↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The prevalent pretraining-finetuning paradigm in deep learning requires high-quality annotated data for effective model finetuning, which is often expensive and time-consuming. Existing active learning methods for selecting optimal samples for finetuning struggle with inherent batch selection bias and neglect local decision boundaries. This leads to suboptimal model performance.
This research proposes a novel Bi-Level Active Finetuning Framework (BiLAF) to overcome these issues. BiLAF incorporates two stages: core sample selection for global diversity and boundary sample selection for local uncertainty. Using a novel denoising technique and evaluation metric, BiLAF effectively identifies pseudo-class centers and boundary samples, improving sample selection accuracy and efficiency. Extensive experiments consistently demonstrate that BiLAF outperforms state-of-the-art methods, exhibiting superior efficacy in diverse vision tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel active finetuning framework (BiLAF) that significantly improves sample selection efficiency in vision tasks. BiLAF addresses limitations of existing active learning methods, which often struggle to select samples effectively for model finetuning due to inherent bias and reliance on global distribution alignment rather than local decision boundaries. The proposed method shows superior performance across various datasets and benchmarks, opening new avenues for research in active learning and model finetuning.
Visual Insights#

This figure illustrates the key difference between the proposed BiLAF method and previous active finetuning methods in sample selection. Previous methods primarily focus on selecting samples based on global diversity, neglecting the importance of samples near decision boundaries. In contrast, BiLAF incorporates a bi-level approach selecting both core samples (for diversity) and boundary samples (for uncertainty near decision boundaries) to improve model performance. The figure visually represents this using feature distribution diagrams, highlighting how BiLAF’s selection strategy captures both global distribution and local decision boundary information.
This table presents the benchmark results of the BiLAF method and several other baselines on three popular datasets (CIFAR10, CIFAR100, and ImageNet) with varying annotation ratios (1%, 2%, 5%, and 10%). The results demonstrate BiLAF’s superior performance across different scenarios, highlighting its effectiveness compared to traditional active learning methods and other state-of-the-art active finetuning techniques.
In-depth insights#
BiLAF Framework#
The BiLAF framework introduces a novel bi-level active learning approach for finetuning pretrained models. Its core innovation lies in addressing the limitations of existing methods by incorporating both global diversity and local uncertainty. BiLAF tackles the challenge of sample selection in active finetuning by employing a two-stage process: First, it selects core samples representing global class diversity. Second, and more importantly, it identifies boundary samples that lie near decision boundaries using an unsupervised denoising technique and a novel boundary score. This unique approach ensures not only diverse representation but also focuses on the most informative samples for improving model accuracy near the class boundaries. The framework’s flexibility allows the integration of various core sample selection methods, making it adaptable to different datasets and model architectures. Furthermore, BiLAF demonstrates superior performance over existing baselines, showing effectiveness across various tasks and annotation budgets. The core methodology offers a substantial improvement over existing techniques, demonstrating a significant advancement in active learning for finetuning.
Boundary Selection#
The process of boundary selection in active learning aims to identify data points near the decision boundary, which are crucial for model accuracy and generalization. Effective boundary selection balances exploration and exploitation: selecting samples that are both informative (uncertain) and diverse (represent different regions of the feature space). This is particularly challenging in the context of pre-trained models used for active fine-tuning, where labeled data is scarce. Many techniques focus on uncertainty sampling, yet ignoring the diversity aspect can lead to overfitting on the selected subset. Strategies such as clustering or density-based methods are used to identify samples close to class boundaries, but these can be computationally intensive. Furthermore, the concept of ‘boundary’ might not be well-defined in high-dimensional spaces, requiring sophisticated feature extraction and representation techniques for effective selection. Successful boundary selection must account for dataset characteristics, such as class imbalance or noise, and model characteristics, particularly in the context of transfer learning.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a research paper, this involves removing or modifying parts of the proposed method and evaluating the impact on the overall performance. This helps isolate the effectiveness of specific components, separating their effects from others. Well-designed ablation studies are crucial for establishing causality and demonstrating the unique contributions of the proposed method. They also help to understand the interplay between different components, identifying potential synergies or redundancies. The results of ablation studies should be presented clearly and comprehensively, with quantitative metrics and visualizations to support the claims. By carefully analyzing the impact of removing individual parts, researchers can gain insights into which components are most essential and which can be improved or removed without significantly impacting the performance. This process facilitates a deeper understanding of the proposed method and its strengths, allowing for more targeted improvements and future research directions. The rigor and thoroughness of ablation studies strongly influence the credibility and impact of the research. A poorly designed ablation study can cast doubt on the validity of the conclusions made, while a well-executed one can strongly support the claims and offer valuable insights into the inner workings of the approach.
Active Finetuning#
Active finetuning addresses the challenge of efficiently utilizing limited annotation resources in the prevalent pretraining-finetuning paradigm. It strategically selects the most informative samples for finetuning, maximizing the model’s performance gains within a constrained budget. Unlike traditional active learning, which focuses on training from scratch, active finetuning leverages the knowledge gained during the pretraining phase. This approach is particularly crucial when labeled data is scarce or expensive. Effective active finetuning methods often incorporate uncertainty sampling and diversity considerations to select a representative subset of data that balances the need for informative samples and the avoidance of redundant selections. A key aspect is the development of suitable metrics to quantify sample informativeness in the context of a pretrained model, often without reliance on ground-truth labels for the unlabeled pool. The research area holds potential for substantial improvements in model efficiency and performance across various applications, particularly those dealing with large-scale datasets and limited resources for annotation. Further research directions include exploring novel metrics for sample selection, developing more robust methods for handling noisy data, and extending active finetuning to address various tasks beyond image classification.
Future Work#
Future research directions stemming from this BiLAF framework could involve exploring alternative core sample selection methods beyond ActiveFT to enhance robustness and efficiency. Investigating the impact of different distance metrics and denoising techniques on various datasets would refine the model’s boundary sensitivity. A significant area for future work is extending BiLAF to diverse tasks like object detection and semantic segmentation, requiring modifications to the boundary score calculation to accommodate task-specific features. Addressing the limitations in long-tail scenarios where the class imbalance affects performance significantly is another key direction. This could involve exploring techniques to prevent outlier removal of minority classes. Finally, a comprehensive theoretical analysis could further elucidate the framework’s efficiency and effectiveness, potentially leading to more refined selection strategies and a deeper understanding of the interplay between diversity and uncertainty in active finetuning.
More visual insights#
More on figures

This figure illustrates the BiLAF framework’s two-stage approach for active finetuning. The first stage (Core Sample Selection) identifies pseudo-class centers in the high-dimensional feature space. A denoising method removes noisy samples. The second stage (Boundary Samples Selection) iteratively selects boundary samples based on a novel Boundary Score metric, balancing diversity and uncertainty. Finally, selected samples are labeled and used for supervised finetuning.

This figure uses t-distributed Stochastic Neighbor Embedding (t-SNE) to visualize the feature embeddings of CIFAR10 data points after applying the Bi-Level Active Finetuning Framework (BiLAF). The core samples selected by BiLAF are marked as pentagrams, and the boundary samples are indicated by circles. The visualization aims to show how BiLAF selects samples that are both representative of the data distribution (core samples) and informative for improving the model’s decision boundaries (boundary samples). The different colors likely represent different classes in the CIFAR10 dataset. By focusing on these two types of samples, BiLAF aims to maximize the effectiveness of limited annotation budget in the active finetuning process.
This figure shows a t-SNE embedding of CIFAR10 features with 1% annotation budget using BiLAF. The core samples selected by BiLAF are marked with pentagrams, and the boundary samples are marked with circles. The visualization helps to illustrate how BiLAF selects core samples to represent the central areas of each class and boundary samples which lie near the decision boundaries. This approach improves the model’s ability to learn the class boundaries effectively, which is one of the core ideas of BiLAF.
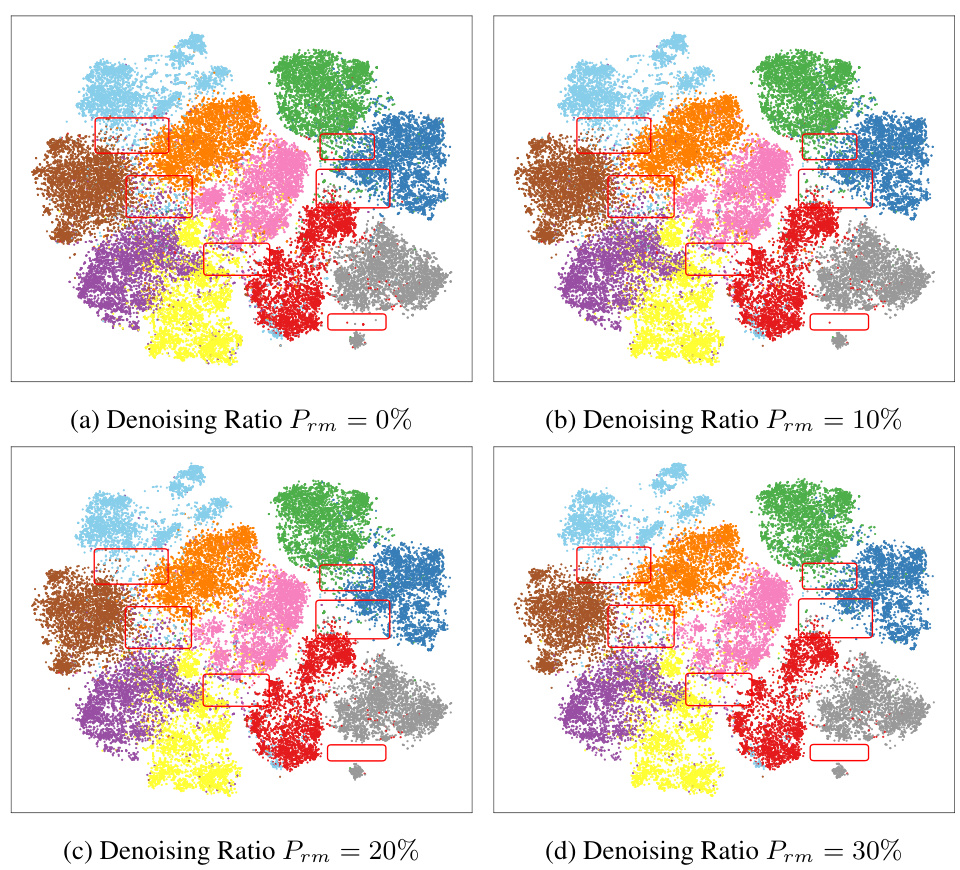
This figure visualizes the impact of variations in the removal rate (Prm) during the denoising process on the retained samples. The red bounding boxes highlight areas with significant changes, including outliers and regions of class confusion. As Prm increases, the number of samples in these areas decreases, reducing their influence on boundary selection, while relatively dense boundaries are often preserved. However, this is a trade-off, as some important samples might also be removed.

This figure compares the sample selection results of four different methods (FDS, K-Means, ActiveFT, and BiLAF) on the CIFAR10 dataset using a 1% annotation budget. t-SNE is used to visualize the high-dimensional feature embeddings in a 2D space. Each color represents a different class. The plots show the spatial distribution of selected samples. BiLAF demonstrates a more focused selection on boundary samples, while the others show more central selections.
More on tables

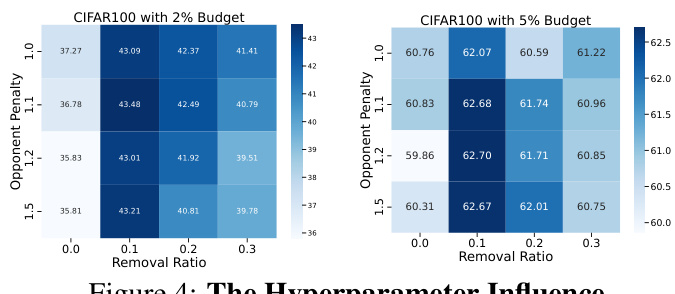
This ablation study on CIFAR100 dataset investigates the impact of three key components of the BiLAF framework: the denoising process, the selection criterion, and the selection process. It compares the performance of BiLAF against variants where one or more of these components are modified or removed, providing insights into the contribution of each component to the overall accuracy. The table displays the results for different annotation budgets (1%, 2%, 5%, 10%).

This table compares the time complexity of different active learning methods, including the proposed BiLAF method, for selecting varying proportions of data from the CIFAR100 dataset. The results highlight BiLAF’s efficiency compared to other methods, demonstrating its advantage in terms of time taken for data selection.

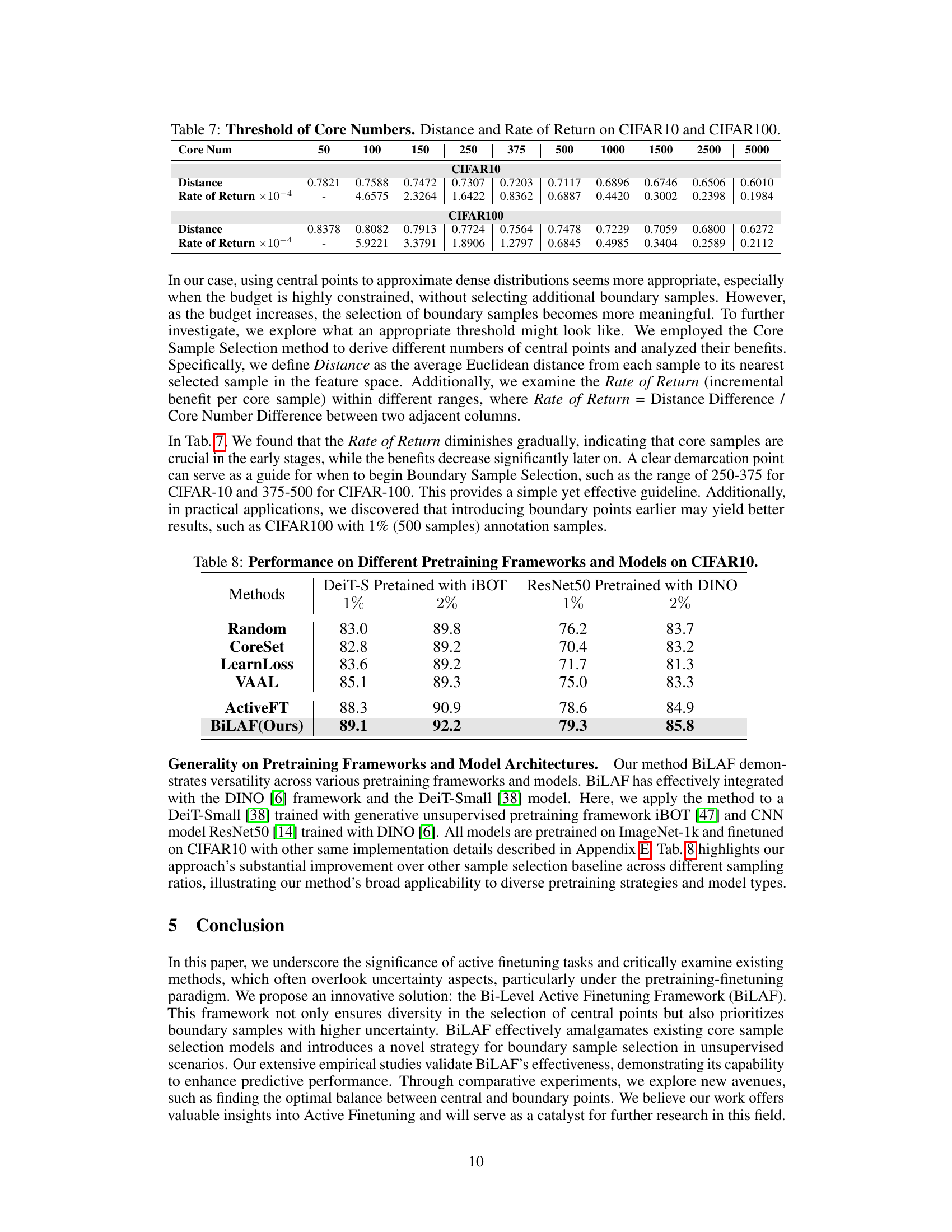
This table shows the ablation study on the number of core samples used in the BiLAF method. It demonstrates the impact of varying the number of core samples on the accuracy across different annotation budgets, specifically in the CIFAR100 dataset. The results illustrate that insufficient core samples lead to suboptimal performance due to inadequate representation of all categories, whereas an excessive number does not result in significant performance gains, indicating an optimal ratio of core samples to boundary samples exists.

This table presents an ablation study on the impact of varying the number of core samples on the performance of the BiLAF method. It shows the average Euclidean distance from each sample to its nearest selected sample (Distance) and the rate of return (incremental benefit per core sample) for different numbers of core samples on CIFAR10 and CIFAR100 datasets. The rate of return decreases as the number of core samples increases, indicating that the benefits of adding more core samples diminish after a certain point. The table helps to determine an optimal threshold for the number of core samples.
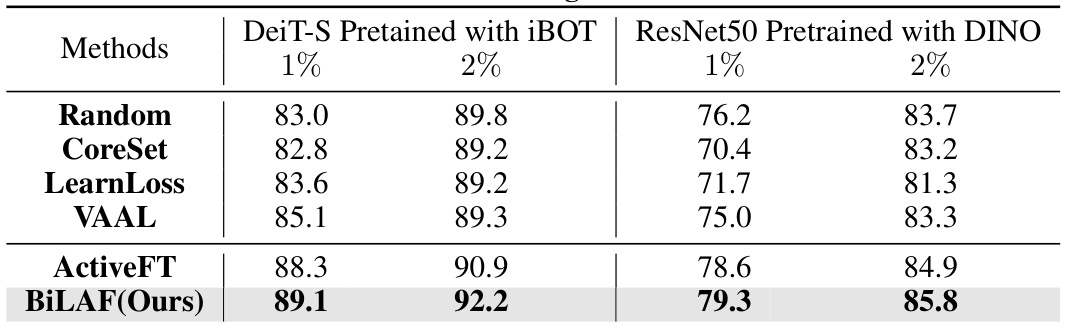
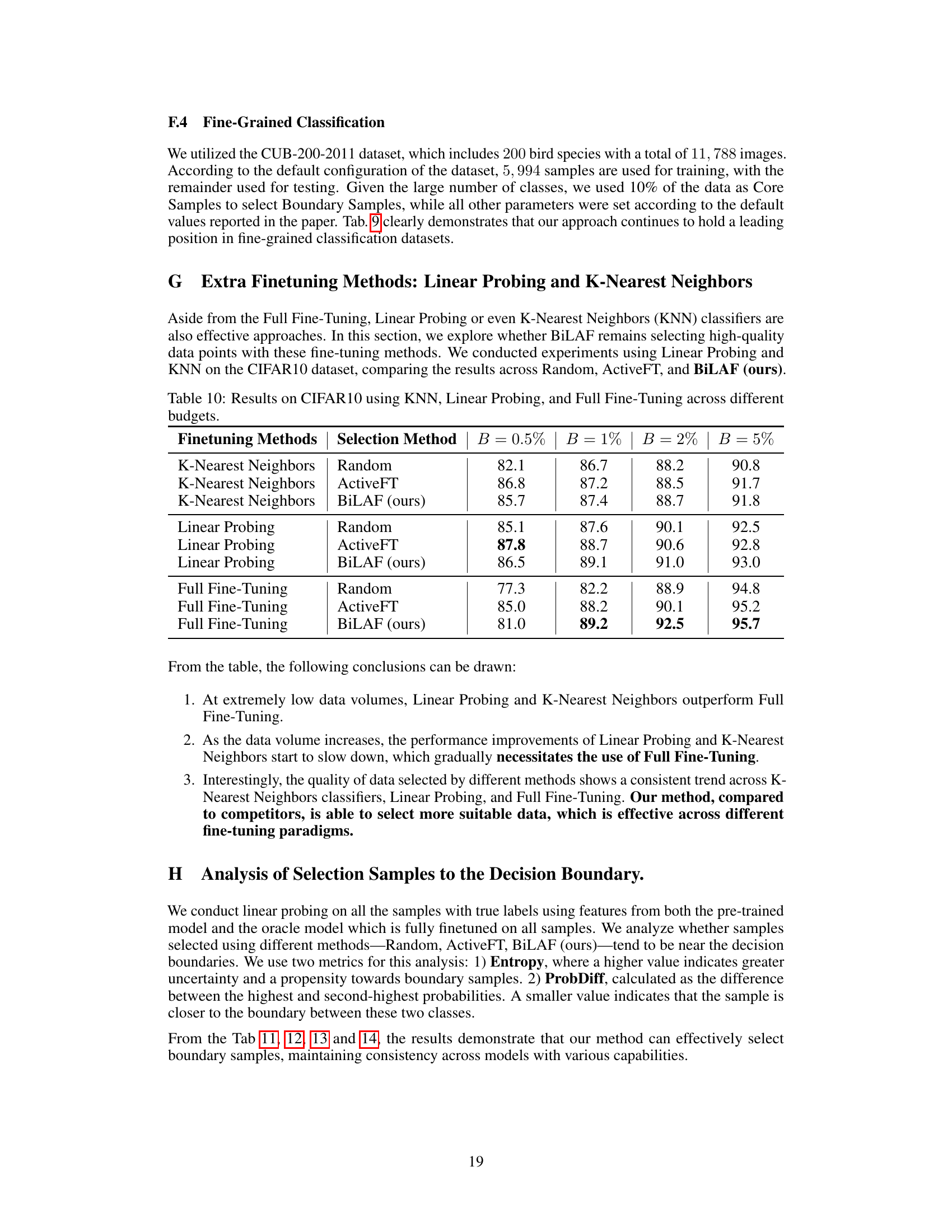
This table compares the performance of different active learning methods on CIFAR10 using two different pre-trained models (DeiT-S with iBOT and ResNet50 with DINO) with varying annotation budgets (1% and 2%). It demonstrates the generalizability and robustness of the proposed BiLAF method across different model architectures and pre-training frameworks.

This table presents the performance comparison of three different sample selection methods (Random, ActiveFT, and BiLAF) on the CUB-200-2011 dataset for fine-grained image classification. It shows the Top-1 accuracy achieved by each method under varying annotation budgets (20%, 30%, 40%, and 50%). The results demonstrate the superior performance of BiLAF in selecting informative samples, leading to higher accuracy compared to the baselines, especially as the budget increases.
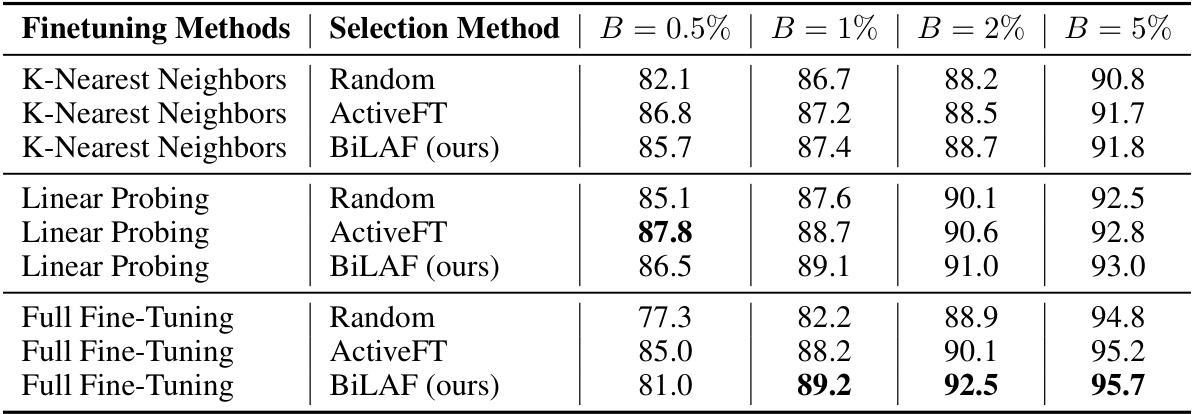
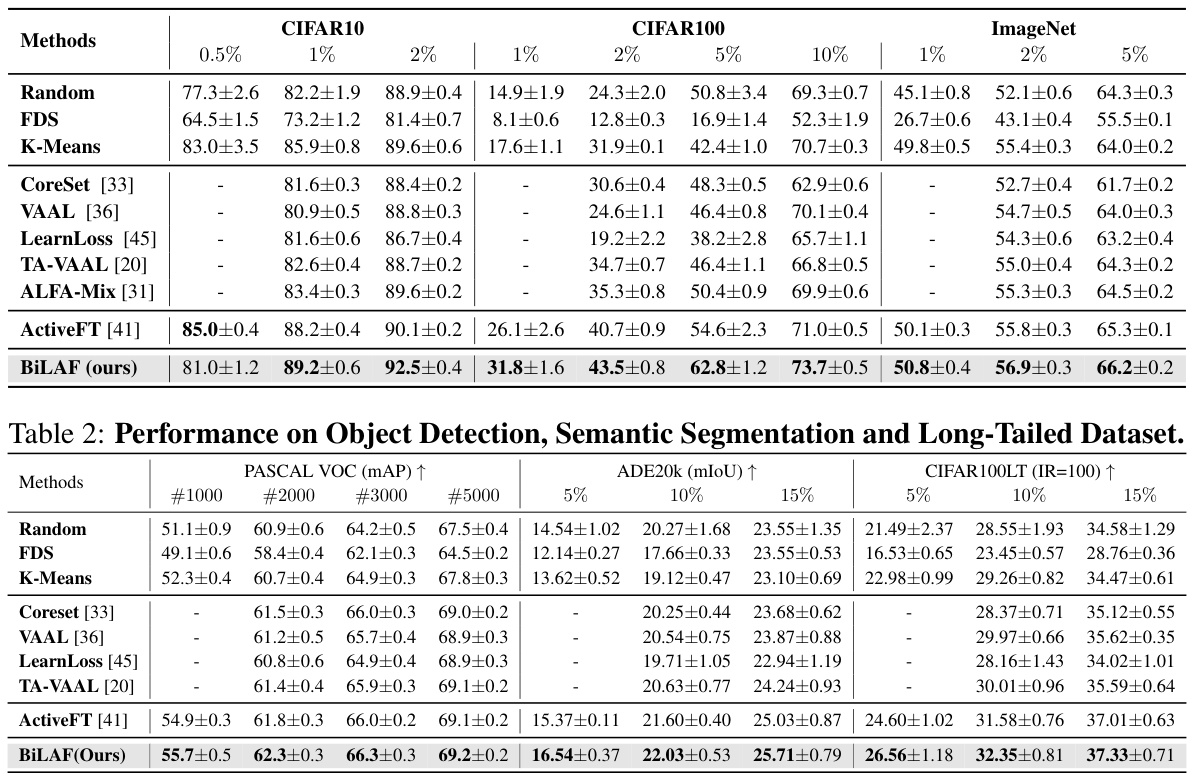
This table presents the performance comparison of three different finetuning methods (K-Nearest Neighbors, Linear Probing, and Full Fine-Tuning) using three different sample selection methods (Random, ActiveFT, and BiLAF) on the CIFAR10 dataset. The results are shown for various annotation budgets (B = 0.5%, 1%, 2%, 5%). It demonstrates how the choice of finetuning method and sample selection strategy impacts the final accuracy of the model, particularly at different annotation budget scales.

This table presents a comparison of the BiLAF model’s performance against several baselines and existing active learning methods on three widely-used image classification datasets (CIFAR10, CIFAR100, and ImageNet). The results are shown for different annotation ratios (1%, 2%, 5%, and 10%), demonstrating the model’s performance under varying data constraints. The table highlights BiLAF’s consistent superior performance compared to alternative methods, particularly when the annotation budget is limited.

This table presents the benchmark results of the BiLAF method compared to various baselines on three popular datasets (CIFAR10, CIFAR100, and ImageNet) with different annotation ratios. The results, averaged over three trials, show BiLAF’s superior performance in most scenarios, highlighting its effectiveness in the active finetuning task.
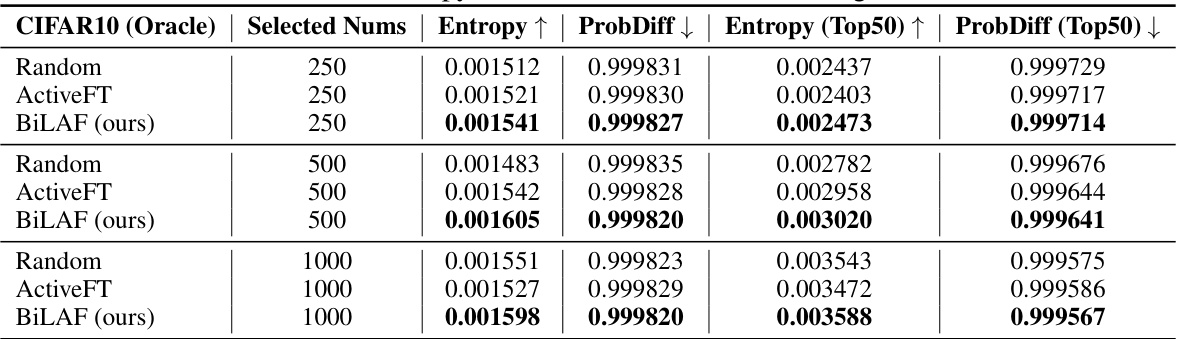
This table presents a comparison of the BiLAF method’s performance against various baselines and traditional active learning methods across three datasets (CIFAR10, CIFAR100, and ImageNet) under different annotation ratios (1%, 2%, and 5%). The results highlight BiLAF’s superior performance in most scenarios.
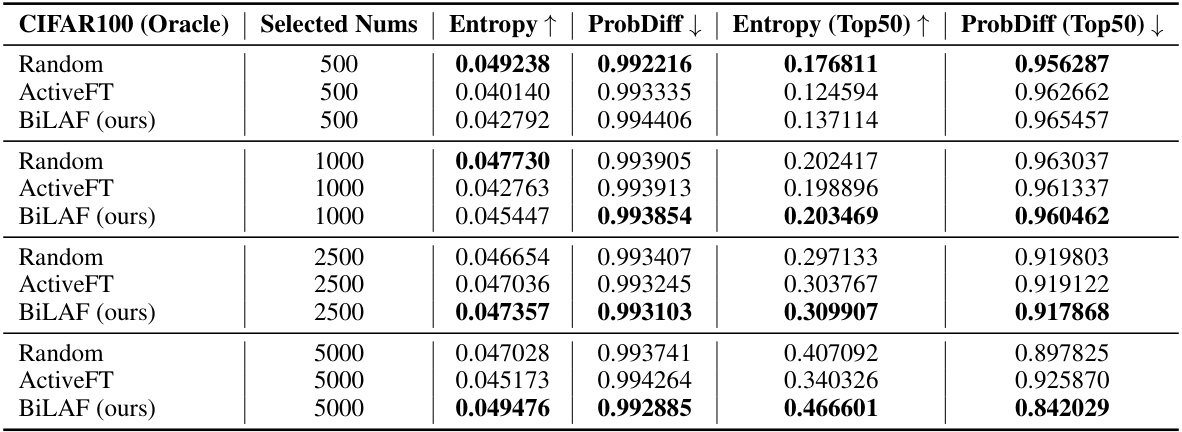
This table presents the benchmark results of the BiLAF method and several baselines on three popular image classification datasets (CIFAR10, CIFAR100, and ImageNet) using different annotation ratios (1%, 2%, 5%, and 10%). For each dataset and annotation ratio, the table shows the mean and standard deviation of the Top-1 accuracy achieved by each method over three independent trials. The results demonstrate BiLAF’s superior performance across various settings.
Full paper#