↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
In-context learning (ICL) allows pre-trained language models to quickly learn new tasks using a few demonstrations without parameter updates. However, interpreting how these demonstrations influence the model’s performance is challenging. Existing attribution methods are often computationally expensive or don’t adequately address ICL’s unique characteristics, such as sensitivity to demonstration order.
The paper proposes DETAIL, a novel attribution method based on influence functions. DETAIL effectively addresses the challenges of ICL by formulating an influence function over the internal optimizer that transformers are believed to employ during ICL. It demonstrates improved efficiency and the ability to identify helpful and unhelpful demonstrations. The method’s applicability is further showcased through successful demonstration reordering and curation strategies. Crucially, the scores generated by DETAIL are shown to be transferable to black-box models, significantly expanding its utility.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in interpretable machine learning and natural language processing. It introduces DETAIL, a novel and efficient technique for understanding in-context learning, a crucial aspect of large language models. The transferability of DETAIL across different models expands its applicability and opens avenues for improving model performance and prompting strategies. This work advances the field by providing a valuable tool and insightful analysis of a complex learning paradigm.
Visual Insights#
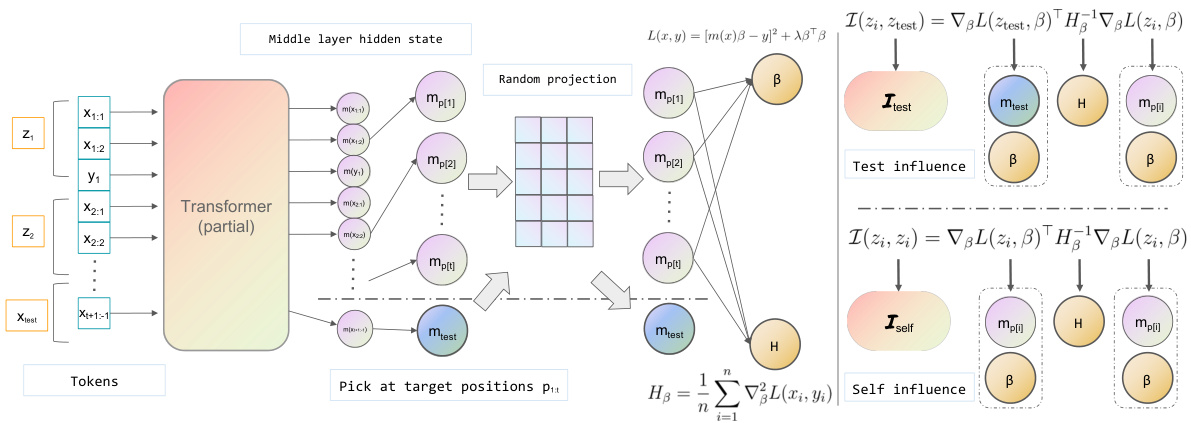
This figure illustrates the process of calculating DETAIL scores for in-context learning (ICL) in transformer-based models. It shows how the input demonstrations and query are processed through the transformer’s layers to obtain internal representations (m). These representations are then projected (optionally) to a lower dimension (mp) for computational efficiency. The core calculation involves computing both ’test influence’ (Itest) and ‘self influence’ (Iself) scores using a kernel regression approach. Itest measures the impact of each demonstration on the model’s prediction of the query, while Iself assesses the relative importance of each demonstration within the overall prompt. The figure highlights the key steps and components of the DETAIL method, providing a visual guide to its inner workings.
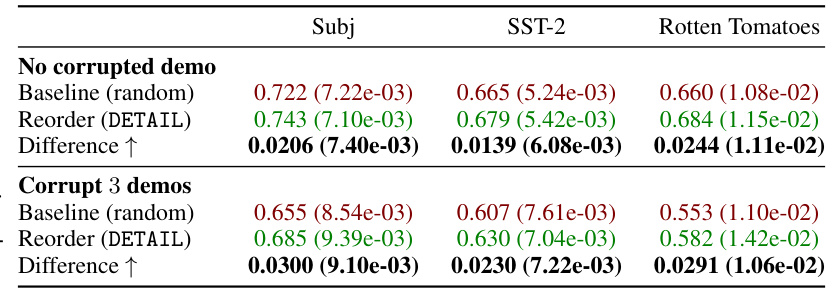
This table presents the results of an experiment comparing the predictive accuracy of a model using randomly permuted demonstrations versus demonstrations reordered based on the Iself scores (a measure of self-influence). The experiment was repeated 80 times, and the mean and standard error of the accuracy are reported for each condition (random order, Iself-ordered). It shows the impact of demonstration ordering on model performance, and the improvement achieved by using Iself scores for ordering.
In-depth insights#
ICL Attribution#
In the realm of in-context learning (ICL), understanding how a model leverages provided examples to solve a given task is crucial. ICL attribution methods seek to dissect this process, identifying which examples are most influential in shaping the model’s prediction. This is particularly important because ICL’s flexibility also introduces challenges, such as sensitivity to example order and the presence of noisy or irrelevant data. Effective attribution techniques help to explain model behavior by quantifying each example’s contribution, highlighting the importance of specific details or patterns. Such methods are key to improving ICL performance by enabling the identification and removal of unhelpful examples, the reordering of examples for optimal impact, and the creation of more effective and curated training sets. The development of robust and efficient ICL attribution techniques, therefore, represents a significant step forward in making ICL more reliable, interpretable, and ultimately, more powerful.
DETAIL Method#
The DETAIL method, as described in the research paper, presents a novel approach to attributing the influence of individual task demonstrations within the in-context learning (ICL) paradigm. It leverages the understanding that transformers implicitly function as optimizers, learning from demonstrations without explicit parameter updates. DETAIL cleverly adapts the classical influence function, a technique used for attribution in conventional machine learning, to this unique ICL setting. This adaptation is crucial because standard influence functions aren’t directly applicable to ICL due to the absence of parameter changes. The core innovation lies in its efficient formulation which tackles computational challenges inherent in analyzing large language models (LLMs) and explicitly addresses the order sensitivity of ICL. By formulating the influence function on an internal kernel regression, and using techniques such as random projection to reduce dimensionality, DETAIL offers both accuracy and speed. The method’s effectiveness is extensively validated through experiments on various tasks, including demonstration reordering and curation, showcasing its real-world applicability. Further, the transferability of DETAIL scores across different models is demonstrated, highlighting its value even when dealing with black-box LLMs. This transferability is important as many powerful LLMs are closed-source, making interpretation particularly difficult. In essence, DETAIL provides a powerful, interpretable and computationally efficient way to analyze and improve the performance of ICL systems.
LLM Experiments#
A hypothetical section titled “LLM Experiments” in a research paper would likely detail the empirical evaluation of large language models (LLMs). This would involve specifying the chosen LLMs, the datasets used for evaluation (including their characteristics and sizes), and the evaluation metrics employed (e.g., accuracy, F1-score, BLEU). Specific tasks or prompts used to probe the models’ capabilities would be described, along with a discussion of the experimental setup (e.g., parameter settings, random seeds). Crucially, the results would be presented clearly, potentially with visualizations like charts and tables showing performance across different models and datasets. Analysis of these results would be key, interpreting the strengths and weaknesses of the LLMs in relation to the specific tasks and datasets and providing a thoughtful comparison between the models’ performance. Furthermore, any limitations or challenges encountered during the experiments should be addressed, and the implications of the findings would be discussed within the broader context of the paper’s research question.
Transferability#
The concept of transferability in the context of in-context learning (ICL) is crucial for the practical application of the proposed attribution method, DETAIL. The research demonstrates that attribution scores obtained from white-box models (models where internal workings are accessible) can be successfully transferred to black-box models (models whose inner mechanisms are hidden), such as GPT-3.5. This is a significant finding because many powerful large language models (LLMs) are proprietary and thus inaccessible for direct gradient-based attribution analysis. The transferability of DETAIL’s attribution scores suggests that the underlying principles of how LLMs learn in context are shared across different model architectures, even if the specific internal parameters differ. This is important because it expands the applicability of the method beyond a limited set of accessible models and demonstrates its potential as a general tool for understanding ICL across various LLMs. The experimental results show consistent performance improvements in demonstration reordering and curation tasks when using the transferred scores, further highlighting the robustness and generalizability of DETAIL’s approach.
Future ICL#
Future research in In-context Learning (ICL) should prioritize improving interpretability and control. Current methods often lack transparency, making it difficult to understand why a model makes specific decisions, especially in complex scenarios. Future ICL research should address these limitations. Developing techniques that allow for better attribution of demonstrated tasks and explainable AI (XAI) methods specifically tailored for ICL’s unique characteristics would be valuable. Additionally, exploring methods to improve ICL’s robustness to noisy or adversarial demonstrations is crucial. Addressing ICL’s sensitivity to prompt ordering and crafting more effective demonstration curation strategies are also key areas for future research. Finally, investigating how ICL can be scaled to handle increasingly complex tasks and larger datasets while maintaining efficiency and interpretability is essential for the future of this powerful learning paradigm. The goal is not only to improve the performance but also to make it more reliable and trustworthy. Theoretical frameworks for a better understanding of ICL’s internal mechanisms should be further explored.
More visual insights#
More on figures

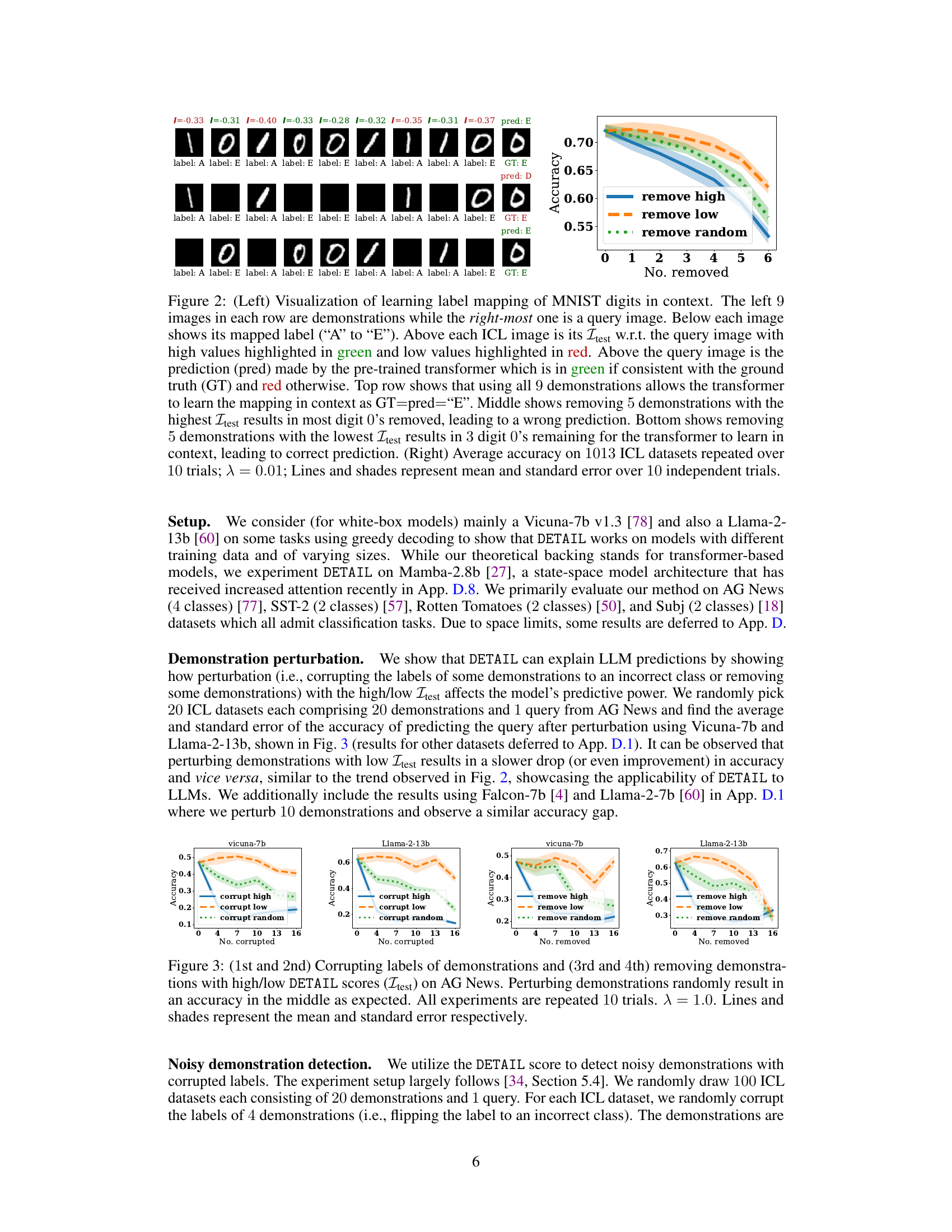
The left part of the figure visualizes how the DETAIL score attributes the prediction of a custom transformer to individual demonstrations in an MNIST digit classification task. The right part shows the average accuracy of the model when demonstrations with high or low DETAIL scores are removed.

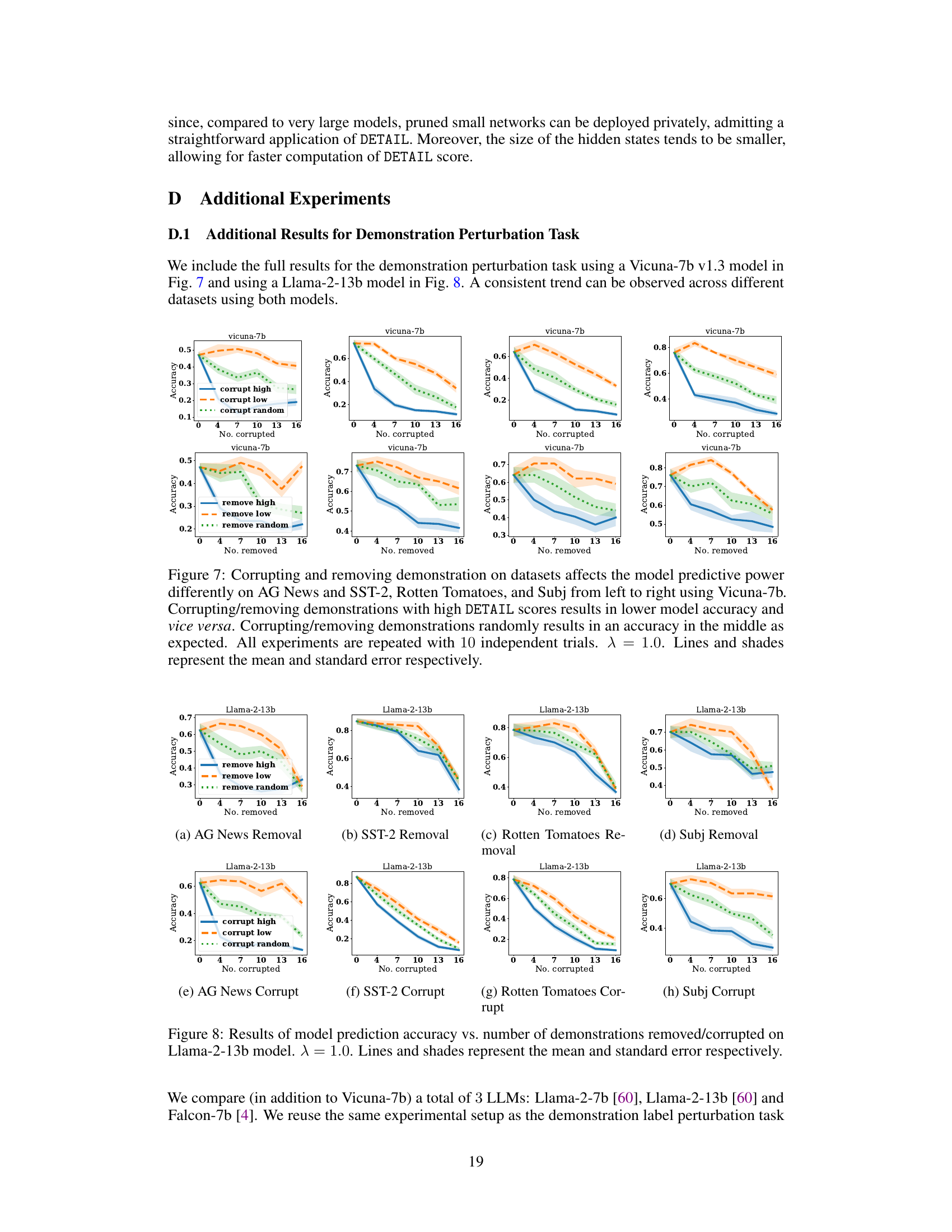
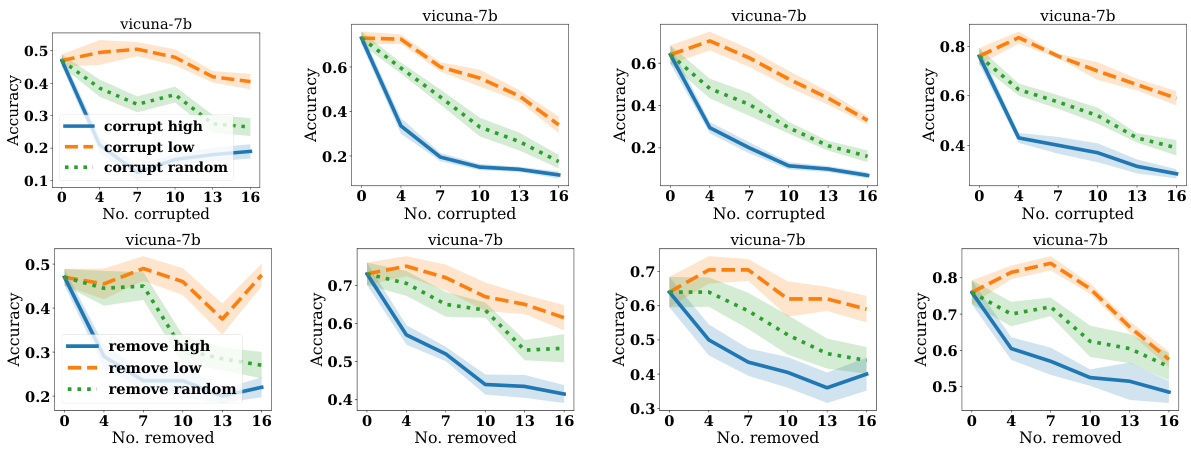
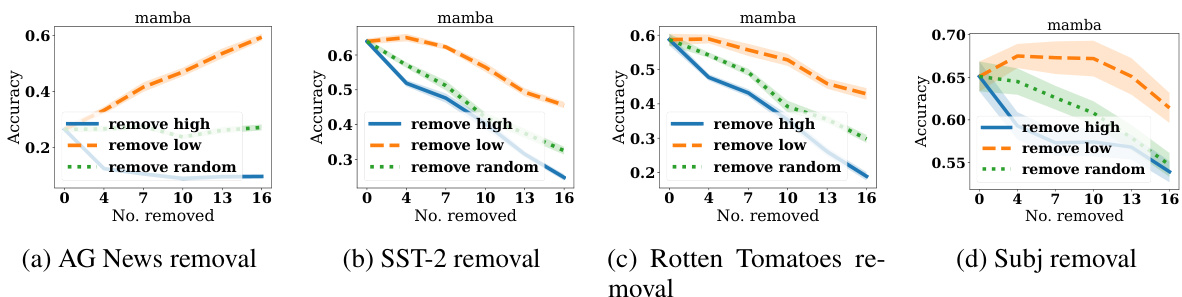
This figure shows the results of experiments on the AG News dataset, demonstrating the effectiveness of DETAIL scores in identifying helpful and harmful demonstrations. The left two plots show that corrupting (changing labels) demonstrations with low DETAIL scores (Itest) has less impact on accuracy than corrupting demonstrations with high scores. The right two plots show that removing demonstrations with low DETAIL scores leads to a smaller decrease in accuracy than removing high-scoring demonstrations. A control experiment with random removal is included.

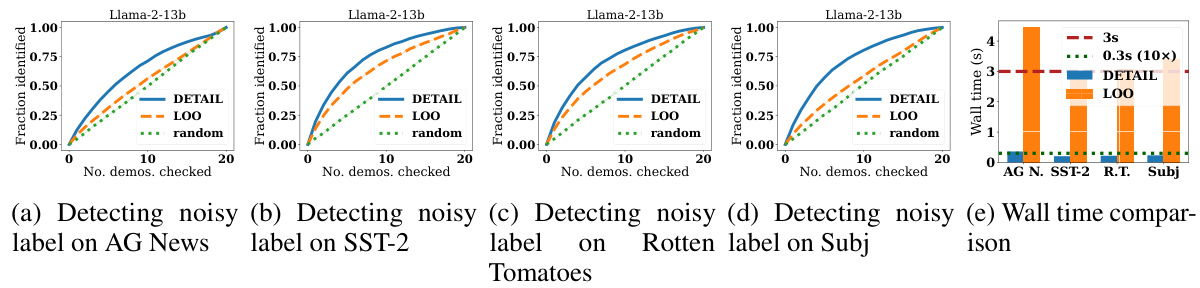
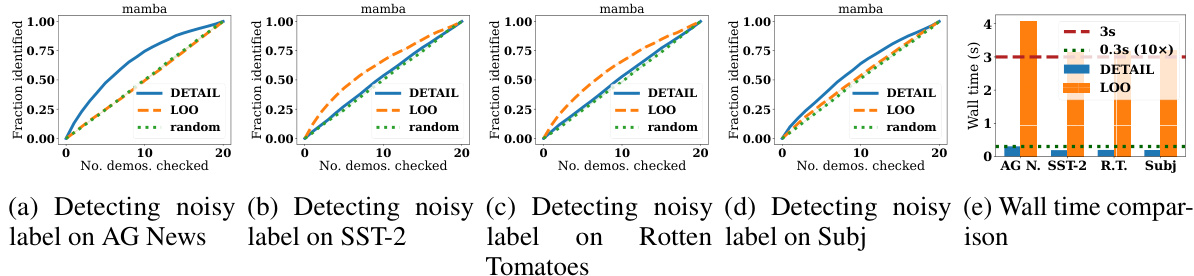
This figure demonstrates the effectiveness of DETAIL in noisy demonstration detection. The first two subfigures show the fraction of noisy labels identified against the number of demonstrations checked using DETAIL and the Leave-One-Out (LOO) method for Subj dataset with Vicuna-7b and Llama-2-13b models. The third subfigure compares the wall time of DETAIL and LOO across multiple datasets. The final subfigure shows the trade-off between computational speed and AUC-ROC score of DETAIL by varying the dimension reduction using random projection on Subj dataset with Vicuna-7b model.

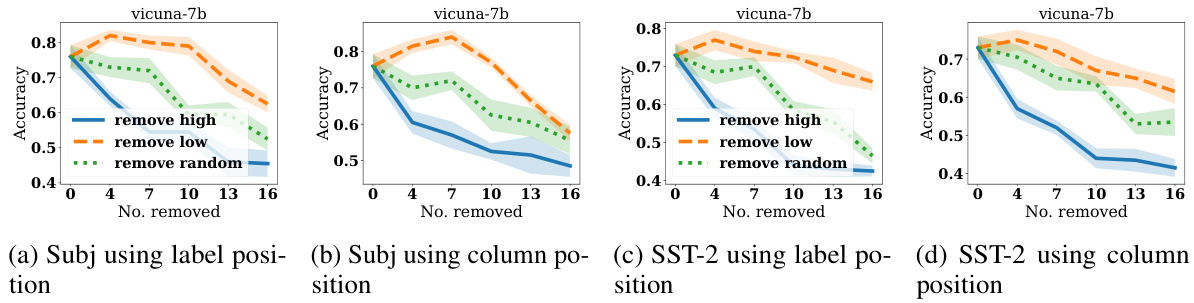
This figure displays the test accuracy results over 50 trials. The x-axis represents the position of a single perturbed (corrupted label) demonstration within a sequence of demonstrations used for in-context learning. The y-axis shows the test accuracy. Three datasets (Rotten Tomatoes, Subj, and SST-2) are shown, each with its own line and shaded error region. The figure demonstrates how changing the position of a noisy demonstration impacts model accuracy. The trend shows that placing a noisy demonstration towards the edges of the demonstration sequence often yields better accuracy than placing it near the middle.

This figure shows the results of experiments on the AG News dataset, demonstrating how model accuracy changes when labels are corrupted or demonstrations are removed based on their DETAIL scores. The four subplots illustrate the effects of corrupting high-score, low-score, and randomly selected demonstrations, and removing high-score, low-score, and randomly selected demonstrations. The results show that corrupting or removing demonstrations with high DETAIL scores (Itest) leads to a larger drop in accuracy than those with low DETAIL scores. This supports the effectiveness of the DETAIL method in identifying influential and less influential demonstrations.
This figure visualizes the results of applying the DETAIL method to a custom transformer on the MNIST dataset. The left side shows how removing demonstrations with high or low influence scores affects the model’s prediction accuracy. The right side shows the average accuracy across multiple experiments, demonstrating the impact of removing different demonstrations on the overall performance. The visualization helps to understand how DETAIL attributes the model’s prediction to individual demonstrations.

This figure visualizes how DETAIL scores (Itest) attribute the model’s prediction to individual demonstrations in an in-context learning task using a custom transformer on the MNIST dataset. The left panel shows a qualitative visualization of Itest, highlighting how removing demonstrations with high Itest (green) leads to incorrect predictions, while removing those with low Itest (red) maintains correct predictions. The right panel quantitatively shows the average accuracy of the model when demonstrations are removed, confirming that removing high-Itest demonstrations causes a more significant drop in accuracy.

This figure presents a comparison of DETAIL and Leave-One-Out (LOO) methods for noisy demonstration detection. The first two subfigures show the fraction of noisy labels identified as a function of the number of demonstrations checked, comparing DETAIL and LOO on the Subj dataset using two different LLMs: Vicuna-7b and Llama-2-13b. The third subfigure displays the wall-clock time of each method on various datasets. Finally, the fourth subfigure shows how the wall-clock time and Area Under the ROC Curve (AUCROC) for DETAIL vary with the dimensionality reduction achieved using random projection on the Subj dataset. In all cases, error bars are included.
The left part of the figure visualizes how DETAIL scores (Itest) attribute the model’s prediction to each demonstration in a custom transformer trained on the MNIST dataset. The right part shows that removing demonstrations with high Itest scores leads to a faster decrease in accuracy than removing those with low Itest scores, indicating that high-scoring demonstrations are more informative.

This figure illustrates the process of computing the DETAIL score for transformer-based in-context learning (ICL). It shows how the influence of each demonstration on the model’s prediction is calculated. The process involves mapping demonstrations to internal representations (using a random projection optionally), creating a kernel regression with these representations, and then computing influence scores using the Hessian and gradient of the loss function. The figure visually demonstrates the computation of both test influence (Itest) and self-influence (Iself) scores, highlighting the key steps involved in the DETAIL method.

The left part of the figure visualizes how the DETAIL score attributes the model’s prediction to individual demonstrations in an in-context learning task on the MNIST dataset. It shows examples of how removing demonstrations with high or low DETAIL scores (Itest) impacts the model’s prediction accuracy. The right part shows the average accuracy over multiple trials when removing demonstrations with varying Itest scores, demonstrating that higher Itest scores correspond to more helpful demonstrations.

This figure illustrates the process of computing the DETAIL score for transformer-based in-context learning (ICL). It shows how the influence function is applied to the internal kernel regression of the transformer model. The process begins with the input tokens and demonstrations, which are mapped to internal representations (m). These representations are used to compute the kernel regression weights (β), which in turn are used to calculate the influence of each demonstration on the model’s prediction (Itest and Iself). The optional random projection step is included to reduce the dimensionality of the internal representations for computational efficiency. The figure clearly illustrates the flow of information and computations involved in obtaining the DETAIL scores.
This figure illustrates the process of calculating the DETAIL score for transformer-based in-context learning (ICL). It depicts the key steps involved in the computation, highlighting the role of the internal kernel regression, the influence function, and the optional random projection for dimensionality reduction. The figure visually represents the flow of information from input demonstrations to the final DETAIL score, which is used to attribute the model’s prediction to individual demonstrations.
This figure illustrates the process of computing the DETAIL score for transformer-based in-context learning (ICL). It shows how the influence function is applied to an internal kernel regression to attribute the model’s prediction to each demonstration. The figure highlights the key steps involved in computing the influence function, including the mapping of ICL demonstrations to an internal representation and the computation of the Hessian and gradient. It also shows how random projection can be used to speed up the computation. The figure uses a consistent notation to represent the embedding before and after random projection, indicating that the projection is optional.
This figure visualizes the DETAIL scores’ ability to attribute a model’s prediction to individual demonstrations in an in-context learning setting using a custom transformer on the MNIST dataset. The left panel shows a qualitative visualization of how removing demonstrations with high or low influence scores impacts the model’s prediction accuracy. The right panel provides a quantitative evaluation of this effect across multiple datasets.

The figure visualizes how the DETAIL scores attribute model prediction to each demonstration on a custom transformer using the MNIST dataset. The left panel shows a qualitative visualization of the Itest attribution by highlighting demonstrations with high Itest (green) and low Itest (red). It demonstrates how removing helpful demonstrations (high Itest) leads to wrong predictions and removing unhelpful ones (low Itest) still allows for correct prediction. The right panel shows the average accuracy of the model on 1013 datasets after removing various numbers of demonstrations with high Itest, low Itest, or randomly.
More on tables
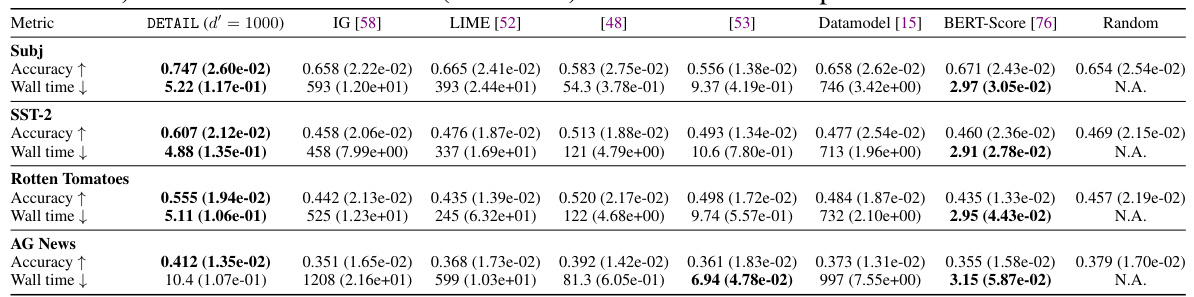
This table presents the test accuracy and wall-clock time for various demonstration curation methods. It compares the DETAIL method against several other attribution techniques (IG, LIME, [48], [53], Datamodel, BERT-Score, and random removal). The results are shown for four datasets (Subj, SST-2, Rotten Tomatoes, and AG News) and indicate the improvement in accuracy after removing the least helpful demonstrations based on each method. Wall time provides the computational cost for each method.

This table presents the results of a demonstration curation experiment. The experiment compared the test accuracy achieved by using DETAIL to select demonstrations with the lowest scores against a baseline approach using randomly selected demonstrations. The wall time (time taken for computation) is also provided for each method on four different datasets: Subj, SST-2, Rotten Tomatoes, and AG News. The mean and standard deviation are provided for 20 repeated trials to evaluate the reliability and consistency of the results. The results aim to show that DETAIL is both effective in improving accuracy and computationally efficient.
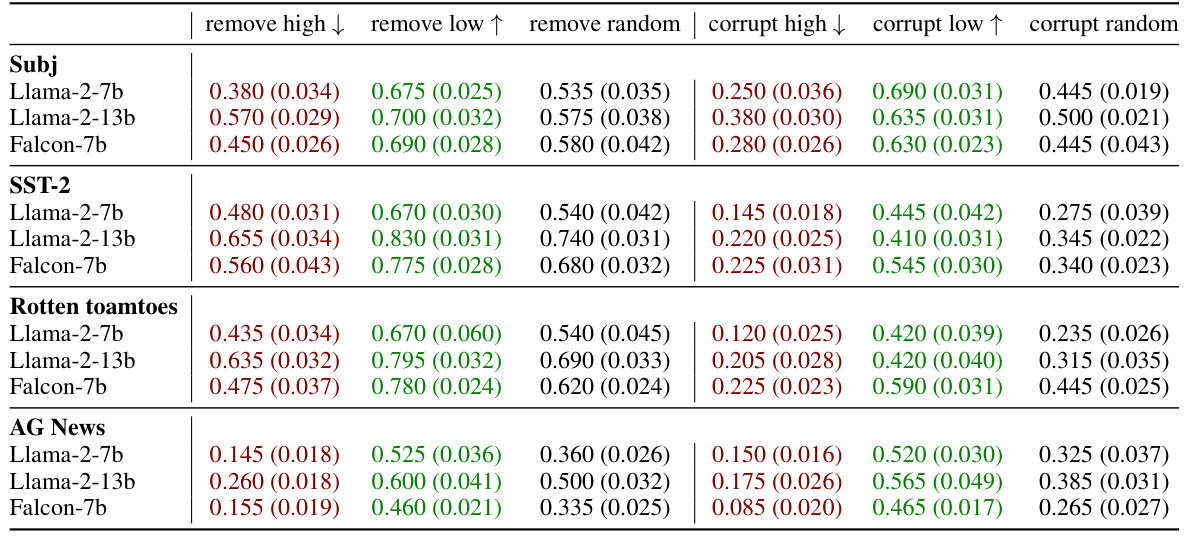
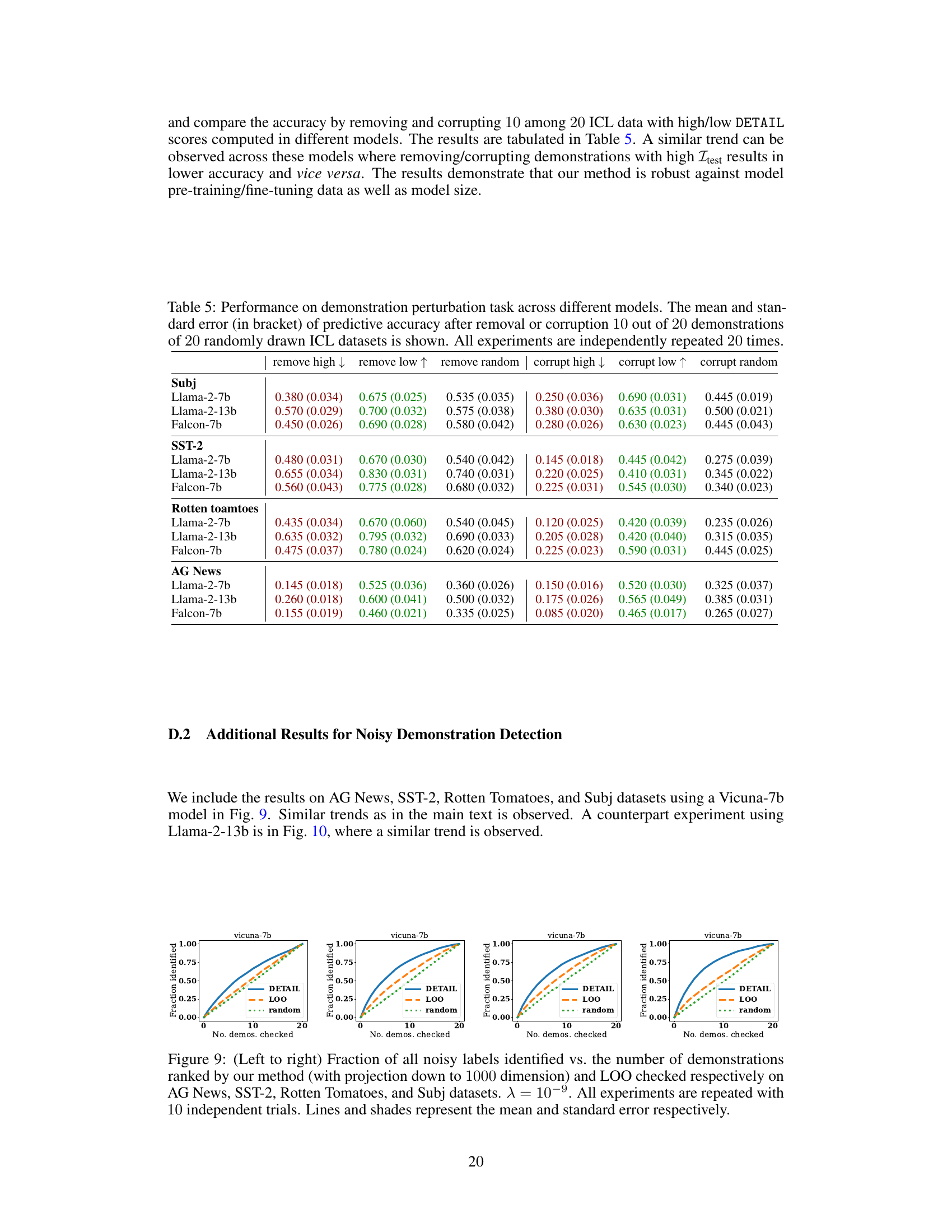
This table presents the results of experiments on demonstration perturbation, comparing the performance of three different large language models (LLMs): Llama-2-7b, Llama-2-13b, and Falcon-7b. The experiment involves removing or corrupting 10 out of 20 demonstrations within an in-context learning (ICL) dataset. The table shows the average accuracy and standard error for each model under different conditions (removing high-influence, low-influence, or random demonstrations; corrupting high-influence, low-influence, or random demonstrations). The data illustrates how sensitive the models are to the quality and order of demonstrations.

This table presents the results of an experiment comparing the predictive accuracy of a model using randomly ordered demonstrations versus demonstrations ordered based on the Iself scores from the DETAIL method. The experiment was repeated 80 times, and the mean and standard error are reported for each condition (random ordering and Iself-based ordering). The results are shown separately for three different datasets: Subj, SST-2, and Rotten Tomatoes, and for two conditions: without any corrupted demonstrations and with 3 corrupted demonstrations.
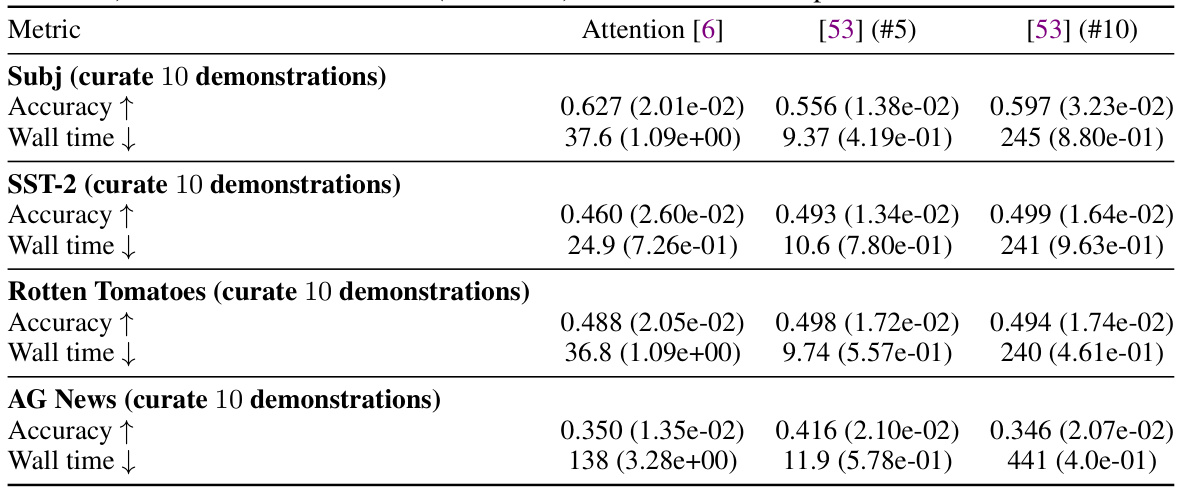
This table presents the test accuracy and wall time for different demonstration curation methods on four datasets: Subj, SST-2, Rotten Tomatoes, and AG News. The results are compared across multiple methods, including the proposed DETAIL method and several baselines (IG, LIME, Attention, etc.). Each method’s performance is evaluated by removing 10 demonstrations from the dataset and measuring the resulting test accuracy. Wall times indicate the computational efficiency of each method.
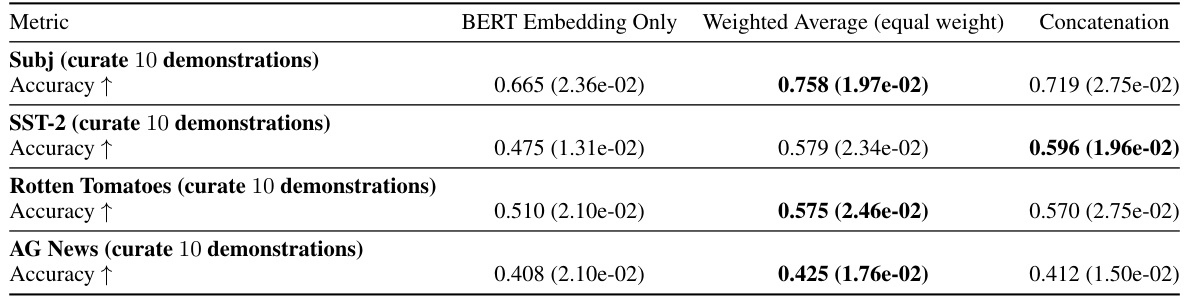
This table presents the test accuracy and wall time for the demonstration curation task using different methods for combining BERT embeddings and transformer hidden states. The methods compared include using only BERT embeddings, a weighted average of BERT embeddings and transformer hidden states, and a concatenation of both. The results show the accuracy achieved after curating 10 demonstrations on four different datasets (Subj, SST-2, Rotten Tomatoes, AG News).
Full paper#