↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The rise of powerful diffusion models has created highly realistic synthetic videos, posing a significant threat to information authenticity. Current video forgery detection methods often struggle to identify these videos effectively, particularly those with diverse semantic content. Existing methods mainly focused on detecting facial forgeries and struggle with generalizing to various forgery types. This paper addresses these issues.
The researchers propose a new algorithm called Multi-Modal Detection (MM-Det), which uses large multimodal models to analyze videos and learn a more robust representation of forgeries. It also uses a mechanism that pays attention to both spatial and temporal features in videos, improving detection accuracy. To support their work, they created a large-scale dataset called Diffusion Video Forensics (DVF). MM-Det achieves state-of-the-art results on the DVF dataset. This work makes significant contributions to the field of video forensics by addressing its limitations and paving the way for more effective deepfake detection methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in video forensics and AI-generated content detection. It addresses the growing threat of realistic fake videos by introducing a novel algorithm (MM-Det) and a large-scale dataset (DVF), significantly advancing the field’s ability to identify and counter deepfakes. The innovative use of large multimodal models and the focus on generalizability open avenues for new research in robust forgery detection.
Visual Insights#
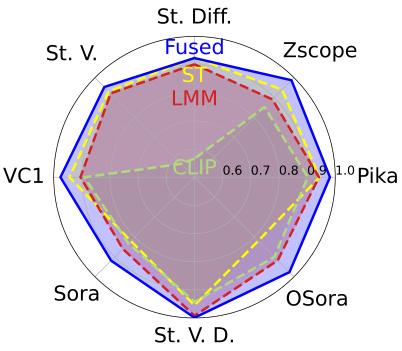
This figure shows a radar chart comparing the performance of different feature extraction methods used in the Multi-Modal Detection (MM-Det) model for diffusion video forgery detection. The methods compared are spatiotemporal (ST) features, CLIP encoder features, and Large Multimodal Model (LMM) features. The chart shows that combining these features (‘Fused’) results in the best performance on the Diffusion Video Forensics (DVF) dataset. Each axis represents a different diffusion video generation method, and the distance from the center to the line represents the performance of the method on that dataset. The figure demonstrates the effectiveness of MM-Det in detecting diffusion-generated videos.
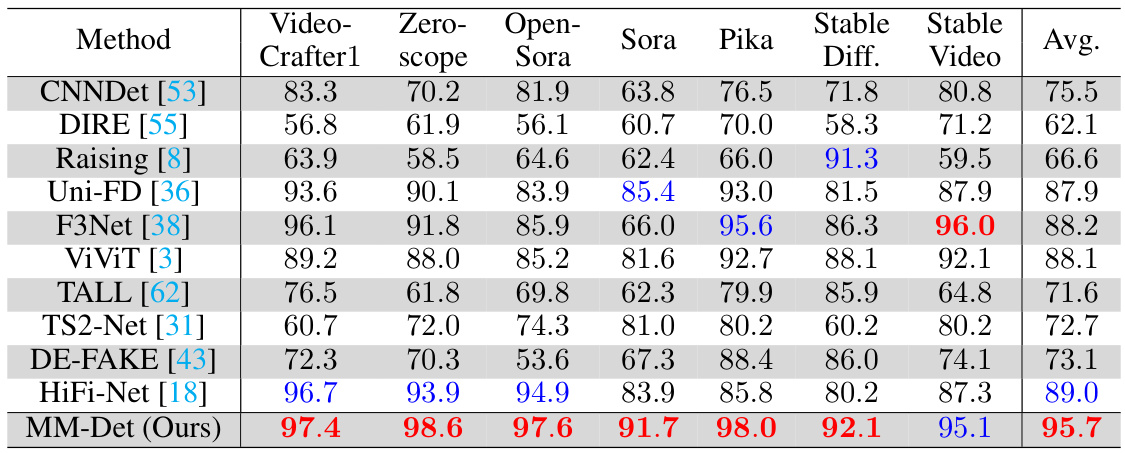
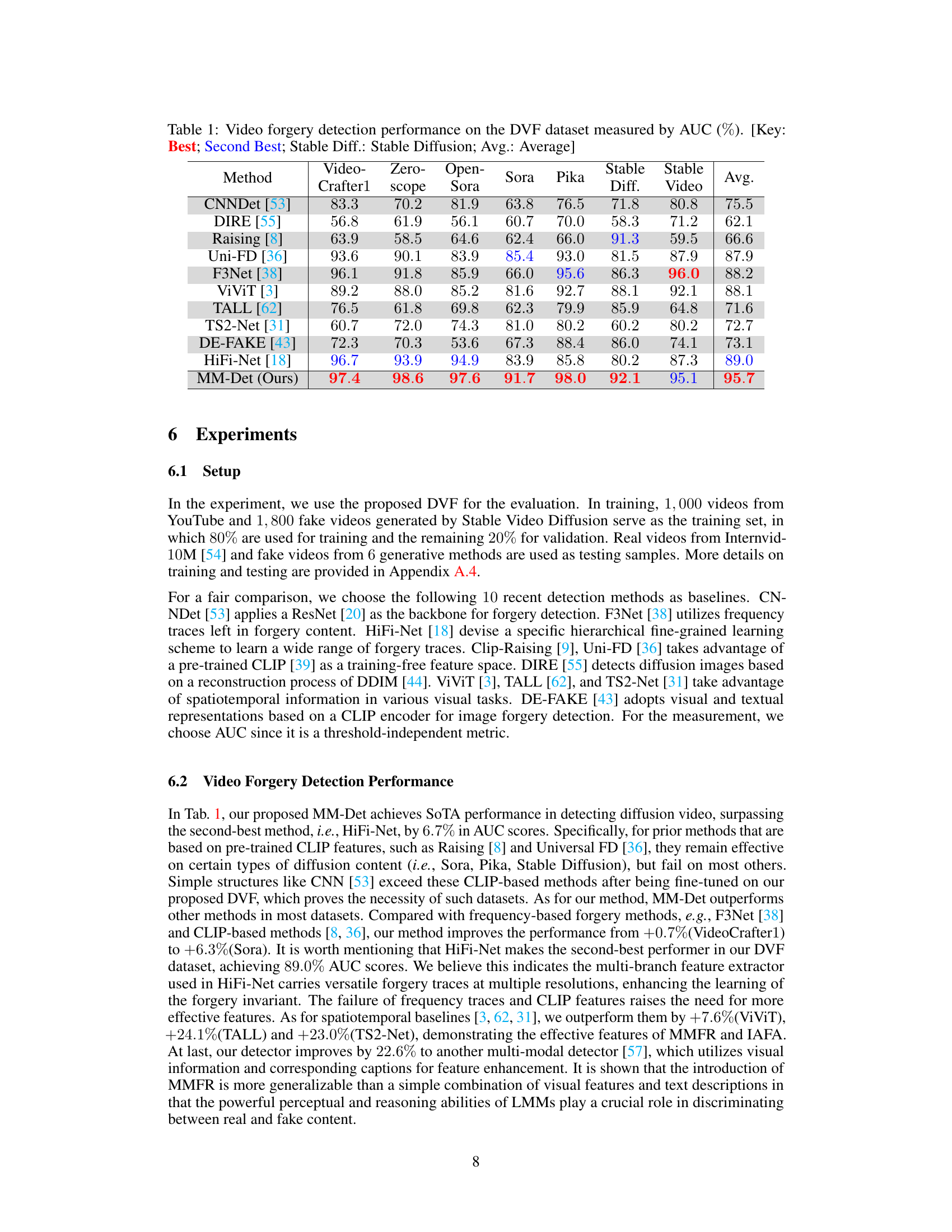
This table presents the Area Under the Curve (AUC) scores achieved by various video forgery detection methods on the Diffusion Video Forensics (DVF) dataset. The AUC score is a common metric for evaluating the performance of binary classification models, and higher scores indicate better performance. The table compares the proposed MM-Det method to several state-of-the-art techniques across different video generation methods (including Stable Diffusion and several others). The ‘Key’ section provides a legend explaining abbreviations used in the table.
In-depth insights#
Multimodal Fusion#
Multimodal fusion, in the context of this research paper, likely refers to the method of combining information from different data modalities (e.g., visual, textual) to improve the accuracy and robustness of diffusion-generated video detection. The core idea is that integrating visual features from a video with textual descriptions or other contextual data leads to a more comprehensive understanding of the video’s content and whether it’s a forgery. This fusion process may involve sophisticated techniques, such as attention mechanisms, to weigh the importance of different modalities dynamically. Successfully implementing multimodal fusion would demonstrate a significant step towards creating more resilient and generalized video forgery detection systems. It addresses the inherent limitations of unimodal approaches, which often fail to capture subtle cues present in only one data modality. The effectiveness of the fusion method will depend on the quality of the individual modalities’ representations and the appropriateness of the fusion technique employed. Ultimately, the success of multimodal fusion hinges on its ability to learn robust representations that generalize well to various types of forgeries and across different diffusion models.
Forgery Detection#
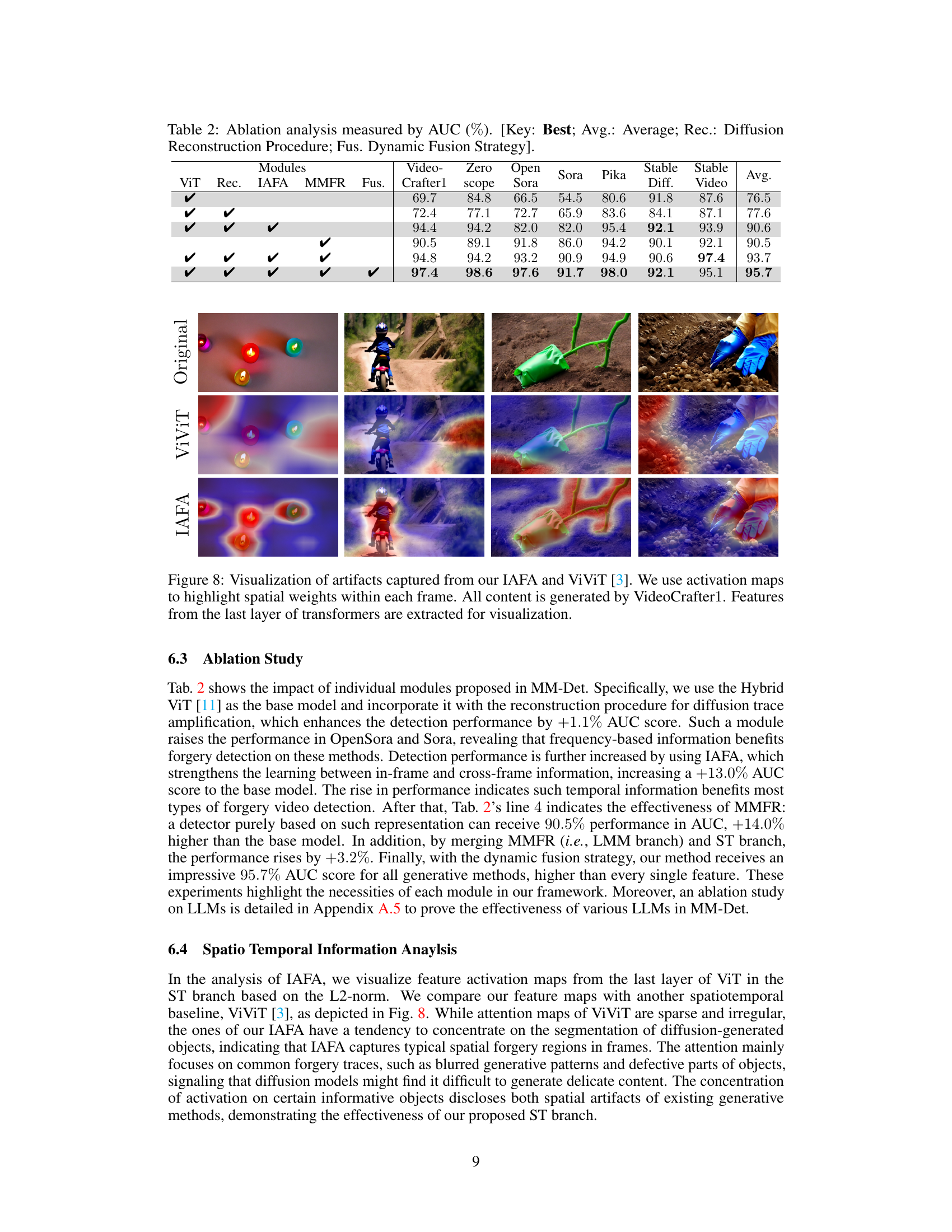
The research paper explores multi-modal forgery detection focusing on videos generated by diffusion models. It highlights the limitations of existing methods, which often struggle with diverse video semantics beyond facial forgeries. The proposed approach, Multi-Modal Detection (MM-Det), leverages large multi-modal models (LMMs) to create a robust forgery representation, capturing both perceptual and semantic information. This is combined with a spatio-temporal attention mechanism to enhance detection of subtle artifacts. A new dataset, Diffusion Video Forensics (DVF), is introduced to facilitate robust algorithm evaluation, demonstrating superior performance compared to existing state-of-the-art techniques. However, generalization to unseen forgery types remains a challenge and is identified as a key area for future work. The approach emphasizes the potential of LMMs in tackling the complexities of modern video forgery.
DVF Dataset#
The creation of a robust and comprehensive dataset is crucial for advancing the field of video forgery detection. The DVF (Diffusion Video Forensics) dataset, as described in the paper, addresses this need by providing a large-scale collection of videos generated from diverse diffusion models. Its diversity is a key strength, encompassing various resolutions, durations, and semantic content. This characteristic allows researchers to train and evaluate models that generalize well to unseen forgeries. By including real-world videos, DVF further enhances the realism of the evaluation and enables the assessment of performance against real-world scenarios. The availability of DVF, alongside the source code, promotes reproducibility and collaborative advancement in this critical area of research. However, future improvements could involve expanding the range of diffusion models included, incorporating a wider variety of manipulation techniques and video types to improve generalizability, and even addressing potential biases within the dataset to enhance fairness and robustness in detection algorithms.
LMMs in Forensics#
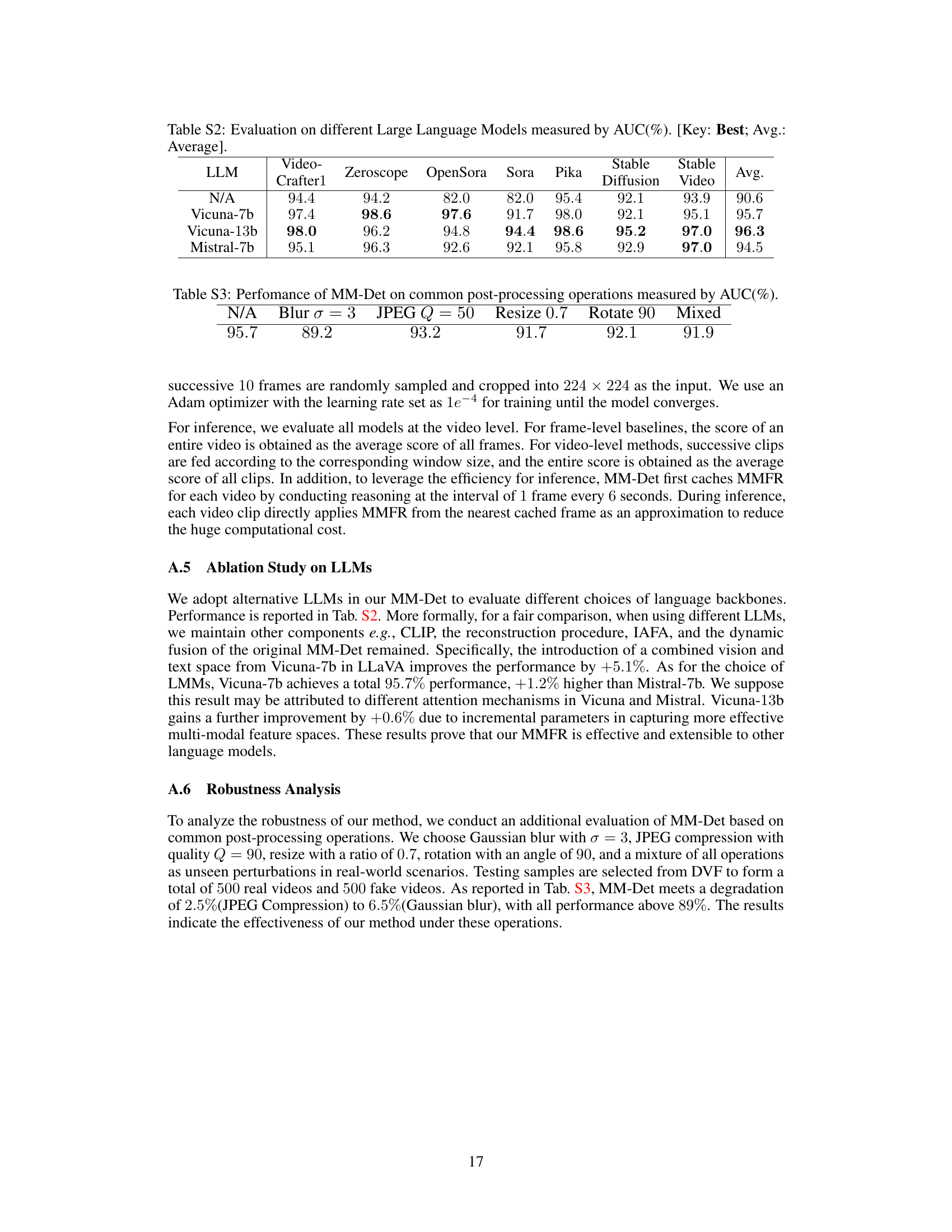
The application of Large Multimodal Models (LMMs) in forensics presents a paradigm shift in how we approach digital evidence analysis. LMMs, with their ability to integrate and reason across diverse data modalities (images, text, audio), offer unprecedented potential for detecting sophisticated forgeries and uncovering subtle inconsistencies undetectable by traditional methods. Multimodal forgery representation learned by LMMs can capture complex patterns and artifacts beyond the capabilities of single-modality models. This enables more accurate and robust detection of deepfakes, synthetic media, and other forms of digital manipulation. However, challenges remain. Data scarcity in the forensic domain is a significant hurdle for training effective LMMs, and explainability and bias in their decision-making processes are major concerns requiring attention. Moreover, the computational cost of LMMs can pose a limitation, but ongoing advancements in model efficiency and hardware capabilities should mitigate this in the future. The generalizability of LMMs to unseen forgery techniques remains a crucial area of ongoing research, which necessitates the development of new, robust benchmark datasets.
Future Directions#
Future research in diffusion-generated video detection could explore several promising avenues. Improving robustness against adversarial attacks is crucial, as sophisticated forgeries could easily bypass current detection methods. Developing more efficient and scalable algorithms is also vital for real-time applications, especially considering the ever-increasing resolution and length of videos. Addressing the challenges posed by diverse forgery techniques and the constant evolution of generative models requires adaptive and generalizable detection systems. The development of larger and more comprehensive datasets covering diverse diffusion models, forgery types, and video characteristics is necessary to evaluate the performance and generalization abilities of these systems fairly. Furthermore, exploring the integration of explainable AI techniques would enhance trust and transparency, allowing users to understand why a video is flagged as fake and providing insightful information about the detected forgeries. Finally, research should investigate the ethical implications of this technology, focusing on its potential misuse and ensuring responsible development and deployment.
More visual insights#
More on figures
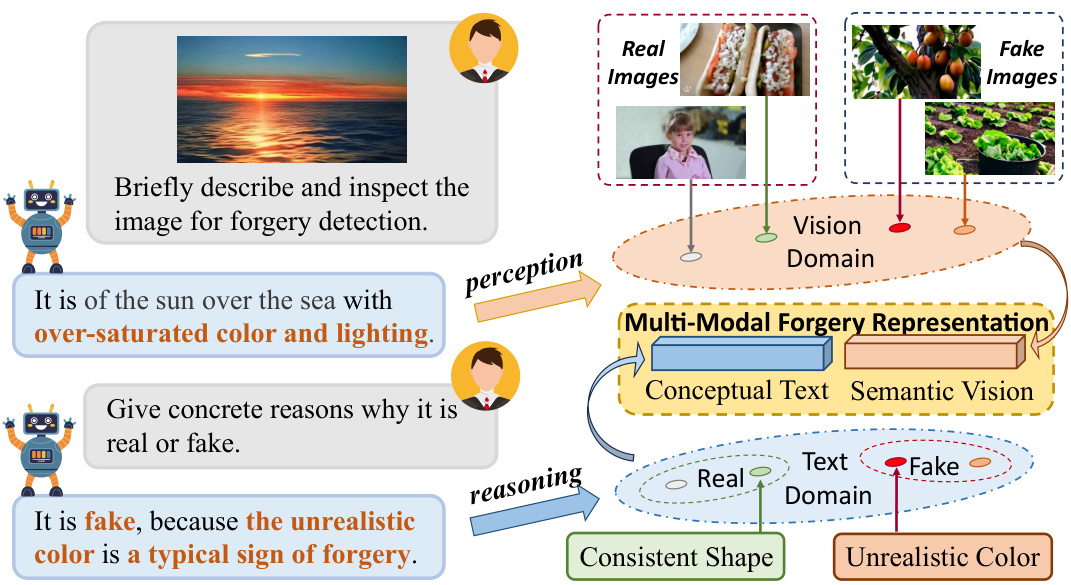
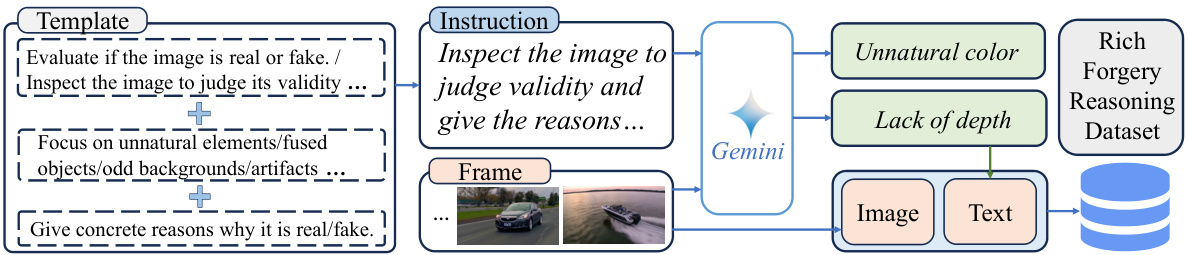
This figure illustrates how Large Multi-modal Models (LMMs) are used to detect forgeries by analyzing both visual and textual information. The LMMs perceive visual artifacts and anomalies in an image and provide a textual explanation for why it is considered real or fake. This textual explanation highlights features like ‘consistent shape’ (indicative of authenticity) and ‘unrealistic color’ (indicative of forgery). The process culminates in the generation of a Multi-Modal Forgery Representation (MMFR), used for forgery detection.
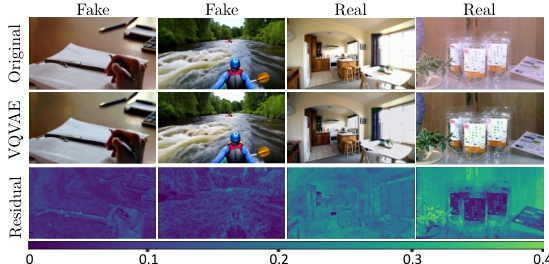
This figure shows the residual difference between the original images and the images reconstructed using a VQ-VAE. The reconstruction of real images shows clear edges and visible traces, while the reconstruction of diffusion-generated images is much more effective, resulting in residual images with far fewer visible traces. This highlights the ability of the VQ-VAE to amplify the artifacts present in diffusion-generated videos, making them easier to detect.

This figure illustrates the architecture of the proposed Multi-Modal Detection (MM-Det) network for diffusion video forgery detection. It shows two main branches: the LMM branch and the ST branch. The LMM branch uses a Large Multi-modal Model to generate a Multi-Modal Forgery Representation (MMFR) that captures forgery traces from various videos. The ST branch uses a VQ-VAE, CNN encoder, and IAFA to extract spatiotemporal features based on spatial artifacts and temporal inconsistencies. Finally, a dynamic fusion strategy combines the features from both branches for the final forgery prediction.
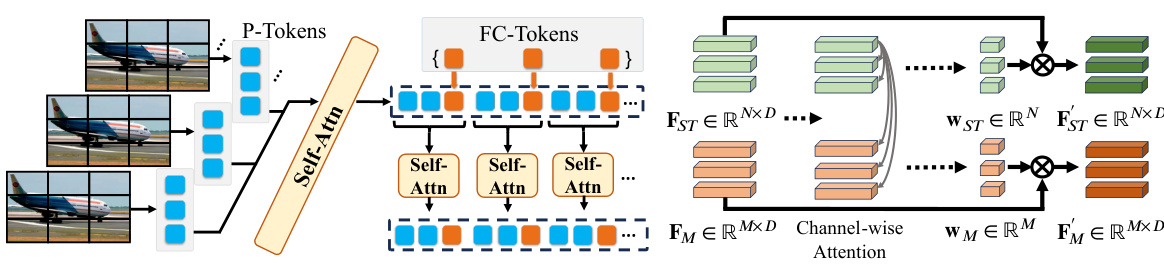
This figure details the architecture of the In-and-Across Frame Attention (IAFA) mechanism and the dynamic fusion strategy in the MM-Det model. IAFA processes both local (patch-level) and global (frame-level) features within each frame and across frames using a transformer network. The dynamic fusion strategy combines features from the IAFA module and a multi-modal forgery representation to generate a final forgery prediction.

This figure shows sample videos from the Diffusion Video Forensics (DVF) dataset, which is a new dataset created for this research. It showcases the variety of videos included, highlighting both real videos (from Internvid-10M and Youtube-8M) and fake videos generated using eight different diffusion models (OSora, VC1, Zscope, Sora, Pika, St. V. D., St. Diff., and St.V.). The figure visually demonstrates the diversity of content and quality in the DVF dataset.

This figure provides an overview of the Diffusion Video Forensics (DVF) dataset. Panel (a) illustrates the process of generating fake videos using both text-to-video and image-to-video methods, drawing on real data from Internvid-10M and YouTube-8M. Panel (b) shows the distribution of videos across different resolutions and durations. Panel (c) presents a bar chart visualizing the number of videos and frames within the dataset for each of the eight included video generation methods.

This figure compares the attention maps from the last layer of the transformer in IAFA and ViViT to highlight spatial weights within each frame. The activation maps show where the models focus their attention when trying to detect forgery. All the video frames shown are generated by VideoCrafter1. The comparison illustrates differences in how IAFA and ViViT identify spatial artifacts in generated videos.
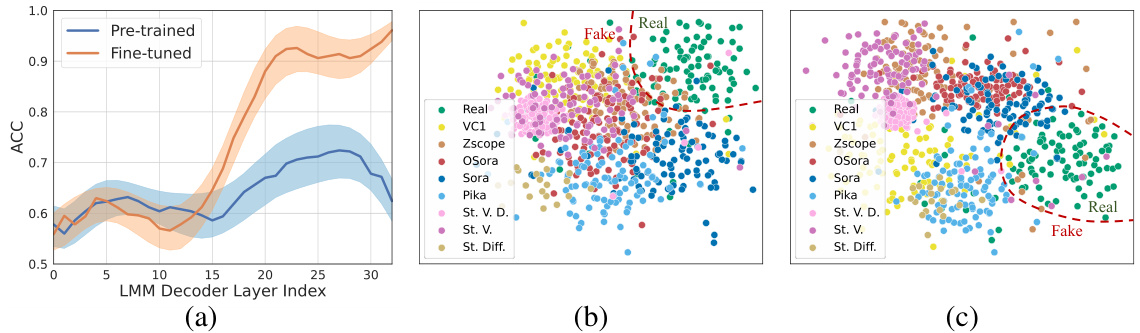
This figure presents an analysis of the Multimodal Forgery Representation (MMFR) and its effectiveness in distinguishing real and fake videos. (a) shows clustering accuracy using features from different layers of the LMM branch, demonstrating that certain layers are better at distinguishing forgeries. (b) and (c) use t-SNE to visualize features from the ST (spatio-temporal) and LMM branches, respectively, showing clear separation between real and fake videos, highlighting the effectiveness of MMFR in capturing discriminatory characteristics.
More on tables
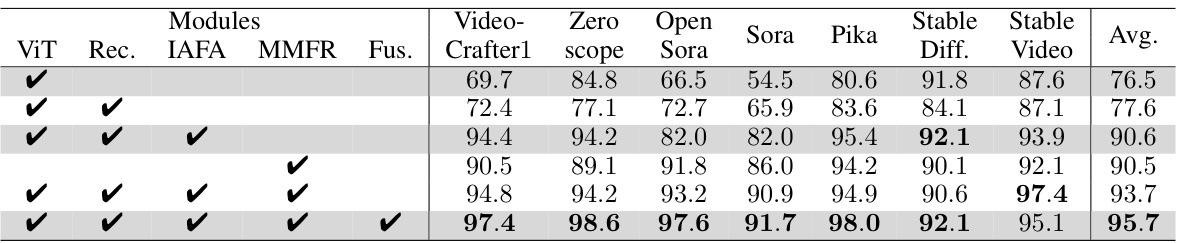
This table presents the Area Under the Curve (AUC) scores achieved by various video forgery detection methods on the Diffusion Video Forensics (DVF) dataset. It compares the performance of the proposed Multi-Modal Detection (MM-Det) method against ten state-of-the-art baselines. The AUC score measures the overall ability of each method to correctly classify videos as either real or fake. The table is broken down by different video generation methods (e.g., VideoCrafter1, Zeroscope, Sora, Pika, Stable Diffusion, Stable Video) allowing for performance comparison across various forgery types. The ‘Avg.’ column provides an average AUC across all generation methods.

This table presents the Area Under the Curve (AUC) scores achieved by various video forgery detection methods on the Diffusion Video Forensics (DVF) dataset. The AUC score quantifies the performance of each method in distinguishing between real and fake videos. The table includes several state-of-the-art methods (e.g., HiFi-Net, DIRE, Uni-FD) along with the proposed MM-Det method. The ‘Key’ section provides a legend for abbreviations used in the table.
This table presents the Area Under the Curve (AUC) scores achieved by various video forgery detection methods on the Diffusion Video Forensics (DVF) dataset. The AUC represents the performance of each method in distinguishing between real and fake videos. The table compares the proposed MM-Det method with ten state-of-the-art baseline methods across different diffusion models (VideoCrafter1, Zeroscope, OpenSora, Sora, Pika, Stable Diffusion, Stable Video) and provides average performance metrics. The key clarifies abbreviations used in the table.

This table presents the Area Under the Curve (AUC) scores for video forgery detection on the Diffusion Video Forensics (DVF) dataset. Multiple state-of-the-art methods are compared against the proposed MM-Det method. The AUC scores are shown for individual video generation methods (Video-Crafter1, Zeroscope, OpenSora, Sora, Pika, Stable Diffusion, Stable Video) and the average (Avg.) across all methods. The table highlights the best and second-best performing methods for each generation method, indicating the superior performance of MM-Det.
Full paper#