↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-task reinforcement learning (MTRL) aims to train agents to perform multiple tasks simultaneously, ideally leveraging shared knowledge between them. However, current MTRL methods often struggle with efficiently transferring knowledge between tasks, leading to slow learning and suboptimal performance. Many approaches focus solely on parameter sharing, neglecting the potential of using successful policies from one task to directly improve the learning of another.
The paper introduces Cross-Task Policy Guidance (CTPG), a novel framework that directly addresses this limitation. CTPG trains a separate ‘guide policy’ for each task, which selects the most beneficial policy from a pool of all learned task policies to generate training data for the target task. This approach, combined with gating mechanisms that filter out unhelpful policies and prioritize those for which guidance is needed, leads to substantial performance improvements compared to existing methods in multiple robotics benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel framework, Cross-Task Policy Guidance (CTPG), that significantly improves the efficiency of multi-task reinforcement learning (MTRL). CTPG leverages cross-task similarities by guiding the learning of unmastered tasks using the policies of already proficient tasks. This addresses a key challenge in MTRL, leading to enhanced performance in both manipulation and locomotion benchmarks and opening new avenues for research in efficient MTRL.
Visual Insights#

This figure shows examples of full or partial policy sharing in robotic arm manipulation tasks. In (a), the tasks ‘Button-Press’ and ‘Drawer-Close’ share a similar policy where the robot arm must reach a target location and then push it. In (b), ‘Door-Open’ and ‘Drawer-Open’ tasks share an initial policy of grasping a handle but differ in how they subsequently open the object (rotation vs. translation). These examples illustrate the potential for sharing policies between tasks with similar sub-tasks.
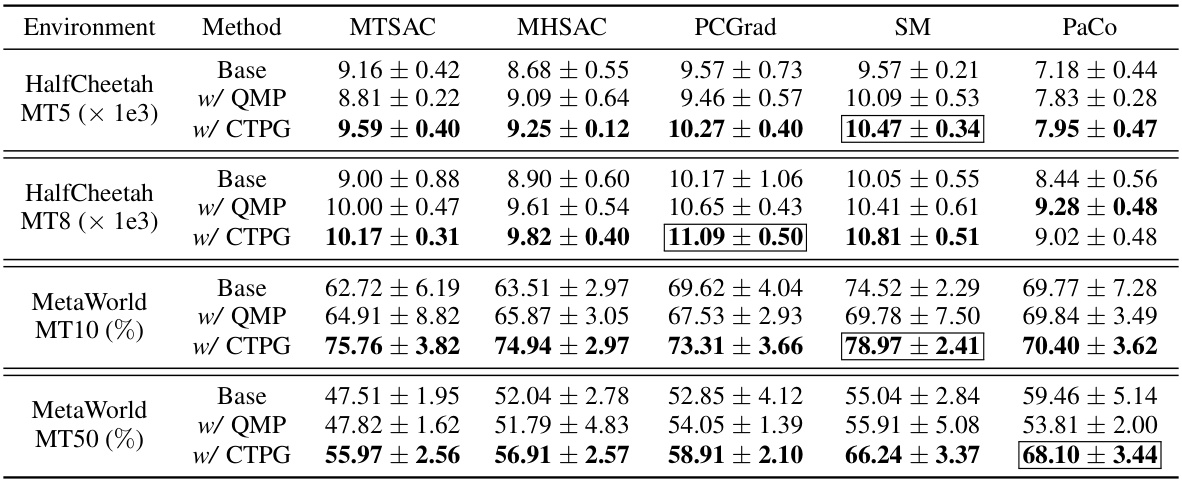
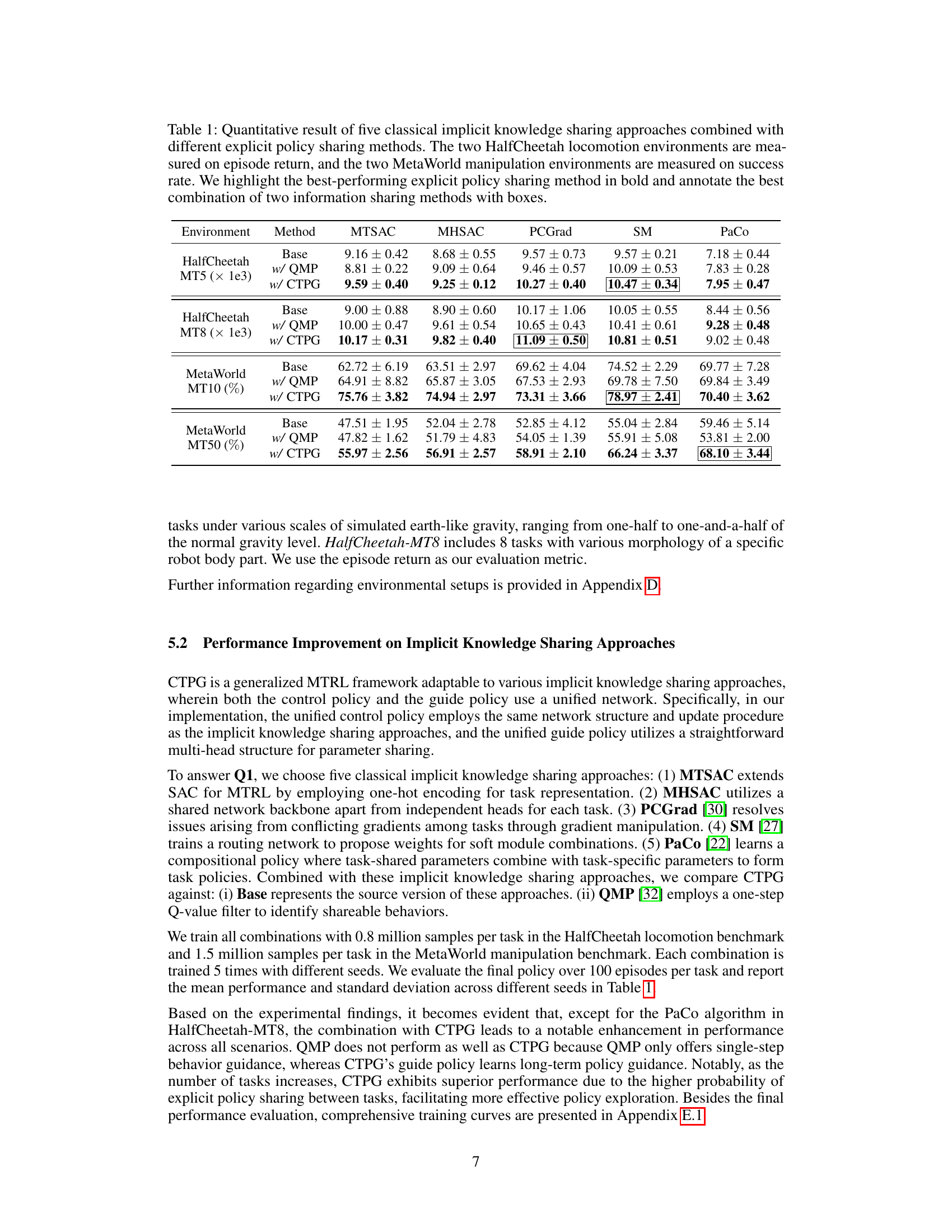
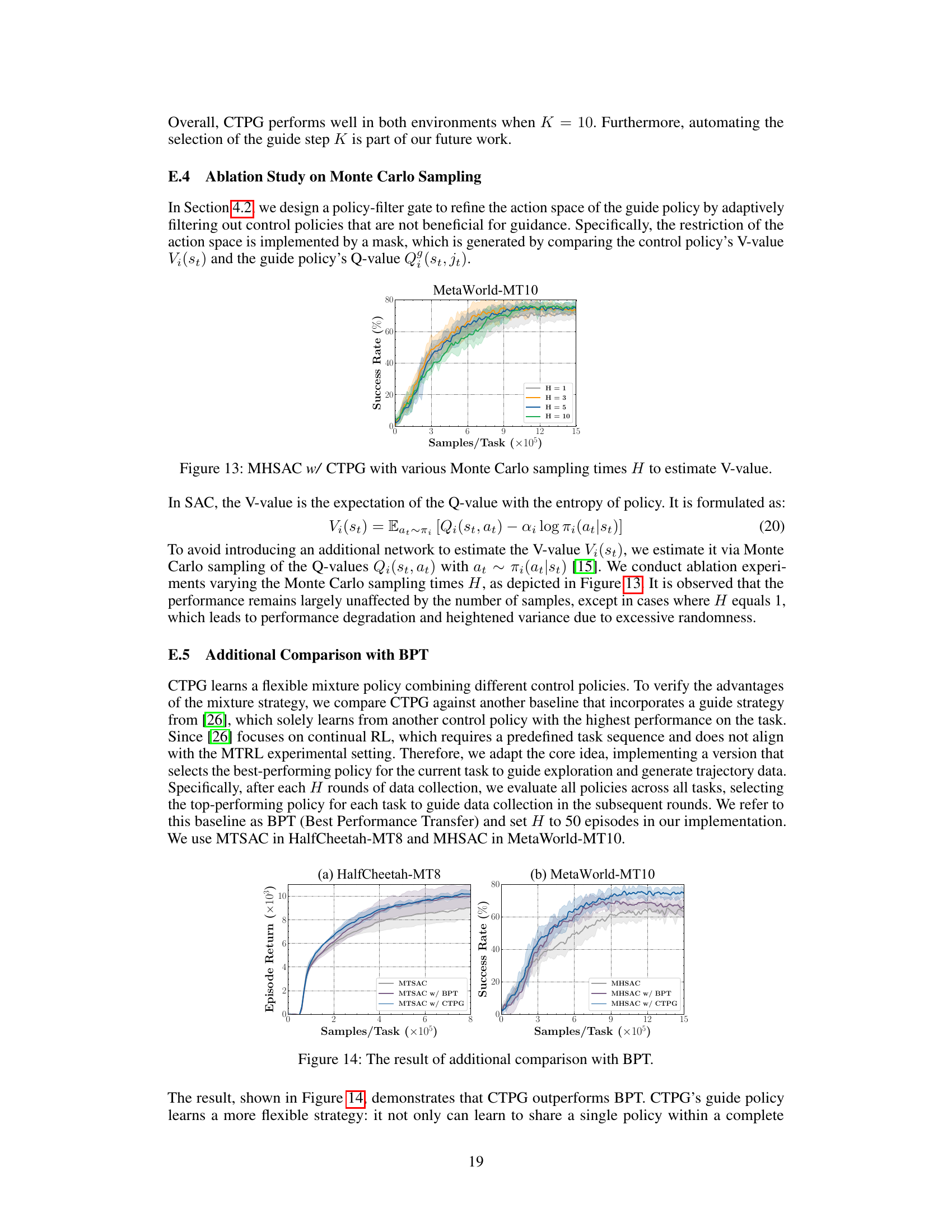
This table presents the quantitative results of experiments comparing five different implicit knowledge sharing approaches (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with three different explicit policy sharing methods (Base, w/ QMP, w/ CTPG). The table shows performance metrics (episode return or success rate) on two HalfCheetah locomotion tasks (MT5 and MT8) and two MetaWorld manipulation tasks (MT10 and MT50). The best-performing explicit policy sharing method for each implicit knowledge sharing approach is highlighted in bold, and the best overall combination (implicit and explicit) is indicated by a box.
In-depth insights#
Cross-Task Guidance#
Cross-task guidance in multi-task reinforcement learning (MTRL) aims to improve learning efficiency by leveraging knowledge from already mastered tasks to guide the learning process in new, related tasks. This approach acknowledges that tasks often share underlying skills or sub-policies, and intelligently transferring this knowledge can significantly reduce the amount of exploration and training required for each individual task. Effective cross-task guidance requires careful selection of which tasks’ policies are most beneficial for a given target task, and this selection process could be guided by various criteria such as the similarity of state spaces, action spaces, or reward functions. Moreover, strategies for integrating the guidance within existing MTRL frameworks—such as how to balance guidance from multiple source tasks—need careful consideration. Effective integration may involve gating mechanisms that filter out unhelpful guidance or prioritize guidance from certain source tasks under specific conditions. The success of cross-task guidance hinges on the design of appropriate mechanisms for selecting and weighting the guidance from different source tasks, and the overall effectiveness will ultimately depend on the specific tasks and the relationships between them. Further research should explore efficient methods for identifying and utilizing task relationships, dynamically adjusting the weight given to different sources of guidance, and evaluating performance improvements across diverse MTRL benchmarks.
Policy-Filter Gate#
The Policy-Filter Gate is a crucial mechanism within the Cross-Task Policy Guidance (CTPG) framework, designed to enhance efficiency by selectively filtering out unhelpful control policies. Its core function is to identify and prevent the use of control policies that hinder, rather than help, the learning process of a given task. This is achieved by comparing the Q-value of a candidate policy with the value function of the current task’s policy. If a candidate policy’s expected return (Q-value) is lower than the current task’s value function, it is deemed less beneficial and masked out by the gate. This adaptive filtering dynamically adjusts the action space of the guide policy, ensuring only high-quality control policies are considered for guidance. The effectiveness of this approach is supported by empirical evidence showing significant performance improvement when the policy-filter gate is incorporated. The mechanism avoids unnecessary exploration of similar contexts in different tasks by actively directing the guide policy towards the most relevant and effective control policies, ultimately accelerating the learning process.
MTRL Framework#
A Multi-Task Reinforcement Learning (MTRL) framework typically aims to efficiently leverage shared information across multiple tasks, thereby improving sample efficiency and generalization compared to training tasks in isolation. A well-designed framework might incorporate techniques like parameter sharing (e.g., shared layers in a neural network) to encode commonalities, task-specific modules to capture unique characteristics, and potentially curriculum learning, introducing tasks in a gradual manner based on difficulty or similarity. Optimization strategies are crucial, often addressing conflicting gradients from different tasks. Effective MTRL frameworks often involve careful task selection to ensure meaningful task relationships and avoid negative transfer. Finally, evaluation metrics must appropriately assess multi-task performance, going beyond individual task success rates.
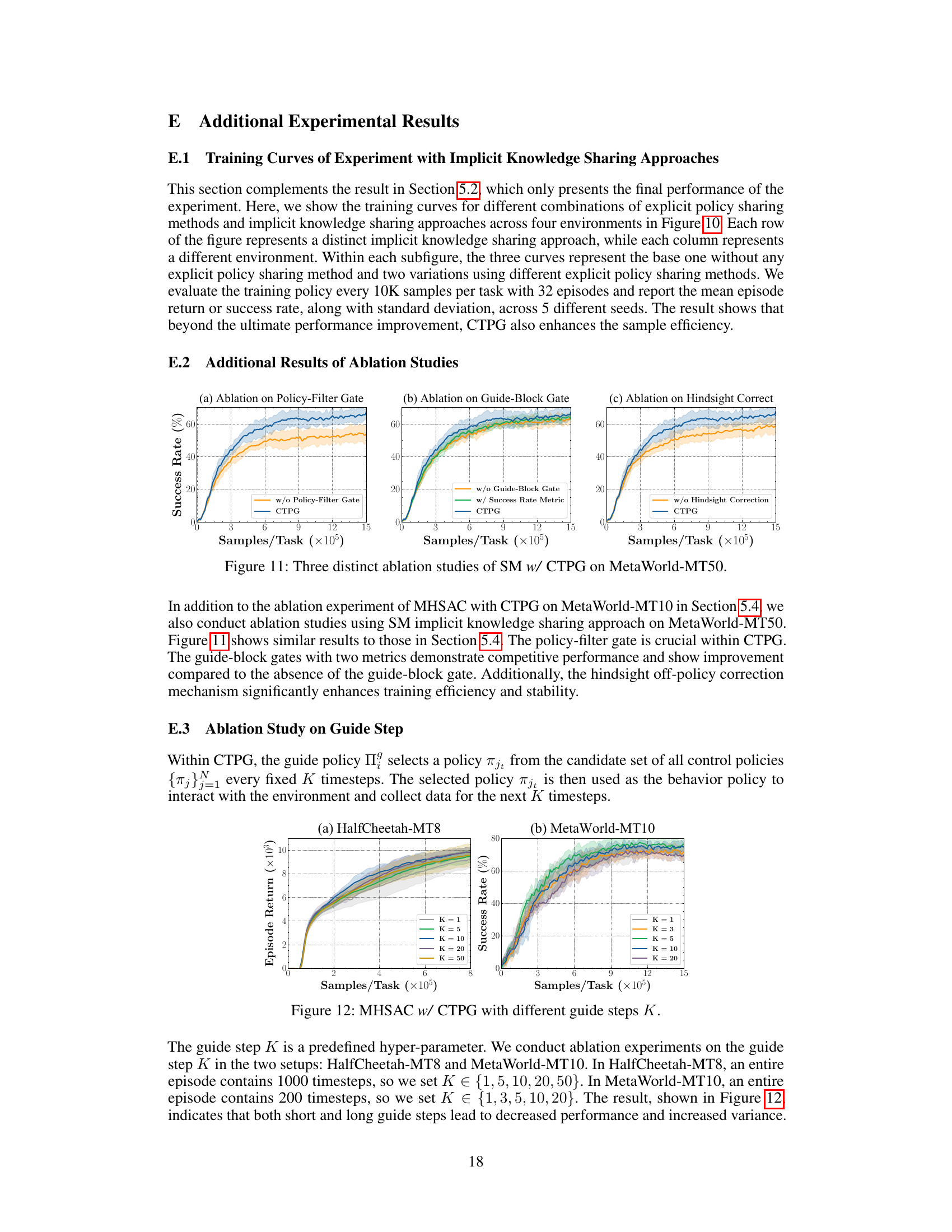
Ablation Studies#
Ablation studies systematically remove components of a model to understand their individual contributions. In the context of a reinforcement learning paper, this could involve removing different aspects of a novel method, such as policy guidance, gating mechanisms, or specific components of the architecture. By comparing the performance of the full model to models with specific parts removed, one can determine the effect of each removed element. For example, removing a policy-filter gate might result in significantly worse performance, demonstrating its importance in filtering less effective policies. Similarly, removing the hindsight off-policy correction mechanism could reveal its contribution to improved training stability. These ablation studies provide critical evidence of the importance and individual contributions of each element within the proposed approach, bolstering the argument for its effectiveness. Well-designed ablation studies are essential to showcase the impact of individual components, thus increasing confidence in the reported results. They provide a rigorous evaluation framework and help isolate the key elements responsible for the overall success of the methodology.
Future Directions#
Future research could explore several promising avenues. Improving the guide policy’s efficiency by developing more sophisticated methods for selecting beneficial policies and incorporating advanced reinforcement learning techniques is crucial. Investigating alternative approaches to policy guidance, beyond explicit sharing, could unlock further performance gains. Addressing the limitations of the fixed guide step K is vital; this could involve adaptive methods that dynamically adjust the guidance frequency based on task difficulty and progress. Moreover, exploring the application of CTPG to more complex and diverse multi-task learning scenarios, such as those involving continuous action spaces and high-dimensional state spaces, would significantly extend its applicability. Finally, a thorough investigation into the interaction between explicit and implicit knowledge sharing within the CTPG framework, and how this interaction can be optimally balanced for enhanced performance, warrants further study. Addressing potential negative societal impacts related to the application of multi-task reinforcement learning, such as bias in learned policies or the possibility of misuse, requires attention.
More visual insights#
More on figures
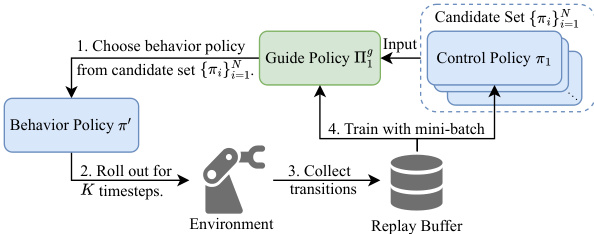
This figure illustrates the CTPG (Cross-Task Policy Guidance) framework. The guide policy for a given task selects a behavior policy from a candidate set of policies for all tasks. This selected policy then interacts with the environment for a fixed number of timesteps (K). The transitions (states, actions, rewards, next states) collected during this interaction are stored in a replay buffer. This data is then used to train the guide policy and control policy.

This figure illustrates the CTPG (Cross-Task Policy Guidance) framework. The guide policy selects a behavior policy from a candidate set of all tasks’ control policies. This chosen policy interacts with the environment for K timesteps, collecting data that is then stored in a replay buffer. This data is used to train both the guide policy and the control policy, enhancing exploration and improving the training trajectories.

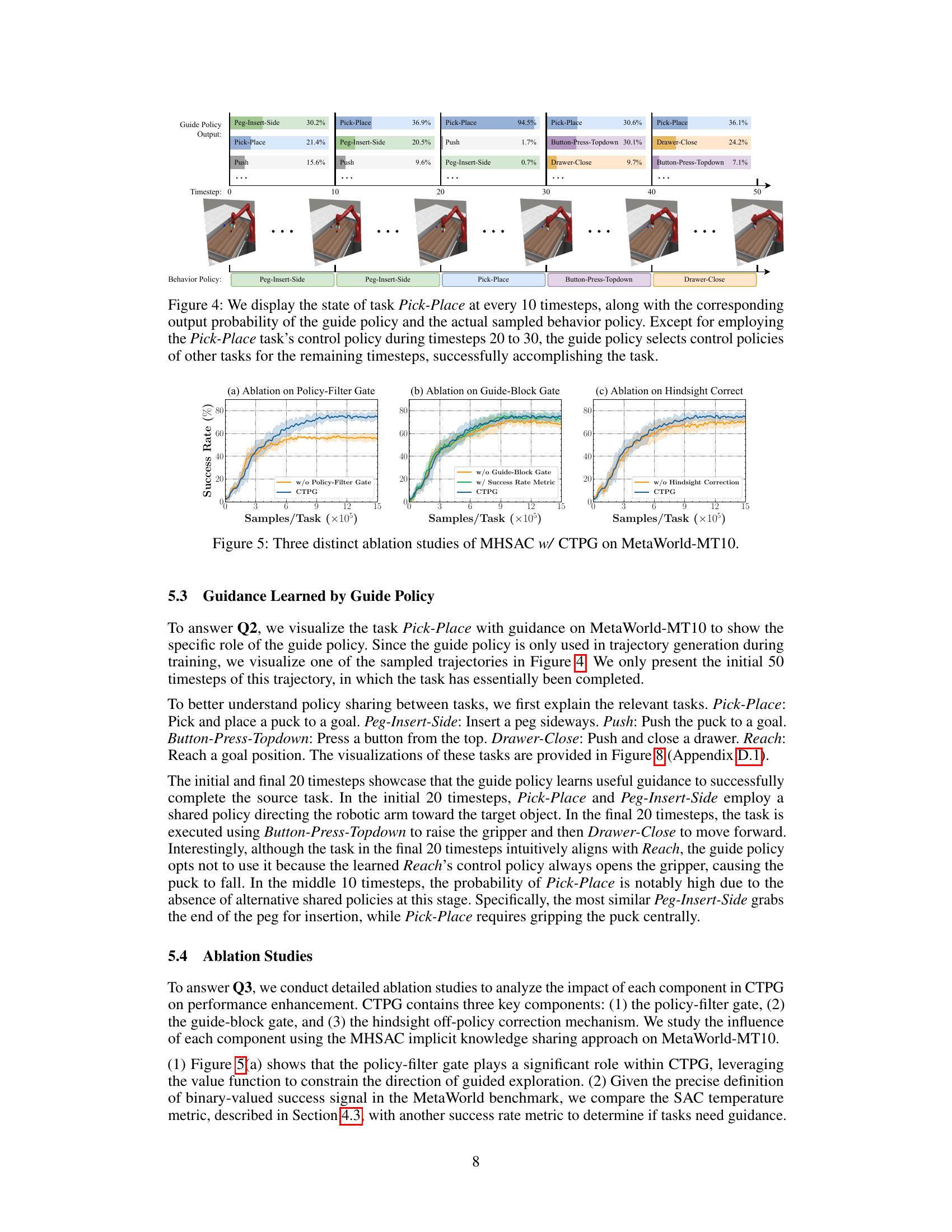
This figure visualizes a trajectory of the Pick-Place task in the MetaWorld-MT10 environment to demonstrate how the guide policy works. The guide policy selects different behavior policies from all tasks every 10 timesteps. The figure shows the probability of each task being selected by the guide policy and which policy was actually used at each timestep. It highlights how the guide policy leverages policies from other tasks to effectively complete the Pick-Place task by dynamically choosing the most beneficial policy at each step.
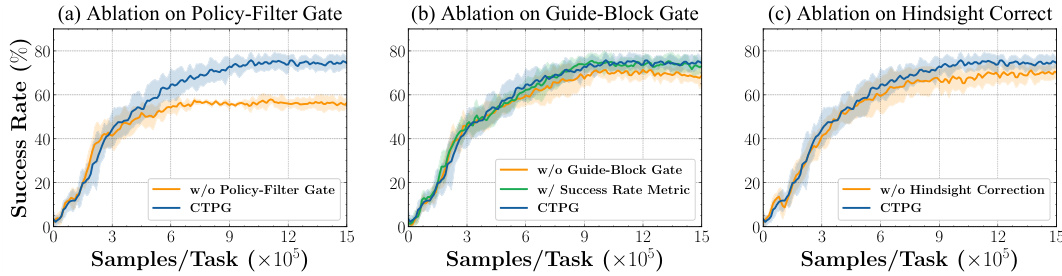
This figure presents the results of three ablation studies conducted to evaluate the impact of each component of the Cross-Task Policy Guidance (CTPG) framework on the performance of the Multi-Head Soft Actor-Critic (MHSAC) algorithm. The studies were performed on the MetaWorld-MT10 benchmark. The three subfigures show the impact of removing: (a) the policy-filter gate, (b) the guide-block gate, and (c) the hindsight off-policy correction. Each subfigure shows the success rate over training samples/task for the MHSAC w/ CTPG model along with the ablation variants. This allows for an assessment of the contribution of each component to the overall performance.

This figure shows the performance improvement achieved by using CTPG (Cross-Task Policy Guidance) on two different benchmark tasks (HalfCheetah-MT8 and MetaWorld-MT10) even without using implicit knowledge sharing. The results demonstrate that CTPG improves the performance of single-task SAC by providing explicit policy guidance, particularly more significant improvement in MetaWorld-MT10 where task difficulty varies more.

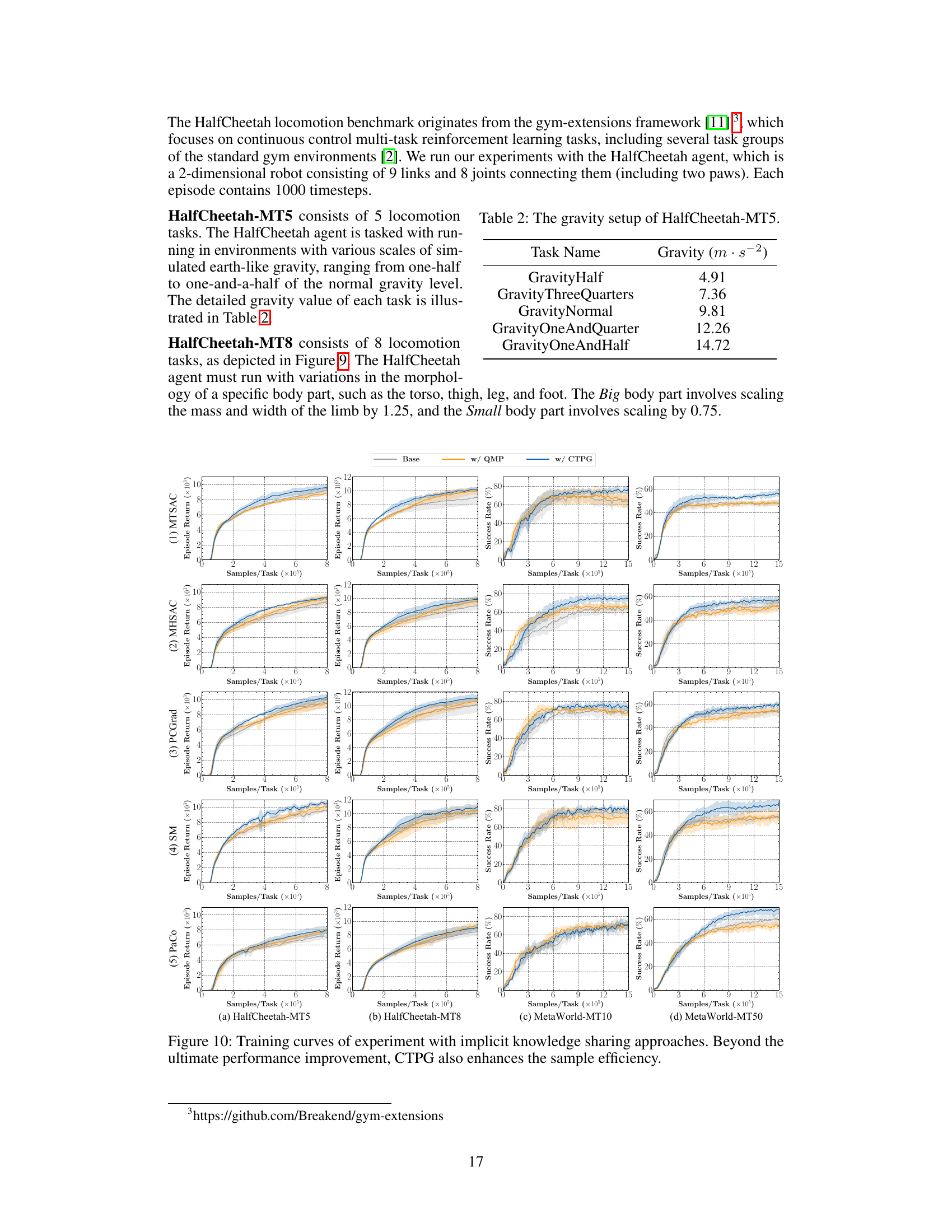
This figure shows the training curves for different combinations of explicit policy sharing methods and implicit knowledge sharing approaches across four environments. Each row represents a distinct implicit knowledge sharing approach, while each column represents a different environment. Within each subfigure, the three curves represent the base one without any explicit policy sharing method and two variations using different explicit policy sharing methods. The results show that beyond the ultimate performance improvement, CTPG also enhances the sample efficiency.
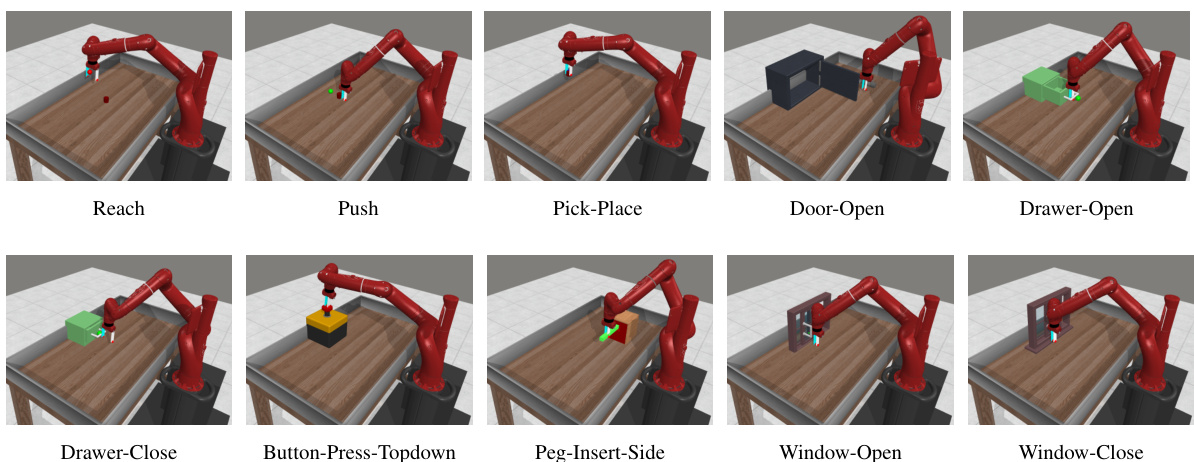
This figure shows ten different robotic manipulation tasks from the MetaWorld-MT10 benchmark. Each image displays a robotic arm in a different configuration interacting with an object in a scene. The tasks shown include Reach, Push, Pick-Place, Door-Open, Drawer-Open, Drawer-Close, Button-Press-Topdown, Peg-Insert-Side, Window-Open, and Window-Close, illustrating the diversity of manipulation skills tested in this benchmark.
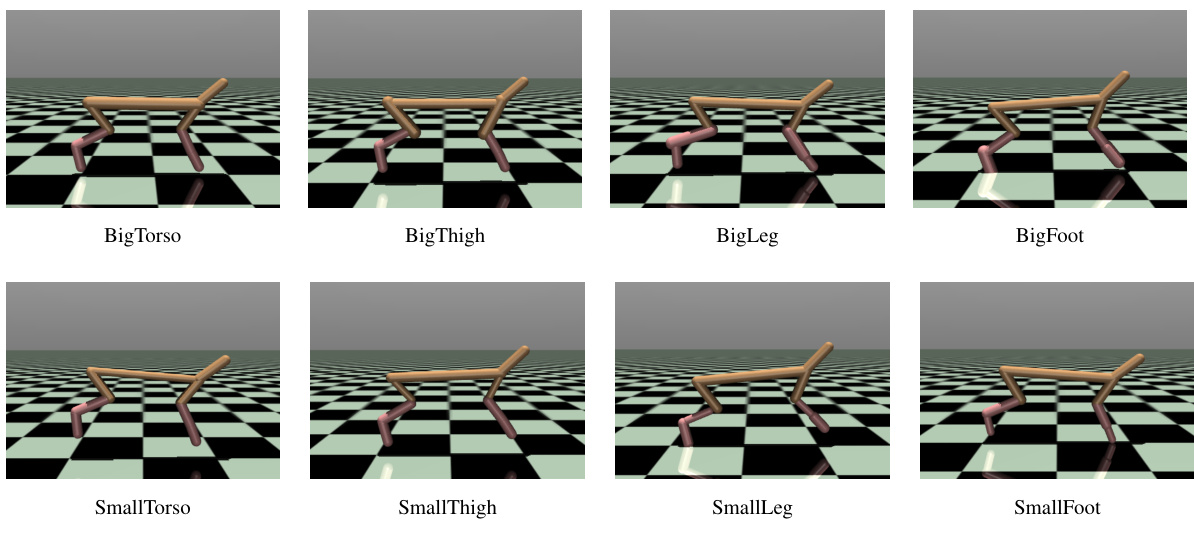
The figure shows eight different variations of the HalfCheetah robot used in the HalfCheetah-MT8 locomotion benchmark. Each variation modifies the size of a specific body part (torso, thigh, leg, or foot), resulting in either a ‘Big’ or a ‘Small’ version of that body part. These variations create diverse locomotion challenges for the reinforcement learning agent.

This figure illustrates the concept of policy sharing in multi-task reinforcement learning using robotic arm manipulation tasks. Panel (a) shows two tasks, Button-Press and Drawer-Close, that share a very similar policy because the robot arm must reach and push a button or handle. Panel (b) shows the tasks Door-Open and Drawer-Open. These share only a part of their policies (grabbing the handle), but differ in the subsequent steps required to open the door (rotation) versus the drawer (translation). This visual example is used to support the claim that sharing policies between tasks can improve learning efficiency.

This figure shows three ablation studies performed on the MHSAC (Multi-Head Soft Actor-Critic) algorithm with CTPG (Cross-Task Policy Guidance) on the MetaWorld-MT10 benchmark. Each subfigure demonstrates the impact of removing one component of CTPG: (a) the policy-filter gate, (b) the guide-block gate, and (c) the hindsight off-policy correction. The plots show success rate over training samples, comparing the full CTPG method against versions with each component removed. The results illustrate the contribution of each component to the overall performance improvement of the algorithm.
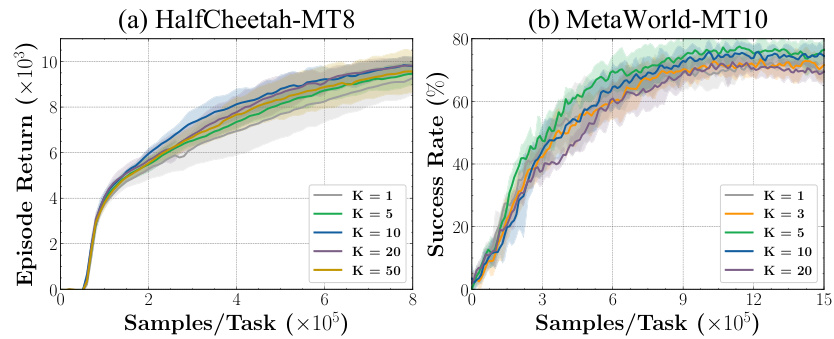
The ablation study on guide policy selection step K is shown in this figure. The guide step K is a hyperparameter in CTPG that determines how often the guide policy samples from other tasks’ policies. The plots show the training curves on HalfCheetah-MT8 (episode return) and MetaWorld-MT10 (success rate) for different values of K. The results indicate that both very short (K=1, 3) and long (K=50) guide steps lead to decreased performance and increased variance. The optimal K appears to be around 10 for these environments.

This figure shows three ablation studies performed on the MHSAC (Multi-Head Soft Actor-Critic) algorithm with CTPG (Cross-Task Policy Guidance) on the MetaWorld-MT10 benchmark. Each subplot shows the impact of removing one component of CTPG. (a) shows ablation of the policy-filter gate, (b) shows ablation of the guide-block gate, and (c) shows ablation of the hindsight off-policy correction. The x-axis represents the number of samples per task (in millions) and the y-axis represents the success rate (%). The results demonstrate the importance of each component of CTPG for achieving high performance.

This figure presents the training curves for five different implicit knowledge sharing approaches (MTSAC, MHSAC, PCGrad, SM, PaCo) with and without CTPG across four different environments (HalfCheetah-MT5, HalfCheetah-MT8, MetaWorld-MT10, MetaWorld-MT50). Each row represents a different implicit knowledge sharing approach, while each column represents a different environment. For each combination, three curves are shown: one for the base approach, one with QMP (a single-step policy sharing method), and one with CTPG. The x-axis represents the number of samples per task, and the y-axis represents either the episode return (for HalfCheetah) or the success rate (for MetaWorld). The shaded areas indicate the standard deviation across five different random seeds. The results demonstrate that CTPG consistently improves performance and sample efficiency across all implicit methods and environments, showing that it helps learn better policies more quickly.

This figure presents the training curves for different combinations of explicit policy sharing methods and implicit knowledge sharing approaches across four environments. Each row represents a distinct implicit knowledge sharing approach, while each column represents a different environment. The three curves in each subfigure show the base performance without explicit policy sharing, the performance with QMP, and the performance with CTPG. The figure demonstrates that CTPG not only improves the final performance but also enhances the sample efficiency across all environments.
More on tables

This table presents a quantitative comparison of five different implicit knowledge sharing methods (MTSAC, MHSAC, SM, PaCo, PCGrad) when combined with two explicit policy sharing methods (QMP and CTPG). The performance is evaluated on two locomotion tasks (HalfCheetah MT5 and MT8) using episode return as the metric, and on two manipulation tasks (MetaWorld MT10 and MT50) using success rate. The table highlights the best performing explicit policy sharing method for each implicit method and also indicates the best overall combination of implicit and explicit methods.

This table presents the quantitative results of experiments comparing five different implicit knowledge sharing methods (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with two different explicit policy sharing methods (QMP, CTPG) across four different benchmark environments (HalfCheetah MT5, HalfCheetah MT8, MetaWorld MT10, and MetaWorld MT50). The performance metrics are episode return for the HalfCheetah tasks and success rate for the MetaWorld tasks. The table highlights the best-performing explicit policy sharing method (QMP or CTPG) for each benchmark and also highlights the best overall combination of implicit and explicit policy sharing methods.

This table presents the quantitative results of combining five classical implicit knowledge sharing approaches (MTSAC, MHSAC, SM, PaCo, PCGrad) with two explicit policy sharing methods (QMP and CTPG). It shows the performance on four benchmark environments: HalfCheetah MT5, HalfCheetah MT8, MetaWorld MT10, and MetaWorld MT50. The performance metrics used are episode return (for HalfCheetah) and success rate (for MetaWorld). The table highlights the best-performing explicit policy sharing method for each benchmark and the best overall combination of implicit and explicit methods.

This table presents the quantitative results of experiments comparing five different implicit knowledge sharing methods (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with two different explicit policy sharing methods (QMP, CTPG). The performance is evaluated on two HalfCheetah locomotion environments (episode return) and two MetaWorld manipulation environments (success rate). The table highlights the best performing explicit policy sharing method for each implicit method and shows the best combination of the two approaches.

This table presents the quantitative results of experiments comparing five different implicit knowledge sharing approaches (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with three different explicit policy sharing methods (Base, w/QMP, w/CTPG). The performance is measured on two HalfCheetah locomotion environments (episode return) and two MetaWorld manipulation environments (success rate). The table highlights the best-performing explicit policy sharing method for each task and indicates the best overall combinations.

This table presents the quantitative results of experiments comparing five different implicit knowledge sharing approaches combined with two explicit policy sharing methods (QMP and CTPG). The experiments were conducted on two HalfCheetah locomotion environments (measured by episode return) and two MetaWorld manipulation environments (measured by success rate). The table highlights the best-performing explicit policy sharing method for each setup and also indicates the best combination of implicit and explicit methods.

This table presents the quantitative results of experiments comparing different combinations of implicit and explicit knowledge sharing methods in multi-task reinforcement learning. Five classical implicit knowledge sharing approaches are tested alongside two explicit policy sharing methods (QMP and CTPG). The results are reported for two locomotion tasks (HalfCheetah-MT5 and HalfCheetah-MT8), and two manipulation tasks (MetaWorld-MT10 and MetaWorld-MT50). The table highlights the best performing explicit policy sharing method for each setup and also indicates the best overall combination of implicit and explicit methods.
This table presents the quantitative results of experiments comparing five different implicit knowledge sharing approaches (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with three different explicit policy sharing methods (Base, w/ QMP, w/ CTPG). The comparison is performed on two HalfCheetah locomotion tasks (MT5 and MT8), and two MetaWorld manipulation tasks (MT10 and MT50). The metrics used are episode return (for HalfCheetah) and success rate (for MetaWorld). The table highlights the best-performing explicit policy sharing method for each task and also indicates the best combination of implicit and explicit methods.

This table presents the quantitative results of experiments that combine five classical implicit knowledge sharing approaches with two different explicit policy sharing methods (QMP and CTPG). The experiments were conducted on two HalfCheetah locomotion environments (evaluated by episode return) and two MetaWorld manipulation environments (evaluated by success rate). The table highlights the best-performing explicit policy sharing method for each scenario and also indicates the best overall combination of implicit and explicit methods.

This table presents the quantitative results of experiments comparing five different implicit knowledge sharing methods (MTSAC, MHSAC, SM, PaCo, PCGrad) combined with two different explicit policy sharing methods (QMP and CTPG). The table shows the performance of each combination on four different benchmark environments (HalfCheetah MT5, HalfCheetah MT8, MetaWorld MT10, and MetaWorld MT50). The performance metrics used are episode return (for HalfCheetah) and success rate (for MetaWorld). The best-performing explicit policy sharing method for each implicit method is highlighted in bold, and the best overall combinations are indicated by boxes.
Full paper#