↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
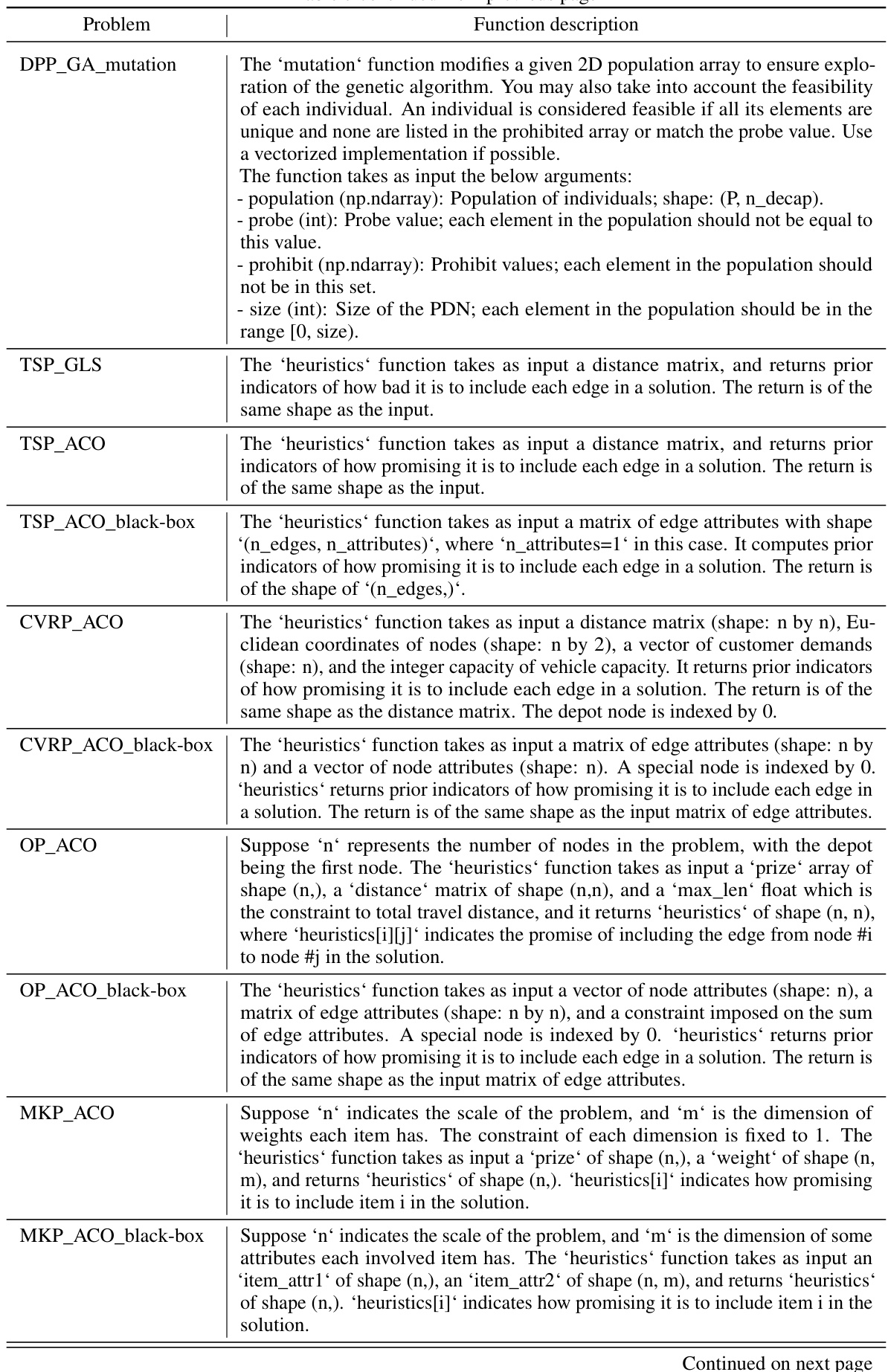
Many real-world problems involve NP-hard combinatorial optimization problems (COPs), requiring laborious heuristic designs by domain experts. Automating this process has been a longstanding challenge, with traditional hyper-heuristics limited by pre-defined heuristic spaces. Large language models (LLMs) offer new possibilities but often lack reasoning and sample efficiency.
ReEvo addresses these issues by integrating evolutionary search with LLM reflections. This enables efficient exploration of open-ended heuristic spaces and provides verbal gradients for improved LLM guidance. ReEvo achieves state-of-the-art performance across multiple COPs and algorithmic types, demonstrating superior sample efficiency. Its application to diverse problems showcases its potential to transform the field of combinatorial optimization, paving the way for more automated and efficient solution generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in combinatorial optimization and AI. It demonstrates a novel approach using LLMs to automate heuristic design, a significant advancement over traditional methods. The results are strong and the approach has wide applicability, opening new avenues for research in AI-driven optimization, and improving the sample efficiency of LLM-based approaches.
Visual Insights#
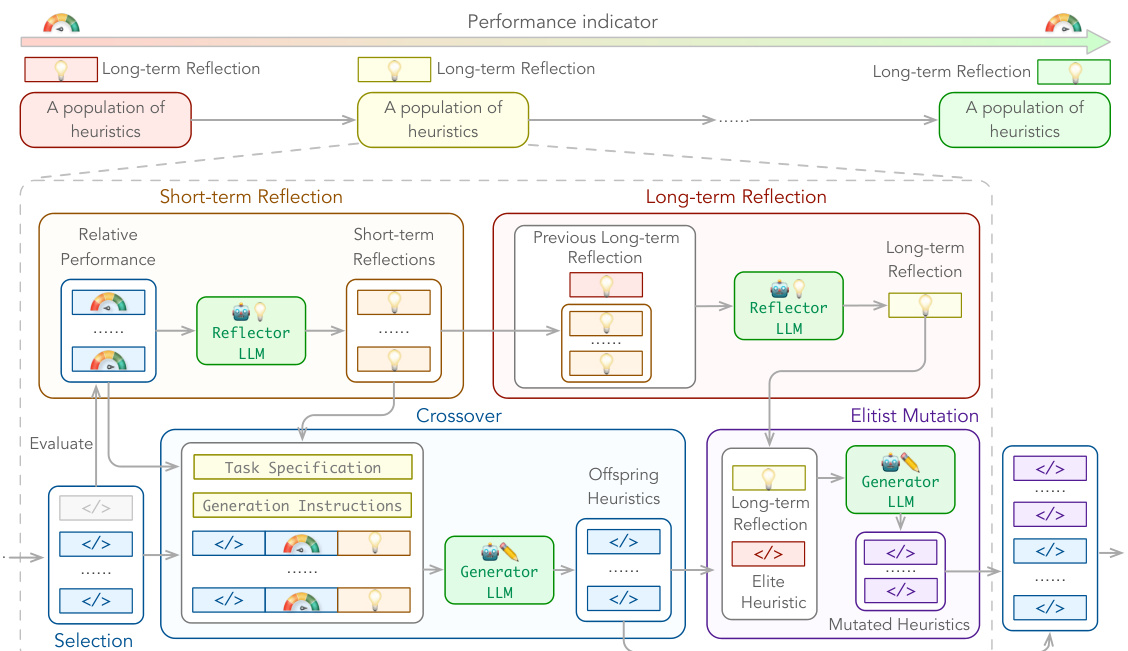
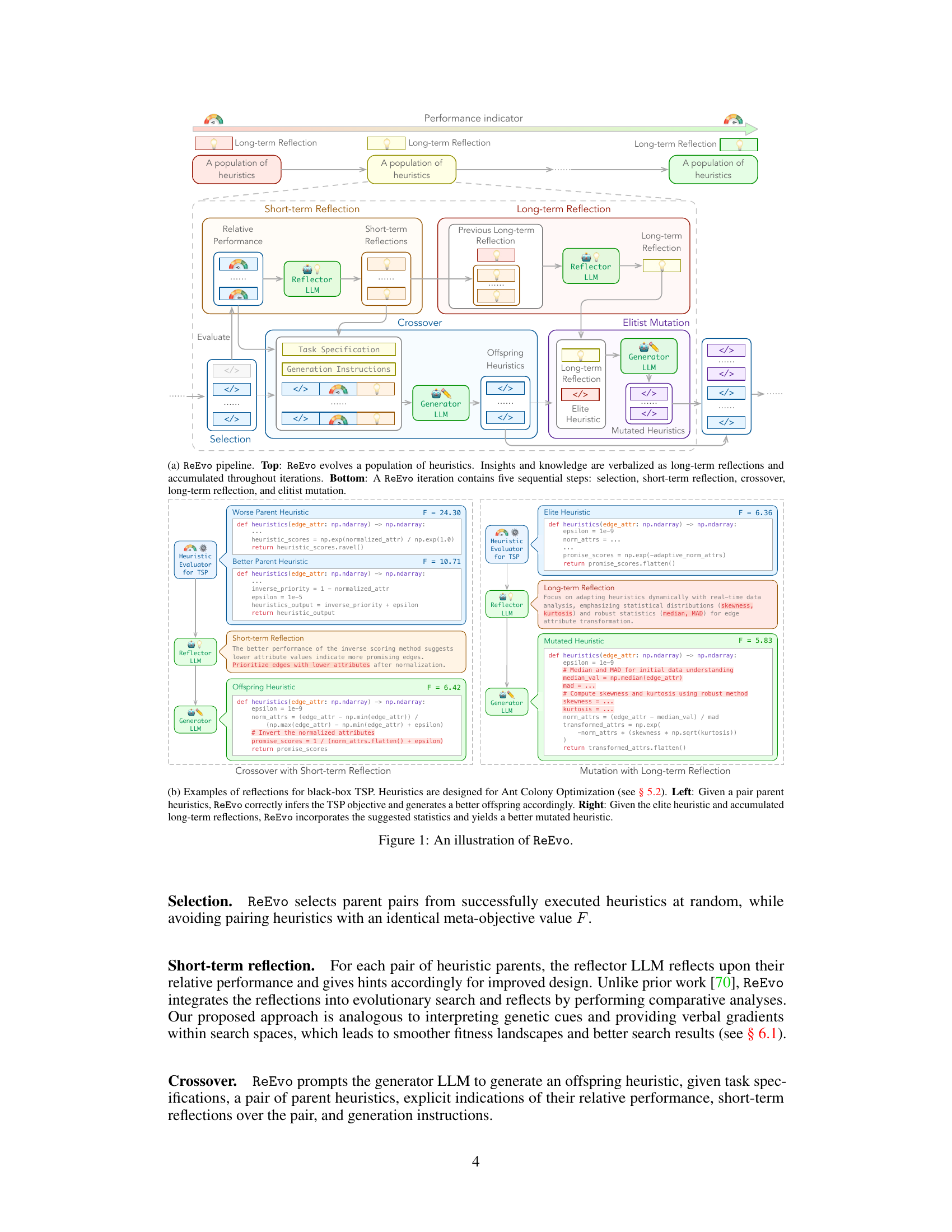
The figure illustrates the ReEvo pipeline, showing how it evolves a population of heuristics using LLMs as a generator and a reflector. The generator LLM produces heuristic code snippets, while the reflector LLM analyzes their performance and provides verbal gradients to guide the evolution. The process involves iterative steps of selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The dual-level reflections (short-term and long-term) enhance heuristic search and verbal inference. Examples of short-term and long-term reflections with specific code snippets from a TSP application are shown.

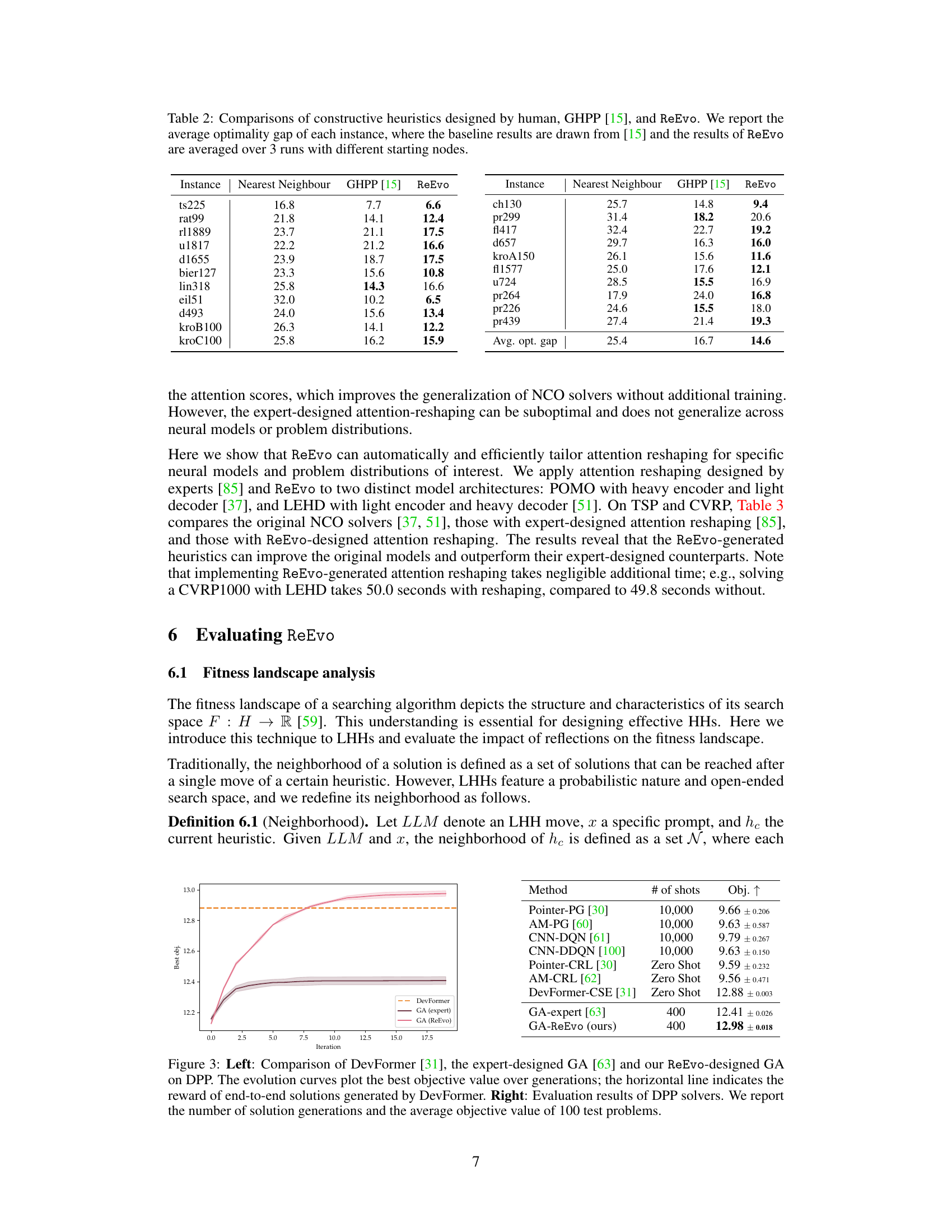
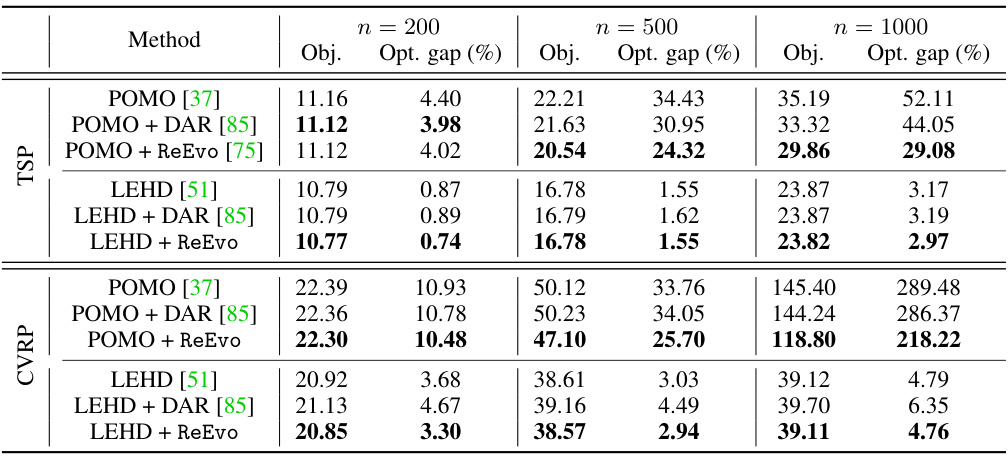
This table presents a comparison of different local search (LS) methods, including the optimality gap and the per-instance execution time for solving the Traveling Salesman Problem (TSP) with different problem sizes (TSP20, TSP50, TSP100, TSP200). The methods compared include various types of Guided Local Search (GLS) approaches, a reinforcement learning approach (NeuOpt), and the proposed method (KGLS-ReEvo). The results show the improvement in solution quality and efficiency achieved by the proposed approach.
In-depth insights#
LHH: LLMs for Heuristics#
The concept of using Large Language Models (LLMs) to generate heuristics, termed Language Hyper-Heuristics (LHHs), presents a paradigm shift in combinatorial optimization. This approach moves away from manually designed heuristics, leveraging the LLMs’ ability to generate diverse and novel solutions. The power of LHHs lies in their potential to automate the heuristic design process, thus overcoming the limitations of traditional methods. However, challenges remain; sample efficiency is a key concern as LLMs may require numerous iterations to produce effective heuristics. Furthermore, reliable evaluation of LLM-generated heuristics is crucial and requires methods to assess their performance in diverse, complex scenarios. Successfully addressing these challenges will unlock the full potential of LHHs, leading to a new era of efficient and adaptable combinatorial optimization.
ReEvo: Reflective Evolution#
ReEvo: Reflective Evolution presents a novel approach to hyper-heuristics, integrating evolutionary algorithms with large language models (LLMs). The core idea is to leverage LLMs not just for heuristic generation, but also for providing insightful reflections on the performance of different heuristics, guiding the evolutionary process. This reflective feedback mechanism mimics human expert behavior, offering verbal gradients during the search and potentially leading to faster convergence. The framework’s strength lies in its sample efficiency, outperforming prior LLM-based approaches across diverse combinatorial optimization problems and algorithmic types. While promising, limitations remain, particularly the reliance on sufficiently capable LLMs and the scalability to more extensive search spaces. Future work should investigate the impact of LLM architecture, prompting strategies, and the exploration of diverse fitness landscapes.
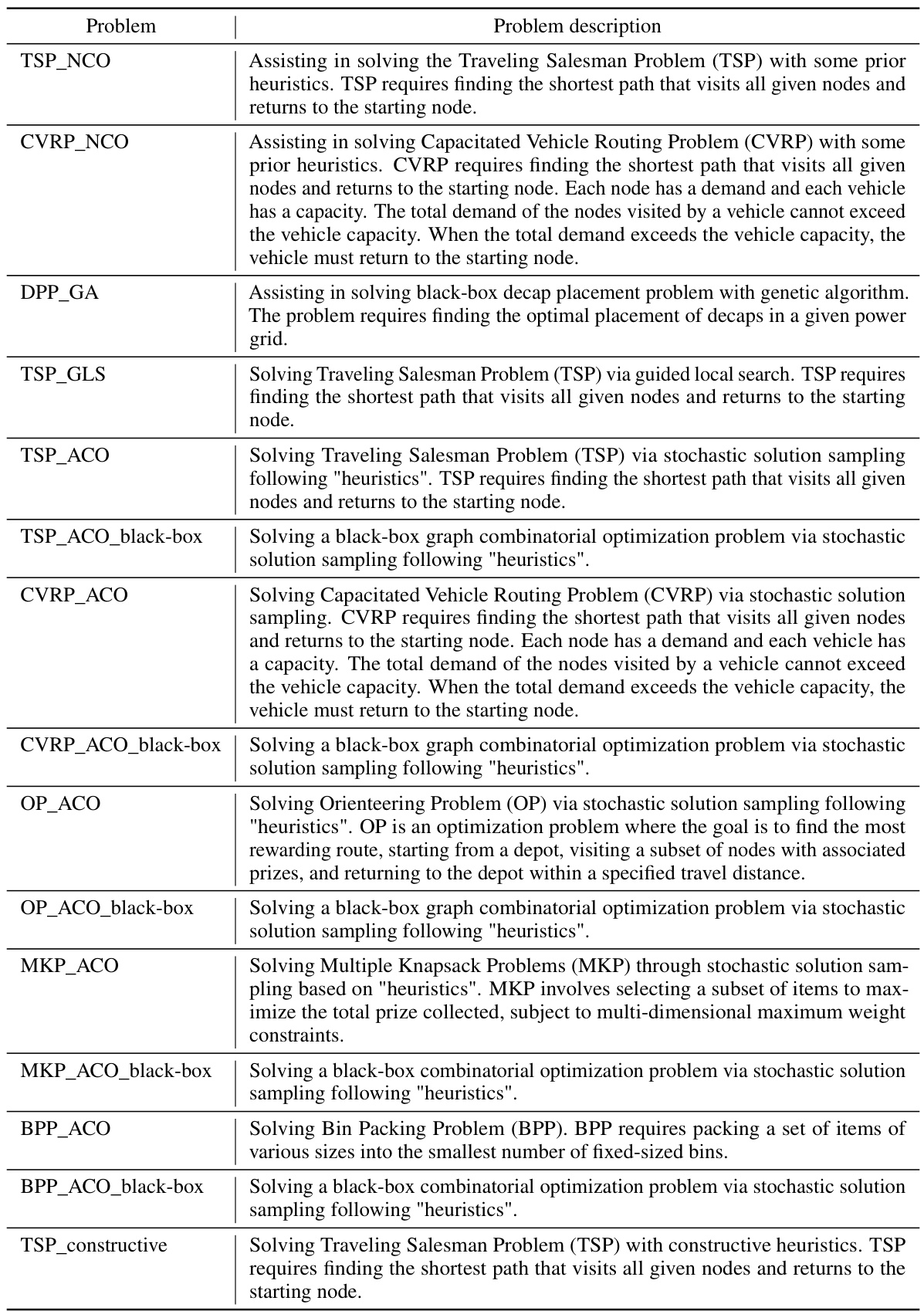
Benchmark COPs Solved#
The heading ‘Benchmark COPs Solved’ suggests a section detailing the types of combinatorial optimization problems (COPs) successfully tackled by the proposed method. A strong presentation would list the specific COPs (e.g., Traveling Salesman Problem, Quadratic Assignment Problem, etc.), highlighting their NP-hard nature and practical significance. Furthermore, the description should specify how these COPs were benchmarked, possibly including the datasets used, evaluation metrics (optimality gap, solution time, etc.), and a comparison to existing state-of-the-art methods. This level of detail is crucial for assessing the method’s generalizability and practical applicability. Crucially, the selection of benchmark COPs is itself a key aspect – a good selection will demonstrate the method’s effectiveness on diverse problem types, while a weak one may limit its impact. Therefore, the discussion should justify the chosen benchmarks, explaining why they represent a comprehensive and challenging test set. Finally, quantitative results showing the method’s performance on each benchmark are essential to understand the method’s true capabilities.
Fitness Landscape Analysis#
Fitness landscape analysis is a crucial aspect of evaluating the effectiveness of search algorithms, especially within the context of hyper-heuristics and evolutionary computation. Analyzing the fitness landscape provides valuable insights into the difficulty of a problem, by revealing its ruggedness or smoothness. A rugged landscape, characterized by many local optima, is challenging for algorithms to navigate, whereas a smooth landscape facilitates efficient exploration and exploitation. The paper’s discussion of fitness landscapes in relation to Language Hyper-Heuristics (LHHs) is particularly insightful. By defining neighborhood in terms of LLM-generated heuristics and utilizing autocorrelation, the authors offer a novel method for characterizing the heuristic search space. This approach considers the probabilistic nature of LLMs and their open-ended heuristic generation capabilities, overcoming limitations of traditional HH fitness landscape analyses. The impact of reflections (short-term and long-term) on the fitness landscape is a key contribution, revealing how these reflections contribute to a smoother landscape, thus enhancing search efficiency. This finding underscores the symbiotic relationship between LLMs and evolutionary computation within the ReEvo framework.
Future of LHH Research#
The future of Language Hyper-Heuristics (LHH) research is brimming with potential. Improved LLM capabilities will be crucial, enabling more sophisticated heuristic generation and reflection. Enhanced reflection mechanisms are needed to refine the verbal gradients and guide LHHs more effectively. Hybrid approaches that combine LHHs with other optimization methods, like neural combinatorial optimization, promise significant advancements. Benchmarking methodologies need further development to reliably compare LHHs across diverse problems and LLMs. Finally, exploring the ethical implications of using LLMs for automated heuristic design will be vital, as it directly affects the trustworthiness and fairness of systems using LHH-generated heuristics. The research should focus on developing robust, reliable, and ethical methods for various applications.
More visual insights#
More on figures
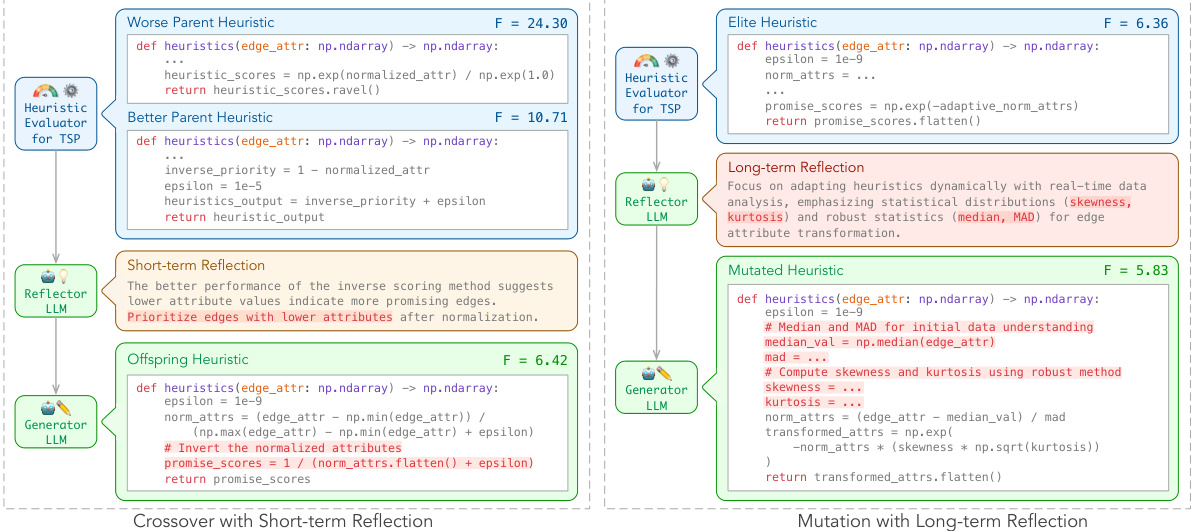
This figure shows a schematic illustration of the ReEvo pipeline. The top part illustrates the overall process of evolving a population of heuristics, with verbalized insights and knowledge accumulated as long-term reflections across iterations. The bottom part details a single ReEvo iteration, highlighting the five sequential steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Examples of short-term and long-term reflections are also shown, demonstrating how ReEvo uses LLMs to interpret genetic cues from evolutionary search and provide verbal gradients within the search space, improving heuristic design.
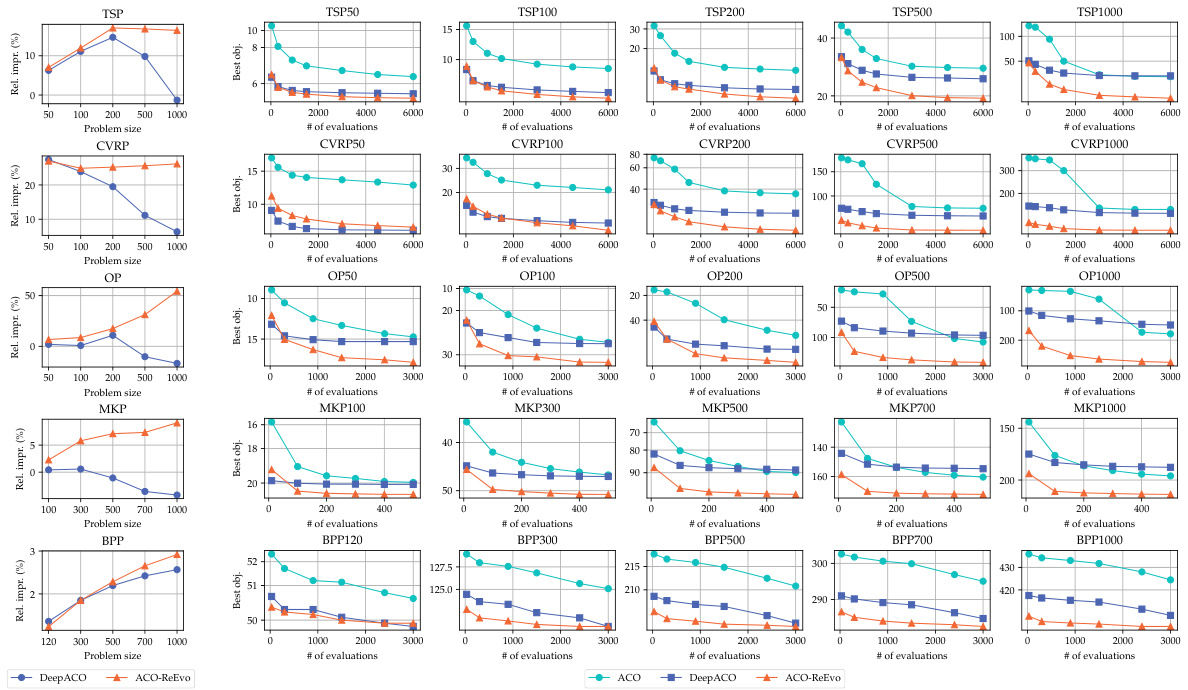
This figure compares the performance of Ant Colony Optimization (ACO) using different heuristics: expert-designed, neural, and ReEvo-generated. The left panel shows the relative improvement of DeepACO and ReEvo over expert-designed heuristics for various problem sizes across five different COPs. The right panel displays the ACO evolution curves, illustrating the best objective values over the number of evaluations for each COP and heuristic type. The results demonstrate the consistent superiority of ReEvo across different COPs and problem sizes.
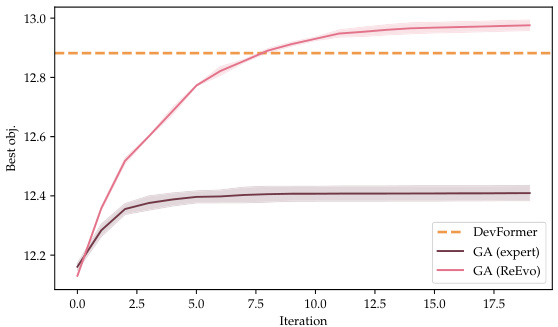
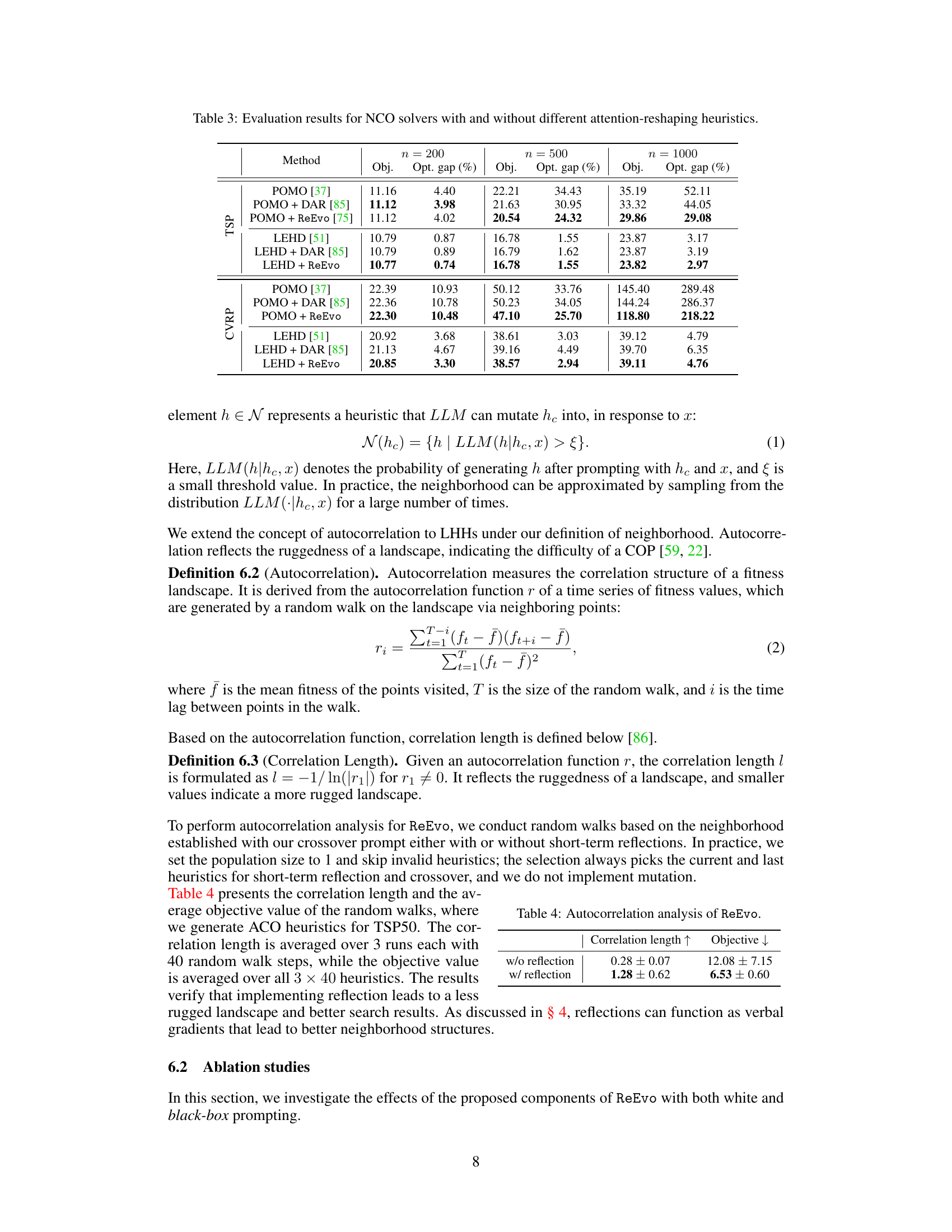
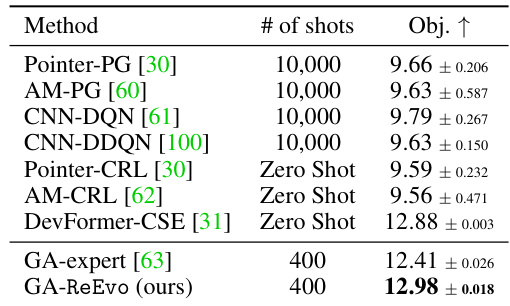
This figure compares the performance of three different methods for solving the Decap Placement Problem (DPP): DevFormer, an expert-designed Genetic Algorithm (GA), and a ReEvo-designed GA. The left panel shows evolution curves, illustrating the best objective value achieved over multiple generations (iterations) for each method. The horizontal line represents the performance of DevFormer’s end-to-end solutions. The right panel provides a summary of the evaluation results for various DPP solvers, indicating the number of solution generations and the average objective value obtained from 100 test problems. The comparison showcases the superior performance of the ReEvo-designed GA.

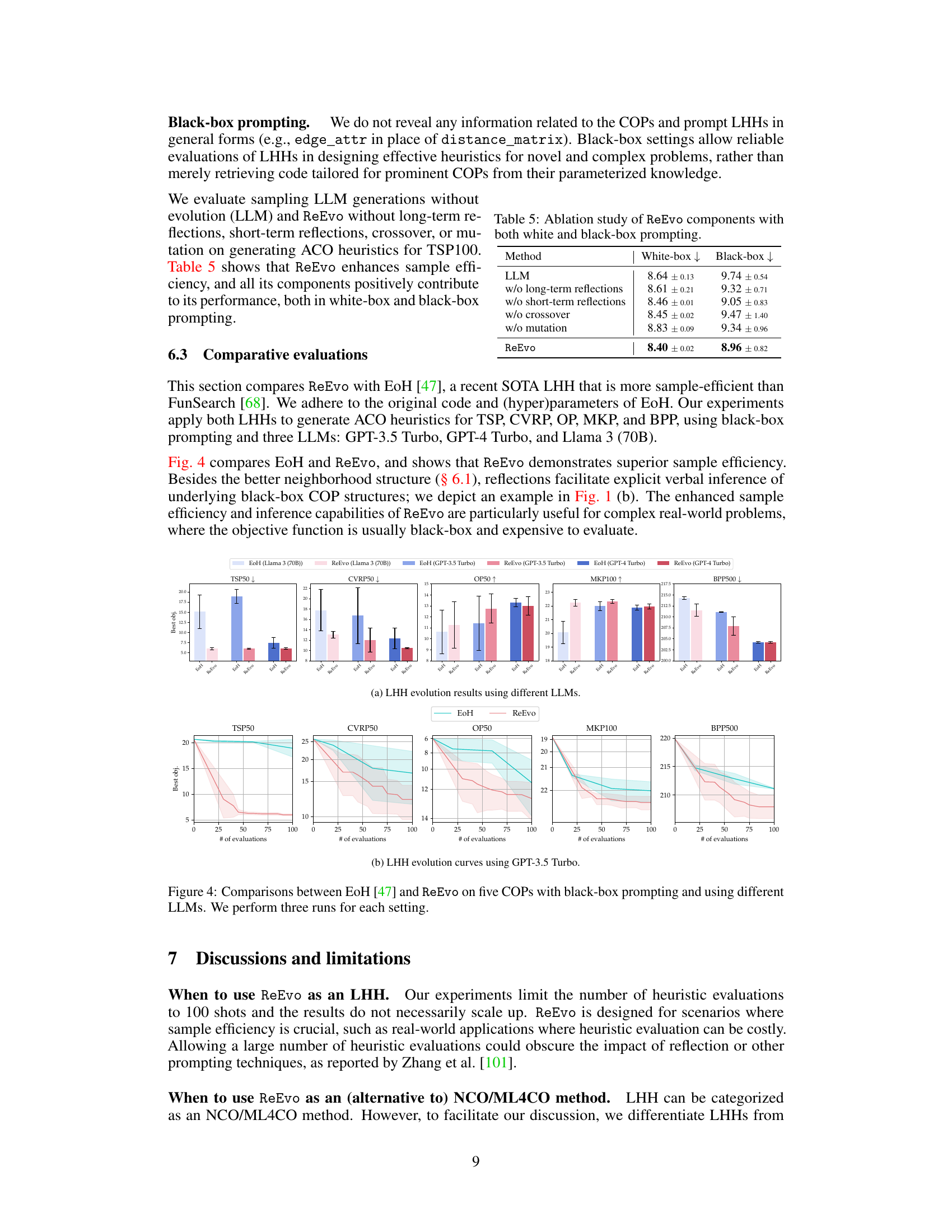
This figure compares the performance of two Language Hyper-Heuristics (LHHs), EoH and ReEvo, across five different Combinatorial Optimization Problems (COPs). The comparison is based on the number of heuristic evaluations needed to achieve a certain solution quality using three different Large Language Models (LLMs): GPT-3.5 Turbo, GPT-4 Turbo, and Llama 3 (70B). The figure highlights ReEvo’s superior sample efficiency and consistent performance across various COPs and LLMs when using black-box prompting.

This figure shows a schematic illustration of the ReEvo pipeline. It illustrates the five sequential steps in a ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. It also shows how the insights and knowledge are verbalized as long-term reflections and accumulated throughout the iterations.

This figure illustrates the ReEvo pipeline, which couples evolutionary search with LLM reflections to improve heuristic generation. The pipeline includes several steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Each step uses LLMs in the roles of a generator and a reflector to guide the evolutionary process. Examples of short-term and long-term reflections are shown, demonstrating how ReEvo emulates human experts by reflecting on the relative performance of two heuristics and gathering insights across iterations.

This figure shows a schematic illustration of the ReEvo pipeline and a detailed breakdown of a single ReEvo iteration. The pipeline depicts the evolutionary process of generating heuristics using two LLMs: a generator LLM and a reflector LLM. The iteration steps include selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Examples of short-term and long-term reflections for a black-box TSP problem using Ant Colony Optimization are provided as well, showing how ReEvo integrates LLM reflections with evolutionary search to improve heuristic generation.

The figure illustrates the ReEvo pipeline, showing how it evolves a population of heuristics using an evolutionary framework. It also details the five sequential steps within a single ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Examples of short-term and long-term reflections, using a Traveling Salesman Problem (TSP) as an example, are included to show the feedback loop between heuristic performance and LLM-driven insights for improved design.

This figure shows a schematic illustration of the ReEvo pipeline. The top part shows how ReEvo evolves a population of heuristics. The bottom part illustrates the five sequential steps in a ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The figure also includes two examples illustrating short-term and long-term reflections.
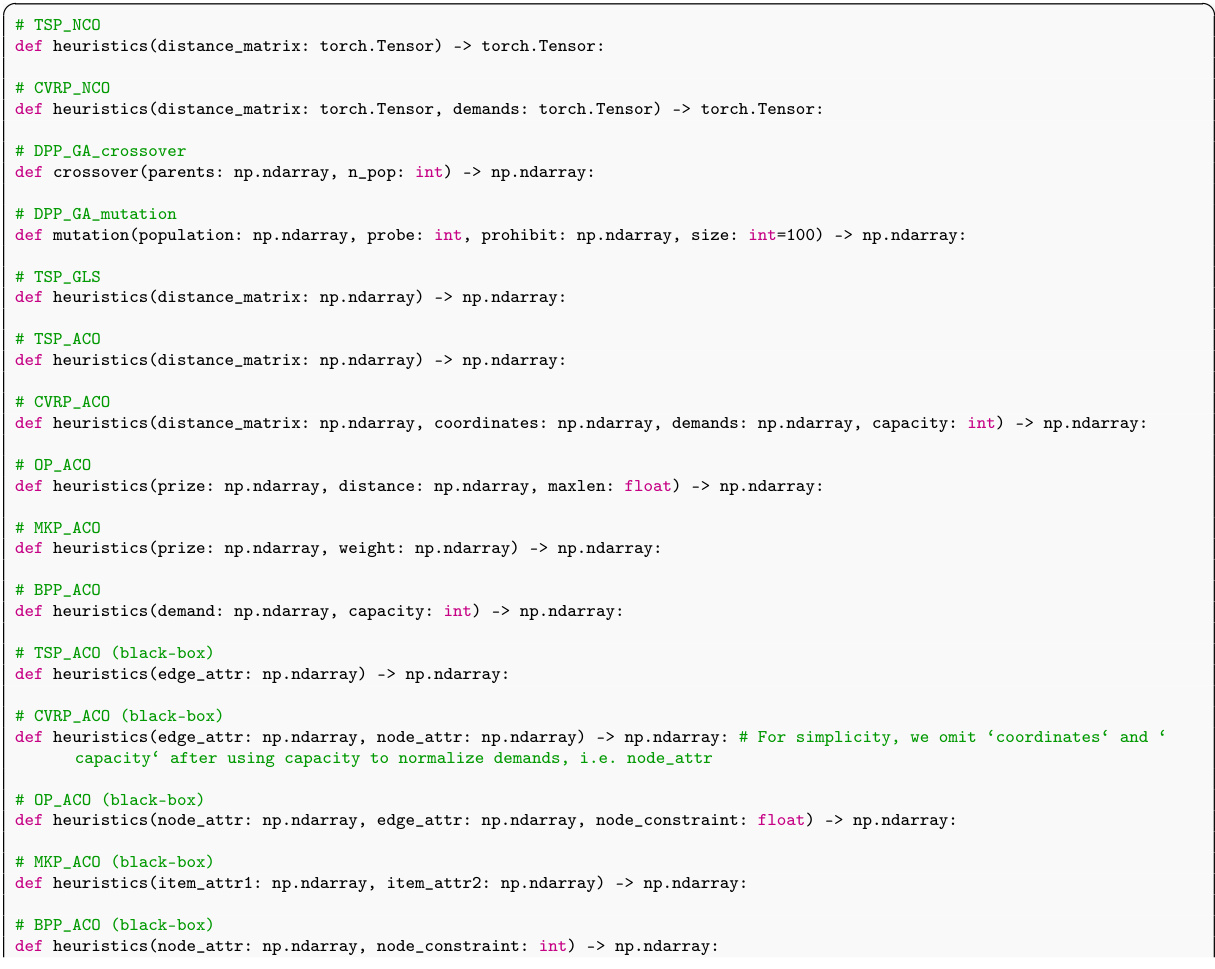
This figure illustrates the ReEvo pipeline, showing how it evolves a population of heuristics. It highlights the dual-level reflection mechanism involving short-term reflections (guiding each generation) and long-term reflections (accumulating expertise). The five sequential steps of a ReEvo iteration are also detailed: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Examples of the reflection prompts and generated heuristics are shown for a black-box TSP problem.

This figure shows a schematic illustration of the ReEvo pipeline. The top part shows the overall process of ReEvo evolving a population of heuristics, where insights and knowledge are accumulated through long-term reflections. The bottom part illustrates the five sequential steps in a single ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Two examples of reflections for black-box TSP are also included, demonstrating how ReEvo guides the heuristic generation process using self-reflections.

This figure shows a schematic illustration of the ReEvo pipeline and its five sequential steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The pipeline shows how ReEvo integrates evolutionary search with LLM reflections to improve heuristic generation for combinatorial optimization problems. It also includes example prompts and outputs from the reflector and generator LLMs, highlighting the process of generating and refining heuristics based on performance feedback.

This figure illustrates the ReEvo pipeline and a single ReEvo iteration. The pipeline shows how a population of heuristics evolves over several iterations, incorporating short-term and long-term reflections from an LLM to guide the search. A single iteration comprises selection of parent heuristics, short-term reflection (involving comparison of parent performance), crossover to produce offspring, long-term reflection (summarizing insights across iterations), and elitist mutation. Examples of short-term and long-term reflections are shown for a black-box TSP problem, illustrating how the LLM provides verbal gradients by interpreting genetic cues.

This figure illustrates the ReEvo pipeline and a single ReEvo iteration, highlighting the roles of generator and reflector LLMs, the iterative steps (selection, short-term reflection, crossover, long-term reflection, and elitist mutation), and the integration of evolutionary search with LLM reflections. The bottom panel shows example prompts and outputs illustrating short-term and long-term reflections in a black-box TSP scenario, demonstrating how the LLMs provide verbal gradients to guide the heuristic search.
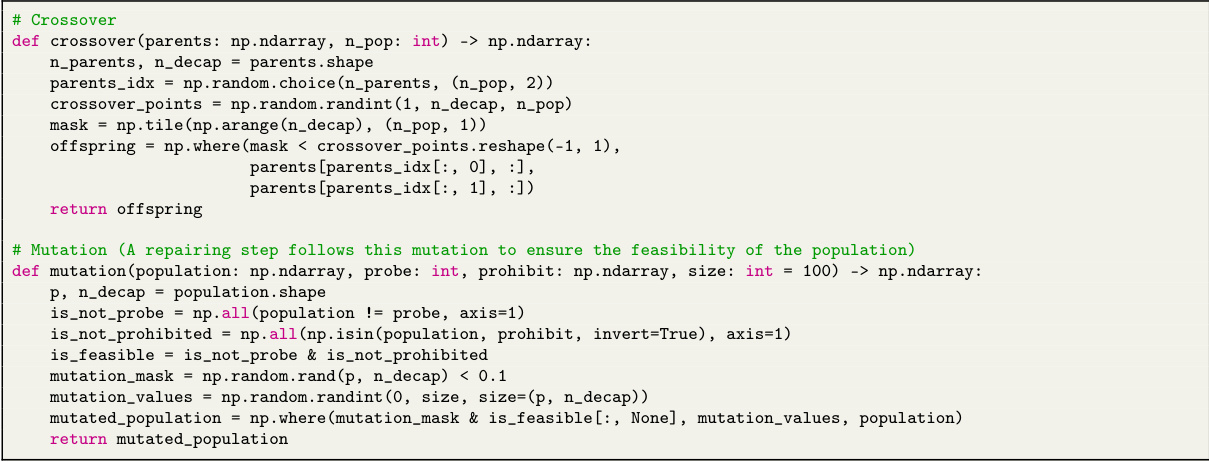
This figure shows a schematic illustration of the ReEvo pipeline. The top part shows the overall workflow of ReEvo, including population of heuristics, short-term and long-term reflections, and the iterative steps of selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The bottom part shows the five sequential steps of a single ReEvo iteration, including the interaction between the generator LLM and the reflector LLM.
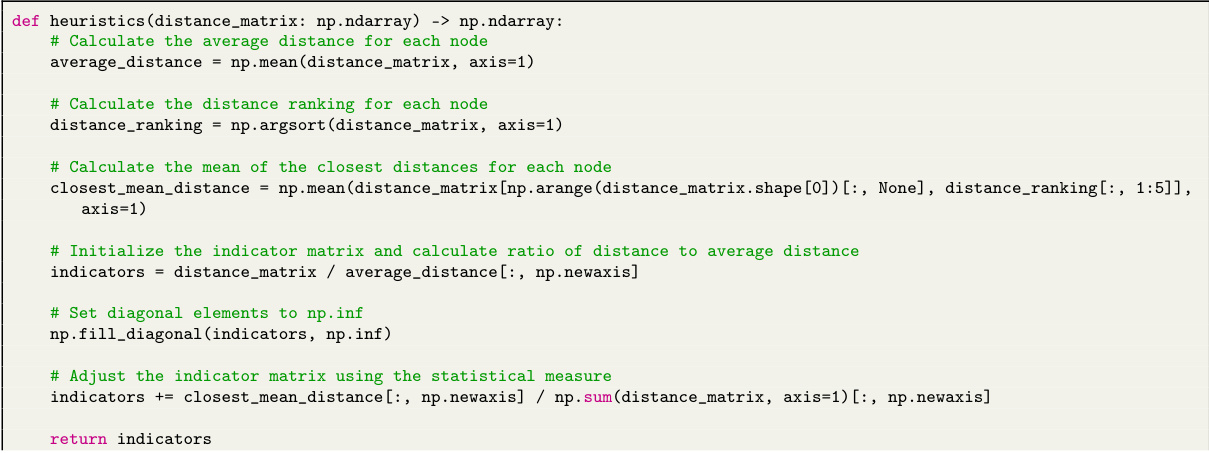
This figure provides a schematic illustration of the ReEvo pipeline, showing how it integrates LLMs with an evolutionary framework. The top part shows the overall process of evolving a population of heuristics using LLMs for generation and reflection. The bottom depicts the five sequential steps within each iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. Examples of the reflection prompts and outputs are provided to show how ReEvo uses LLMs to provide feedback and guidance for heuristic improvement.

This figure shows a schematic illustration of the ReEvo pipeline and a detailed breakdown of a single ReEvo iteration, which includes five sequential steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The figure also provides example prompts and code snippets to illustrate how the generator and reflector LLMs interact within the evolutionary framework, providing verbal gradients that guide the search for improved heuristics. The dual-level reflections (short-term and long-term) help the LLMs learn and adapt over time, improving heuristic design.
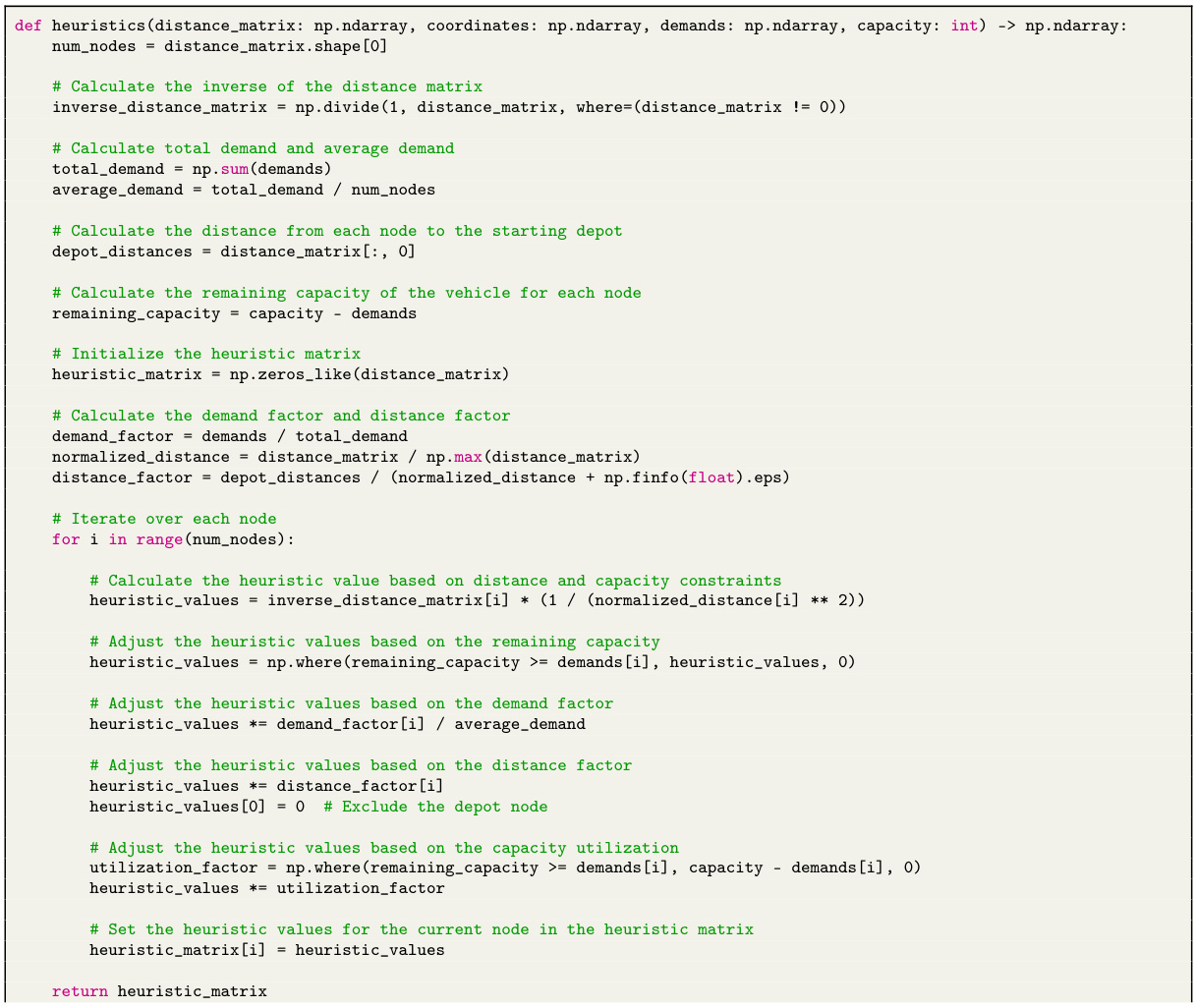
This figure shows a schematic illustration of the ReEvo pipeline. It illustrates the five sequential steps of a ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. It also visually represents the interaction between the generator LLM, the reflector LLM, and the heuristic evaluator within an evolutionary framework, highlighting the process of generating, evaluating, reflecting upon, and refining heuristics.

This figure shows a schematic illustration of the ReEvo pipeline and a detailed breakdown of one iteration, highlighting the five sequential steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. It also provides examples of short-term and long-term reflections with code snippets for the Traveling Salesman Problem (TSP) to illustrate how ReEvo utilizes LLMs for both heuristic generation and reflection. The diagram visually represents the interplay between the generator LLM, reflector LLM, and evolutionary search process within ReEvo.

This figure illustrates the ReEvo pipeline, which couples evolutionary search with LLM reflections. It shows the five sequential steps in a ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The figure also includes example prompts and responses from the generator and reflector LLMs, showcasing how ReEvo utilizes self-reflections to enhance the reasoning capabilities of LLMs and interpret genetic cues to boost heuristic search.

This figure shows a schematic illustration of the ReEvo pipeline, which integrates evolutionary search with LLM reflections to generate heuristics. It highlights the five sequential steps in a ReEvo iteration: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The figure also provides examples of short-term and long-term reflections using prompts and LLM outputs for the Traveling Salesman Problem (TSP).

This figure shows a schematic illustration of the ReEvo pipeline. The top part illustrates the overall workflow of ReEvo, which involves an evolutionary process of generating and evaluating heuristics, guided by short-term and long-term reflections from an LLM. The bottom part illustrates a single iteration of ReEvo, showing the five sequential steps: selection, short-term reflection, crossover, long-term reflection, and elitist mutation. The figure also includes examples of short-term and long-term reflections, illustrating how the LLM provides feedback to improve heuristic designs.
More on tables
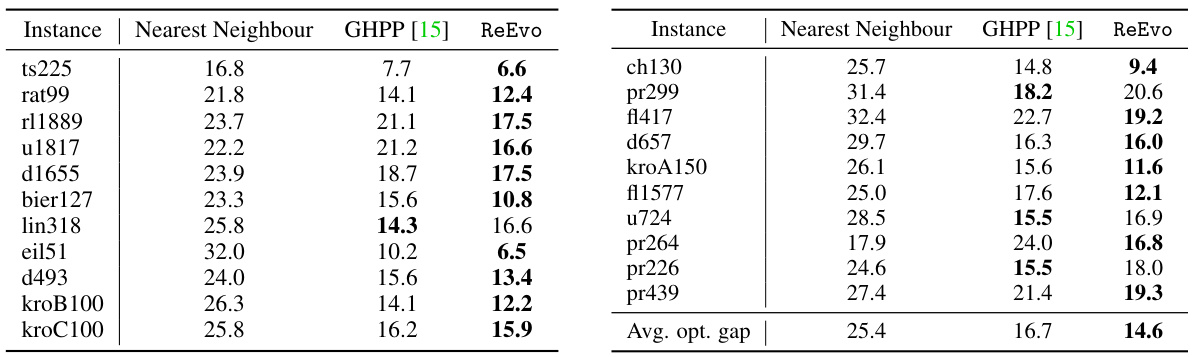
This table presents a comparison of various local search (LS) methods for solving the Traveling Salesman Problem (TSP). The methods compared include traditional GLS, several GLS variants incorporating machine learning (GNNGLS, NeuralGLS+, EoH), and a state-of-the-art neural combinatorial optimization (NCO) method (NeuOpt). For each method, the table reports the optimality gap (percentage difference between the solution found and the optimal solution) and the average per-instance execution time. The results demonstrate the effectiveness of the ReEvo-enhanced GLS (KGLS-ReEvo) in achieving superior performance and sample efficiency.
This table compares the performance of different local search variants for solving the Traveling Salesman Problem (TSP). The methods compared include several state-of-the-art (SOTA) learning-based and neural local search approaches, as well as the classic Guided Local Search (GLS) and a new GLS variant enhanced with ReEvo-generated heuristics (KGLS-ReEvo). The results are reported in terms of optimality gap (the difference between the solution obtained and the optimal solution) and execution time for each instance of the TSP with different sizes (TSP20, TSP50, TSP100, and TSP200).
This table compares the performance of different local search variants, including the proposed method KGLS-ReEvo, on the TSP problem. The comparison includes optimality gap (percentage difference from optimal solution) and per-instance execution time. It shows how KGLS-ReEvo improves upon the baseline KGLS and outperforms other state-of-the-art (SOTA) methods. Notably, it highlights that KGLS-ReEvo uses a single heuristic across problem sizes, unlike other methods.

This table compares the performance of different local search variants, including the proposed KGLS-ReEvo method, on four different TSP problem instances. The comparison includes optimality gaps (percentage difference from optimal solution) and per-instance execution time (in seconds). It demonstrates the effectiveness of ReEvo in improving upon the original KGLS algorithm and outperforming state-of-the-art learning-based and neural GLS solvers.
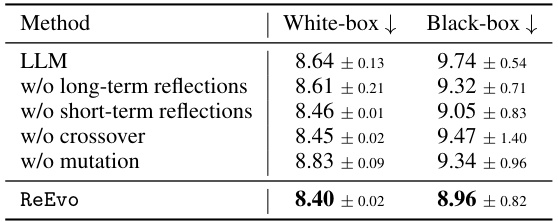
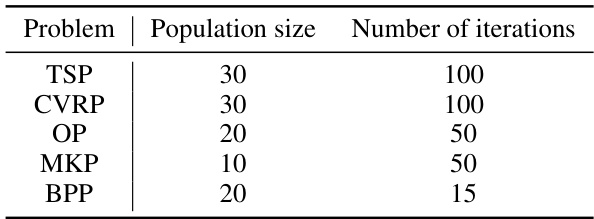
This table presents the ablation study results of ReEvo’s components. It evaluates the performance of ReEvo with different components removed (no long-term reflections, no short-term reflections, no crossover, no mutation) and compares it with a baseline (LLM generations alone). The experiments are conducted under both white-box and black-box prompting settings. The results show that all components contribute positively to ReEvo’s performance and that it is more sample efficient than the LLM baseline.

This table compares the performance of different local search variants for solving the traveling salesman problem (TSP). The methods compared include several GLS variants (including the one enhanced with ReEvo), as well as a state-of-the-art neural combinatorial optimization (NCO) method. The table reports the optimality gap (the difference between the solution found and the optimal solution) and the per-instance execution time for TSP instances of sizes 20, 50, 100, and 200 nodes. The results demonstrate the improvement achieved by ReEvo over existing state-of-the-art methods.

This table presents a comparison of different local search variants for solving the Traveling Salesman Problem (TSP). The methods compared include several GLS (Guided Local Search) variations, a learning-based method (NeuOpt), and the proposed KGLS-ReEvo method. The table shows the optimality gap (percentage difference from the optimal solution) and per-instance execution time for TSP instances of sizes 20, 50, 100, and 200 nodes. The results demonstrate the improved performance of KGLS-ReEvo over existing methods.

This table presents a comparison of different local search variants for solving the Traveling Salesman Problem (TSP). The methods compared include several variations of Guided Local Search (GLS) incorporating machine learning and neural approaches, along with a classic GLS method. The table reports optimality gaps (the difference between the solution found and the optimal solution) and the per-instance execution time for four different problem sizes (TSP20, TSP50, TSP100, TSP200). The results highlight the improved performance of the ReEvo-enhanced GLS (KGLS-ReEvo) compared to the baseline GLS and other state-of-the-art (SOTA) methods.
This table compares the performance of different local search variants for solving the traveling salesman problem (TSP). The methods compared include several guided local search (GLS) approaches enhanced with reinforcement learning (RL) or large language models (LLMs), as well as a standard GLS method. The table reports the optimality gap (the difference between the solution found and the optimal solution) and the per-instance execution time for various sizes of TSP instances (TSP20, TSP50, TSP100, and TSP200). This allows for a comparison of the effectiveness and efficiency of different heuristic search methods for combinatorial optimization problems.

This table compares the performance of different local search variants for solving the Traveling Salesman Problem (TSP) with varying sizes (TSP20, TSP50, TSP100, TSP200). The methods compared include NeuOpt (learning-based LS with reinforcement learning), GNNGLS and NeuralGLS+ (graph neural network-based GLS), EoH (a prior language hyper-heuristic approach), KGLS (a classical GLS), and KGLS-ReEvo (the proposed approach combining KGLS with penalty heuristics generated by ReEvo). For each method, the table reports the optimality gap (the percentage difference between the solution found and the optimal solution) and the average execution time per instance. The results demonstrate that KGLS-ReEvo achieves state-of-the-art performance, outperforming other methods across all problem sizes while being more sample-efficient.
This table presents a comparison of various local search (LS) methods for solving the Traveling Salesman Problem (TSP). The methods include several variations of Guided Local Search (GLS) enhanced with different techniques (reinforcement learning, supervised learning, language hyper-heuristics), along with a state-of-the-art neural combinatorial optimization approach (NeuOpt). The table reports the optimality gap (percentage difference between the solution found and the optimal solution) and the per-instance execution time for four different TSP problem sizes (20, 50, 100, and 200 nodes). The results demonstrate the performance improvement achieved by the KGLS-ReEvo method, an integration of ReEvo with KGLS, which outperforms other state-of-the-art methods, particularly in larger problem instances.

This table compares the performance of different local search variants, including the proposed KGLS-ReEvo method, on solving TSP problems of varying sizes (TSP20, TSP50, TSP100, TSP200). The metrics used are the optimality gap (percentage difference between the solution found and the optimal solution) and the per-instance execution time (in seconds). The table allows for a comparison of the ReEvo method against state-of-the-art (SOTA) learning-based and neural methods for local search.
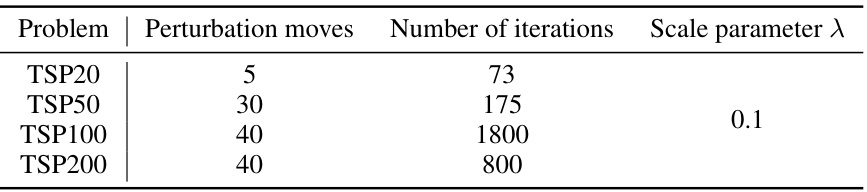
This table compares the performance of different local search (LS) variants on solving the Traveling Salesman Problem (TSP) with varying problem sizes (TSP20, TSP50, TSP100, TSP200). The methods compared include NeuOpt (a learning-based local search method), GNNGLS and NeuralGLS+ (graph neural network-enhanced GLS methods), EoH (an LLM-based hyper-heuristic method), KGLS (a standard GLS), and the proposed KGLS-ReEvo (KGLS enhanced with ReEvo-generated heuristics). The table reports the optimality gap (the difference between the solution found and the optimal solution, expressed as a percentage) and the per-instance execution time for each method and problem size. This demonstrates ReEvo’s effectiveness in improving the optimality of local search algorithms.
This table presents a comparison of different local search variants for solving the Traveling Salesman Problem (TSP). The methods compared include several GLS (Guided Local Search) variations enhanced with different techniques (reinforcement learning, symbolic learning, Language Hyper-Heuristics), as well as a classic GLS method and the KGLS-ReEvo approach (KGLS combined with ReEvo). The table reports the optimality gap (the difference between the solution found and the optimal solution) and the execution time for each method across various TSP sizes (20, 50, 100, and 200 nodes).
This table presents a comparison of different local search variants, focusing on their performance in solving the Traveling Salesman Problem (TSP). The methods compared include various Guided Local Search (GLS) approaches augmented with reinforcement learning, neural networks, and Language Hyper-Heuristics (LHHs), along with a standard GLS implementation. The results are categorized by TSP problem size and show the optimality gaps (percentage difference from the optimal solution) and the per-instance execution time (in seconds). This allows readers to assess the relative effectiveness of each method in terms of solution quality and efficiency. The table highlights the superior performance of KGLS-ReEvo, showcasing the effectiveness of the LHH approach.
Full paper#