↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Automating photo finishing, the process of refining images using software like Adobe Lightroom, is challenging due to the complexity and non-differentiability of existing pipelines. Previous attempts using optimization methods are slow and often require differentiable proxy models, which are difficult to train and may not perfectly replicate real-world pipelines. This results in low-quality results or a lengthy processing time.
This paper tackles these challenges using goal-conditioned reinforcement learning (RL). The authors treat the photo finishing pipeline as a ‘black box’, eliminating the need for proxy models. The RL agent learns a policy that efficiently finds the optimal parameter set by using the goal image as a condition. Experiments demonstrate that the proposed RL-based method outperforms traditional methods in both speed and image quality, achieving comparable PSNR results in only 10 iterations compared to 500 iterations required by zeroth-order methods. The study also explores photo stylization, expanding the applications of their efficient tuning approach.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel and efficient approach to automate the photo finishing process, a task that is currently time-consuming and requires expertise. The RL-based method offers significant improvements in speed and quality over existing techniques, opening new avenues for research in image processing and computer vision. Its applicability to black-box systems has broad implications for various domains using similar non-differentiable image manipulation pipelines.
Visual Insights#

This figure compares the performance of three different photo finishing tuning methods: the proposed RL-based method, a cascaded proxy-based method, and a CMAES (Covariance Matrix Adaptation Evolution Strategy) method. The RL-based method is shown to achieve comparable PSNR (Peak Signal-to-Noise Ratio) with significantly fewer iterations (10) compared to the other two methods (200 and 500 iterations, respectively). The figure highlights the advantages of the RL-based approach in terms of speed, quality, and the avoidance of needing a differentiable proxy of the photo finishing pipeline. The image shows a visual comparison of the output of each method at different iterations.

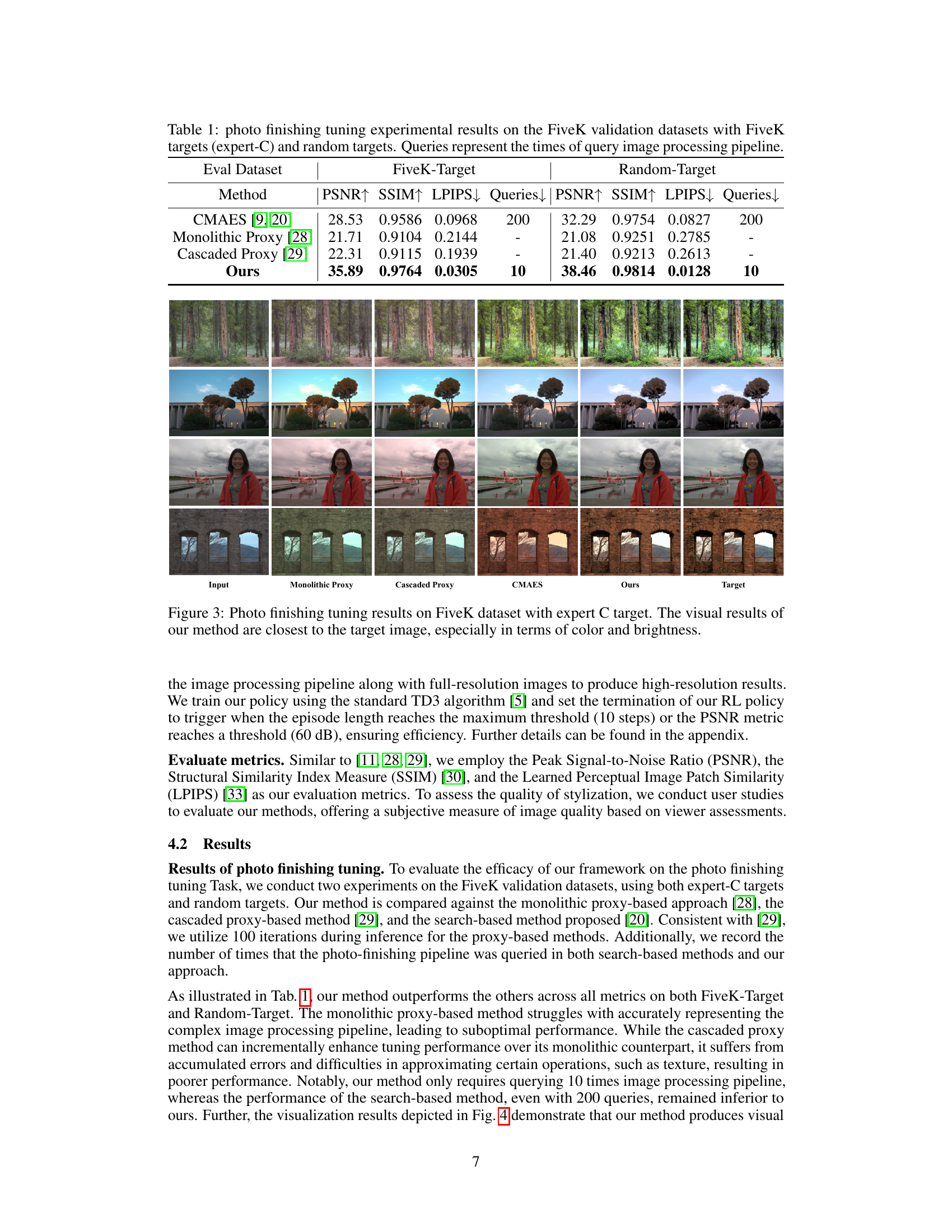
This table presents a comparison of different methods for photo finishing tuning on the FiveK dataset. It shows the performance of four methods (CMAES, Monolithic Proxy, Cascaded Proxy, and the proposed RL method) using two different target types: expert-curated targets and randomly generated targets. The metrics used are PSNR, SSIM, LPIPS, and the number of queries to the image processing pipeline. The table highlights the superior efficiency and image quality of the proposed RL-based method which requires significantly fewer queries than other methods while achieving higher PSNR, SSIM, and lower LPIPS scores.
In-depth insights#
RL for ISP Tuning#
Reinforcement learning (RL) presents a novel approach to Image Signal Processing (ISP) tuning, addressing limitations of traditional methods. Unlike optimization-based techniques that struggle with high-dimensional parameter spaces and non-differentiable pipelines, RL agents can directly learn effective tuning policies by interacting with the ISP as a black box. A key advantage is the potential for faster convergence compared to zeroth-order or gradient-based methods. This is because RL agents learn to explore the parameter space efficiently, guided by a reward function that measures the closeness of the processed image to the target. However, successful application requires careful design of the reward function and state representation, which must effectively capture relevant image features and tuning parameters. The choice of RL algorithm also influences performance, balancing exploration-exploitation trade-offs. Future research should focus on more robust reward functions, advanced RL algorithms, and techniques to address potential overfitting and generalization issues.
Goal-Conditioned RL#
Goal-conditioned reinforcement learning (RL) represents a significant advancement in RL, addressing the challenge of directing an agent towards specific, predefined objectives. Instead of relying solely on reward signals, goal-conditioned RL incorporates a goal representation as an explicit input to the agent’s policy. This allows the agent to learn a mapping from states and goals to actions, enabling more efficient and targeted behavior. The key advantage lies in the enhanced ability to solve complex tasks requiring precise control and planning, where simple reward functions may be insufficient. Different methods for representing and incorporating goals exist, including direct embedding, separate goal networks, or hierarchical approaches. The approach is particularly useful in scenarios involving sparse rewards, long-term planning, and diverse task specifications. Careful consideration must be given to goal representation and the design of the reward function to ensure effective learning and desired behavior. The complexity of the goal representation and the reward function can significantly impact the efficiency and overall success of the goal-conditioned RL approach. Further research is exploring the application of goal-conditioned RL to a wider array of applications, such as robotics, game playing, and image processing.
State Representation#
Effective state representation is crucial for reinforcement learning (RL) agents to succeed in complex environments. In the context of photo finishing and stylization, a well-designed state representation must capture the nuances of both image content and style, enabling the RL agent to learn efficient tuning policies. A comprehensive approach involves combining multiple features, such as CNN-based dual-path features (capturing both global and local image properties), photo statistics (histogram matching for perceptual similarity), and historical action embeddings (providing temporal context for sequential tuning). The dual-path CNN approach is particularly insightful, offering a fine-grained understanding of the image. The combination of these features allows the agent to learn richer policies and achieve better performance than simpler representations using only image pixel data or limited image statistics. The inclusion of historical actions is key, as it allows the agent to learn from the consequences of past actions and adapt its strategy accordingly, facilitating effective iterative refinement.
Efficiency Analysis#
An Efficiency Analysis section in a research paper would ideally delve into a multifaceted evaluation of the proposed method’s performance. It should go beyond simply stating that the method is ’efficient’ and provide concrete evidence. This could involve comparing the computational cost (time complexity) against existing state-of-the-art approaches, possibly using benchmark datasets and standard metrics. A strong analysis would also quantify the resource usage, such as memory and energy consumption, to provide a holistic picture. Crucially, it should discuss scalability, showing how the method’s efficiency holds up as the problem size increases (e.g., number of data points, image resolution). Furthermore, a good analysis would explore potential trade-offs. For example, a more computationally expensive method might yield superior accuracy, requiring a discussion of this trade-off and the practical implications. Finally, the analysis should also consider implementation details that might impact efficiency and offer insights into potential optimization strategies for future improvements. Benchmarking against established baselines is key, ensuring the comparison is fair and meaningful. The methodology employed for timing and resource measurements also needs to be clearly detailed and rigorous, emphasizing reproducibility.
Future Directions#
Future research could explore several promising avenues. Extending the RL framework to handle diverse input modalities, beyond images, such as textual descriptions or other sensor data, would significantly broaden its applicability. This would require designing robust state representations capable of integrating heterogeneous information effectively. Another critical area is improving the efficiency of the RL training process, potentially through the use of more advanced RL algorithms or more efficient network architectures. The current approach relies on a black-box pipeline; investigating methods for integrating learned models with existing, differentiable ISP modules could enhance performance and provide more control. Finally, the paper focuses primarily on photo finishing and stylization; expanding to encompass a broader range of image editing tasks is a logical next step. This could involve developing more sophisticated reward functions and incorporating user feedback mechanisms for improved adaptability and customization.
More visual insights#
More on figures

This figure illustrates the proposed RL-based photo finishing tuning framework. The top row shows the architecture of the goal-conditioned policy, which takes the current image and goal image as input to generate the next set of parameters for the image processing pipeline. The state representation comprises dual-path features (encoding global and local image characteristics), photo statistics (matching traditional image statistics), and historical actions. The bottom row visualizes the iterative tuning process, showcasing how the pipeline parameters are adjusted step-by-step to match the goal image. Each step involves the policy mapping the current image and the goal image to a new set of parameters, which are then used by the image processing pipeline to generate the next step’s processed image.

This figure shows a visual comparison of photo finishing results on the FiveK dataset using different methods: Monolithic Proxy, Cascaded Proxy, CMAES, and the proposed RL-based method. Each row represents a different input image with its corresponding outputs from each method and the expert-generated target image. The RL-based method consistently produces results that closely resemble the expert-generated targets in terms of color and brightness, demonstrating its effectiveness.

This figure showcases a visual comparison of photo finishing tuning results on the FiveK dataset using expert C targets. It compares the results of five different methods: input image, monolithic proxy, cascaded proxy, CMAES, and the proposed RL-based method. Each row represents a different image, illustrating the results of each method side-by-side. The visual comparison highlights that the proposed method produces image results that are closer to the expert C target images in terms of color and brightness, demonstrating its superiority in photo finishing tuning.

This figure compares the visual results of different photo finishing tuning methods on the FiveK dataset using expert C target images. The methods compared include Monolithic Proxy, Cascaded Proxy, CMAES, and the authors’ proposed RL-based method. The figure shows that the RL-based method produces results that are visually closer to the target images than the other methods, particularly in terms of color and brightness. Each row displays the input image, the results of each method, and the target image for a specific example.

This figure displays the results of a user study comparing four different photo stylization methods: Ours, CMAES, Cascaded Proxy, and Monolithic Proxy. Participants were shown a target image and four images generated by each method and asked to select the images most similar to the target. The bar chart shows the number of times each method was chosen as the most similar, illustrating the relative success of each approach in the user’s opinion. The results indicate a strong preference for the ‘Ours’ method, showcasing its superior ability to produce stylistically accurate results.

This figure compares the visual results of photo finishing tuning on the FiveK dataset using expert C target images. It shows the input image, the results obtained using the monolithic proxy method, the cascaded proxy method, the CMAES algorithm, the proposed RL-based method, and finally, the target image. The comparison highlights the superior performance of the RL-based approach in terms of color accuracy and brightness, demonstrating its ability to produce results that closely match the target.

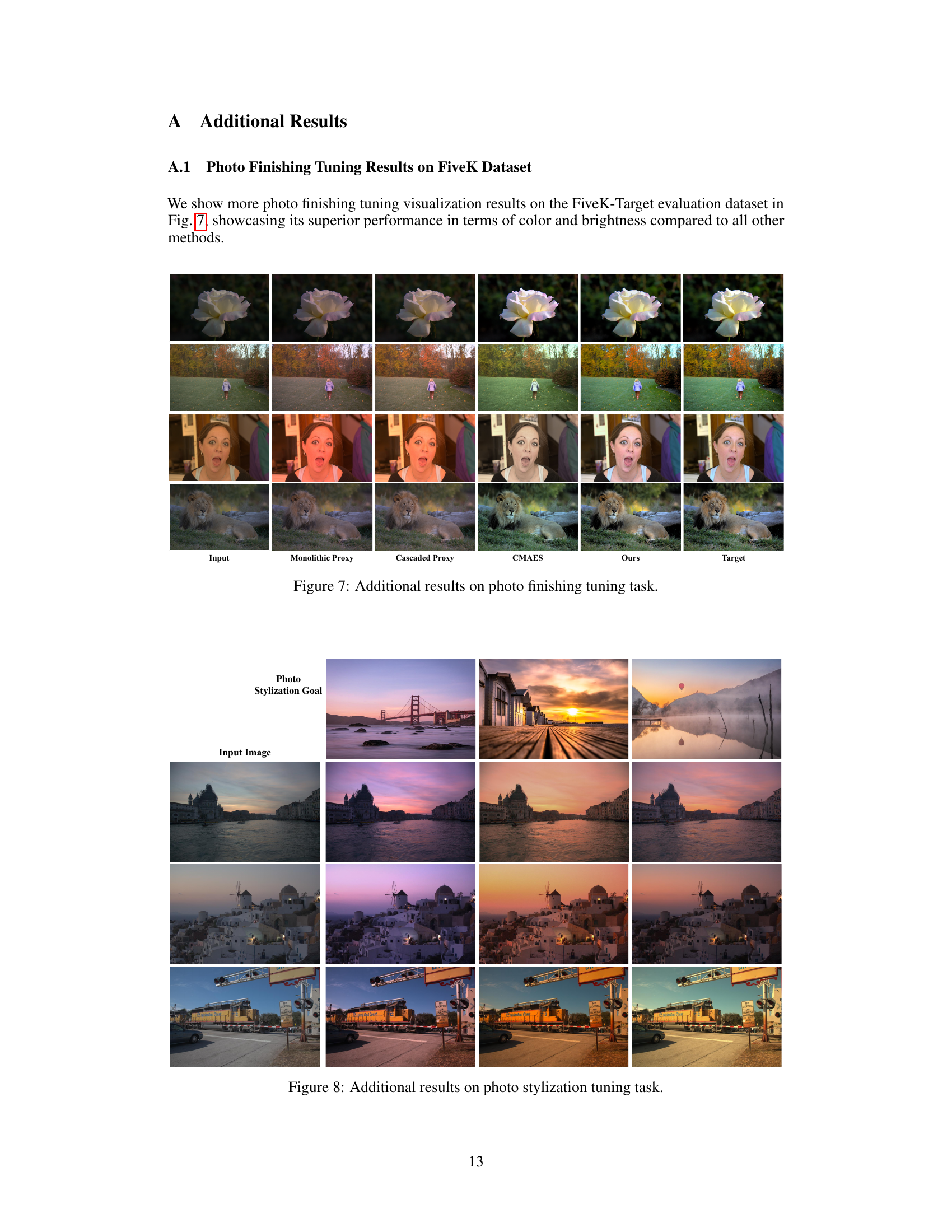
This figure shows a qualitative comparison of photo stylization results obtained using four different methods: the proposed RL-based method, CMAES, monolithic proxy, and cascaded proxy. For each of several input images, it presents the input image and the outputs generated by each method, alongside the style target image. The results demonstrate that the RL-based method produces outputs that visually align best with the style of the target image, outperforming the other three methods in terms of achieving the desired stylistic effect.

This figure shows the options provided to participants in question 7 of a user study. The user study was designed to assess the quality of photo stylization tuning results produced by various methods. Participants were shown a target image and four alternative images (labeled A, B, C, and D), and asked to select the image(s) that most closely resembled the target image. Each option represents a different method’s photo stylization result for a given input image. The figure helps to visually illustrate the diversity of results produced by different algorithms and the challenges involved in this task.

This figure compares the performance of the proposed RL-based photo finishing tuning algorithm against three other methods: a cascaded proxy-based method, a monolithic proxy-based method, and a zeroth-order optimization method (CMAES). It shows that the RL-based approach achieves comparable Peak Signal-to-Noise Ratio (PSNR) values using only 10 iterations compared to 500 iterations for the zeroth-order method. The RL-based method also exhibits better image quality and doesn’t require a proxy model.

This figure shows the options given to participants in question 7 of the user study on photo stylization tuning. The ‘Target’ image is presented to the left, showing the desired style, followed by four different image processing outputs (A, B, C, D) that participants could choose from, indicating which result best matched the target style. The purpose is to compare the perceptual similarity of the stylization results from different algorithms.

This figure shows the results of a user study comparing different methods for photo stylization. Participants were shown a target image and four stylized versions generated by different techniques (Ours, CMAES, Cascaded Proxy, Monolithic Proxy). They chose up to two images that best matched the target. The bar chart displays the number of times each method was selected for each of 20 questions, demonstrating user preference for different stylization approaches.

This figure shows a visual comparison of photo finishing results using different methods on the FiveK dataset, with a specific expert’s edited image as the target. The input image is shown alongside results from three baseline methods (Monolithic Proxy, Cascaded Proxy, and CMAES) and the proposed RL-based method. The visual comparison highlights the superiority of the RL approach in closely matching the target image in terms of color and brightness.

This figure shows the options presented to participants in question 2 of a user study. The goal image (Target) is displayed alongside four images (A, B, C, D) generated by different methods. Participants were asked to choose which image(s) most closely resembled the goal image. The purpose was to evaluate the performance of each method for photo stylization tuning by subjective user assessment.

This figure shows the options provided to participants in question 2 of the user study. The target image and four options (A, B, C, and D) are shown, and participants were asked to select the image that most closely resembles the target image. This was part of a user study designed to evaluate the effectiveness of different photo stylization methods.

This figure presents a visual comparison of photo finishing results on the FiveK dataset using the expert C target. The top row shows the input image and the target image. The bottom four rows show the results produced by four different methods: Monolithic Proxy, Cascaded Proxy, CMAES, and the proposed method (Ours). The visual comparison highlights that the proposed method most accurately reproduces the color and brightness of the target image, outperforming the other three methods.

This figure shows the options given to participants in question 7 of the user study. The target image is shown on the left and four different processed images (A, B, C, D), presumably generated by different methods (ours, CMAES, Monolithic proxy, Cascaded proxy), are displayed on the right. The participants were asked to select up to two images that most closely resemble the target image.

This figure compares the proposed RL-based method with other methods for photo finishing tuning. It shows that the RL-based method achieves comparable PSNR (Peak Signal-to-Noise Ratio) in significantly fewer iterations (10) than a zeroth-order optimization method (500). The comparison highlights the advantages of RL in terms of speed, quality, and avoidance of proxy models.

This figure displays the options presented to participants in question 7 of a user study on photo stylization. It shows a target image alongside four stylized versions (A, B, C, and D), generated using different methods. Participants were asked to select the options that most closely resembled the target image.

This figure illustrates the proposed reinforcement learning framework for photo finishing tuning. The top row shows the architecture, where a goal-conditioned policy uses the current image and goal image to generate new parameters for an image processing pipeline. The state representation incorporates dual-path features, photo statistics, and historical actions. The bottom row visually demonstrates the iterative tuning process, showing how the generated parameters progressively refine the image towards the goal image.

This figure shows the options provided to participants in question 7 of the user study. The user study aimed to evaluate the effectiveness of different photo stylization methods. In this specific question, participants were presented with a target image and four different stylized versions (labeled A, B, C, and D) generated by different methods. The task was to select the option(s) most closely resembling the target image.

This figure shows the options provided to participants in question 7 of a user study evaluating photo stylization tuning. The figure presents a target image alongside four different results (A, B, C, and D), generated by various methods. Participants were asked to select up to two images that most closely resembled the target style.

This figure shows the options given to participants in question 1 of the user study. The target image is displayed on the left, and four different image processing results (A, B, C, D) are shown on the right. Each result represents the output of a different photo stylization method, and participants were asked to select the option(s) that most closely resemble the target style.

This figure shows the options given to participants in question 5 of the user study. The target image is displayed on the left, followed by four processed versions (labeled A, B, C, and D) generated by different methods. Participants were asked to select the image(s) that most closely resembled the target image.

This figure shows the options provided to participants in question 17 of a user study. The user study evaluated the results of a photo stylization tuning task. Each option presents four different stylized versions (A, B, C, and D) of a single image, with the goal being to identify which options (or option) most closely matched the style of a target image shown above. This helps assess the effectiveness of different photo stylization methods.

This figure shows the options provided to participants in question 7 of the user study. The options consist of four images (labeled A, B, C, and D) resulting from different photo stylization methods. Participants were asked to select the image(s) that most closely resembled the target image shown at the top of the figure.

This figure shows the options presented to participants in question 2 of the user study. The target image depicts a cityscape at sunset, and the four options (A, B, C, and D) represent different stylization results from four different methods in the photo stylization tuning task. Participants were asked to choose the option(s) most closely resembling the target image.

This figure shows the options given to participants in question 2 of the user study. The target image is displayed on the left, followed by four processed images (A, B, C, D) generated using different methods. Participants were asked to choose the image(s) that most closely resembles the target image.
More on tables

This table compares the processing time of four different photo finishing tuning methods (Monolithic Proxy, Cascaded Proxy, CMAES, and the proposed RL-based method) across four different input image resolutions (720P, 1K, 2K, and 4K). The results demonstrate that the RL-based method is significantly faster than the other methods, particularly at higher resolutions.

This table presents the results of a photo finishing tuning experiment conducted on the HDR+ dataset. The experiment compares different methods: CMAES, Greedy Search, Monolithic Proxy, Cascaded Proxy, and the authors’ proposed method. The metrics used for evaluation are PSNR, SSIM, LPIPS, and the number of queries to the image processing pipeline. The authors’ method significantly outperforms the others in terms of PSNR, SSIM, and LPIPS, while requiring significantly fewer queries.
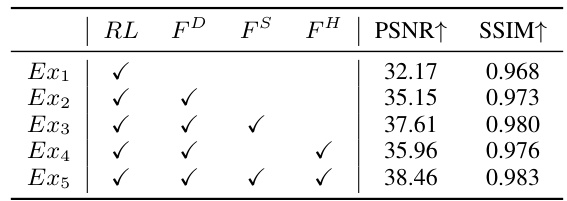
This table presents the results of an ablation study investigating the impact of each component of the proposed photo finishing state representation on the performance of the reinforcement learning (RL) based method. The study uses FiveK Random-Target dataset for photo finishing tuning. The baseline (RL) uses a naive CNN-based encoder. Subsequent experiments add one component at a time: dual-path feature representation (FD), photo statistics representation (FS), and historical actions embedding (FH). The PSNR and SSIM metrics are used to evaluate the performance, showing incremental improvements with the addition of each component.
Full paper#