↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Diffusion models are known for their impressive generative capabilities but suffer from slow inference speeds due to their sequential nature. This significantly limits their application in real-time or resource-constrained environments. Existing acceleration techniques often compromise on quality or require extensive model retraining. This is a major bottleneck hindering the wider adoption and practicality of diffusion models for various applications.
This research introduces AsyncDiff, a novel acceleration scheme that tackles this issue by leveraging asynchronous denoising and model parallelism. AsyncDiff partitions the denoising model into multiple components, each assigned to a different device, enabling parallel computation. It cleverly addresses the inherent sequential dependencies within the diffusion process by exploiting the high similarity between consecutive diffusion steps, allowing for asynchronous processing that significantly reduces inference latency with minimal effect on the generated image quality. The efficiency of AsyncDiff is validated through extensive experiments across multiple image and video diffusion models demonstrating speedup ratios and maintains high-quality image outputs.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AsyncDiff, a novel and efficient method for accelerating inference in diffusion models. This is crucial because diffusion models, while powerful, are computationally expensive. AsyncDiff’s model parallelism approach offers a significant speedup with minimal impact on generation quality, opening new avenues for research in distributed computing and large-scale generative modeling. The method’s versatility, demonstrated through successful application to both image and video diffusion models, further enhances its significance for the broader AI community.
Visual Insights#

This figure shows five example images generated using Stable Diffusion XL. The top row shows the images generated using the standard method. The bottom row shows the images generated using the AsyncDiff method which achieves a 2.8x speedup with the use of four NVIDIA A5000 GPUs while maintaining the visual quality.
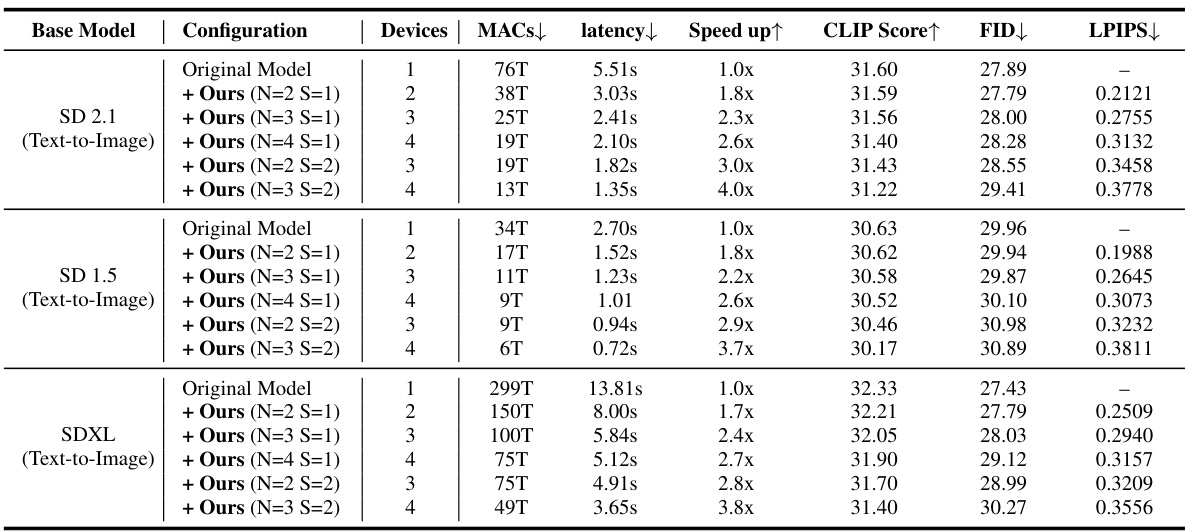
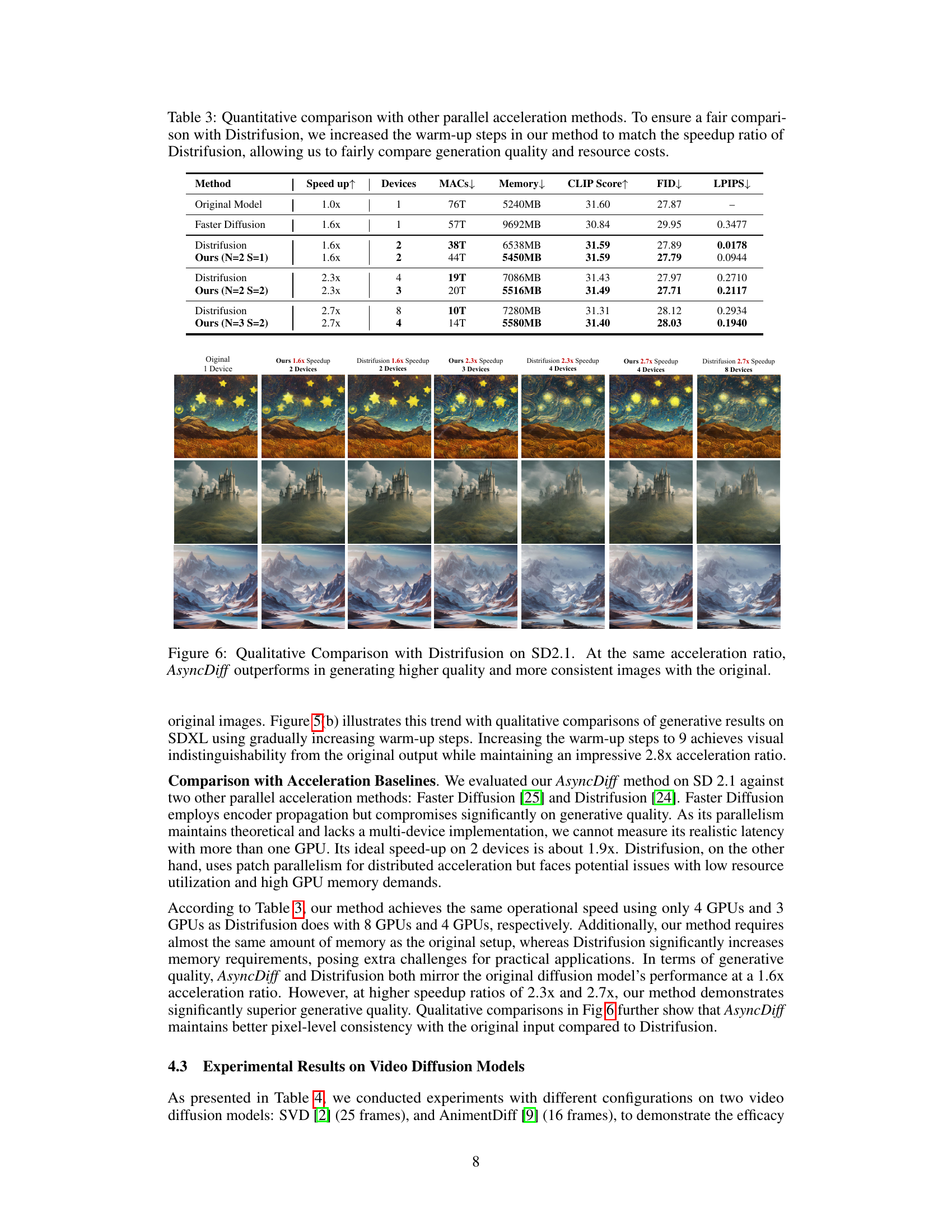
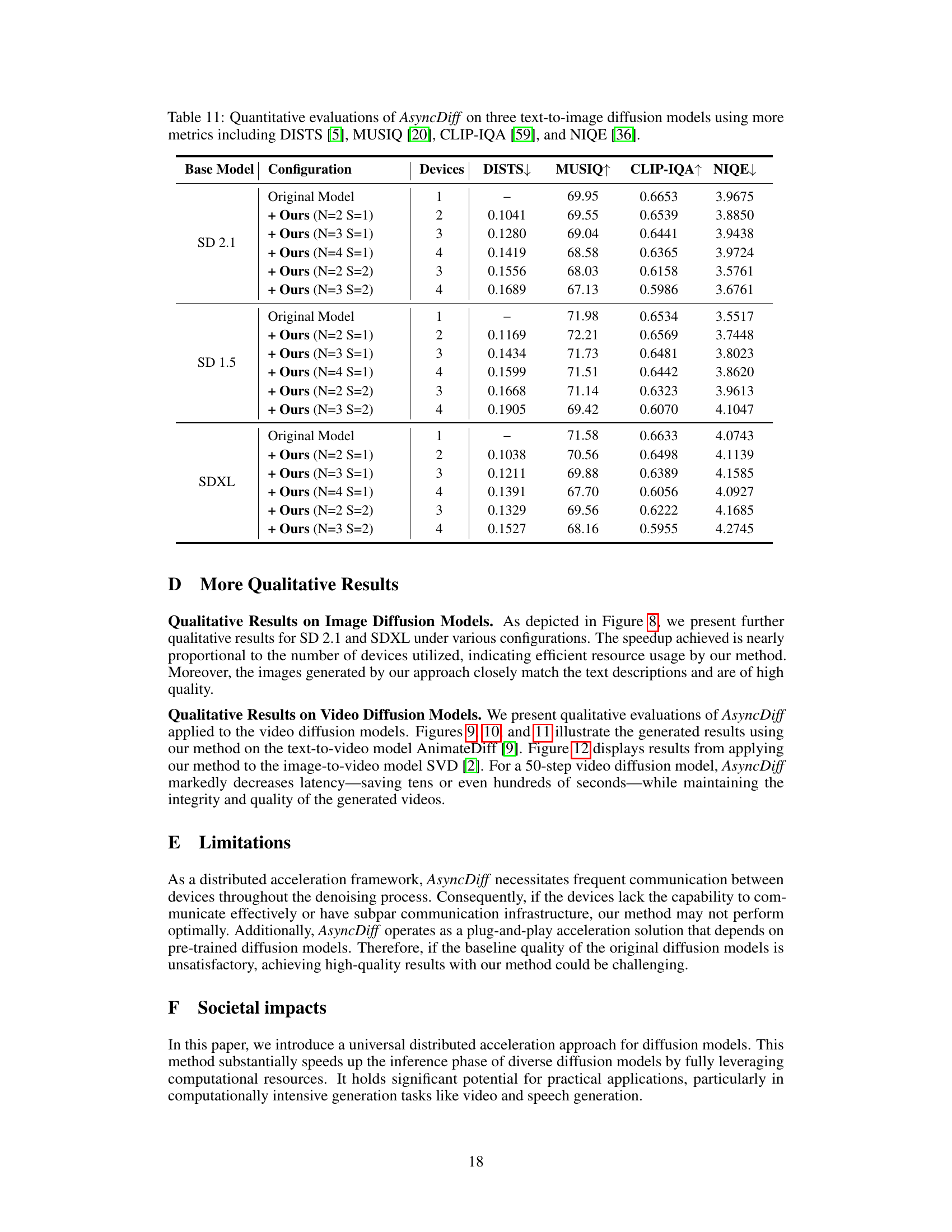
This table presents a quantitative analysis of AsyncDiff’s performance on three different text-to-image diffusion models (SD 2.1, SD 1.5, and SDXL). It shows how different configurations of the method, specified by the number of components (N) and the denoising stride (S), affect several key metrics: MACs (Multiply-Accumulate operations), latency, speedup, CLIP score, FID (Fréchet Inception Distance), and LPIPS (Learned Perceptual Image Patch Similarity). The results demonstrate the trade-off between speedup and the slight degradation in image quality (as measured by CLIP, FID, and LPIPS).
In-depth insights#
Async. Diffusion#
The concept of “Async. Diffusion” presents a compelling approach to accelerating diffusion models by introducing asynchronous processing. The core idea is to decouple the sequential dependency inherent in traditional diffusion models, where each denoising step relies on the output of its predecessor. This is achieved by transforming the sequential process into an asynchronous one, exploiting the high similarity between hidden states in consecutive steps. This allows parallel computation of multiple denoising components, significantly reducing inference latency while minimally affecting generative quality. The success of this approach relies on the ability to accurately approximate the results of the sequential process through asynchronous updates, and its effectiveness depends on factors like the model architecture, the degree of similarity between hidden states, and the communication overhead across parallel devices. Asynchronous processing allows for model parallelism, distributing computations across multiple GPUs to improve efficiency, and techniques like stride denoising further enhance efficiency by skipping redundant computations. This method holds significant promise for accelerating various diffusion-based applications, particularly those with high computational demands.
Model Parallelism#
The concept of model parallelism, as discussed in the context of accelerating diffusion models, centers on splitting the computationally intensive noise prediction model across multiple devices. This strategy directly tackles the inherent sequentiality of traditional diffusion processes, a major bottleneck to faster inference. By distributing model components, AsyncDiff aims to break the dependency chain that normally restricts parallel computation. A key innovation is the asynchronous processing enabled by leveraging the high similarity between hidden states in consecutive diffusion steps. This allows components to compute in parallel, approximating the results of the sequential approach while dramatically reducing latency. Efficient communication between devices is crucial for this strategy’s success, requiring careful consideration of data transfer and synchronization overhead. Overall, model parallelism presents a powerful paradigm shift in accelerating diffusion model inference, offering a trade-off between computational efficiency and generative quality.
Stride Denoising#
Stride denoising, as a technique to accelerate diffusion models, cleverly addresses the inherent sequential nature of the denoising process by performing multiple denoising steps simultaneously. Instead of processing each step individually, it strategically skips intermediate steps, significantly reducing computational load and communication overhead. This innovative approach enables greater parallelism by combining computations and broadcasting updates less frequently, leading to a notable increase in speed. While introducing a stride might lead to slightly reduced precision, the gains in efficiency often outweigh this minimal compromise in quality, particularly when combined with sufficient warm-up steps to ensure stability. The key to stride denoising is the balance between acceleration and accuracy. The method’s success hinges on the inherent similarity of hidden states between consecutive steps, justifying the approximation made by skipping iterations. This is a practical approach for achieving significant speed-ups in the generation process of diffusion models. It’s particularly useful in applications demanding real-time performance or deploying models across multiple devices.
GPU Acceleration#
The concept of GPU acceleration in the context of diffusion models centers on leveraging the parallel processing capabilities of GPUs to significantly reduce inference latency. Traditional diffusion models’ sequential nature hinders parallelization, creating a bottleneck. However, techniques like AsyncDiff cleverly re-architect the model, partitioning it into components processed asynchronously across multiple GPUs. This approach breaks the sequential dependency chain inherent in diffusion, enabling true model parallelism. The success of AsyncDiff hinges on exploiting the high similarity between hidden states in consecutive diffusion steps, allowing for the approximation of input data, thus enabling parallel execution and drastically improving speed without significantly impacting generative quality. Additional speed gains are achieved through stride denoising, a technique that intelligently skips redundant calculations, further optimizing computation across GPUs. The effectiveness of these strategies is demonstrated through empirical results showcasing substantial speedups with minimal quality degradation, making GPU acceleration a crucial step in deploying diffusion models for various real-world applications.
Future Work#
Future research directions stemming from this work on AsyncDiff could explore several promising avenues. Extending AsyncDiff to encompass a broader range of diffusion models, beyond those tested, is crucial for establishing its general applicability. This includes investigating its performance with different network architectures and varying levels of complexity. Another important area is optimizing the communication overhead between devices. While AsyncDiff significantly reduces latency, further refinement of the communication strategy could yield even greater efficiency gains. Investigating the impact of different hardware configurations and network topologies on AsyncDiff’s performance is essential for broader adoption. Finally, exploring innovative sampling techniques that synergistically interact with the asynchronous denoising approach could unlock further speed improvements while maintaining or improving image quality.
More visual insights#
More on figures

This figure illustrates the core concept of AsyncDiff, which is a method for parallelizing the denoising process in diffusion models. The top part shows the traditional sequential denoising process where each component of the model is processed sequentially on a single GPU. The bottom part shows the AsyncDiff approach where the model is divided into multiple components and each component is processed in parallel on a different GPU. Communication between the GPUs is minimized by preparing each component’s input in advance. This parallel approach significantly reduces latency (the time it takes to generate an image) while maintaining good image quality.
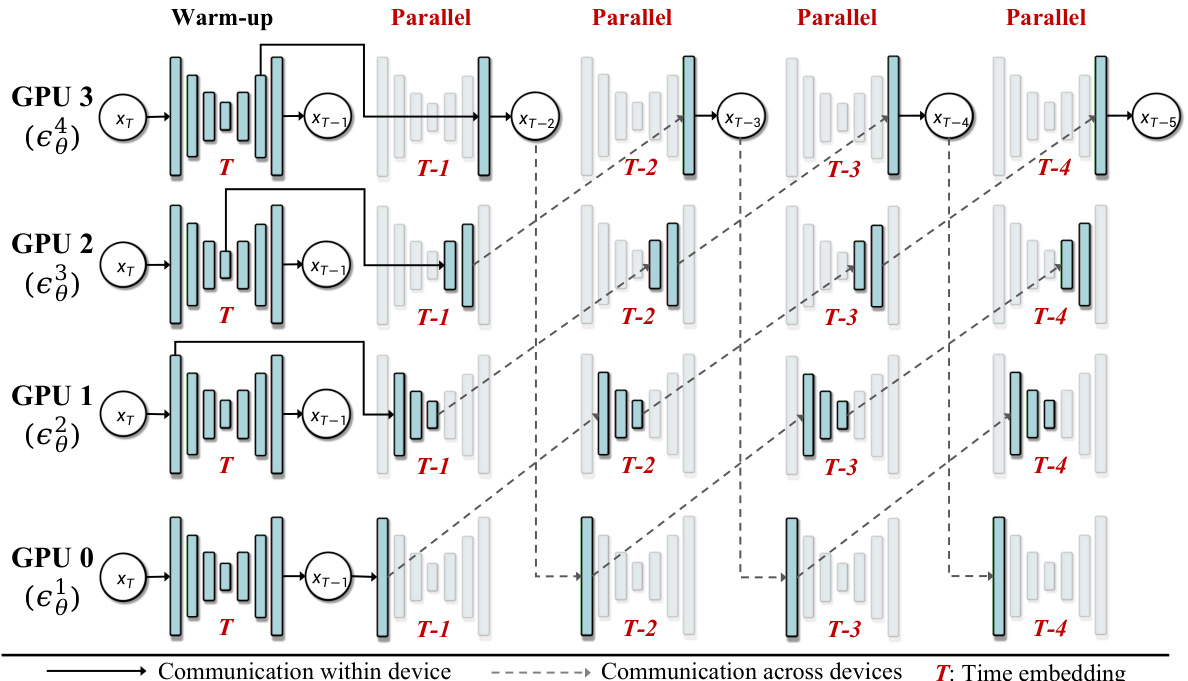
This figure illustrates the asynchronous denoising process used in AsyncDiff. The denoising model is divided into components, each assigned to a different GPU. After a brief warm-up phase of sequential processing, the components process inputs asynchronously, using the output of the previous component at a slightly earlier time step as its input, rather than waiting for the completion of the immediately preceding step. This breaks the sequential dependency and allows parallel computation.
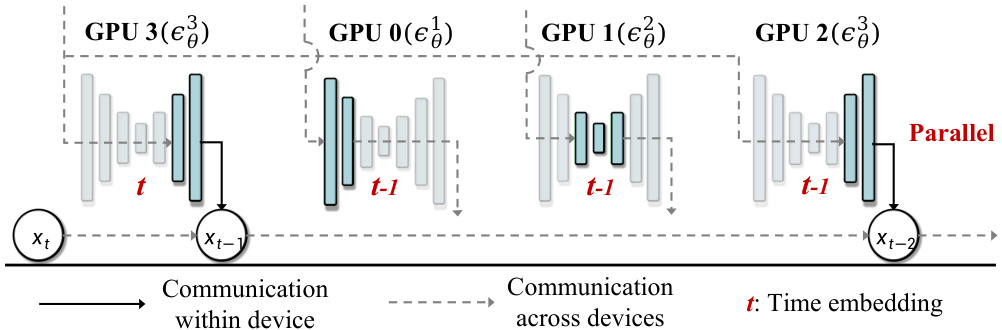
This figure illustrates how the AsyncDiff method uses stride denoising to further enhance efficiency. Instead of processing one denoising step at a time, stride denoising groups multiple steps together for parallel processing. This diagram uses a stride of 2, meaning that for each parallel processing batch, only components e and e need to be processed, skipping components e and e. This reduces communication overhead and accelerates the completion of multiple denoising steps.

This figure presents qualitative results to showcase the impact of AsyncDiff on image generation quality and speed. (a) demonstrates the acceleration achieved with different configurations (number of devices and stride). (b) shows the effect of adjusting the warm-up steps on the consistency between AsyncDiff’s output and the original Stable Diffusion output. The results show that AsyncDiff significantly speeds up inference while maintaining high image quality. Increasing the warm-up steps further improves the consistency of the generated images.

This figure compares the image generation quality of AsyncDiff and Distrifusion on the Stable Diffusion 2.1 model. Both methods achieve similar acceleration ratios (1.6x, 2.3x, and 2.7x). However, AsyncDiff consistently produces higher-quality images that are visually closer to the original images compared to Distrifusion, especially at higher acceleration ratios.
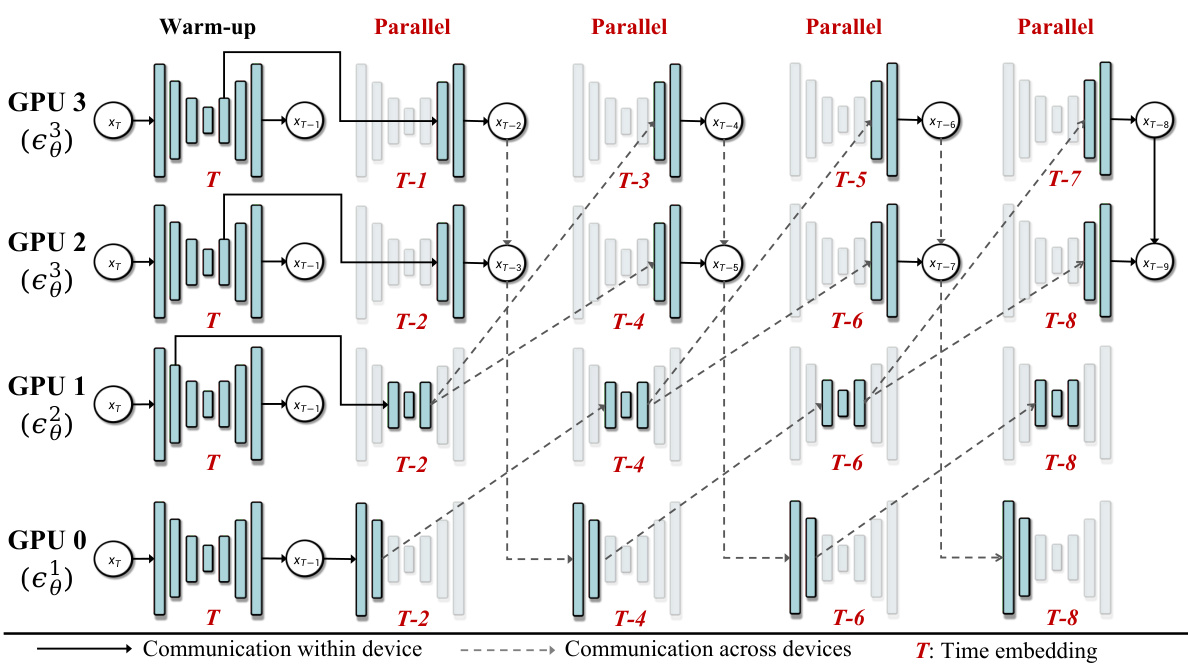
This figure illustrates the asynchronous denoising process used in AsyncDiff. The denoising model is split into four components (in this example), each assigned to a different GPU. A warm-up phase uses sequential processing for the initial steps to establish a baseline. After the warm-up, the components process different time steps concurrently, breaking the sequential dependency and achieving parallel computation. The dashed lines show communication between GPUs.
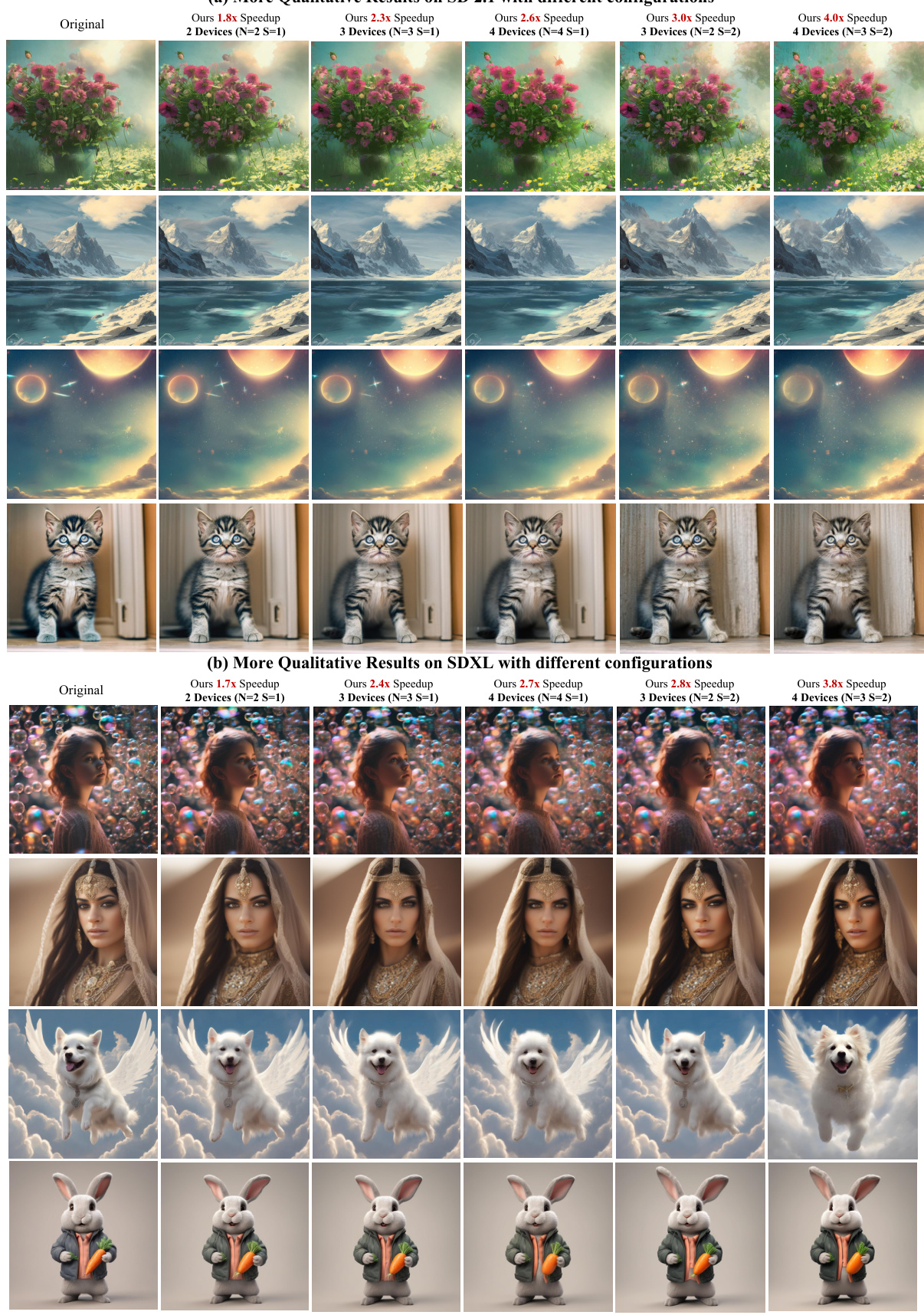
This figure demonstrates the qualitative results of the AsyncDiff method on two different Stable Diffusion models (SD 2.1 and SDXL) under various configurations. It visually compares the image generation quality of the original models with the outputs of AsyncDiff using different numbers of GPUs (2, 3, and 4) and different stride values (S=1 and S=2). The images show that even with significant speedups (up to 4x), AsyncDiff preserves the quality of the generated images, maintaining pixel-level consistency in many cases.

This figure shows the qualitative results of applying AsyncDiff to the AnimateDiff model with a prompt of ‘Brilliant fireworks on the town, Van Gogh style, digital artwork, illustrative, painterly, matte painting, highly detailed, cinematic’. It compares the original generation (43.5 seconds) with the results using AsyncDiff on 2 devices (23.5 seconds) and 4 devices (11.5 seconds). The images showcase the visual quality and consistency across different acceleration levels.
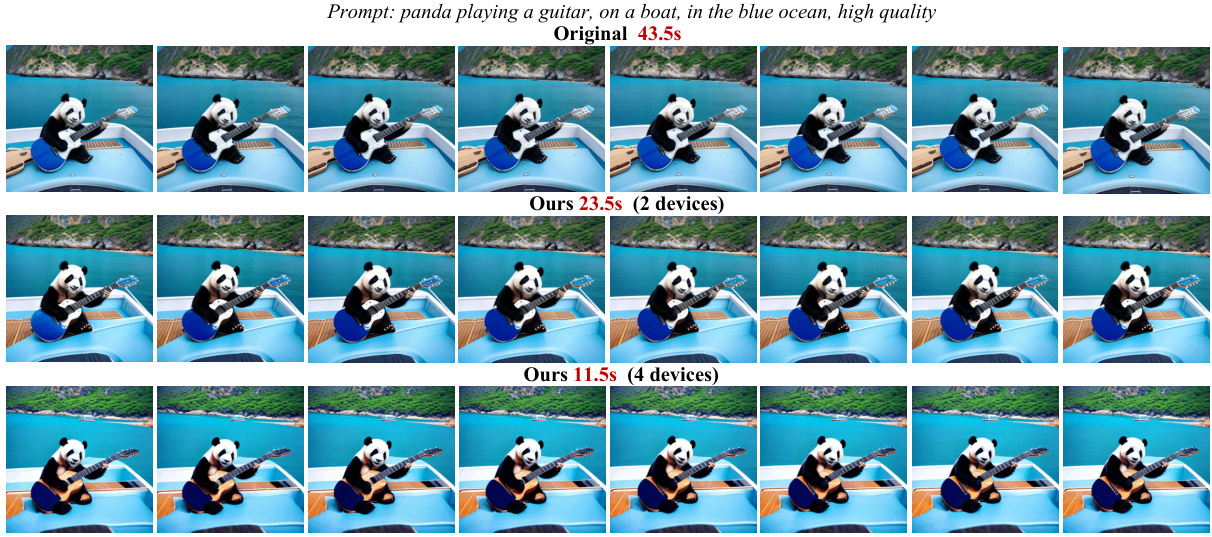
This figure shows the qualitative results of applying AsyncDiff to the AnimateDiff model with the prompt ‘panda playing a guitar, on a boat, in the blue ocean, high quality’. It presents the original images generated by AnimateDiff, and compares them to results obtained using AsyncDiff with 2 and 4 devices. The comparison is to illustrate that the AsyncDiff method can significantly reduce inference latency (43.5s down to 23.5s with 2 devices and 11.5s with 4 devices) while preserving the image quality.

This figure illustrates the asynchronous denoising process of the AsyncDiff model. The denoising model is divided into multiple components, each assigned to a different GPU. The initial ‘warm-up’ steps are processed sequentially. Then, the dependencies between components are broken by utilizing the similarity between hidden states in consecutive diffusion steps, allowing components to compute in parallel. This figure clearly shows how the asynchronous denoising process enables parallel execution, resulting in a significant reduction of inference latency.

This figure shows a qualitative comparison of video generation results using Stable Video Diffusion with different numbers of GPUs. The original video took 184 seconds to generate. Using 2 GPUs, the generation time was reduced to 101 seconds; with 3 GPUs, it took 80 seconds; and with 4 GPUs, it took 64 seconds. The figure visually demonstrates the effectiveness of the proposed AsyncDiff method in accelerating video generation, showing that as the number of GPUs increases, the generation time decreases while the visual quality of the generated videos remains largely consistent.
More on tables
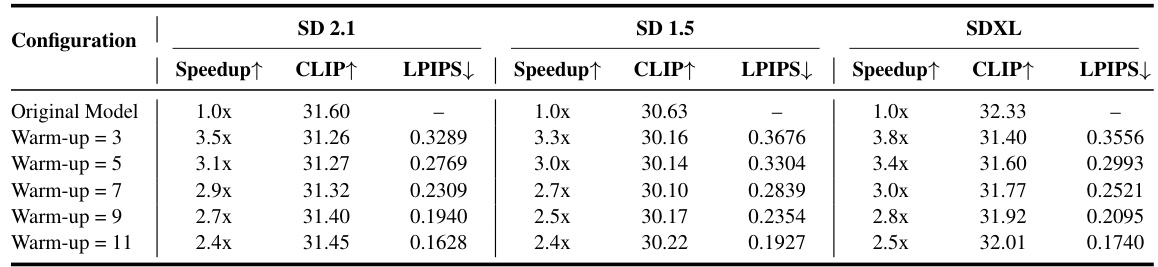
This table presents a quantitative analysis of how increasing the number of warm-up steps in the AsyncDiff model affects its speed and the pixel-level consistency of its generated images compared to the original sequential model. It shows that increasing warm-up steps improves pixel-level consistency (as measured by LPIPS) but slightly reduces the speedup achieved.

This table compares AsyncDiff with two other parallel acceleration methods, Faster Diffusion and Distrifusion, across three different speedup ratios (1.6x, 2.3x, and 2.7x). It shows the number of devices used, the MACs (multiply-accumulate operations), memory consumption, CLIP Score, FID (Fréchet Inception Distance), and LPIPS (Learned Perceptual Image Patch Similarity) scores for each method at each speedup ratio. The comparison highlights AsyncDiff’s superior performance and resource efficiency.
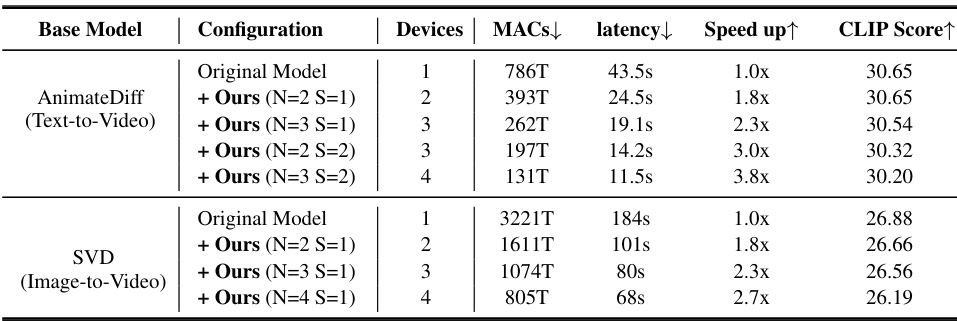
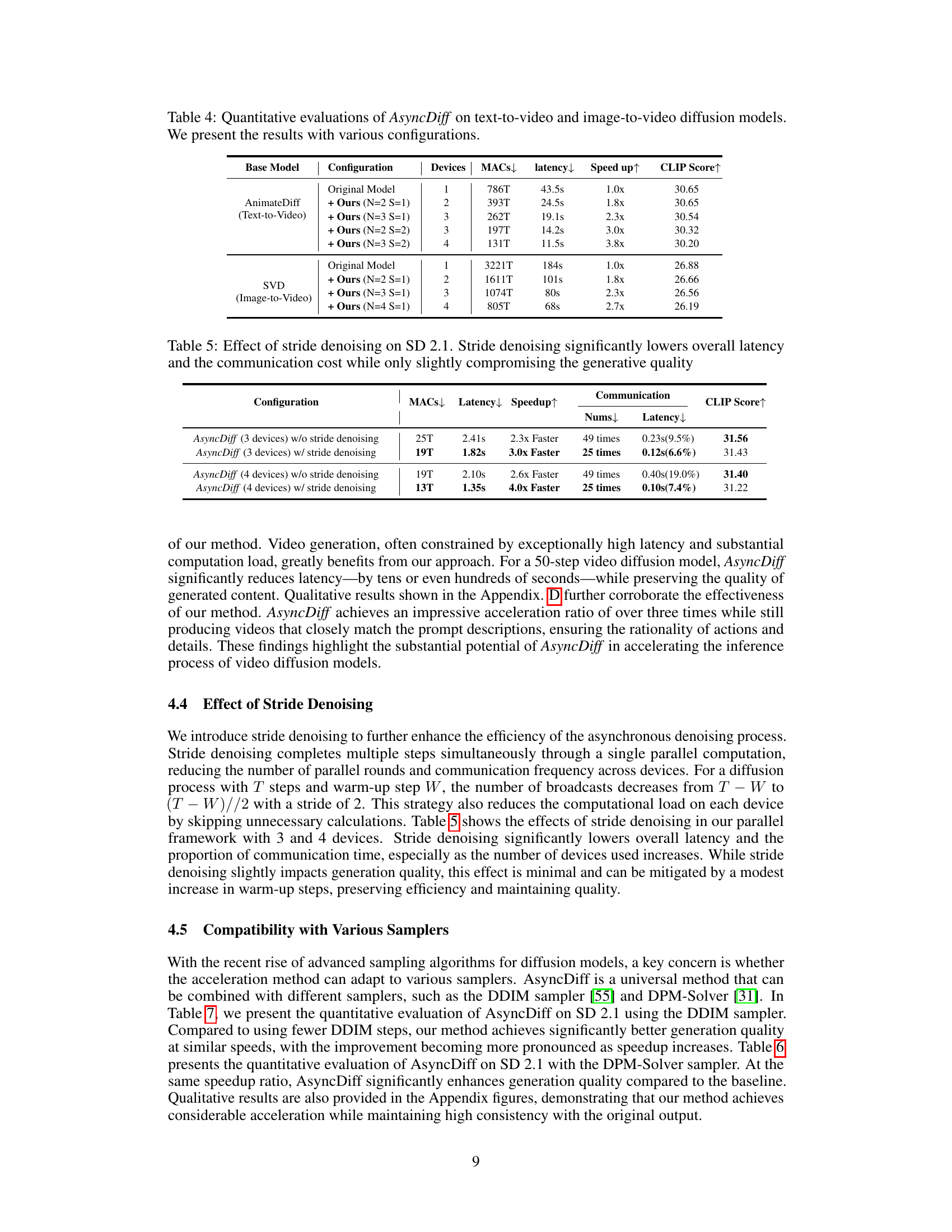
This table presents the quantitative results of applying AsyncDiff to two video diffusion models: AnimateDiff (text-to-video) and Stable Video Diffusion (image-to-video). It shows the original model’s performance, and then compares it to AsyncDiff’s performance with different configurations (number of devices and stride). The metrics reported are MACs (Multiply-Accumulate operations), latency (inference time), speedup (relative to the original model), and CLIP score (a measure of image quality). The results demonstrate AsyncDiff’s ability to significantly reduce inference time while maintaining reasonable image quality.
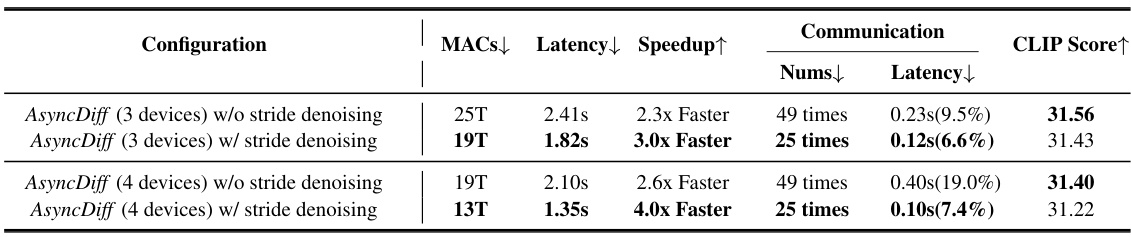
This table presents a quantitative evaluation of the impact of stride denoising on the Stable Diffusion 2.1 model. It compares the performance of AsyncDiff with and without stride denoising, showing metrics such as MACs (Million Arithmetic Calculations), latency, speedup, communication number, communication latency, and CLIP score. The results demonstrate that stride denoising substantially reduces both latency and communication overhead with minimal impact on generative quality.
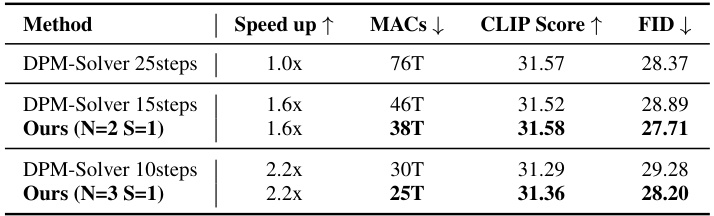
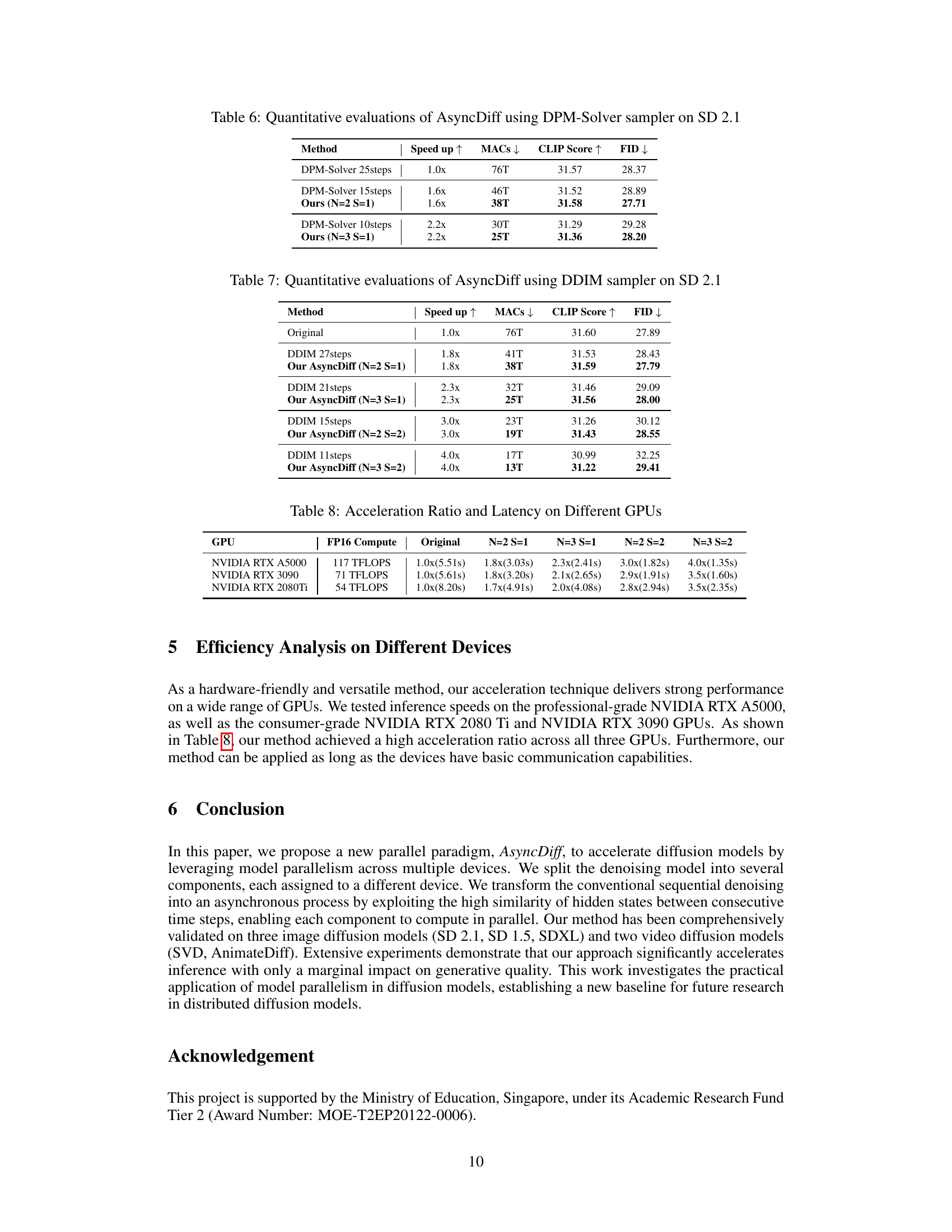
This table presents a quantitative comparison of the performance of AsyncDiff and the DPM-Solver method on the Stable Diffusion 2.1 model using the DPM-Solver sampler. It shows the speedup achieved, the number of Multiply-Accumulate operations (MACs), the CLIP score, and the Fréchet Inception Distance (FID). The comparison is made for different numbers of steps used in the denoising process, showcasing the effect of AsyncDiff on different speedup levels.
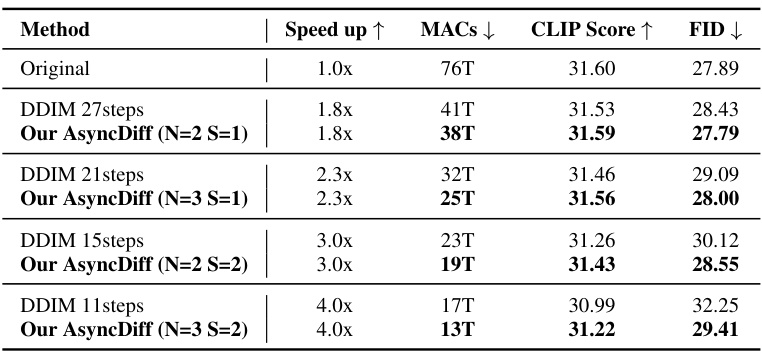
This table presents a quantitative comparison of the performance of AsyncDiff using the DDIM sampler with different speedup ratios on the Stable Diffusion 2.1 model. It shows the speedup achieved, the resulting MACs (Million Multiply-Accumulates), CLIP Score, and FID (Fréchet Inception Distance) for different numbers of denoising steps (and configurations of AsyncDiff). The comparison is made against the standard DDIM method with the same number of steps, to highlight the tradeoffs between speed and image quality.

This table compares the acceleration ratios and inference latency achieved by AsyncDiff on three different GPUs: NVIDIA RTX A5000, NVIDIA RTX 3090, and NVIDIA RTX 2080Ti. The original latency and speedup factors (relative to the original) are presented for AsyncDiff configurations with different numbers of components (N) and strides (S). It demonstrates the effectiveness of AsyncDiff across a range of GPU hardware.
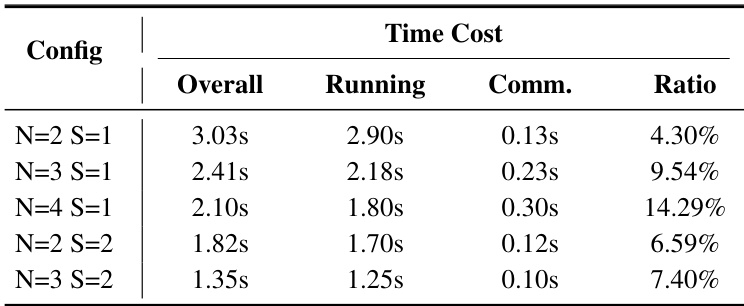
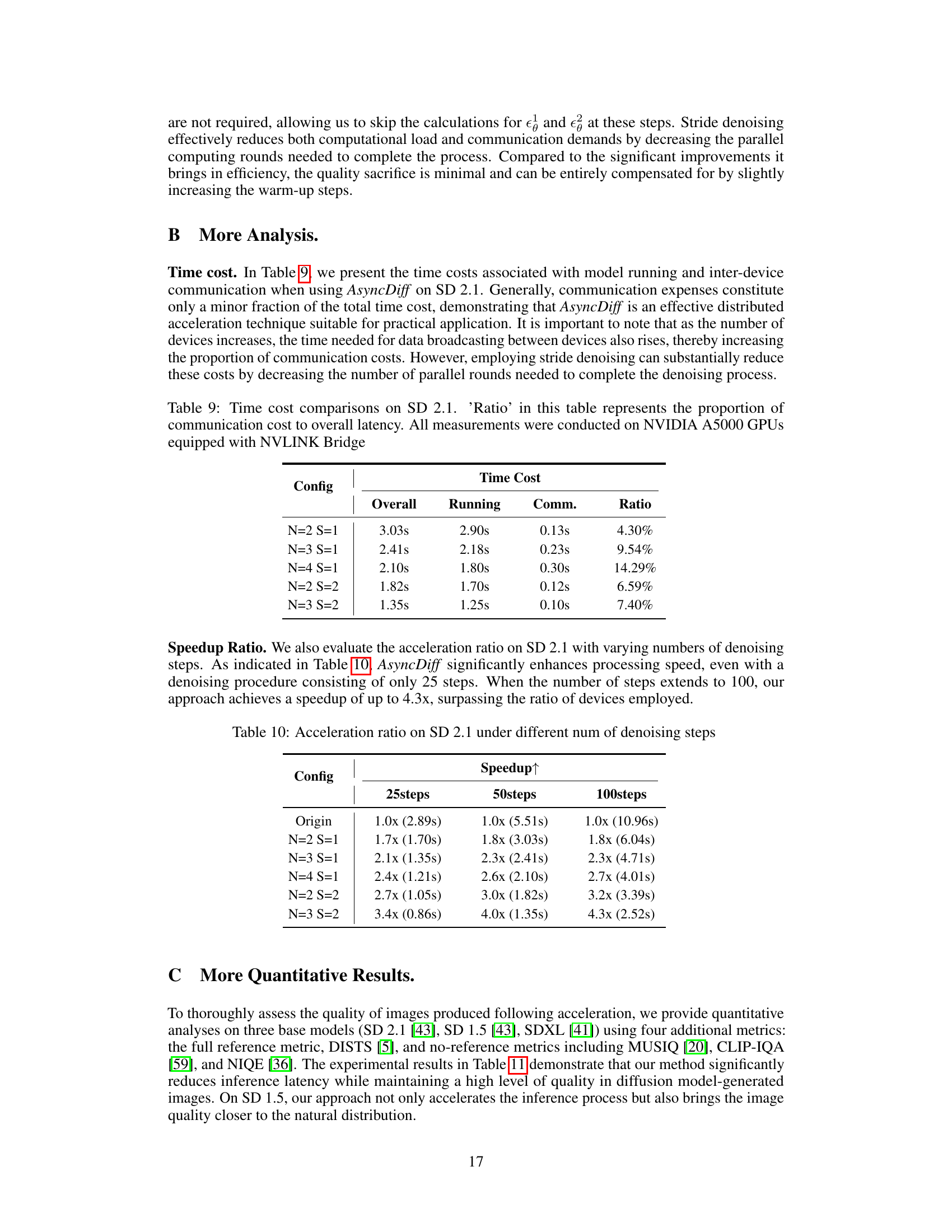
This table presents a quantitative analysis of the time costs associated with model execution and inter-device communication when using AsyncDiff on the Stable Diffusion 2.1 model. It breaks down the overall time into running time and communication time, and calculates the ratio of communication time to overall time for different configurations. The configurations vary in terms of the number of components the model is split into (N) and the stride of denoising (S). The results show that communication overhead is a relatively small part of the overall process, making AsyncDiff efficient for distributed computing, although it does slightly increase as the number of devices and the stride increases.

This table shows how the speedup achieved by AsyncDiff on the Stable Diffusion 2.1 model changes depending on the number of denoising steps used (25, 50, and 100). Different AsyncDiff configurations (N= number of components, S = stride) are compared against the original sequential method. The numbers in parentheses represent the time taken for inference in seconds.
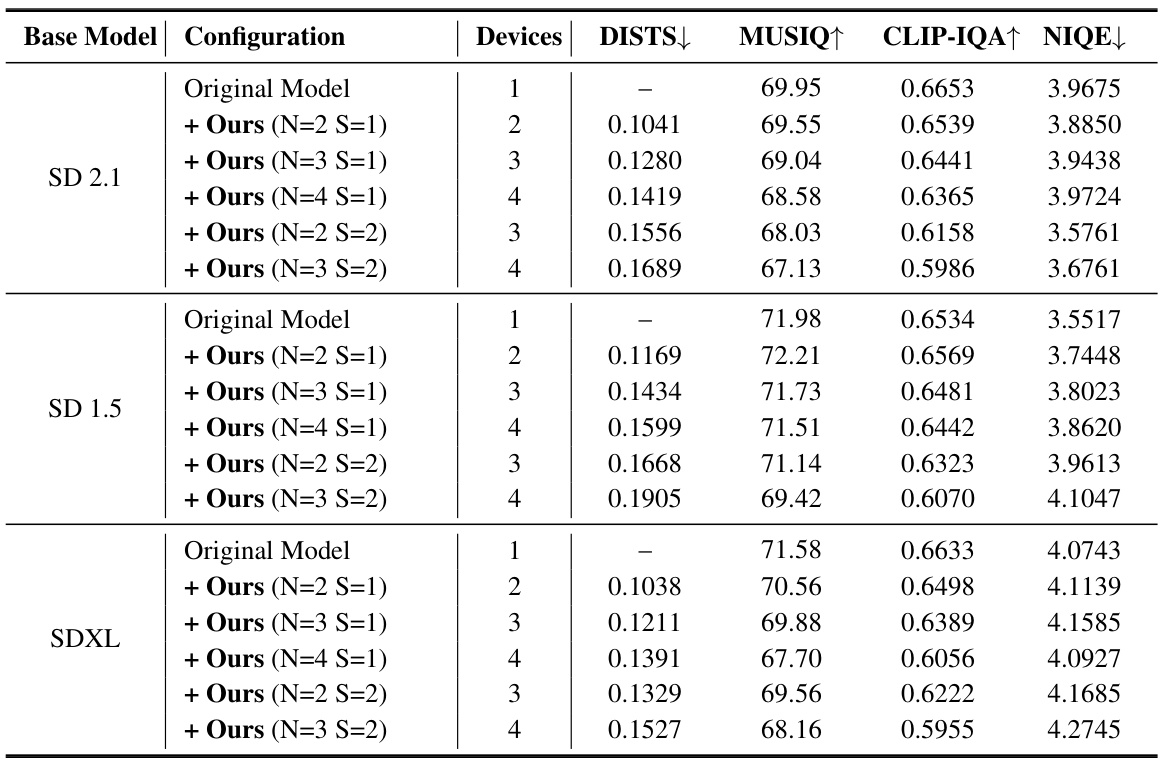
This table presents a quantitative analysis of the AsyncDiff model’s performance on three different text-to-image diffusion models (SD 2.1, SD 1.5, and SDXL). It shows how different model configurations (number of components ‘N’ and denoising stride ‘S’) affect the model’s latency, speedup, CLIP score, FID, and LPIPS metrics across varying numbers of devices. MACs (Multiply-Accumulate operations) provides a measure of computational cost per device.
Full paper#