↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current offline preference optimization methods, such as Direct Preference Optimization (DPO), rely on reference models and complex reward functions, limiting their efficiency and scalability. These methods also suffer from a mismatch between training and inference, potentially hindering performance. The reward functions used don’t always align with how language models generate text.
SimPO addresses these issues by using a simpler, reference-free reward formulation based on the average log probability of a sequence. This novel approach makes it more computationally efficient and aligns the reward function with the model’s generation process, leading to superior performance. Adding a target reward margin further enhances performance. SimPO consistently outperforms existing methods on several benchmark datasets without significant increases in response length.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SimPO, a simpler and more efficient offline preference optimization algorithm. This offers significant improvements in performance over existing methods while reducing computational needs, thus advancing research in reinforcement learning from human feedback (RLHF). It opens avenues for further research into reference-free reward formulations and efficient LLM alignment techniques.
Visual Insights#

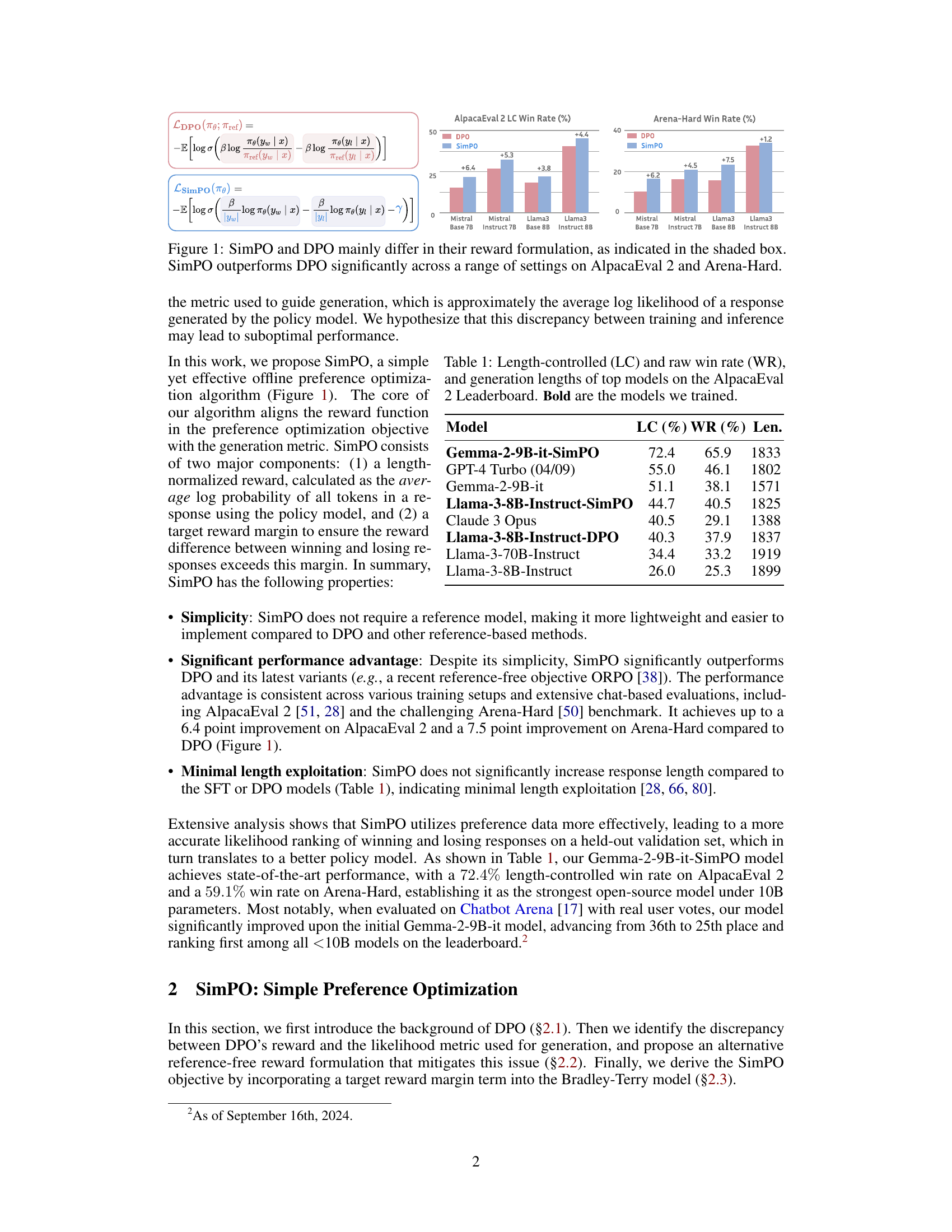
This figure compares the performance of SimPO and DPO on AlpacaEval 2 and Arena-Hard benchmarks. The shaded box highlights the key difference between the two methods: their reward formulation. SimPO uses the average log probability of a sequence as the implicit reward, while DPO uses the log ratio of the likelihood of a response between the current policy model and a reference model. The bar chart shows that SimPO consistently and significantly outperforms DPO across various settings, indicating the effectiveness of SimPO’s simpler yet more effective reward formulation.
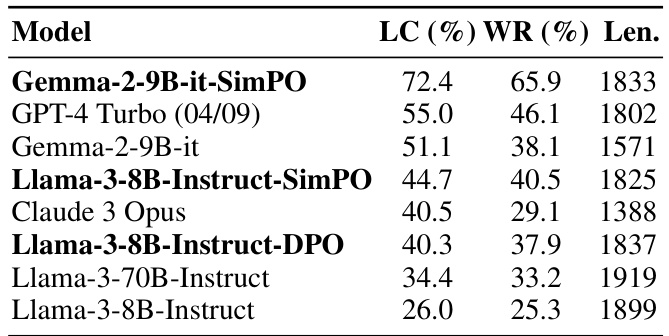
This table presents the performance of several language models on the AlpacaEval 2 Leaderboard, comparing their length-controlled win rate (LC), raw win rate (WR), and average generation length. The models include both base and instruction-tuned models, highlighting the results of models trained by the authors in bold.
In-depth insights#
SimPO’s Core Design#
SimPO’s core design revolves around a simpler yet more effective approach to offline preference optimization. Its key innovation lies in using the average log probability of a sequence as an implicit reward, eliminating the need for a reference model. This design choice directly aligns the reward function with the model’s generation process, enhancing efficiency and potentially improving performance. Further, SimPO incorporates a target reward margin to the Bradley-Terry objective, which encourages larger margins between winning and losing responses, leading to more robust learning. This combination of a reference-free reward and a target margin significantly simplifies the optimization process while potentially improving the quality and consistency of model outputs. Simplicity and enhanced efficiency are major advantages of this approach, making it potentially more accessible and scalable than existing methods.
Reward Function#
A crucial aspect of reinforcement learning from human feedback (RLHF) is the design of the reward function. This function guides the learning process by assigning numerical values to different model behaviors. In many RLHF approaches, such as Direct Preference Optimization (DPO), the reward function is implicitly defined, often relying on the log probability ratio between model and reference outputs. However, SimPO proposes a simpler yet effective approach by utilizing the average log probability of a sequence as an implicit reward. This is significant because it directly aligns with model generation, eliminating the need for a reference model and improving computational efficiency. Furthermore, SimPO incorporates a target reward margin to increase the gap between positive and negative feedback, enhancing performance. This design choice avoids the discrepancies between the reward function’s form during training and the evaluation metric used during inference, a known shortcoming of implicit reward methods like DPO. The impact of these design choices is significant, as demonstrated by SimPO’s consistent and substantial outperformance of existing methods. The reference-free aspect and improved efficiency of SimPO make it a promising technique for future RLHF applications.
Empirical Results#
An Empirical Results section should present a thorough analysis of experimental findings, comparing different models’ performance on various benchmarks. It’s crucial to clearly state the metrics used and justify their relevance. Statistical significance should be rigorously addressed, using appropriate tests and error bars. Qualitative analysis, including representative examples of model outputs, can provide valuable insights, complementing the quantitative data. The discussion should highlight key performance differences, explaining why certain models excel or underperform in specific areas. A strong Empirical Results section would not just report numbers, but contextualize them within the broader research goals, explaining how the results contribute to a deeper understanding of the problem.
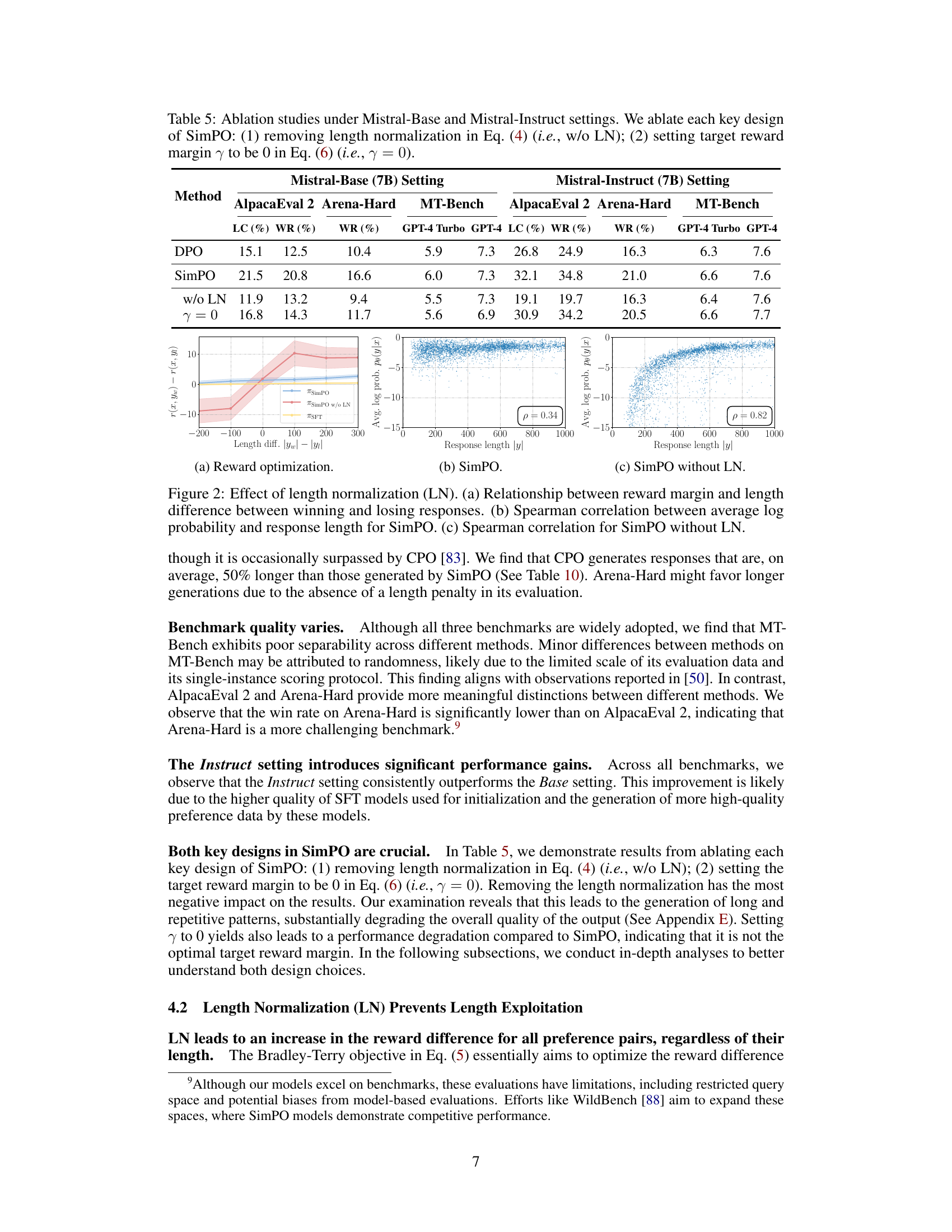
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In a machine learning context, this might involve removing layers from a neural network, features from a dataset, or hyperparameters from an optimization algorithm. The goal is to understand which parts are essential for achieving good performance and which are less important or even detrimental. Well-designed ablation studies isolate the effects of individual components, allowing researchers to build more efficient and robust models. They also aid in understanding the underlying mechanisms driving a model’s success or failure, thus helping improve future designs. Interpreting results from ablation studies requires careful consideration of interactions between components, the choice of baseline configuration, and the metrics used to evaluate performance. A robust ablation study should demonstrate a clear and consistent relationship between the removed component and the resulting change in performance. The absence of such a relationship might indicate redundant components, masking effects from other parts, or limitations in the evaluation methodology. Careful design and thorough reporting of ablation studies are critical for ensuring their validity and fostering reproducibility in research, leading to a deeper understanding of the subject matter.
Future Work#
Future research directions stemming from this work could explore several key areas. Extending SimPO’s theoretical grounding is crucial, moving beyond the empirical observations to provide a more robust understanding of its effectiveness. This includes a deeper investigation into the influence of the target reward margin and length normalization parameters on model generalization and performance. Addressing potential safety and honesty concerns within the framework is also vital. SimPO, while improving performance, doesn’t explicitly address these crucial aspects of LLM alignment. Incorporating such constraints directly into the objective function or through careful data selection is necessary for responsible LLM deployment. Finally, exploring more efficient and scalable training methods for SimPO warrants further investigation. While SimPO is already more memory-efficient than DPO, further optimizations could make it suitable for even larger models and datasets. Investigating techniques like early stopping or more efficient gradient calculations could improve training speed and reduce computational costs. These are important avenues to further explore to solidify SimPO’s position as a leading offline preference optimization technique.
More visual insights#
More on figures

This figure compares the performance of SimPO and DPO on AlpacaEval 2 and Arena-Hard benchmarks. The key difference highlighted is in their reward formulation. SimPO shows a significant performance improvement over DPO across various settings. The shaded box emphasizes the core difference between the reward functions used by SimPO and DPO.

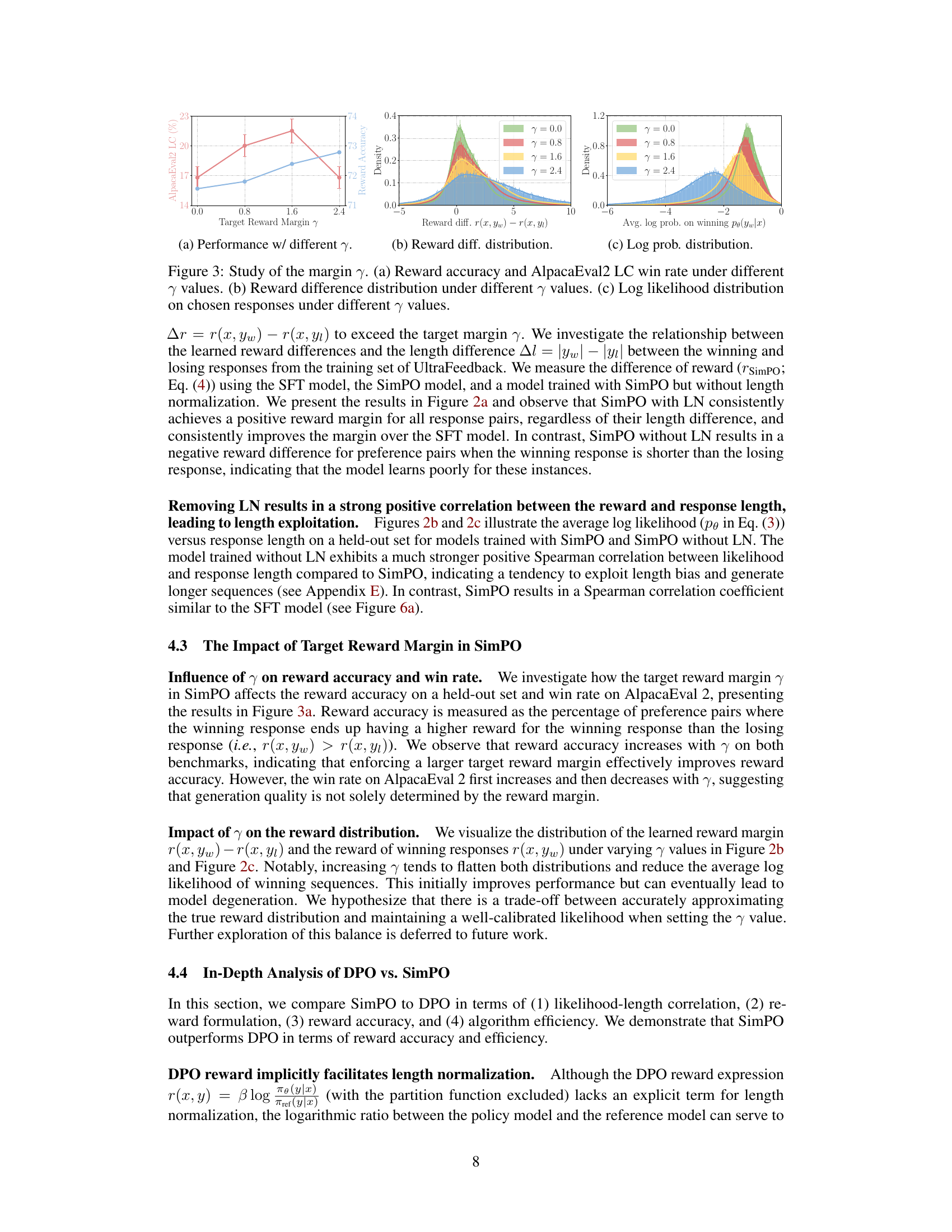
This figure analyzes the impact of the target reward margin (γ) on SimPO’s performance. Subfigure (a) shows how reward accuracy and AlpacaEval2 LC win rate change with different γ values. Subfigure (b) displays the distribution of reward differences (r(x, yw) - r(x, yı)) for various γ values, illustrating how the margin affects the separation between winning and losing responses. Subfigure (c) presents the distribution of average log probabilities of winning responses (pθ(yw|x)) under different γ values, showing the effect of the margin on response likelihood.
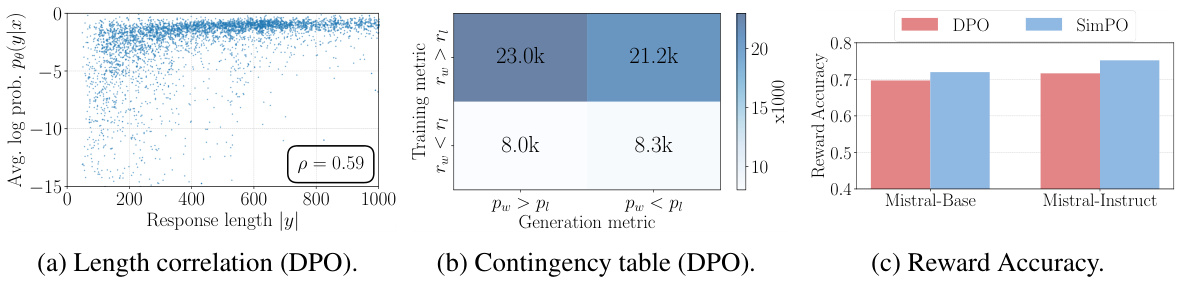
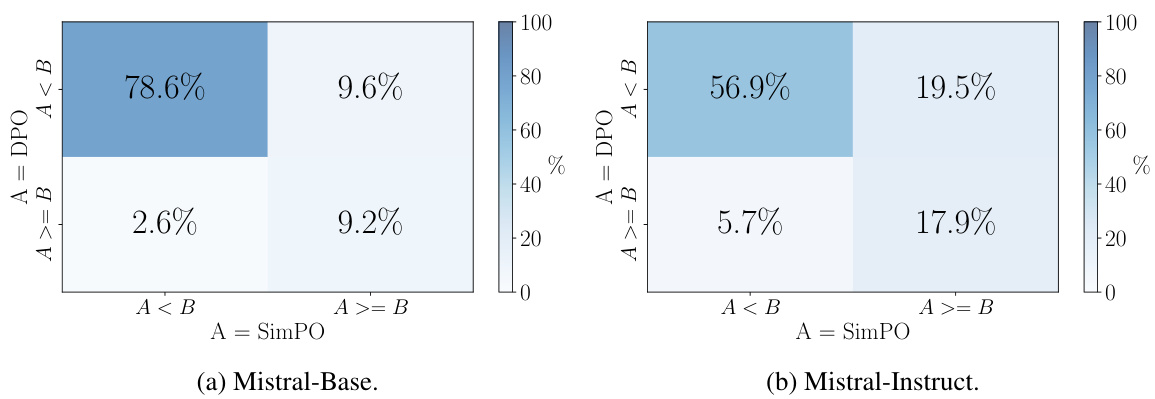
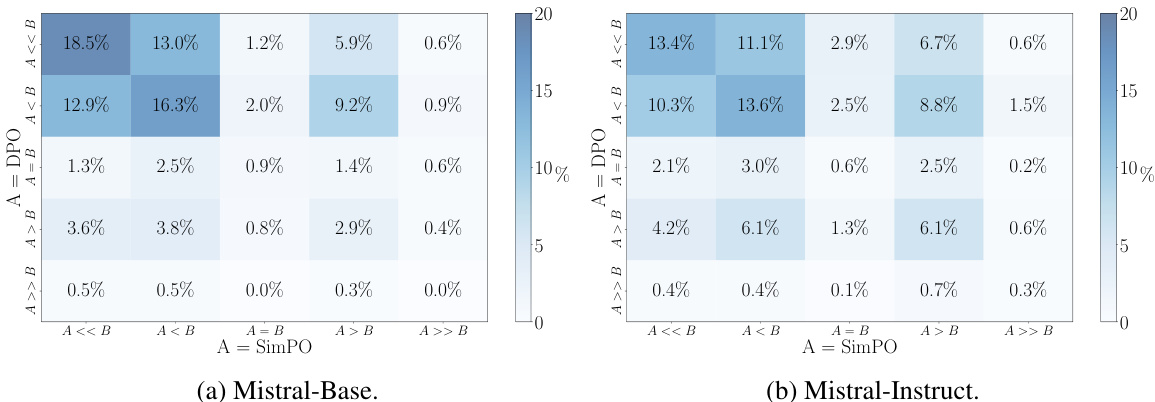
This figure compares SimPO and DPO using data from UltraFeedback. Panel (a) shows a scatter plot illustrating the Spearman correlation between the average log probability and response length for DPO, revealing a positive correlation and suggesting length bias. Panel (b) presents a contingency table contrasting DPO reward rankings against average log likelihood rankings for the training data, highlighting a significant mismatch (approximately 50%). Panel (c) displays a bar chart comparing the reward accuracy of SimPO and DPO in Mistral-Base and Mistral-Instruct settings, demonstrating SimPO’s superior accuracy in aligning reward rankings with preference data.

This figure compares SimPO and DPO, highlighting their main difference in reward formulation and showing SimPO’s superior performance on AlpacaEval 2 and Arena-Hard benchmarks. The shaded box emphasizes the key difference in the reward calculation between the two methods. The bar chart visually demonstrates SimPO’s consistent and significant performance improvement over DPO across different model settings.
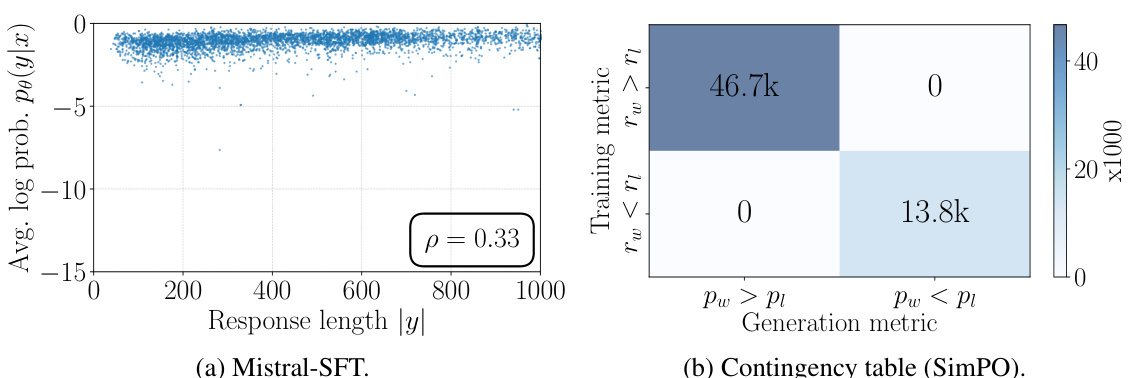
This figure shows the effects of length normalization in SimPO. The first plot (a) demonstrates the relationship between the reward margin and the length difference between winning and losing responses. The second plot (b) shows the correlation between the average log probability and response length for SimPO, and the third plot (c) shows the same correlation for SimPO without length normalization. These plots illustrate how length normalization helps mitigate bias towards longer responses.
This figure compares SimPO and DPO, highlighting their differences in reward formulation and the resulting performance on AlpacaEval 2 and Arena-Hard benchmarks. The shaded box shows the key difference in their reward functions: SimPO uses the average log probability of a response as the reward, while DPO uses a ratio of probabilities involving a reference model. The bar chart shows that SimPO consistently outperforms DPO across different model sizes and training conditions.
This figure compares the performance of SimPO and DPO on AlpacaEval 2 and Arena-Hard benchmark datasets. The shaded box highlights the key difference between the two methods: their reward formulation. SimPO uses the average log probability of a sequence as the reward, while DPO uses a more complex reward formulation based on the log ratio of likelihoods from the current policy and a reference model. The bar charts show that SimPO consistently and significantly outperforms DPO across various settings. The y-axis indicates the win rate increase and the x-axis shows different model sizes and training methods.

The figure compares the performance of SimPO and DPO on AlpacaEval 2 and Arena-Hard benchmarks. It highlights that the key difference between SimPO and DPO lies in their reward formulation. SimPO uses an average log probability as its implicit reward, while DPO uses a log ratio of likelihoods from the current policy and reference model. The bar chart visually demonstrates SimPO’s superior performance across various settings, showing a significant improvement in both win rates.
More on tables

This table details the evaluation benchmarks used in the paper. It shows the number of examples (# Exs.) used for each benchmark, the baseline model used for comparison, the judge model used for scoring (GPT-4 Turbo), the scoring type used (pairwise comparison for AlpacaEval 2 and Arena-Hard, single-answer grading for MT-Bench), and the metric used for evaluation (LC & raw win rate for AlpacaEval 2, win rate for Arena-Hard, and rating of 1-10 for MT-Bench).

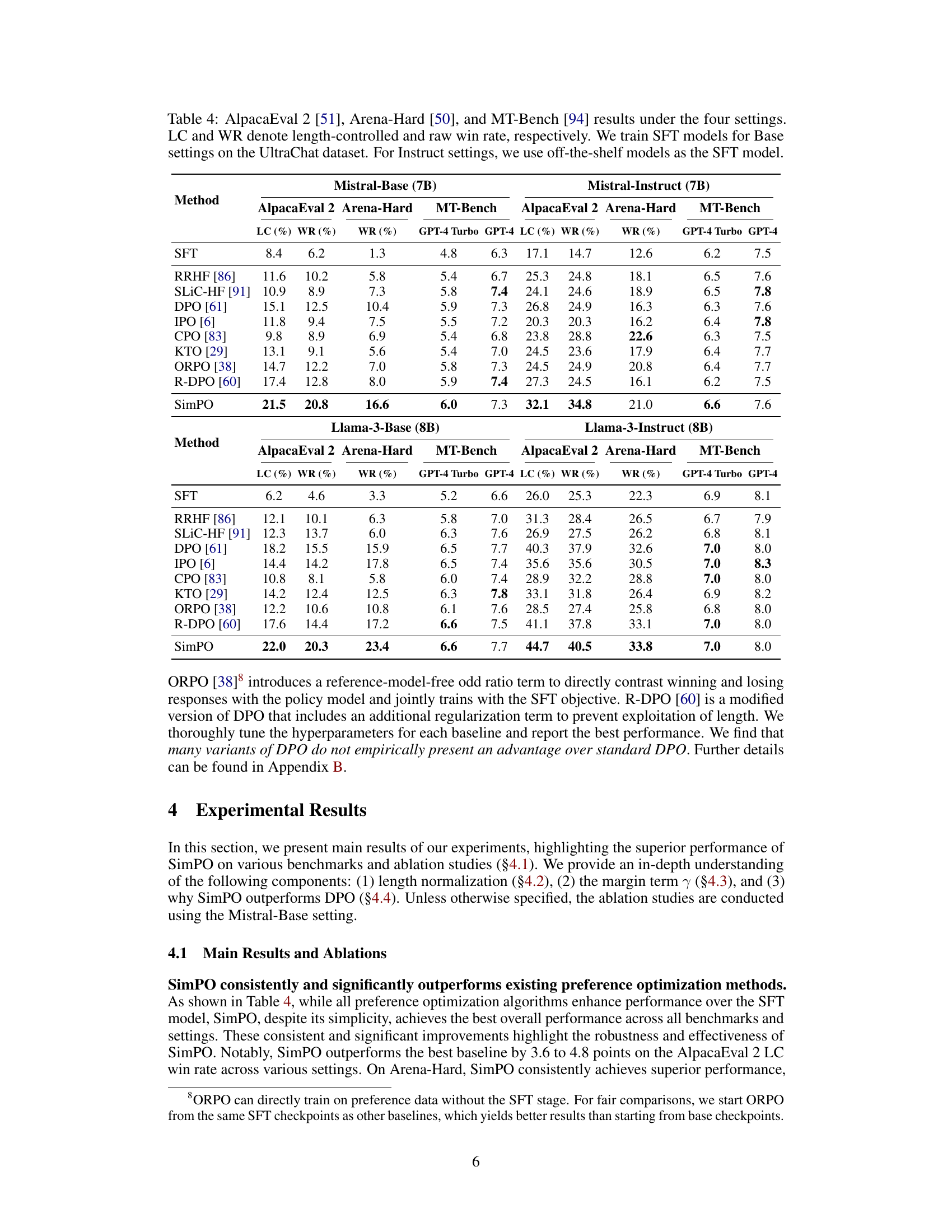
This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, and Mistral-Instruct) evaluated on three benchmark datasets (AlpacaEval 2, Arena-Hard, and MT-Bench). For each setting, it shows the length-controlled win rate (LC), raw win rate (WR), and the average response length in tokens. The table also indicates the training method used for the Supervised Fine-Tuning (SFT) models used as a baseline for each setting.
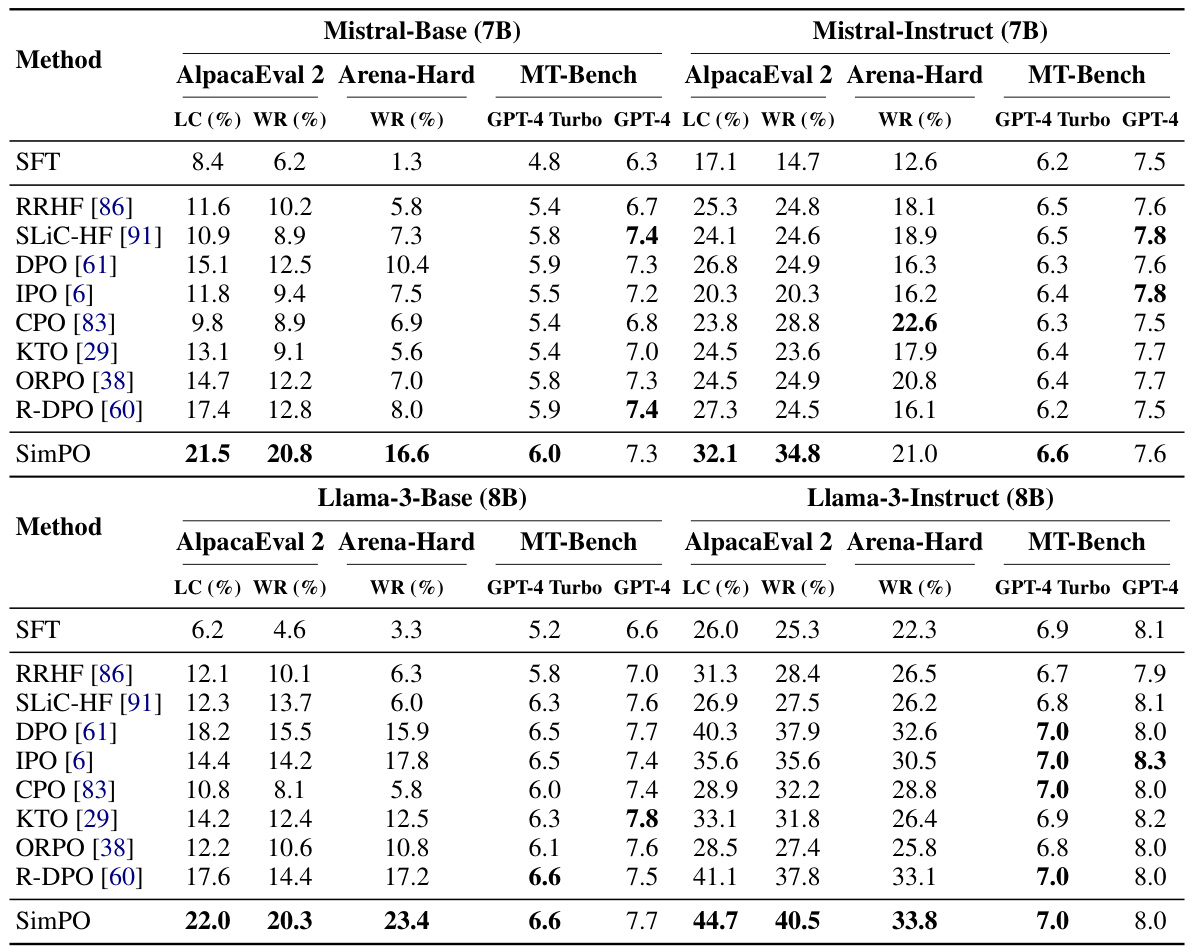
This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) on three benchmark datasets (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting and dataset, the table shows the length-controlled win rate (LC), the raw win rate (WR), and the average response length. The models were trained using different preference optimization methods (SimPO and baselines). The Base settings used models fine-tuned on the UltraChat dataset, while the Instruct settings used pre-trained instruction-tuned models. The table highlights the performance differences between SimPO and other methods across various model architectures and training procedures.

This table presents the Spearman rank correlation coefficient (ρ) between the average log-likelihood of different language models and their response lengths on a held-out dataset. The models compared are SimPO without length normalization (w/o LN), DPO, and SimPO. The correlation coefficient measures the strength and direction of the monotonic relationship between the two variables. A higher absolute value of ρ indicates a stronger correlation, while the sign indicates the direction (positive for increasing relationship, negative for decreasing). This table helps to analyze the impact of length normalization on the relationship between response length and model performance, highlighting SimPO’s effectiveness in mitigating length bias.

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) evaluated on three benchmarks (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting and benchmark, it shows the length-controlled win rate (LC), raw win rate (WR), and the win rate against GPT-4 or GPT-4 Turbo. The table also indicates whether the models used were trained from scratch (Base) or used pre-trained instruction-tuned models (Instruct).

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) evaluated on three benchmark datasets (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting, the table shows the length-controlled win rate (LC), the raw win rate (WR), and the average response length. The table also distinguishes between models trained with supervised fine-tuning (SFT) and those further optimized using various preference optimization methods (including SimPO).

This table presents the results of evaluating different preference optimization methods on three benchmark datasets: AlpacaEval 2, Arena-Hard, and MT-Bench. The table shows the length-controlled win rate (LC) and raw win rate (WR) for each method across four model settings: Llama-3-Base, Llama-3-Instruct, Mistral-Base, and Mistral-Instruct. The ‘SFT’ row represents the performance of the supervised fine-tuned models, serving as baselines for the preference optimization methods. The table highlights the performance differences among various methods and model settings.

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) on three benchmark tests (AlpacaEval 2, Arena-Hard, MT-Bench). For each model setting and benchmark, the table shows the length-controlled win rate (LC), raw win rate (WR), and the average response length. It highlights the performance differences between models trained with different setups (Base vs. Instruct) and the effect of different preference optimization methods.

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) on three benchmark datasets (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting and dataset, the table shows the length-controlled win rate (LC), the raw win rate (WR), and the average response length. The SFT (Supervised Fine-Tuned) models used are specified for each setting type. The table compares the performance of SimPO against several other preference optimization methods.

This table presents the average response lengths generated by the SimPO and SimPO without length normalization models. The results are broken down by model (SimPO vs. SimPO without length normalization), benchmark (AlpacaEval 2 vs. Arena-Hard), and model setting (Mistral-Base vs. Mistral-Instruct). It demonstrates the impact of length normalization on the length of generated responses for different models and evaluation benchmarks.

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) on three benchmark datasets (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting and benchmark, it shows the length-controlled win rate (LC), raw win rate (WR), and the average response length. It highlights the performance of SimPO against other preference optimization methods and indicates whether the models were trained from scratch (Base) or using pre-trained models (Instruct).

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) evaluated on three benchmarks (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting and benchmark, the table shows the length-controlled win rate (LC), raw win rate (WR), and the average response length. It highlights the performance differences between different preference optimization methods and model setups, indicating the effectiveness of SimPO in various contexts.

This table presents the results of using the Llama-3-Instruct (8B) model with preference optimization, but using a stronger reward model (ArmoRM) for annotation. It shows the performance metrics (LC%, WR%, Length, WR%, Length, GPT-4 Turbo, GPT-4) achieved by various preference optimization methods (SimPO v0.1, SimPO v0.2, RRHF, SLIC-HF, DPO, IPO, CPO, KTO, ORPO, R-DPO, SFT) on AlpacaEval 2, Arena-Hard, and MT-Bench.

This table presents the results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, and Mistral-Instruct) on three benchmark evaluations (AlpacaEval 2, Arena-Hard, and MT-Bench). For each setting, it shows the length-controlled win rate (LC), raw win rate (WR), and the average score on MT-Bench. It highlights the performance differences between base and instruction-tuned models, and between different preference optimization techniques (SimPO and its baselines). The training data used for the supervised fine-tuned (SFT) models is also specified.

This table presents the results of using Llama-3-Instruct (8B) model with preference optimization. A key difference from the results in Table 4 is the use of a stronger reward model (ArmoRM) for annotating the preference labels. The table shows the performance metrics (LC win rate, WR win rate, and average response length) on three benchmarks: AlpacaEval 2, Arena-Hard, and MT-Bench, along with GPT-4 Turbo and GPT-4 evaluation metrics. The ‘v0.2’ denotes the version of SimPO using a stronger reward model.

This table presents the quantitative results of four different model settings (Llama-3-Base, Llama-3-Instruct, Mistral-Base, Mistral-Instruct) evaluated on three benchmarks (AlpacaEval 2, Arena-Hard, MT-Bench). For each setting, the table shows the length-controlled win rate (LC), raw win rate (WR), and average response length. It compares the performance of SimPO against several baseline methods (SFT, RRHF, SLIC-HF, DPO, IPO, CPO, KTO, ORPO, R-DPO). The SFT models used are trained on the UltraChat dataset for Base settings and are off-the-shelf instruction-tuned models for Instruct settings.
This table presents the results of using Llama-3-Instruct (8B) model with preference optimization. A key aspect is that it uses a stronger reward model (ArmoRM) for annotating the preference labels, resulting in a version 0.2 of the model. The table shows the performance of several preference optimization methods (SimPO, RRHF, SLIC-HF, DPO, IPO, CPO, KTO, ORPO, R-DPO) on AlpacaEval 2, Arena-Hard, and MT-Bench benchmarks. Metrics include length-controlled win rate (LC), raw win rate (WR), and average response length. The GPT-4 Turbo and GPT-4 models were used for evaluation.

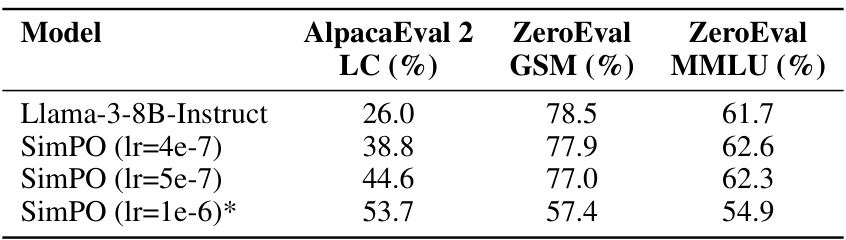
This table compares the performance of Gemma-2-9B model fine-tuned with DPO and SimPO methods on several benchmarks. The benchmarks assess both instruction following capabilities (AlpacaEval 2 LC, Arena-Hard) and knowledge capabilities (ZeroEval GSM, ZeroEval MMLU). The results show that SimPO achieves better instruction following performance without sacrificing performance on other tasks. The table also includes results for the released checkpoint (*).
Full paper#