↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current 3D scene understanding methods based on 3D Gaussian Splatting primarily focus on 2D pixel-level parsing, struggling with 3D point-level tasks due to weak feature expressiveness and inaccurate 2D-3D associations. This limitation hinders applications requiring precise 3D point-level interaction and understanding.
To address this, OpenGaussian introduces a novel method employing SAM masks for training 3D instance features with high intra-object consistency and inter-object distinction. It uses a two-stage codebook to efficiently discretize features, and links 3D points to 2D masks which are associated with CLIP features. Through extensive experiments, OpenGaussian demonstrates its effectiveness in open-vocabulary-based 3D object selection, 3D point cloud understanding, and click-based 3D object selection, outperforming existing methods.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents OpenGaussian, a novel approach to 3D scene understanding that significantly improves upon existing methods. Its focus on point-level open vocabulary understanding addresses a critical limitation in current 3DGS-based techniques. The use of lossless CLIP features and a two-level codebook for efficient feature discretization contributes valuable advancements in 3D vision. The proposed approach shows superior performance in multiple tasks and opens new avenues for research in interactive 3D scene manipulation and embodied AI applications. The work also tackles the challenges of weak feature expressiveness and inaccurate 2D-3D feature associations prevalent in existing methods.
Visual Insights#
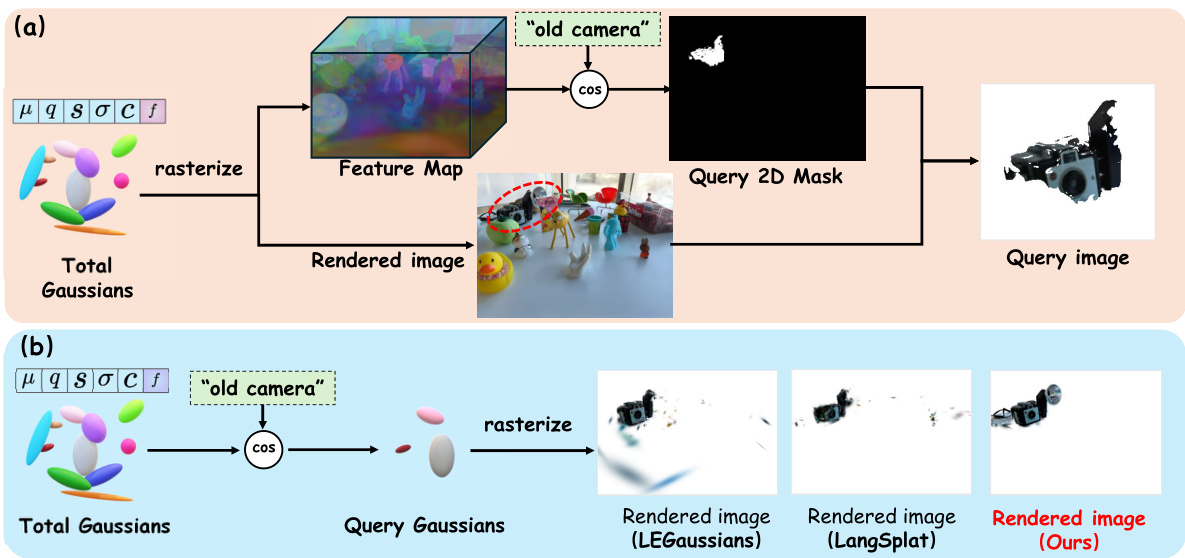
This figure compares two different methods for querying 3D scenes using text. Method (a) renders a feature map from the 3D scene and compares this map to text features to obtain a 2D mask. This mask is then used to select the relevant parts of the 3D scene to render. Method (b), the proposed method, directly compares text features to the language features of the 3D Gaussian points to select the relevant points before rendering, leading to a more efficient process.

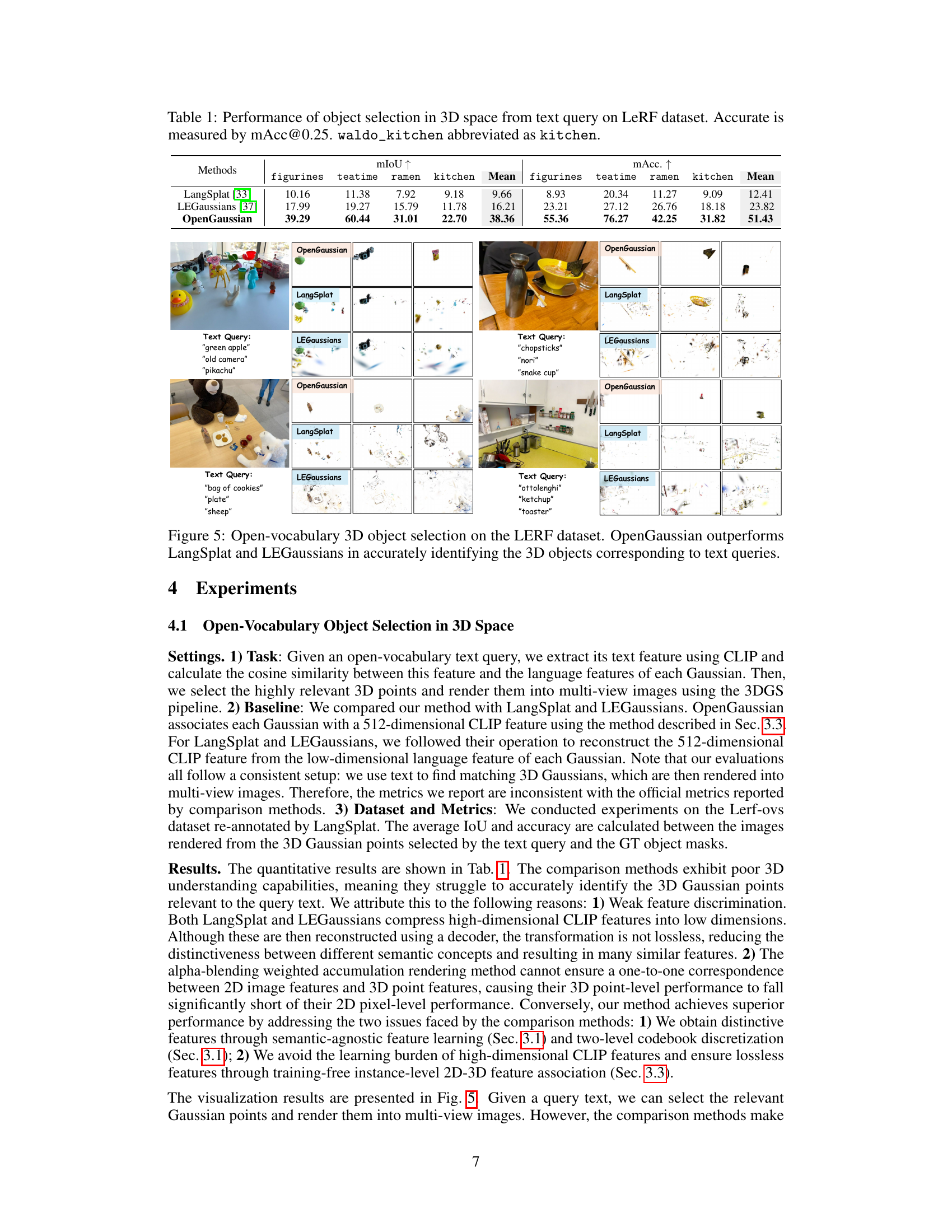
This table presents a quantitative comparison of semantic segmentation performance on the ScanNet dataset. Three methods are compared: LangSplat, LEGaussians, and the proposed OpenGaussian. The results are broken down by the number of classes (19, 15, and 10) used for the semantic segmentation task, and both mIoU (mean Intersection over Union) and mAcc (mean Accuracy) are reported. OpenGaussian shows significantly improved performance compared to the other two methods, highlighting the effectiveness of its proposed approach.
In-depth insights#
3DGS Enhancements#
3D Gaussian Splatting (3DGS) enhancements are crucial for advancing 3D scene understanding. Improving feature representation is key, moving beyond 2D-centric approaches to leverage the inherent 3D nature of 3DGS. This involves developing methods for learning distinctive and consistent 3D point-level features, potentially using techniques like contrastive learning or self-supervised learning. Addressing inaccurate 2D-3D correspondence is also vital, as current alpha-blending approaches hinder precise point-level understanding. Solutions might include refining rendering techniques to establish a more direct mapping between 3D points and 2D pixels, perhaps through novel rasterization methods. Efficient feature discretization is another important area, enabling interactive 3D object segmentation and improving memory efficiency. This can be done via codebooks, possibly hierarchical ones, for efficient clustering and representation of 3D features. Incorporating open vocabulary capabilities is critical to build intelligent agents, requiring methods to seamlessly integrate 3D point-level features with language-based scene understanding. Solutions may utilize models like CLIP to effectively connect language features with 3D features. Finally, handling limitations like occlusion and sparsity in 3D point clouds are vital for real-world applications and future improvements.
Feature Discretization#
Feature discretization in the context of 3D scene understanding using Gaussian splatting is crucial for efficient and effective processing. The core idea is to transform high-dimensional, continuous features into a lower-dimensional discrete representation. This is often achieved using codebooks, which map continuous features to discrete indices. A two-level codebook approach, employing coarse and fine-level discretization, can significantly enhance performance. The coarse level utilizes both spatial (3D coordinates) and feature information for initial clustering, mitigating issues caused by occlusions or distance. The subsequent fine-level discretization refines the clusters based solely on features, leading to more distinct and consistent representations. This strategy effectively addresses challenges like ambiguous feature representations and inaccurate 2D-3D correspondences. By leveraging codebooks, we can enable efficient similarity calculations and interactions for downstream tasks such as 3D object selection and point cloud understanding, paving the way for more intuitive and robust open vocabulary understanding in 3D scenes.
Open Vocab 3D#
The concept of “Open Vocab 3D” signifies a significant advancement in 3D scene understanding. It suggests systems capable of interpreting and interacting with 3D environments using natural language, without needing pre-defined object categories. This open-vocabulary approach addresses limitations of traditional methods that rely on fixed vocabularies, making them inflexible and unable to handle unseen objects. A successful “Open Vocab 3D” system would integrate language models with 3D representations, likely leveraging neural rendering techniques to bridge the gap between textual descriptions and point clouds or voxel grids. Robust feature extraction and matching are crucial to ensure accurate associations between language and 3D spatial data. This involves handling ambiguities and variations in language, as well as efficiently managing the high dimensionality of 3D data. Furthermore, the ability to handle occlusion and partial views is essential. The ultimate goal is a flexible, adaptable, and human-like understanding of 3D environments, enabling applications in robotics, augmented reality, and virtual world interaction.
Ablation Study#
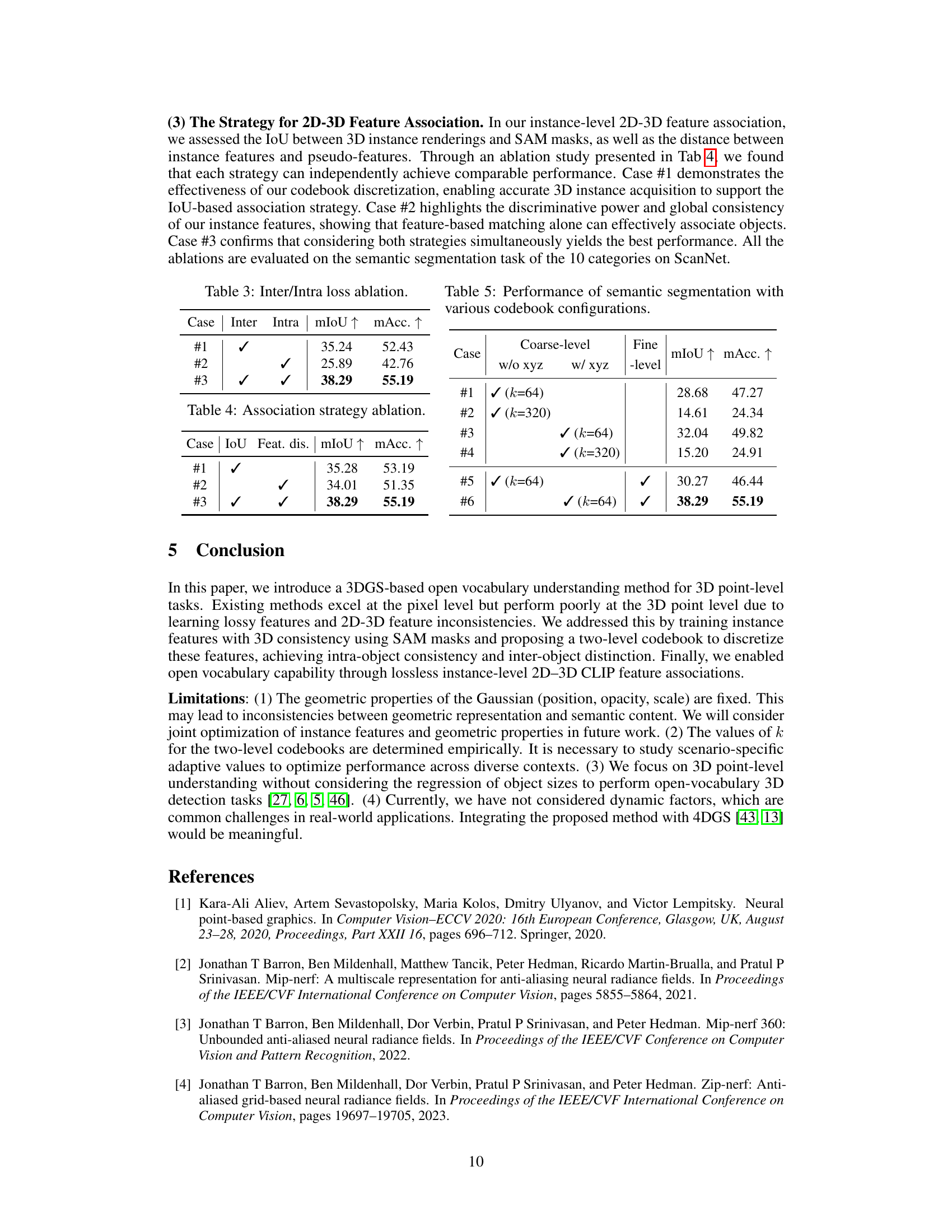
An ablation study systematically removes components of a model to assess their individual contributions. In this context, the ablation study likely investigated the impact of different loss functions (intra-mask smoothing and inter-mask contrastive loss) and the two-level codebook architecture on the model’s performance. The results likely showed that both losses significantly improved performance, with the inter-mask contrastive loss being more crucial than the intra-mask smoothing loss. This is probably because the model naturally produces some degree of smoothing during rendering. The two-level codebook is also crucial; a single-level codebook may not be sufficient to capture the complexity of features in larger datasets; while increasing the capacity of a single-level codebook did not yield better results. The study likely also analyzed the importance of feature associations (IoU and feature distance) in achieving optimal performance, demonstrating how different aspects of the model contribute to the overall effectiveness of the 3D point-level open-vocabulary understanding. The ablation study provides valuable insights into the design choices of the model and helps understand how the different components interact.
Future of 3DGS#
The future of 3D Gaussian Splatting (3DGS) appears bright, driven by its speed and efficiency in real-time rendering. Further advancements in feature representation are crucial, moving beyond the current limitations of weak feature expressiveness and inaccurate 2D-3D correspondence. This could involve exploring higher-dimensional features or developing more robust methods for associating 3D points with 2D information. Integration with larger language models (LLMs) will enhance open-vocabulary capabilities, enabling more natural and intuitive interactions with 3D scenes. Addressing occlusion and improving object discrimination within the 3D point cloud are important areas of focus. The potential for 3DGS in diverse applications including robotics, augmented reality, and interactive 3D modeling necessitates robust, efficient methods that can handle complex real-world scenarios. Research into more efficient training procedures and novel loss functions will improve both accuracy and speed. Ultimately, the future of 3DGS hinges on its ability to seamlessly blend with emerging technologies to create truly interactive and realistic 3D experiences.
More visual insights#
More on figures

This figure illustrates the OpenGaussian method’s three main stages. (a) shows how instance features are learned from SAM masks with a focus on maintaining 3D consistency across different views. (b) details the two-level codebook used for discretizing instance features, enhancing both efficiency and the distinctiveness of features for each instance. (c) describes the instance-level 3D-2D feature association method which links 3D points to 2D CLIP features without additional training.
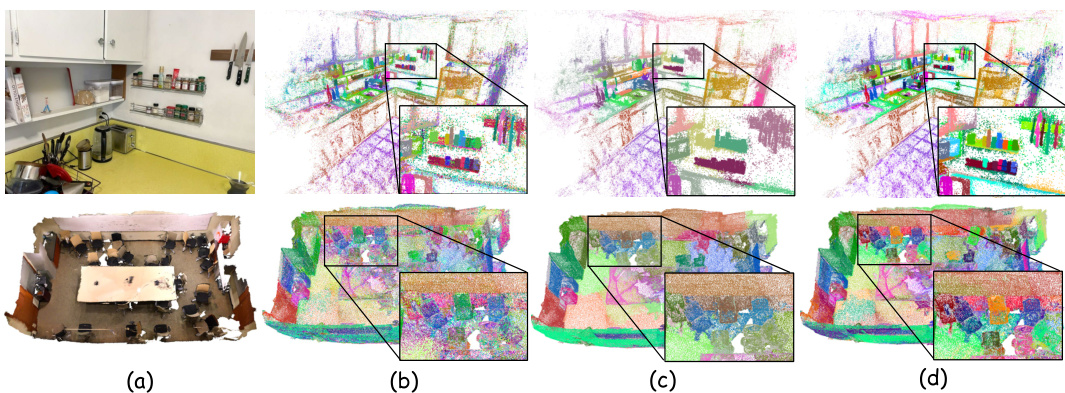
This figure shows a comparison of 3D Gaussian feature visualizations on the LERF and ScanNet datasets. It compares the results of the proposed OpenGaussian method with those of LangSplat and LEGaussians. The visualizations likely aim to demonstrate the differences in feature distinctiveness and spatial consistency between the methods, highlighting the improved performance of OpenGaussian in accurately identifying and representing 3D objects. Each row represents a different scene, showing multi-view renderings of the 3D features.

This figure illustrates the method used for instance-level 2D-3D association. It shows how 3D instance points are rendered to a 2D view. The process uses both the Intersection over Union (IoU) between the rendered features and a SAM mask and the feature similarity between the rendered features and the mask’s CLIP features to link 3D points to 2D information. This indirect association helps connect the 3D points to CLIP features without the need for depth information or occlusion testing. This approach makes the model robust and efficient.
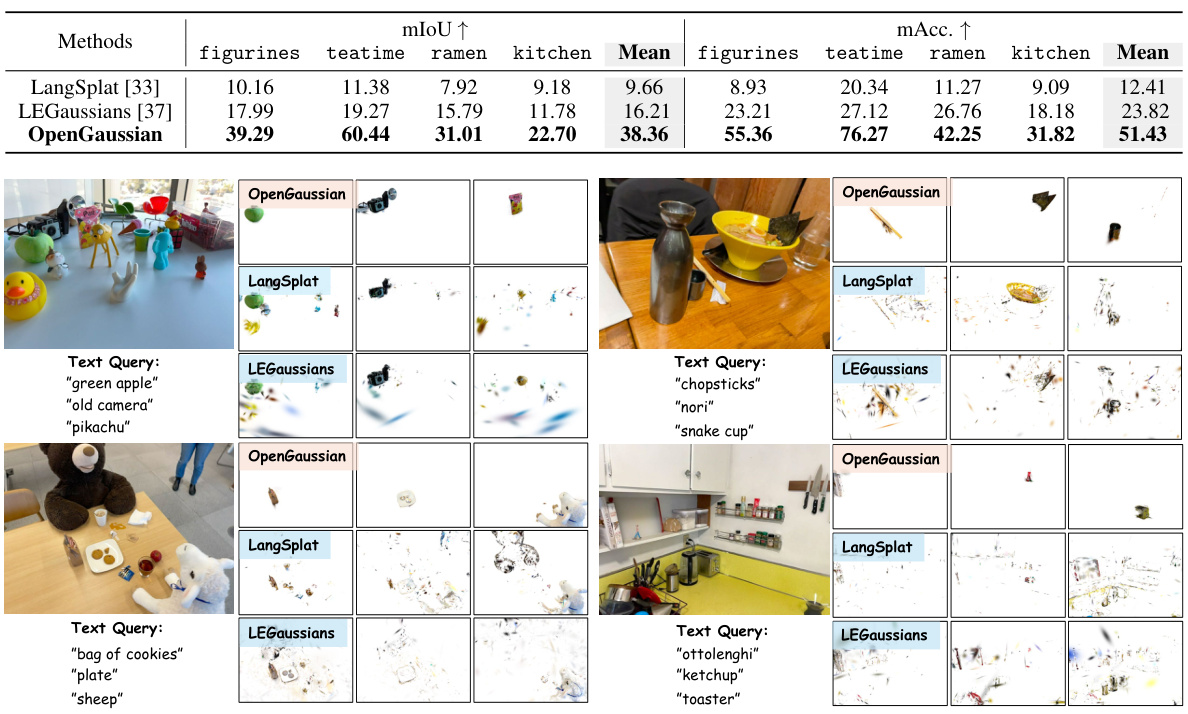
This figure shows a qualitative comparison of open-vocabulary 3D object selection performance between OpenGaussian and two baseline methods (LangSplat and LEGaussians) on the LERF dataset. For several text queries (e.g., ‘green apple’, ‘old camera’, ‘pikachu’), the figure displays the rendered results from each method. The results demonstrate that OpenGaussian significantly outperforms the baselines in accurately identifying and rendering the 3D objects corresponding to the given text queries, highlighting its superior capabilities in open-vocabulary 3D scene understanding.
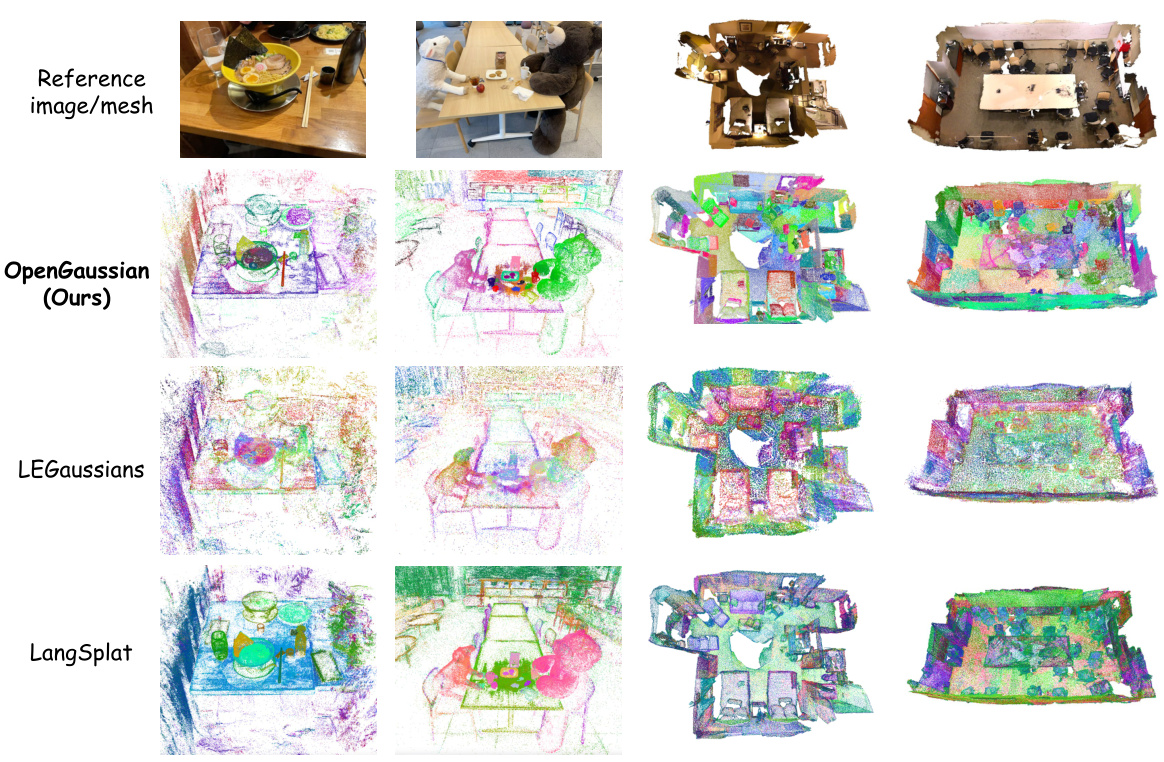
This figure shows a comparison of 3D Gaussian feature visualizations across three different methods: OpenGaussian (the proposed method), LEGaussians, and LangSplat. The visualizations are presented for both the LERF and ScanNet datasets. Each row represents a different method, and each column shows a different viewpoint (or scene) in the dataset. The color of the points represent the different features extracted. The visualization helps to understand the differences in the quality and granularity of the features extracted by each method.

This figure shows a comparison of click-based 3D object selection results between OpenGaussian and SegAnyGaussian. OpenGaussian, the proposed method, demonstrates more complete and accurate selection of 3D objects based on a 2D click, avoiding incompleteness or selecting redundant parts. SegAnyGaussian, in contrast, shows less accurate results with either missing parts or excessive selections.

This figure demonstrates the scene editing capabilities of OpenGaussian. It shows four variations of a 3D scene, all rendered using the model: (a) the original reconstructed scene; (b) the scene with one object removed; (c) the scene with a new object added; and (d) the scene with the color of a selected object changed. Importantly, the figure highlights that these edits are made directly in the 3D model representation, not as post-processing effects on a rendered image.
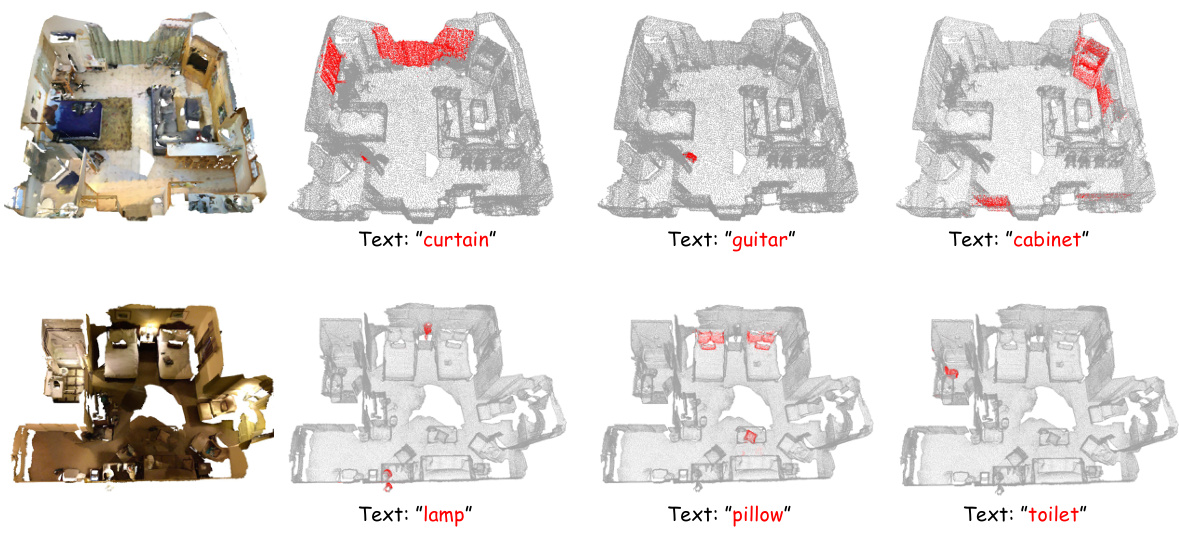
This figure demonstrates the capability of the OpenGaussian model to retrieve relevant 3D Gaussian points based on text queries. The top row shows results for the scene ‘scene0000_00’, while the bottom row displays results for ‘scene0645_00’. For each scene, multiple views are presented alongside the rendered image, illustrating how the model identifies and highlights the 3D Gaussians that most closely correspond to the input text query. This showcases the models ability for open-vocabulary 3D point-level understanding, selecting only the relevant points from the 3D scene.

This figure shows the results of rendering 3D point instance features into multiple views. The results demonstrate the cross-view consistency of the learned instance features. This is important because it shows that the features are not only consistent across different views but also provide a stable representation of the objects in the scene.

This figure shows the visualization of 3D point features obtained from a real-world scene captured using a mobile phone. It includes three RGB images of the scene showing different viewpoints and a point cloud visualization, highlighting the effectiveness of the proposed method in capturing real-world scenes and extracting meaningful instance-level features.

This figure compares the 3D feature visualizations of OpenGaussian with two other methods, LangSplat and LEGaussians, across four different scenes. The visualization highlights the superior granularity and accuracy of OpenGaussian’s features in representing objects within the 3D scenes.

This figure showcases the visualization of 3D point features extracted from six different scenes within the large-scale Waymo outdoor dataset. Each row presents a pair of images: on the left, an RGB image from the scene, and on the right, the corresponding 3D point features are visualized. The visualization highlights the distribution and characteristics of these 3D features within various outdoor environments, demonstrating the model’s ability to learn features from diverse and complex scenes. The figure provides a visual confirmation of the model’s performance in handling large-scale, outdoor datasets.

This figure visualizes the 3D point features learned by the model on six different scenes from the large-scale outdoor Waymo dataset. Each row represents a different scene. The left column shows the original RGB image of the scene, while the right column visualizes the learned 3D point features. The visualization helps to understand how well the model is able to distinguish different objects and their spatial relationships within each scene.
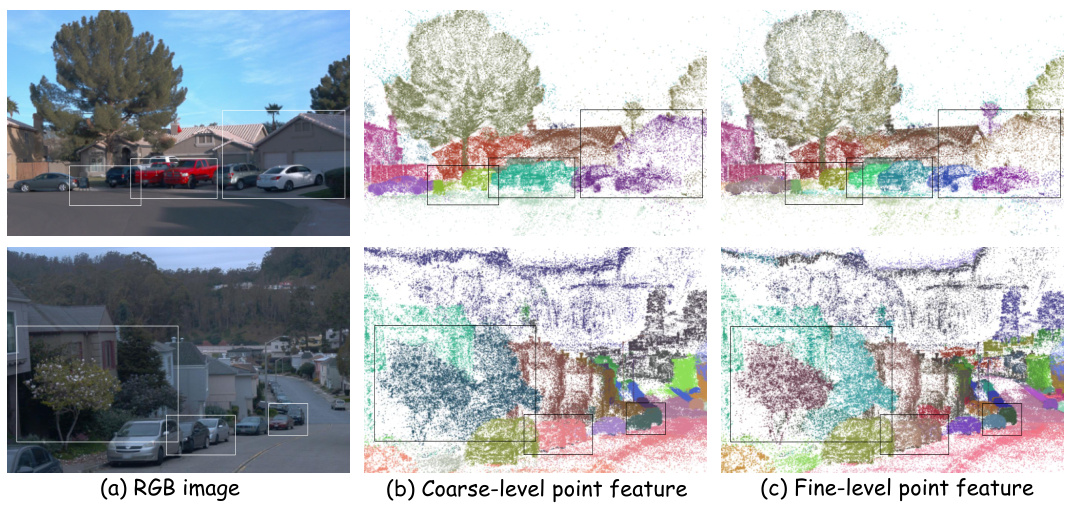
This figure demonstrates the effectiveness of the proposed two-level codebook for discretizing instance features. The top row shows an RGB image of a residential area, followed by the results of applying the coarse-level and fine-level codebooks respectively. Similarly, the bottom row shows another scene with the same processing. Comparing the results shows that the fine-level codebook leads to significantly better discretization of the features, resulting in improved instance-level discrimination and object segmentation.
More on tables
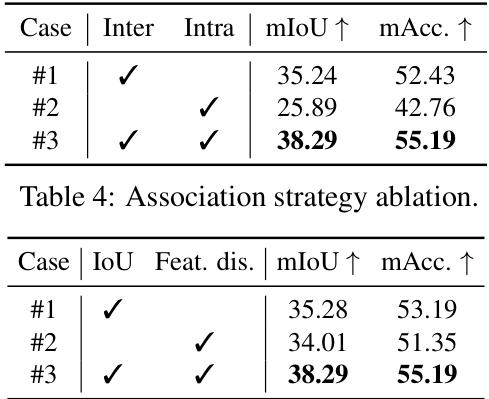
This table presents the ablation study of the association strategies used in the paper. It compares the performance (mIoU and mAcc) of three different approaches: 1. Using only IoU (Intersection over Union) between 3D instance renderings and SAM masks for association. 2. Using only feature distance between instance features and pseudo-features for association. 3. Using both IoU and feature distance for association. The results show that combining both IoU and feature distance leads to the best performance, indicating the importance of considering both geometric and semantic information for accurate object association.
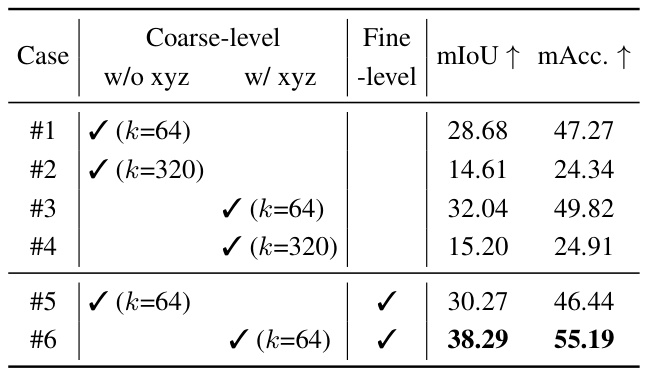
This table presents the results of ablation studies on different codebook configurations for semantic segmentation. It compares the performance (mIoU and mAcc) of using a single-level codebook with different numbers of clusters (k), a two-level codebook where the coarse level uses only instance features or both instance and spatial features (xyz), and a two-level codebook with different numbers of clusters at both levels. The results demonstrate the benefits of using a two-level codebook incorporating spatial information for better performance.
Full paper#