↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current offboard perception methods for autonomous driving heavily rely on human-labeled data, which is costly and time-consuming. They also struggle with open-set recognition and the challenges of data imbalance and sparsity, particularly for small and distant objects. This limits their ability to adapt to rapidly evolving perception tasks and hinders the development of robust, fully autonomous systems.
The proposed ZOPP framework tackles these issues with a novel multi-modal approach that leverages zero-shot recognition capabilities. It integrates vision foundation models with point cloud data to generate high-quality 3D labels automatically without human intervention. ZOPP demonstrates strong performance across various perception tasks including 3D object detection, segmentation, and occupancy prediction, highlighting its potential for real-world applications and paving the way for a more efficient and robust approach to auto-labeling in autonomous driving.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and computer vision. It addresses the challenge of data scarcity and imbalance in existing offboard perception methods by introducing a novel zero-shot approach. The multi-modal framework and open-set capabilities are highly relevant to current research trends, while the comprehensive empirical studies provide a strong foundation for future work in this field. The findings open new avenues for research in efficient auto-labeling techniques and robust open-vocabulary perception, advancing the development of safer and more reliable autonomous driving systems.
Visual Insights#
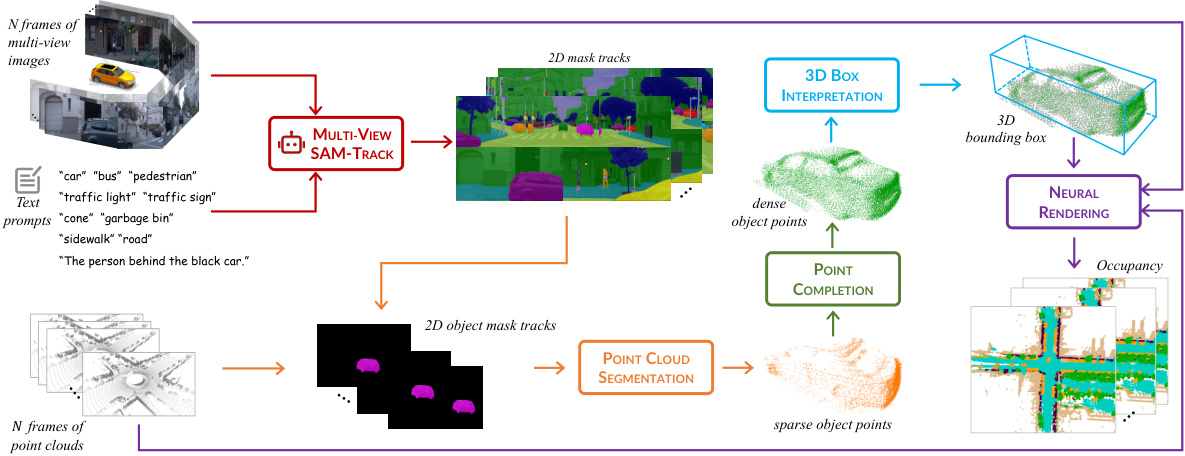
This figure illustrates the overall framework of the Zero-shot Offboard Panoptic Perception (ZOPP) system. It shows a pipeline that processes multi-view images and point clouds to generate 2D and 3D panoptic segmentations, 3D object detections, and 4D occupancy reconstruction. Each stage is color-coded to illustrate the flow of information and the different modules involved.
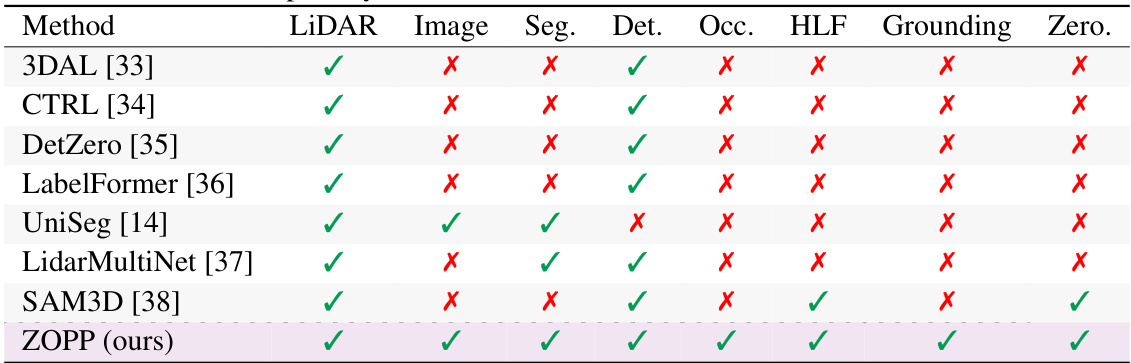
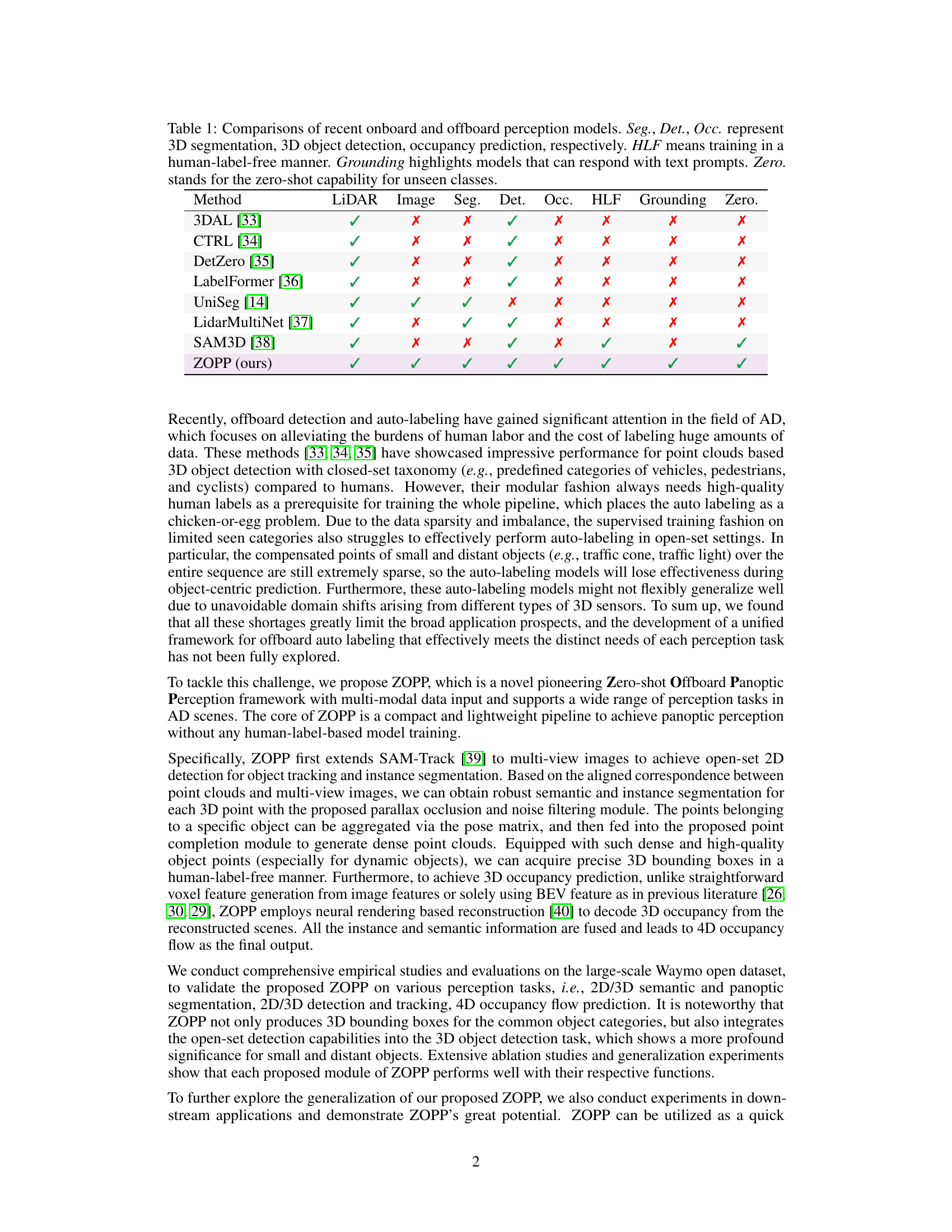
This table compares several existing onboard and offboard perception models across various criteria, including their use of LiDAR and image data, their ability to perform 3D segmentation, detection, and occupancy prediction, whether they are trained in a human-label-free manner, if they support grounding (responding to text prompts), and if they have zero-shot capabilities for unseen classes. It helps to highlight the unique features of the proposed ZOPP model in comparison to prior art.
In-depth insights#
Zero-Shot Panoptic#
Zero-shot panoptic approaches in computer vision aim to achieve high-quality scene understanding without relying on extensive labeled datasets for training. This is particularly useful in autonomous driving where rapidly evolving scenarios and the cost of human labeling are significant challenges. A zero-shot panoptic system would ideally accomplish simultaneous semantic and instance segmentation across diverse object classes, even those not seen during training. It leverages the power of large, pre-trained models such as foundation models to generalize recognition capabilities, potentially using multi-modal data sources (e.g., images and LiDAR). Key challenges involve robust object detection and tracking, effective occlusion handling, and the ability to seamlessly integrate different modalities for a consistent and accurate scene representation. Success in this area would significantly accelerate the development of more robust, efficient, and cost-effective autonomous systems.
Multi-Modal Fusion#
Multi-modal fusion in the context of autonomous driving signifies the integration of data from diverse sensors, such as LiDAR, cameras, and radar, to achieve a more holistic and robust perception of the environment. Effective fusion strategies are critical because individual sensors provide incomplete or noisy data; combining them mitigates limitations. For example, LiDAR offers precise 3D point cloud data but struggles with identifying object classes, while cameras excel at object recognition but lack depth information. Fusion techniques leverage the strengths of each modality, resulting in more accurate object detection, tracking, and scene understanding than unimodal approaches. Challenges include efficient data alignment and handling the inherent differences in data representation and sampling rates across diverse sensors. Advanced deep learning models are commonly employed, often involving attention mechanisms or transformer networks, to weigh the importance of information from each sensor contextually. Successful multi-modal fusion is essential for reliable and safe autonomous navigation in complex and dynamic real-world scenarios.
Parallax Handling#
Parallax error, inherent in multi-camera or LiDAR-camera systems due to differing sensor viewpoints, significantly impacts 3D scene reconstruction accuracy. Effective parallax handling is crucial for accurate 3D object detection and segmentation. The core challenge lies in identifying and correcting for discrepancies between projected 2D image coordinates and their corresponding 3D points. Robust solutions often involve sophisticated algorithms that leverage multi-view geometry and/or point cloud processing techniques. These may include techniques like parallax occlusion filtering, which removes background points erroneously projected onto foreground objects, and point cloud completion methods, which infer missing or sparse 3D data to create a more comprehensive representation of the scene. Accuracy heavily depends on precise sensor calibration and alignment. Additionally, the complexity of parallax handling increases with the number of viewpoints and the presence of occlusions. Therefore, efficient and computationally feasible solutions are essential, often involving careful consideration of trade-offs between accuracy, computational cost, and real-time performance requirements. Advanced deep learning models may play a vital role in automatically learning and addressing parallax issues, potentially providing more robust and generalized solutions than traditional geometric approaches.
4D Occupancy#
The concept of ‘4D Occupancy’ in autonomous driving extends traditional 3D scene understanding by incorporating the temporal dimension. It moves beyond simply representing the presence or absence of objects in a 3D space at a single point in time. 4D occupancy aims to capture the dynamic evolution of the scene, showing how objects move and change over time. This is crucial for autonomous vehicles to predict future movements of other vehicles and pedestrians, enabling safer and more efficient navigation. Accurate 4D occupancy estimation relies on robust sensor fusion, typically combining data from LiDAR, cameras, and potentially radar, to generate a comprehensive and temporally consistent representation of the environment. Challenges in achieving this include handling occlusions, noise in sensor data, and computationally efficient processing of large datasets. Moreover, the choice of representation significantly impacts both accuracy and computational cost, making the selection of an appropriate 4D occupancy representation a critical design consideration.
Open-Set AD#
The concept of “Open-Set AD” (Autonomous Driving) signifies a crucial advancement in the field, moving beyond the limitations of closed-set systems. Closed-set systems are trained on a fixed set of objects and scenarios, leading to poor performance when encountering unfamiliar situations. Open-set AD, however, aims to build systems capable of handling unforeseen objects and situations, mimicking human adaptability. This requires addressing significant challenges such as robust perception, capable of identifying novel objects, and generalization, enabling the system to apply learned knowledge to new contexts. Zero-shot learning techniques become critical in this paradigm, allowing the AD system to recognize and react to objects never seen during training. The core of open-set AD lies in developing more versatile and adaptable algorithms that leverage a combination of data, models, and real-world experience, enabling safe and efficient navigation in dynamic and unpredictable environments. Safety and robustness become paramount concerns as the system deals with potentially hazardous scenarios resulting from the unexpected.
More visual insights#
More on figures
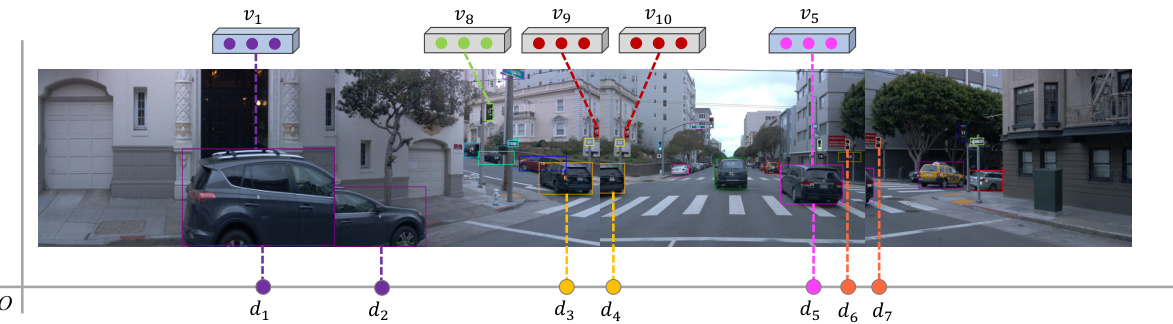
This figure illustrates the multi-view object association method used in the ZOPP framework. It shows how the system matches objects across multiple camera views by combining visual appearance similarity (visual features v1-v10) and spatial proximity (distances d1-d7). Objects with similar visual features and close spatial locations are linked, ensuring consistent tracking even when objects appear in multiple views. The example highlights how traffic lights, despite being spatially separated, are correctly associated due to similar visual features.
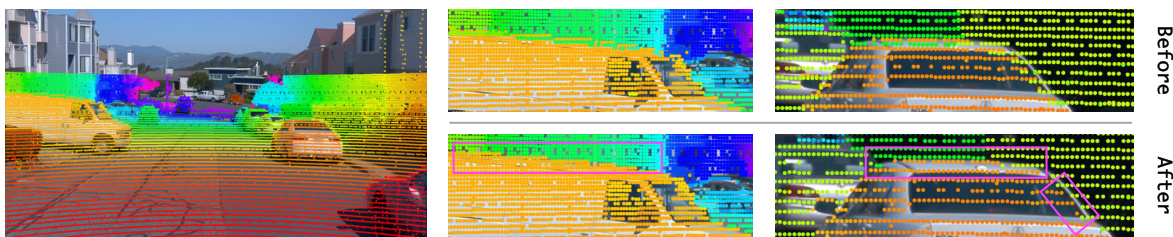
This figure shows the effect of parallax occlusion filtering on point cloud projection. The top row displays point clouds projected onto the image plane before filtering, showing how background points are incorrectly projected onto foreground objects due to the LiDAR’s higher vantage point. The bottom row demonstrates the result after filtering, where background points are removed, resulting in cleaner and more accurate foreground object point clouds. The color map represents the depth values, with nearer points in lighter colors and farther points in darker colors. The pink boxes highlight areas where background points were filtered out.

This figure provides a high-level overview of the ZOPP framework, illustrating the various stages involved in achieving offboard panoptic perception. It highlights the key components and their sequential processing, from multi-view mask tracking to final 4D occupancy reconstruction.
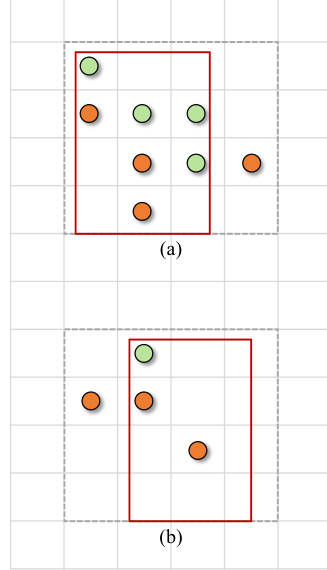
This figure illustrates two scenarios for constructing local rectangular regions used in the parallax occlusion filtering algorithm. The algorithm aims to identify and remove background points that are incorrectly projected onto foreground objects due to the parallax effect of LiDAR’s higher vantage point compared to the cameras. In (a), multiple foreground points (green) have projected points (orange) inside the rectangle region, indicating background points that must be removed. In (b), only one foreground point has this issue, and a pseudo-coordinate is used to generate the rectangular region. The rectangle region encompasses the points to be filtered out.

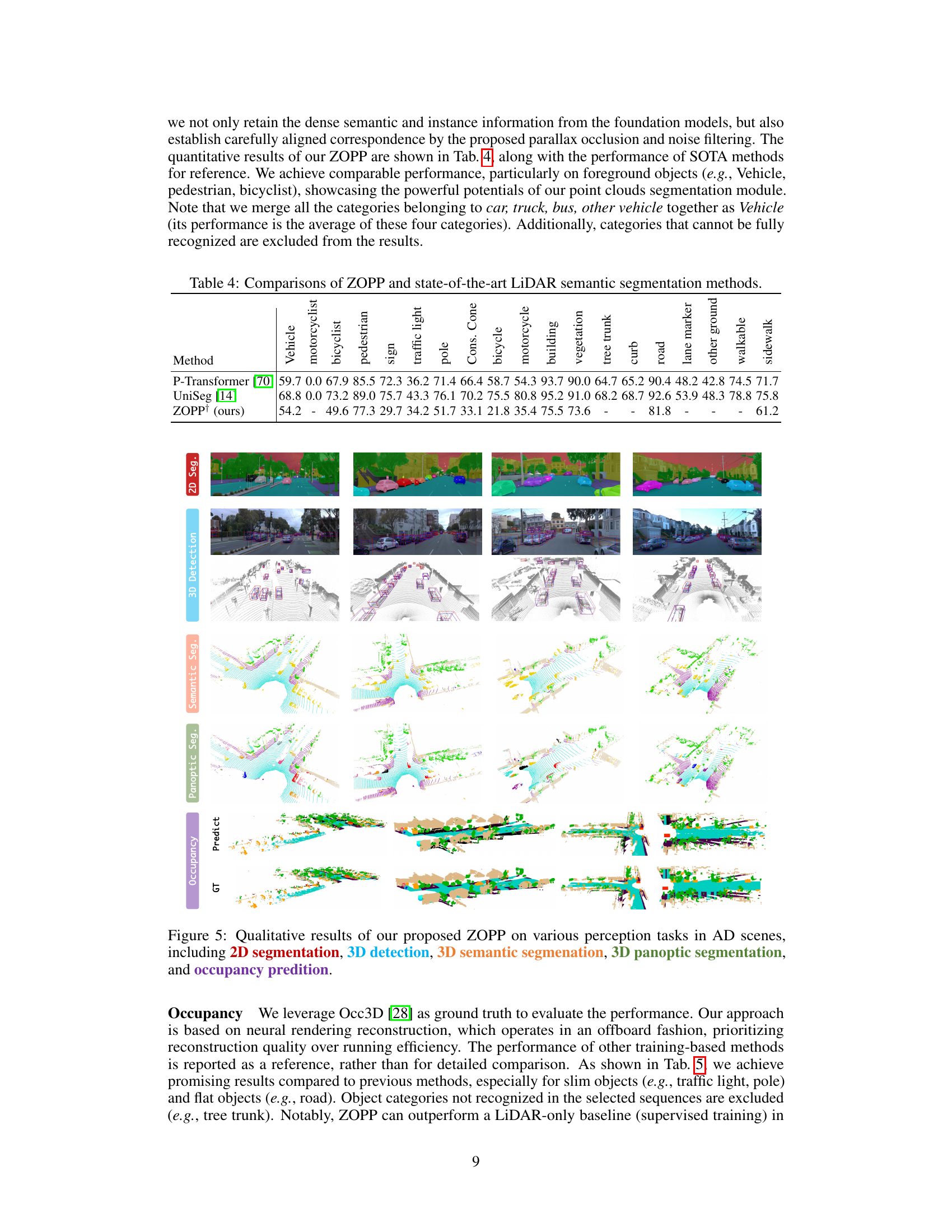
This figure showcases the qualitative results of the ZOPP model on various perception tasks in autonomous driving scenarios. It presents results for 2D segmentation, 3D detection (with bounding boxes), 3D semantic segmentation (showing the different semantic classes), 3D panoptic segmentation (combining semantic and instance information), and occupancy prediction (representing the 3D structure of the scene). Each column represents a different scene from the Waymo Open Dataset, illustrating the capabilities of ZOPP in handling diverse and complex driving scenarios.
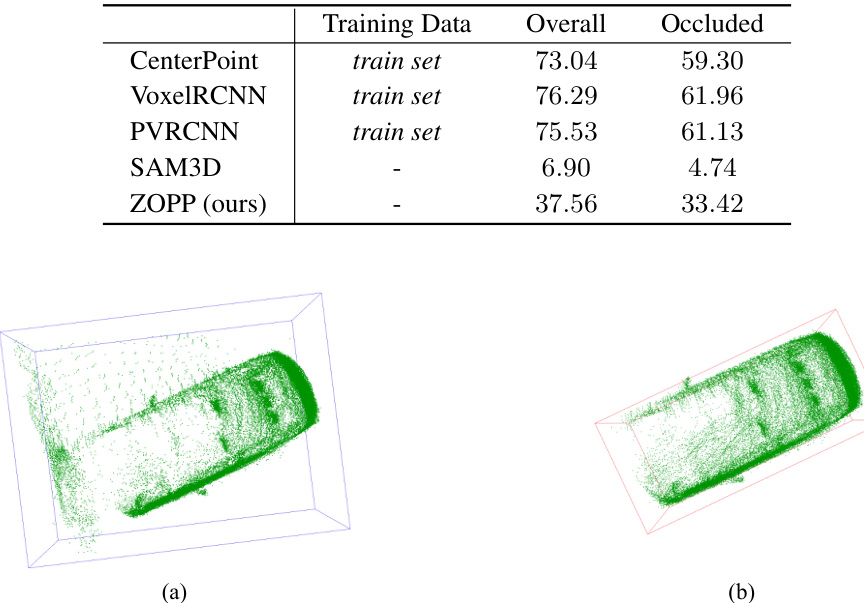
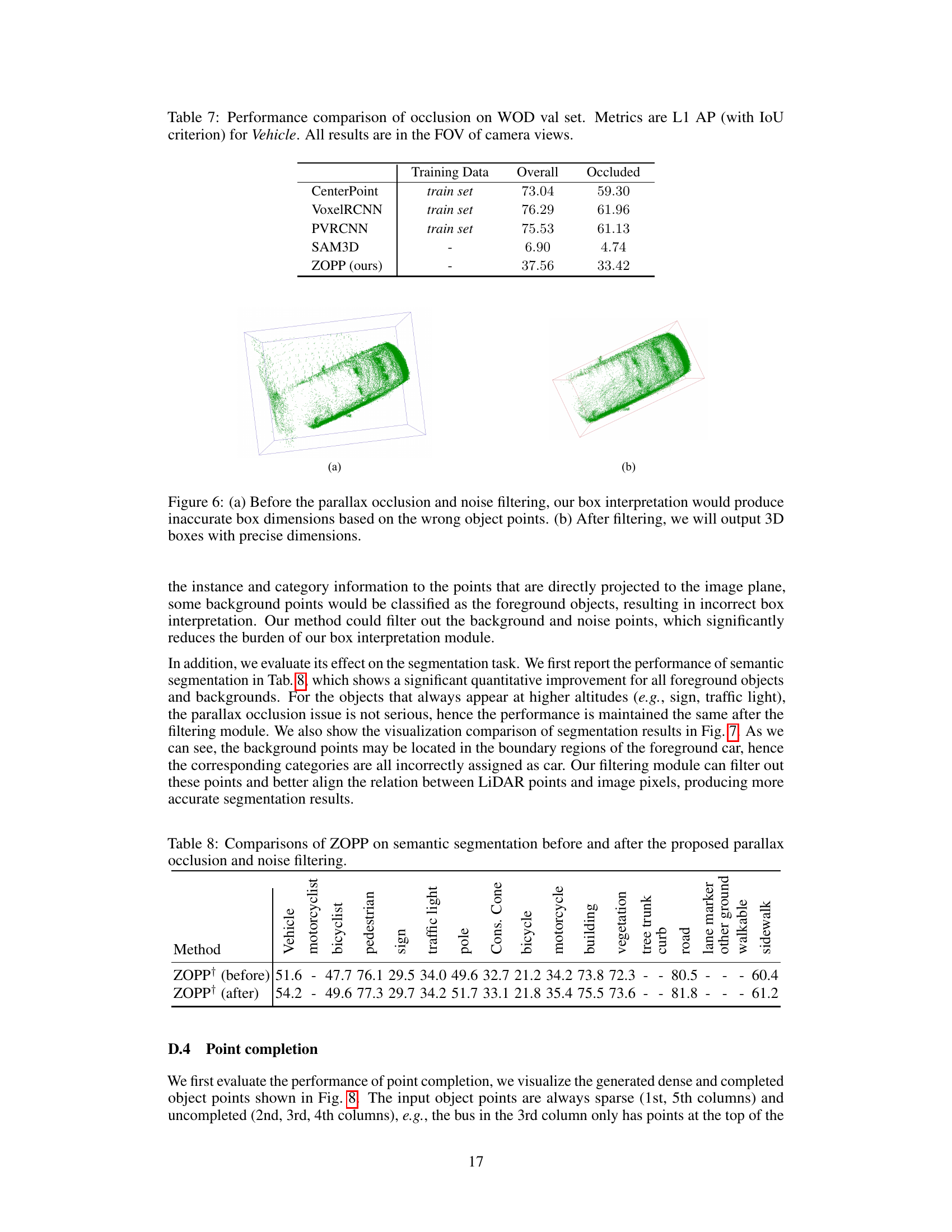
This figure shows the effectiveness of the parallax occlusion and noise filtering module by comparing the box interpretation results before and after the filtering operation. The left image (a) demonstrates inaccurate box dimensions due to incorrect object points before filtering. The right image (b) shows the accurate 3D boxes obtained after filtering out background points and noise, leading to more precise dimensions.

This figure shows the effect of the parallax occlusion and noise filtering module. Before filtering (top), the 3D points belonging to the background are incorrectly projected into the pixel regions of the foreground object (car). After applying the proposed filtering method, the background points are removed, resulting in a more accurate segmentation of the foreground object.

This figure shows the effectiveness of the point cloud completion module. The top row displays the sparse and incomplete input point clouds for various objects. The bottom row presents the same objects but with dense and complete point clouds generated by the point completion module. This demonstrates the module’s ability to recover detailed geometric structures from sparse data, which is crucial for accurate 3D bounding box prediction.

This figure shows the effect of the parallax occlusion and noise filtering module. The left side shows point clouds projected onto the image plane, color-coded by depth. The right side compares the results before and after applying the filtering, highlighting how background points that are incorrectly assigned to foreground objects due to parallax are removed.
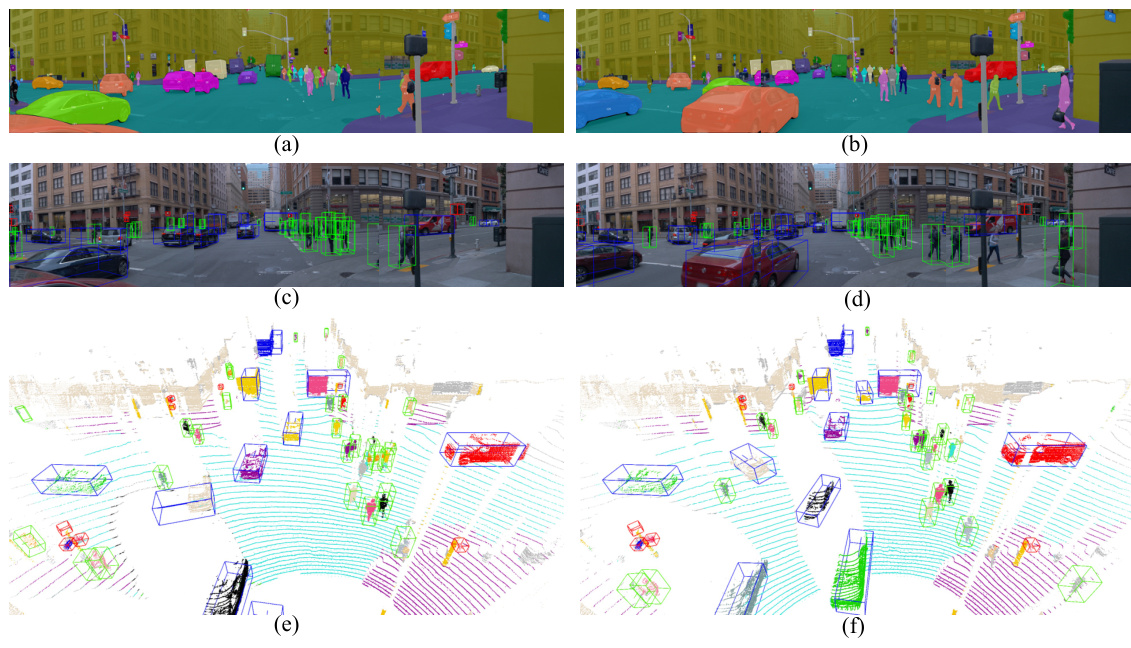
This figure shows several qualitative results of the proposed ZOPP model on various perception tasks for autonomous driving. It presents visualizations for different tasks, such as 2D and 3D semantic segmentation, object detection, panoptic segmentation, and occupancy prediction. The results showcase the model’s ability to generate high-quality perception outputs across different modalities.

This figure shows four examples of failure cases for the ZOPP model. The failures are caused by challenging weather conditions (night, rain), and overexposed images. The resulting outputs show the negative impact of these conditions on detection, segmentation, and reconstruction quality.
More on tables

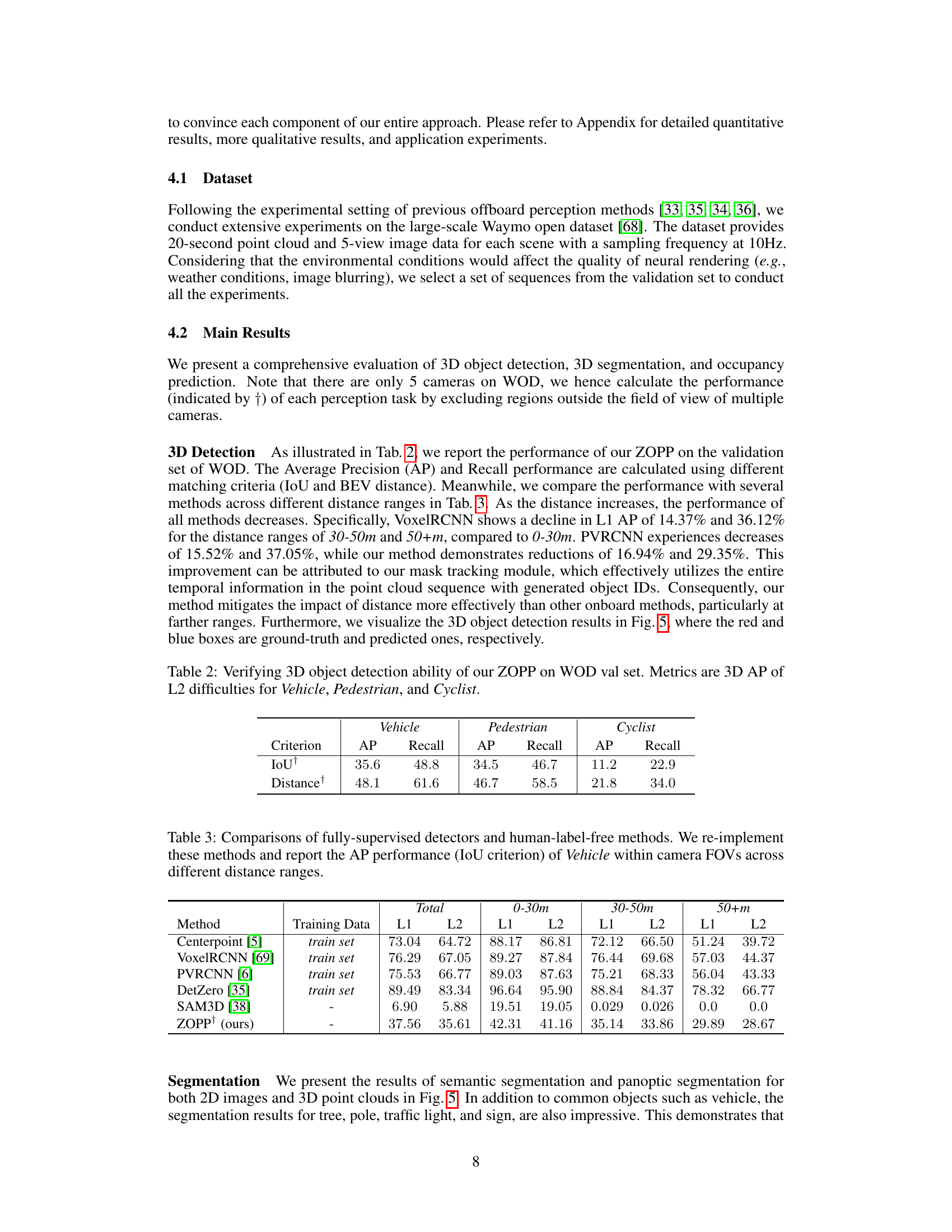
This table presents the performance of the ZOPP model on the Waymo Open Dataset validation set for 3D object detection. It shows the Average Precision (AP) and Recall for vehicles, pedestrians, and cyclists, using two different matching criteria: Intersection over Union (IoU) and BEV distance. The results demonstrate the effectiveness of ZOPP in 3D object detection across different difficulty levels (L2).
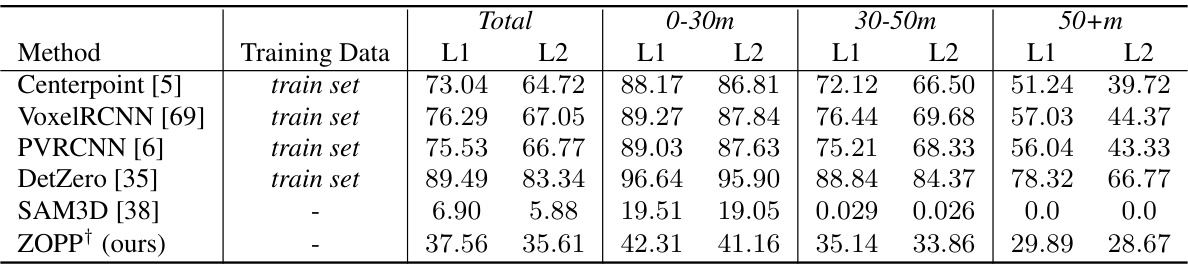
This table compares the Average Precision (AP) performance of various 3D object detection methods, categorized as fully-supervised and human-label-free. The comparison is done across three different distance ranges (0-30m, 30-50m, and 50+m) to illustrate the impact of distance on performance. The IoU criterion is used for evaluating the accuracy of bounding boxes. The results highlight the performance differences between methods trained with human-labeled data versus those that do not require human labels.
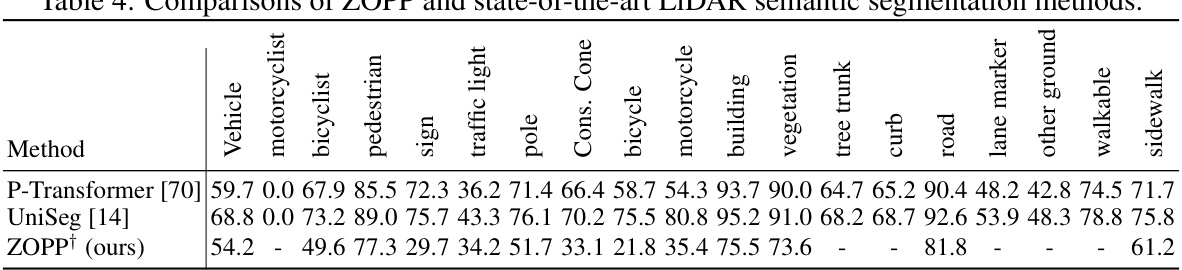
This table compares the performance of the proposed ZOPP method against other state-of-the-art LiDAR semantic segmentation methods. The comparison is done using various metrics across different object categories (vehicle, motorcyclist, bicyclist, pedestrian, sign, traffic light, pole, cone, bicycle, motorcycle, building, vegetation, tree trunk, curb, road, lane marker, other ground, walkable, sidewalk). The results show how ZOPP performs relative to existing methods in terms of accuracy for semantic segmentation of LiDAR point cloud data.
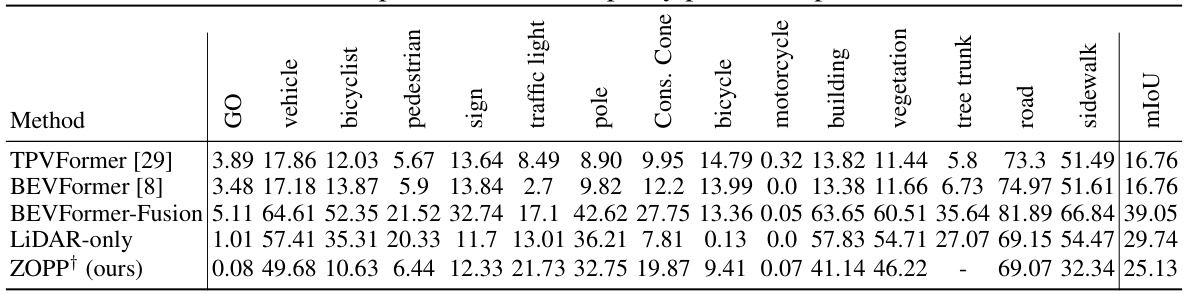
This table compares the performance of ZOPP against other state-of-the-art methods on 3D occupancy prediction. The metrics used include mean Intersection over Union (mIoU) and Average Precision (AP) for various object categories (vehicle, bicyclist, pedestrian, etc.). The table highlights the strengths and weaknesses of ZOPP in relation to existing approaches.
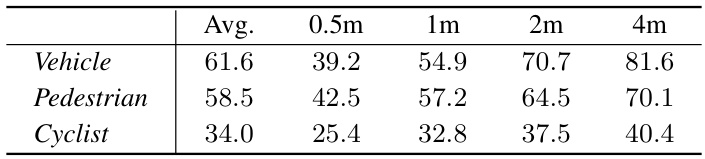
This table presents the results of the 3D object detection performance evaluation on the Waymo Open Dataset (WOD) validation set. The evaluation metrics used are Average Precision (AP) and Recall, calculated for different levels of difficulty (L2) and across various object categories (Vehicle, Pedestrian, and Cyclist). The table demonstrates the ability of the proposed ZOPP framework to accurately detect 3D objects in autonomous driving scenes.

This table compares the performance of semantic segmentation on various object categories before and after applying parallax occlusion and noise filtering. The results demonstrate the improvement in segmentation accuracy achieved by this filtering module, particularly for foreground objects. Note that the performance on objects like signs and traffic lights, which are typically less affected by occlusion, remains relatively consistent.

This table presents the recall of the 3D bounding box interpretation on the Waymo Open Dataset validation set before and after applying parallax noise filtering and point completion. The metrics used are Recall of L2 difficulties (IoU criterion) for vehicles, pedestrians, and cyclists. The results are limited to the field of view of the cameras.
Full paper#