GEN tokens degrade global image structure in early steps.

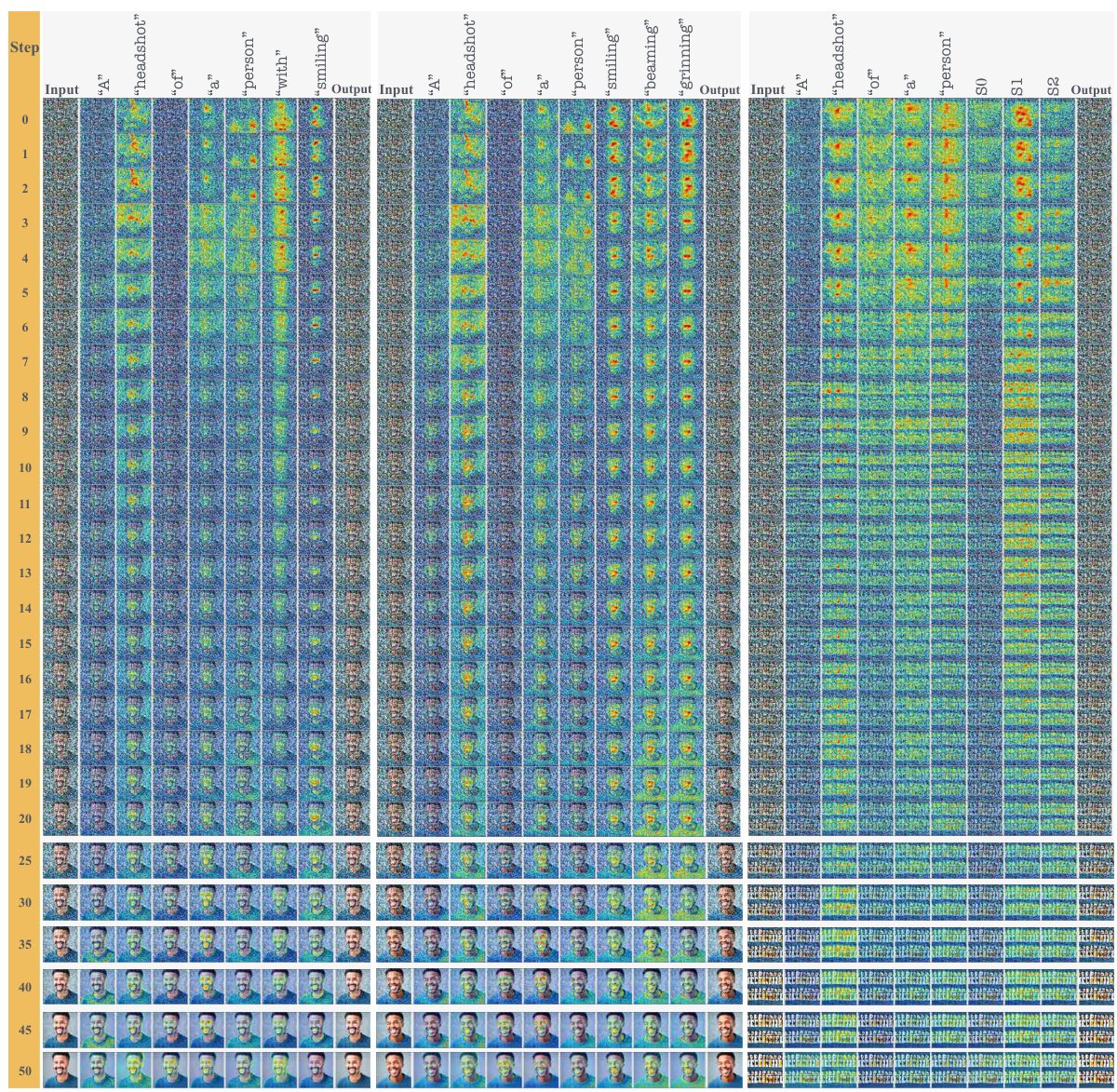
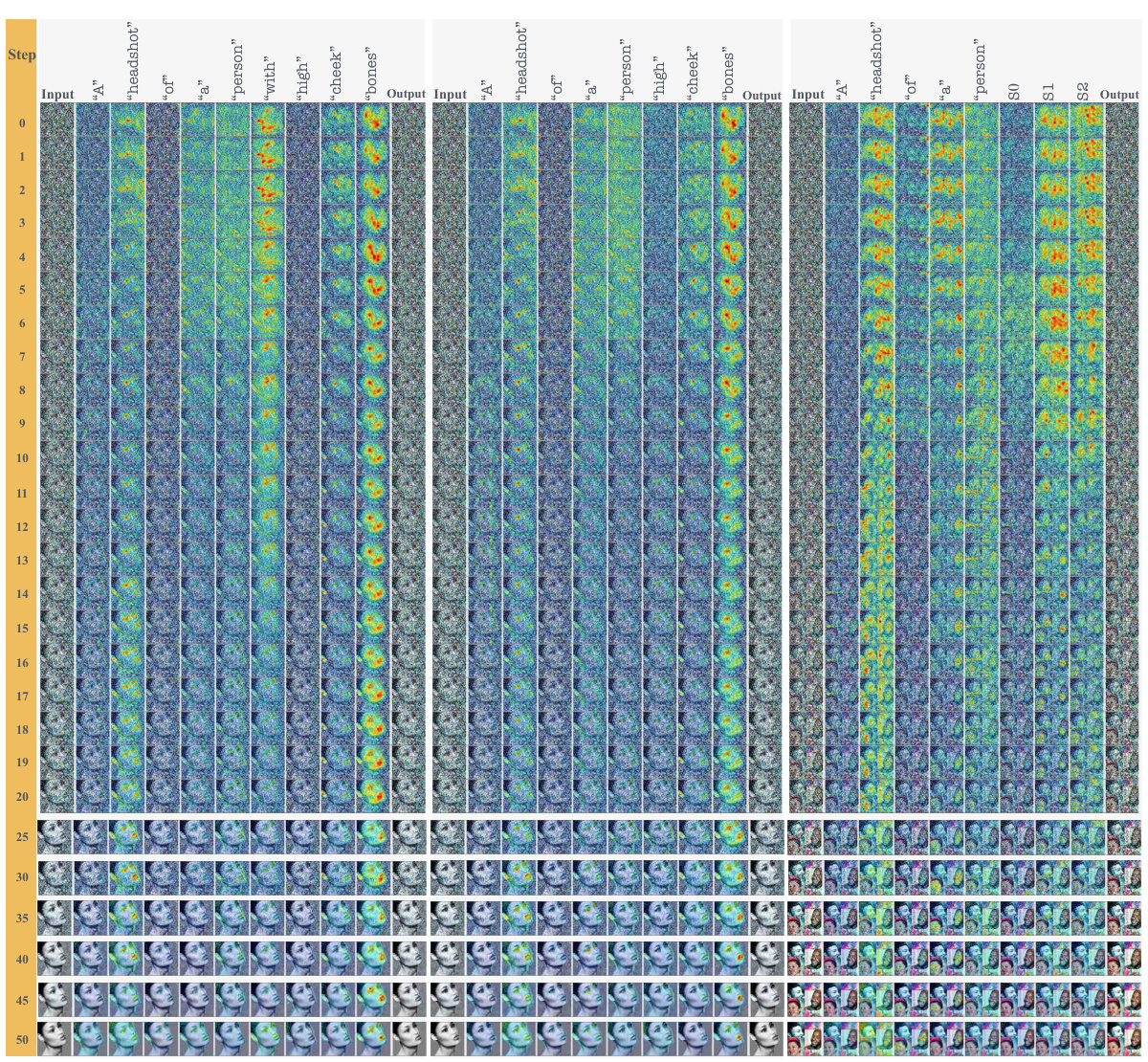
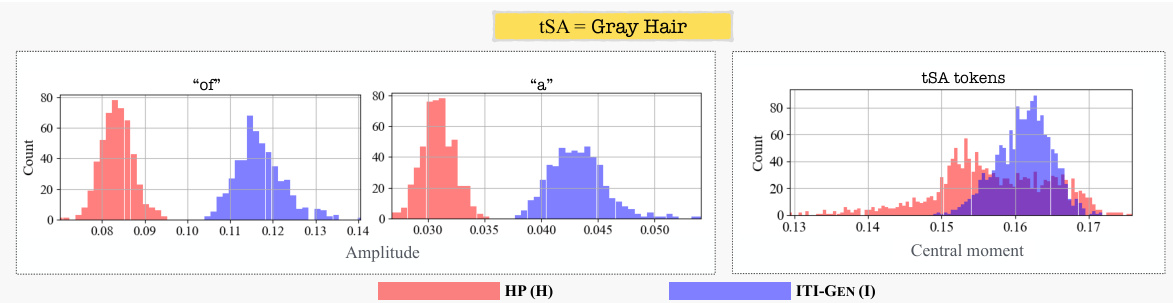
This figure visualizes the cross-attention maps during the denoising process for a single sample generation, comparing the hard prompt (HP) approach with the Inclusive T2I Generation (ITI-GEN) method. The cross-attention maps show how the different tokens in the prompts interact with different parts of the image at each denoising step. The generated images at each step are also shown below the maps. This visualization helps to understand how the ITI-GEN prompts lead to abnormalities in cross-attention, particularly in the early stages of denoising, contributing to the degraded image quality observed in the ITI-GEN approach. The target sensitive attribute (tSA) for this example is ‘Gray Hair’.

This figure compares the cross-attention maps during the denoising process for both hard prompt (HP) and ITI-GEN prompt for the tSA Smiling. It highlights three key observations that demonstrate abnormalities in the ITI-GEN prompt’s cross-attention maps, particularly in the early stages of the denoising process, leading to degraded global structures in the generated image.

This figure visualizes cross-attention maps during the denoising process for a single sample generation, comparing the behavior of Hard Prompts (HP) and ITI-GEN prompts. Each row represents a denoising step, showing the attention maps for each token in the prompt. The images at the bottom show the generated images at each step. The figure aims to illustrate how ITI-GEN prompts differ from HPs in their attention patterns, specifically highlighting potential abnormalities in ITI-GEN’s attention mechanisms, especially in the early stages of the generation process, which could lead to degraded sample quality.

This figure compares the cross-attention maps during the denoising process for both HP and ITI-GEN prompts. Three key observations are highlighted: ITI-GEN tokens show abnormal activities; non-tSA tokens are abnormally active with ITI-GEN tokens; ITI-GEN tokens degrade the global structure in the early denoising steps.

This figure compares cross-attention maps during the denoising process for both hard prompts (HP) and ITI-GEN prompts. The three key observations highlighted are that ITI-GEN tokens show abnormal activities; non-tSA tokens are abnormally more active in the presence of ITI-GEN tokens; and the global image structure is degraded in the early denoising steps due to ITI-GEN tokens. The analysis reveals abnormalities in cross-attention maps of the learned prompts, especially in the early denoising steps, that result in synthesizing improper global structures.
This figure compares cross-attention maps during the denoising process for a sample image generated using Hard Prompts (HP) and Inclusive T2I Generation (ITI-GEN) methods. It highlights abnormalities in ITI-GEN’s cross-attention maps, particularly in the early stages, leading to degraded global image structure and lower quality samples. The observations are supported by highlighting three key issues in ITI-GEN’s attention maps.

This figure compares the cross-attention maps during the denoising process for both HP and ITI-GEN prompts, highlighting the abnormalities in ITI-GEN’s attention patterns. Key observations include abnormal activity in ITI-GEN tokens, higher activity of non-tSA tokens, and degradation of global structure in early steps. The comparison helps to explain how ITI-GEN’s distorted prompts negatively impact the image generation process.

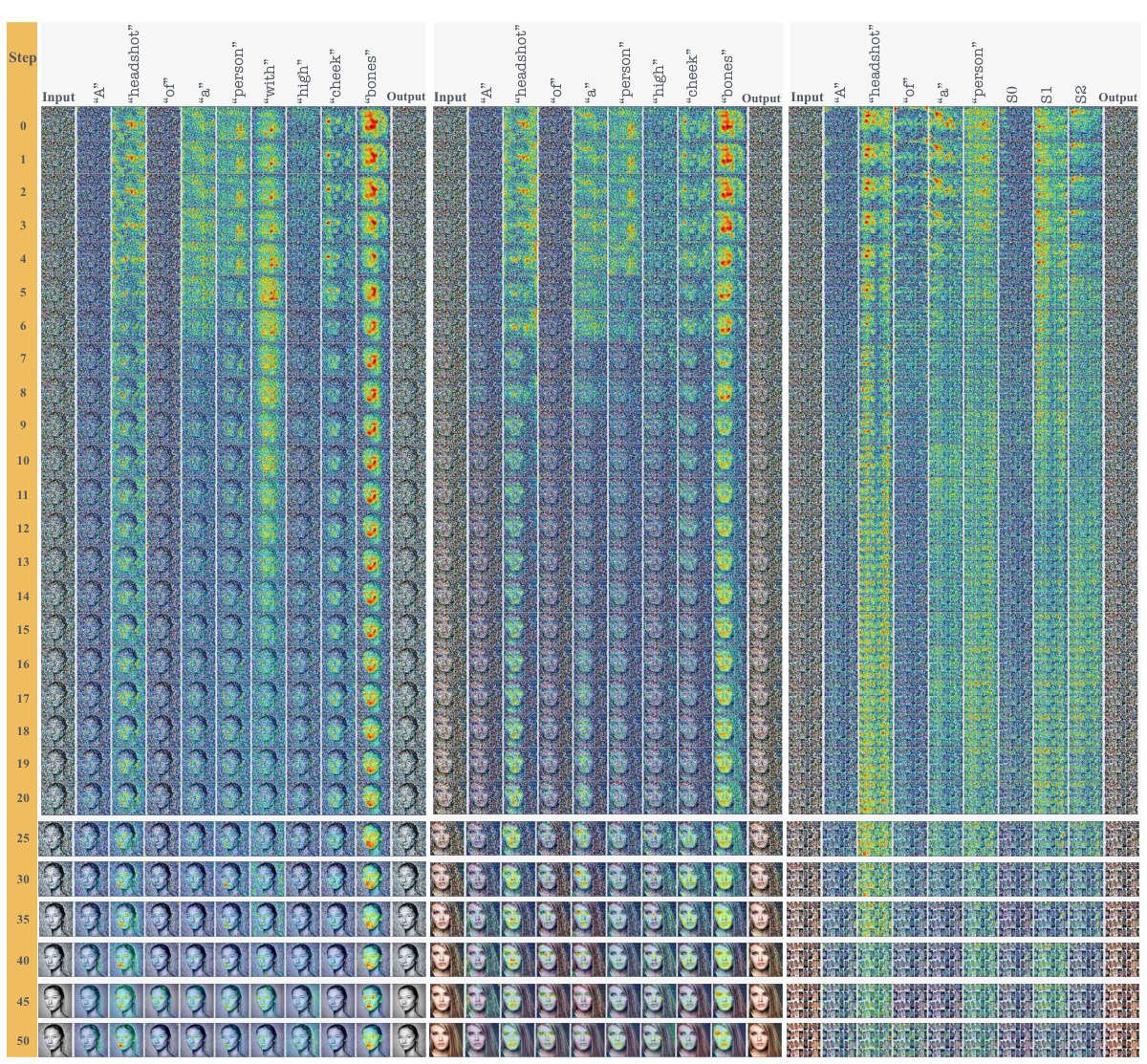
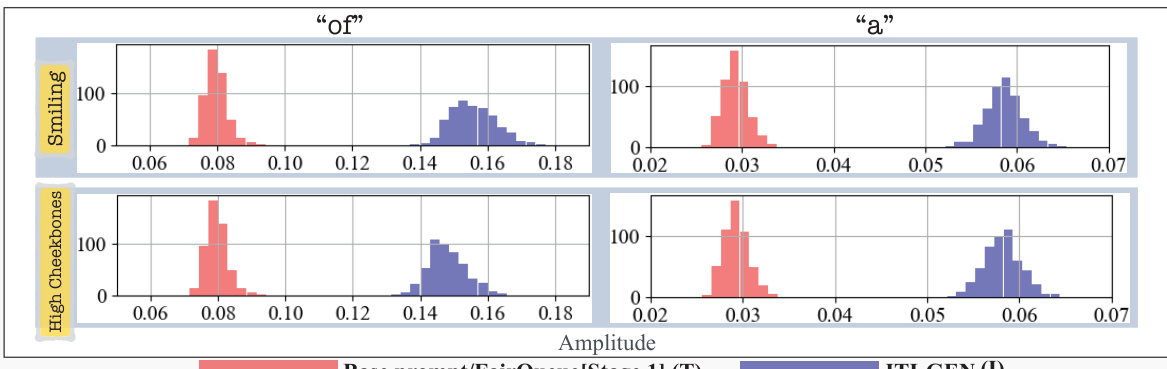
The figure presents histograms visualizing the results of a cross-attention analysis comparing hard prompts (HP) and ITI-GEN prompts for the tSA (Target Sensitive Attribute) ‘Chubby’. The analysis is performed within the framework of prompt switching experiments, specifically I2H and H2I, which involve switching prompts during the denoising process. The histograms illustrate the distribution of the amplitude and central moment of cross-attention maps for non-tSA tokens (‘of’, ‘a’) and tSA tokens. The purpose is to quantitatively demonstrate abnormalities observed in the cross-attention maps, especially in the early steps of the denoising process when using ITI-GEN prompts, which contribute to the degraded quality of generated images. The comparison highlights differences between the HP and ITI-GEN approaches, showcasing the impact of distorted prompts learned by ITI-GEN on the image generation process.
This figure presents histograms that visualize the results of a quantitative analysis performed on cross-attention maps. The analysis is part of a prompt switching experiment (I2H and H2I) designed to investigate the effects of distorted tokens generated by the ITI-GEN method on the image generation process of a text-to-image model. The histograms show the distribution of two metrics: amplitude and central moment. These metrics quantify the abnormality of attention maps, specifically focusing on the activities of non-tSA tokens (like “of” and “a”) and tSA tokens, respectively, during the denoising process. This analysis aims to understand how ITI-GEN’s learning objective may lead to distortion of learned tokens and ultimately impact image generation quality.

This figure compares the performance of three methods for generating text-to-image samples: hard prompts (HP), Inclusive T2I Generation (ITI-GEN), and the proposed FairQueue. It shows that HP performs best for unambiguous attributes, but ITI-GEN suffers from quality degradation, impacting fairness. FairQueue achieves competitive performance to HP in both quality and fairness, especially for those attributes that have less linguistic ambiguity.
This figure compares the cross-attention maps during the denoising process for hard prompts (HP) and ITI-GEN prompts. The comparison highlights abnormalities in ITI-GEN’s attention maps, showing that ITI-GEN tokens have abnormal activities compared to HP tokens and degrade the global structure, especially in the early denoising steps. Non-tSA tokens like ‘of’ and ‘a’ are also abnormally more active with ITI-GEN prompts.

This figure shows the effect of changing the attention amplification scaling factor (c) in the FairQueue model. Multiple rows of images are shown, each row representing a different scaling factor, and each column using a different seed/transition point for the same prompt. The changes to c showcase the impact of this hyperparameter on the degree to which the subject of the prompt is expressed in the resulting image.

This figure compares the performance of three methods for generating images based on text prompts: Hard Prompts (HP), Inclusive T2I Generation (ITI-GEN), and the proposed FairQueue. It shows sample images and quantitative metrics (Fairness Discrepancy (FD), Text-Alignment (TA), Fréchet Inception Distance (FID), and DreamSim (DS)) for two target sensitive attributes (tSAs) with minimal linguistic ambiguity. The results demonstrate that FairQueue achieves competitive fairness and high image quality, outperforming ITI-GEN and matching the performance of HP (for unambiguous tSAs).

This figure compares the performance of three methods for generating images based on text prompts: hard prompts (HP), Inclusive T2I Generation (ITI-GEN), and the proposed FairQueue. The comparison is done using metrics such as fairness discrepancy (FD), text alignment (TA), Fréchet Inception Distance (FID), and DreamSim (DS). The results show that HP achieves the best performance for unambiguous sensitive attributes but is limited in scope. ITI-GEN improves fairness but degrades image quality. The proposed FairQueue provides a good balance between quality and fairness, often outperforming the other methods.

This figure compares the performance of three methods (Hard Prompts, ITI-GEN, and FairQueue) for generating images based on different sensitive attributes (Smiling, High Cheekbones). Hard Prompts achieve high quality and fairness but are limited to unambiguous attributes. ITI-GEN improves fairness but degrades image quality. FairQueue achieves comparable performance to Hard Prompts, enhancing both quality and fairness.

The figure compares the performance of three methods (Hard Prompt, ITI-GEN, and FairQueue) for generating images based on text prompts that include sensitive attributes. It shows that Hard Prompt performs well on unambiguous attributes but poorly on others, ITI-GEN has quality issues, while FairQueue provides both better quality and better fairness.

This figure compares the performance of three methods for generating text-to-image (T2I) samples: Hard Prompts (HP), Inclusive T2I Generation (ITI-GEN), and the proposed FairQueue. The comparison focuses on target sensitive attributes (TSAs) with minimal linguistic ambiguity. The results show that HP produces high-quality, fair images, but only for unambiguous TSAs; ITI-GEN shows moderate sample quality degradation affecting fairness; and FairQueue achieves comparable or even better performance than HP.

This figure compares the image generation results of three methods: HP, ITI-GEN, and FairQueue. It uses two sensitive attributes (smiling and high cheekbones) that have minimal linguistic ambiguity. HP shows high quality and fairness but only works for unambiguous attributes. ITI-GEN shows degraded quality compared to HP, while FairQueue achieves competitive fairness and even surpasses HP’s quality in many cases.

This figure compares the performance of three methods for generating images from text prompts: Hard Prompts (HP), Inclusive T2I Generation (ITI-GEN), and the proposed FairQueue. It shows that HP produces the highest-quality images with good fairness, but only works for unambiguous attributes. ITI-GEN improves fairness but reduces image quality. FairQueue achieves comparable quality to HP while maintaining competitive fairness.

This figure compares the performance of three methods for generating images: HP (Hard Prompts), ITI-GEN (Inclusive T2I Generation), and FairQueue (the proposed method). It shows sample images generated by each method for two different sensitive attributes (Smiling and High Cheekbones) and includes quantitative metrics like Fairness Discrepancy (FD), Text Alignment (TA), Fréchet Inception Distance (FID), and DreamSim (DS) to evaluate fairness, quality, and semantic preservation. The results demonstrate that ITI-GEN degrades image quality, while FairQueue achieves comparable or superior performance to HP, especially for attributes with linguistic ambiguity.

This figure compares the performance of three different methods for generating images from text prompts: Hard Prompts (HP), Inclusive Text-to-Image Generation (ITI-GEN), and the proposed FairQueue method. The comparison is based on fairness, quality (FID and TA), and semantic preservation (DS) metrics for two target sensitive attributes (smiling and high cheekbones). The results show that HP has the best performance, but it is limited to unambiguous attributes; ITI-GEN suffers from reduced quality, which also impacts fairness; and FairQueue achieves a balance between the two, outperforming ITI-GEN in many cases.

The figure compares the performance of three methods (HP, ITI-GEN, and FairQueue) for generating images based on text prompts, focusing on fairness and quality. HP shows the best performance for unambiguous attributes, while ITI-GEN suffers from quality degradation, and FairQueue demonstrates comparable performance to HP while maintaining fairness.

This figure compares the performance of three methods (HP, ITI-GEN, and FairQueue) for generating images of people with different attributes. The results are shown using quantitative metrics such as Fairness Discrepancy (FD), Text-Alignment (TA), Fréchet Inception Distance (FID), and DreamSim (DS). The figure shows that FairQueue achieves the best balance between fairness and image quality. It also demonstrates the limitation of using Hard Prompts (HP) which works only for attributes with minimal linguistic ambiguity.

The figure shows the process of re-visiting SOTA fair text-to-image generation (ITI-GEN). It shows the observation of degraded images generated by ITI-GEN’s learned prompts, analyzes the abnormalities in cross-attention maps and proposes a solution (FairQueue) to address the quality issue.

The figure compares the performance of three different methods (HP, ITI-GEN, and FairQueue) for generating images based on text prompts related to sensitive attributes (SAs). HP performs well in terms of fairness and quality but only for unambiguous SAs. ITI-GEN shows degraded image quality, while FairQueue achieves comparable or even better performance than HP for various SAs, successfully balancing quality and fairness.

This figure compares the performance of three methods (Hard Prompts, ITI-GEN, and FairQueue) for generating images based on different sensitive attributes (tSAs). It shows that Hard Prompts perform best for unambiguous tSAs, while ITI-GEN suffers from degraded quality and FairQueue offers a good compromise between quality and fairness.

This figure compares the image generation quality and fairness of three different methods: Hard Prompts (HP), ITI-GEN, and the proposed FairQueue. The results show that HP performs best overall for unambiguous tSAs but is limited in its applicability; ITI-GEN suffers from decreased quality; and FairQueue achieves comparable or superior performance to HP while maintaining fairness.

This figure compares the performance of three methods (HP, ITI-GEN, and FairQueue) for generating images based on text prompts that include sensitive attributes. It shows that HP generates high-quality images but has limited applicability. ITI-GEN, while improving fairness, sacrifices image quality. FairQueue achieves comparable or better image quality than HP while maintaining high fairness, suggesting it’s the superior approach.
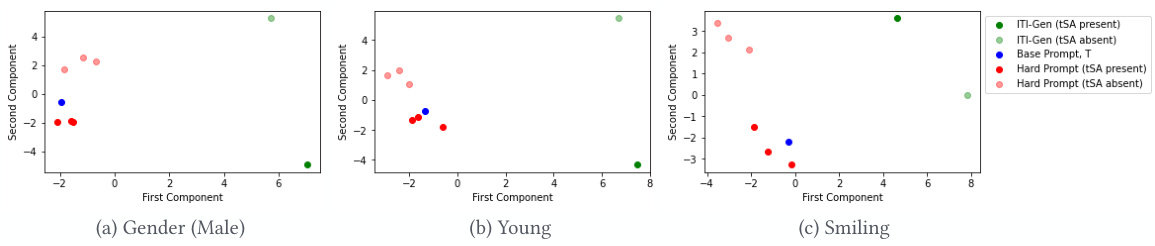
This figure shows the PCA analysis of CLIP text embeddings for ITI-GEN, well-defined hard prompts (HP), and base prompts (T). The analysis visualizes the embeddings in a 2D space, revealing the relationships between different prompt types for the sensitive attributes (SAs) Gender (Male), Young, and Smiling. It highlights how ITI-GEN embeddings differ from the base and HP embeddings, suggesting the inclusion of unrelated concepts and potential causes of quality degradation in ITI-GEN image generation.
More on tables
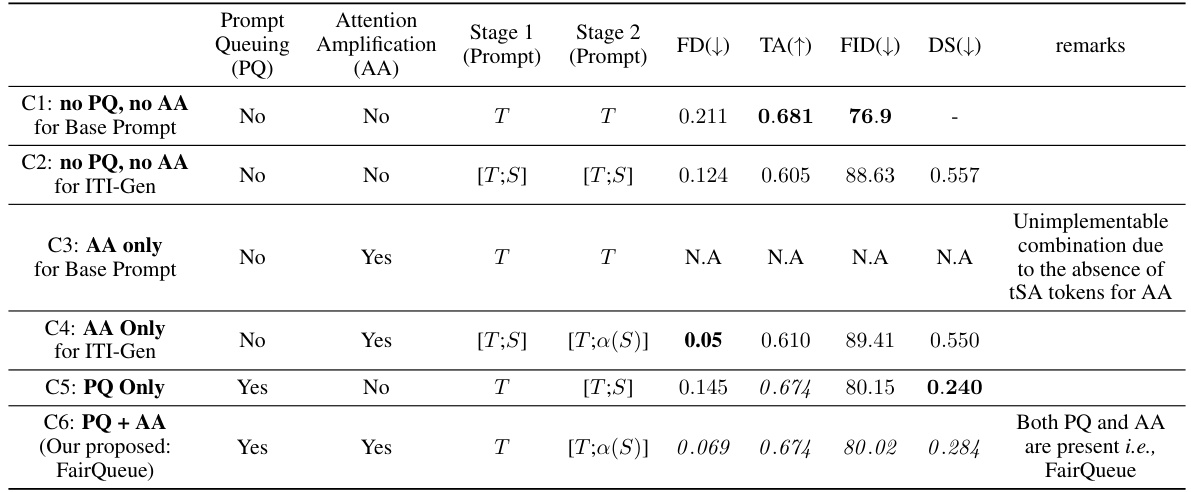
This table presents an ablation study comparing different combinations of prompt queuing (PQ) and attention amplification (AA) for the tSA ‘Smiling’. It shows the fairness (FD), text alignment (TA), Fr chet Inception Distance (FID), and DreamSim (DS) scores for each combination. The results highlight that FairQueue (PQ+AA), which uses both techniques, achieves the best balance between sample quality and fairness.
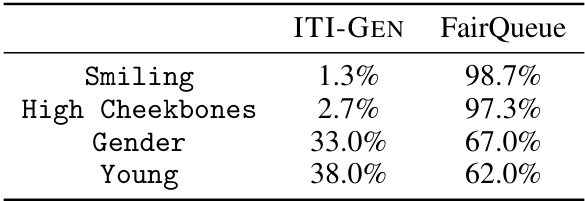
This table presents the results of a human evaluation comparing the image quality of samples generated by ITI-GEN and FairQueue. For each of four sensitive attributes (Smiling, High Cheekbones, Gender, and Young), 200 image pairs (one from each method) were evaluated by human labelers using A/B testing to determine which sample was of higher quality. The percentages in the table show the proportion of labelers who preferred each method for each attribute. Higher percentages indicate better perceived quality.

This table presents the Fairness Discrepancy (FD) values, a measure of fairness in image generation, for both the ITI-GEN and FairQueue methods. The results are shown for four different sensitive attributes: Smiling, High Cheekbones, Gender, and Young. Lower FD values indicate better fairness. The table summarizes the human evaluation results from the user study comparing the fairness of images generated using both methods for each tSA.

This table presents a comparison of the proposed FairQueue method against the state-of-the-art ITI-GEN method for fair text-to-image generation. It evaluates performance across multiple sensitive attributes (tSAs) using four metrics: Fairness Discrepancy (FD) to measure fairness, Text-Alignment (TA) and Fréchet Inception Distance (FID) to assess quality, and DreamSim (DS) to evaluate semantic preservation. The results show that FairQueue achieves a better balance between quality and fairness compared to ITI-GEN, while maintaining the semantic content of the base prompt.

This table presents a comparison of the proposed FairQueue method against the state-of-the-art ITI-GEN method for fair text-to-image generation. Multiple metrics are used to evaluate both the fairness and quality of the generated images, considering various sensitive attributes (tSAs). The metrics include Fairness Discrepancy (FD), measuring equal representation across tSA categories; Text-Alignment (TA), assessing semantic preservation; Fréchet Inception Distance (FID), evaluating image quality; and DreamSim (DS), measuring semantic preservation. The results show that FairQueue achieves a better balance between fairness and image quality compared to ITI-GEN.

This table presents a comparison of the proposed FairQueue method against the state-of-the-art ITI-GEN method for fair text-to-image generation. It evaluates performance across multiple metrics: Fairness Discrepancy (FD), which measures fairness; Text-Alignment (TA) and Fréchet Inception Distance (FID), which measure image quality; and DreamSim (DS), which measures semantic preservation. The results show that FairQueue achieves a better balance between sample quality and fairness compared to ITI-GEN.

This table presents a comparison of the proposed FairQueue method against the state-of-the-art ITI-GEN method for fair text-to-image generation across various sensitive attributes (tSAs). It uses four metrics to evaluate performance: Fairness Discrepancy (FD), Text Alignment (TA), Fréchet Inception Distance (FID), and DreamSim (DS). Lower FD indicates better fairness, higher TA and lower FID indicate better quality, and lower DS indicates better semantic preservation. The results show that FairQueue achieves a better balance of fairness and quality than ITI-GEN, while maintaining good semantic preservation.
Full paper#