↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Most existing Automatic Prompt Optimization (APO) methods for text-to-image generation are model-specific, hindering their use with newly emerging models. This necessitates retraining the APO method for each new model, a time-consuming and inefficient process. This paper introduces the problem of Model-Generalized Automatic Prompt Optimization (MGAPO), focusing on training APO methods that generalize well to unseen models.
The paper proposes AP-Adapter, a two-stage method that addresses MGAPO. The first stage uses a large language model for prompt rewriting. The second stage constructs an enhanced representation space using inter-model differences, creating domain prototypes that adapt prompt representations for various models. Experiments demonstrate that AP-Adapter significantly improves both semantic consistency and image quality compared to existing methods, even on unseen models. This method shows the potential for generating high-quality images effectively and efficiently across different diffusion models.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of model generalization in automatic prompt optimization (APO) for text-to-image models. Current APO methods struggle to adapt to new, unseen models. This work introduces a novel solution, improving efficiency and reducing the need for retraining when new models are released. This advancement is highly relevant to researchers working on prompt engineering, diffusion models, and large language model applications. The proposed method opens avenues for more robust and efficient approaches to text-to-image generation.
Visual Insights#
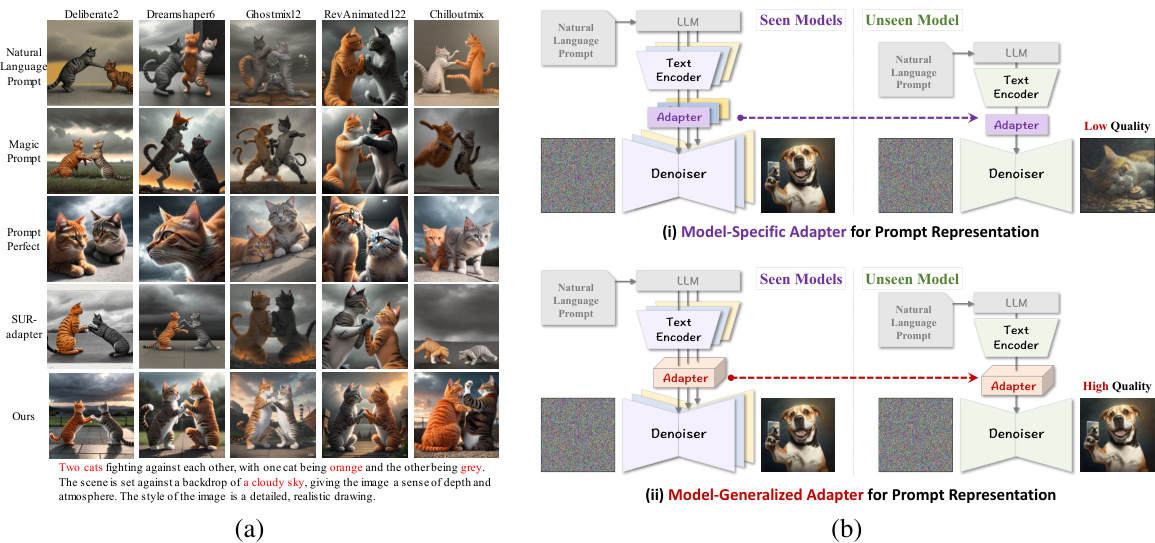
This figure shows a comparison of different Automatic Prompt Optimization (APO) methods’ performance on unseen text-to-image diffusion models. (a) illustrates the generation quality of several APO methods across different models, highlighting their limitations in generalizing to unseen models. (b) contrasts model-specific and model-generalized approaches to prompt adaptation, showcasing the advantages of a generalized approach for improved performance on unseen models. The examples demonstrate that model-generalized adapters achieve higher image quality compared to model-specific adapters when handling unseen models.
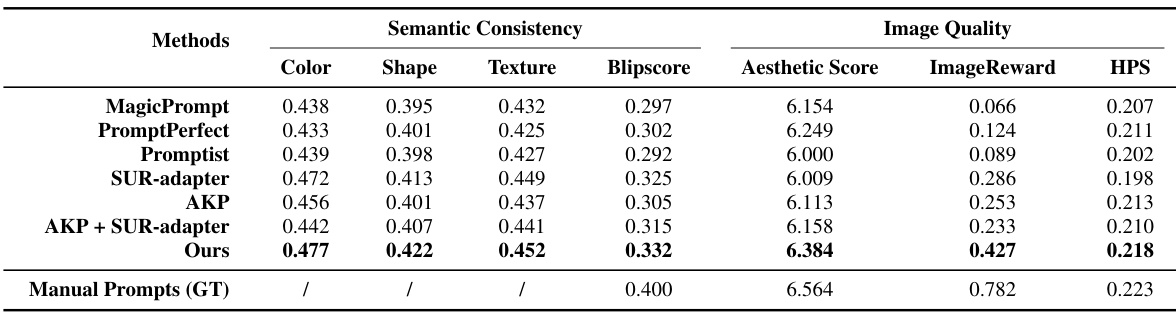
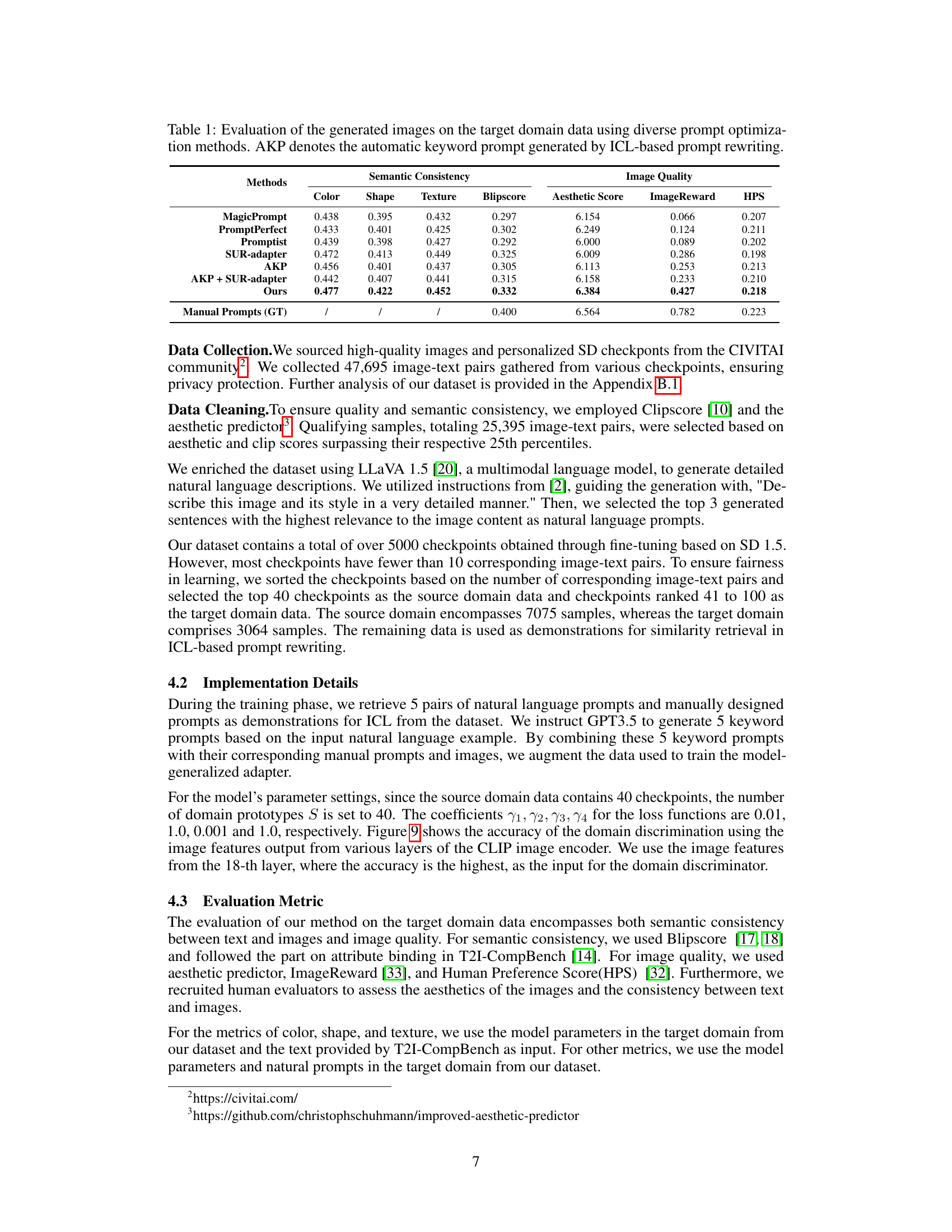
This table presents a quantitative comparison of different prompt optimization methods on their ability to generate high-quality images on unseen diffusion models. The methods are evaluated based on several metrics: semantic consistency (measured by Color, Shape, Texture, and Blipscore), and image quality (measured by Aesthetic Score, ImageReward, and HPS). The results show a comparison between the proposed method and existing methods, with manual prompts serving as the ground truth.
In-depth insights#
MGAPO: A Novel Task#
The proposed task, MGAPO (Model-Generalized Automatic Prompt Optimization), represents a significant advancement in text-to-image generation. It directly addresses the limitations of existing APO methods, which typically struggle with generalization to unseen models. MGAPO’s novelty lies in its shift from model-specific APO to model-generalized APO, training methods on a diverse set of models to foster adaptability to new, unseen models during testing. This tackles the impracticality of retraining APO for every emerging diffusion model. The core challenge of MGAPO involves effectively capturing and leveraging inter-model differences to enable generalization. This requires innovative techniques to manage model-specific information while simultaneously focusing on semantic consistency and aesthetic quality in the generated images, making the creation of a robust, effective MGAPO method an exciting area of research.
AP-Adapter: Two-Stage APO#
The proposed AP-Adapter tackles the challenge of model-generalized automatic prompt optimization (MGAPO) using a two-stage approach. Stage one leverages a large language model (LLM) for in-context learning to rewrite prompts into more effective keyword prompts. This addresses the limitations of existing methods which struggle with unseen models. Stage two introduces a novel method to create an enhanced representation space by leveraging inter-model differences, capturing model characteristics as domain prototypes. These prototypes act as anchors to adjust prompt representations, enabling generalization. The method’s strength lies in its ability to handle the emergence of new diffusion models without retraining, improving both semantic consistency and image quality, as demonstrated experimentally. A key contribution is the creation of a curated multi-modal, multi-model dataset facilitating this model-generalized setting. The AP-Adapter’s two-stage design directly addresses the core challenges of MGAPO, showcasing significant advancements in the field of automatic prompt optimization for text-to-image generation.
Multi-modal Dataset#
A robust multi-modal dataset is crucial for evaluating and advancing the state-of-the-art in text-to-image generation. Such a dataset should ideally include diverse and high-quality images, coupled with corresponding natural language descriptions and, importantly, manually crafted prompts known to yield superior results. Diversity in image styles and subject matter is key, ensuring the model’s ability to generalize across a broad spectrum of visual concepts. Furthermore, the inclusion of multiple diffusion model checkpoints is vital for assessing model generalization capabilities; a system trained solely on a single model is likely to underperform when encountering new model architectures. Careful data curation, including strategies for handling biases and inconsistencies, is paramount. A well-constructed dataset provides valuable insights into the strengths and weaknesses of different prompt optimization techniques, fostering advancements in both automatic prompt generation and model robustness.
Generalization Results#
A dedicated ‘Generalization Results’ section would ideally present a multifaceted analysis of the AP-Adapter’s performance on unseen models. This would go beyond simply reporting quantitative metrics; it should offer a nuanced discussion of how well the method generalizes across various model architectures and data distributions. Key aspects to include would be a comparison against state-of-the-art baselines, demonstrating statistically significant improvements in image quality and semantic consistency. Visual examples showcasing successes and failures of the AP-Adapter on a range of unseen models would be invaluable. An in-depth examination of error modes, analyzing the types of prompts where generalization falters, is crucial. This could reveal underlying limitations of the approach and suggest avenues for future research. The influence of hyperparameters on generalization should also be explored, and any sensitivity analysis performed should be documented. Finally, it is essential to discuss whether performance differences correlate with specific model characteristics, or whether generalization is consistently observed across a diverse set of unseen models.
Future of MGAPO#
The future of Model-Generalized Automatic Prompt Optimization (MGAPO) is bright, promising more efficient and versatile text-to-image generation. Further research should focus on enhancing the robustness of AP-Adapters to handle a wider variety of unseen diffusion models and diverse image styles. This could involve exploring more sophisticated techniques for capturing model-specific characteristics and leveraging larger, more diverse datasets for training. Improving the efficiency of AP-Adapters is also crucial, as current methods can be computationally expensive. This might involve exploring more lightweight architectures or optimization strategies. Addressing the challenges posed by the scarcity of high-quality multi-modal datasets is another key area for future work. Methods for automatically generating or augmenting such datasets, potentially through semi-supervised or unsupervised techniques, could be highly beneficial. Finally, exploring the potential of MGAPO in other text-to-media generation tasks, such as text-to-video or text-to-3D, is a promising avenue for future research. The development of MGAPO holds the key to unlocking truly user-friendly and powerful AI-powered creative tools.
More visual insights#
More on figures

This figure illustrates the two-stage process of the AP-Adapter. The first stage uses in-context learning with a large language model (LLM) to rewrite natural language prompts into keyword prompts. These prompts are then fed into the text encoder of a Stable Diffusion (SD) model. The second stage leverages an adapter module to enhance the keyword prompts by decoding domain-specific content from images. Domain prototypes maintain domain-specific details. The adapter integrates information from text and prototypes, aligning the output with manually crafted prompts in the feature space. The final adapted embedding is used for image generation.

This figure compares the image generation results of different automatic prompt optimization (APO) methods on various unseen Stable Diffusion (SD) models. Each column represents a different APO method (including a novel method called AP-Adapter), and each row shows the results obtained from a specific SD model. The color-coding helps to visualize which SD models were used to train each APO method. The goal is to demonstrate how well each APO method generalizes to unseen SD models, maintaining image quality and semantic consistency.

This figure compares the results of different automatic prompt optimization (APO) methods on a model-generalized automatic prompt optimization (MGAPO) task. Each column represents a different APO method, and each row shows images generated using the same stable diffusion (SD) model. The matching color between columns and rows indicates that the APO model was trained on images from that specific SD model. This visualization effectively demonstrates the generalization capabilities (or lack thereof) of various APO methods when applied to unseen SD models.

This figure showcases a comparison of different automatic prompt optimization (APO) methods’ performance on unseen text-to-image diffusion models. Part (a) illustrates the image generation quality for various models using multiple existing APO methods. Part (b) specifically contrasts the results of a model-specific adapter (trained on a single, fixed model) versus a model-generalized adapter (trained on multiple models), demonstrating the improved generalization capacity of the latter.

This figure illustrates the two-stage process of the AP-Adapter. The first stage uses in-context learning with a large language model (LLM) to rewrite natural language prompts into keyword prompts, which are then fed into the text encoder of a Stable Diffusion model. The second stage improves automatic keyword prompts by decoding domain-specific information from images (using CLIP) and aligning it with manually crafted prompts. Domain-specific information is captured through domain prototypes, which serve as anchors for adjusting the prompt representation. The adapter module then integrates information from text and prototypes to produce a final adapted embedding for generating high-quality images.

This figure shows a comparison of different automatic prompt optimization (APO) methods’ performance on unseen diffusion models. (a) demonstrates how various APO methods perform in generating images from various unseen diffusion models. The results highlight the limitations of existing model-specific methods. (b) compares the performance of model-specific and model-generalized adapters. It emphasizes the challenge of model generalization in APO and highlights the potential of the proposed AP-Adapter.
This figure compares the performance of different automatic prompt optimization (APO) methods on the model-generalized automatic prompt optimization (MGAPO) task. Each column represents a different APO method, and each row shows results from a different stable diffusion (SD) model. The colors of the cells match the SD models used to train the APO models. The image generation quality from each APO model is compared across unseen SD models to demonstrate the ability of the models to generalize.
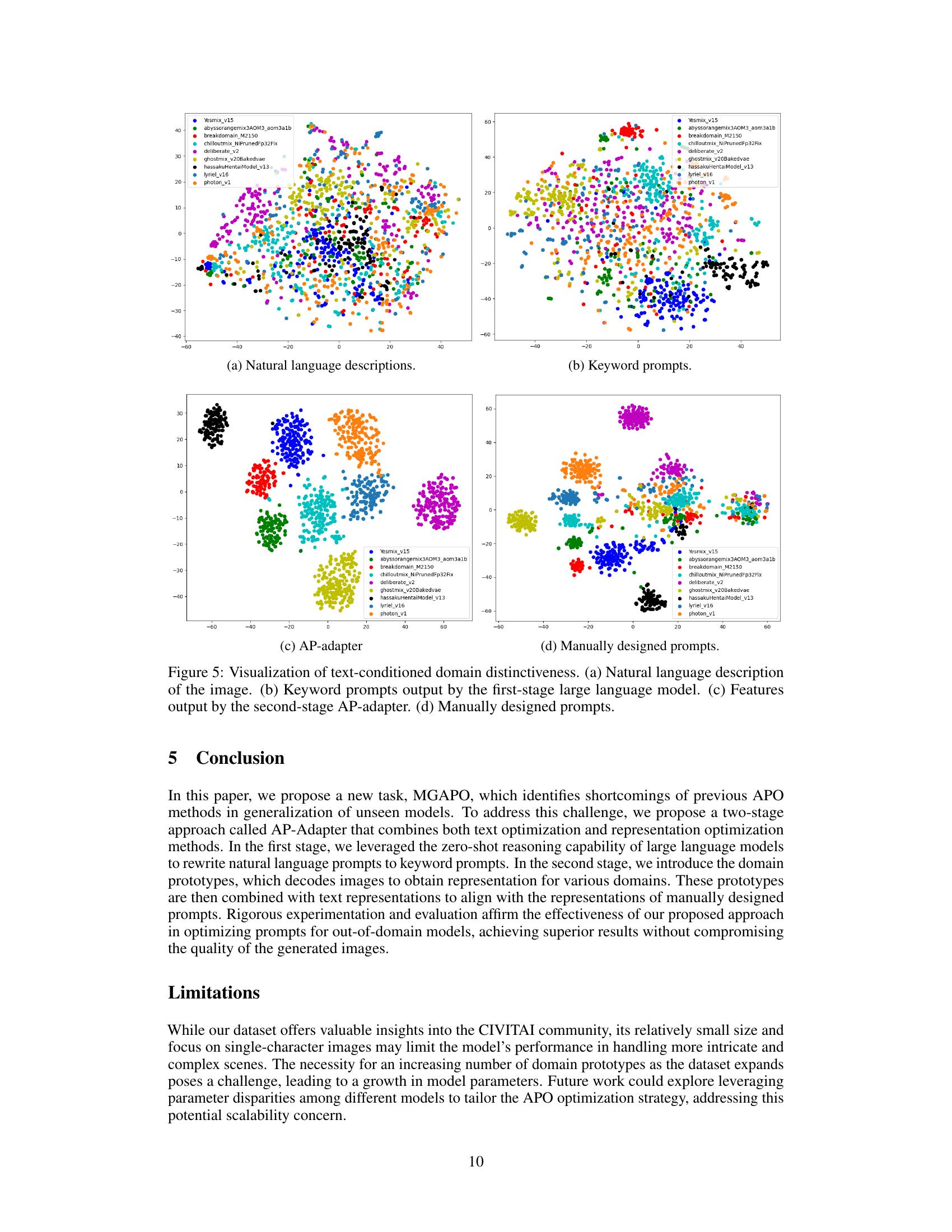
This figure visualizes the domain distinctiveness of different text representations used for image generation. It shows t-SNE plots of (a) natural language descriptions, (b) keyword prompts generated by a large language model, (c) adapted prompt embeddings produced by the AP-Adapter, and (d) manually designed prompts. The plots illustrate how the AP-Adapter improves the domain distinctiveness of the prompts compared to the initial natural language descriptions and keyword prompts, making them more suitable for generalization to unseen models.
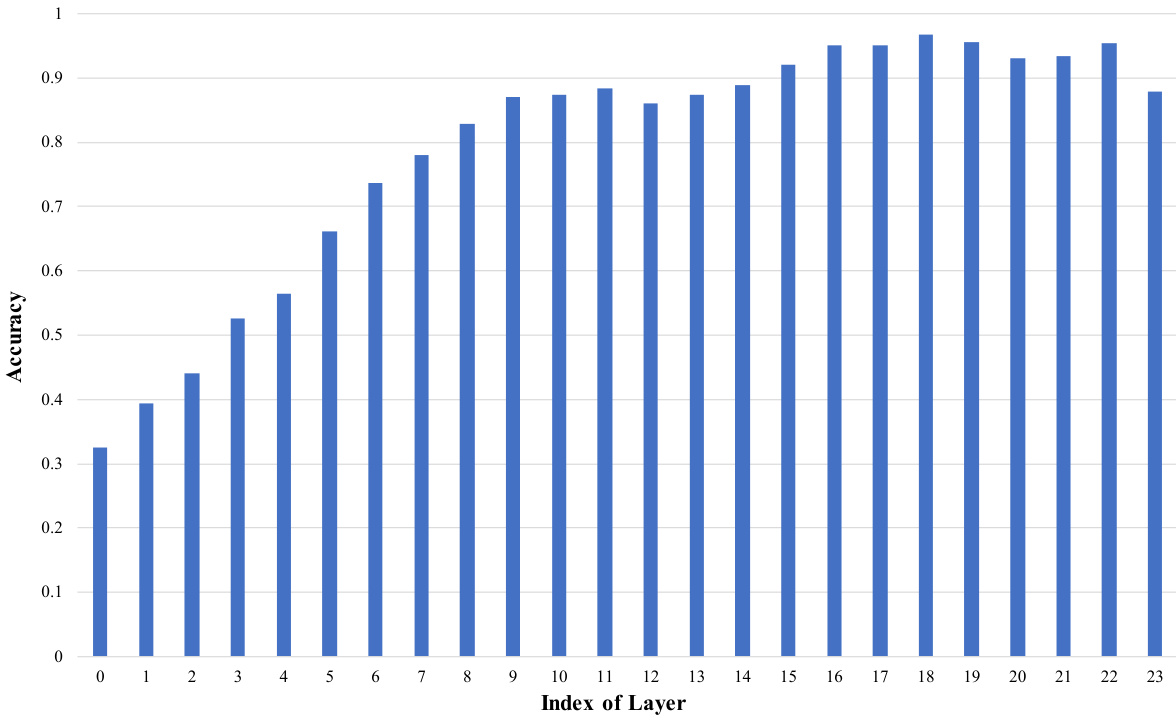
The figure demonstrates the performance of different automatic prompt optimization (APO) methods on unseen text-to-image diffusion models. Panel (a) compares several methods (including the authors’ proposed AP-Adapter) on various models, showcasing their ability to generate high-quality images. Panel (b) focuses specifically on the generalization capabilities of model-specific and model-generalized adapters, highlighting the strengths and weaknesses of each approach when dealing with unseen models.

This figure shows the results of different automatic prompt optimization (APO) methods on the model-generalized automatic prompt optimization (MGAPO) task. Each column represents a different APO method, while each row shows images generated using a specific stable diffusion (SD) model. The color-coding links the APO method and SD model used to generate the images. This visualization demonstrates how well each APO method generalizes to unseen models, highlighting the performance differences between model-specific and model-generalized approaches.

This figure compares the results of different automatic prompt optimization (APO) methods on the model-generalized automatic prompt optimization (MGAPO) task. Each column represents a different APO method, and each row shows images generated by a specific stable diffusion (SD) model. The consistent coloring within rows highlights images generated by the same SD model using various APO methods. This visual comparison emphasizes how each APO method performs differently across various unseen SD models, showcasing their generalization capabilities in the MGAPO setting.

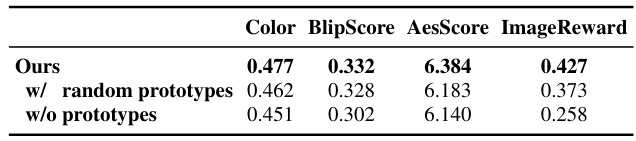
This figure visualizes the impact of linear combinations of domain prototypes on image generation. It shows how blending prototypes from different models (ith and jth models) affects the generated images. The experiment demonstrates the ability of the AP-Adapter to control the style of generated images by adjusting the weights of different domain prototypes. The image rows represent varying linear combinations of the selected ith and jth prototypes, showing style transitions between different model characteristics.

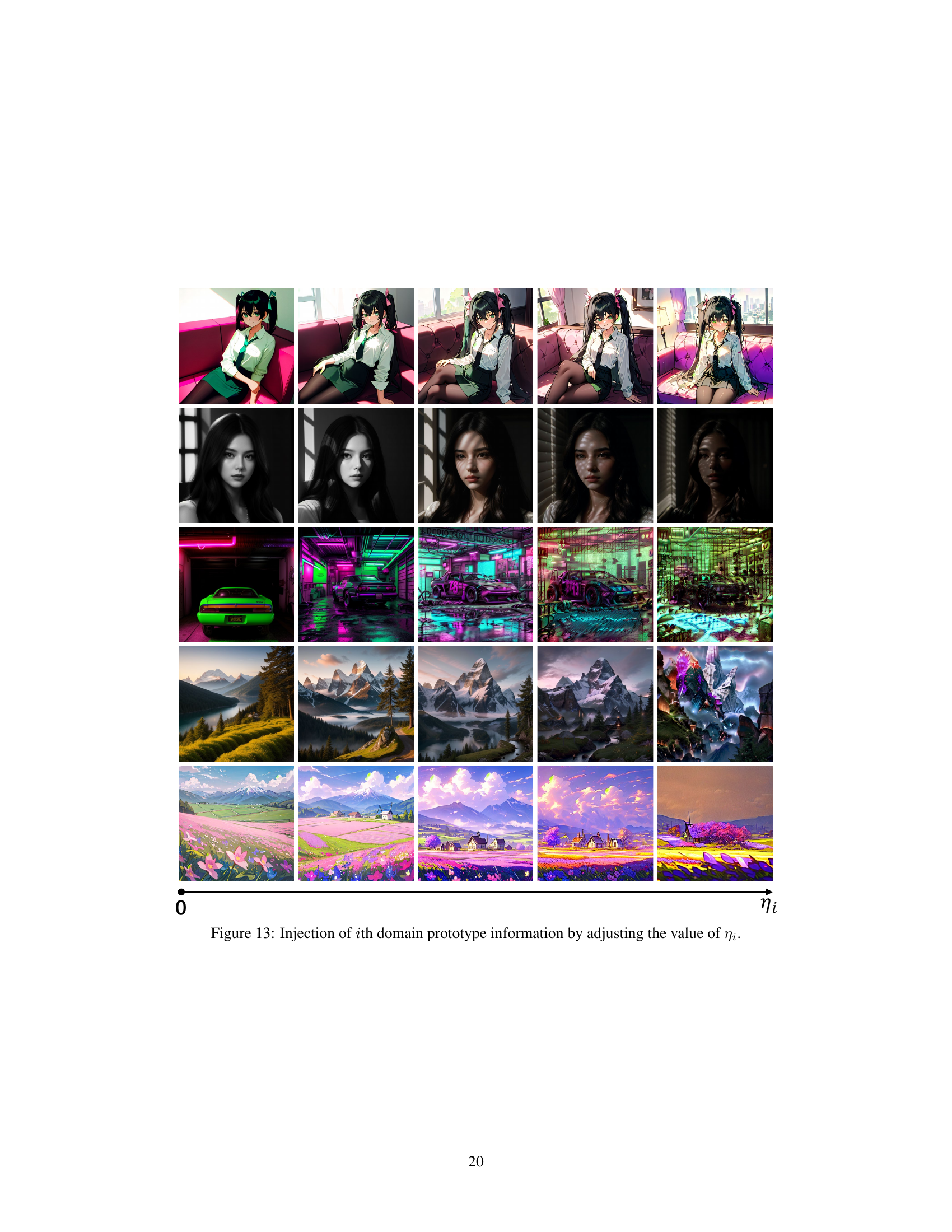
This figure visualizes how injecting different proportions of domain prototype information affects image generation. By modifying the weighting factor (ηi) applied to each domain prototype, the generated images shift in style and characteristics, reflecting the influence of different domain prototypes on the overall image generation process.

This figure shows the results of an ablation study on the loss functions used in the AP-Adapter model. Each column represents a different scenario where one of the loss functions (Lc, La, Lr, Ld) was removed. The final column shows the results when all loss functions are used. The images illustrate the impact of each loss function on the quality and consistency of the generated images, showcasing the importance of each component in achieving optimal results.

This figure compares the results of different automatic prompt optimization (APO) methods on the model-generalized automatic prompt optimization (MGAPO) task. Each column represents a different APO method, and each row shows images generated using a specific Stable Diffusion (SD) model. The color-coding helps to visualize which APO method was trained on which SD model; methods with the same color and row were trained on the same SD model. This allows for a direct comparison of how well different APO methods generalize to unseen SD models.

This figure shows the results of an ablation study on the loss functions used in the AP-Adapter model. Each row represents a different prompt and shows the images generated when different loss functions are removed. The purpose is to demonstrate the individual contribution of each loss function to the overall image quality and to highlight the importance of using all loss functions for optimal performance.

Figure 1(a) shows the results of several Automatic Prompt Optimization (APO) methods applied to various unseen diffusion models, highlighting the differences in image quality and semantic consistency. Figure 1(b) directly compares a model-specific approach to the proposed model-generalized approach for APO, demonstrating the improved generalization ability of the latter on unseen models.
More on tables
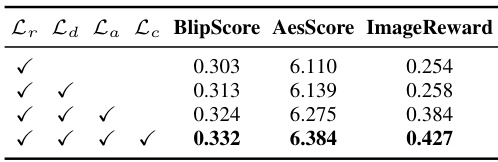
This table presents the results of an ablation study on the loss functions used in the AP-Adapter model. It shows the impact of removing each loss function individually (Lr, Ld, La, Lc) on the model’s performance, as measured by BlipScore, AesScore, and ImageReward. The results demonstrate the importance of each loss function for achieving optimal performance. The row with all loss functions checked represents the full model’s performance, providing a benchmark to compare against the individual ablation results.
This table presents a comparison of different automatic prompt optimization (APO) methods on the task of generating images for unseen text-to-image diffusion models. The methods are evaluated based on several metrics assessing both semantic consistency and image quality. The metrics include semantic consistency (Color, Shape, Texture, Blipscore, Aesthetic Score), and image quality (ImageReward, HPS). The table shows that the proposed AP-Adapter method outperforms other APO methods in terms of both semantic consistency and image quality.

This table presents a quantitative comparison of different automatic prompt optimization (APO) methods on unseen diffusion models. The evaluation metrics cover both semantic consistency (how well the generated image matches the prompt’s meaning) and image quality (aesthetic appeal, color, shape, and texture). The methods compared include popular techniques like MagicPrompt, PromptPerfect, and SUR-adapter, along with an intermediate step using only automatically generated keyword prompts (AKP) and a combination of AKP and SUR-adapter. The final row shows results for manually crafted prompts, serving as a ground truth for comparison.
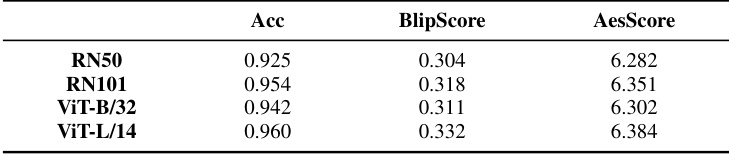
This table presents the results of an ablation study comparing different backbones of the CLIP image encoder on the performance of the AP-Adapter model. The backbones tested were RN50, RN101, ViT-B/32, and ViT-L/14. The table shows the accuracy of domain discrimination (Acc) achieved by each backbone, along with the BlipScore and AesScore of the generated images. These metrics evaluate the semantic consistency and aesthetic quality of the generated images respectively.
Full paper#