↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating realistic images from arbitrary viewpoints using a single source image is a significant challenge in computer vision. Existing methods, like Zero-1-to-3, while promising, struggle with inconsistencies and implausibilities, especially when handling significant viewpoint changes. These issues often stem from inconsistencies in the attention maps generated during the image synthesis process.
The proposed Zero-to-Hero method tackles these issues by implementing a novel test-time approach to filter and enhance attention maps. By drawing an analogy between the denoising process and stochastic gradient descent, the method iteratively aggregates and averages attention maps, thus improving generation reliability and reducing inconsistencies. Furthermore, Zero-to-Hero incorporates information from the source view, reducing shape distortions. Experiments demonstrated that the technique consistently improves image fidelity, consistency, and geometric accuracy across multiple datasets and various types of objects, achieving significant improvements over baseline methods without the need for additional training.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a novel, training-free method to significantly improve the quality of novel view synthesis. The technique is applicable to various generative models, reducing the need for extensive retraining, and opens avenues for enhancing other image generation tasks. Its test-time approach makes it readily accessible to researchers, simplifying and accelerating research in computer vision and related fields. The improved consistency and realism of generated images have broad applications, impacting fields like e-commerce, AR/VR, and robotics.
Visual Insights#

This figure compares the novel view synthesis results of Zero123-XL and the proposed Zero-to-Hero method. Multiple novel views are generated from a single source image at different angles using both methods. The figure highlights that Zero-to-Hero produces more realistic and faithful results compared to Zero123-XL, while also maintaining variability in the generated outputs.

This table presents a quantitative evaluation of the Zero-to-Hero model on a subset of the Google Scanned Objects (GSO) dataset. The models compared are Zero-1-to-3, Zero123-XL, and the Zero-to-Hero model applied to both. For each model, results are shown for 25, 50, and 100 denoising steps. The metrics used are PSNR, SSIM, LPIPS, and IoU. The bottom rows show oracle results achieved by using ground-truth attention maps.
In-depth insights#
Attn Map Filtering#
The core idea behind ‘Attn Map Filtering’ is to enhance the robustness and reliability of attention maps within a diffusion model for improved image generation. The authors cleverly draw an analogy between the denoising process in diffusion models and stochastic gradient descent (SGD) in neural network training. This analogy allows them to adapt techniques from SGD, such as gradient and weight averaging, to improve the attention map predictions within the diffusion model. The method involves a multi-step filtering process, incorporating both in-step and cross-step map averaging. In-step averaging aggregates attention maps generated within the same denoising step (achieved through a resampling strategy), while cross-step averaging combines attention maps across different denoising steps using an exponential moving average. This filtering mechanism aims to reduce noise and inconsistencies in the attention maps, resulting in more faithful and plausible image generation. The method is notable for being test-time based, meaning it doesn’t require model retraining and adds minimal computational overhead. The effectiveness of ‘Attn Map Filtering’ is extensively demonstrated through experimental results, showcasing significant improvements in geometric consistency and image quality without retraining.
SGD-Diffusion Analogy#
The SGD-Diffusion Analogy section likely explores the conceptual parallels between the iterative weight updates in stochastic gradient descent (SGD) and the denoising process in diffusion models. The core idea is that the denoising process of a diffusion model can be viewed as an unrolled optimization process, analogous to SGD’s iterative refinement of model weights. Each denoising step, guided by attention maps, is compared to an SGD update step guided by gradients. This framework allows researchers to transfer optimization techniques from SGD, such as gradient aggregation and weight averaging, to enhance attention map reliability in diffusion models. This transfer is particularly useful because attention maps play a critical role in latent predictions within the diffusion model. By treating attention maps as parameters and leveraging SGD-inspired filtering mechanisms, the authors aim to improve the robustness and consistency of novel view generation, reducing implausible or inconsistent results that are often observed in diffusion-based image synthesis. This analogy provides a novel test-time approach, enhancing the generation process without requiring model retraining or significant additional computational resources. The success hinges on the effectiveness of the chosen filtering mechanism in aggregating and averaging attention maps to produce more reliable, spatially coherent representations.
View Synthesis Boost#
A hypothetical ‘View Synthesis Boost’ section in a research paper would likely detail advancements in generating novel views of 3D objects from limited input data, such as a single image. The core idea revolves around improving the realism and consistency of synthesized views, addressing common issues like implausible shapes or textures. This might involve novel network architectures, loss functions, or training techniques. A significant focus could be on attention mechanisms, which play a crucial role in directing the model’s focus and generating details. The paper would likely introduce a new approach for manipulating attention maps, potentially enhancing the network’s ability to leverage existing features effectively. The ‘boost’ likely comes from a training-free or computationally inexpensive method that is easily integrated into existing view synthesis pipelines, without requiring extensive re-training or added complexity. The authors would demonstrate this improvement through quantitative metrics and qualitative visual comparisons, showcasing how their method reduces artifacts and generates more realistic results. Benchmarking against state-of-the-art methods would be critical to establish the significance of the ‘boost’. The section would likely conclude by discussing the limitations of the approach and proposing future directions for research.
Zero-Shot Limits#
The heading ‘Zero-Shot Limits’ suggests an exploration of the boundaries and constraints inherent in zero-shot learning. A thoughtful analysis would delve into the inherent limitations of expecting a model to perform well on unseen tasks without any prior training examples. Generalization capabilities are key; how well can a model trained on one set of tasks successfully transfer its knowledge to completely novel, unseen tasks? This section would likely discuss the challenges posed by the lack of task-specific training data which necessitates reliance on broader, more general features for successful zero-shot performance. Domain adaptation would likely be explored, considering how significant differences between training and testing data domains can severely limit zero-shot performance. Furthermore, the role of biases introduced during the training phase—either from the training data itself or the model architecture—must be investigated, analyzing how these biases may negatively impact the model’s ability to perform adequately on zero-shot tasks. Finally, a discussion of the tradeoffs between zero-shot performance and model complexity would be crucial; simpler models might exhibit more limited zero-shot capabilities, while highly complex models might overfit and struggle with generalization. Therefore, a thorough investigation into these ‘Zero-Shot Limits’ is crucial for advancing the field of zero-shot learning.
Future Enhancements#
The paper’s core contribution is a test-time method to improve the realism and consistency of novel view synthesis. Future work naturally focuses on enhancing these core aspects. A promising direction is to replace the current test-time filtering mechanism with trainable filters, potentially using a learnable loss function to guide the optimization process. This shift would necessitate training but could significantly improve the method’s generalization and robustness. Another avenue of exploration is incorporating more sophisticated mechanisms to better enforce pose authenticity; perhaps leveraging techniques beyond cross-attention for a more nuanced understanding of view transformations. Extending the approach to other diffusion-based generative tasks, such as video generation or 3D model synthesis, represents a significant opportunity. This broader applicability would demonstrate the versatility and transferability of the core attention map manipulation technique. Finally, a more thorough investigation into the sampling schedule’s role, perhaps experimenting with adaptive strategies or alternative sampling algorithms, could further optimize the tradeoff between efficiency and visual quality. These enhancements would move beyond test-time manipulations and would involve fundamental algorithmic modifications, aiming for increased reliability, efficiency and broadened capabilities.
More visual insights#
More on figures
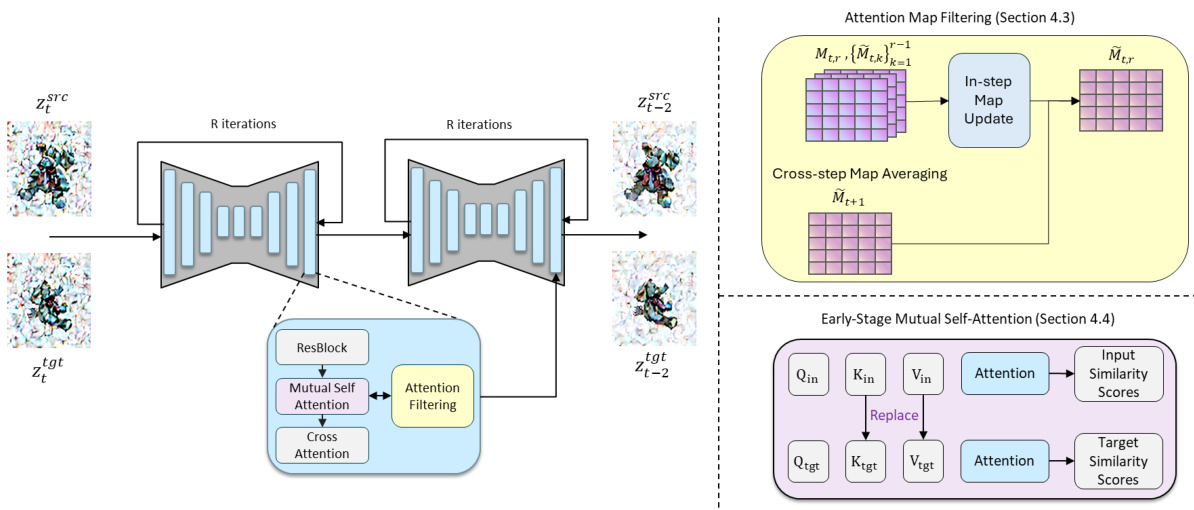
This figure illustrates the main modules of the Zero-to-Hero method. The left panel shows the overall architecture, highlighting the two denoising steps for source and target views, each involving R resampling iterations. The right panel zooms into the two key components: attention map filtering (top right) which enhances robustness by aggregating attention maps across steps, and early-stage mutual self-attention (bottom right) which ensures consistency by incorporating information from the source view into the target view generation.

This figure shows the impact of using ground-truth attention maps in the view synthesis process. By replacing the computed self-attention maps with the ground truth maps, the results show a significant improvement, demonstrating the importance of accurate self-attention maps for robust view generation.
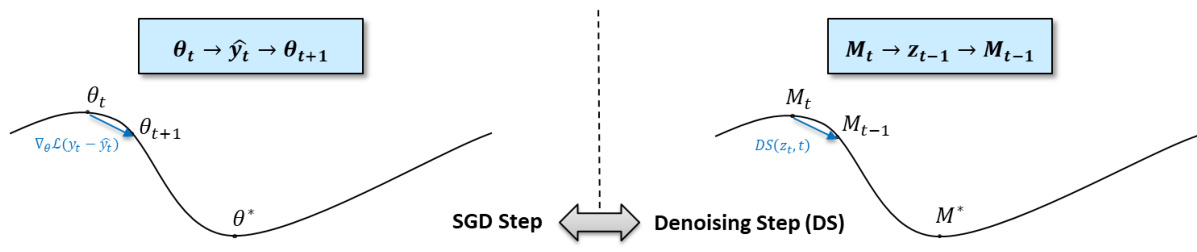
This figure illustrates the conceptual analogy drawn between the weight update process in stochastic gradient descent (SGD) optimization and the attention map update process during the denoising steps in diffusion models. The left side shows a typical SGD step where network parameters (θ) are updated based on the gradient of a loss function. The right side shows the analogous process in diffusion models where attention maps (Mt) are updated based on the denoising process (DS). The analogy highlights that both processes iteratively refine parameters (weights or attention maps) to approach a desirable solution (minimum of loss function or a realistic image).
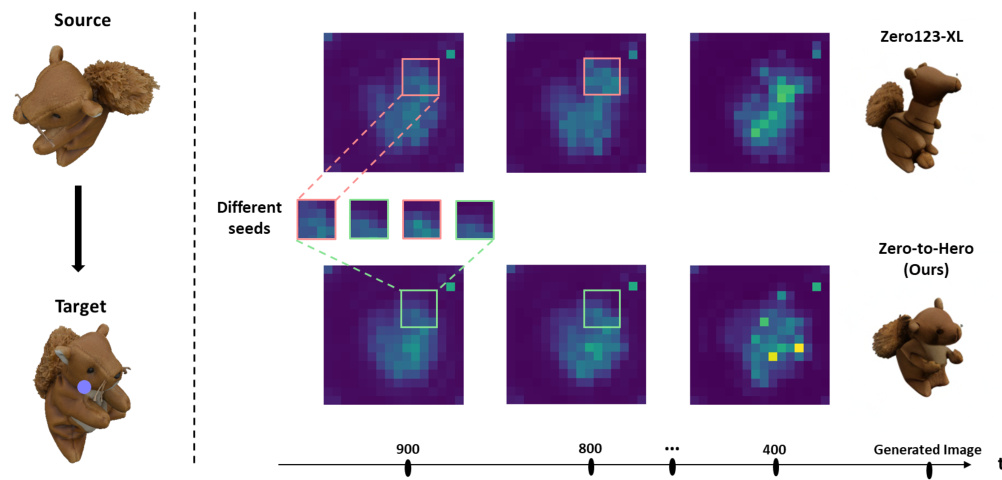
This figure compares attention maps of Zero123-XL and Zero-to-Hero models at different denoising steps. The focus is on a specific region (purple circle) where strong correlations in Zero123-XL’s attention maps lead to unrealistic details (elongated neck). Zero-to-Hero’s attention map filtering mitigates these artifacts and produces more realistic results.

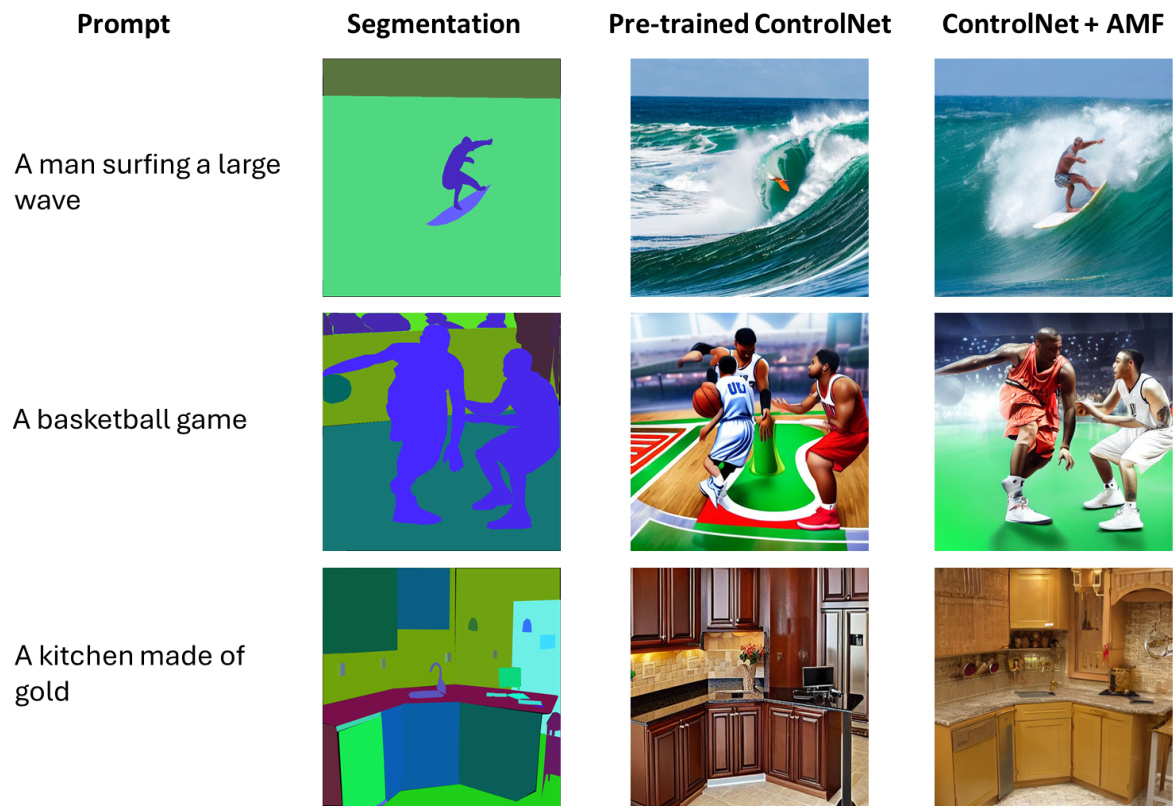
This figure shows a comparison of image generation results using a pre-trained ControlNet model versus ControlNet enhanced with the proposed Attention Map Filtering (AMF) method. The experiment uses three different prompts: ‘Superman flying above the ocean,’ ‘A witch riding her broomstick,’ and ‘A swimmer dives around sharks, wearing a red swimsuit.’ Each prompt is paired with a pose provided as input to the model. The figure demonstrates that the AMF method enhances the quality and realism of the generated images and improves their alignment with the input prompts and pose.

This figure compares the novel view synthesis results of Zero123-XL and the proposed Zero-to-Hero method. The leftmost column shows the single source image used as input. The subsequent columns display several novel views generated by each method at the same target angle, using different random seeds. The far right column shows the ground truth target view. The comparison demonstrates that Zero-to-Hero produces more realistic and faithful novel views while maintaining the authenticity of the original image.
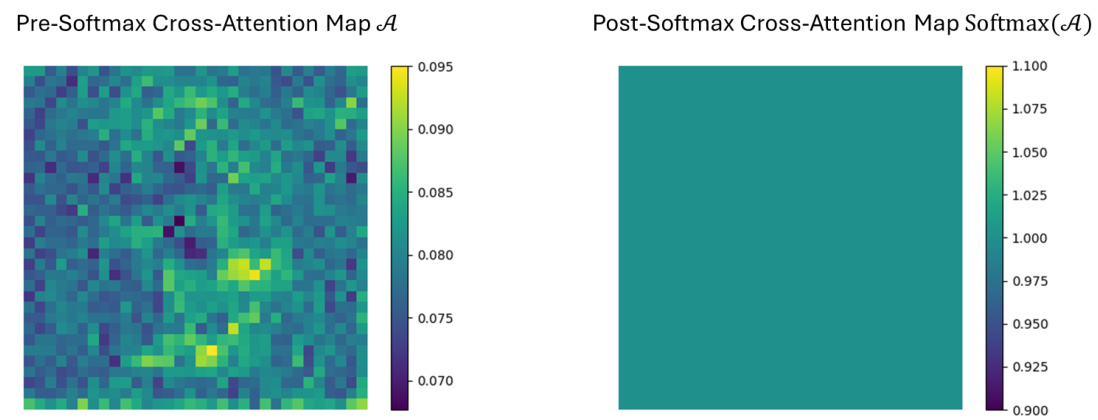
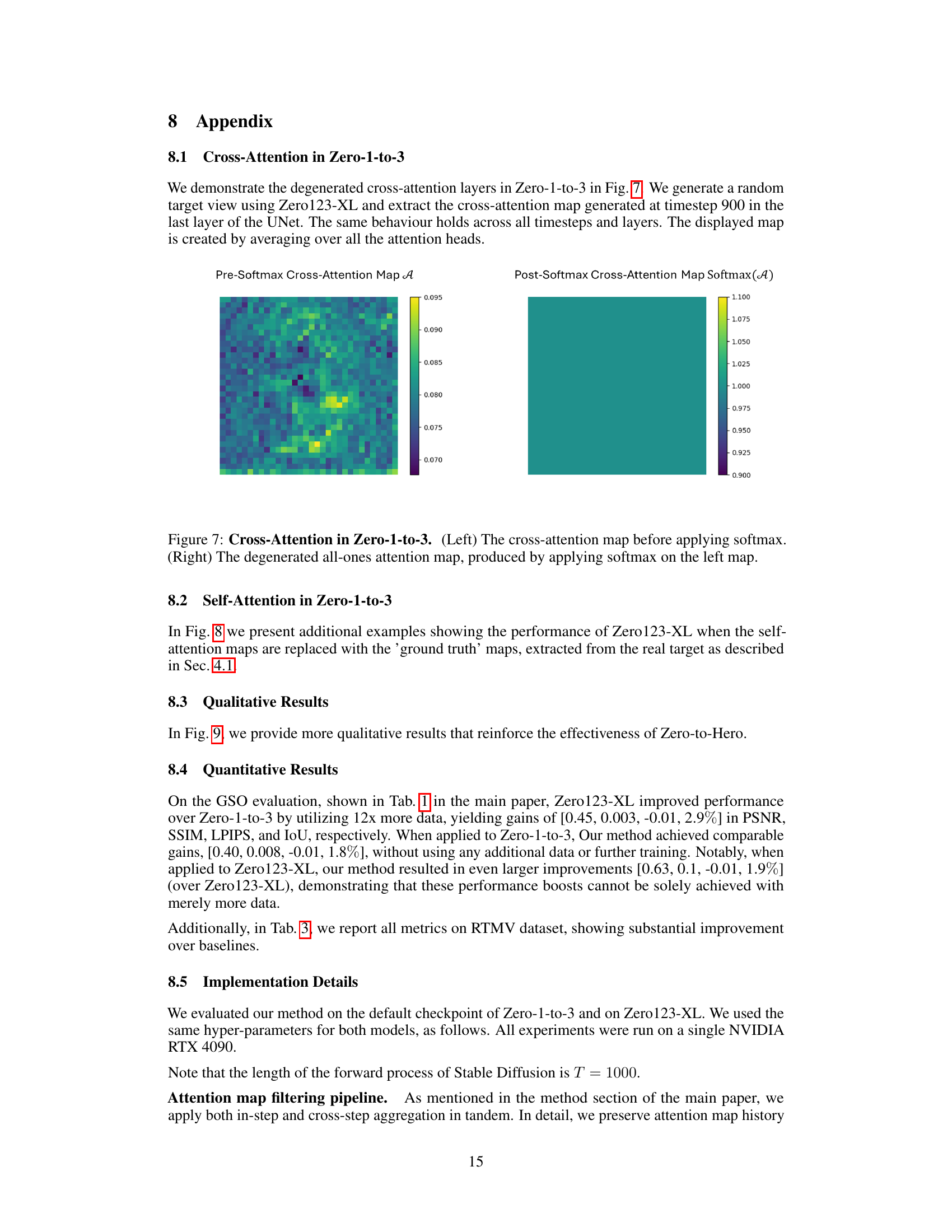
This figure demonstrates the issue of degenerated cross-attention in the Zero-1-to-3 model. The left panel shows the cross-attention map before the softmax function is applied. The right panel shows the map after softmax; it has become a uniform all-ones matrix, losing all spatial information that would normally be encoded in the attention weights. This highlights the key limitation the authors address: the inability of the cross-attention layer to effectively inject spatial information based on pose, preventing accurate control over the shape of the generated image.

This figure shows the results of an experiment where ground-truth attention maps from the target view were injected into the Zero123-XL model during the generation process. The results demonstrate that self-attention maps are crucial for robust view synthesis, as using the ground truth maps leads to significant improvement in image quality. This supports the paper’s claim that manipulating attention maps can significantly enhance the quality of view synthesis.

This figure shows a comparison of novel view synthesis results between the Zero123-XL model and the proposed Zero-to-Hero method. Multiple generated views from a single source image are shown for each method. Zero-to-Hero demonstrates improved fidelity, authenticity, and realistic variations compared to Zero123-XL. The rightmost column shows the ground truth target views.

This figure compares novel view synthesis results from the Zero123-XL model and the proposed Zero-to-Hero method. Given a single source image, both methods generate multiple novel views from a specific target angle using different random seeds. The Zero-to-Hero method shows significantly improved fidelity to the source image while maintaining realistic variations and avoiding artifacts present in the Zero123-XL results. The ground truth target view is included for comparison.
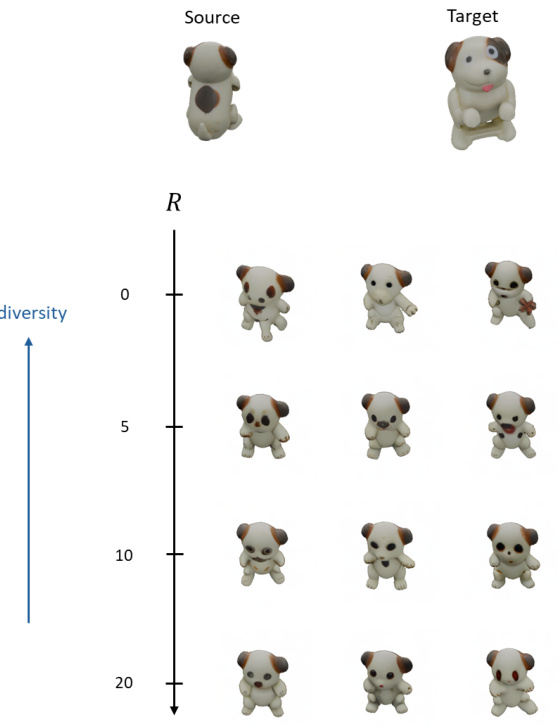
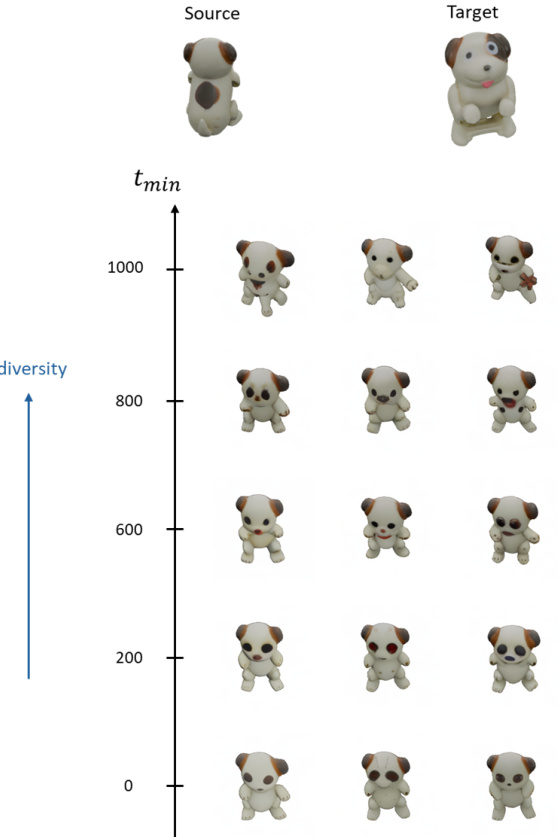
This figure shows the impact of the number of resampling iterations (R) on the diversity of generated images using the Zero-to-Hero method. As R increases, the model becomes more focused, resulting in less diverse but more realistic outputs. This demonstrates a trade-off between diversity and realism controlled by the parameter R, a key aspect of the attention map filtering technique. The experiment uses a challenging viewpoint change to highlight this effect.
This figure shows the comparison of novel view generation results between the Zero123-XL baseline method and the proposed Zero-to-Hero method. Multiple samples are shown for each target angle, demonstrating the improved fidelity, authenticity, and consistency of Zero-to-Hero. The leftmost column shows the input source image, and the rightmost column shows the ground truth target view for comparison. The superior realism and attention to detail in the Zero-to-Hero results are highlighted.
This figure shows a comparison of novel view synthesis results using Zero123-XL, with and without ground-truth (GT) attention maps. The leftmost column displays the source view. The middle column shows Zero123-XL’s results using its own calculated attention maps, while the rightmost column shows the results when the model uses GT attention maps from the target view. The results demonstrate that the self-attention maps play a crucial role in the robustness and quality of view synthesis, as using the GT maps leads to significantly more accurate and realistic results.

This figure compares the novel view synthesis results of the Zero123-XL model and the proposed Zero-to-Hero method. The input source image is shown in the far left column. Multiple synthesized images for each of three different random seeds are presented for both models, demonstrating the variance in their outputs. The ground truth target view is given in the far right column. Zero-to-Hero demonstrates improved fidelity and realism compared to Zero123-XL.
More on tables
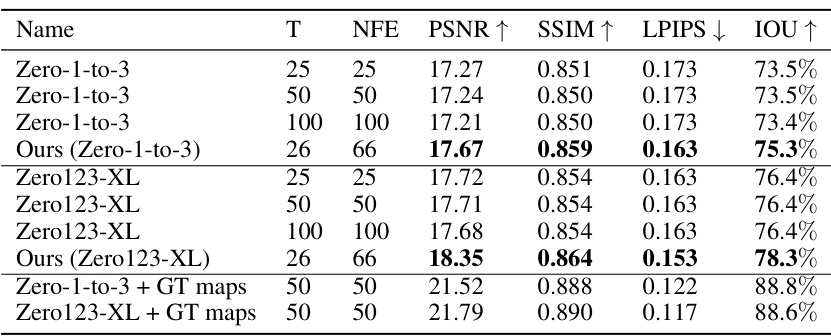
This table presents a quantitative comparison of different novel view synthesis methods on a challenging subset of the Google Scanned Objects (GSO) dataset. The methods compared include Zero-1-to-3, Zero123-XL, and the proposed Zero-to-Hero method, each tested with varying numbers of denoising steps (25, 50, 100). The results are evaluated using four metrics: PSNR, SSIM, LPIPS, and IoU. The bottom rows of the table show the performance using ground truth (GT) attention maps as an upper bound for comparison. The table highlights Zero-to-Hero’s improvement in performance compared to the baseline methods, particularly its advancement towards the performance level achieved with the oracle GT maps.
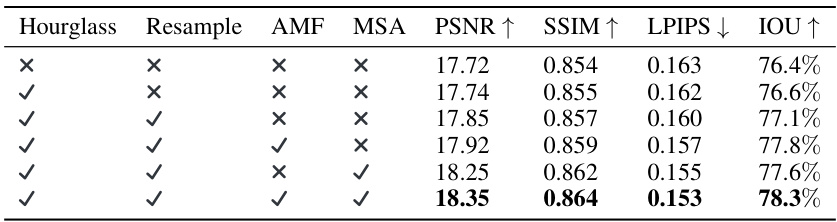
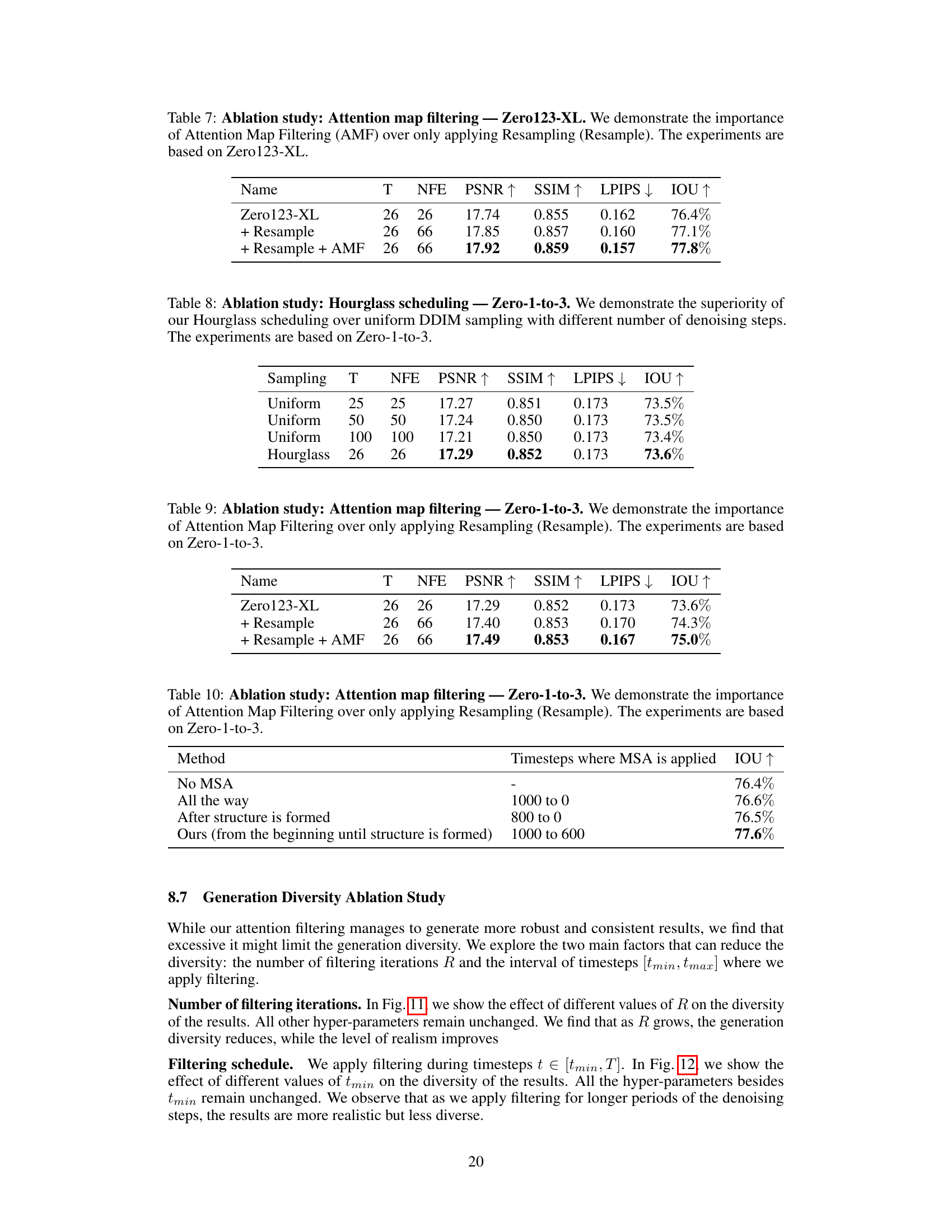
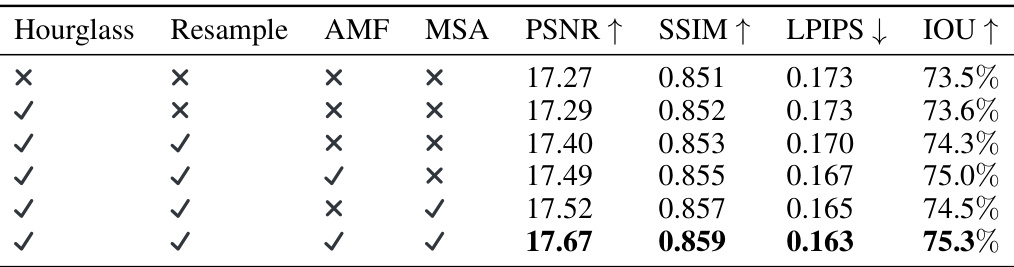
This table presents the ablation study of the Zero-to-Hero model. It shows the impact of each component (Hourglass, Resample, AMF, MSA) on the overall performance when applied to the Zero123-XL model. The results are presented in terms of PSNR, SSIM, LPIPS, and IoU metrics. The study demonstrates that all components contribute to improved performance.
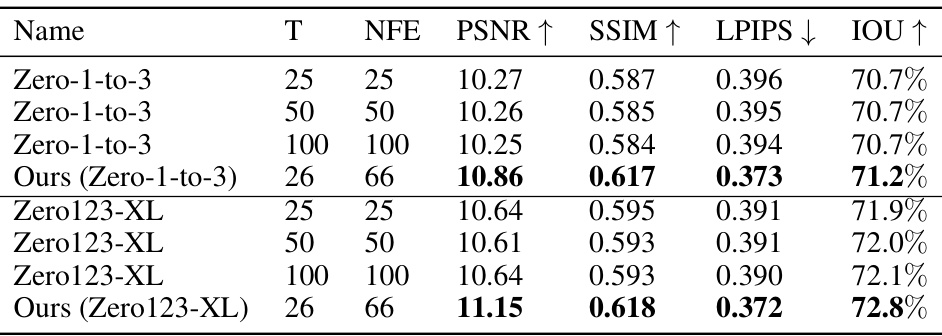
This table presents a quantitative comparison of the performance of Zero-to-Hero against baseline methods (Zero-1-to-3 and Zero123-XL) on the RTMV dataset. The evaluation metrics include PSNR, SSIM, LPIPS, and IoU, calculated for various numbers of denoising steps (T) and function evaluations (NFE). The results demonstrate that Zero-to-Hero consistently outperforms the baseline methods across all metrics.
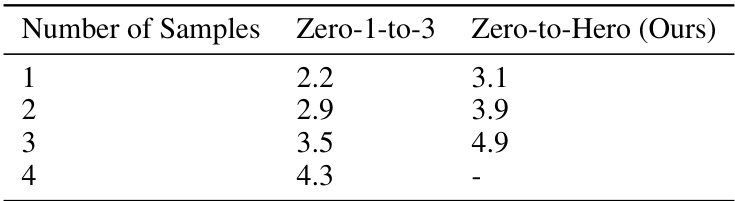
This table shows a runtime analysis comparing the computational overhead introduced by the Zero-to-Hero method against the base model Zero-1-to-3. It demonstrates how the inference time scales with the number of generated samples, showing that the increase in runtime is relatively modest compared to the improvement in image quality.
This table presents a quantitative evaluation of the Zero-to-Hero model on a challenging subset of the Google Scanned Objects (GSO) dataset. It compares the performance of Zero-to-Hero against two baseline models (Zero-1-to-3 and Zero123-XL) across four metrics: PSNR, SSIM, LPIPS, and IoU. The table shows the number of sampled timesteps (T) and the total number of network function evaluations (NFE) for each model. The results demonstrate that Zero-to-Hero consistently outperforms the baselines, achieving a substantial improvement in all metrics, and making significant progress towards the performance of a hypothetical model with access to ground-truth attention maps.
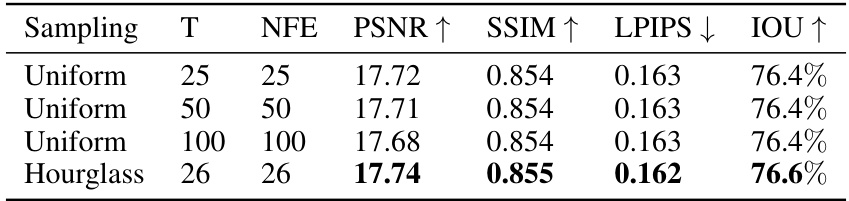
This table presents an ablation study comparing the performance of different sampling schedules within the Zero123-XL model. It contrasts uniform DDIM sampling with varying numbers of steps (25, 50, and 100) against the proposed Hourglass scheduling (26 steps). The Hourglass method is shown to improve or match the performance of uniform sampling using fewer steps, highlighting its efficiency in novel view synthesis.

This table presents the ablation study of the proposed Zero-to-Hero method. It systematically evaluates the impact of each of its components—Hourglass scheduling, resampling, attention map filtering (AMF), and early-stage mutual self-attention (MSA)—on the performance of the Zero123-XL model. The results show the contribution of each module to the final performance improvement. The study also notes that consistent conclusions were obtained when applying the same analysis to the Zero-1-to-3 model.
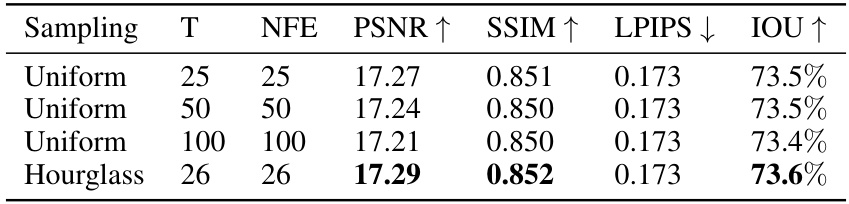
This table presents an ablation study comparing different sampling strategies (uniform vs. Hourglass) used in the Zero123-XL model. It shows the impact of the proposed Hourglass scheduling scheme on the performance of the model, measured by PSNR, SSIM, LPIPS, and IoU metrics. The results demonstrate the effectiveness of the Hourglass scheduler in improving the efficiency and overall performance of the model compared to uniform sampling. The number of sampled timesteps and network function evaluations (NFE) are also reported for each sampling method.

This ablation study systematically evaluates the contribution of each component of the Zero-to-Hero method when applied to the Zero-1-to-3 model. It shows the impact of each module individually and in combination, measuring performance improvements using PSNR, SSIM, LPIPS, and IoU metrics. The results highlight the relative importance of each component in enhancing the overall quality of novel view synthesis.

This table presents the ablation study of applying the Attention Map Filtering (AMF) module of the Zero-to-Hero method to the baseline Zero-1-to-3 model. The study compares the Intersection over Union (IOU) metric for four different settings: without AMF, with only resampling, with AMF and with both AMF and resampling. The results demonstrate the importance of including both the resampling and the AMF modules for improved performance. The timesteps where mutual self-attention (MSA) is applied are indicated for each method. This shows the effectiveness of AMF alone and in tandem with resampling in improving the results.
Full paper#