↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-Language Models (VLMs) like CLIP excel at zero-shot image classification, but their performance degrades significantly when encountering domain shifts (e.g., images from different sources or with corruptions). Existing test-time adaptation methods often require extensive training or additional modules. This limitation hinders their practical application in real-world scenarios.
The paper introduces Weight Average Test-Time Adaptation (WATT), a novel method that addresses this issue. WATT leverages multiple text prompts to generate diverse model hypotheses and updates the model’s weights by averaging the outputs of these models. This technique is computationally efficient and doesn’t require additional modules. WATT shows significant improvement in performance on various datasets compared to current methods. Its efficacy without requiring extra training or parameters makes it suitable for real-world applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on Vision-Language Models (VLMs) and domain adaptation. It introduces a novel, efficient test-time adaptation method that significantly improves VLM performance under domain shifts. The weight averaging technique is particularly relevant for current research, and the results open avenues for improving VLM robustness and generalization in real-world applications.
Visual Insights#
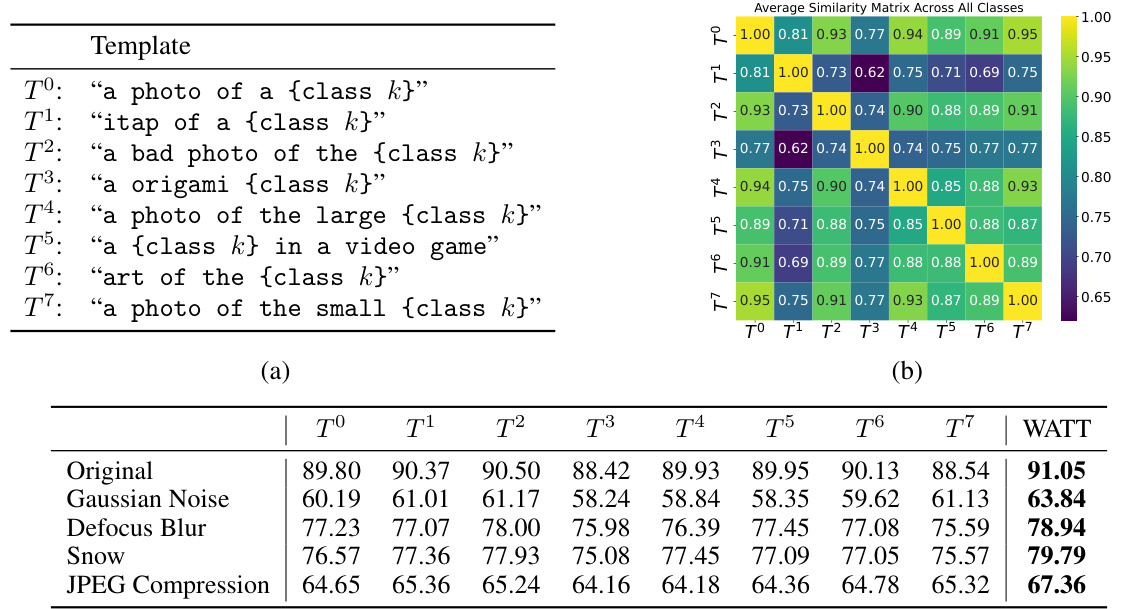
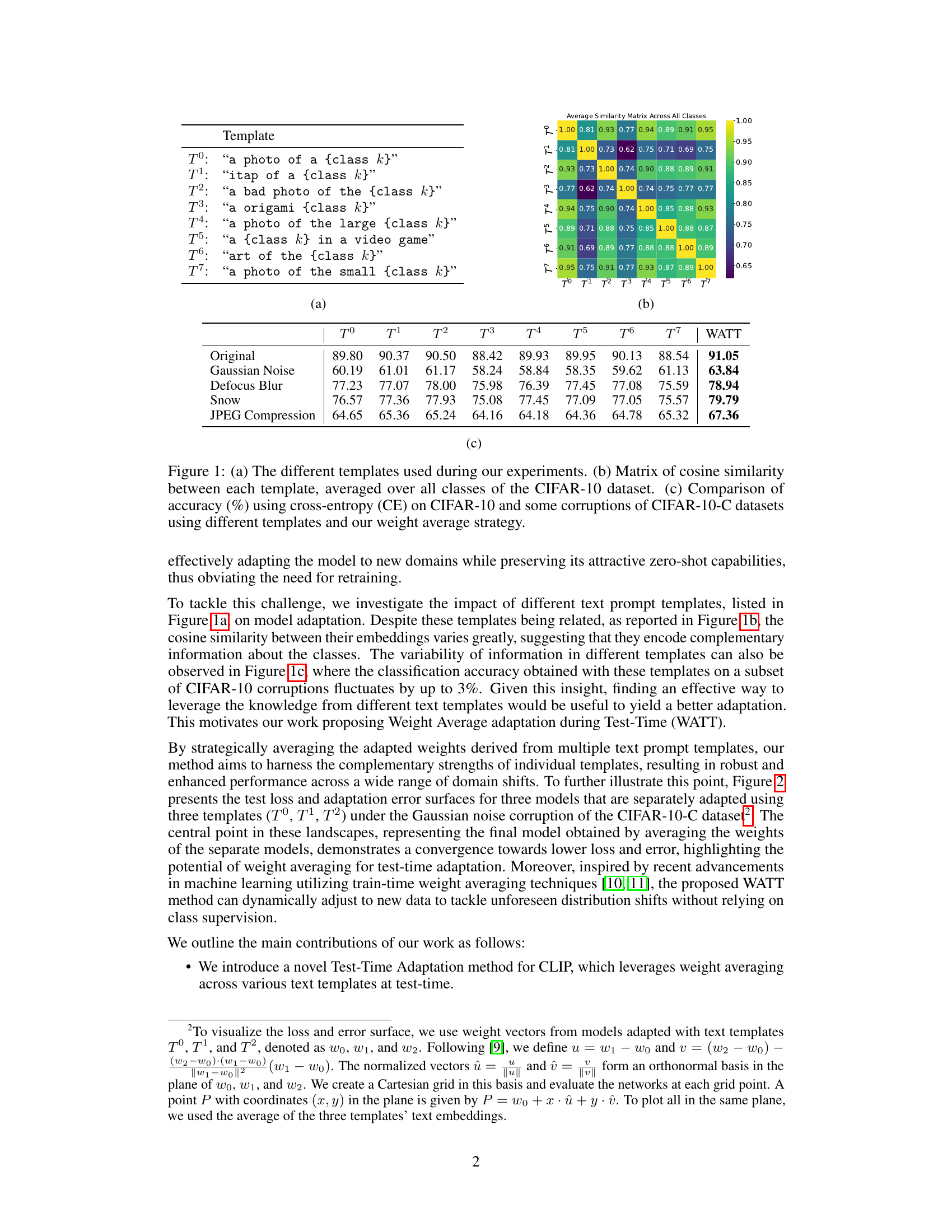
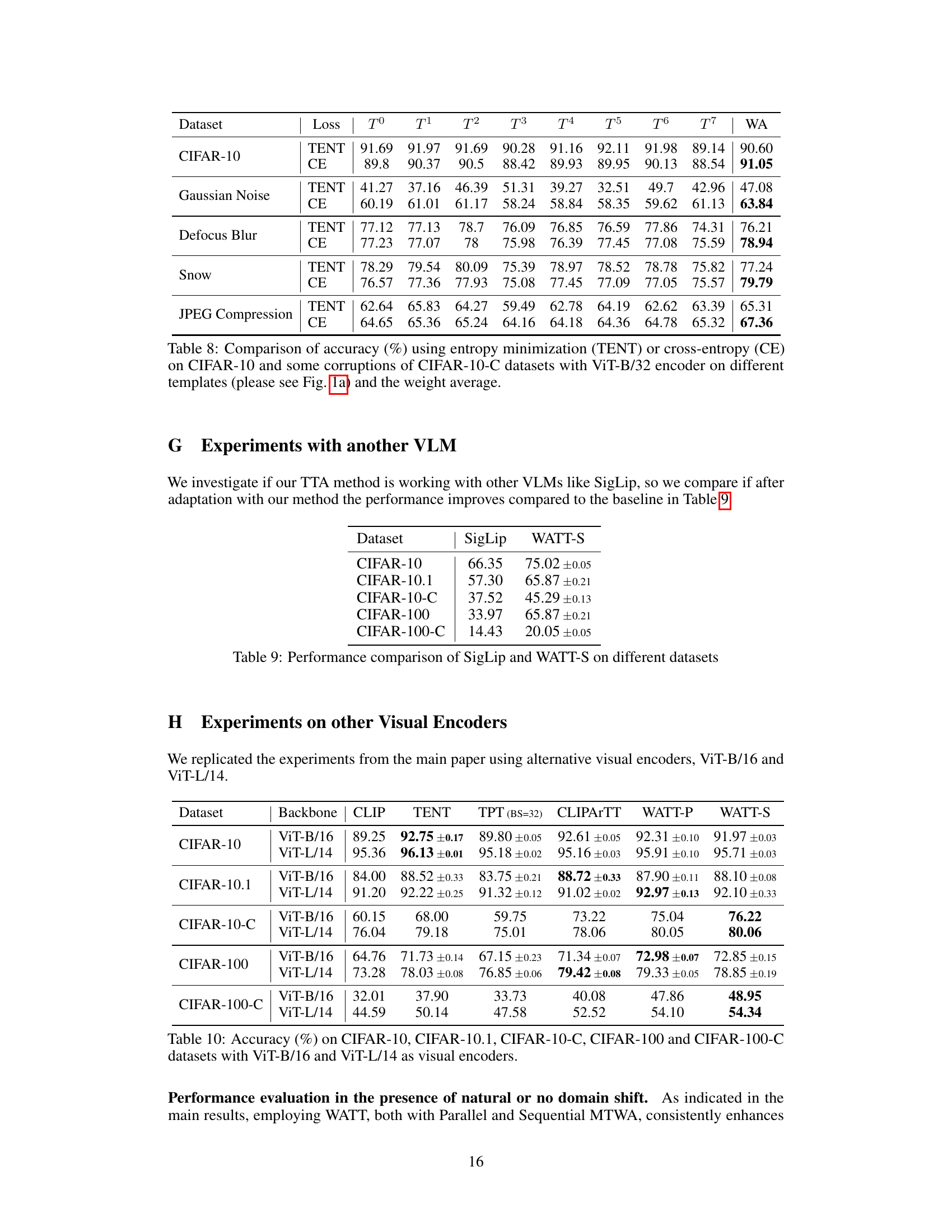
This figure shows the different text prompt templates used in the experiments (a), the cosine similarity matrix between these templates averaged across all CIFAR-10 classes (b), and a comparison of the classification accuracy achieved using different templates and the proposed weight average strategy on CIFAR-10 and various corrupted versions of CIFAR-10 (c). The results highlight the variability in information encoded by different templates and the effectiveness of the proposed weight averaging technique in improving robustness across domain shifts.
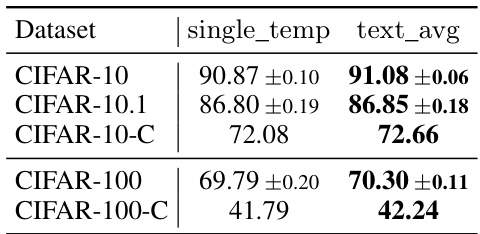
This table presents the accuracy results obtained using different text ensembles (single template vs. text average) for image classification on various datasets: CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. The results demonstrate the effectiveness of employing a text averaging technique to boost the overall test-time performance in comparison to the use of a single text template for prompt generation. The improvements in accuracy are shown across different datasets exhibiting varying levels of difficulty and domain shifts.
In-depth insights#
WATT: Test-Time CLIP#
The heading “WATT: Test-Time CLIP” suggests a research paper focusing on adapting the CLIP (Contrastive Language–Image Pre-training) model for improved performance during test time. WATT likely represents a novel method proposed in the paper, perhaps an adaptation technique applied to CLIP’s architecture or training process. The “Test-Time” aspect indicates that this adaptation occurs during the testing phase, rather than during a prior training stage, making it suitable for scenarios with limited labeled data or when dealing with domain shift. This approach is crucial in real-world applications where retraining the entire model is costly or infeasible. The paper likely benchmarks WATT against existing test-time adaptation (TTA) methods and demonstrates its superior performance on various datasets and under different domain shifts. The key contributions would likely include the introduction of WATT itself, along with a comprehensive experimental evaluation showing its effectiveness and efficiency compared to other TTA methods for CLIP. The paper might also investigate various factors influencing WATT’s performance, such as hyperparameter choices, dataset characteristics, and types of domain shift encountered. The overall goal would be to show how WATT improves the generalization and robustness of CLIP in situations where standard zero-shot inference might fall short.
Multi-Template WA#
The proposed Multi-Template Weight Averaging (WA) strategy is a significant contribution, addressing limitations of single-template adaptation in Vision-Language Models (VLMs). By employing multiple text prompts, it leverages the complementary information encoded in diverse textual cues. This approach tackles the challenge of domain shift by generating a diverse set of model hypotheses during the adaptation phase. The subsequent weight averaging of these hypotheses effectively consolidates the learned information, leading to a more robust and generalizable model. The strategy’s effectiveness stems from its ability to harness the complementary strengths of individual templates, mitigating the weaknesses inherent in relying on a single prompt. This methodology also showcases a more effective way to exploit the inherent capabilities of CLIP, specifically in scenarios involving significant domain shifts and data scarcity. The results demonstrate the method’s ability to enhance model performance and robustness across diverse datasets and corruption types, indicating a powerful, yet simple approach to improve VLM adaptation during test-time.
Transductive TTA Loss#
The heading ‘Transductive TTA Loss’ suggests a method for test-time adaptation (TTA) that leverages relationships between samples within a batch. Transductive learning is emphasized, implying the algorithm considers the entire batch simultaneously rather than individual samples. The loss function likely incorporates both visual and textual similarities between samples, possibly using similarity matrices derived from embeddings of image and text data to guide adaptation. This holistic approach aims to improve the model’s understanding of the current batch’s distribution, enabling more effective adaptation to unseen data, particularly when dealing with limited examples at test time. The term ‘TTA’ highlights the method’s focus on adaptation during the test phase, avoiding the need for additional training cycles. This approach stands in contrast to inductive methods, which treat each example independently. The effectiveness of a transductive TTA loss would hinge on its ability to effectively capture and utilize inter-sample relationships to refine predictions, making it particularly useful for scenarios with limited test data where the model’s limited exposure needs to be maximally leveraged. The use of cross-entropy suggests the method likely employs pseudo-labels to aid the adaptation process.
Ablation Studies#
Ablation studies systematically investigate the contribution of individual components within a machine learning model. In this context, it would involve selectively removing or disabling parts of the proposed Weight Average Test-Time Adaptation (WATT) method to assess their impact on overall performance. This could entail experiments with different numbers of templates, analyzing the effects of various averaging strategies (weight vs. output vs. text averaging), and examining the influence of the choice of loss function and other hyperparameters. The primary goal is to identify the core elements crucial for WATT’s success and highlight the relative importance of different architectural choices and design decisions. This process not only validates the design but also reveals potential areas for improvement or simplification. By understanding which components most substantially affect performance, researchers can refine their approach, optimize resource allocation, and gain a deeper understanding of the underlying principles driving WATT’s effectiveness. Insights gained could lead to more robust and efficient adaptation techniques. The ablation study results, therefore, provide crucial evidence to support the claims made about WATT’s performance and contribute to a more thorough understanding of its capabilities and limitations.
Future of WATT#
The future of WATT, a novel test-time adaptation method for CLIP, holds significant promise. Further research could explore extending WATT’s effectiveness to other vision-language models beyond CLIP, potentially leveraging its weight averaging technique to improve the zero-shot capabilities and robustness of various architectures. Investigating the impact of different text prompt strategies and their interplay with weight averaging could yield further performance enhancements. Exploring applications of WATT in diverse tasks, such as video understanding and medical image analysis, is crucial to establish its broader utility. Finally, developing more efficient methods for weight averaging and template selection, especially for resource-constrained environments, will be crucial for practical deployment and widespread adoption. Addressing potential limitations, such as the computational cost of multi-template adaptation, will be key to realizing WATT’s full potential.
More visual insights#
More on figures
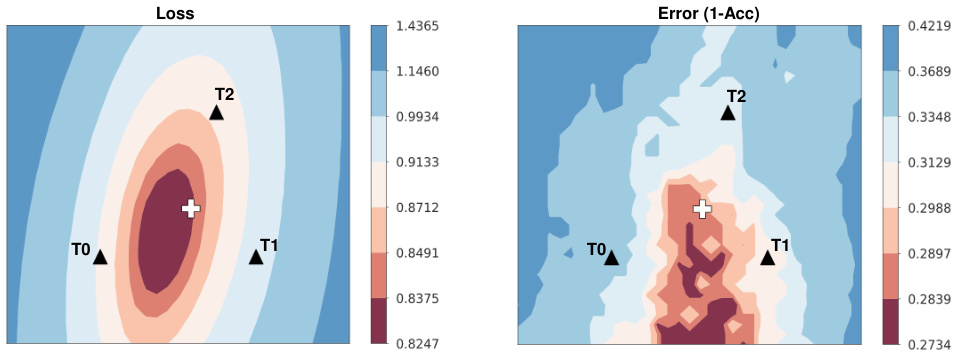
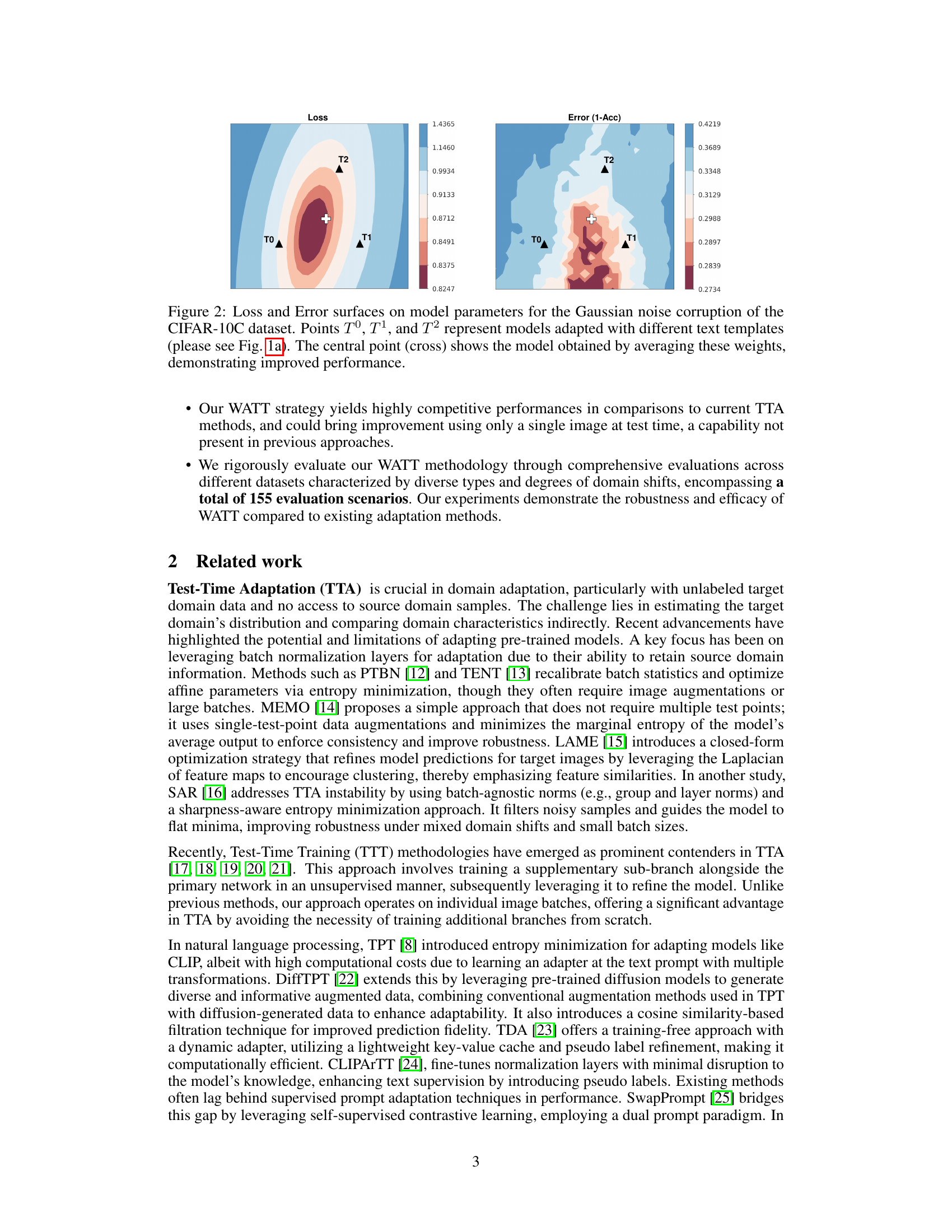
This figure shows the loss and error surfaces for three models adapted using three different text templates (T0, T1, T2) under Gaussian noise corruption of the CIFAR-10-C dataset. Each point on the surface represents a model’s performance based on its parameter values. The central point (marked by a cross) represents the model obtained by averaging the weights of the three individually adapted models. This visualization demonstrates that the weight averaging strategy leads to a model with improved performance (lower loss and error) compared to models adapted with individual templates.
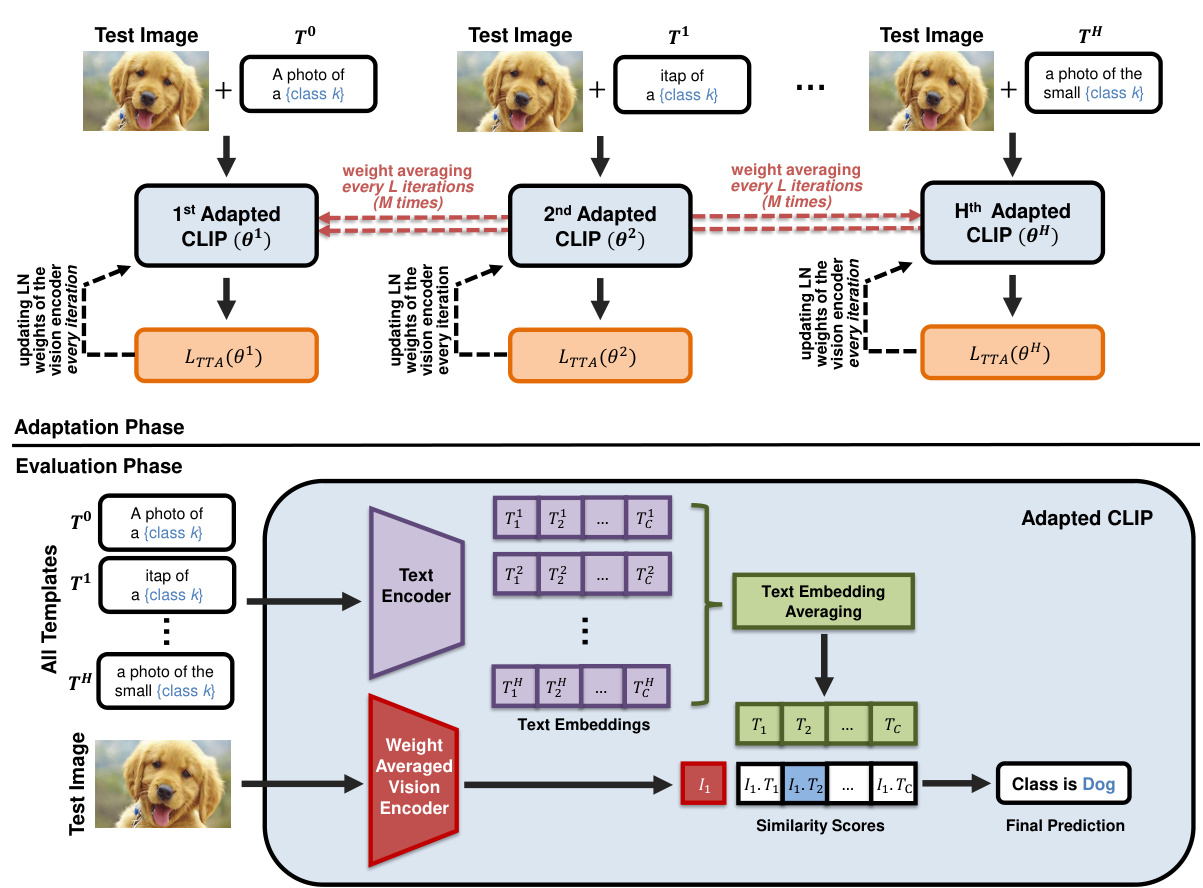
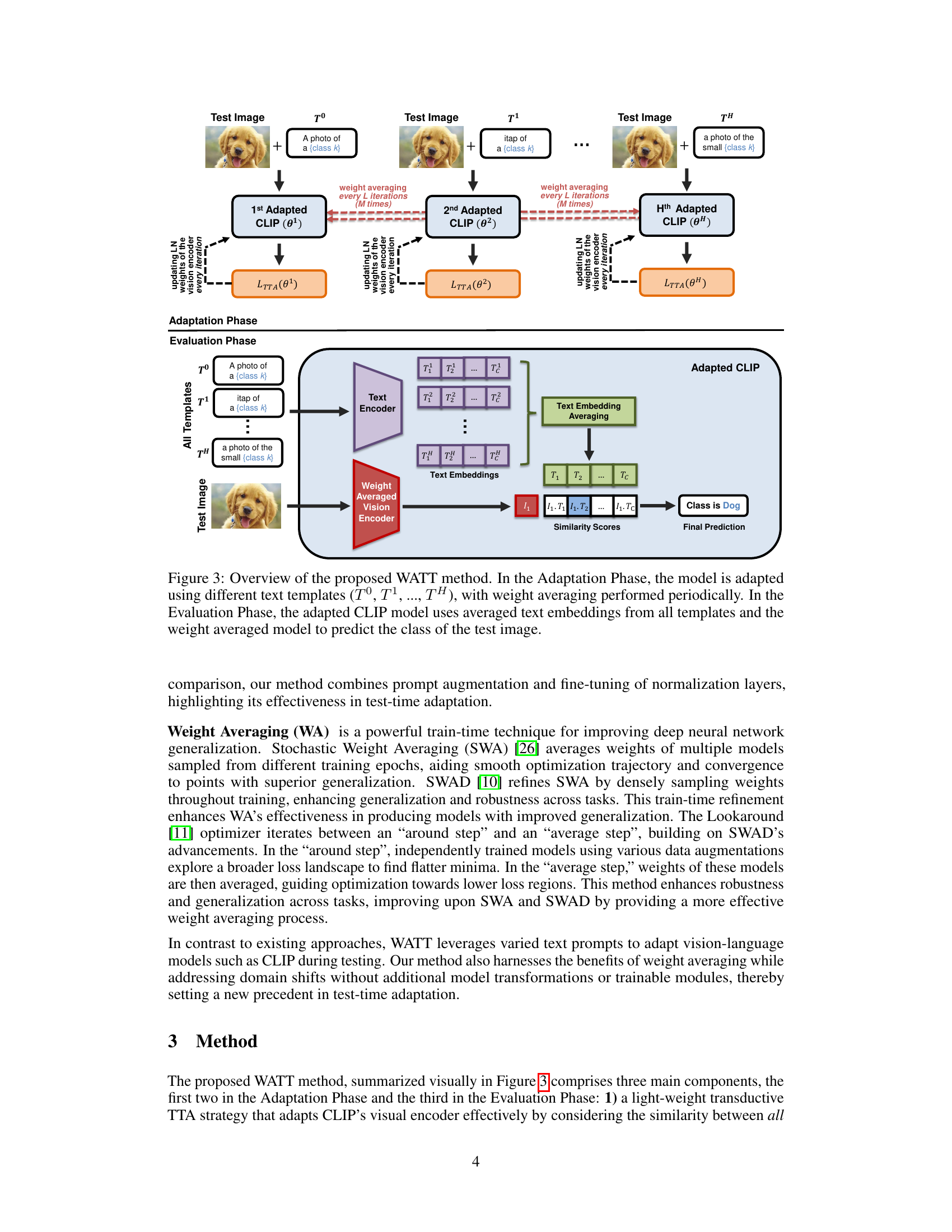
This figure illustrates the WATT method’s two phases: Adaptation and Evaluation. In the Adaptation Phase, multiple versions of the CLIP model are created, each using a different text template to adapt to a test image. Weight averaging is performed periodically to combine the knowledge gained from each template. The Evaluation Phase leverages the averaged text embeddings and the weight-averaged vision encoder from the Adaptation Phase to generate a final class prediction for the test image.
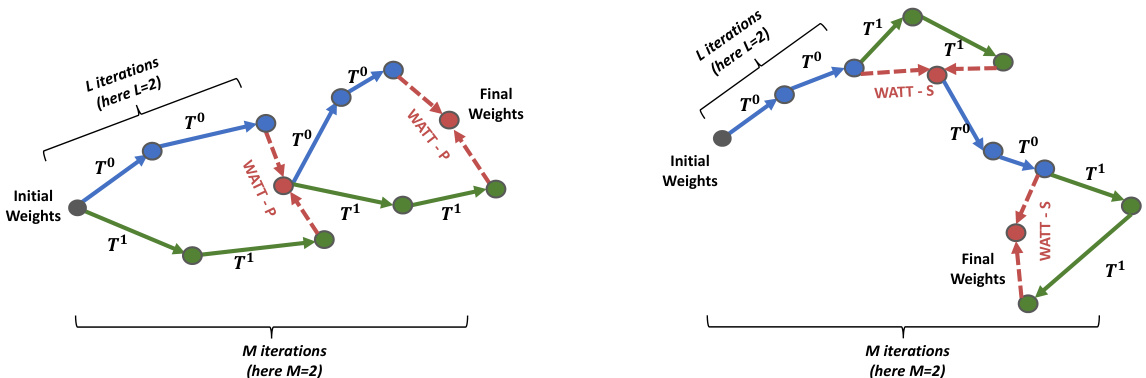
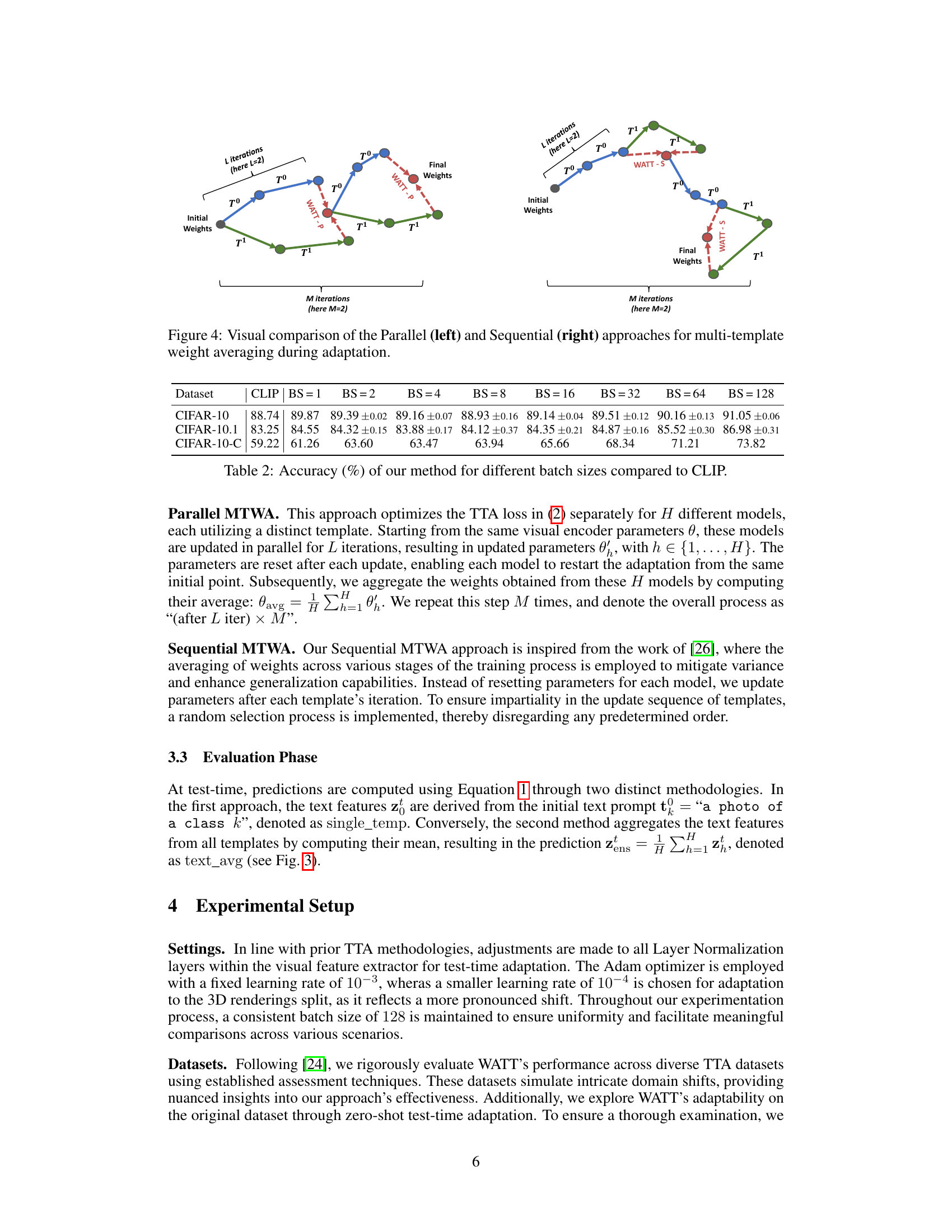
This figure visually compares two multi-template weight averaging strategies: Parallel (WATT-P) and Sequential (WATT-S). In the Parallel approach, multiple models are trained in parallel, each using a different template. After L iterations, their weights are averaged to obtain a final set of weights. This process is repeated M times. The Sequential approach trains a single model iteratively, updating the weights after each template is used for L iterations, this is also repeated M times. The diagram shows how the weights are updated and averaged for each method, highlighting the differences in their adaptation strategies.
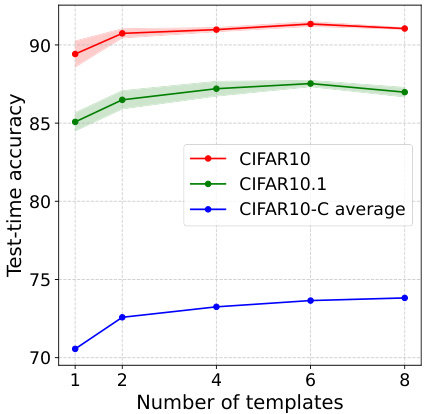
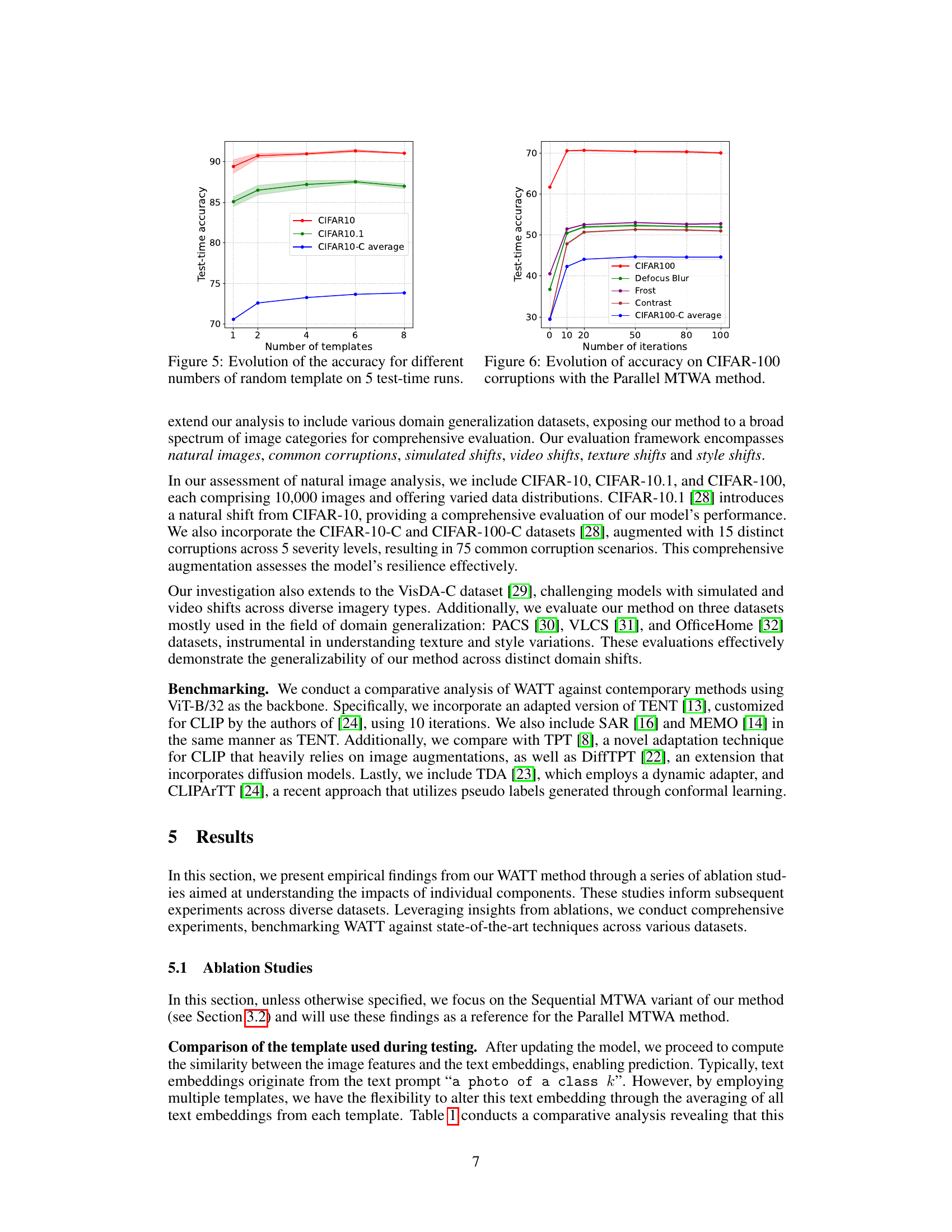
This figure shows the performance of the WATT model on CIFAR-10, CIFAR-10.1, and CIFAR-10-C datasets as the number of templates used for adaptation is varied. The x-axis represents the number of templates randomly selected for adaptation in each of the 5 test-time runs. The y-axis shows the test-time accuracy. The shaded regions represent the standard deviation across those 5 runs. The plot demonstrates that the model’s accuracy increases with the number of templates, particularly on the more challenging CIFAR-10-C dataset, which involves various types of image corruptions. For CIFAR-10 and CIFAR-10.1, the accuracy plateaus after using about 6 templates.
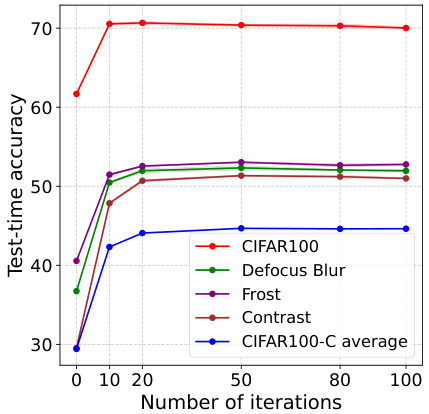
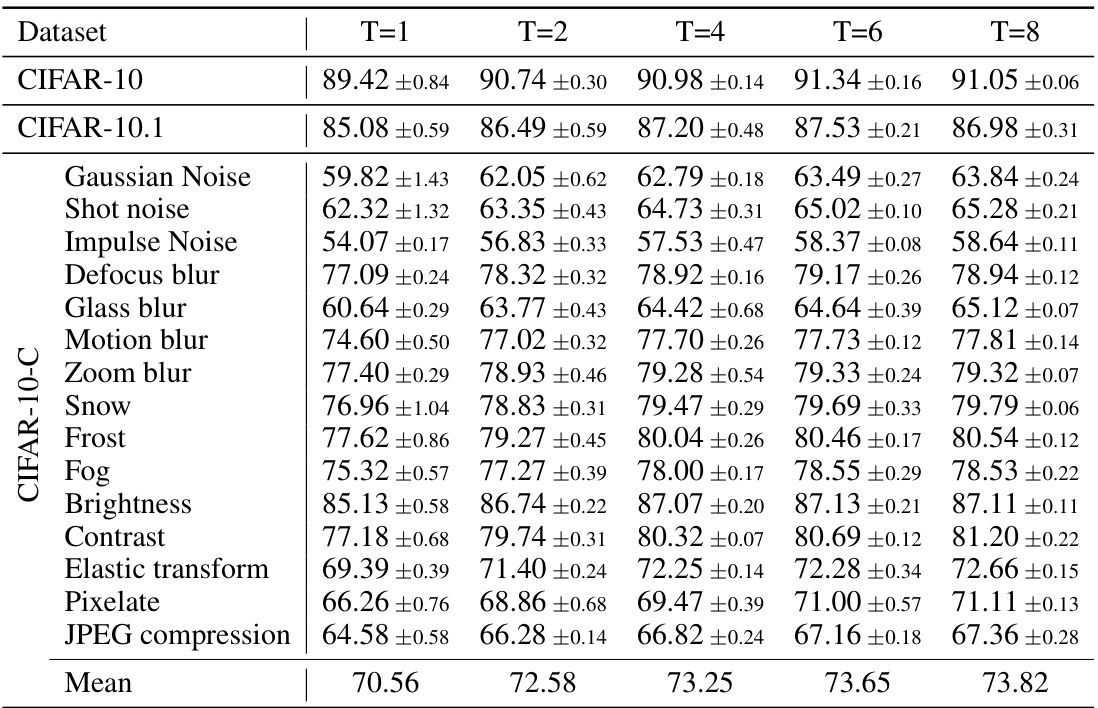
This figure shows how the accuracy of the Parallel Multi-Template Weight Averaging (MTWA) method changes over different numbers of iterations on various CIFAR-100 corruptions (e.g., Defocus Blur, Frost, Contrast). It illustrates the convergence of the model’s performance as the number of adaptation iterations increases. The plot helps to determine an optimal number of iterations where additional adaptations yield minimal improvement, suggesting a point of diminishing returns in the model’s refinement process.
More on tables

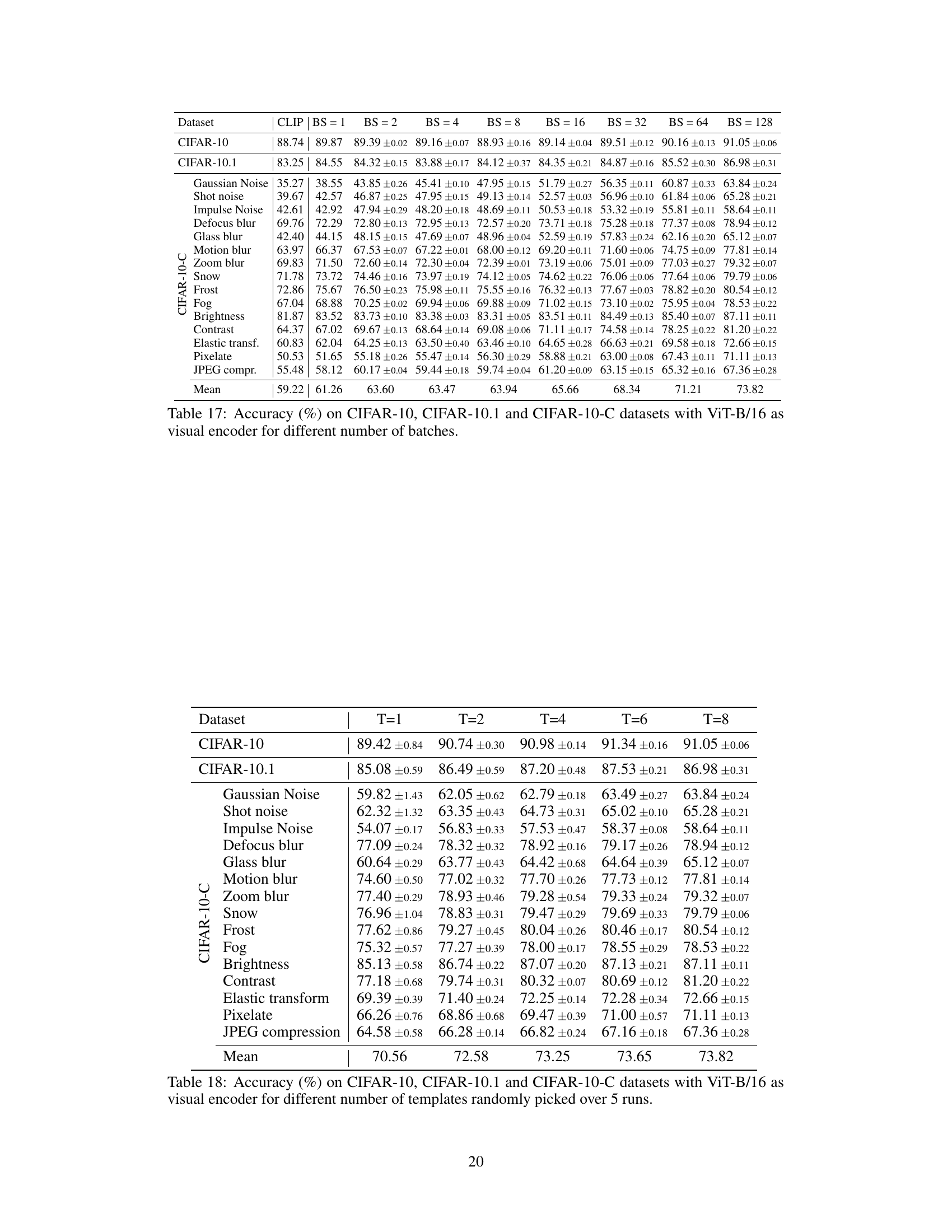
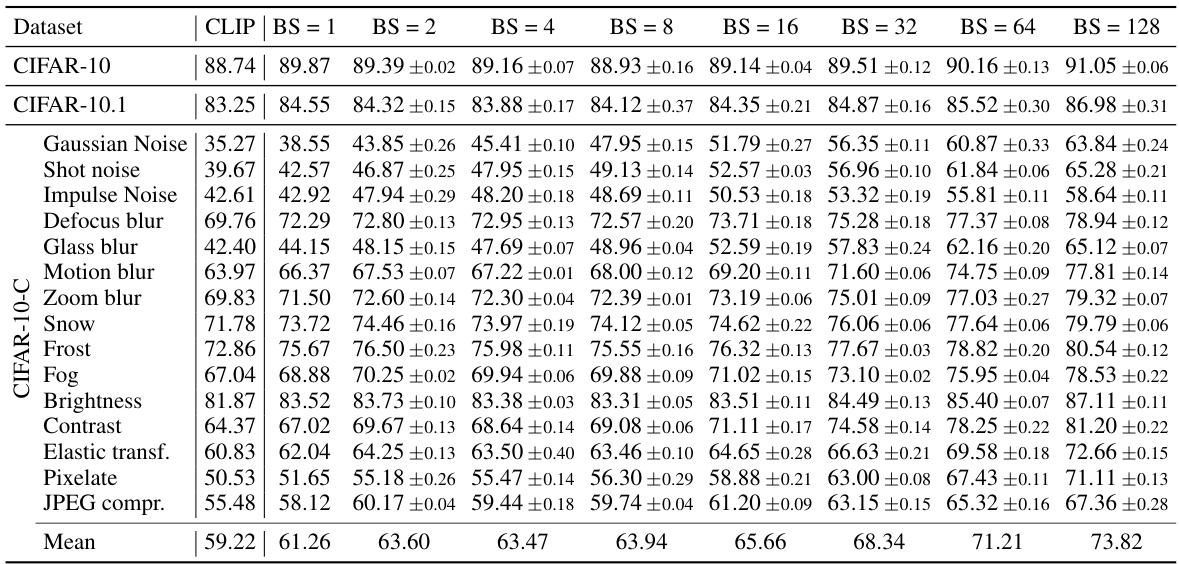
This table presents the accuracy of the proposed WATT method across different batch sizes (BS) on the CIFAR-10, CIFAR-10.1, and CIFAR-10-C datasets. The results are compared against the baseline CLIP model. The table demonstrates the robustness of WATT across varying batch sizes, highlighting its ability to maintain high accuracy even with smaller batch sizes.
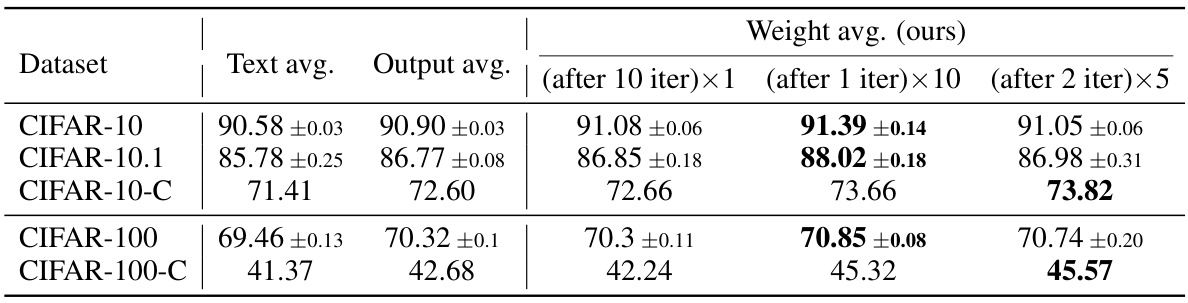
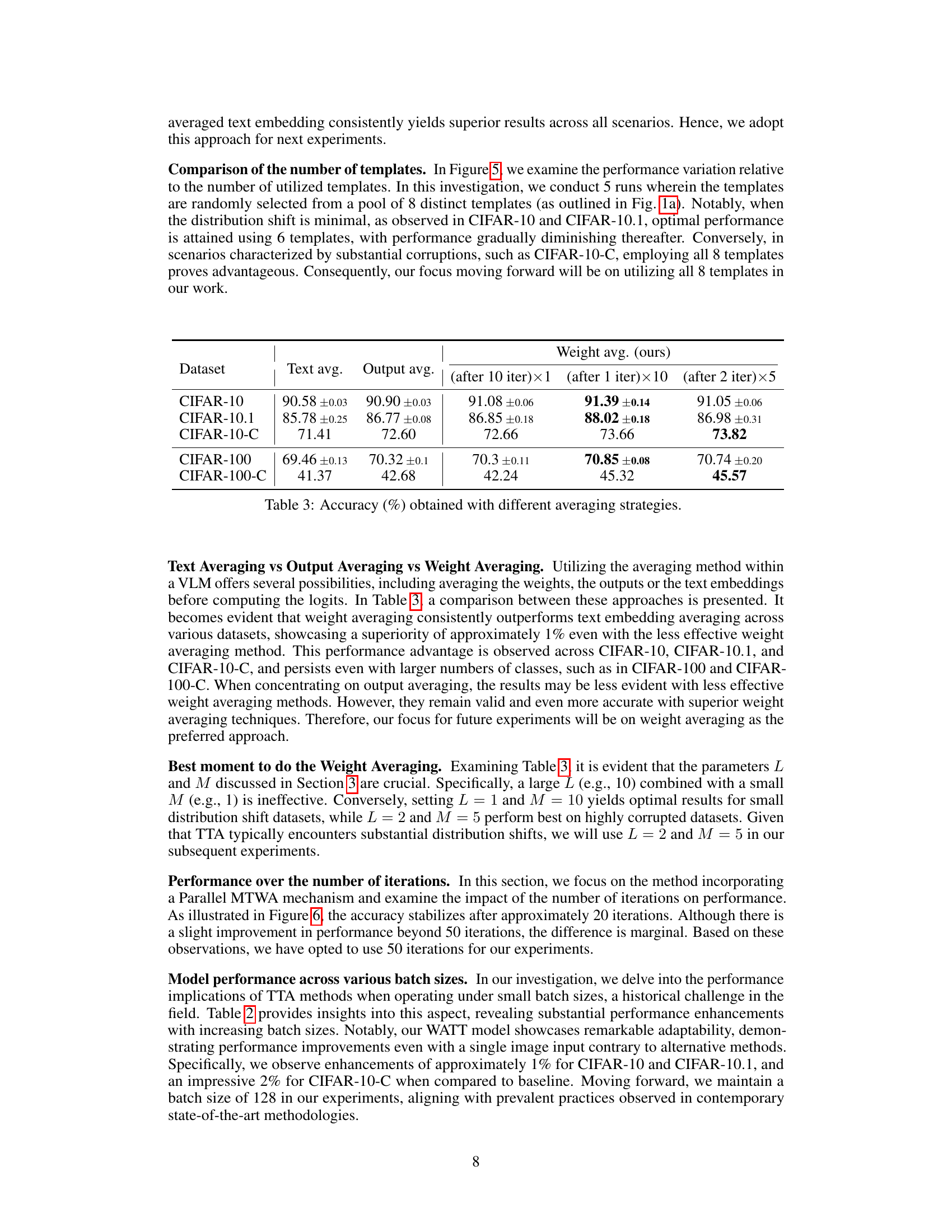
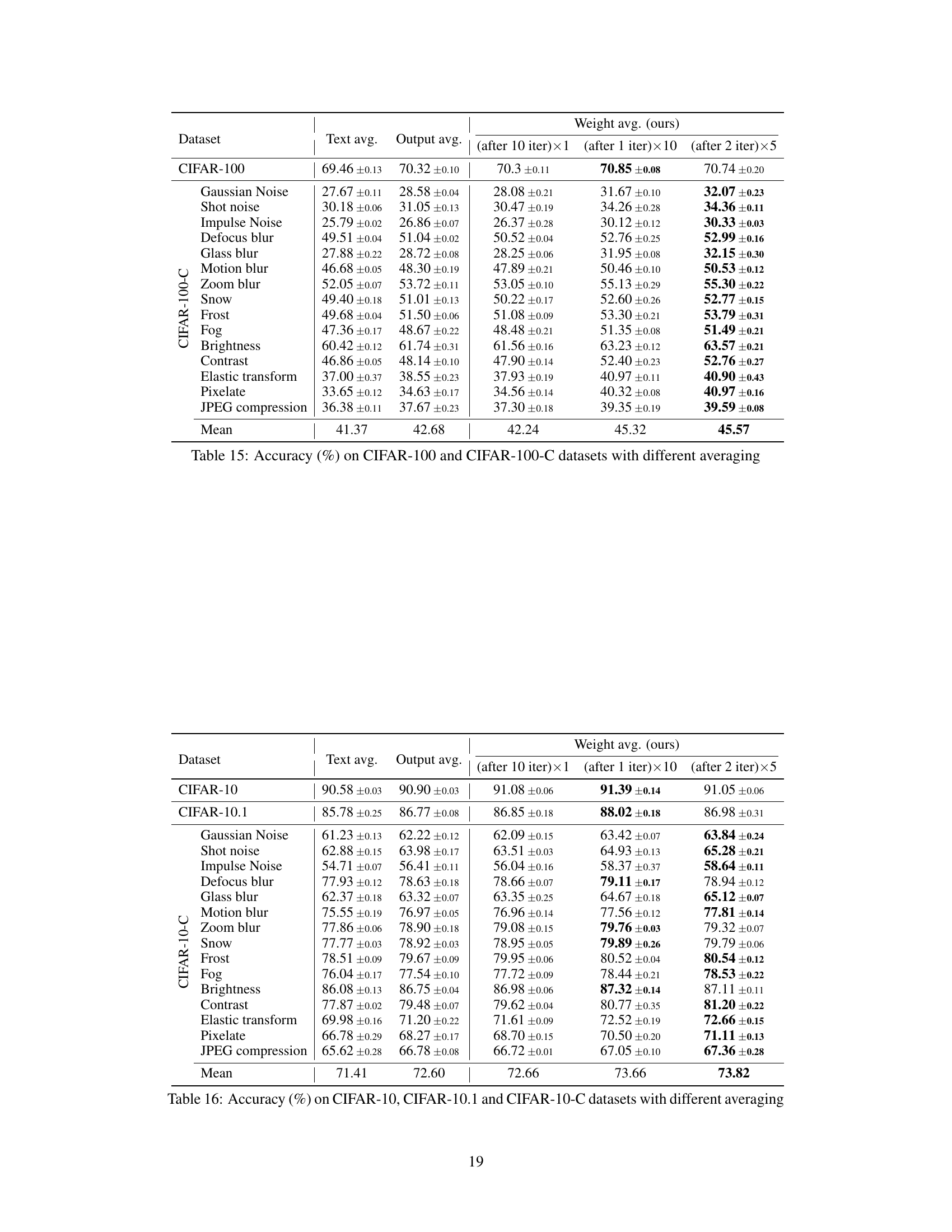
This table compares the performance of three different averaging strategies: Text averaging, Output averaging, and Weight averaging (the proposed WATT method). The results are shown for various datasets (CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C), and different numbers of iterations of the weight averaging process are included for the WATT method. The table demonstrates that the weight averaging strategy generally outperforms the other methods, showcasing the effectiveness of the proposed WATT approach for test-time adaptation.
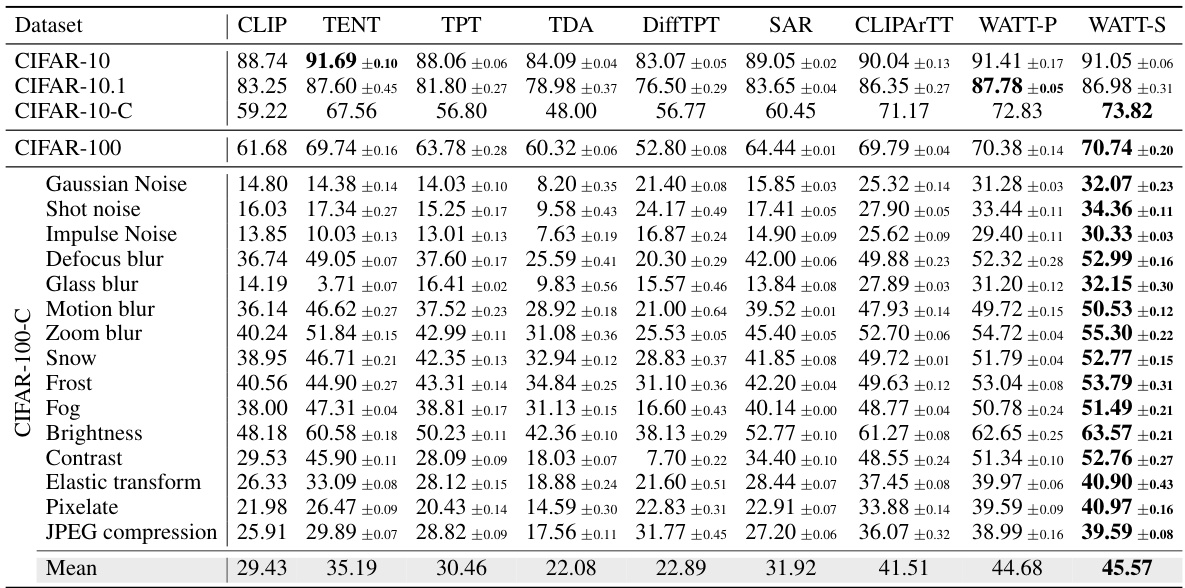
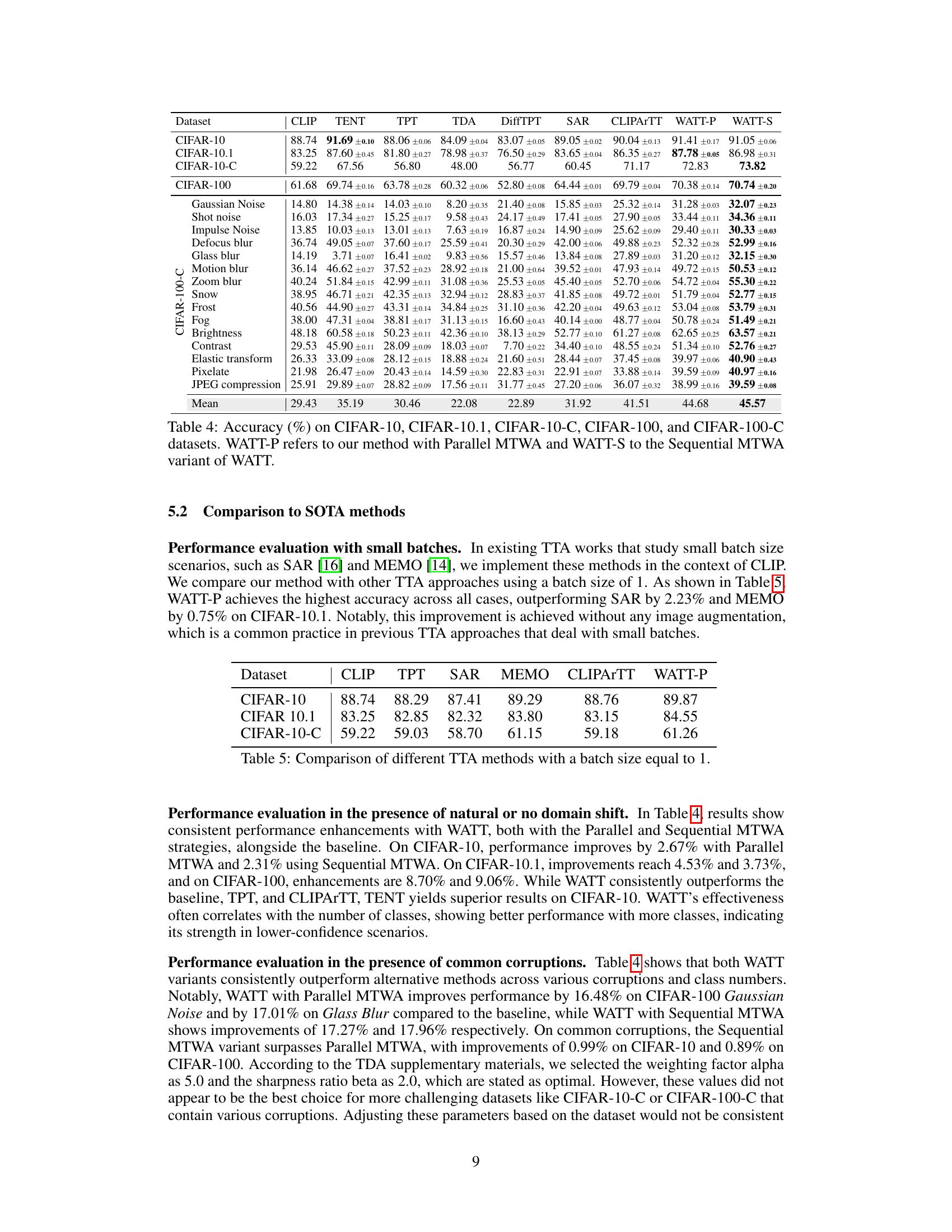
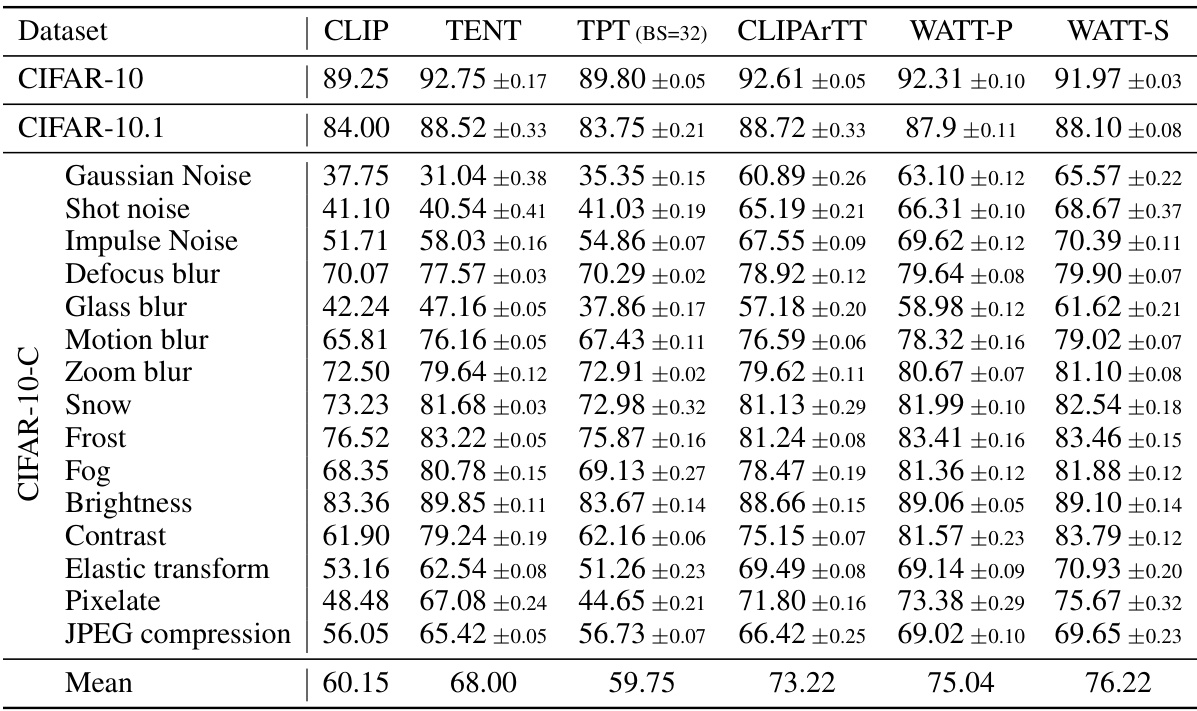
This table presents the accuracy results of different methods (CLIP, TENT, TPT, TDA, DiffTPT, SAR, CLIPARTT, WATT-P, and WATT-S) on various CIFAR datasets (CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C). It shows the performance of these methods on both the original datasets and on datasets with common corruptions. WATT-P and WATT-S represent two variations of the proposed WATT method, using parallel and sequential multi-template weight averaging, respectively.

This table compares the performance of various Test-Time Adaptation (TTA) methods, including the proposed WATT-P, on CIFAR-10, CIFAR-10.1, and CIFAR-10-C datasets when using a batch size of 1. It highlights the relative performance gains of WATT-P compared to existing methods (CLIP, TPT, SAR, MEMO, and CLIPArTT) in low-data adaptation scenarios. The results demonstrate that WATT-P achieves the highest accuracy across all datasets without requiring image augmentation, a common practice in previous TTA approaches.
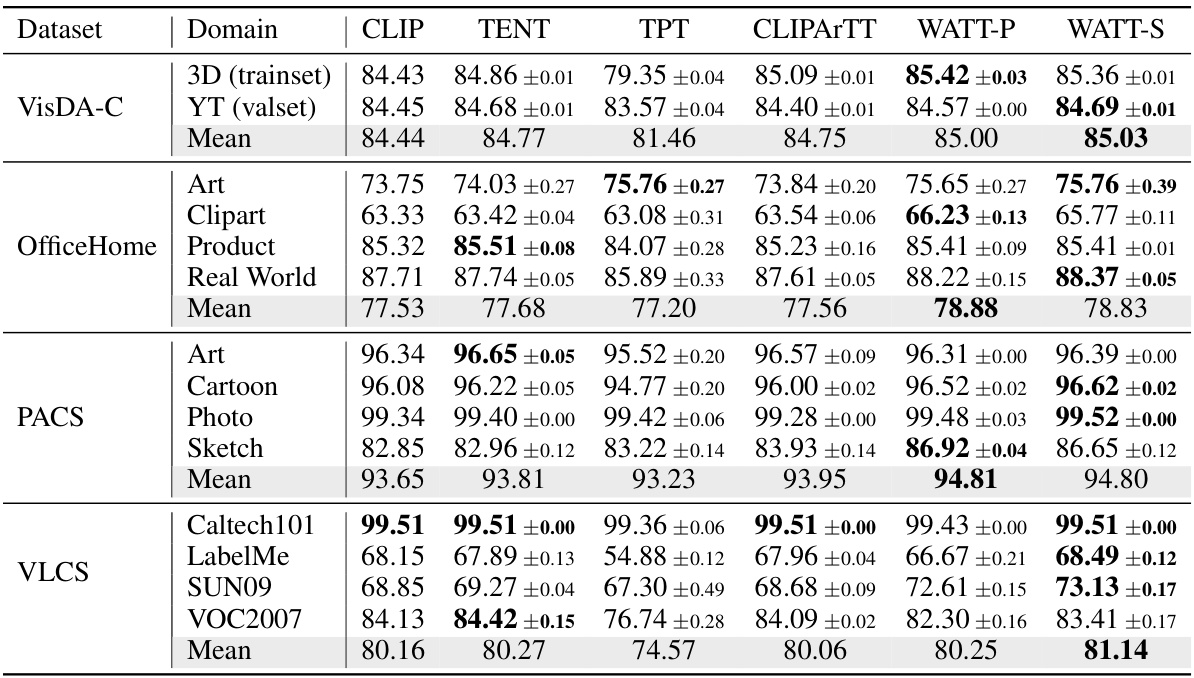
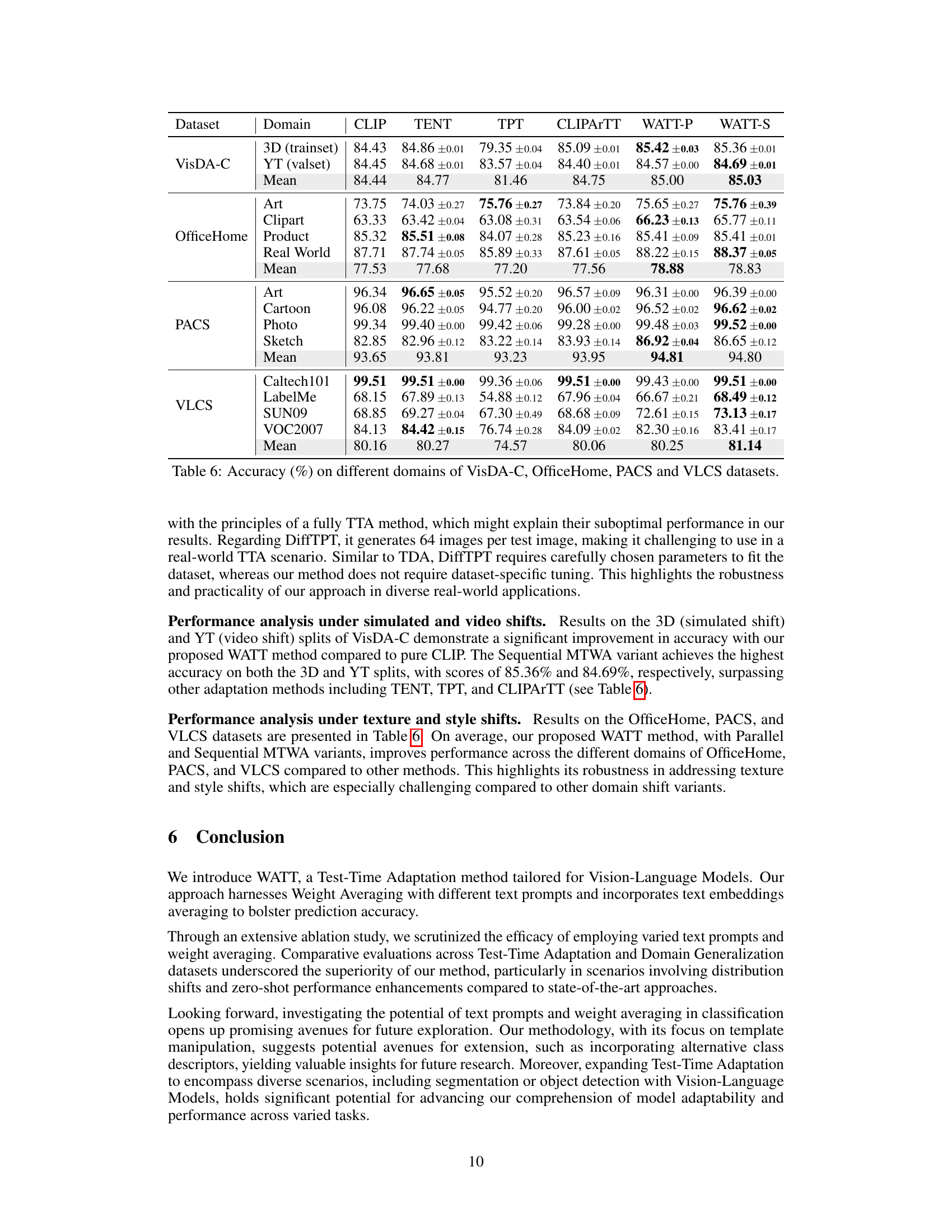
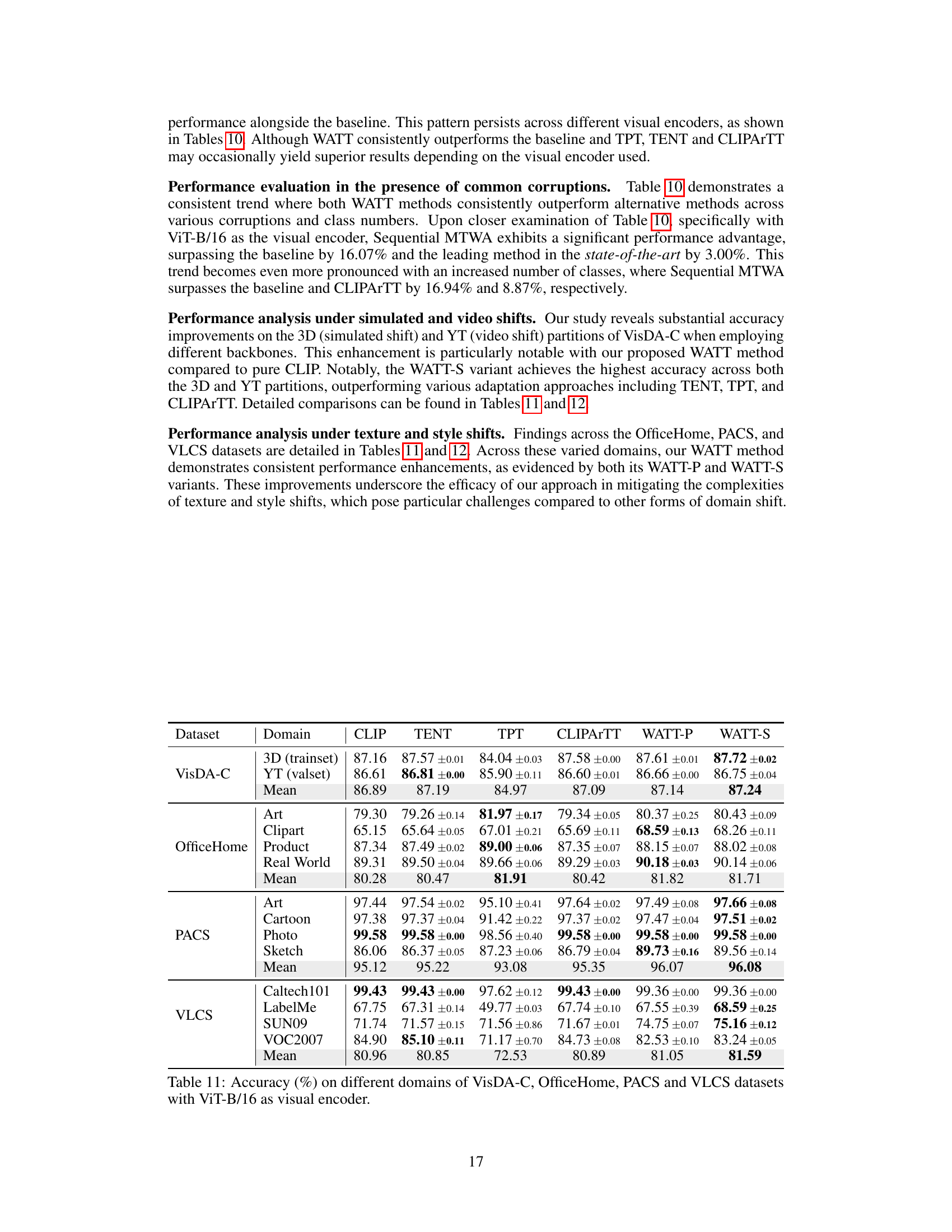
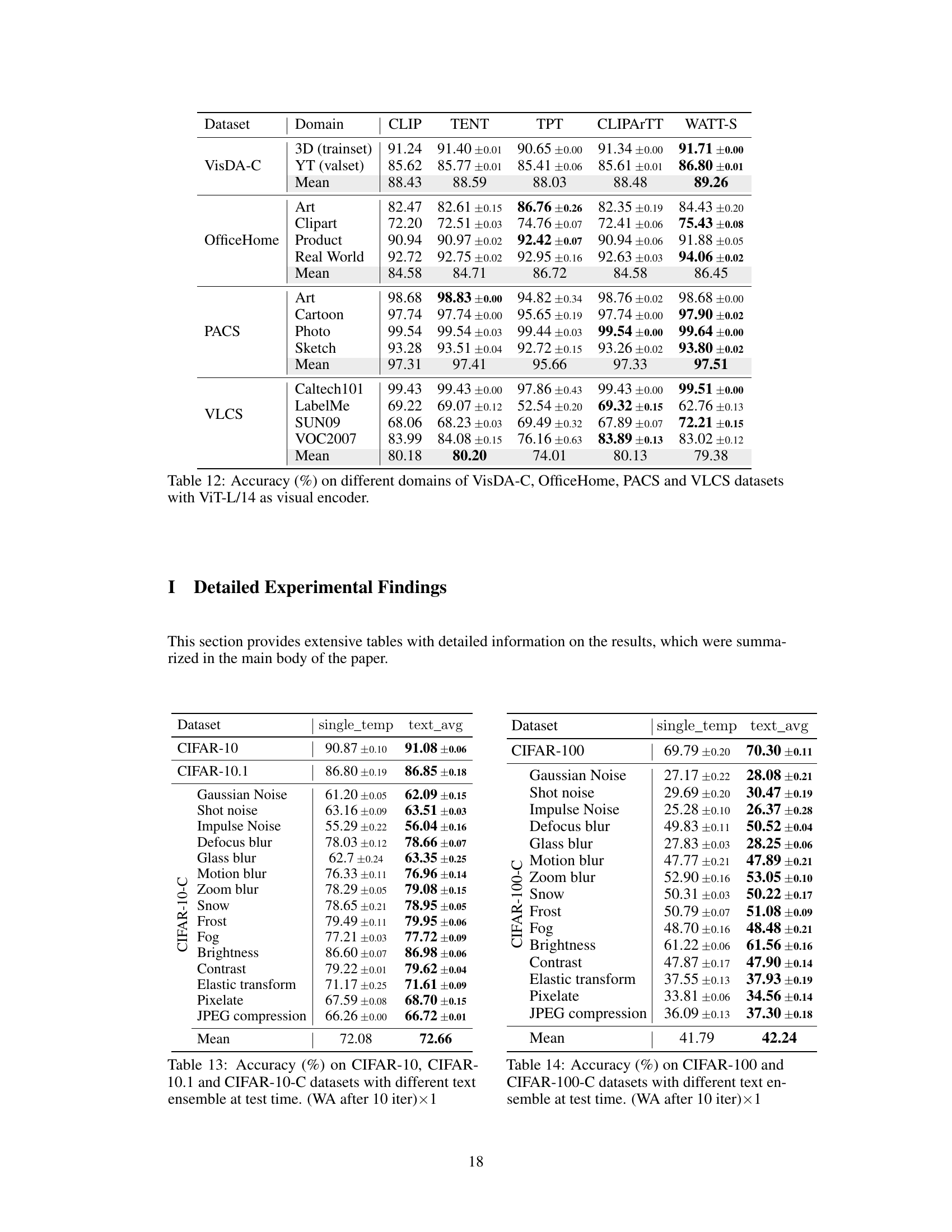
This table presents the accuracy results of different test-time adaptation methods (CLIP, TENT, TPT, CLIPARTT, WATT-P, and WATT-S) across four distinct datasets: VisDA-C, OfficeHome, PACS, and VLCS. Each dataset represents a different type of domain shift (simulated, video, texture, and style), and the results show how well each method adapts to these various shifts. The table provides a comprehensive comparison of the different methods’ generalization capabilities in diverse scenarios.

This table compares the computational cost, including adaptation time, memory usage, and the percentage of learnable parameters, for various test-time adaptation (TTA) methods. The methods compared include WATT-S (Sequential Multi-Template Weight Averaging), WATT-P (Parallel Multi-Template Weight Averaging), TENT, CLIPArTT, SAR, MEMO, and DiffTPT. It demonstrates that WATT-S and WATT-P are computationally efficient compared to other methods, especially considering their robustness. The results showcase a balance between efficiency and effectiveness, highlighting the advantages of the proposed WATT approach.

This table shows the accuracy achieved using different text ensembles at the test time. The results are presented for various datasets including CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. The table compares the performance of using a single template versus using an average of multiple templates.
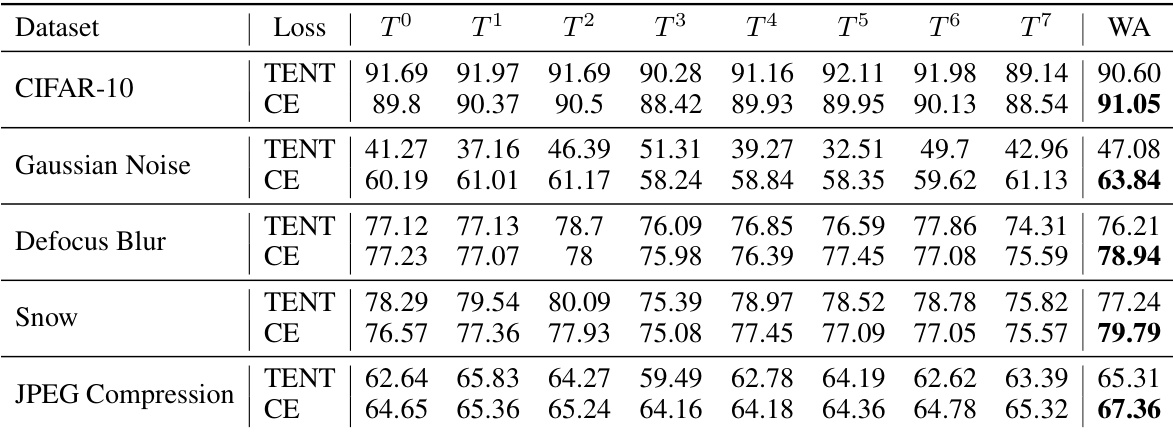
This table presents the accuracy achieved using different text ensemble strategies at test time. It compares the performance of using a single template versus averaging embeddings from multiple templates. The results are shown for various datasets: CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C, demonstrating the effectiveness of the text averaging approach across diverse datasets and corruption types.
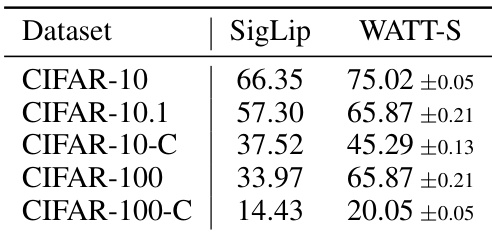
This table compares the performance of the SigLip model and the proposed WATT-S method on five different datasets: CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. The datasets represent variations in complexity and the presence of corruptions. The results show a significant improvement in accuracy achieved by WATT-S across all datasets, highlighting its effectiveness in adapting to different data distributions.
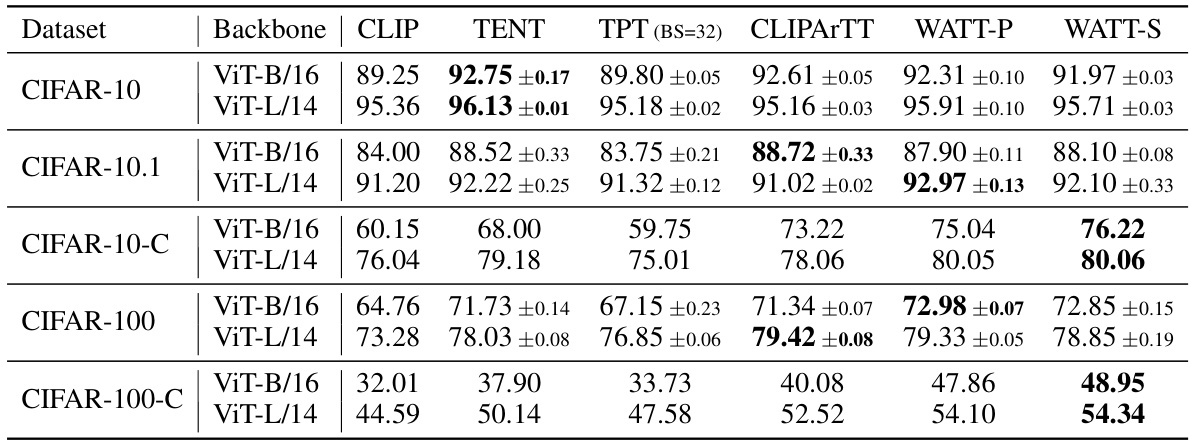
This table presents the accuracy results achieved by different methods (CLIP, TENT, TPT, CLIPArTT, WATT-P, and WATT-S) on CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C datasets. The results are broken down by backbone model used (ViT-B/16 and ViT-L/14). It showcases the performance of the proposed WATT method in comparison to state-of-the-art techniques across various datasets and image corruption levels.
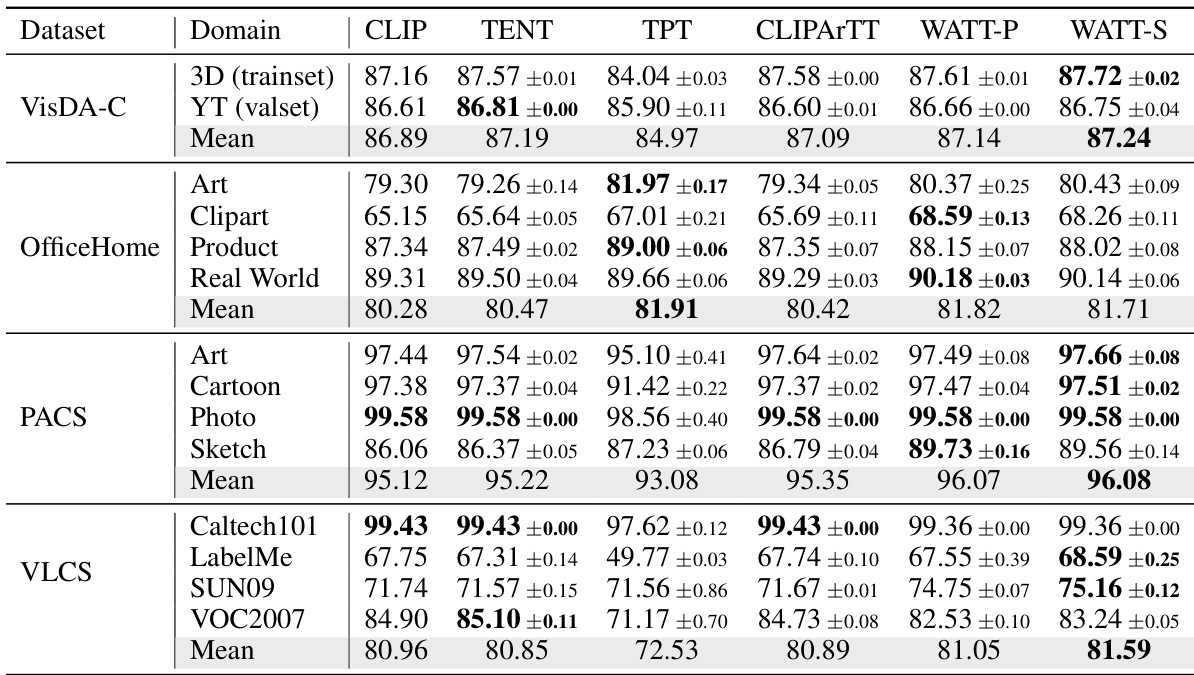
This table presents the accuracy of different test-time adaptation methods (CLIP, TENT, TPT, CLIPARTT, WATT-P, and WATT-S) on four different domain generalization datasets: VisDA-C, OfficeHome, PACS, and VLCS. Each dataset represents a different type of domain shift, allowing for a comprehensive evaluation of the methods’ robustness across various data distributions and image categories. VisDA-C includes 3D-rendered images and YouTube video frames, OfficeHome contains product, clipart, art, and real-world images, PACS includes art, cartoons, photos, and sketches, and VLCS contains images from Caltech-101, LabelMe, SUN09, and VOC2007. The results show how well each method generalizes to unseen data.
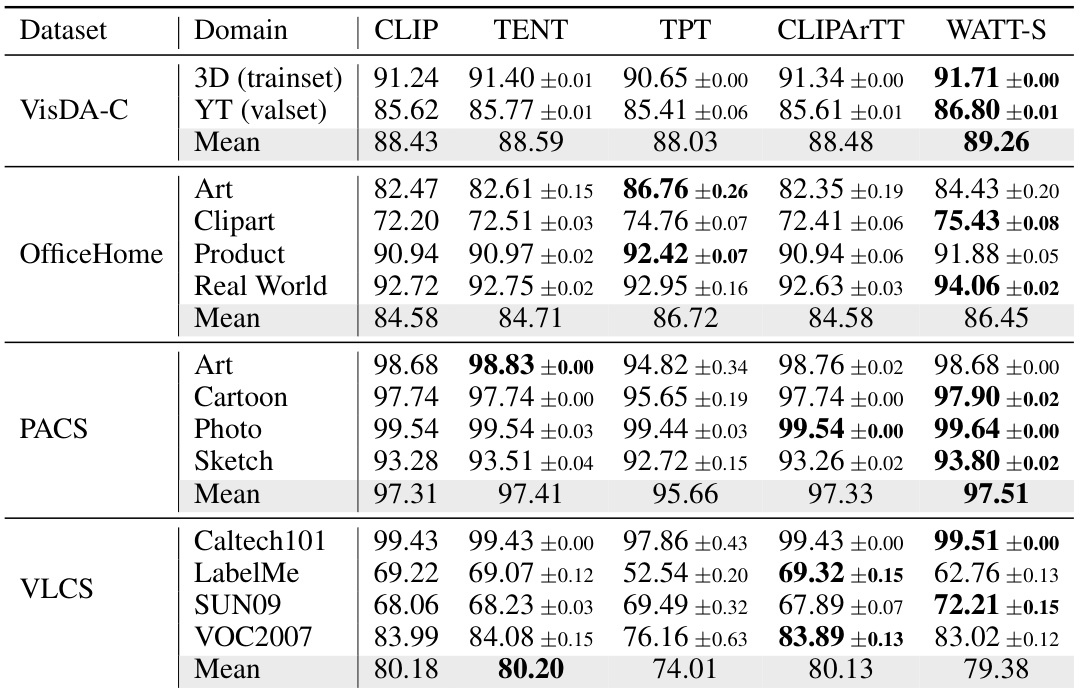
This table presents the accuracy results of different test-time adaptation methods on four domain generalization datasets: VisDA-C, OfficeHome, PACS, and VLCS. Each dataset contains images from different visual domains (e.g., photos, sketches, cartoons). The table shows how well each method adapts to these domain shifts, comparing the performance to a baseline CLIP model. The results are broken down by dataset and domain, providing a detailed comparison of the effectiveness of various adaptation methods.
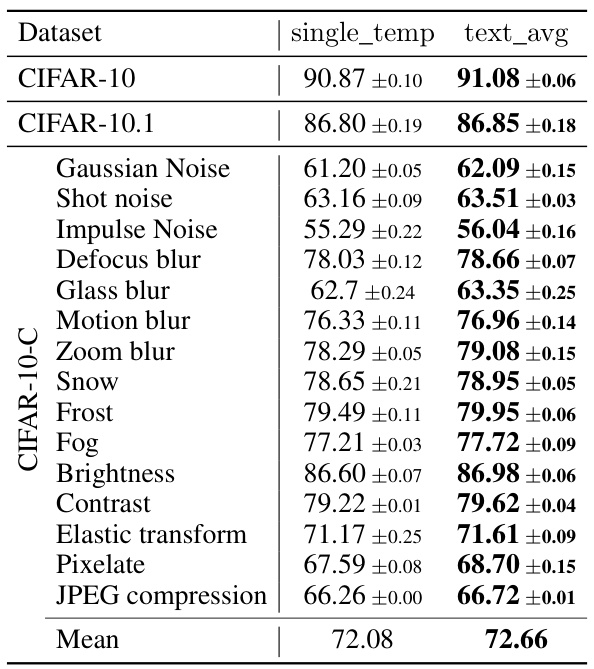
This table shows the accuracy achieved using different text ensemble methods at test time. The ‘single_temp’ column represents the accuracy using a single template, while the ’text_avg’ column shows the accuracy when averaging the embeddings from multiple text templates. The results are presented for different datasets (CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, CIFAR-100-C), illustrating the impact of text ensemble on the model’s performance across various datasets and scenarios.
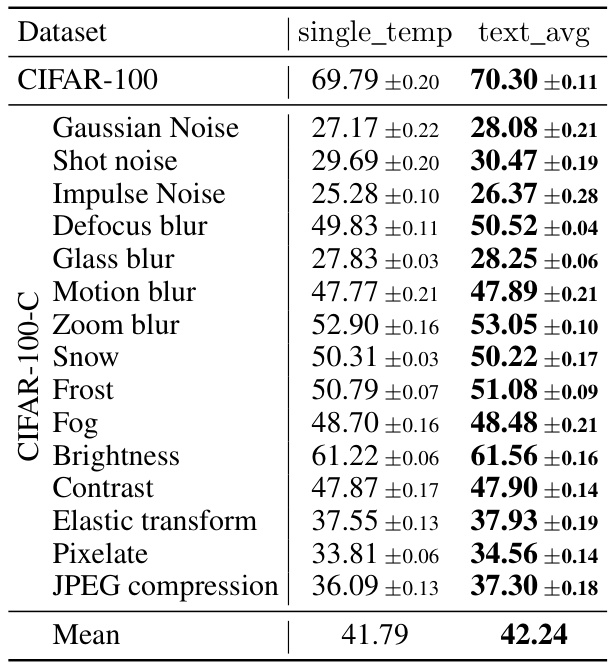
This table presents the accuracy achieved using different text ensemble methods at test time. The results are presented for various datasets including CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. Each dataset represents a different challenge in terms of image classification, with some including various types of corruptions or domain shifts. The table compares the performance of using a single text template versus an average of multiple text templates.
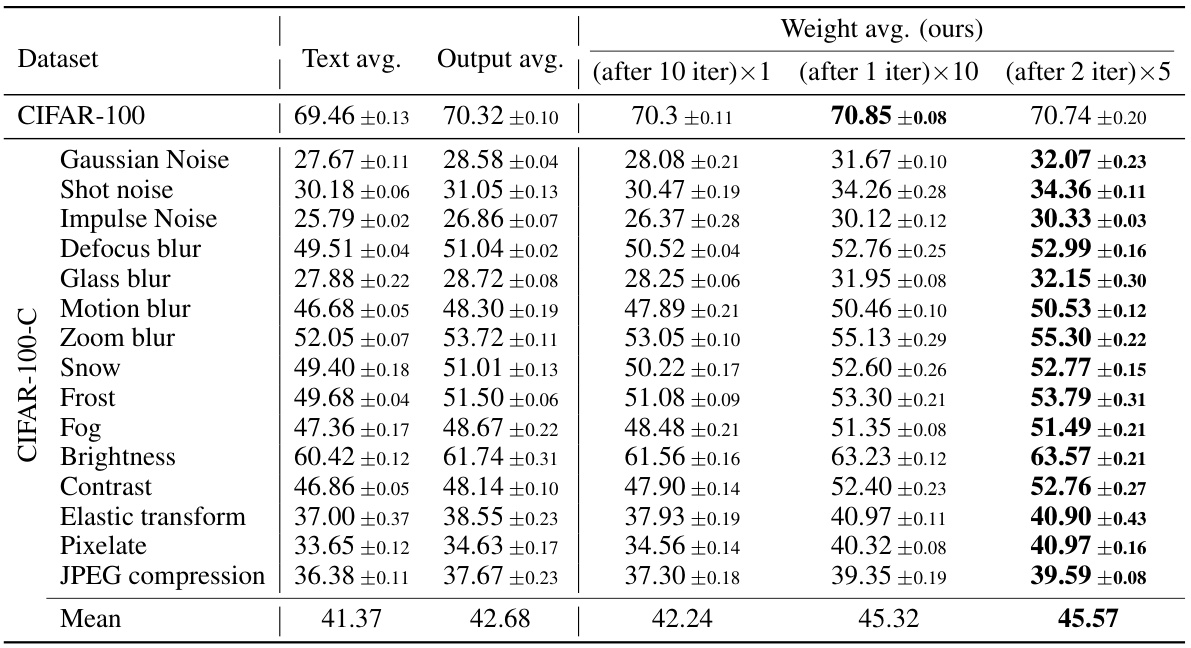
This table presents the accuracy achieved using different text ensembles at test time. It shows the results for single template approach and text average approach on several datasets: CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. The text average method uses the embedding from all the templates.
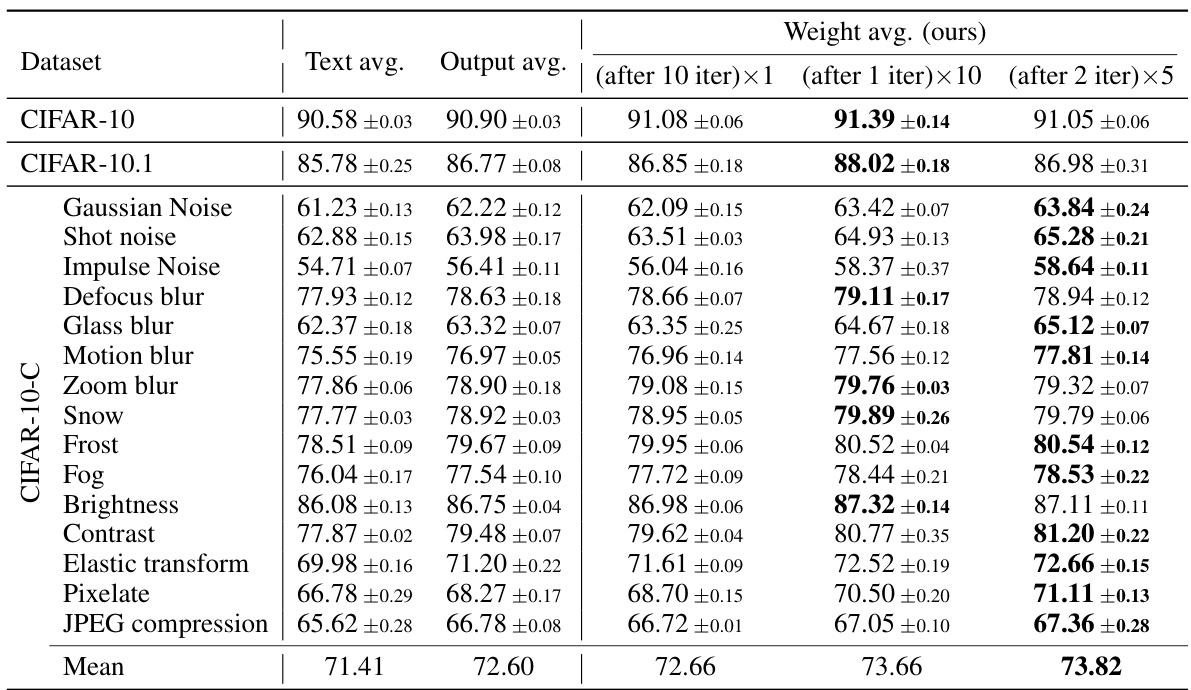
This table shows the accuracy achieved by using different text prompt ensemble methods during the testing phase. The results are presented for several benchmark datasets, including CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. It compares the performance of using a single template versus averaging the embeddings from multiple templates (text_avg).
This table shows the accuracy achieved using different text ensemble methods at test time. The results are presented for various datasets, including CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, and CIFAR-100-C. The table compares the performance of using a single template versus averaging the embeddings from multiple templates. This helps demonstrate the impact of the text ensemble strategy on test-time adaptation.
This table presents the accuracy results achieved using different text ensemble methods at test time. The ‘single_temp’ column shows the accuracy when a single template is used for text prompts. The ’text_avg’ column demonstrates the improved accuracy obtained by averaging text embeddings from multiple templates. The table compares the performance across different datasets (CIFAR-10, CIFAR-10.1, CIFAR-10-C, CIFAR-100, CIFAR-100-C), highlighting the effectiveness of the text averaging approach. The results show that averaging text embeddings from multiple templates consistently improves the classification accuracy across all datasets.
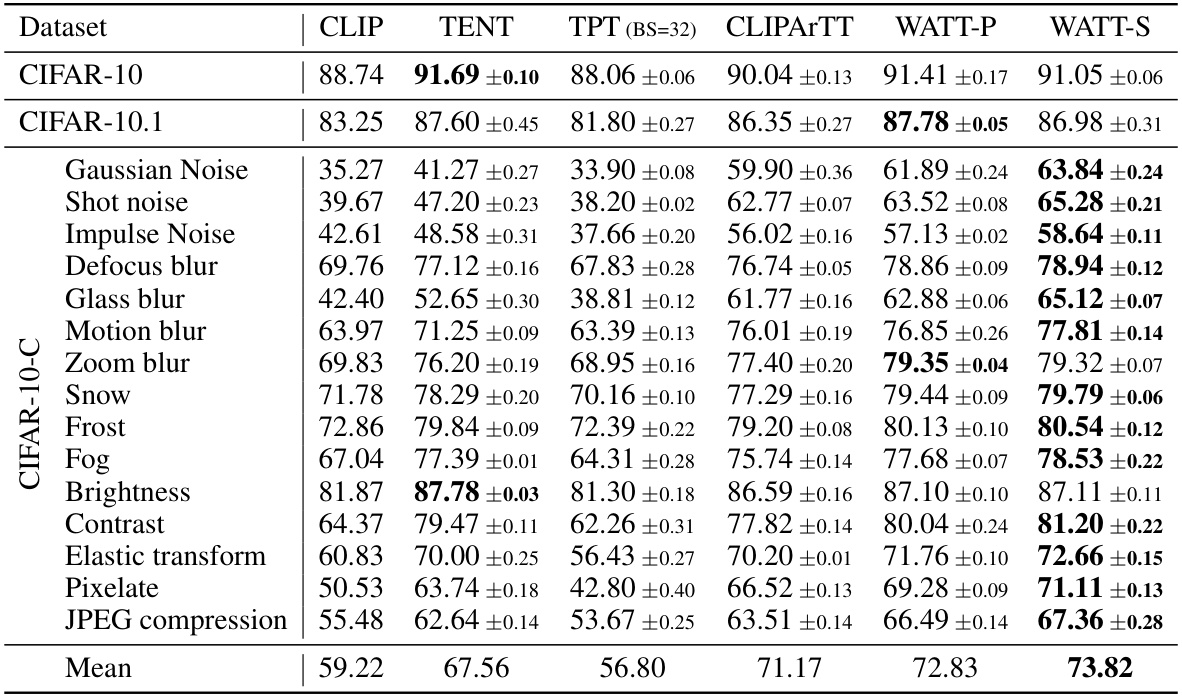
This table presents the accuracy results of the proposed WATT method (both Parallel and Sequential MTWA variants) compared to several other state-of-the-art Test-Time Adaptation (TTA) methods on various CIFAR datasets. The datasets include CIFAR-10, CIFAR-10.1 (a natural shift from CIFAR-10), and CIFAR-10-C (CIFAR-10 with 15 common corruptions), along with their 100-class counterparts. The results show the accuracy achieved by each method on these datasets. WATT-P denotes the parallel version of the WATT method, while WATT-S is the sequential version.
This table presents the accuracy of different methods on various CIFAR datasets. It compares the performance of CLIP, TENT, TPT, TDA, DiffTPT, SAR, CLIPArTT, WATT-P (Parallel Multi-Template Weight Averaging), and WATT-S (Sequential Multi-Template Weight Averaging). The datasets include CIFAR-10, CIFAR-10.1, CIFAR-10-C (CIFAR-10 with common corruptions), CIFAR-100, and CIFAR-100-C (CIFAR-100 with common corruptions). The table highlights the effectiveness of WATT-P and WATT-S compared to existing test-time adaptation methods across a range of dataset corruptions.
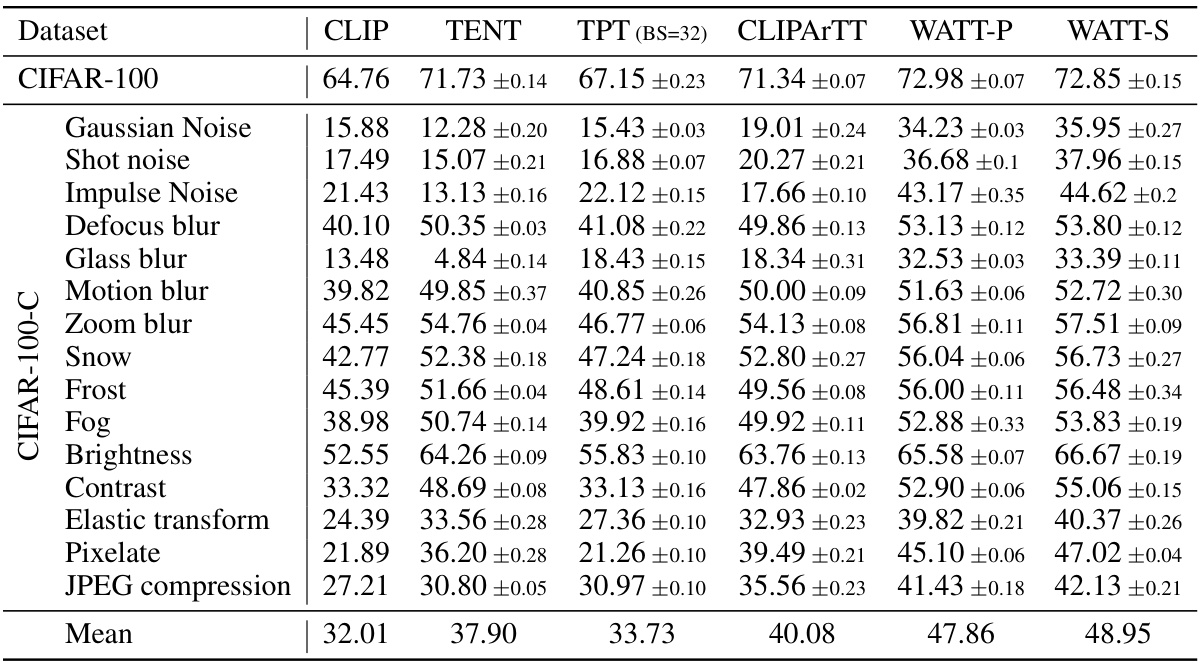
This table presents the accuracy results of different methods on various CIFAR datasets. It compares the performance of the proposed WATT method (using both parallel and sequential multi-template weight averaging) against several other state-of-the-art test-time adaptation (TTA) methods, including CLIP, TENT, TPT, TDA, DiffTPT, SAR, and CLIPArTT. The datasets include the standard CIFAR-10 and CIFAR-100, along with their corrupted versions CIFAR-10-C and CIFAR-100-C, and the CIFAR-10.1 dataset which represents a natural domain shift from CIFAR-10. The results demonstrate the effectiveness of WATT in handling various levels of domain shifts and corruption compared to existing TTA techniques.
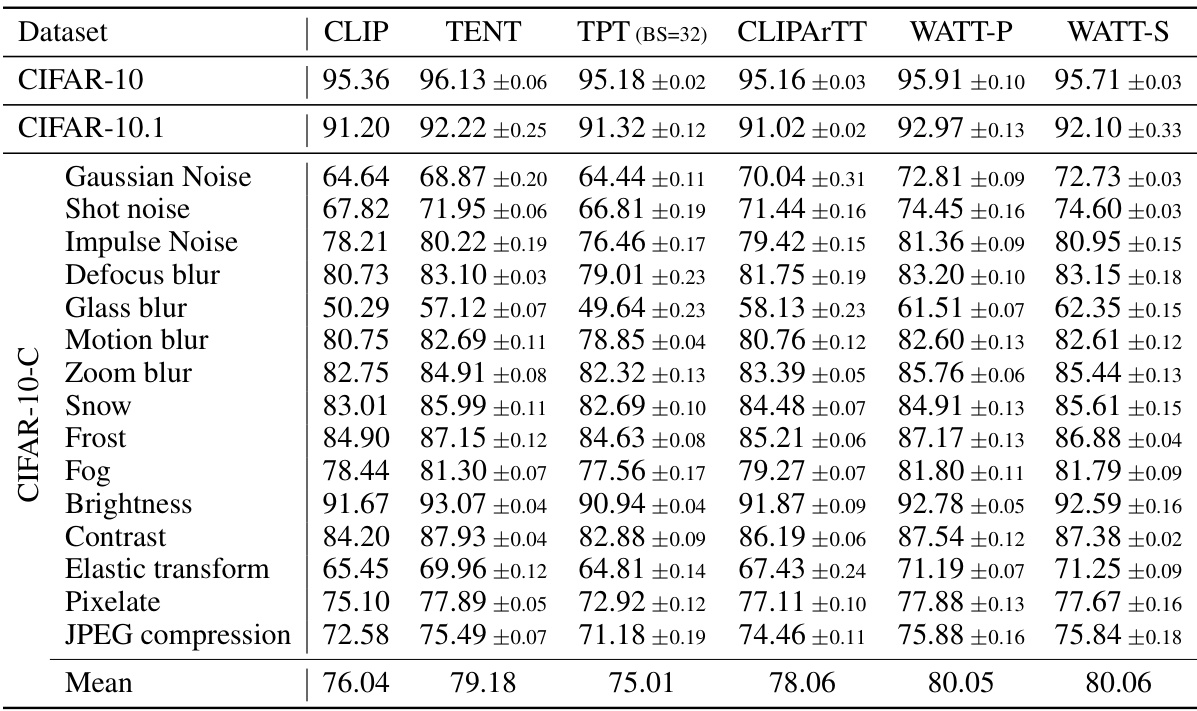
This table presents the accuracy of different methods (CLIP, TENT, TPT, TDA, DiffTPT, SAR, CLIPARTT, WATT-P, and WATT-S) on various CIFAR datasets. The CIFAR datasets are standard image classification datasets, with CIFAR-10-C and CIFAR-100-C representing corrupted versions of the datasets, simulating real-world image degradation. WATT-P and WATT-S represent two variants of the proposed WATT method, differing in their weight averaging strategy (Parallel and Sequential, respectively). The table allows a comparison of the performance of WATT against state-of-the-art test-time adaptation methods across diverse datasets.
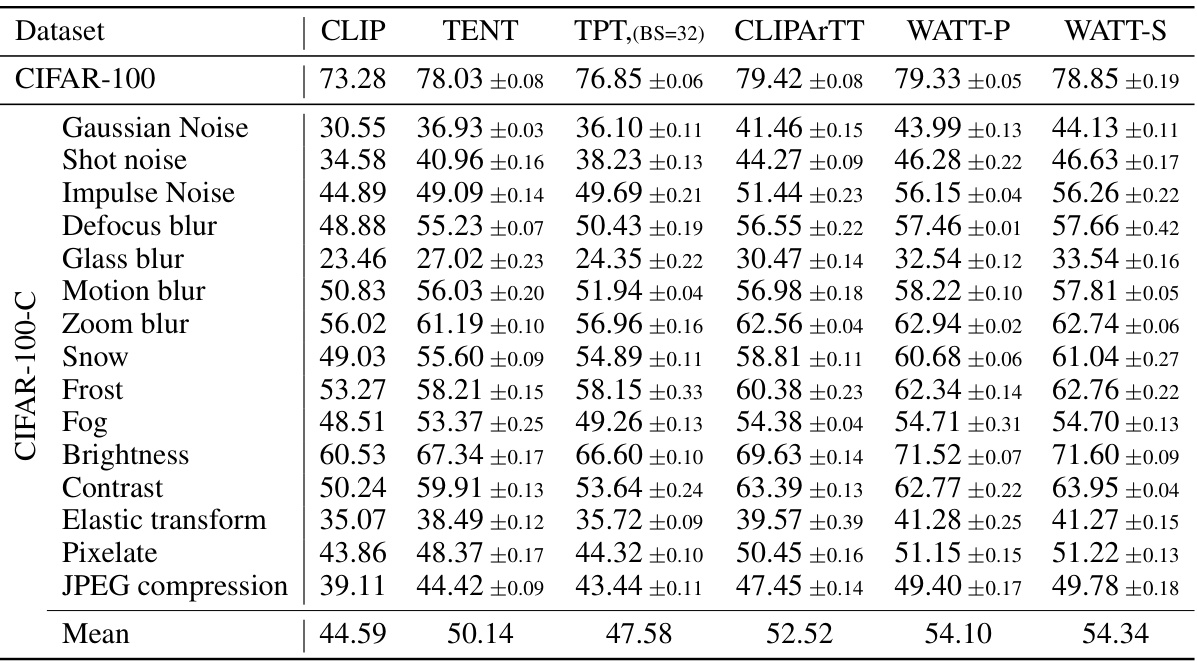
This table presents the accuracy results (%) achieved by different methods on various CIFAR datasets. It compares the performance of CLIP (baseline), TENT, TPT, TDA, DiffTPT, SAR, CLIPArTT, WATT-P (Parallel Multi-Template Weight Averaging), and WATT-S (Sequential Multi-Template Weight Averaging). The datasets include CIFAR-10, CIFAR-10.1 (a natural shift from CIFAR-10), CIFAR-10-C (CIFAR-10 with 15 common corruptions), CIFAR-100, and CIFAR-100-C (CIFAR-100 with 15 common corruptions). This allows for a comprehensive evaluation of the methods’ performance under various degrees of domain shift and corruption.
Full paper#