↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Offline safe reinforcement learning faces challenges due to the mismatch between imperfect demonstration data and desired safe, high-reward performance. Existing methods struggle with this, often leading to suboptimal or unsafe policies. Many attempt to address this using model-centric techniques, but these struggle in the face of imbalanced or biased data.
This work introduces OASIS, a data-centric approach that uses a conditional diffusion model to generate improved training data. OASIS shapes the data distribution towards a better target domain, improving both safety and reward. The results show that OASIS significantly outperforms existing methods in data efficiency and robustness across various benchmarks, highlighting the effectiveness of the data-centric approach for offline safe RL.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in offline safe reinforcement learning due to its novel data-centric approach. OASIS offers a practical solution to the critical data mismatch problem, improving data efficiency and robustness, particularly valuable for real-world applications with limited high-quality demonstrations. It opens avenues for further research in data synthesis and distribution shaping techniques within constrained RL settings.
Visual Insights#
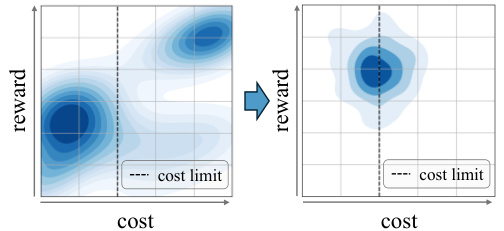
The figure illustrates the concept of distribution shaping in offline safe reinforcement learning. The left panel shows the original data distribution, which is spread out and includes many data points with both high cost and low reward, as well as low cost and low reward. The right panel shows how the distribution is shaped using a data-centric approach (OASIS). The new distribution generated by OASIS is concentrated in the area of low cost and high reward, which is beneficial for training a safe and rewarding RL agent. The dashed line represents the cost limit.

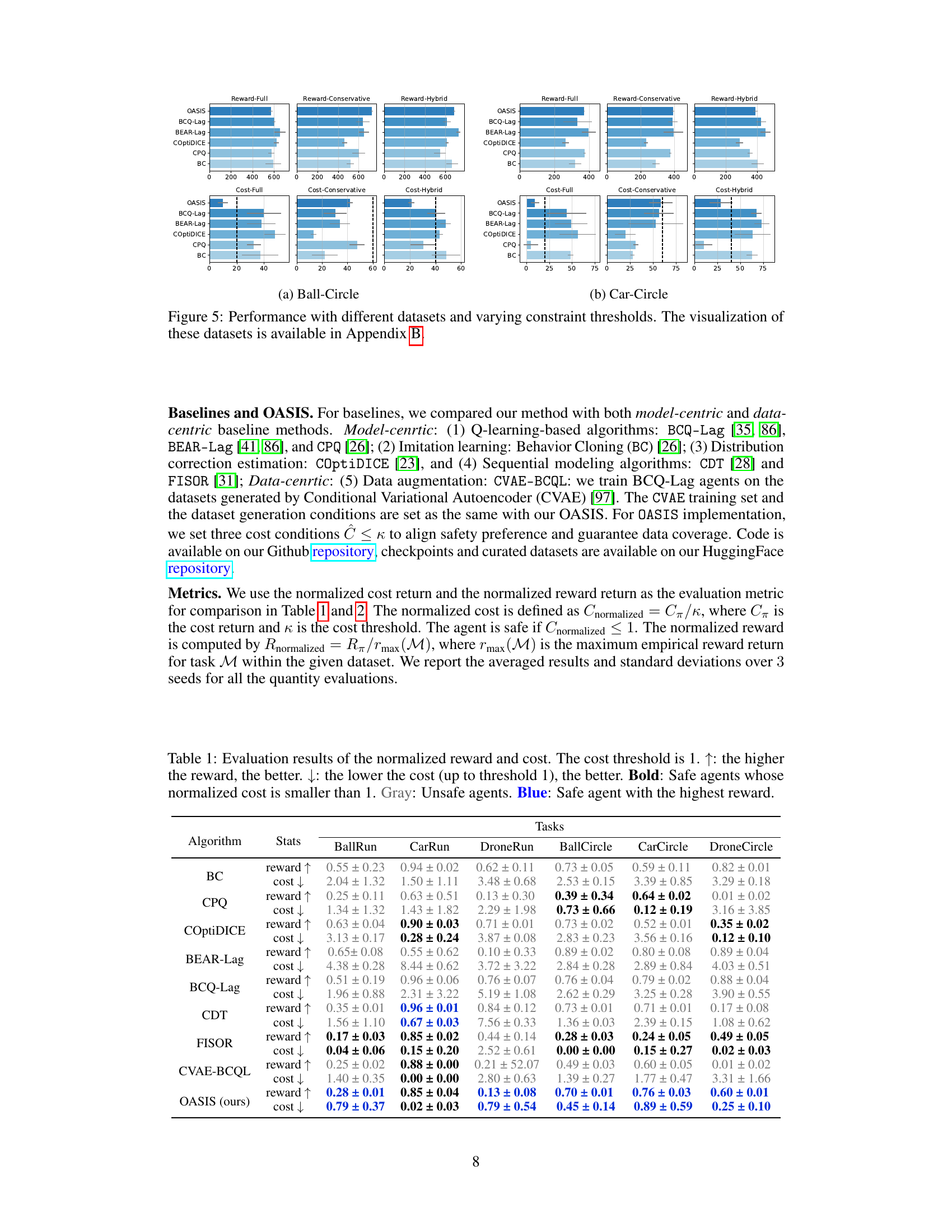
This table presents the performance comparison of different offline safe reinforcement learning algorithms on various tasks. The metrics used are the normalized reward and cost, indicating how well the algorithms achieve high rewards while maintaining safety constraints (cost below the threshold of 1). The table highlights the superior performance of the proposed OASIS method compared to existing baselines in terms of both reward and safety.
In-depth insights#
Safe Dataset Mismatch#
The concept of “Safe Dataset Mismatch” in offline safe reinforcement learning highlights a critical challenge: the discrepancy between the data distribution of a pre-collected dataset and the desired distribution for training a safe and optimal policy. A dataset dominated by unsafe or low-reward behaviors (tempting dataset) can lead to policies that prioritize rewards over safety, while a dataset lacking sufficient exploration of high-reward, safe regions (conservative dataset) may result in overly cautious, suboptimal policies. This mismatch arises from inherent limitations in data collection, where perfect, balanced demonstrations are rarely available. Mitigating this mismatch is crucial for successful offline safe RL, as it directly impacts the ability to learn policies that both satisfy safety constraints and achieve high rewards. Addressing this requires careful dataset curation or generation techniques that actively shift the data distribution towards a more beneficial target, improving the quality and representativeness of the training data for better generalization and safety assurance.
Diffusion Model Use#
The utilization of diffusion models in this research is a novel approach to address the limitations of existing offline safe reinforcement learning methods. Instead of directly optimizing the RL agent’s policy, the authors leverage a conditional diffusion model to shape the data distribution of the training dataset. This data-centric strategy aims to mitigate the mismatch between imperfect offline data and the desired safe, high-reward policy. By generating synthetic data that better reflects the target distribution, the approach improves the effectiveness of subsequent RL training, potentially leading to improved data efficiency and robustness. The conditional aspect of the diffusion model allows for incorporating safety constraints, ensuring that the synthesized data remains within the safe operating region. The results show this method outperforms baselines, showcasing the promise of data-centric approaches for safer, more efficient RL. However, the reliance on a generative model introduces challenges regarding computational cost and the potential for generating unrealistic or unsafe data. Future research could explore methods to improve the quality and efficiency of data generation.
OASIS Algorithm#
The OASIS algorithm, a data-centric approach to offline safe reinforcement learning, tackles the challenge of imperfect datasets by shaping the data distribution. Instead of directly modifying the RL algorithm, OASIS uses a conditional diffusion model to generate synthetic data that’s safer and more rewarding. This method addresses the safe dataset mismatch problem, generating data closer to the target policy distribution, resulting in improved policy performance. Key contributions include the identification of this mismatch, the introduction of this novel distribution shaping paradigm, and comprehensive evaluation demonstrating improved safety and efficiency over baselines. While effective, limitations exist regarding computational cost and the reliance on a high-quality initial dataset, though the method showcases promise for real-world applications where safety is paramount.
Data Efficiency Gains#
Data efficiency is crucial for real-world reinforcement learning applications, especially when dealing with limited data or high data acquisition costs. The paper highlights significant data efficiency gains by leveraging a conditional diffusion model to generate high-quality, safe data. This data augmentation strategy overcomes the limitations of traditional offline safe reinforcement learning methods that struggle with imperfect or biased datasets. OASIS excels at generating new data by focusing on a target cost limit, and the resulting dataset dramatically improves the performance of offline safe RL agents with substantially less data than previous approaches. The ability to synthesize data with desirable reward and cost characteristics enhances data quality and reduces the reliance on large, perfectly labeled datasets, making it particularly beneficial in safety-critical applications where obtaining high-quality demonstrations is challenging. This significantly reduces training time and computational cost. The overall effect showcases OASIS’s remarkable data efficiency and its potential to transform offline safe RL in practical settings.
Distribution Shaping#
The concept of “Distribution Shaping” in the context of offline safe reinforcement learning is a powerful technique to improve data quality and mitigate the mismatch between the behavior policy and the target safe policy. The core idea revolves around transforming the initial dataset through generative models or weighting methods to create a new distribution that is more suitable for training a safe and high-reward policy. This is crucial because imperfect demonstrations in offline RL often lead to suboptimal, unsafe policies. By reshaping the distribution, the algorithm learns from more diverse, relevant, and informative data, improving both safety and performance. Conditional diffusion models, for instance, offer a promising approach to generate data that better satisfies safety constraints while still achieving high rewards. However, successful distribution shaping requires careful consideration of various factors, including the choice of generative model, the definition of a desirable target distribution, and the potential for overfitting or bias introduced by the shaping process. The balance between data efficiency and generalizability also needs careful attention.
More visual insights#
More on figures

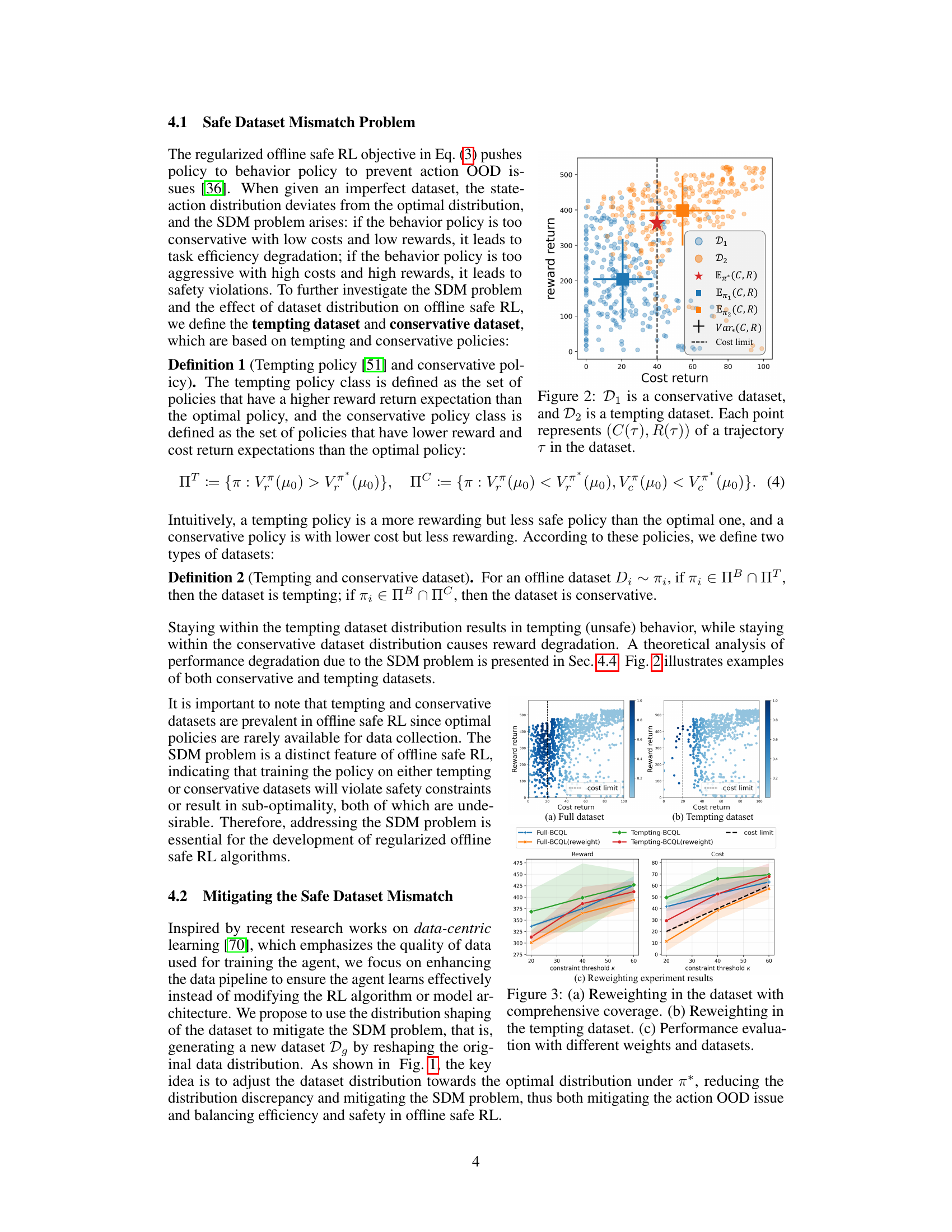
This figure visually represents two types of datasets in offline safe reinforcement learning: conservative and tempting. A conservative dataset (D₁) contains mostly low-reward, low-cost data points, while a tempting dataset (D₂) shows high-reward, high-cost data points. The plot displays the cost return (x-axis) versus the reward return (y-axis) for each trajectory in each dataset. A vertical dashed line indicates the cost limit (κ). The means and variances of both reward and cost for the optimal policy (π*) as well as the mean reward and cost for the policies generating D₁ (π₁) and D₂ (π₂) are also shown for comparison, highlighting the mismatch between the behavior policy’s data distribution and the optimal policy’s characteristics.

This figure shows the effect of dataset reweighting on the performance of offline safe RL. Panel (a) shows the effect of reweighting on the full dataset, while panel (b) shows the effect of reweighting on a dataset with an excess of tempting trajectories (tempting dataset). The results show that reweighting can improve the performance of offline safe RL in the full dataset, but that it is less effective in the tempting dataset. Panel (c) presents a quantitative comparison of different algorithms based on normalized reward and cost, showing that OASIS significantly outperforms existing methods.

This figure illustrates the OASIS framework. It starts with a pre-collected dataset containing state, action, next state, reward, and cost information. A preference is specified, indicating desired reward and cost limits. OASIS uses an inverse dynamics model and reward/cost models to process this data. A conditional diffusion model then generates a new dataset shaped by the specified preference using condition-guided denoising. Finally, an offline safe RL agent is trained on this modified dataset. The image visually depicts the generation process using color-coded data points representing different cost and reward values.
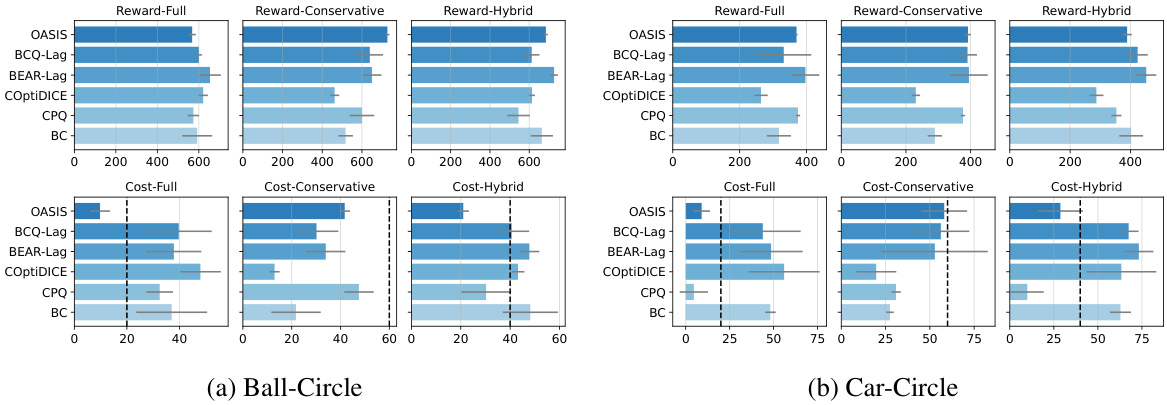
This figure visualizes the performance of different offline safe RL algorithms across various datasets (Full, Conservative, Tempting, Hybrid) and constraint thresholds (κ). The datasets represent different data distributions relevant to the safe RL problem. The results illustrate how well each algorithm handles these scenarios, demonstrating the impact of data distribution on safety and reward in offline safe reinforcement learning. The x-axis represents the reward or cost return and the y-axis represents the algorithms.
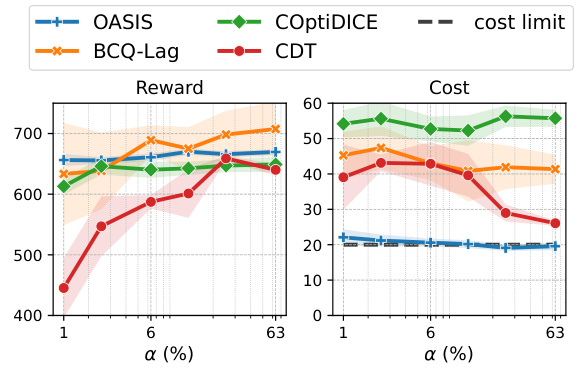
This figure shows the results of an experiment evaluating the data efficiency of the proposed OASIS method and several baseline methods on the Ball-Circle task, which uses a tempting dataset. The x-axis represents the percentage of the training data used, and the y-axis shows the average reward and cost. The shaded regions represent the standard deviation across multiple trials. OASIS consistently outperforms baseline methods in terms of reward and cost, even with very limited data, demonstrating its high data efficiency. The cost limit is shown as a horizontal dashed line.
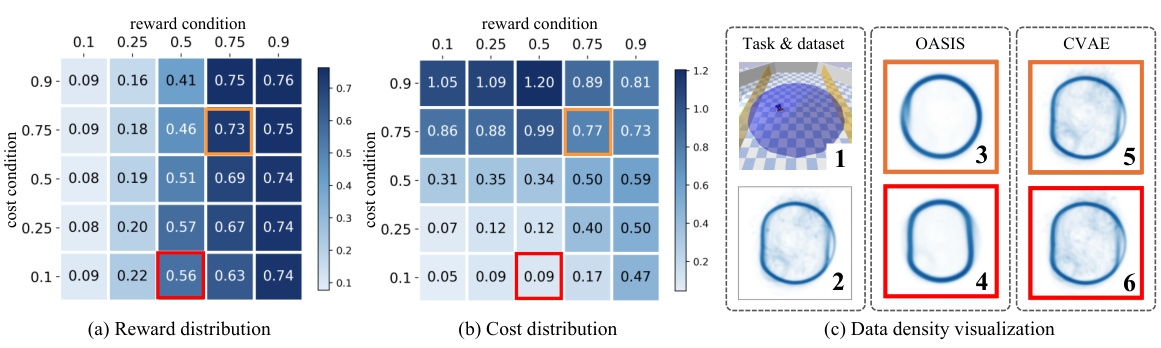
This figure visualizes the reward and cost of generated data by OASIS and CVAE under different conditions. It also shows the density of generated data and compares it with the original dataset. OASIS successfully shapes the distribution while CVAE fails to do so.
This figure compares the performance of the proposed OASIS method with a baseline method (CVAE) in generating data for offline safe reinforcement learning. It shows that CVAE fails to successfully encode conditions into the data generation process, resulting in similar results across different conditions. In contrast, OASIS demonstrates strong data generation capability and accurately reflects the specified reward and cost conditions.
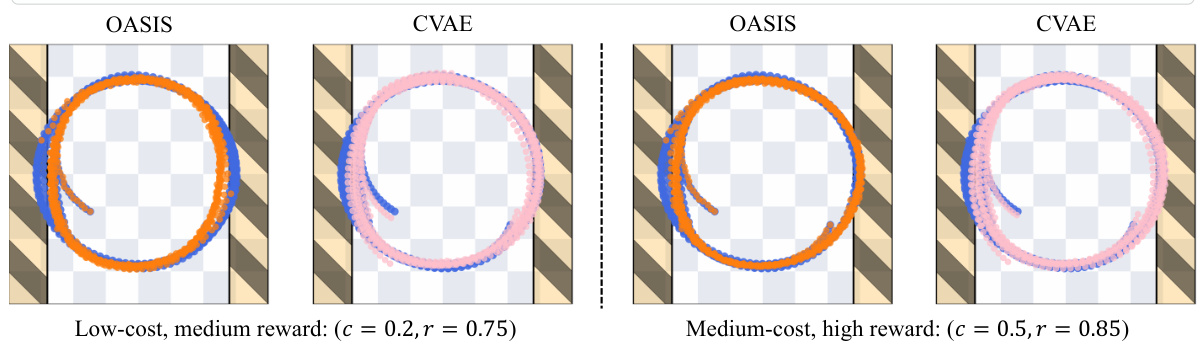
This figure compares the generated trajectories by OASIS and CVAE under two different conditions: low-cost-medium-reward and medium-cost-high-reward. While CVAE generates trajectories similar to the original data, OASIS successfully generates trajectories that satisfy the specified conditions, avoiding restricted areas when a low-cost condition is applied.
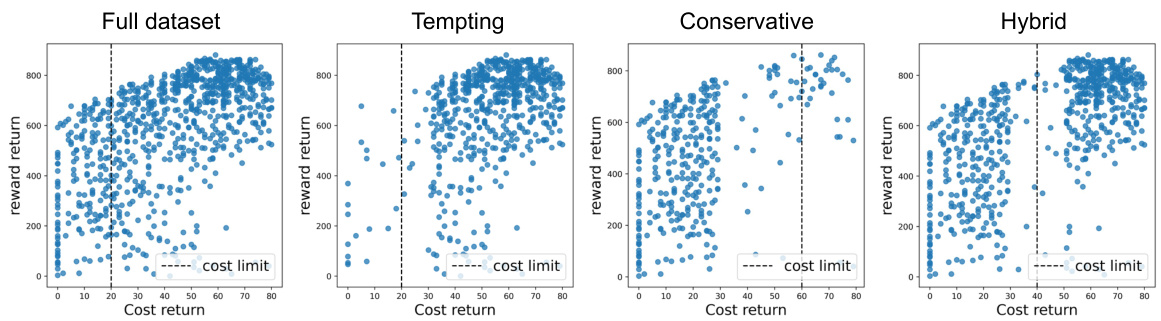
This figure displays four scatter plots visualizing the relationship between cost return and reward return for four different dataset types in the BallCircle task: Full dataset, Tempting dataset, Conservative dataset, and Hybrid dataset. Each point in the scatter plots represents a single trajectory (τ) from the dataset, with its cost return (C(τ)) plotted on the x-axis and reward return (R(τ)) plotted on the y-axis. The plots illustrate how the distribution of cost and reward returns differs across the four dataset types, which are designed to present different characteristics relevant to offline safe reinforcement learning. A dashed vertical line indicates the cost limit (κ).
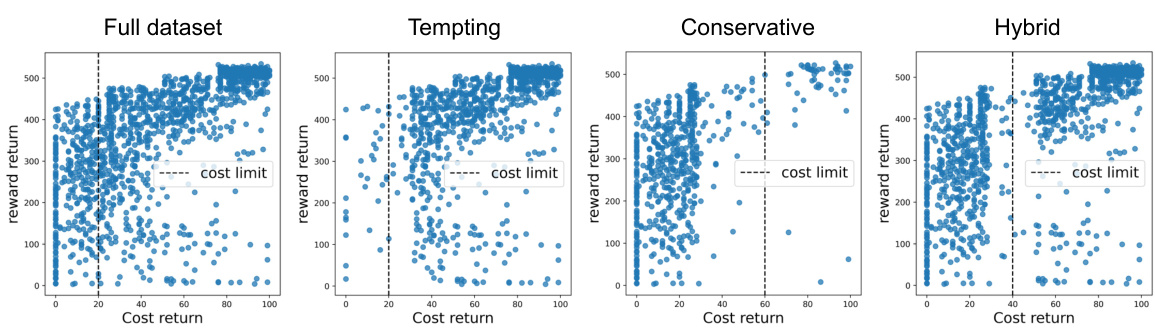
This figure shows the results of a reweighting experiment to mitigate the safe dataset mismatch (SDM) problem. Panel (a) shows the results when comprehensive coverage is present in the dataset; Panel (b) when there is a tempting dataset. (c) summarizes the results of the reweighting experiment, demonstrating its effectiveness. The experiment involves reweighting the dataset to address the SDM problem, improving offline safe RL performance. The experiment uses several datasets, including a full dataset, a tempting dataset, and a conservative dataset.
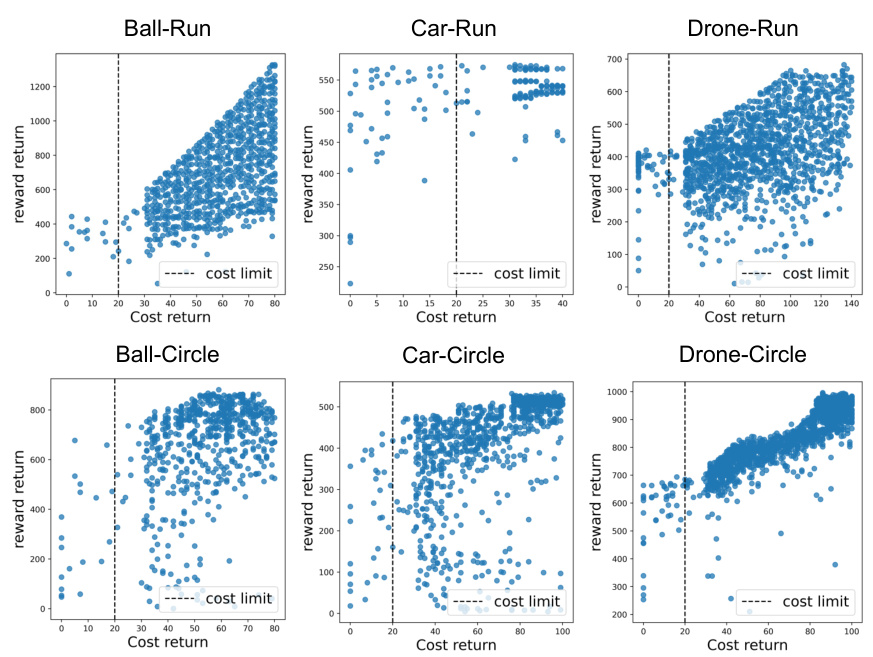
This figure compares the performance of different offline safe reinforcement learning algorithms across various datasets (Full, Conservative, Tempting, Hybrid) and constraint thresholds. It visually demonstrates the impact of dataset composition and safety constraints on algorithm effectiveness. The visualization of the datasets themselves is provided in Appendix B for detailed reference.
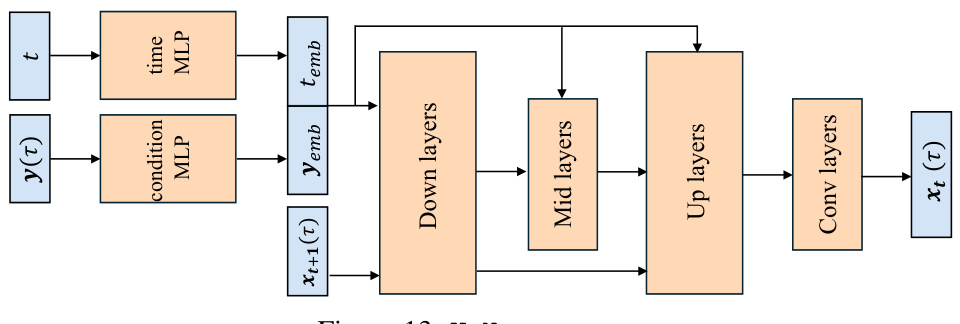
This figure shows the architecture of the U-Net used as the denoising core in the OASIS method. It consists of a series of down-sampling (downsampling) layers that reduce spatial dimensions, followed by mid layers that process the features, and then upsampling (upsampling) layers that increase spatial dimensions. Finally, convolutional (Conv layers) layers transform the processed features into the desired output. The inputs include time embeddings (’temb’) and condition embeddings (‘yemb’) generated by multi-layer perceptrons (MLPs) from the time step and condition information respectively. The output is the denoised trajectory.
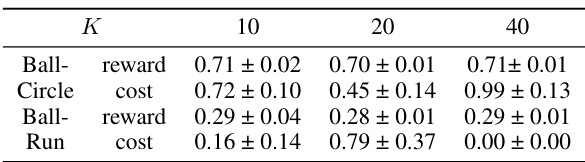
More on tables
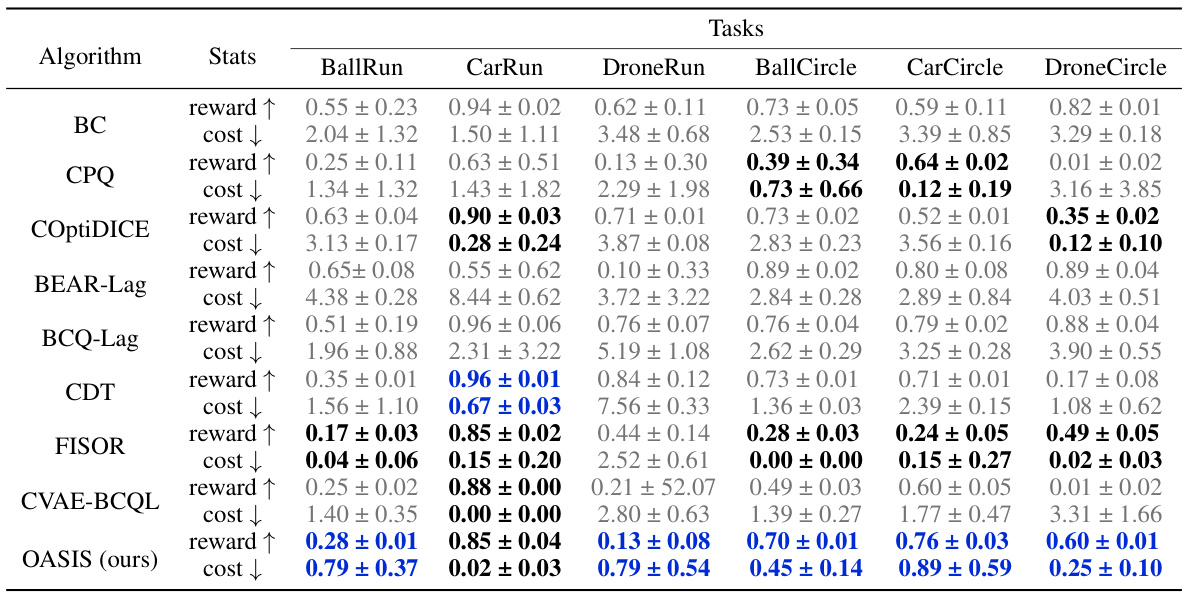
This table presents the performance comparison of different offline safe RL algorithms across various tasks. The algorithms are evaluated based on their normalized reward (higher is better) and normalized cost (lower is better, with a threshold of 1 for safety). The table highlights which algorithms successfully maintain safety (cost ≤1) while achieving high rewards. Results are shown for different robot types performing different tasks (Run and Circle).
This table presents the performance evaluation results of different algorithms on various tasks. The normalized reward and cost are used as metrics. Higher normalized reward indicates better performance, while lower normalized cost (below 1) represents successful constraint satisfaction. The table highlights safe and unsafe agents and identifies the algorithm achieving the best reward among safe agents for each task.
This table presents a quantitative comparison of different offline safe reinforcement learning algorithms across various tasks (BallRun, CarRun, DroneRun, BallCircle, CarCircle, DroneCircle). The performance is evaluated using two metrics: normalized reward (higher is better) and normalized cost (lower is better, with a threshold of 1 indicating constraint satisfaction). The table highlights which algorithms successfully satisfy safety constraints (bold values) and identifies the best-performing safe algorithm for each task.

This table presents the performance comparison of different offline safe RL algorithms on various tasks. The metrics used are the normalized reward and cost. A lower normalized cost (below 1) indicates the algorithm satisfied the safety constraint, shown in bold. The highest reward among safe algorithms is highlighted in blue. Gray indicates unsafe algorithms.
Full paper#