↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current machine learning often struggles with the difficulty of reusing pre-trained models across different users and tasks, particularly when models are built with different features or data. The learnware paradigm aims to address this by managing and reusing high-performing models through a “learnware dock” system. However, existing approaches mainly focus on homogeneous feature spaces, hindering the efficient use of diverse models. This poses a challenge in real-world scenarios where models with varying features are readily available.
This research introduces a novel method to address the limitations of existing learnware systems. It extends the model specification to better leverage label information, specifically model outputs. This enhancement allows for the creation of a more unified and coherent embedding space, improving learnware identification and accommodation of models with heterogeneous feature spaces. The experimental results demonstrate the effectiveness of the proposed approach, showing that the system can effectively handle user tasks by leveraging models from diverse feature spaces, even without a model directly tailored to a specific user task.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on learnware systems and heterogeneous model management. It offers a novel solution to leverage models with diverse feature spaces, which is a common challenge in real-world applications. The explicit use of label information significantly improves the system’s ability to identify and utilize these diverse models, opening up new research avenues in areas like cross-domain model reuse and improving the efficiency of machine learning.
Visual Insights#

This figure illustrates how different feature engineering approaches can lead to heterogeneous models within a clinical database (OMOP Common Data Model). Experts might use different subsets of standardized tables (person, diagnose, laboratory, drug) to build models for a task like drug safety analysis. This results in models with varying feature spaces, requiring a mechanism to manage and leverage them effectively. The example highlights the challenges of the learnware paradigm in real-world scenarios where feature spaces are not always homogenous.
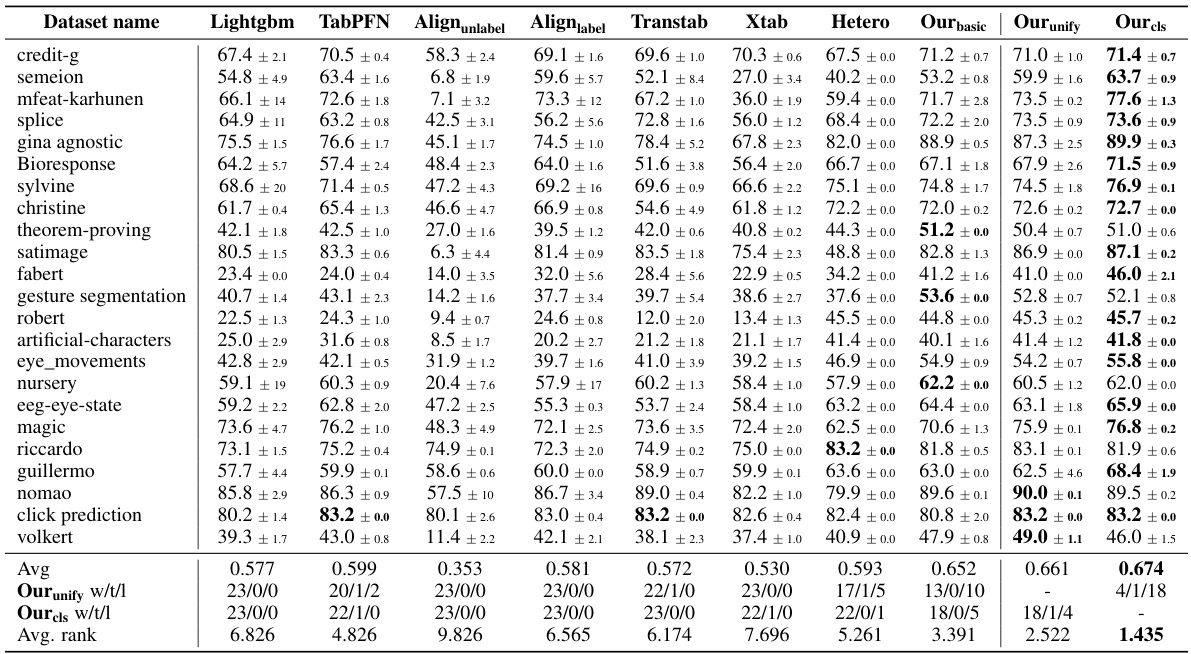
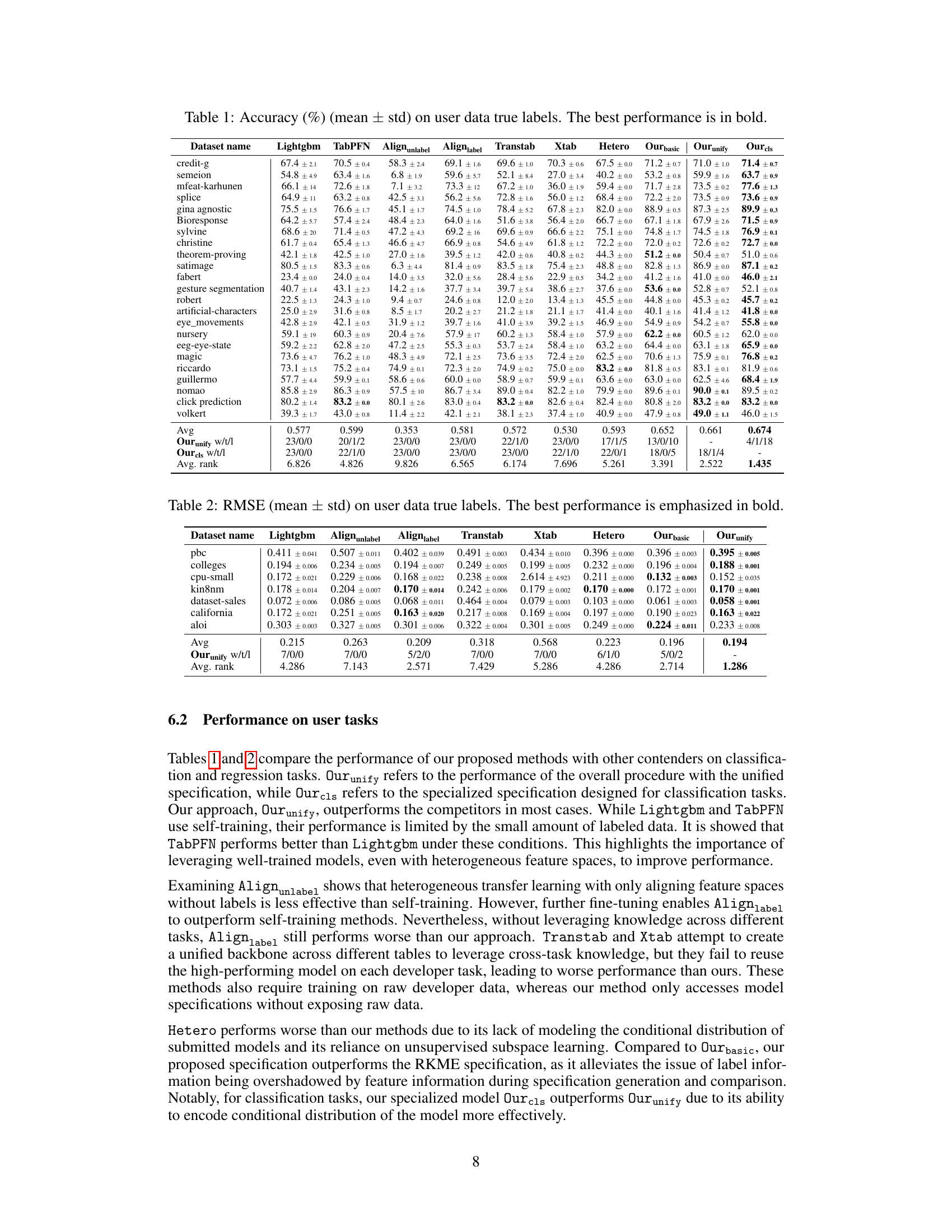
This table presents the accuracy results for classification tasks. It compares the performance of the proposed methods (Ourbasic, Ourunify, Ourcls) against several baseline methods (Lightgbm, TabPFN, Alignunlabel, Alignlabel, Transtab, Xtab, Hetero) across various datasets. The best-performing method for each dataset is highlighted in bold. The ‘Ourunify w/t/l’ and ‘Ourcls w/t/l’ rows show the number of wins, ties, and losses for each method across all datasets.
In-depth insights#
Learnware Paradigm#
The learnware paradigm represents a paradigm shift in machine learning, moving away from the traditional approach of building models from scratch. It focuses on leveraging pre-trained, high-performing models (’learnwares’) stored in a centralized repository. Each learnware includes not only the model itself, but also a comprehensive specification describing its capabilities and limitations. This allows for efficient reuse and adaptation of existing models to solve new tasks, even when those tasks differ in feature space or domain. Key advantages include reduced development time and cost, increased model accessibility for users without deep expertise, and improved data privacy, as raw data is not necessarily required for model reuse. However, challenges remain in effectively handling heterogeneous learnwares (models with different feature spaces) and efficiently matching user tasks with the most appropriate learnwares from a large, diverse repository. The paper focuses on addressing these challenges through label exploitation, specifically model outputs, to better manage and identify suitable models for diverse user tasks.
Label Exploitation#
The concept of ‘Label Exploitation’ in the context of handling learnwares from heterogeneous feature spaces centers on leveraging readily available label information, specifically model outputs, to improve learnware identification and unified embedding space creation. Without explicit use of labels, subspace learning can produce entangled embeddings, hindering effective learnware matching. The authors extend learnware specifications to encode both marginal and conditional distributions using pseudo-labels. This supervised approach enhances subspace learning, leading to more accurate embeddings and improved model identification, even when dealing with models from diverse feature spaces. Crucially, the method avoids direct use of raw data, preserving privacy while achieving superior results compared to unsupervised approaches. The integration of labels bridges the gap between heterogeneous feature spaces, empowering a more robust and efficient learnware dock system.
Unified Subspace#
The concept of a “Unified Subspace” in the context of handling learnwares from heterogeneous feature spaces is crucial for effective model reuse. It addresses the challenge of integrating models trained on different feature sets by creating a common, shared representation space. This unified subspace enables comparison and combination of models regardless of their original feature engineering, facilitating effective model recommendation and task completion even when a perfectly matching model is unavailable. The creation of this subspace is a key technical challenge, requiring careful consideration of feature weighting, dimensionality reduction, and the preservation of important discriminative information. The success of the unified subspace approach hinges on its ability to effectively capture the essential characteristics of different feature spaces while minimizing information loss and avoiding the entanglement of class representations. The integration of label information further enhances the effectiveness of this subspace by enabling supervised learning methods that can more accurately capture the relationships between feature spaces and model predictions.
Heterogeneous Models#
The concept of “Heterogeneous Models” in machine learning signifies the challenge of integrating models trained on different feature spaces or using varying architectures. This heterogeneity arises from diverse data sources, preprocessing techniques, or feature engineering choices, making direct comparison or ensemble creation difficult. The core issue revolves around finding effective methods for aligning or integrating these disparate models to leverage their collective knowledge. This might involve techniques like subspace learning to find a common representation, or sophisticated weighting schemes to combine predictions. Successful strategies necessitate careful consideration of label information, particularly when dealing with weak correlations between feature spaces. The ability to effectively incorporate label information into the model integration process is paramount to achieving accurate and robust predictions. Furthermore, privacy considerations must be addressed. Any approach needs to manage model integration without compromising the confidentiality of the underlying training data. Ultimately, effective management of heterogeneous models is crucial for building real-world applications that can adapt and learn from a variety of data sources, and requires careful model selection and integration techniques.
Future Directions#
Future research could explore extending the learnware paradigm to handle heterogeneous label spaces, where models may predict different types of labels. Another promising direction involves developing more sophisticated methods for specification generation and evolution, potentially incorporating techniques from automated machine learning or meta-learning. Improving the efficiency and scalability of the subspace learning algorithms used to accommodate heterogeneous feature spaces is also crucial, particularly when dealing with a massive number of learnwares. Research should investigate more advanced techniques for matching models to user tasks, possibly leveraging advanced similarity metrics or incorporating contextual information. Finally, rigorous evaluations on diverse real-world datasets are necessary to better understand the capabilities and limitations of the learnware paradigm in practical settings and to assess its broader societal impact.
More visual insights#
More on figures
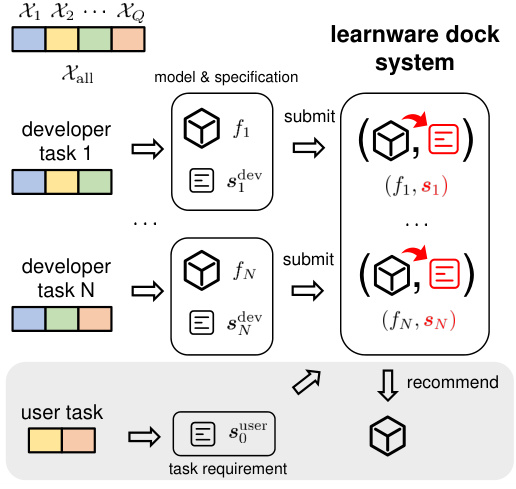
This figure illustrates the workflow of a learnware dock system. Developers submit their models and specifications (developer task 1 to N), which are then accommodated by the system. The system generates a system-level specification for each model and stores them as learnwares. Users submit their task requirements (user task) and the system recommends the most helpful model(s) for reuse, leveraging models from diverse feature spaces even if no model is explicitly tailored to the user’s task.

The figure shows five models with uniform distributions, four with circular support sets and one with a square support set. It illustrates that matching models solely on marginal distributions is insufficient, as models with the same marginal distribution can have different conditional distributions and thus be unsuitable for certain user tasks. Additionally, it highlights how models with different marginal distributions, but similar conditional distributions, are overlooked when using only marginal distributions for model selection. The figure emphasizes the importance of incorporating conditional distributions and label information to improve model matching.

This figure displays the performance of the proposed ensemble method compared to self-training on several classification datasets. The x-axis represents the number of labeled data points used, and the y-axis represents accuracy or RMSE (Root Mean Squared Error), depending on whether it is a classification or regression task. The plots show that the ensemble method generally outperforms self-training, especially when the number of labeled data points is low. The performance difference between the methods tends to decrease as the number of labeled data points increases. The figure also includes a panel that shows the win ratio (percentage of tasks where the ensemble method outperformed self-training) and dataset count for different ranges of labeled data.
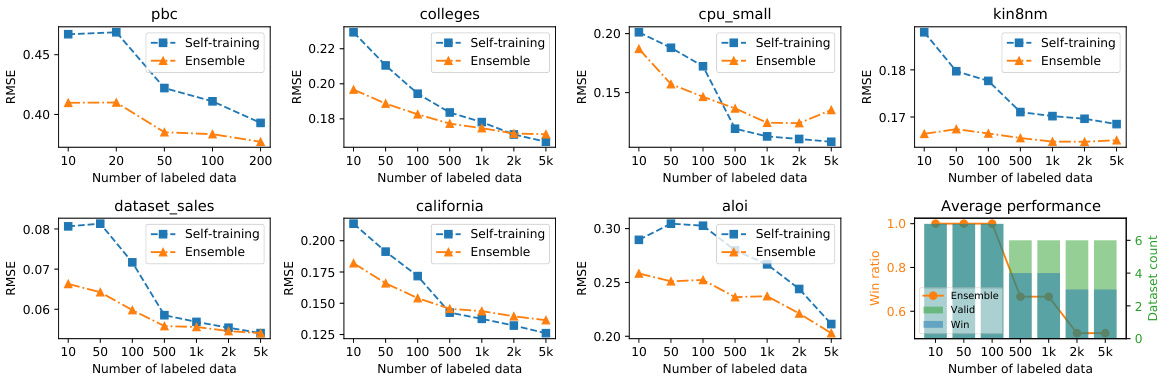
The figure shows the performance comparison between self-training and ensemble methods on several classification tasks with varying numbers of labeled data points. It illustrates how the ensemble approach using the learnware dock system consistently outperforms self-training, especially when limited labeled data is available. The results highlight the effectiveness of leveraging pre-trained models from the learnware dock even with limited labeled user data.

This figure illustrates the two main processes involved in generating the RKME₁ specification and user requirements. For specification generation, it begins with original data which is input into a model to generate pseudo-labeled data. The pseudo-labeled data is then used to create a reduced set by sketching the marginal distribution Px. A further step, currently only supporting classification, is to use the model to sketch the conditional distribution Px|Y, resulting in a labeled reduced set. In requirement generation, the process begins with user data. For regression, the process involves sketching the marginal distribution Px to obtain a reduced set. For classification, the process includes sketching both Px and Px|Y using a model trained on the user’s data to generate a labeled reduced set.

This figure displays the performance of self-training versus ensemble methods on classification tasks using different amounts of labeled data. It shows that the ensemble method consistently outperforms self-training, even with larger amounts of labeled data. The performance is broken down by dataset to highlight the differences in performance across datasets.
More on tables
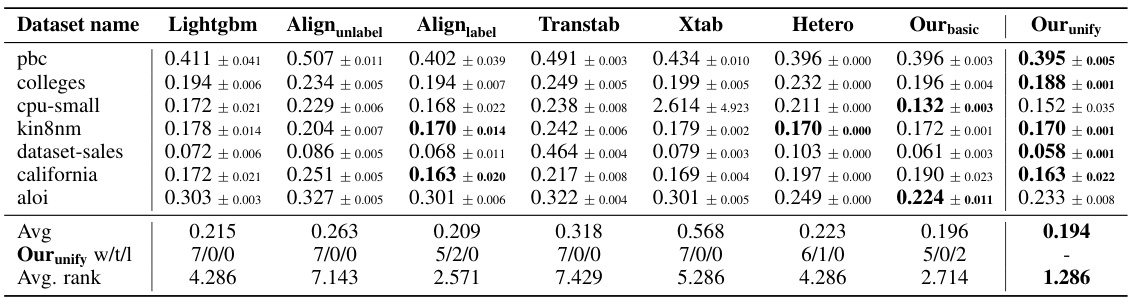
This table presents the Root Mean Squared Error (RMSE) achieved by different methods on regression tasks using true labels from user data. Lower RMSE values indicate better performance. The results are averaged over multiple trials, and standard deviations are included to show variability. The best performing method for each dataset is highlighted in bold.

This table presents the average accuracy (with standard deviation) achieved by different methods on user data for various classification tasks. The methods compared include LightGBM, TabPFN, Alignunlabel, Alignlabel, Transtab, Xtab, Hetero, Our basic, Our unify, and Our cls. The best performing method for each task is highlighted in bold. This allows for a comparison of the proposed methods against existing techniques and variations of the proposed approach, showing the impact of different design choices on performance.

This table presents the details of the 23 classification datasets used in the experiments. For each dataset, it shows the number of classes, the number of features, and the total number of instances.

This table presents the details of seven regression datasets used in the experiments. For each dataset, the number of classes, the number of features, and the number of instances are provided. All datasets have only one class, but vary significantly in the number of features and instances. This information is crucial for understanding the scale and characteristics of the data used in the evaluation of the proposed learnware approach.

This table presents the accuracy (mean ± standard deviation) achieved on the user’s data true labels for various classification tasks. Different methods are compared: LightGBM, TabPFN, Alignunlabel, Alignlabel, Transtab, Xtab, Hetero, Ourbasic, Ourunify, and Ourcls. The best performing method for each task is highlighted in bold. The table also provides the average accuracy across all tasks for each method and a win count (number of times a method achieved the best performance).

This table shows the RMSE results of ablation study on regression tasks. The ablation study progressively adds loss functions (contrastive, reconstruction, supervised) to evaluate their individual and combined effects on the model’s performance. The results demonstrate that incorporating all three loss functions yields the best performance (lowest RMSE).
Full paper#