↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Visual anomaly segmentation struggles with limited data and reliance on vision-language models. Existing methods struggle with unseen anomalies and require extensive labeled data. This often results in poor generalization across various applications.
MetaUAS tackles this by framing anomaly segmentation as change segmentation. It leverages a one-prompt meta-learning approach on a large-scale synthetic dataset derived from existing images. This novel method efficiently segments unseen anomalies using only one normal image prompt, demonstrating superior performance over existing methods. The soft feature alignment module addresses geometric variations between the prompt and query images.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the challenge of limited anomaly segmentation datasets by introducing a novel paradigm that unifies anomaly and change segmentation. This allows leveraging large-scale synthetic datasets and achieving universal anomaly segmentation without relying on specialized datasets or vision-language models. Its efficiency and effectiveness, demonstrated through state-of-the-art results, make it highly relevant to various applications and researchers interested in anomaly detection.
Visual Insights#

The figure illustrates the architecture of MetaUAS, a model for universal anomaly segmentation. It uses a one-prompt meta-learning approach, meaning it only requires one normal image as a prompt to segment anomalies in a new image. The model consists of three main components: an encoder (which extracts features from the input images), a feature alignment module (FAM) (which aligns features from the prompt and query images to handle geometric variations), and a decoder (which generates the anomaly segmentation map). The model is trained on a synthetic dataset of image pairs with changes, simulating the appearance and disappearance of anomalies, before being applied to real-world anomaly segmentation tasks.
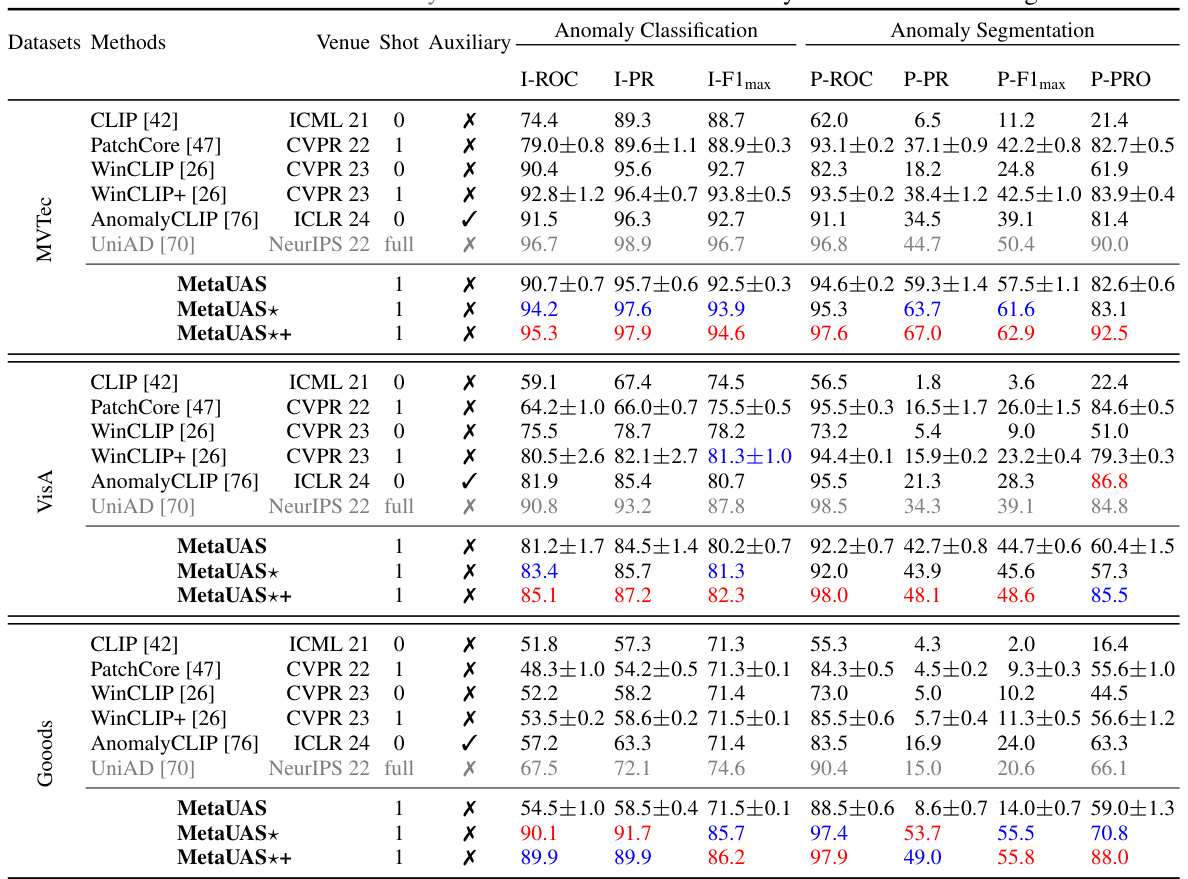
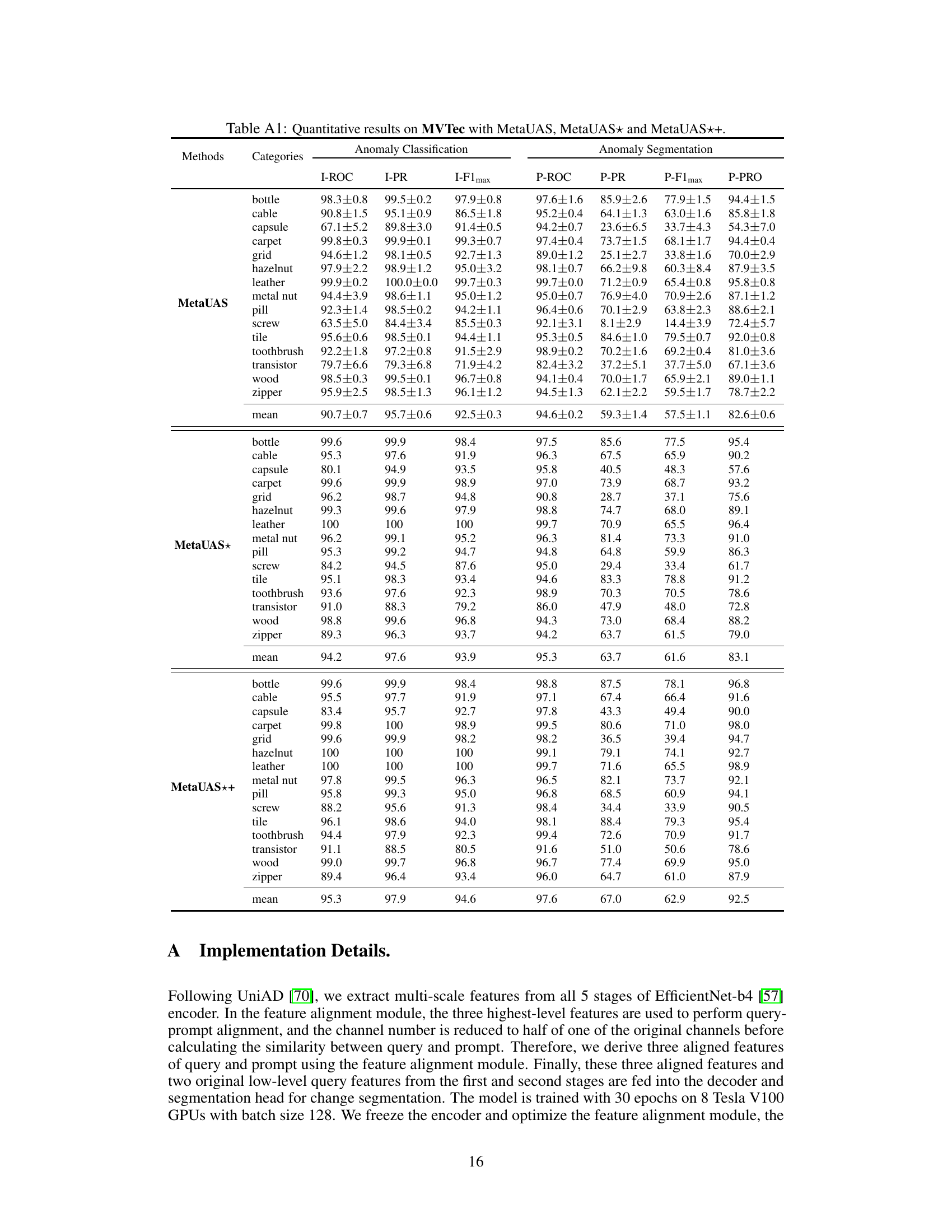
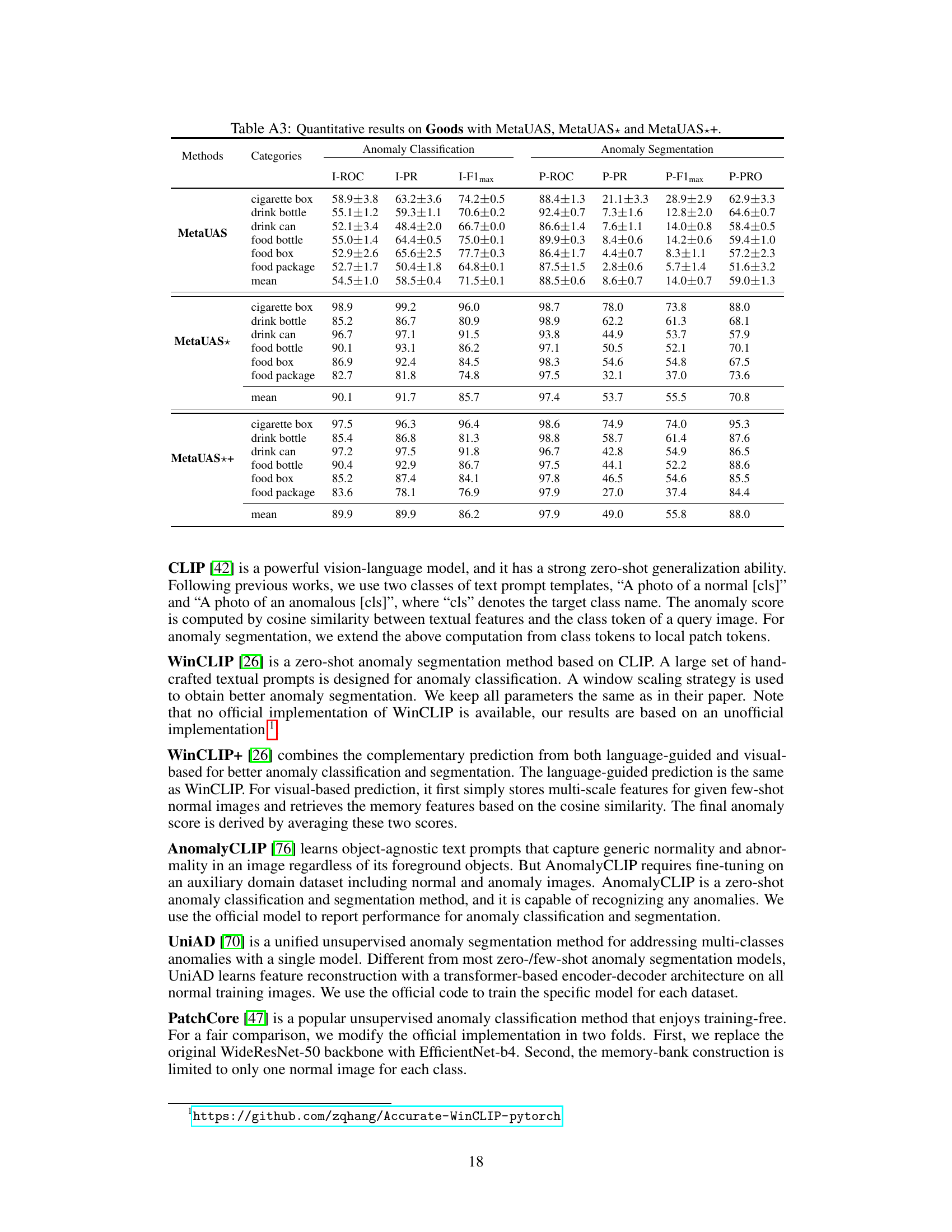
This table presents a quantitative comparison of the proposed MetaUAS model and several other state-of-the-art anomaly detection methods on three benchmark datasets: MVTec, VisA, and Goods. The comparison includes metrics for both anomaly classification (I-ROC, I-PR, I-F1 max) and anomaly segmentation (P-ROC, P-PR, P-F1 max, P-PRO). The results are categorized by dataset, method, number of shots (zero-shot, few-shot, full-shot), use of auxiliary data, and performance metrics. Red highlights the best performance for each metric on each dataset and blue denotes the second-best performance. Gray shading indicates that the model was trained using full-shot normal images.
In-depth insights#
Visual Anomaly Segmentation#
Visual anomaly segmentation is a crucial task in computer vision, aiming to identify and delineate anomalous regions within an image compared to a notion of normality. Traditional approaches often rely on supervised learning, requiring large annotated datasets of both normal and anomalous samples, which are expensive and time-consuming to acquire. This challenge motivates significant research into unsupervised and few-shot methods, which leverage techniques like one-class classification, reconstruction-based anomaly detection, or generative models to learn normal patterns and identify deviations. Vision-language models have also recently emerged as powerful tools, enabling zero-shot and few-shot anomaly segmentation by leveraging textual descriptions to guide the process, although reliance on language introduces constraints. Future research will likely explore more robust and efficient techniques, especially in handling diverse anomaly types, unseen objects, and limited data scenarios. Addressing the inherent ambiguity in defining ’normality’ and developing approaches that generalize effectively to real-world scenarios remain key challenges.
One-Prompt Meta-Learning#
The concept of “One-Prompt Meta-Learning” suggests a paradigm shift in few-shot learning, particularly in anomaly segmentation. Instead of relying on multiple prompts or extensive fine-tuning, a single normal image prompt is used to guide the model’s learning and generalization. This approach leverages the power of meta-learning, enabling the model to adapt to unseen anomalies using only a limited amount of information. The efficiency is significantly increased because it reduces the need for multiple prompts or data-hungry fine-tuning. This paradigm is particularly beneficial for tasks with limited labeled data, as is common in anomaly detection. The effectiveness rests on the model’s ability to extract generalizable visual features from the single prompt and effectively transfer that knowledge to various anomaly detection tasks, a key challenge in this area. Success hinges on the development of robust visual representation learning and effective meta-learning strategies that facilitate rapid adaptation. While promising, challenges remain in robustness to geometrical variations between the prompt and query images and potential limitations in handling diverse anomaly patterns with a single prompt.
Synthetic Data Augmentation#
Synthetic data augmentation is a crucial technique in addressing the scarcity of real-world anomaly data for training robust anomaly segmentation models. The core idea involves generating synthetic images exhibiting various types of anomalies (object appearance/disappearance/exchange and local region changes) to supplement the limited real datasets. This strategy tackles the inherent challenge of obtaining adequately labeled anomaly data by creating a vast and diverse training set. The effectiveness of synthetic augmentation depends heavily on the realism and variability of the generated anomalies. Poorly designed synthetic data could introduce biases or hinder generalization to unseen real-world anomalies. The paper highlights a creative method for creating these augmentations, emphasizing both object-level and local region manipulations to capture the diversity of anomalies. The successful implementation of this technique relies on careful control over the types of changes generated and accurate annotation of the resulting synthetic images. This ensures the model learns to generalize effectively and avoids overfitting to the artificial data. Ultimately, the balance between the quality and quantity of synthetic data is critical for achieving superior anomaly segmentation performance.
Feature Alignment Module#
The Feature Alignment Module is a crucial component addressing a key challenge in visual anomaly detection: geometrical variations between the query image and its normal image prompt. Traditional methods struggle when these images aren’t perfectly aligned, impacting feature comparison and leading to inaccurate anomaly segmentation. This module intelligently bridges this gap by aligning features from the query and prompt images in the feature space, allowing for more robust comparison even with misaligned inputs. This is achieved through either hard alignment, identifying the most similar prompt feature for each query feature spatially, or soft alignment, which weighs prompt features based on similarity to achieve a softer spatial alignment. The choice of alignment strategy is critical; soft alignment typically outperforms hard alignment due to its ability to handle more nuanced geometric discrepancies. The use of soft alignment, in particular, significantly enhances the model’s robustness and generalization capability, enabling accurate anomaly segmentation even when the prompt and query images have different perspectives or object positions.
Universal AS Limitations#
Universal anomaly segmentation (UAS) aims to address the limitations of traditional anomaly detection methods by enabling the detection of unseen anomalies. However, several challenges hinder the full realization of UAS. Data scarcity remains a significant bottleneck, as obtaining labeled data for diverse anomaly types is often difficult and expensive. Generalizability is another key limitation, as models trained on one dataset may not perform well on others with different distributions or anomaly characteristics. Computational cost can also be prohibitive, especially for complex models or large datasets. Finally, robustness to noise and variations in image quality and acquisition poses a significant challenge to UAS performance. Addressing these limitations is crucial for advancing the capabilities and real-world applicability of UAS.
More visual insights#
More on figures

This figure shows the architecture of the proposed MetaUAS model. The model takes a query image and a normal image prompt as input. The encoder extracts multi-scale features from both images. The FAM aligns the features of the query and prompt images to handle geometric variations. The decoder combines the aligned features to predict a change heatmap, which is then used to segment anomalies. The model is trained on a synthetic dataset using one-prompt meta-learning and can generalize to unseen anomalies.
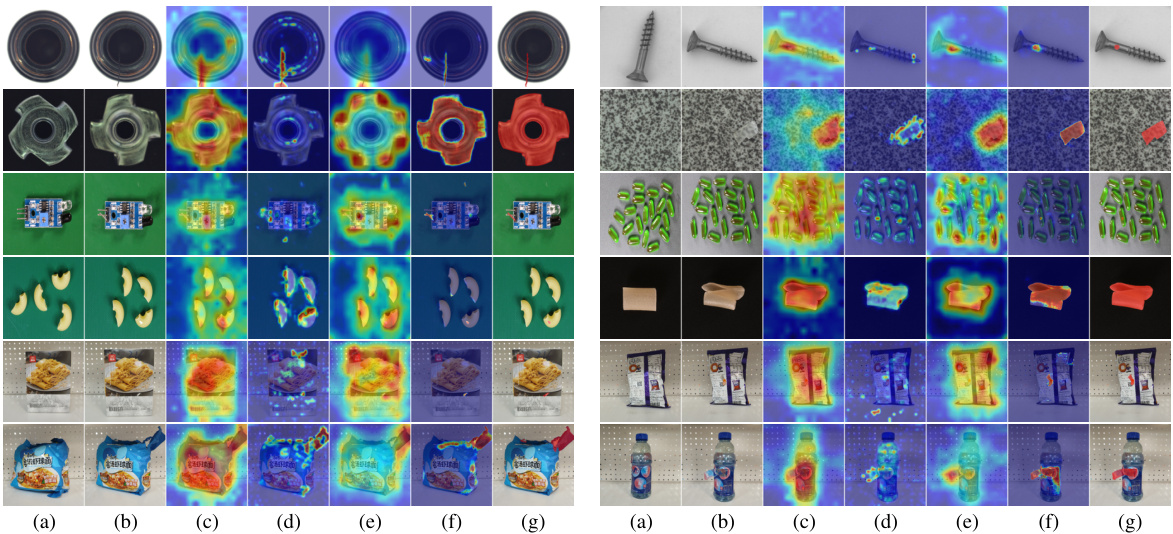
This figure shows a qualitative comparison of anomaly segmentation results between MetaUAS and other state-of-the-art methods on three different datasets (MVTec, VisA, Goods). For each dataset, several examples are presented, with (a) showing the normal image prompt used, (b) showing the query image, (g) the corresponding ground truth mask, and (c-f) showing the anomaly segmentation results from four other methods including WinCLIP+, AnomalyCLIP, UniAD and MetaUAS. The goal is to visually demonstrate the effectiveness of MetaUAS compared to existing approaches.

This figure shows the anomaly segmentation results of MetaUAS, MetaUAS*, and MetaUAS++ on three different types of anomalies from the MVTEC dataset. For each anomaly type, a query image is shown along with segmentation results from the three methods using 5 different randomly selected normal image prompts, and the best performing prompt identified as ‘prompt*’. The ground truth anomaly mask is also provided. The figure demonstrates the robustness and effectiveness of the proposed MetaUAS in handling variations in prompt selection and generating accurate anomaly maps.

This figure shows a qualitative comparison of anomaly segmentation results between MetaUAS and other state-of-the-art methods on three datasets (MVTec, VisA, and Goods). For each dataset and method, several examples of query images, ground truth anomaly masks, and predicted anomaly maps are displayed, allowing for visual comparison of performance. The results show MetaUAS producing more accurate segmentations with fewer false positives compared to competing models.
More on tables

This table compares the efficiency and complexity of different anomaly detection methods on the MVTec dataset. The metrics used are the number of parameters, the number of learnable parameters, the input size, the inference time (in milliseconds), the image-level ROC score, the image-level PR score, and the pixel-level PR score. The table allows for a comparison of model size, speed and performance across various approaches.
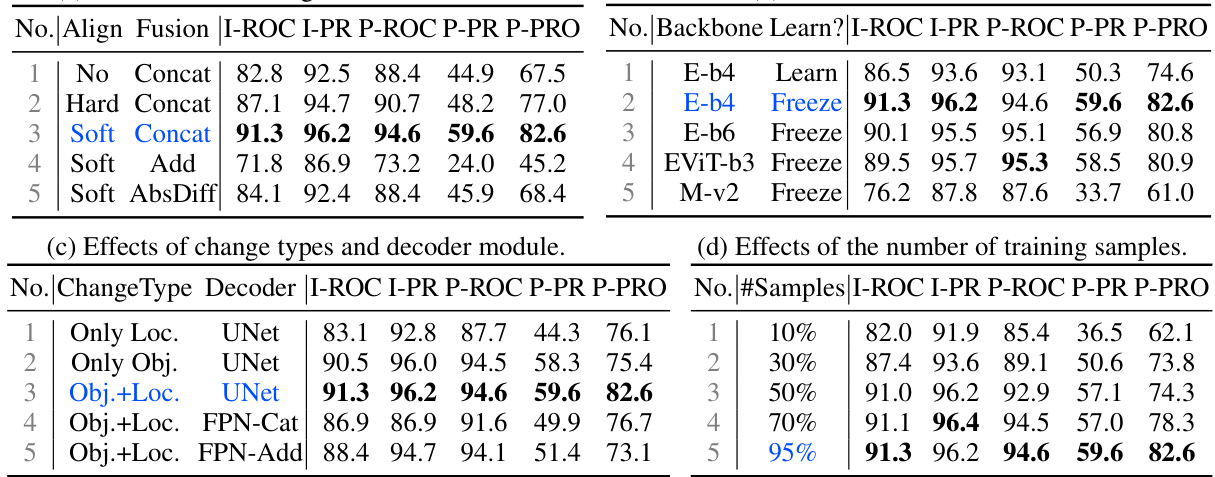
This table presents a quantitative comparison of the proposed MetaUAS model and its variants against several state-of-the-art anomaly detection methods across three benchmark datasets: MVTec, VisA, and Goods. The table evaluates both anomaly classification and anomaly segmentation performance, reporting metrics such as Image-level ROC, Precision, F1-score and Pixel-level ROC, Precision, F1-score, and PRO (Per-Region Overlap). The use of red and blue highlights the best and second-best performing methods for each metric. The ‘Shot’ column specifies whether the compared methods utilize zero-shot, few-shot, or full-shot training approaches, and the ‘Auxiliary’ column indicates whether auxiliary datasets were employed during training.
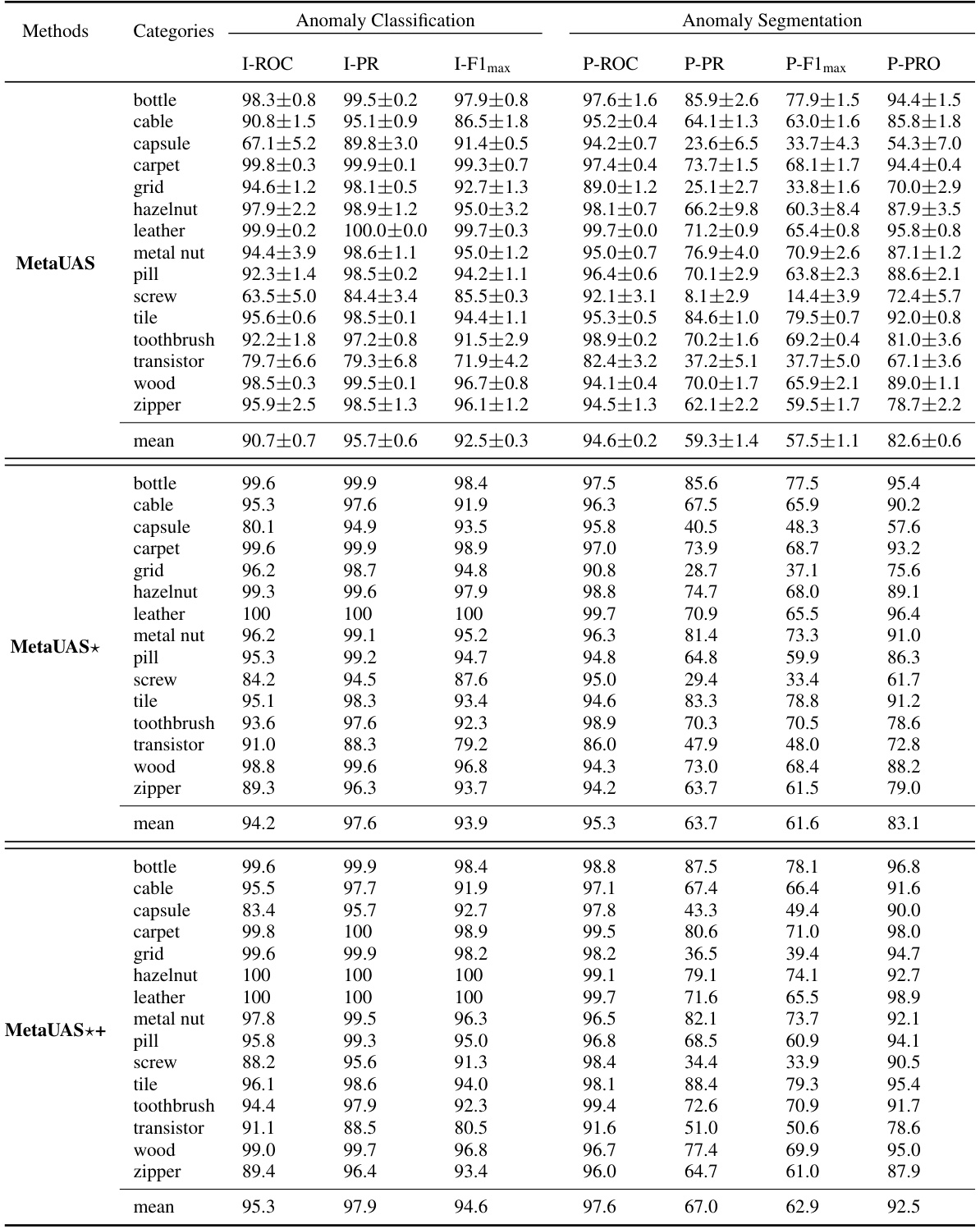
This table presents a quantitative comparison of the proposed MetaUAS model and other state-of-the-art methods on three benchmark datasets for anomaly segmentation (MVTec, VisA, and Goods). The comparison includes various metrics (I-ROC, I-PR, I-F1max, P-ROC, P-PR, P-F1max, P-PRO) for both image-level anomaly classification and pixel-level anomaly segmentation. The table highlights the best (red) and second-best (blue) performances, and also indicates whether the competing methods used full-shot training data (gray). This allows for assessment of MetaUAS’s performance against different training paradigms (zero-shot, few-shot, and full-shot).
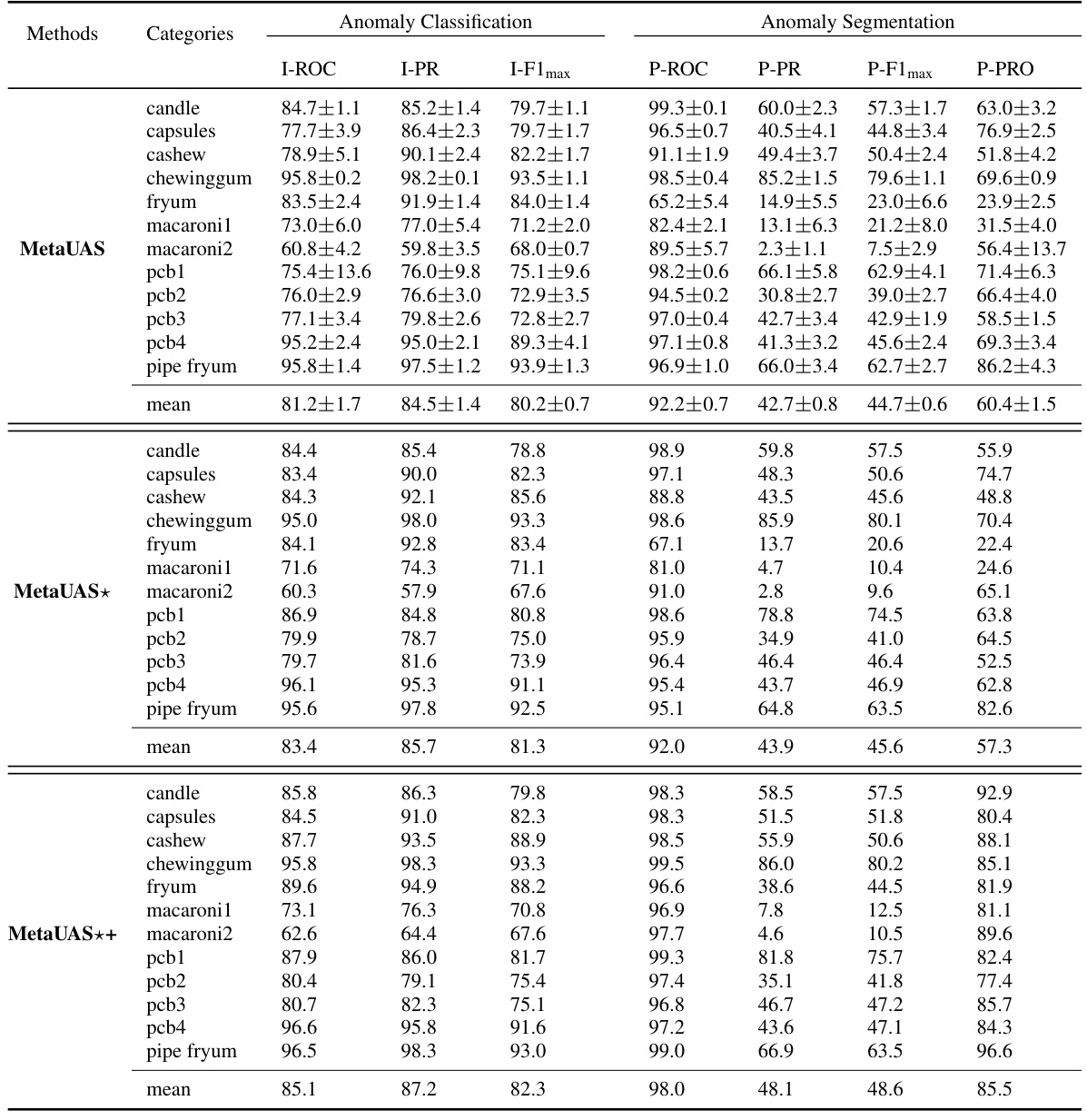
This table presents a quantitative comparison of the proposed MetaUAS model with other state-of-the-art anomaly detection methods on three benchmark datasets: MVTec, VisA, and Goods. The comparison includes metrics for both anomaly classification (image-level) and anomaly segmentation (pixel-level). Performance is evaluated using I-ROC, I-PR, I-F1 max, P-ROC, P-PR, P-F1max, and P-PRO. The table highlights the superior performance of MetaUAS, especially when compared to zero-shot and few-shot methods.

This table presents a quantitative comparison of the proposed MetaUAS model and its variants against other state-of-the-art anomaly detection methods on three benchmark datasets: MVTec, VisA, and Goods. The comparison includes both image-level anomaly classification metrics (I-ROC, I-PR, I-F1max) and pixel-level anomaly segmentation metrics (P-ROC, P-PR, P-F1max, P-PRO). The number of shots (zero-shot, few-shot, full-shot) and the use of auxiliary datasets are also indicated.
Full paper#