↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current video editing methods using pre-trained text-to-image diffusion models struggle to maintain temporal consistency in edited videos due to a lack of temporal constraints. This leads to inconsistencies such as flickering and blurring in the output, hindering the generation of high-quality edited videos. Existing solutions often rely on additional components or extra training, adding to complexity and resource demands.
The proposed COVE method directly addresses this issue by utilizing the inherent correspondence information within diffusion features. A novel sliding-window-based strategy is introduced to efficiently compute similarity among tokens, identifying those with high correspondence across frames. This correspondence information is then used to guide the inversion and denoising process, ensuring temporal coherence. COVE seamlessly integrates into existing T2I diffusion models, requiring no extra training, and demonstrates state-of-the-art performance in both quality and temporal consistency of edited videos.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses a critical challenge in video editing: maintaining temporal consistency. By introducing a novel correspondence-guided approach using inherent diffusion features, it significantly improves the quality and consistency of generated videos, paving the way for more realistic and high-quality video editing applications. The method is efficient and readily integrable into existing diffusion models, broadening its potential impact on the field. This opens new avenues for research into temporal modeling in diffusion-based video generation and editing.
Visual Insights#

This figure shows examples of video editing results using the proposed COVE method. The top row displays the original source videos. The bottom rows demonstrate various video editing results using different text prompts. These prompts cover style changes, object replacement, and background changes, showcasing the method’s versatility and ability to maintain temporal consistency.
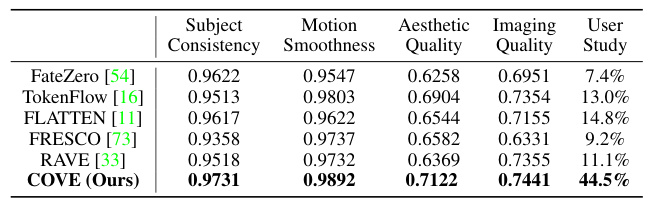
This table presents a quantitative comparison of COVE with five state-of-the-art video editing methods using four metrics from VBench [31]: Subject Consistency, Motion Smoothness, Aesthetic Quality, and Imaging Quality. It also includes the results of a user study comparing user preference for the different methods. COVE demonstrates superior performance across all metrics, particularly in user preference.
In-depth insights#
Diffusion Feature Corr.#
The heading ‘Diffusion Feature Corr.’ likely refers to a method leveraging the inherent correspondence within diffusion model features for a specific task, probably video editing or image manipulation. The core idea revolves around exploiting the semantic similarity between feature tokens across different frames (in video) or image regions. By identifying these correspondences, the method likely aims to achieve more consistent and coherent results, be it style transfer, object manipulation, or inpainting. Calculating this correspondence efficiently is crucial, potentially using techniques like sliding window approaches or other similarity metrics to avoid computationally expensive global comparisons. The effectiveness hinges on the richness and precision of the diffusion features, and the quality of the correspondence information directly impacts the final result’s quality and temporal consistency. This technique likely outperforms methods relying on external cues like optical flow, as it leverages intrinsic information directly from the diffusion process. Overall, ‘Diffusion Feature Corr.’ suggests a novel and potentially powerful approach to improve the fidelity and coherence of diffusion-model based tasks.
COVE Architecture#
A hypothetical “COVE Architecture” for consistent video editing would likely involve three core modules: a feature extraction module to derive meaningful representations from video frames (perhaps using a pre-trained diffusion model), a correspondence estimation module to identify and track consistent features across frames (potentially employing a sliding window approach and cosine similarity to handle one-to-many correspondences efficiently), and a video generation module that leverages the correspondence information to guide the editing process within a diffusion model (incorporating correspondence-guided attention mechanisms to maintain temporal consistency during inversion and denoising). The architecture’s design would prioritize computational efficiency by employing techniques like sliding windows to reduce unnecessary calculations, and would aim for seamless integration with existing pre-trained diffusion models, requiring no extra training. Temporal consistency is the central goal, and the architecture would be evaluated based on metrics like visual quality and temporal coherence of generated edits.
Temporal Consistency#
Maintaining temporal consistency is a critical challenge in video editing, especially when leveraging pre-trained text-to-image diffusion models. These models excel at single-image manipulation but often struggle to maintain coherence across video frames, resulting in inconsistencies like flickering or blurring. The core problem lies in the lack of inherent temporal constraints within standard diffusion models. Therefore, methods focusing on explicitly addressing temporal consistency are crucial. This might involve incorporating techniques like optical flow to track motion across frames or utilizing novel attention mechanisms that consider temporal context during the generation process. The success of such methods hinges on effectively modeling and utilizing correspondence information between frames to ensure smooth transitions and maintain the integrity of dynamic elements within the edited video. High-quality video editing necessitates a delicate balance between stylistic changes dictated by the user’s prompts and the preservation of fluid, natural motion across the video’s temporal dimension.
Ablation Experiments#
Ablation experiments systematically remove components of a model to understand their individual contributions. In a video editing context, this might involve removing or modifying elements such as the correspondence calculation method, attention mechanism, or token merging strategy. By observing how performance metrics (e.g., temporal consistency, visual quality) change with each ablation, researchers can gain valuable insights into the effectiveness and relative importance of different components. A well-designed ablation study provides strong evidence for the claims made in the paper, ruling out alternative explanations for the model’s performance. For instance, if removing correspondence calculation leads to significantly worse temporal consistency, it strongly suggests the importance of this feature. Conversely, if a module’s removal causes minimal performance degradation, it implies its lesser contribution and might be pruned for efficiency. Careful analysis of ablation results often unveils unexpected interactions between different modules, highlighting areas for improvement or future research. The results might show that certain components are crucial for high performance, while others are redundant or even detrimental, enabling a more streamlined and effective model design.
Future Directions#
Future research directions for correspondence-guided video editing could explore more sophisticated correspondence models that go beyond simple cosine similarity. This might involve leveraging advanced techniques like optical flow or transformer-based methods to capture more nuanced relationships between frames. Investigating different diffusion models and their inherent correspondence properties is also crucial. Exploring the use of alternative attention mechanisms beyond self-attention, such as cross-attention or graph neural networks, could potentially improve temporal consistency and quality. Furthermore, research could focus on scaling these methods to handle longer videos and higher resolutions, which is a significant challenge for current video editing techniques. Finally, a deeper analysis of the role of hyperparameters and their impact on the quality of the final videos is needed for robust and reliable editing.
More visual insights#
More on figures
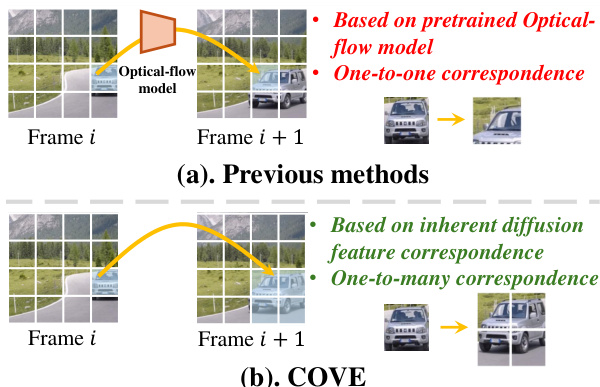
This figure compares the approach of COVE with previous methods for obtaining correspondence information among tokens across frames in video editing. Previous methods rely on pretrained optical flow models to establish a one-to-one correspondence between tokens in consecutive frames. COVE, in contrast, leverages the inherent diffusion feature correspondence, enabling a more accurate one-to-many correspondence, which is more robust in capturing complex temporal relationships.
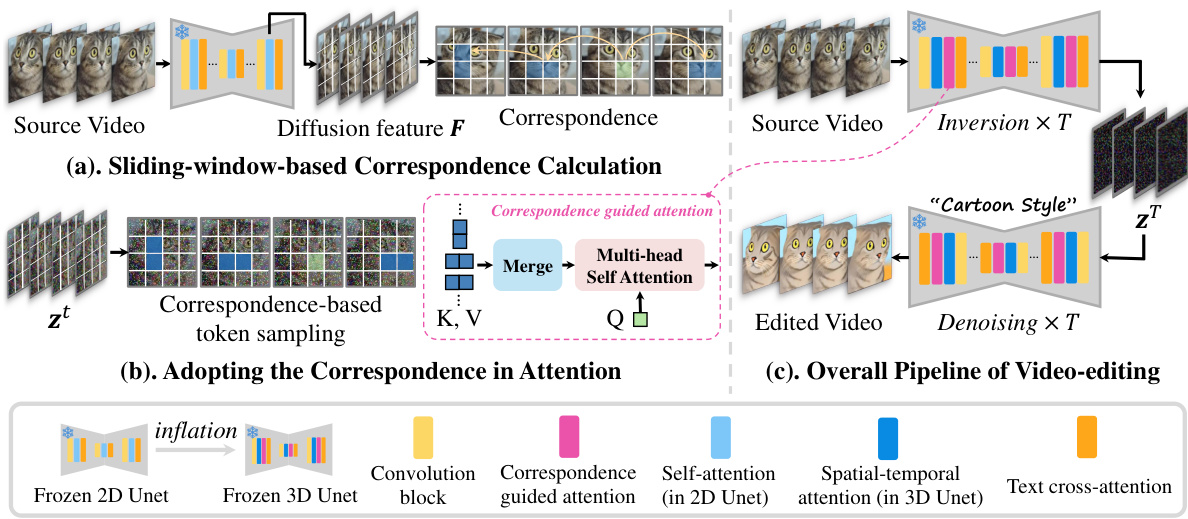
This figure illustrates the overall pipeline of the COVE model for video editing. It shows three main stages: (a) correspondence calculation using a sliding-window based approach on the diffusion features, (b) utilizing this correspondence information for guided attention and token merging within the self-attention mechanism during the inversion process, and (c) the overall video editing pipeline integrating the correspondence-guided attention into a pre-trained text-to-image diffusion model. The subfigures break down the process into more manageable steps, highlighting the key components and their interactions.
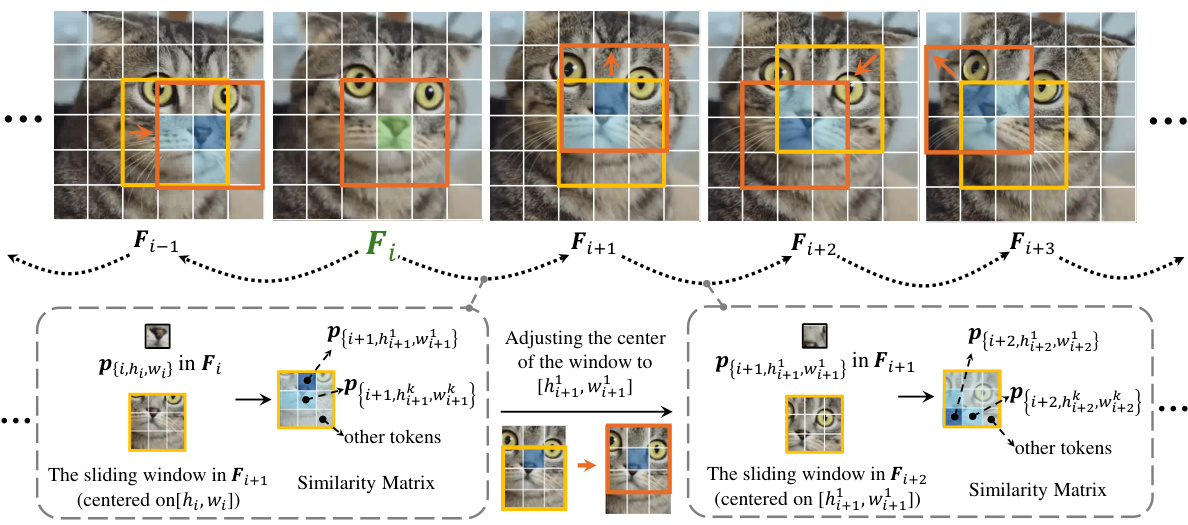
This figure illustrates the sliding-window-based strategy used for efficient correspondence calculation in the COVE model. It shows how, instead of comparing a token in one frame to every token in every other frame (computationally expensive), the algorithm only compares it to tokens within a small window in the adjacent frames. This significantly reduces computational cost while still effectively capturing temporal correspondence information. The figure uses a visual example of a cat’s face across multiple frames to depict the process, highlighting how the window center adjusts frame by frame, focusing on the most similar regions between frames.

This figure showcases various examples of video editing results achieved by the COVE model. Each row presents a source video and its edited versions based on different prompts which include style transfer (e.g., Van Gogh style, Cartoon style), background changes (e.g., snowy winter, milky way), and object transformations (e.g., teddy bear to raccoon). The results highlight the model’s ability to maintain both high visual quality and temporal consistency across diverse editing tasks.

This figure showcases a qualitative comparison between the proposed COVE method and five other state-of-the-art video editing methods (FateZero, RAVE, FRESCO, TokenFlow, and FLATTEN). The comparison is done across three different source videos and editing prompts, highlighting COVE’s superior performance in terms of visual quality and temporal consistency.
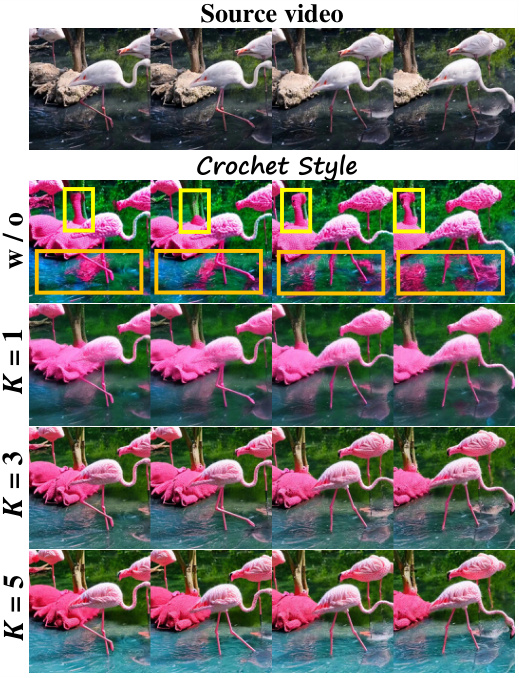
This figure shows the ablation study on the correspondence-guided attention and the effect of parameter K. The top row shows the source video. The second row shows the results without correspondence-guided attention, highlighting the flickering artifacts. The following rows (K=1, K=3, K=5) show the results with correspondence-guided attention and different values of K, demonstrating that increasing K improves the visual quality up to a certain point, after which further increases yield diminishing returns.

This figure shows a comparison of video editing results with and without temporal dimensional token merging. The top row displays the source video frames. The second row shows the edited video frames without token merging, exhibiting some inconsistencies. The bottom row presents the edited video frames with token merging, demonstrating that the merging process does not negatively impact the quality of the results.

This figure shows the ablation study on the window size (l) in the sliding-window-based strategy for correspondence calculation. It compares the results of using different window sizes (l=3, l=9) and without using the sliding window strategy (w/o). The results demonstrate the impact of the window size on the quality of the edited video, showing that a window size of 9 strikes a balance between accuracy and efficiency.

This figure visualizes how the sliding-window-based method identifies corresponding tokens across frames in a long video. It uses a specific token in the first frame as a reference and highlights its corresponding tokens (marked in yellow, green, and blue) in subsequent frames. This demonstrates the accuracy of the method in establishing correspondence for video editing.
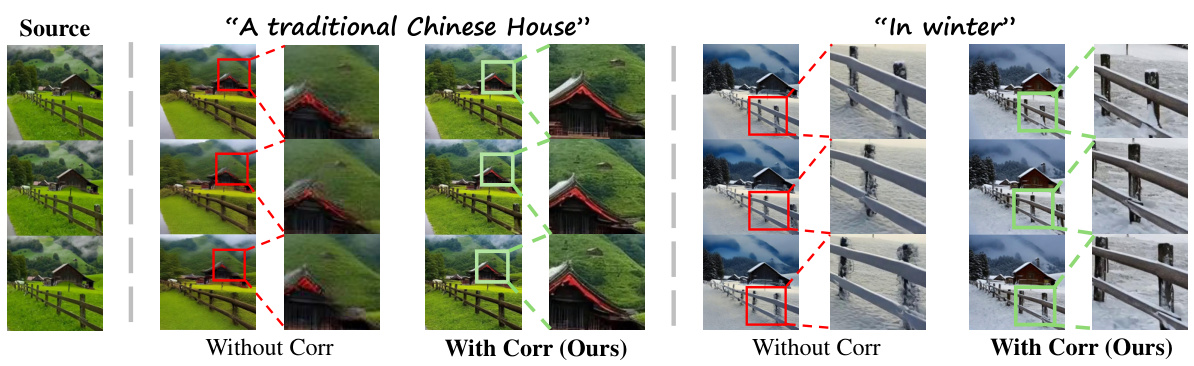
This figure shows an ablation study on the impact of correspondence-guided attention during the inversion process in video editing. The left side demonstrates results without correspondence-guided attention, where videos show blurring and flickering effects, indicating reduced temporal consistency. In contrast, the right side presents results with correspondence-guided attention applied in both inversion and denoising stages. These results exhibit improved visual quality and temporal consistency, demonstrating the effectiveness of the proposed method.

This figure shows several example results of applying the COVE method to various videos. Each row represents a different video and prompt, demonstrating the model’s ability to generate high-quality results for a wide range of prompts. The results include style transfers (e.g., Van Gogh, comic book styles) and background changes, indicating the model’s versatility.

This figure shows several examples of video editing results using the proposed method (COVE). Each row shows a different source video and the results of applying several different editing prompts (e.g. changing the style or appearance of the person or object in the video). The goal is to demonstrate that COVE can be used to generate high-quality videos with a variety of editing prompts while maintaining temporal consistency.
More on tables
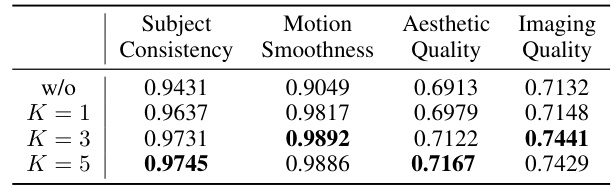
This table presents the results of an ablation study on the impact of the number of tokens (K) used in correspondence-guided attention on video quality. It compares different values of K (1, 3, and 5) against a baseline (w/o) where correspondence-guided attention is not used. The metrics used are Subject Consistency, Motion Smoothness, Aesthetic Quality, and Imaging Quality. The results show that increasing K from 1 to 3 improves all metrics, but further increasing K to 5 provides only minimal gains.
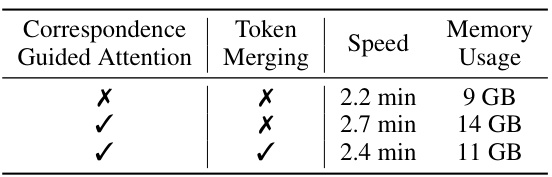
This table presents the results of an ablation study on the impact of temporal dimensional token merging in the video editing process. The study compared three different configurations: (1) without correspondence-guided attention and without token merging; (2) with correspondence-guided attention but without token merging; and (3) with both correspondence-guided attention and token merging. The metrics used for comparison were speed and GPU memory usage. The results show that token merging significantly improves speed and reduces GPU memory usage without substantial loss in video quality.
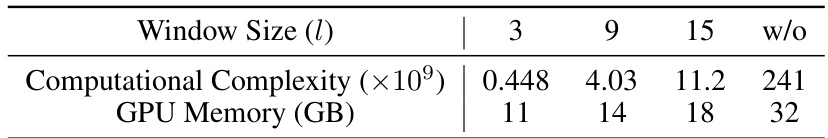
This table quantitatively compares COVE against five state-of-the-art video editing methods across multiple metrics. The metrics used assess subject consistency, motion smoothness, aesthetic quality, and imaging quality. COVE shows superior results in all four categories, demonstrating improved temporal consistency and higher overall quality compared to existing methods.

This table presents the accuracy (PCK) of correspondence obtained using two different methods: Optical-flow Correspondence and Diffusion feature Correspondence. The diffusion feature correspondence method demonstrates higher accuracy (0.92) compared to the optical-flow method (0.87). This highlights the superior precision of using diffusion features for identifying corresponding tokens in video frames.
Full paper#



















