↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Modern machine learning models often struggle with out-of-distribution (OOD) data, which leads to poor generalization and detection performance. This is especially challenging when dealing with real-world data containing both covariate and semantic shifts, for which distinguishing between these types of OOD data is difficult. Existing methods often fail to effectively address both challenges simultaneously.
This paper introduces AHA (Adaptive Human-Assisted OOD learning), a novel framework that uses human assistance to strategically improve both OOD generalization and detection. AHA focuses on labeling data in a specifically chosen “maximum disambiguation region,” where the model’s uncertainty about the type of OOD data is highest. By doing so, it leverages human effort efficiently to maximize improvements in both tasks. The results show that AHA, with a limited labeling budget, significantly outperforms existing methods in both OOD generalization and OOD detection, thus demonstrating the effectiveness of the approach and its potential for improving real-world AI systems.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to improve both out-of-distribution (OOD) generalization and detection simultaneously. It tackles the common challenge of distribution shifts in real-world machine learning applications, significantly improving model robustness using a human-assisted framework that strategically leverages limited human annotations for maximal impact. The findings offer valuable insights into efficient human-in-the-loop learning and pave the way for more reliable and robust AI systems in various fields. This approach effectively utilizes human feedback to address a critical limitation of current state-of-the-art methods, leading to enhanced model performance and significantly reducing OOD errors.
Visual Insights#

The figure illustrates three different strategies for selecting examples from a dataset containing in-distribution (ID), covariate out-of-distribution (OOD), and semantic OOD data for labeling. (a) shows labeling the top-k most OOD examples, (b) shows labeling examples near the 95% true positive rate (TPR) threshold, and (c) - the proposed approach - shows labeling examples within the ‘maximum disambiguation region’, where the densities of covariate and semantic OOD data are approximately equal. This region is designed to maximize the utility of limited human labeling effort by disambiguating the two types of OOD data. The horizontal axis represents the OOD score, and the vertical axis represents the frequency of each type of data.

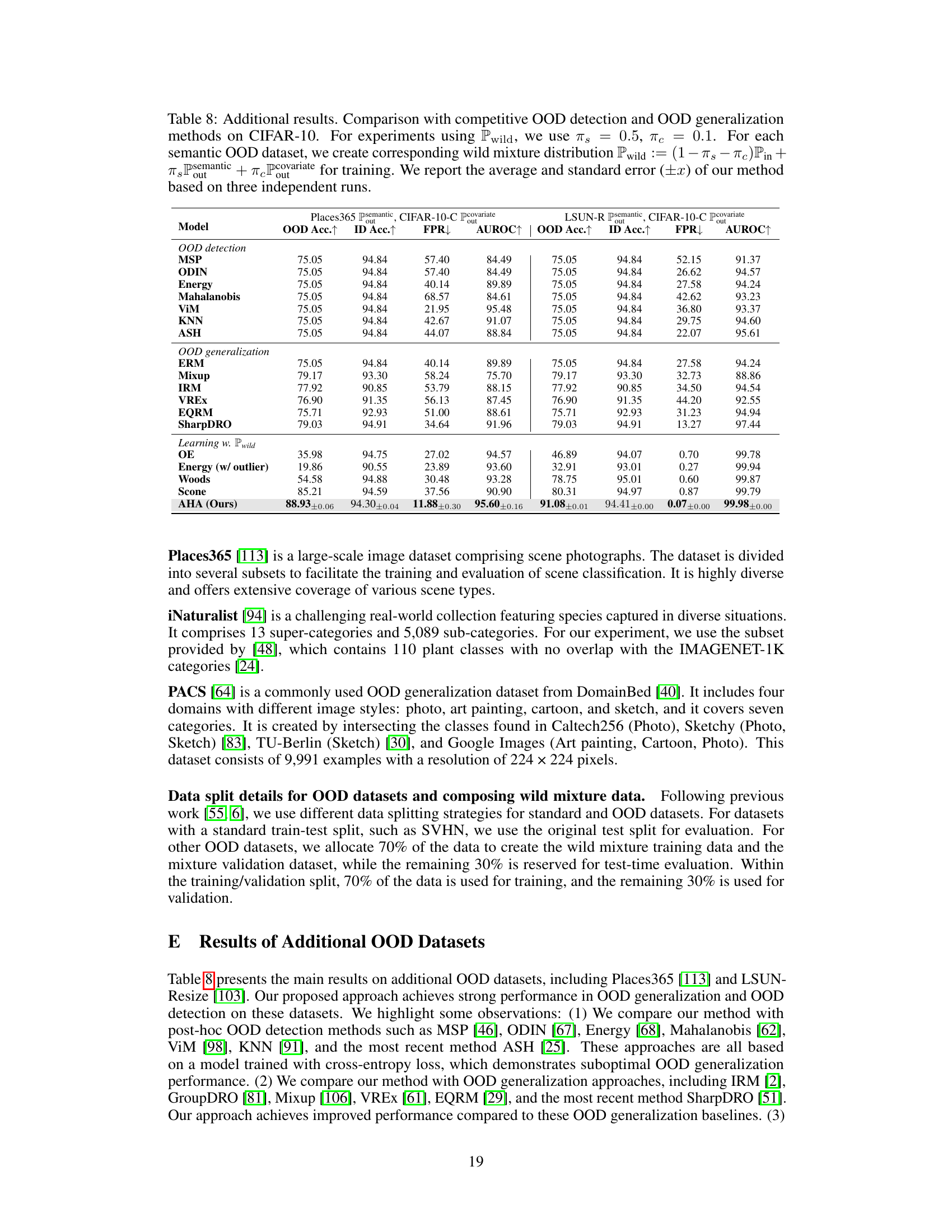
This table presents a comparison of the proposed AHA method against the state-of-the-art SCONE method on the CIFAR-10 benchmark. It shows the improvements achieved by AHA in terms of out-of-distribution (OOD) accuracy, in-distribution (ID) accuracy, false positive rate (FPR), and area under the receiver operating characteristic curve (AUROC) for various semantic and covariate OOD datasets.
In-depth insights#
Human-Aided OOD#
The concept of “Human-Aided OOD” (Out-of-Distribution) in machine learning tackles the critical challenge of model generalization and robustness when encountering unseen data. It leverages human expertise to strategically guide the learning process, focusing on ambiguous data points where the model is most uncertain and human insight is most valuable. This approach acknowledges that while AI excels at pattern recognition, human judgment remains essential in disambiguating complex real-world situations. The core idea revolves around efficiently using limited human labeling efforts by targeting data points that maximize the utility of each annotation, effectively bridging the gap between fully supervised learning and completely unsupervised OOD detection. The results demonstrate that carefully directed human involvement significantly improves both OOD generalization and detection performance, suggesting that a hybrid approach combining human expertise and machine learning is a highly effective strategy for improving the robustness of AI systems in real-world applications.
Max Disambiguity#
The concept of “Max Disambiguity” in the context of out-of-distribution (OOD) detection is crucial for efficient human-in-the-loop learning. It suggests a strategic labeling approach where human effort is focused on the most informative data points. This region, characterized by roughly equal densities of covariate and semantic OOD examples, maximizes the utility of limited human annotation by improving the model’s ability to distinguish between different types of OOD scenarios. The core idea is to target areas of high uncertainty in the model, where labeling is most likely to provide significant improvement in both OOD generalization and detection accuracy. By maximizing the disambiguation between different OOD types, the algorithm ensures that human effort leads to the greatest possible improvement in model performance. This is in contrast to simpler labeling strategies that may focus on the easiest-to-label examples, potentially missing valuable information for improving OOD robustness. Therefore, Max Disambiguity is a powerful technique for achieving high accuracy with minimal human input, which is important for practical applications of human-assisted machine learning.
Noisy Binary Search#
The section on “Noisy Binary Search” is crucial because it details the algorithm used to efficiently identify the optimal labeling region. This region, characterized by roughly equal densities of covariate and semantic OOD examples, maximizes the utility of limited human labeling. The authors cleverly frame the threshold identification as a noisy binary search problem. This is insightful because it leverages existing algorithms with theoretical guarantees, offering a robust and principled solution. The noisy nature of the search is explicitly addressed, acknowledging the inherent uncertainty in human labeling. This ensures the algorithm converges on an accurate threshold with high probability, despite the noise. The strategic use of noisy binary search is key to AHA’s efficiency and effectiveness, making it a unique and powerful contribution to human-assisted OOD learning. The choice of a noisy binary search algorithm directly impacts the efficiency and reliability of finding the maximum ambiguity threshold. A well-chosen algorithm would balance exploration and exploitation effectively, minimizing the number of labels required while maintaining a high probability of identifying the optimal region. This methodology is particularly important when human labeling is expensive or time-consuming.
OOD Generalization#
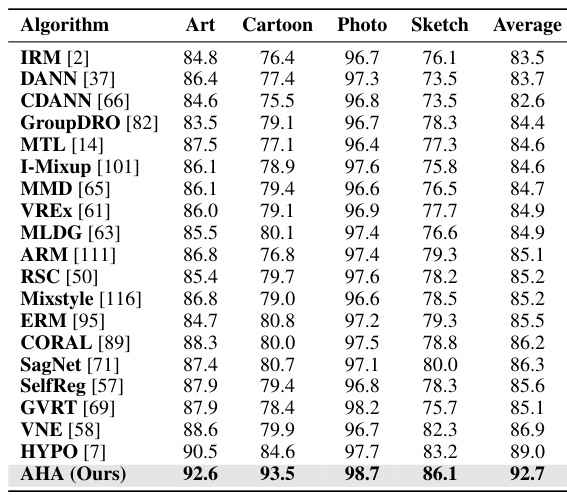
Out-of-distribution (OOD) generalization tackles the challenge of machine learning models performing well on unseen data differing from the training distribution. Robustness is key, as models should generalize to various real-world scenarios, including covariate shift (changes in data characteristics) and semantic shift (emergence of novel classes). Existing approaches often focus on learning domain-invariant features or employing techniques like adversarial training or meta-learning to improve generalization. However, a major limitation is the assumption of knowing the test distribution, which is rarely true in real-world settings. Therefore, new methods are needed which focus on learning generalizable representations effectively without this restrictive assumption, focusing on learning representations that transfer well and developing more data-efficient strategies for robust model development. Human-in-the-loop approaches are promising, but need to address efficiency and bias issues. Further research should prioritize exploration of more flexible techniques that are not limited by test distribution knowledge and integrate effective human-assistance in a thoughtful, bias-mitigating way.
OOD Detection#
Out-of-distribution (OOD) detection is a critical aspect of robust machine learning, aiming to identify data points that deviate significantly from the model’s training distribution. Effective OOD detection is crucial for deploying models in real-world scenarios where unseen data is inevitable. The challenge lies in distinguishing between genuine out-of-distribution samples and in-distribution samples that the model simply misclassifies. Existing methods vary in their approaches, with some using confidence scores, others analyzing prediction gradients, and yet others relying on energy-based methods. The paper explores an adaptive, human-assisted approach, labeling strategically selected data to enhance OOD detection performance. This hybrid approach acknowledges the limitations of fully automated methods, particularly in differentiating various types of OOD data, making the need for human intervention in some scenarios crucial. The adaptive element focuses on identifying and labeling data within a maximum disambiguation region where model uncertainty is high, maximizing the impact of human labeling efforts. This targeted approach appears promising for increasing the effectiveness of OOD detection systems. A key focus for future work should be to improve efficiency and reduce human workload.
More visual insights#
More on tables

This table compares the performance of different labeling strategies for human-assisted out-of-distribution (OOD) learning. It shows that selecting top-k most OOD examples or those near the boundary between in-distribution and OOD data is less effective than the proposed AHA method’s maximum disambiguation region. The results demonstrate the superiority of AHA in enhancing both OOD generalization and detection. The table includes metrics such as OOD accuracy, in-distribution accuracy, false positive rate, and AUROC for different labeling methods. The number of in-distribution, covariate OOD, and semantic OOD examples in each labeling region is also shown.

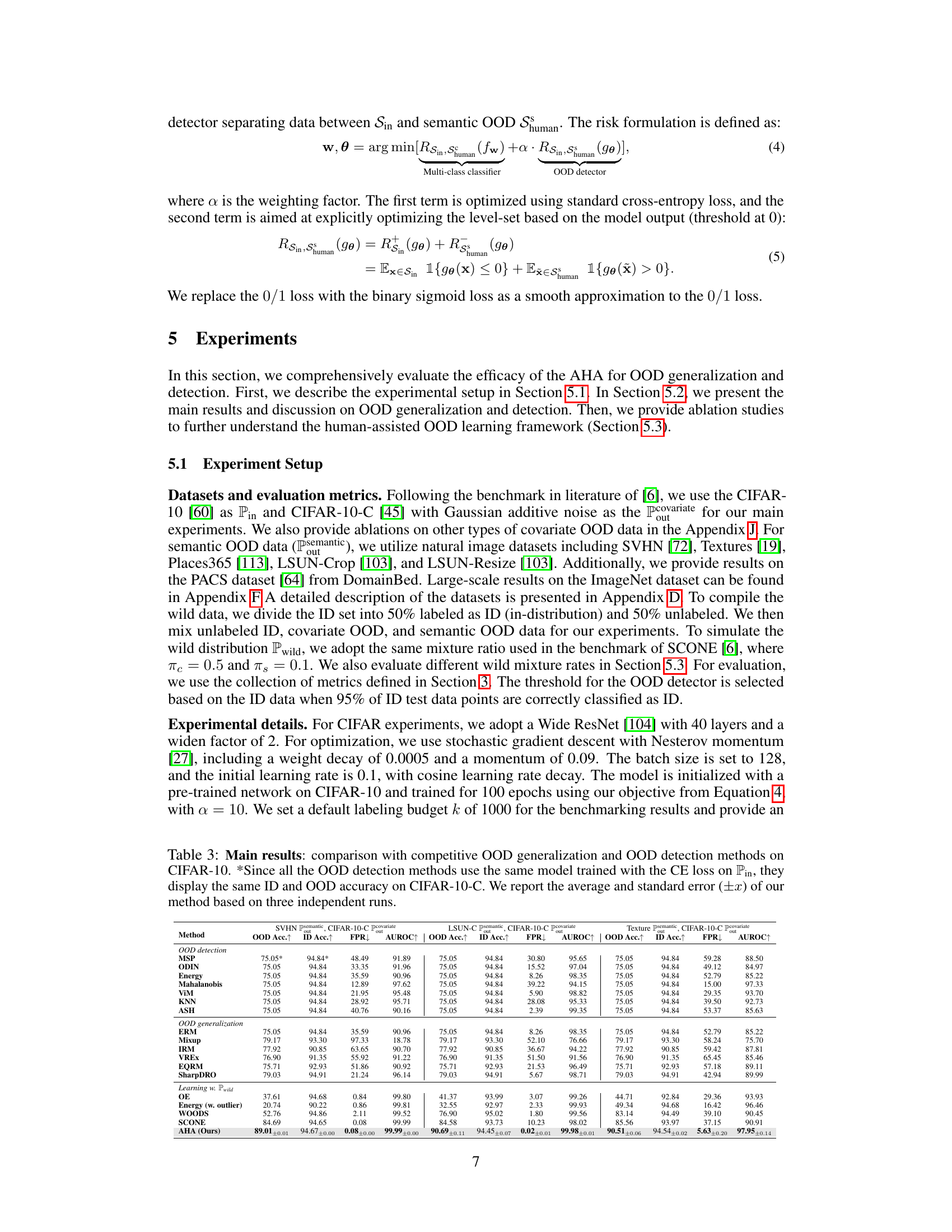
This table presents the main results of the AHA method compared to other state-of-the-art methods for out-of-distribution (OOD) generalization and detection on the CIFAR-10 benchmark dataset. It shows the OOD accuracy, ID accuracy, false positive rate (FPR), and area under the ROC curve (AUROC) for different semantic OOD datasets (SVHN, LSUN-C, Texture). The results highlight the significant improvement achieved by the AHA method, outperforming other OOD generalization and detection baselines.
This table presents the main results comparing the proposed AHA method to other state-of-the-art methods for both OOD generalization and detection on the CIFAR-10 benchmark dataset. The table shows the OOD accuracy, ID accuracy, False Positive Rate (FPR) at 95% True Positive Rate (TPR), and Area Under the Receiver Operating Characteristic curve (AUROC). Different semantic OOD datasets (SVHN, LSUN-C, and Textures) are used to evaluate performance across various semantic shifts.

This table presents a comparison of the proposed AHA method with the state-of-the-art SCONE method on the CIFAR-10 benchmark. It highlights the improvements in OOD accuracy and FPR (false positive rate) achieved by AHA, demonstrating its superior performance in OOD generalization and detection.
This table presents a comparison of the proposed AHA method against the state-of-the-art SCONE method on the CIFAR-10 benchmark. It shows improvements in OOD accuracy and FPR (False Positive Rate) on several semantic and covariate OOD datasets, highlighting the efficacy of AHA in improving both OOD generalization and detection.
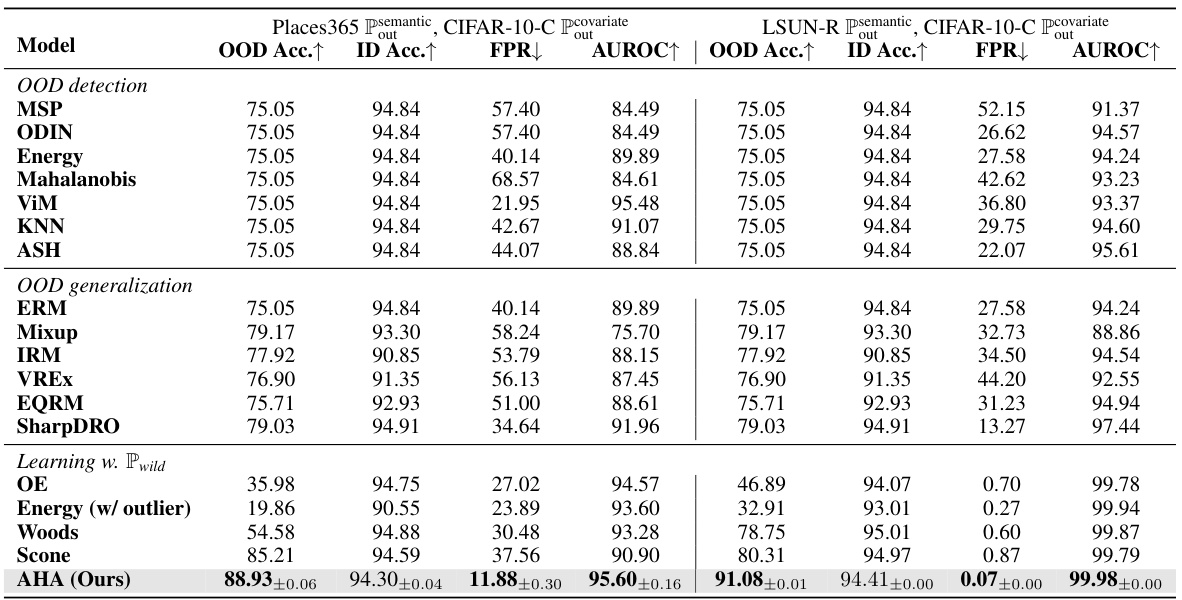
This table presents the main results of the AHA method compared to several state-of-the-art methods for OOD generalization and detection on CIFAR-10 dataset. It shows OOD accuracy, ID accuracy, False Positive Rate (FPR), and Area Under the ROC Curve (AUROC) for different semantic OOD datasets (SVHN, LSUN-C, Textures) and a covariate OOD dataset (CIFAR-10-C). The results highlight AHA’s superior performance across all metrics, demonstrating its effectiveness in handling both types of OOD shifts.

This table presents the results of the proposed AHA method and other competitive methods on the ImageNet-100 dataset. ImageNet-100 is used as the in-distribution (ID) data, while iNaturalist serves as the semantic out-of-distribution (OOD) data. The table shows the OOD accuracy, in-distribution accuracy, false positive rate at 95% true positive rate (FPR95), and area under the receiver operating characteristic curve (AUROC) for each method.

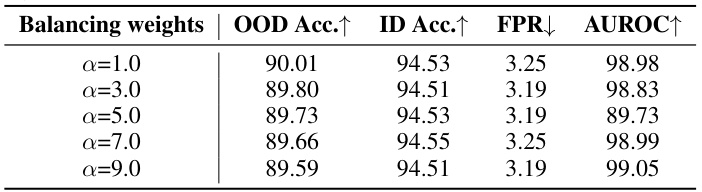
This table presents an ablation study on the impact of different mixing ratios of covariate and semantic out-of-distribution (OOD) data on the performance of the proposed AHA method and a Top-k baseline. It shows the OOD accuracy, in-distribution (ID) accuracy, false positive rate (FPR), and area under the ROC curve (AUROC) for different combinations of covariate OOD (πε) and semantic OOD (πς) proportions in the wild data.
This table presents the main experimental results, comparing the proposed AHA method against various state-of-the-art OOD generalization and detection methods on the CIFAR-10 benchmark dataset. It shows OOD accuracy, ID accuracy, False Positive Rate (FPR), and Area Under the Receiver Operating Characteristic curve (AUROC) across different semantic OOD datasets (SVHN, LSUN-C, Texture). The results highlight the significant performance improvement achieved by AHA.
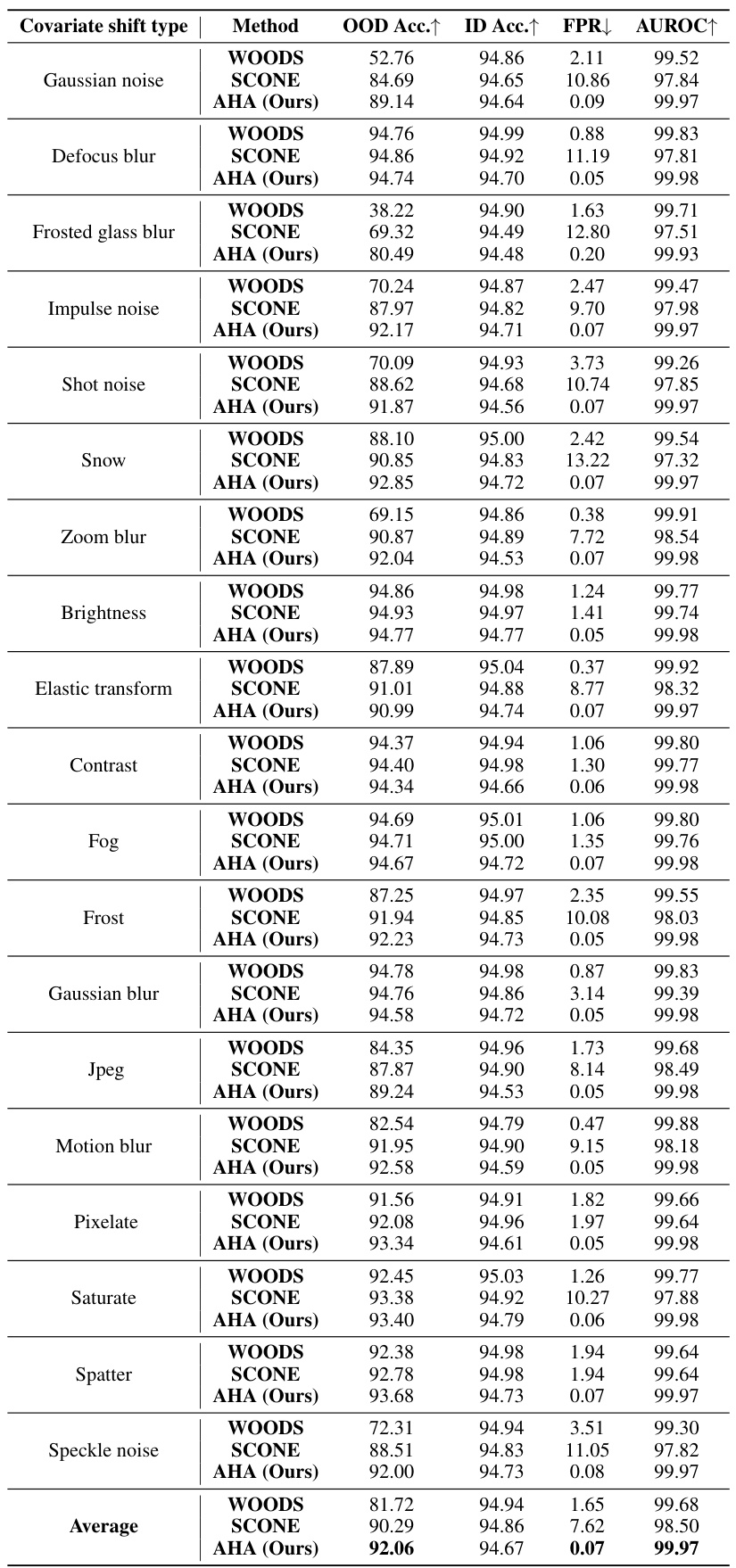
This table presents a comparison of the proposed AHA method against the state-of-the-art SCONE method on the CIFAR-10 benchmark. It shows the improvements achieved by AHA in terms of OOD accuracy, ID accuracy, False Positive Rate (FPR), and Area Under the ROC Curve (AUROC) across various semantic and covariate OOD datasets. The results highlight the significant enhancement in both OOD generalization and detection performance offered by the AHA method.
Full paper#