↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current language models struggle to understand large tables due to context-length constraints. Existing methods often feed the entire table to the model, leading to inefficiency and degraded reasoning. This issue is compounded by the lack of large-scale benchmarks for evaluating such methods.
TableRAG solves this by using a Retrieval-Augmented Generation (RAG) approach. It leverages query expansion, schema retrieval, and cell retrieval to pinpoint crucial information before giving it to the language model. This significantly reduces prompt lengths, improves retrieval quality and achieves superior performance on two newly developed million-token benchmarks, ArcadeQA and BirdQA, demonstrating scalability and state-of-the-art results.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large-scale tabular data and language models. It addresses the critical challenge of scalability in table understanding, offering a novel approach that achieves state-of-the-art performance. The introduced benchmarks and analysis of token complexity are valuable resources for future research in this area, opening new avenues for efficient and effective large-scale table question answering.
Visual Insights#
This figure compares different table prompting techniques used with Language Models (LMs) for table understanding tasks. It shows how different methods (Read Table, Read Schema, Row-Column Retrieval, and Schema-Cell Retrieval (TableRAG)) handle the input data and their efficiency. TableRAG, the proposed method, is highlighted for its superior performance in both column and cell retrieval, which leads to better overall table reasoning.
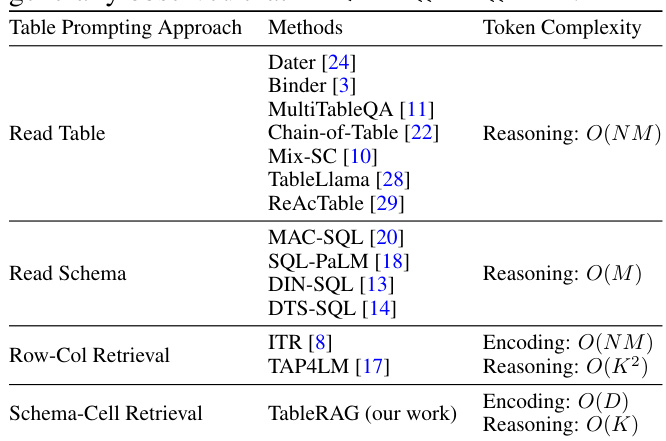
This table compares the token complexity of different table prompting approaches used in large language models for table understanding tasks. It breaks down the complexity into encoding and reasoning components, showing how the number of rows (N), columns (M), top retrieval results (K), and distinct values (D) impact the overall complexity. The table highlights the significant difference in complexity between methods that read the entire table and methods that utilize retrieval techniques to reduce the amount of data processed by the LM.
In-depth insights#
Million-Token Tables#
The concept of “Million-Token Tables” in research signifies a significant challenge and opportunity in natural language processing. Traditional language models struggle with tables exceeding their context window, limiting their ability to reason effectively with large datasets. This limitation necessitates innovative approaches like retrieval-augmented generation (RAG), which selectively retrieves relevant parts of the table based on the query. Handling million-token tables requires efficient encoding methods that reduce the information bottleneck. This could involve focusing on crucial columns and cells or using techniques like sparse embedding, effectively capturing semantic meaning while minimizing memory usage. Furthermore, developing benchmarks with million-token tables is essential for evaluating the scalability and performance of these new approaches. These benchmarks provide a crucial testbed for pushing the boundaries of language model capabilities in handling complex tabular data and could lead to breakthroughs in various fields that rely on large-scale data analysis.
Retrieval-Augmented Gen#
Retrieval-Augmented Generation (RAG) represents a powerful paradigm shift in how large language models (LLMs) interact with external knowledge. Instead of relying solely on their internal knowledge, RAG systems augment LLMs by retrieving relevant information from external sources like databases or the web. This approach offers several key advantages. First, it significantly enhances the factual accuracy and reliability of LLM outputs, as responses are grounded in real-world data. Second, it allows LLMs to handle tasks that demand access to up-to-date information or specialized knowledge bases which are beyond the scope of their training data. The retrieval process itself can be sophisticated, using techniques like semantic search or knowledge graph traversal to pinpoint the most relevant information. Moreover, by only providing the most pertinent information to the LLM, RAG systems mitigate the limitations of context windows and computational costs associated with processing large amounts of text. However, the effectiveness of RAG hinges critically on the quality and relevance of the retrieved information and the ability to seamlessly integrate it with the LLM’s generation process. Poor retrieval strategies or clumsy integration will undermine the benefits of the approach. Future research could explore more advanced retrieval strategies, improved methods for integrating retrieved information, and techniques to evaluate and improve the overall performance of RAG systems.
Benchmark Datasets#
A robust benchmark dataset is crucial for evaluating the performance of table understanding models. Ideally, a benchmark should encompass a diverse range of table structures, including variations in size, complexity, and data types. The choice of existing datasets versus creating novel ones depends on the research goals; leveraging existing datasets allows for direct comparison with state-of-the-art models, while developing new benchmarks enables targeted evaluations of specific aspects or challenges. Consideration must be given to data licensing and accessibility, ensuring that the dataset is readily available to the research community. Further, representative questions and associated answers are essential, reflecting realistic scenarios and avoiding biases that could favor certain algorithms. The evaluation metrics should be meticulously chosen and clearly defined, aligning with the research objectives and encompassing both quantitative and qualitative aspects. A well-designed benchmark dataset drives progress in the field by promoting fair comparisons and facilitating the development of more robust and generalizable table understanding models.
Scalability Analysis#
A thorough scalability analysis of a large language model (LLM) for tabular data would explore its performance across varying table sizes, complexities, and data types. Key aspects would include evaluating the computational cost (time and memory) as table dimensions increase, assessing the impact on inference latency, and measuring accuracy degradation. It’s crucial to examine the model’s ability to handle diverse data distributions within tables, such as different data types (numeric, categorical, text), and missing values. The analysis should distinguish between the costs of model training and inference, as the former is typically a one-time expense while the latter affects real-time performance. Benchmark datasets are essential for validating scalability claims, ensuring comprehensive evaluation across a range of scenarios. A well-designed experiment would include tests with both real-world and synthetic data, and compare the LLM’s performance against other approaches, such as traditional database querying systems or rule-based methods. Finally, a discussion of limitations is essential, acknowledging any constraints on the model’s ability to scale to exceptionally large tables or complex data structures. The insights drawn from this analysis are crucial for understanding the applicability of LLMs for real-world tabular data tasks, especially in big data contexts.
Future Directions#
Future research could explore extending TableRAG’s capabilities to handle even larger and more complex tables, potentially involving distributed processing techniques to overcome memory limitations. Investigating how TableRAG interacts with other multimodal data beyond tabular information (images, text, etc.) would be valuable. A key area for improvement is robustness to noisy or incomplete data, which is common in real-world scenarios. Evaluating performance on diverse table schemas and data types is also crucial, as is exploring methods to improve efficiency by reducing computational costs. Finally, focusing on enhancing the explainability of TableRAG’s reasoning process will be important to build trust and facilitate wider adoption.
More visual insights#
More on figures
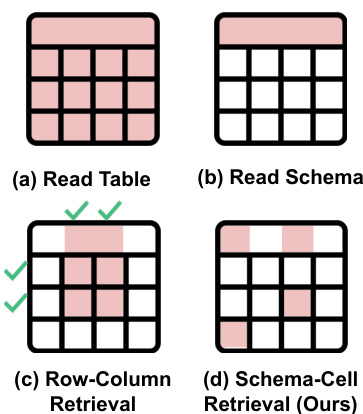
This figure compares different table prompting techniques used with Language Models (LMs) for table understanding. It shows that simply reading the whole table is not feasible for large tables due to context length limits. Reading only the schema loses information, while row/column retrieval is still computationally expensive for large tables. The proposed approach, Schema-Cell Retrieval (TableRAG), only retrieves relevant schema and cells for efficient and accurate processing.
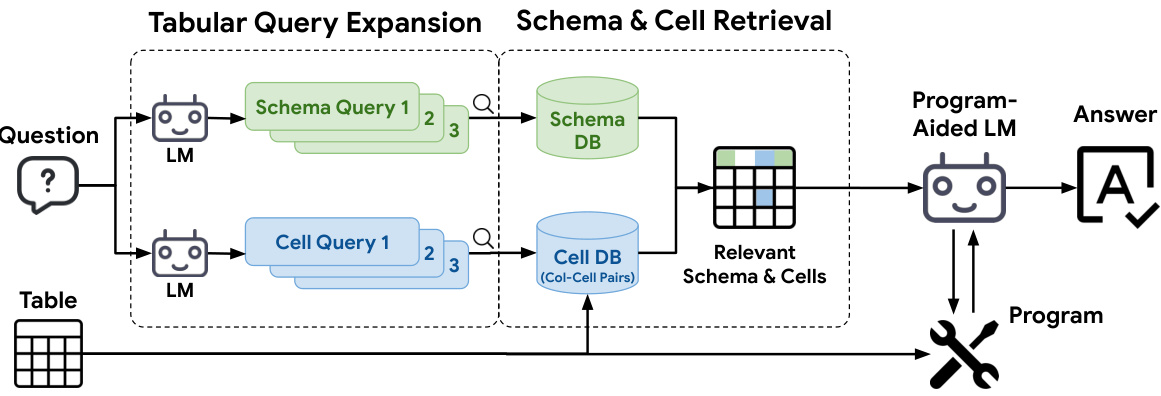
This figure illustrates the workflow of the TableRAG framework. It starts with a question, which is processed by an LM to generate schema and cell queries. These queries are then used to query pre-built schema and cell databases, retrieving the top K results for each. The retrieved schema and cell information are then combined and sent to a program-aided LM, which uses the information to generate a program to answer the question. The process is iterative, involving multiple rounds of query generation and retrieval until a final answer is reached. Algorithm 1 and Figure 8 in the paper provide more details.

This histogram shows the ratio of the number of distinct values to the total number of cells in tables from the ArcadeQA and BirdQA datasets. The data demonstrates that in most tables, the number of unique cell values is significantly smaller than the total number of cells. This observation supports the efficiency of TableRAG’s cell retrieval method, which only encodes distinct values, significantly reducing the computational cost compared to methods that encode all cells.

This figure shows the performance of different table prompting methods (ReadTable, ReadSchema, RandRowSampling, RowColRetrieval, and TableRAG) on a synthetic dataset derived from TabFact with varying table sizes. The x-axis represents the synthetic table size, increasing from the original size to 1000. The y-axis shows the accuracy of each method. TableRAG consistently outperforms other methods across all table sizes, demonstrating its scalability and robustness. The accuracy of other methods decreases significantly with increasing table size, highlighting the scalability challenge of traditional methods when dealing with large tables.

This figure compares the performance of three different table prompting methods (TableRAG, RandRowSampling, and RowColRetrieval) across various prompt lengths, which are directly influenced by the number of top retrieval results (K). It shows that TableRAG maintains higher accuracy with fewer tokens compared to others. Increasing K values increase prompt length but do not always correlate with higher accuracy, especially for RandRowSampling and RowColRetrieval, which indicates that TableRAG’s selective retrieval strategy is more efficient.

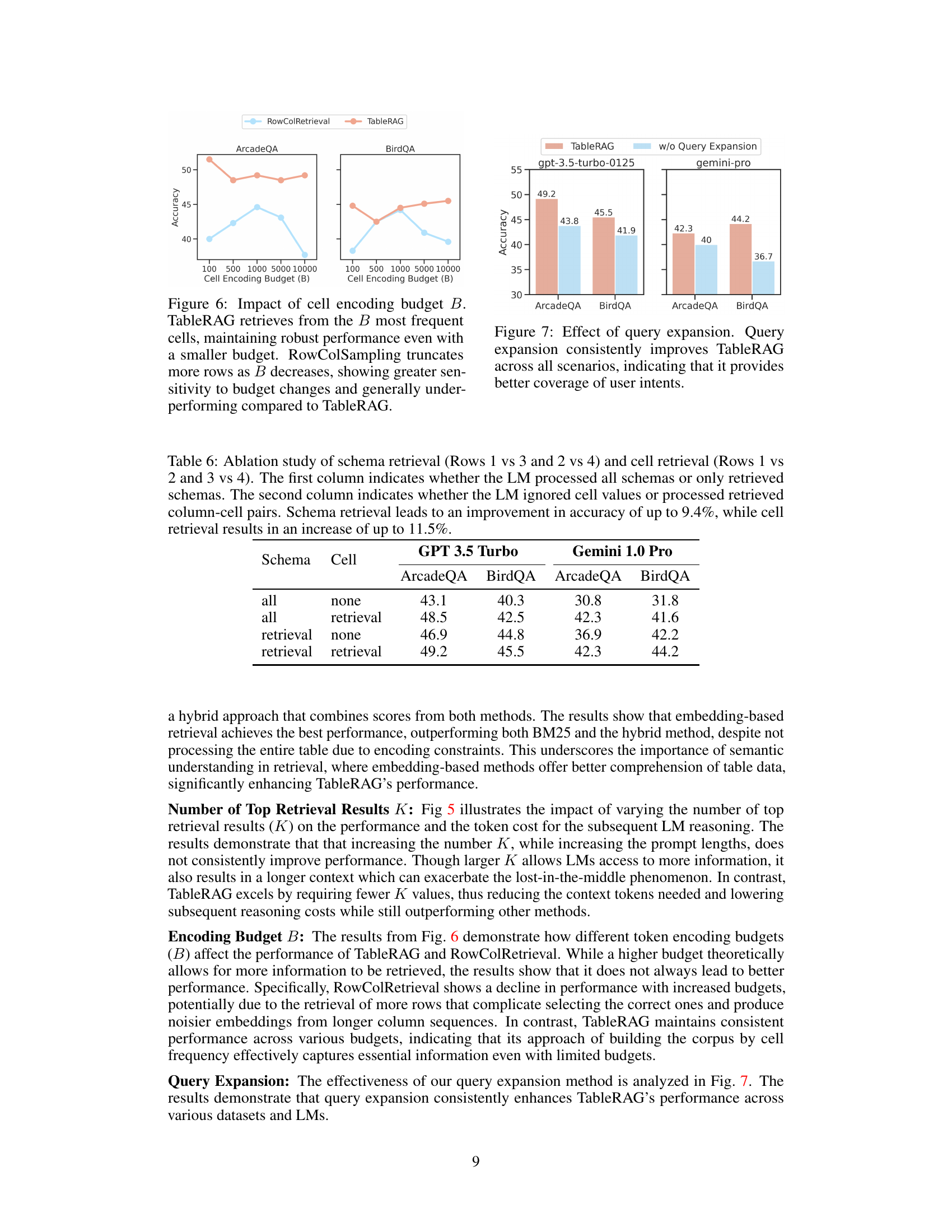
This figure shows the impact of the cell encoding budget (B) on the performance of TableRAG and RowColRetrieval on ArcadeQA and BirdQA datasets. TableRAG demonstrates consistent performance across varying budgets, while RowColRetrieval shows a decline in performance with increased budgets. This highlights TableRAG’s ability to maintain accuracy even with limited encoding budgets.
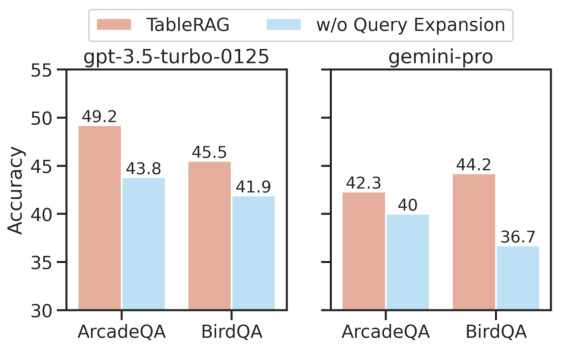
This figure shows the result of an ablation study on the impact of query expansion on TableRAG’s performance. It compares the accuracy of TableRAG with and without query expansion on two datasets, ArcadeQA and BirdQA, using two different language models, GPT-3.5-turbo and Gemini-Pro. The results consistently demonstrate that query expansion significantly improves TableRAG’s accuracy, highlighting its value in enhancing the model’s ability to understand and effectively process user queries.

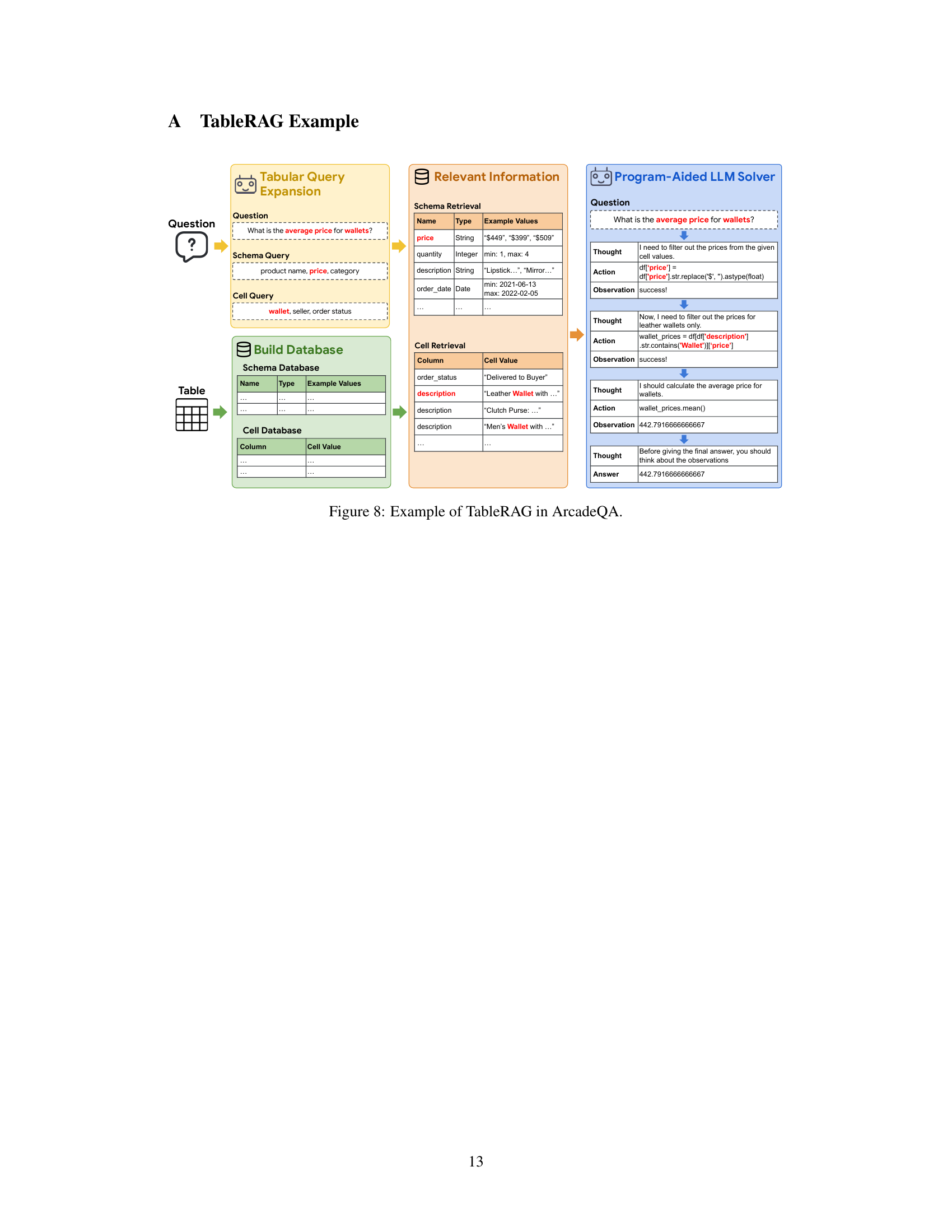
This figure demonstrates a complete workflow of TableRAG using an example from the ArcadeQA dataset. It starts with a question, ‘What is the average price for wallets?’, and shows how TableRAG expands this question into schema and cell queries. These queries are then used to retrieve relevant information from the schema and cell databases built from the table. Finally, the relevant information is passed to a program-aided Language Model (LM) to generate the final answer. The figure shows a step-by-step breakdown of the process, including the queries generated, the relevant information retrieved, and the actions performed by the LM solver to arrive at the final answer.

This figure shows the prompt used for the schema retrieval part of the TableRAG framework. The prompt instructs a large language model (LLM) to suggest column names from a large table (described as ‘amazon seller order status prediction orders data’) that are relevant to answering the question: ‘What is the average price for leather wallets?’ The LLM is instructed to respond with a JSON array of column names, without any further explanation. This is an example of how TableRAG uses the LLM to generate queries for relevant schema information rather than processing the entire table directly. The expected output is a list of column names (as a JSON array) that likely contain the price of leather wallets.

This figure shows the prompt and completion for the query expansion of cell retrieval in TableRAG. The prompt instructs a large language model (LLM) to extract keywords from a hypothetical table about Amazon seller order data that are relevant to answering the question ‘What is the average price for leather wallets?’ The keywords should be categorical rather than numerical and present in the question. The completion provides a JSON array of keywords that the LLM generated.
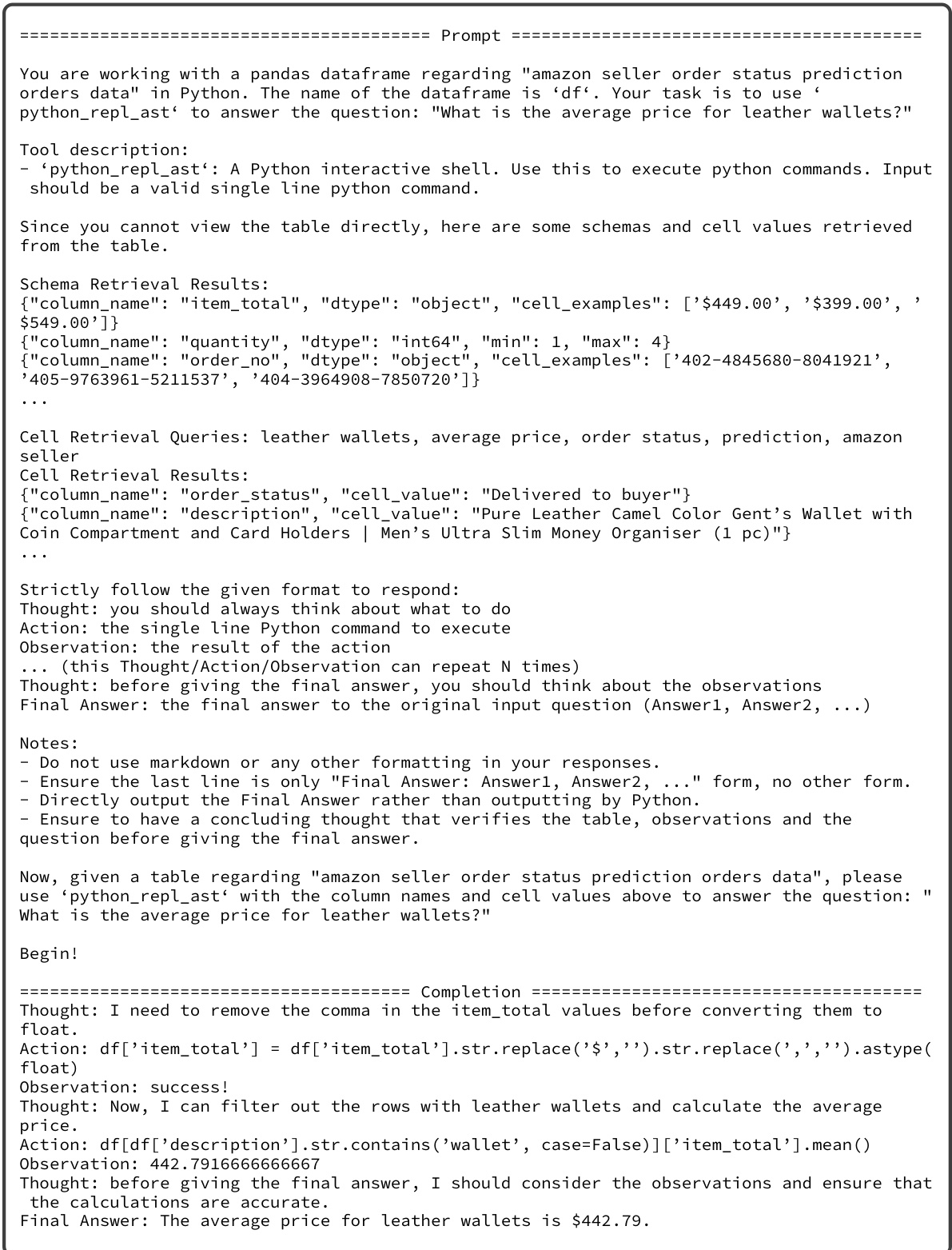
This figure shows an example of how TableRAG works on a real-world table from the ArcadeQA dataset. It illustrates the workflow, starting from the question, then expanding it into multiple queries for schema and cell retrieval. The relevant information extracted from the table using these queries is then presented to the program-aided LM solver, which generates the final answer. This example demonstrates TableRAG’s ability to efficiently handle complex table-based questions.
More on tables
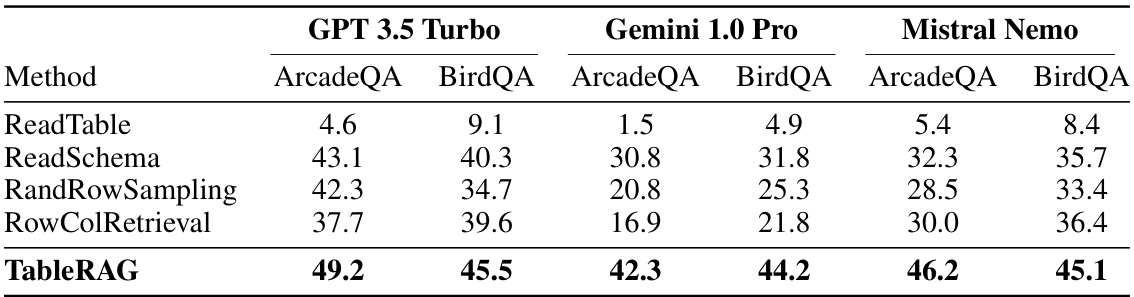
This table presents the performance comparison of different table prompting approaches (ReadTable, ReadSchema, RandRowSampling, RowColRetrieval, and TableRAG) on two benchmark datasets (ArcadeQA and BirdQA) using three different Large Language Models (LLMs): GPT 3.5 Turbo, Gemini 1.0 Pro, and Mistral Nemo. The results are expressed as accuracy scores, illustrating the effectiveness of each method in handling large-scale table understanding tasks across various LLM models. TableRAG consistently demonstrates superior performance compared to other methods.
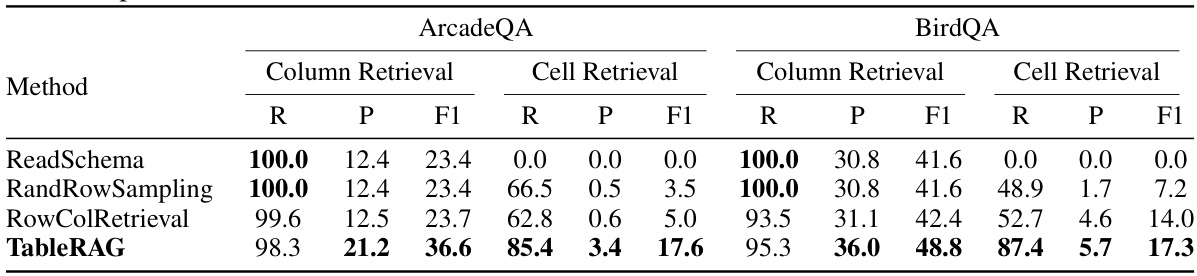
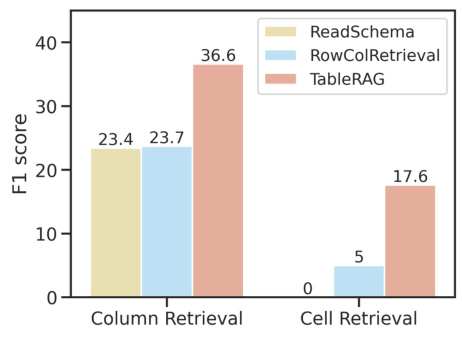
This table presents the results of the retrieval performance evaluation comparing different methods: ReadSchema, RandRowSampling, RowColRetrieval, and TableRAG. The evaluation is done for both column and cell retrieval on two datasets, ArcadeQA and BirdQA. The metrics used are Recall (R), Precision (P), and F1 score (F1). TableRAG demonstrates the best retrieval quality across all tasks and metrics.
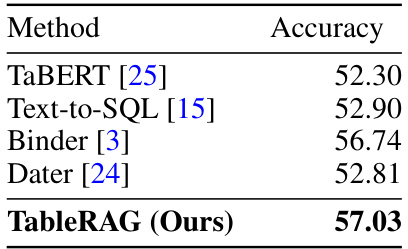
This table presents a comparison of the accuracy achieved by TableRAG against other state-of-the-art methods on the WikiTableQA benchmark dataset. It highlights TableRAG’s superior performance in comparison to existing approaches, demonstrating its effectiveness in the context of large-scale table understanding tasks.
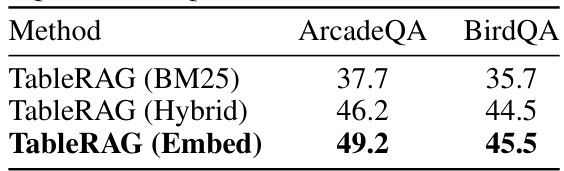
This table presents a comparison of the performance of different table prompting approaches (ReadTable, ReadSchema, RandRowSampling, RowColRetrieval, and TableRAG) on two datasets (ArcadeQA and BirdQA) using three different large language models (LLMs): GPT 3.5 Turbo, Gemini 1.0 Pro, and Mistral Nemo. The performance metric used is not explicitly stated but is likely accuracy or F1-score. The table highlights the superior performance of TableRAG across all LMs and datasets.
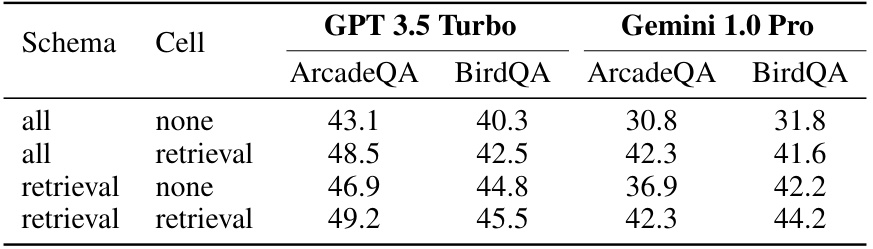
This table presents the results of an ablation study on TableRAG, evaluating the impact of schema and cell retrieval on the model’s performance. It shows that both schema and cell retrieval methods significantly improve accuracy, indicating the importance of incorporating both types of information for effective table understanding.

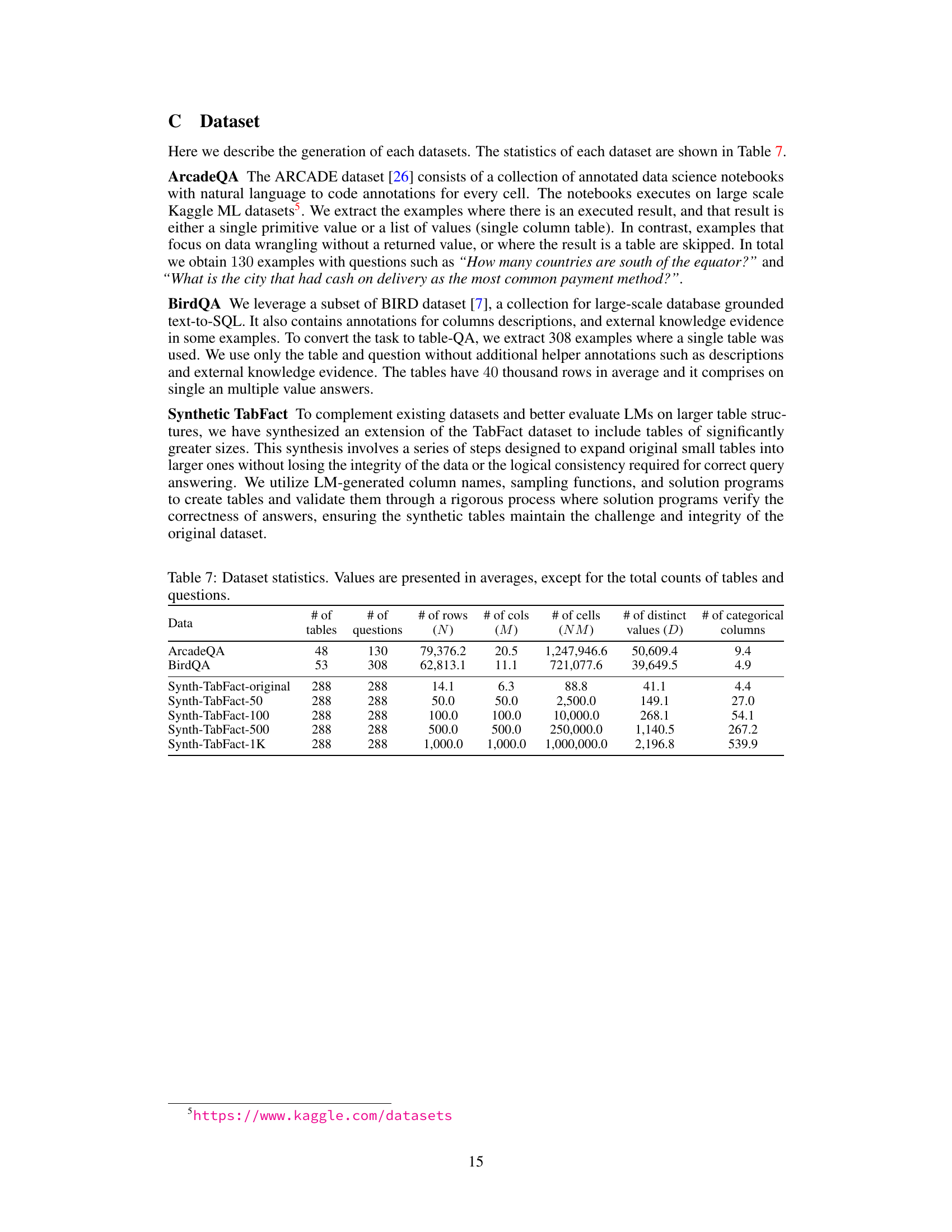
This table presents a statistical summary of six datasets used in the paper’s experiments. The datasets include two real-world datasets (ArcadeQA and BirdQA), and four synthetic datasets derived from TabFact, each with varying sizes. The table shows the number of tables, questions, rows, columns, total number of cells, number of distinct values, and number of categorical columns in each dataset. This information provides a comprehensive overview of the scale and characteristics of the data used to evaluate the proposed TableRAG method.
Full paper#