↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) frequently produce inaccurate long-form responses, hindering their reliability in many applications. Current automated evaluation methods are inadequate for assessing the factuality of lengthy text. This necessitates more effective ways of measuring LLMs’ ability to generate factually accurate and comprehensive answers.
This research introduces two key contributions to address this challenge. First, it presents LongFact, a large-scale, multi-topic benchmark dataset designed to evaluate long-form factuality. Second, it proposes SAFE, a search-augmented factuality evaluator that leverages LLMs to automate the evaluation process, substantially reducing costs and improving accuracy compared to human annotation. Results from benchmarking multiple LLMs reveal that larger models tend to exhibit better performance in generating factually correct long-form text.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers because it introduces a novel approach for evaluating the factuality of long-form text generated by large language models (LLMs). It directly addresses the critical issue of LLM reliability and provides a cost-effective automated evaluation method that surpasses human annotators. This work significantly advances the field by offering a robust benchmark dataset and evaluation technique which facilitates more accurate and reliable assessment of LLM progress.
Visual Insights#
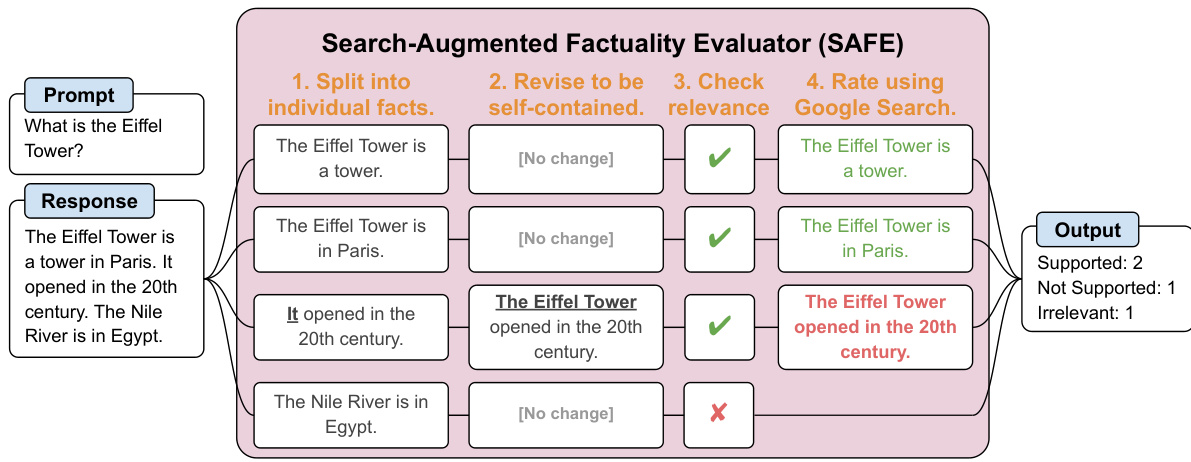
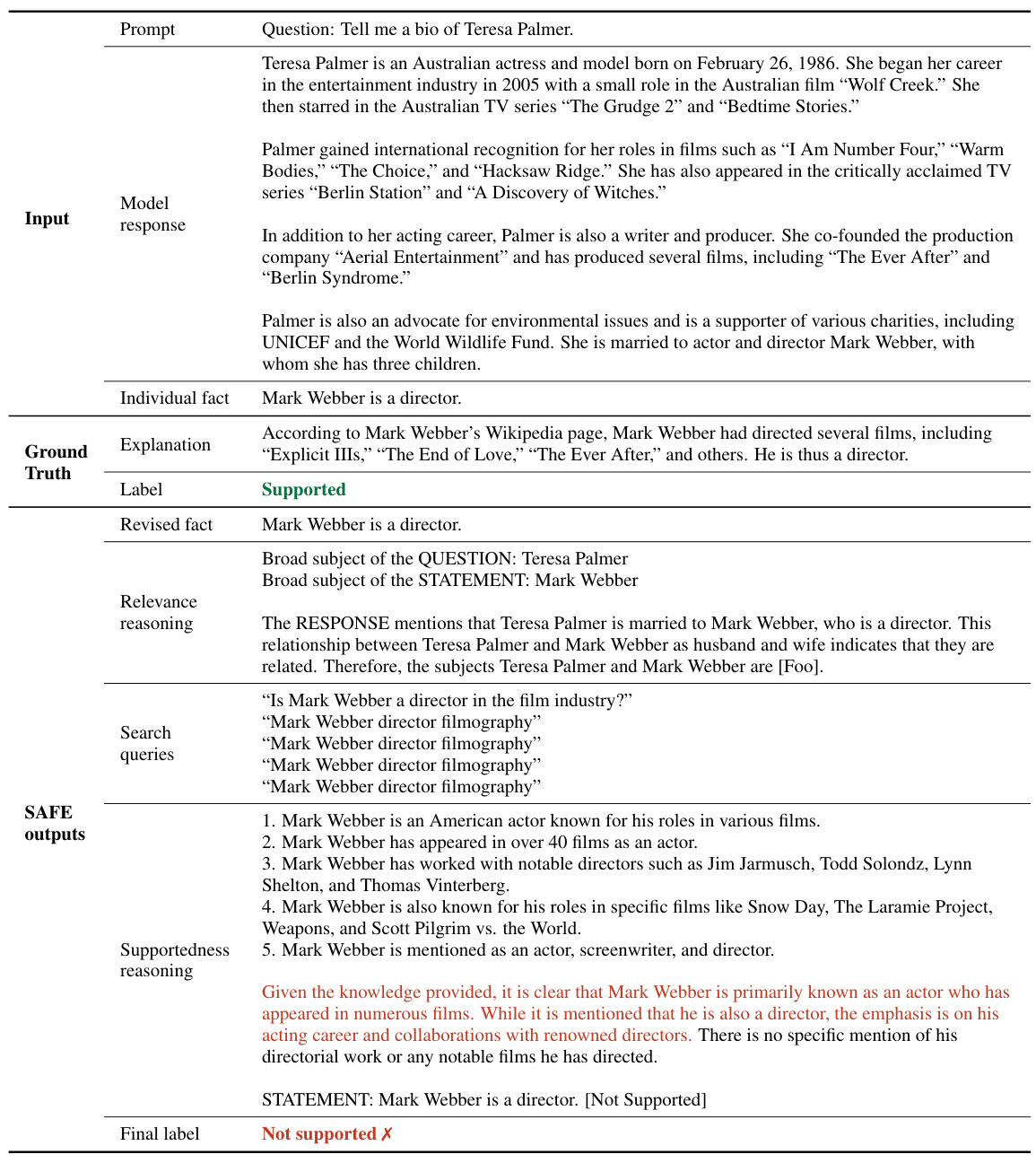
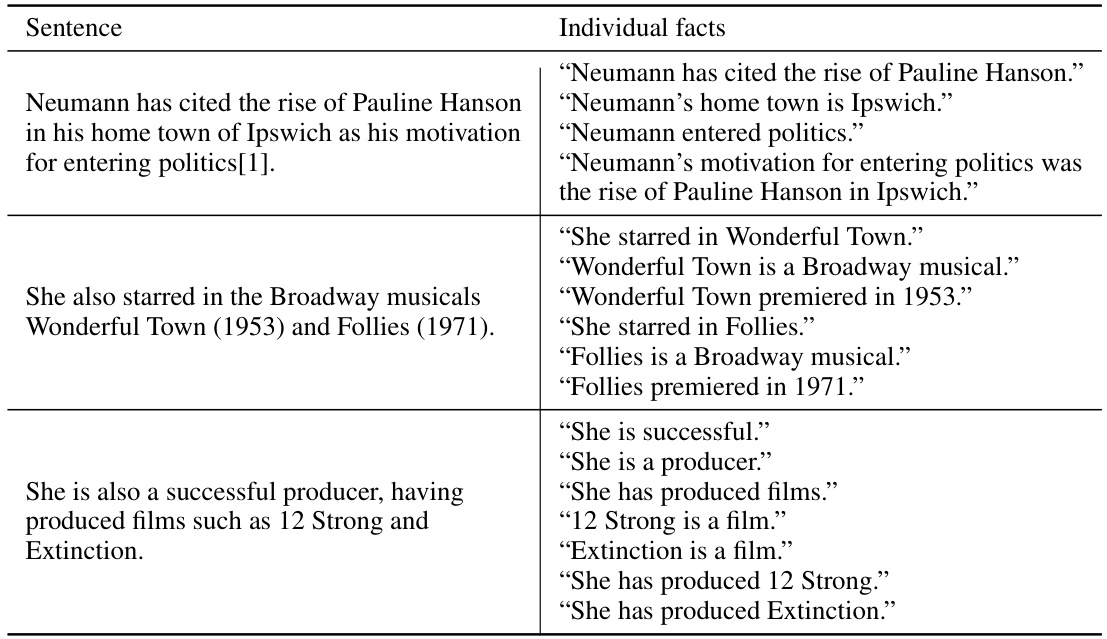
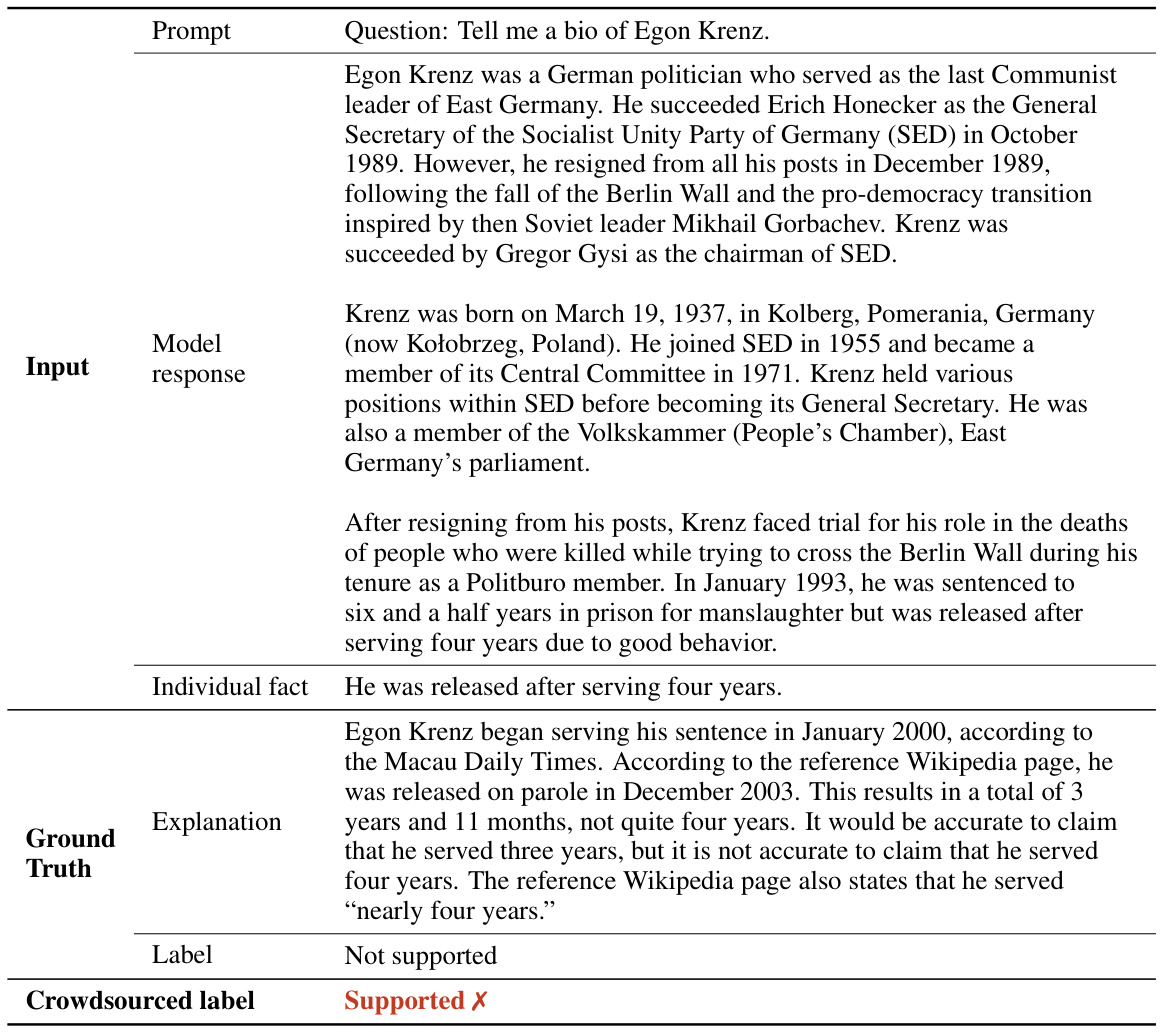
The figure illustrates the SAFE (Search-Augmented Factuality Evaluator) process. SAFE uses an LLM to assess the factuality of a long-form response by breaking it down into individual facts. Each fact is checked for self-containment and relevance to the prompt. Then, Google Search is used to verify the accuracy of relevant facts. The output shows the number of facts categorized as supported, not supported, and irrelevant.
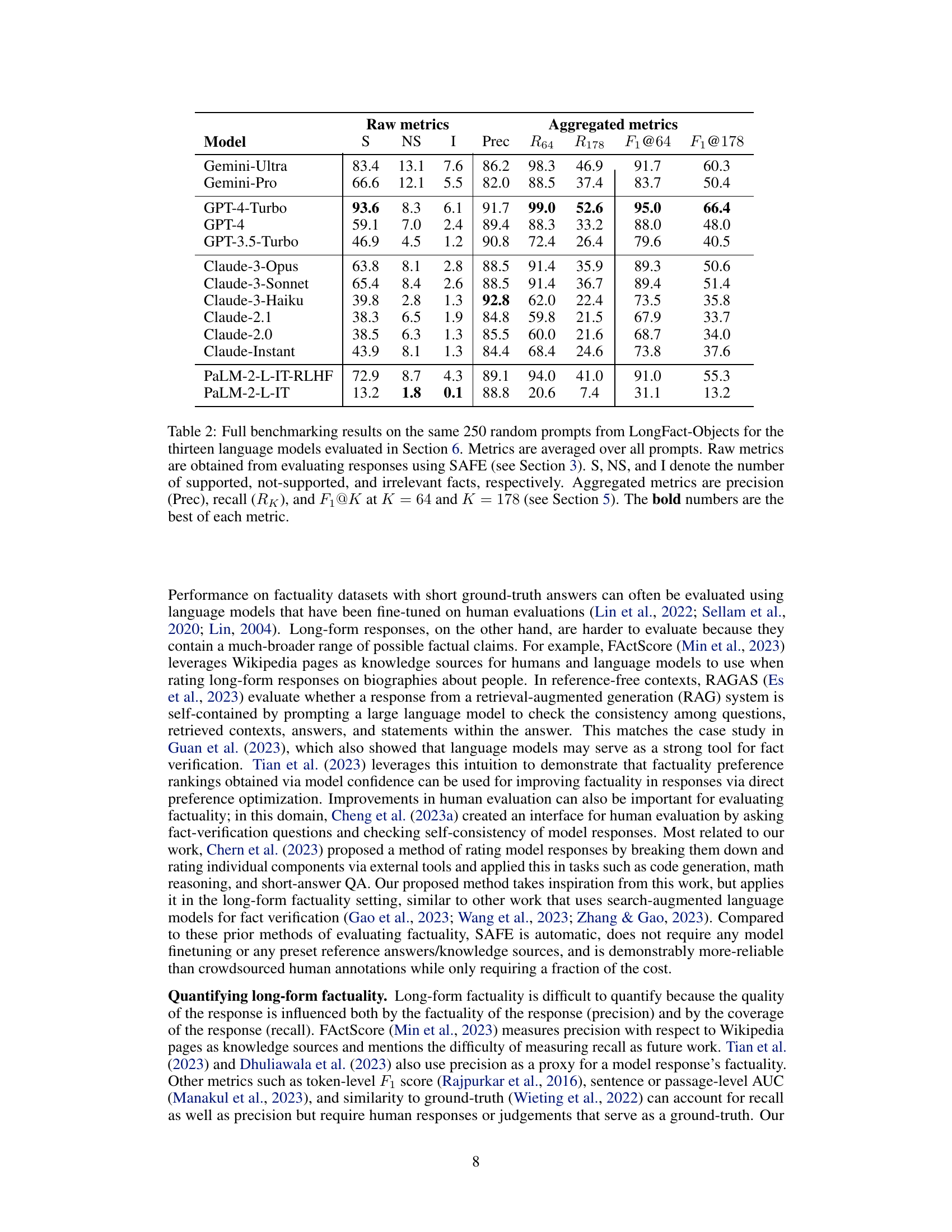
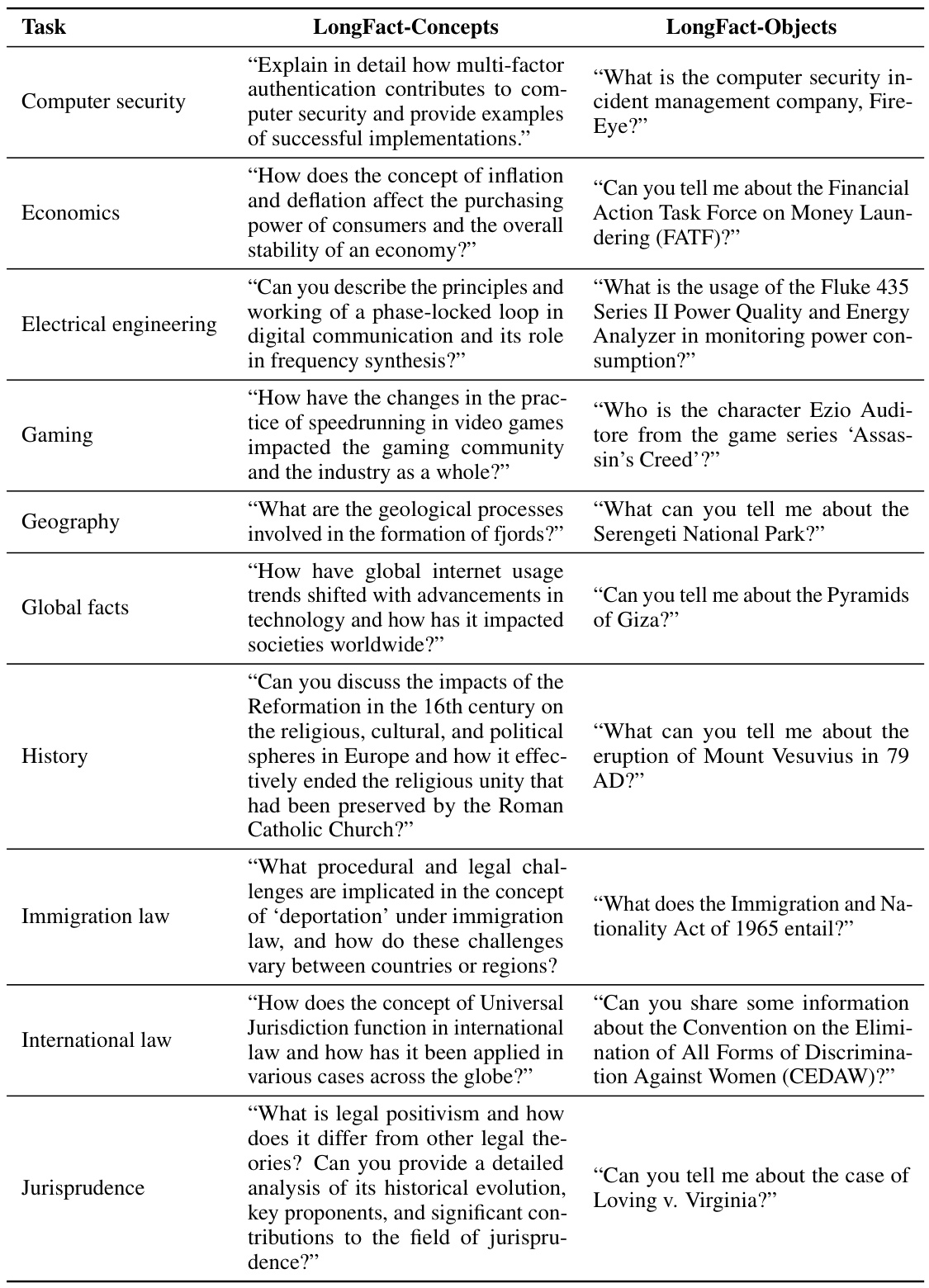
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects dataset. It shows both raw metrics (number of supported, not-supported, and irrelevant facts in model responses) and aggregated metrics (precision, recall at k=64 and k=178, and F1 scores at k=64 and k=178) to evaluate long-form factuality. The models are ranked by their performance on these metrics, highlighting the best-performing models for each metric.
In-depth insights#
LLM Fact Verification#
LLM fact verification is a crucial emerging area of research, addressing the challenge of large language models (LLMs) sometimes generating inaccurate or fabricated information. This involves developing methods to assess the truthfulness of LLM-generated statements. Existing approaches often rely on comparing LLM outputs to established knowledge bases or external sources, such as Wikipedia or web search results. However, this can be limited by the completeness and biases of these sources. A more sophisticated approach might involve multi-step reasoning and fact-checking using the LLM itself, or by combining LLMs with other tools such as search engines or knowledge graphs. The development of robust evaluation metrics is also critical, as the existing metrics may not capture the nuances of long-form factuality or complex reasoning. Furthermore, research must consider the potential biases and limitations of LLMs themselves, which can affect the accuracy and reliability of their fact-verification capabilities. Future research should focus on improving LLM reasoning skills, developing more comprehensive knowledge sources, and creating evaluation metrics that are better aligned with human judgment of factuality.
SAFE Evaluation#
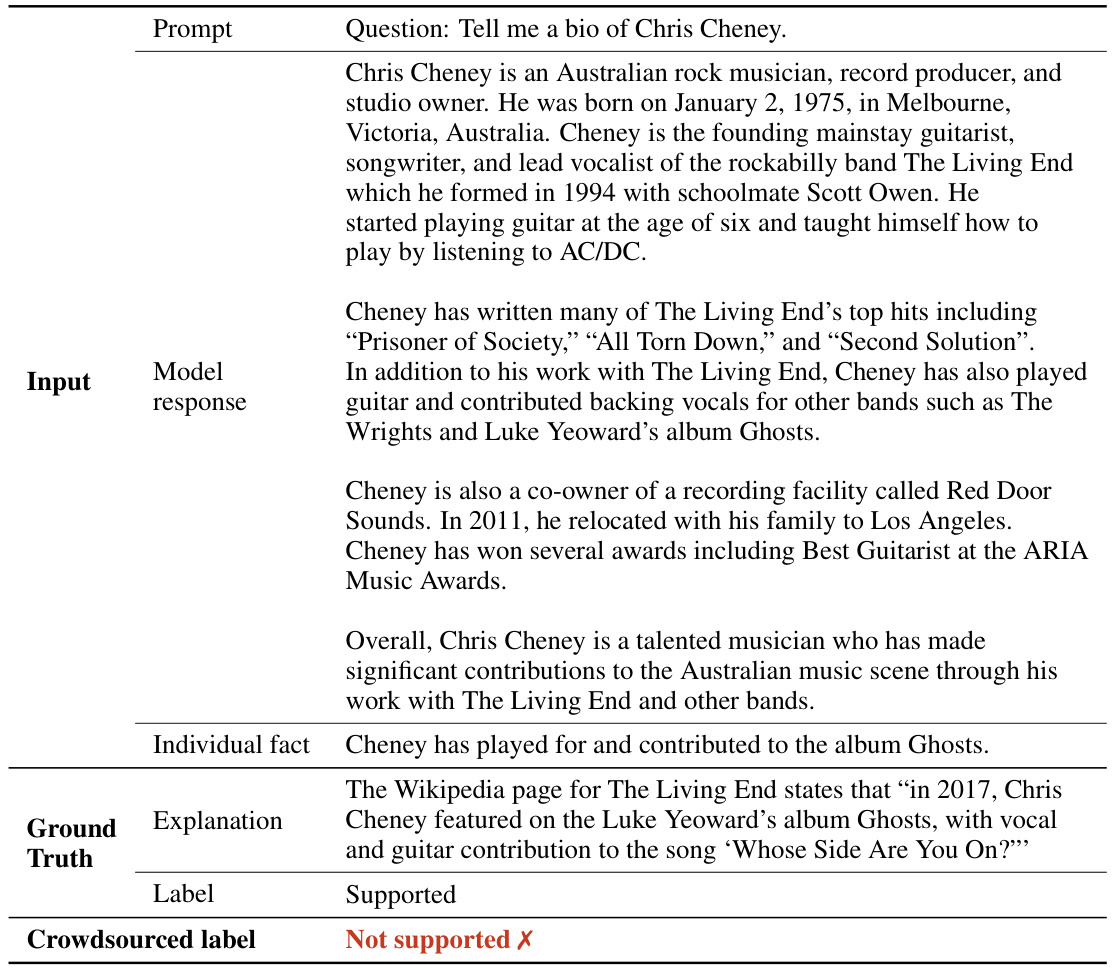
The paper introduces a novel automatic factuality evaluation method called SAFE (Search-Augmented Factuality Evaluator). SAFE leverages LLMs to break down long-form responses into individual factual claims, then utilizes search engines (like Google Search) to verify each claim’s accuracy. This multi-step process involves generating search queries, analyzing results, and ultimately rating each claim as ‘supported’, ’not supported’, or ‘irrelevant’. A key advantage of SAFE is its scalability and cost-effectiveness compared to human annotation. The paper demonstrates that SAFE achieves high agreement with human evaluators, significantly reducing evaluation expenses. While dependent on LLM capabilities and search engine reliability, SAFE offers a promising automated approach for assessing the factuality of lengthy text generated by LLMs, particularly in open-domain scenarios where comprehensive, pre-defined ground truth is unavailable. Further research could focus on improving LLM reasoning within SAFE and exploring alternative knowledge sources beyond search engines to address limitations.
Long-Form F1@K#
The proposed Long-Form F1@K metric offers a nuanced approach to evaluating long-form factuality by integrating both precision and recall. Precision, representing the ratio of supported facts to the total number of facts provided, assesses factual accuracy. Recall, however, is ingeniously adapted to capture the proportion of relevant facts covered, relative to a user-defined ideal length (K). This addresses a limitation of existing metrics by acknowledging that overly long responses, though potentially more comprehensive, may not be preferred by the user. The use of a hyperparameter K allows the metric to be flexible and adaptable across different contexts and user preferences, providing a more realistic assessment of model performance. Unlike methods that rely solely on precision or simple word overlap, Long-Form F1@K offers a sophisticated way to balance factual correctness with the comprehensiveness and desired length of responses. This makes it particularly well-suited to assessing the performance of large language models on open-ended, fact-seeking prompts, a domain where simply quantifying precision falls short of capturing the subtleties of what constitutes a truly “good” answer.
LLM > Human?#
The research explores whether Large Language Models (LLMs) surpass human capabilities in assessing long-form factuality. The study introduces SAFE, an automated evaluation method using LLMs to analyze factual accuracy in lengthy text, comparing its performance to human annotators. SAFE demonstrates comparable accuracy to humans at a significantly lower cost, suggesting LLMs as a potentially superior and scalable alternative. However, the research acknowledges limitations of both LLMs and SAFE, including reliance on Google Search’s accuracy and the potential for LLMs to generate flawed responses. The findings highlight the potential of LLMs for automated evaluation, but also emphasize the need for further research to address the current limitations and ensure reliability in complex factual assessments. The superiority of LLMs over humans in this context isn’t definitively proven; instead, the focus is on highlighting cost-effectiveness and potential for scalability.
Future of SAFE#
The future of SAFE (Search-Augmented Factuality Evaluator) hinges on several key improvements. Improving the LLM’s reasoning capabilities is crucial; a more sophisticated LLM could better handle complex queries and nuanced reasoning, reducing errors in determining fact relevance and accuracy. Expanding fact-checking beyond Google Search would enhance reliability, potentially integrating multiple sources and verifying information across diverse perspectives. Addressing the limitations of relying solely on readily available online information is vital; SAFE needs a mechanism to handle specialized domains or scenarios requiring access to restricted knowledge bases. Incorporating feedback mechanisms to continuously refine the model’s performance is essential, and this could involve active learning or human-in-the-loop techniques. Finally, developing more robust and nuanced metrics beyond F1@K would better capture the complexities of long-form factuality, perhaps incorporating metrics that account for the context and subtleties of human-preferred response lengths.
More visual insights#
More on figures
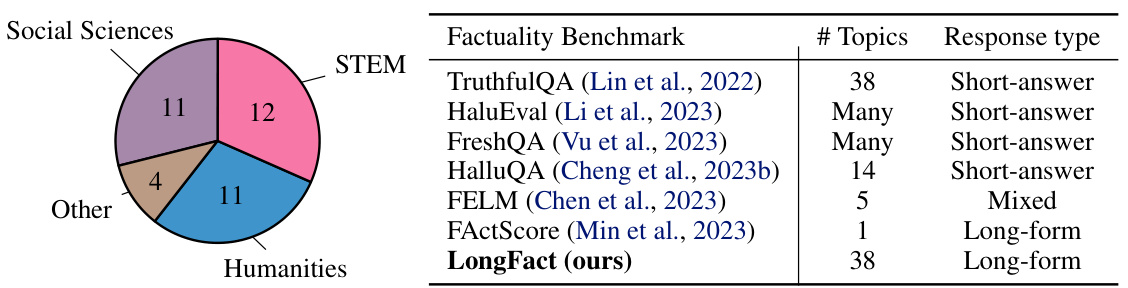
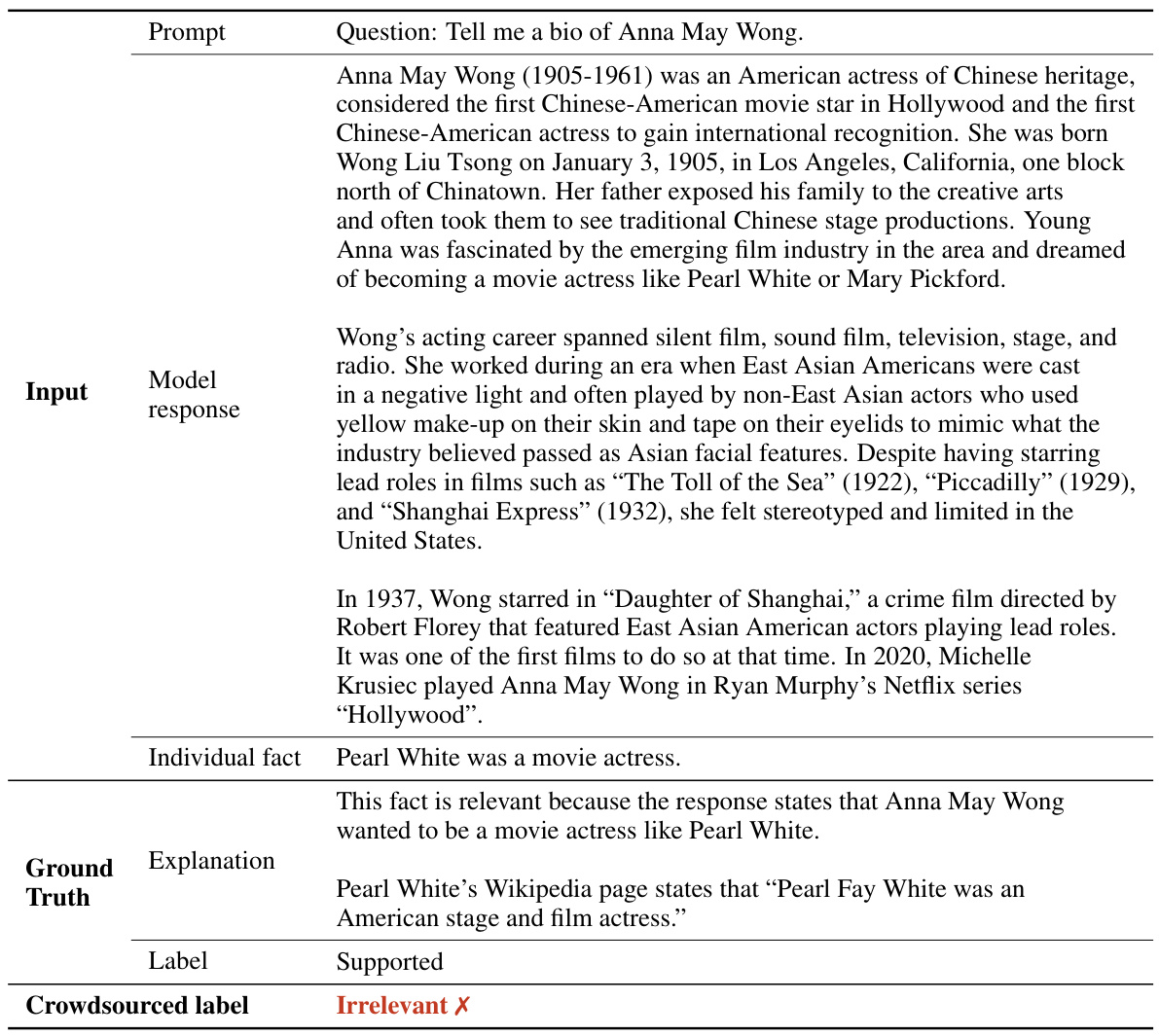
This figure demonstrates the composition and breadth of the LongFact dataset. The left panel shows a pie chart illustrating the distribution of 38 topics across four supercategories: Social Sciences, STEM, Humanities, and Other. The right panel is a table comparing LongFact with existing factuality benchmarks, highlighting its unique focus on long-form responses and diverse topic coverage, unlike datasets that primarily assess short-answer factuality or only cover a limited range of topics.
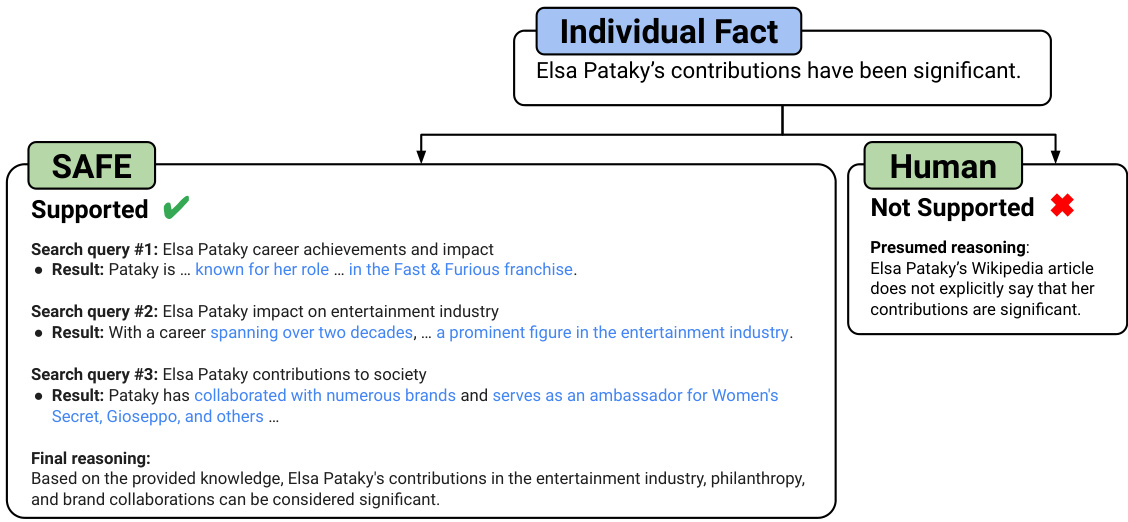
This figure illustrates the SAFE (Search-Augmented Factuality Evaluator) process. It shows how an LLM (large language model) acts as an agent to assess the factuality of individual claims within a long-form response. The process involves the LLM breaking down a response into individual facts, generating relevant search queries for each fact using Google Search, and then reasoning about whether the search results support or refute the facts. The figure provides a visual representation of this iterative process, showing the LLM’s reasoning steps and the final determination (supported or not supported).
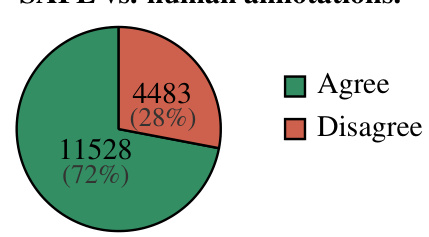
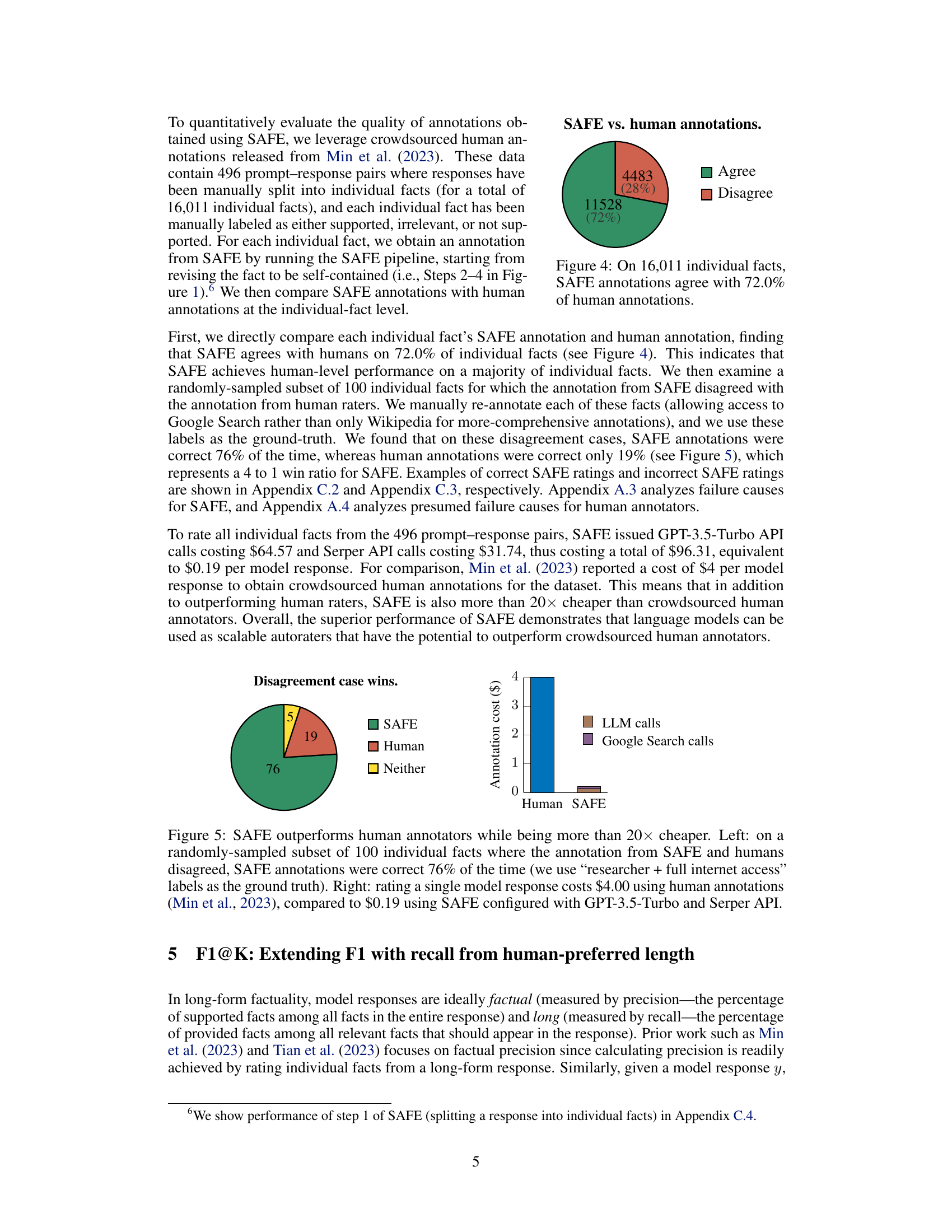
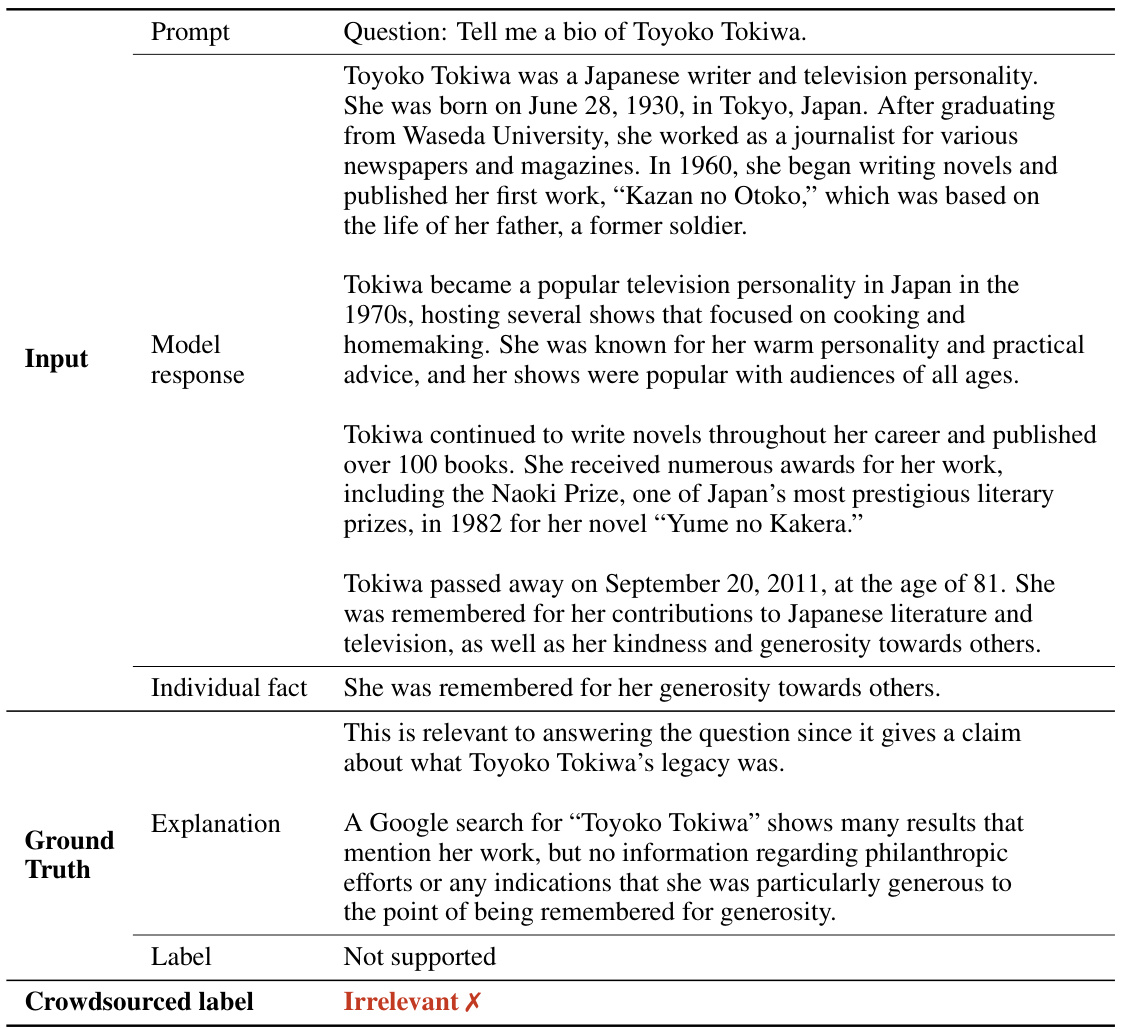
This figure shows the results of comparing SAFE’s annotations with human annotations on a dataset of 16,011 individual facts. The large majority (72%) of SAFE’s annotations agreed with the human annotations, demonstrating a high level of agreement between the automated method and human evaluation. The remaining 28% represent disagreements, indicating areas where further refinement of the SAFE method might be needed. This figure highlights the accuracy and effectiveness of SAFE in automating the factuality evaluation task.
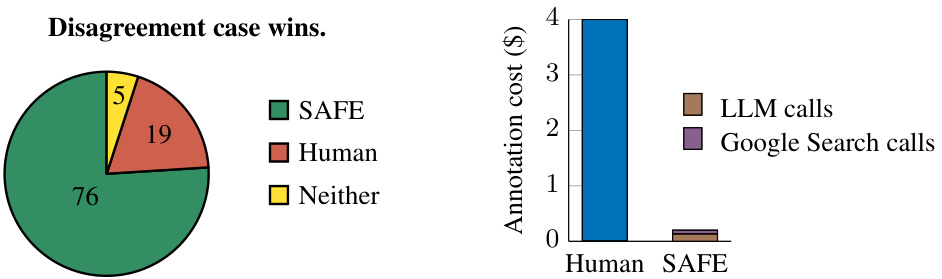
This figure demonstrates the superior performance of SAFE over human annotators. The left panel shows that in a subset of 100 cases where SAFE disagreed with human annotations, SAFE’s annotations were correct 76% of the time, in comparison to only 19% accuracy for human annotators. The right panel highlights the cost-effectiveness of SAFE, indicating that it is more than 20 times cheaper than human annotations.
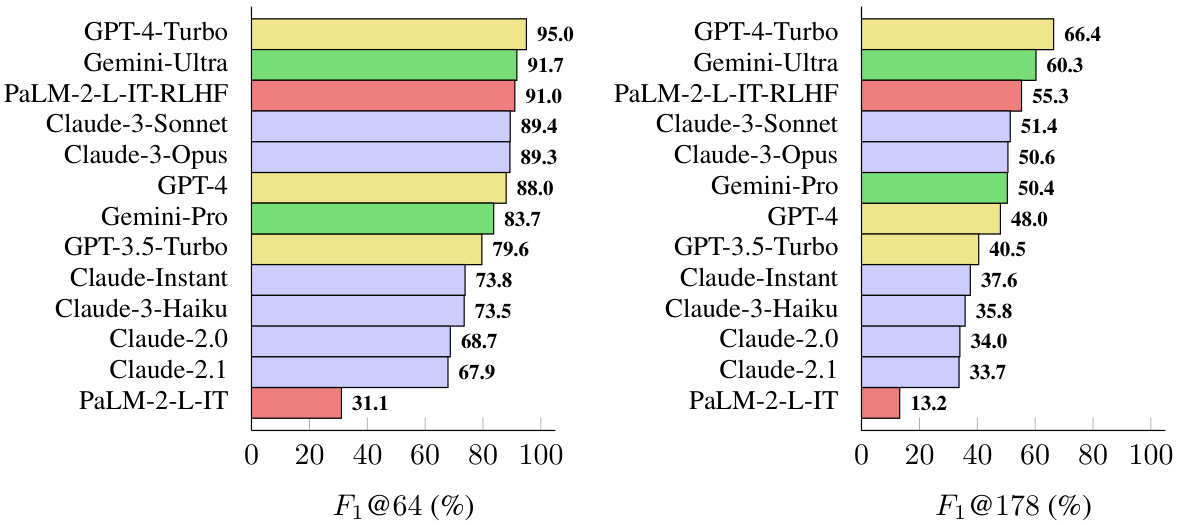
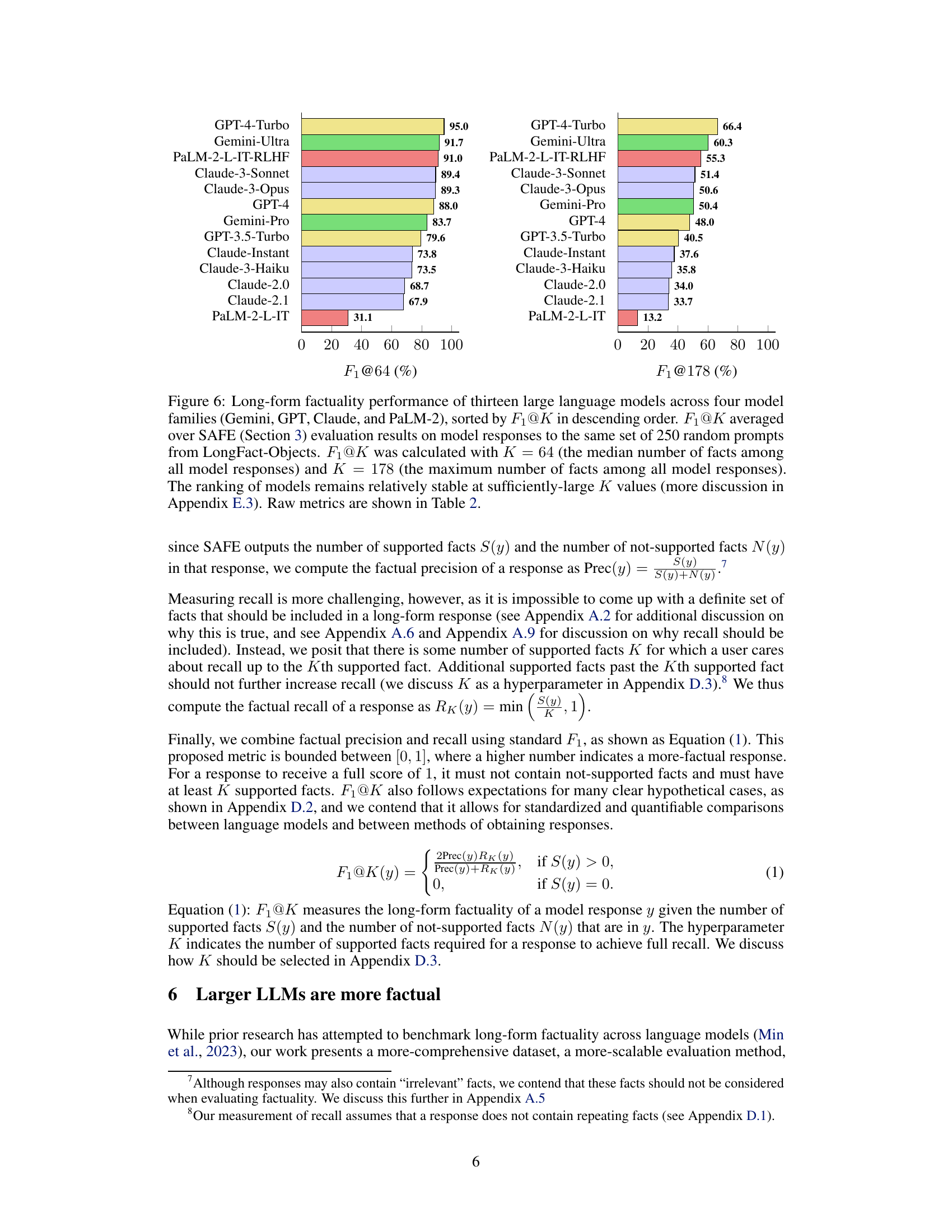
This figure presents a benchmark of thirteen large language models from four families (Gemini, GPT, Claude, and PaLM-2) on their long-form factuality performance. The models are ranked in descending order based on the F₁@K metric, calculated using two different values of K (64 and 178), representing the median and maximum number of facts across all model responses, respectively. The results are obtained using the Search-Augmented Factuality Evaluator (SAFE) method and show a general trend that larger language models tend to achieve better long-form factuality. The ranking stability at larger K values is further discussed in Appendix E.3.
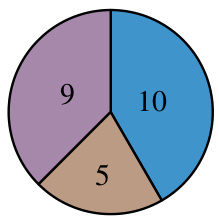
The figure is a pie chart that shows the percentage of errors in SAFE that are caused by three main factors: reasoning errors, Google Search failures, and revision errors. Reasoning errors account for the largest proportion of errors (50%), followed by Google Search failures (30%) and revision errors (20%).
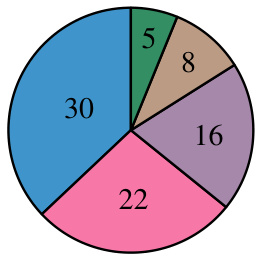
This figure shows the presumed causes of errors made by human annotators when evaluating the 100 disagreement cases in Section 4 of the paper. The causes are categorized as follows: Label confusion (5), Information not given (8), Information missed (30), Misread response (16), and Technicality/reasoning (22). The largest source of error appears to stem from the annotators either misreading the responses or missing information contained in them. It also shows that a significant portion of annotation errors were caused by annotators confusing the labels themselves.
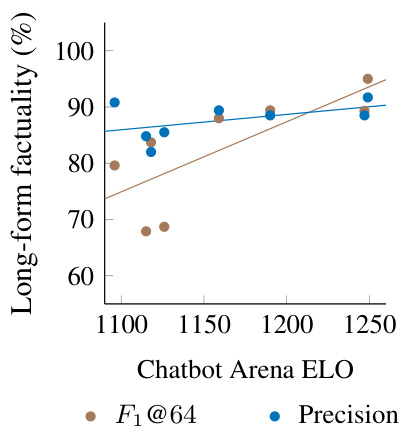
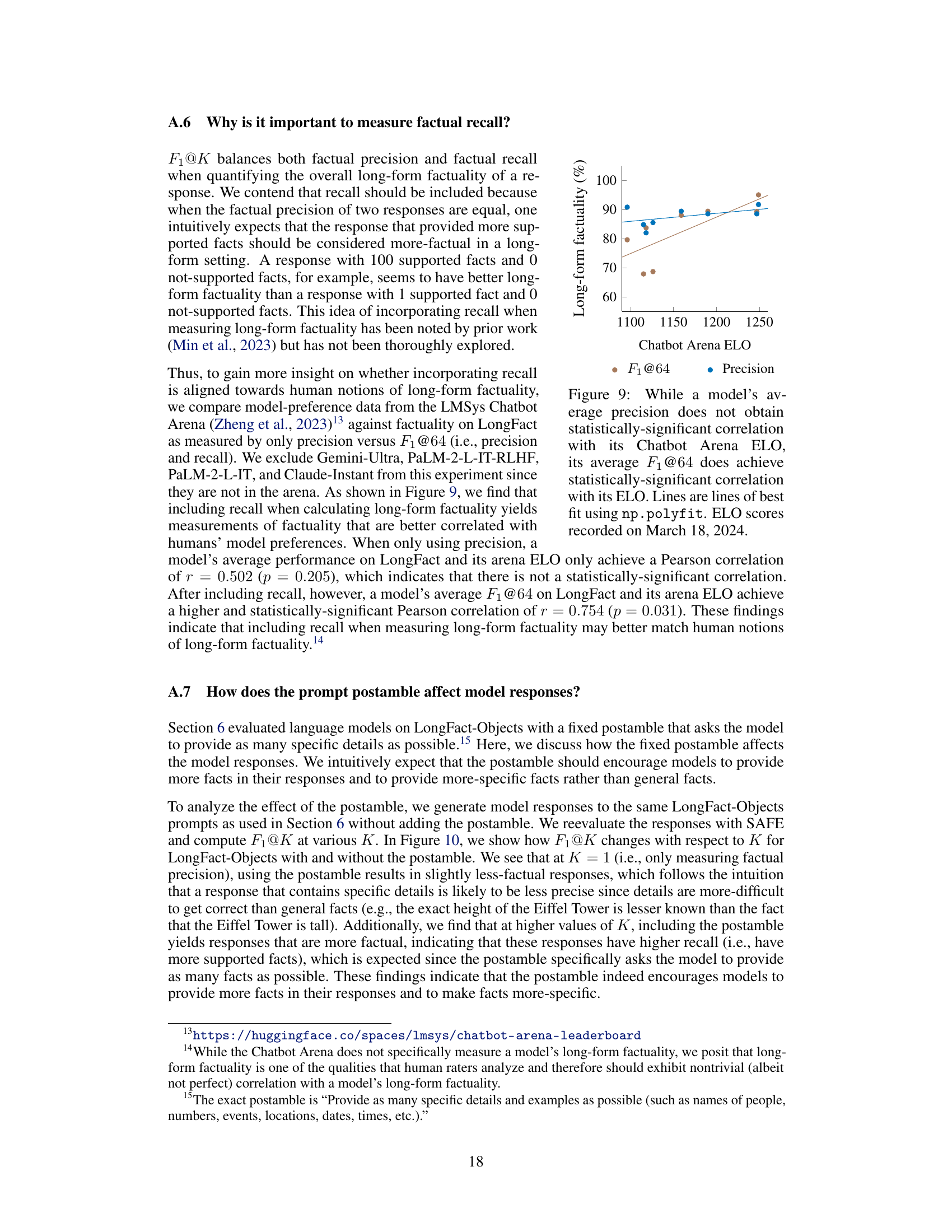
This figure shows the correlation between a model’s performance on the LongFact benchmark and its ELO rating in the LMSys Chatbot Arena. The blue dots represent the correlation between precision (the percentage of supported facts in a response) and ELO, while the brown dots represent the correlation between F1@64 (a metric that combines precision and recall, considering human-preferred response length) and ELO. The figure demonstrates that F1@64, which includes recall, has a stronger, statistically significant correlation with human evaluation (as measured by ELO) than precision alone, suggesting that incorporating recall in evaluating long-form factuality better aligns with human judgment.
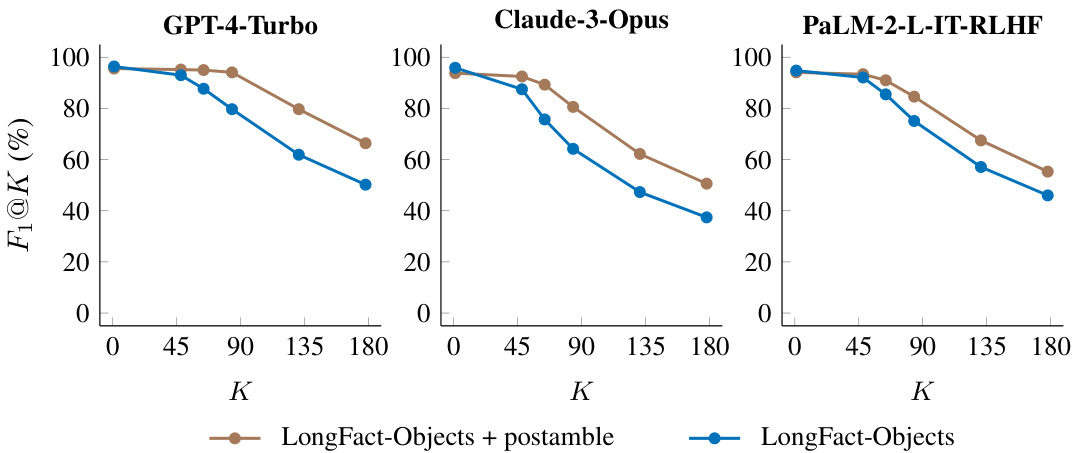
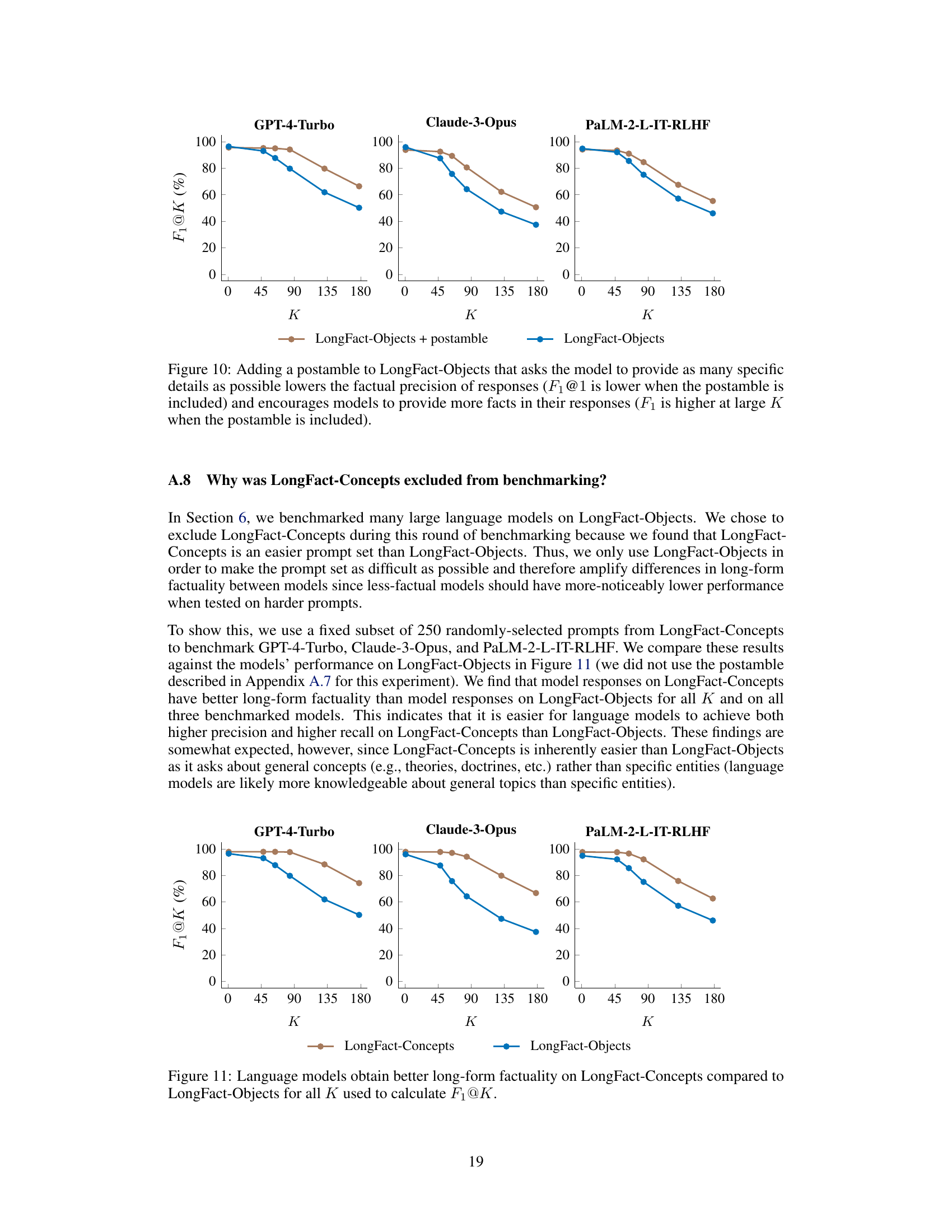
This figure shows the impact of adding a postamble to the LongFact-Objects prompts on the performance of language models. The postamble instructed models to provide more detailed responses. The results indicate that while the factual precision (accuracy of individual facts) decreased slightly, adding the postamble significantly increased the recall (number of supported facts retrieved) at larger values of K (the number of facts considered for recall). This demonstrates a trade-off between precision and recall when more facts are solicited from models. In simpler terms, when models were asked for longer, more detailed answers, they provided more total facts, but had a slightly lower accuracy on the facts given.
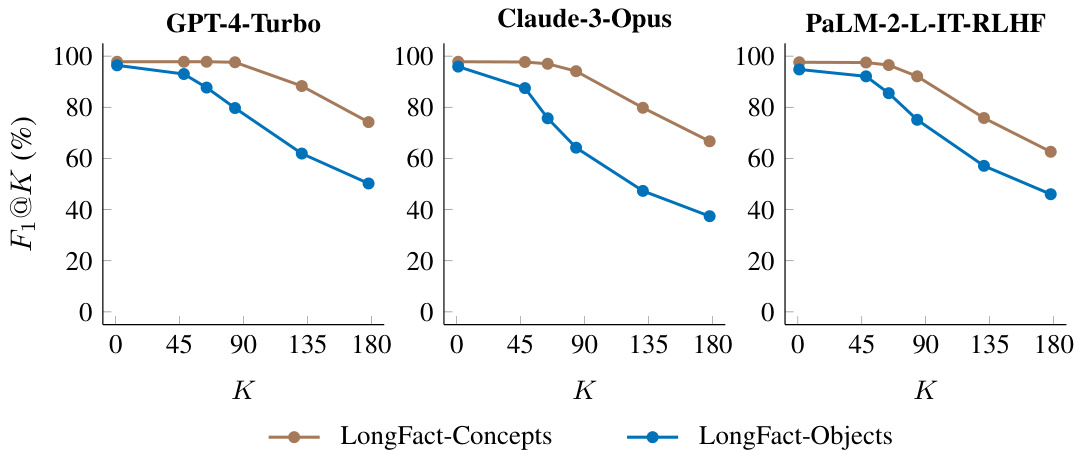
This figure shows the impact of adding a postamble to the LongFact-Objects prompts on the performance of language models. The postamble instructs the model to provide as many specific details as possible. The results show that adding the postamble slightly reduces precision (accuracy of individual facts) at K=1 (measuring only precision). However, at higher values of K, the postamble improves the F1 score (harmonic mean of precision and recall), indicating an increase in recall (proportion of relevant facts retrieved). This suggests that the postamble, while slightly reducing accuracy for concise answers, encourages models to generate longer responses with more factual information.

The figure illustrates the SAFE (Search-Augmented Factuality Evaluator) process. SAFE uses an LLM to break down a long-form response into individual facts. It then checks the relevance of each fact and assesses its accuracy using Google Search. The evaluation results demonstrate that SAFE is both more accurate and significantly cheaper than using human annotators for this task.

The figure illustrates the SAFE (Search-Augmented Factuality Evaluator) process. SAFE uses an LLM to break down a long-form response into individual facts. It then uses the LLM to formulate search queries for each fact, using Google Search to determine if the fact is supported by the search results. The figure shows an example of a prompt and response being processed by SAFE, along with the individual facts extracted, Google Search queries generated, and the final output indicating the number of supported and unsupported facts.
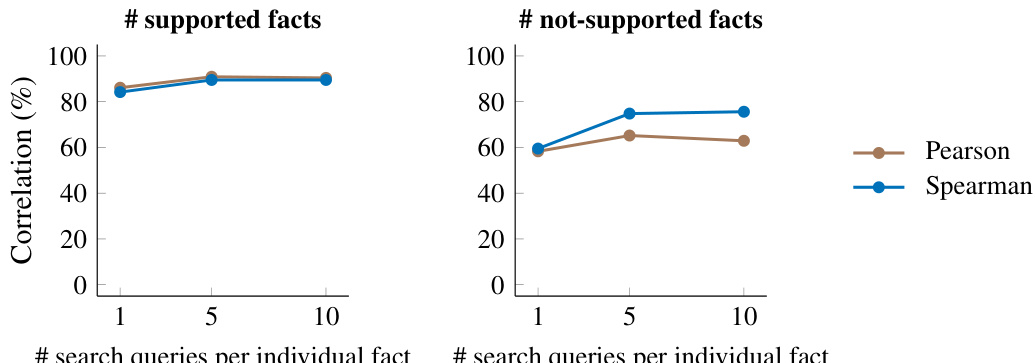
This figure shows the correlation between the number of search queries used in SAFE and the number of supported and not-supported facts. The results indicate that using at least five search queries yields the best correlation with human annotations, while increasing the number of queries beyond five does not lead to significant improvement.
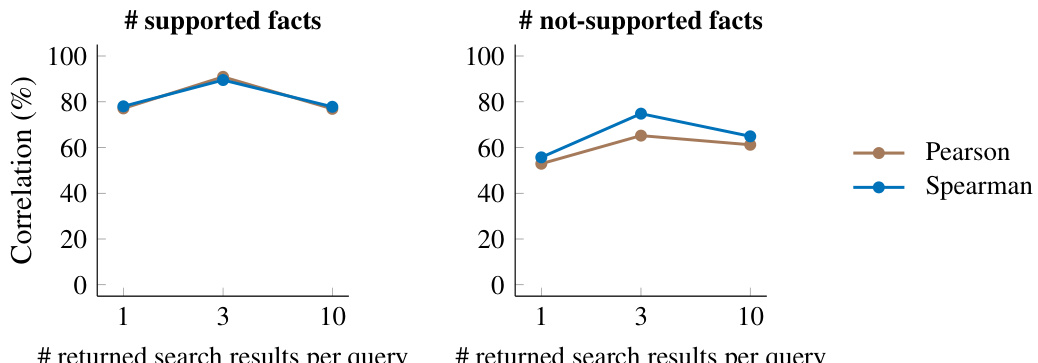
This figure displays the correlation between the number of search queries used in the SAFE model and the accuracy of the model’s annotations. The results indicate that using at least five search queries yields the highest correlation with human annotations, and increasing the number of queries beyond five does not significantly improve the model’s accuracy. The focus is primarily on supported and not-supported facts since Appendix A.4 revealed that human annotators frequently mislabeled these facts as irrelevant. All tests kept the number of returned search results per query constant at 3.
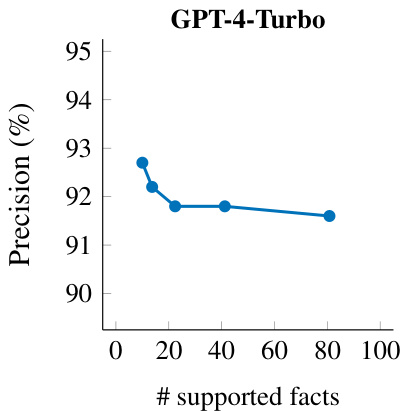
This figure shows the relationship between the number of supported facts and precision for GPT-4-Turbo’s responses to long-form factuality prompts. The x-axis represents the number of supported facts in a response, and the y-axis represents the precision (percentage of supported facts out of all facts). The plot shows that as the number of supported facts increases, the precision tends to slightly decrease. This indicates a trade-off between recall (number of supported facts) and precision (accuracy of facts) when generating longer responses. Longer responses, while having higher recall, may sacrifice a bit of precision.

The figure shows a bar chart comparing the factual precision of different Claude language models on the LongFact-Objects dataset. It demonstrates that the newer Claude-3 models (Claude-3-Haiku, Claude-3-Sonnet, and Claude-3-Opus) significantly outperform earlier generations (Claude-Instant, Claude-2.0, and Claude-2.1) in terms of factual precision. This suggests that improvements in model architecture or training techniques have led to better factual accuracy in the newer models.
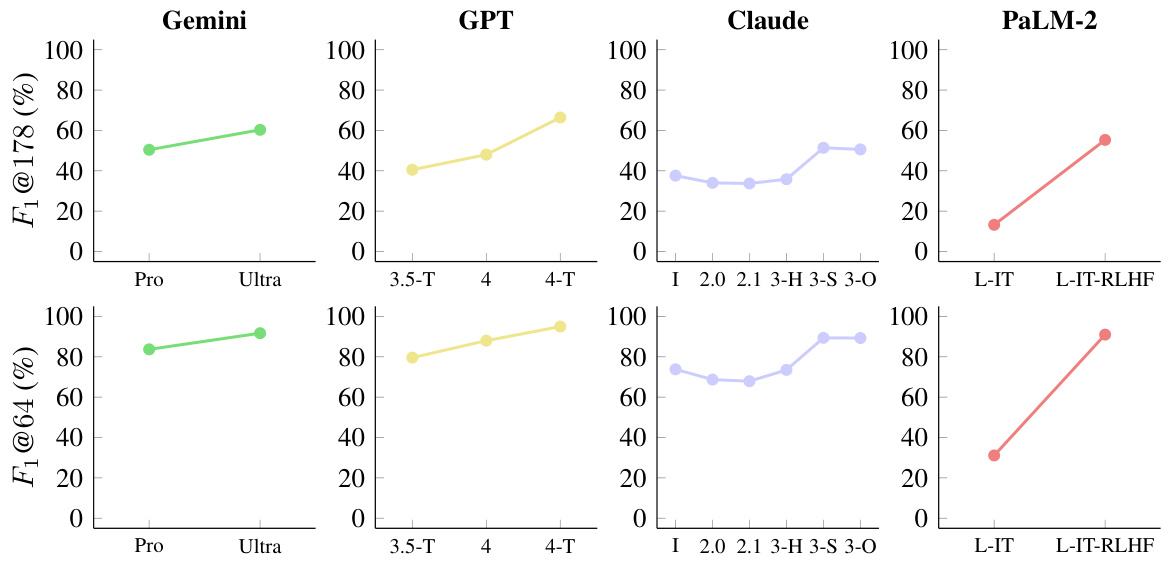
This figure presents the long-form factuality performance of 13 large language models from 4 different families (Gemini, GPT, Claude, and PaLM-2). The models are ranked in descending order based on their F1@K score, a metric that combines precision and recall of factual information in long-form responses. Two different values of K (64 and 178) are used, representing the median and maximum number of facts in the responses, respectively. The chart visually demonstrates how the larger models generally achieve better long-form factuality, although some newer models from different families (like Claude-3) match or even surpass the performance of GPT-4.
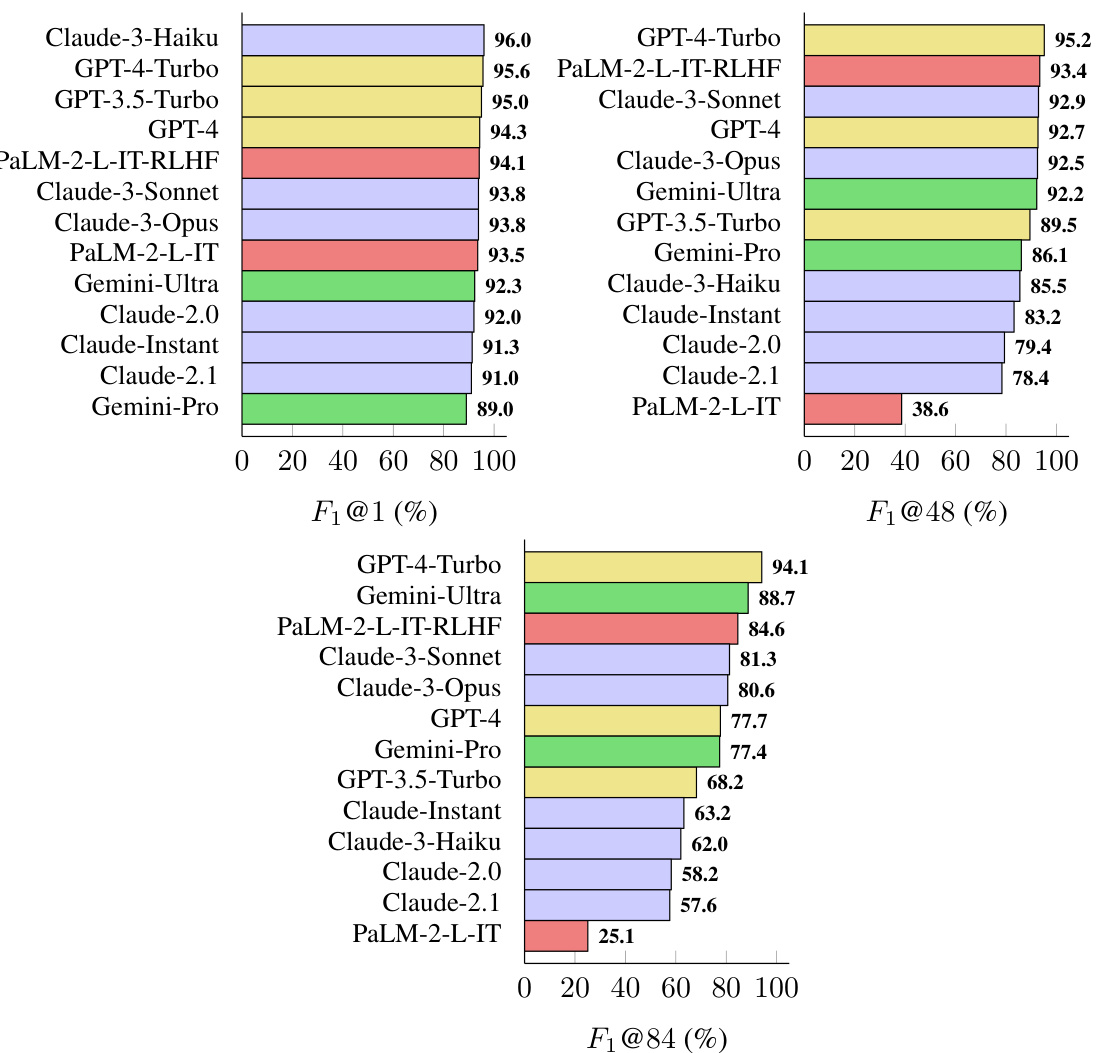
This figure presents the results of a benchmark evaluating thirteen large language models’ performance on long-form factuality using two different metrics (F₁@64 and F₁@178). The models are categorized into four families (Gemini, GPT, Claude, and PaLM-2). The F₁ score is a combined measure of precision (percentage of supported facts) and recall (percentage of provided facts relative to a user-preferred length), calculated using the SAFE evaluation method. The figure shows that larger language models generally perform better, though the relationships between model families and their performance are complex. The stability of model rankings at higher K values suggests the results are relatively robust to variations in human-preferred response length.

This figure shows the performance comparison of two PaLM-2 language models, one with RLHF (Reinforcement Learning from Human Feedback) and one without. The x-axis represents the value of K, which is a hyperparameter determining the number of supported facts required for full recall in the F₁@K metric. The y-axis shows the F₁@K score (a metric combining precision and recall). The results show that the RLHF model consistently outperforms the non-RLHF model across all K values. The difference in performance is more pronounced for larger values of K, suggesting that RLHF improves the model’s ability to generate responses with more factual information (higher recall).
More on tables
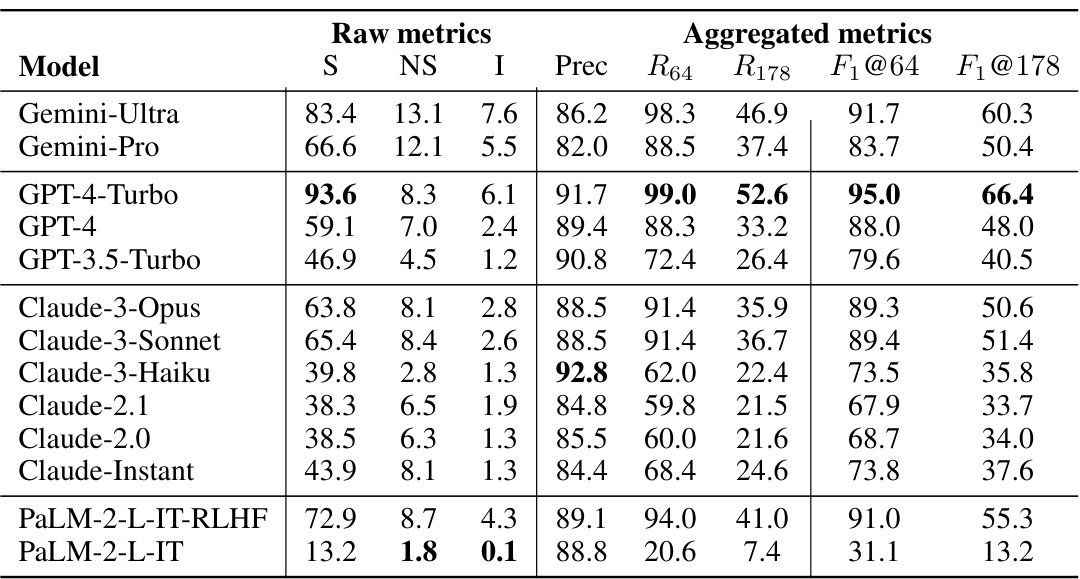
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of LongFact-Objects prompts. The raw metrics (S, NS, I) represent the number of supported, not-supported and irrelevant facts found by SAFE in the model’s responses. Aggregated metrics include precision, recall at K=64 (median number of facts) and K=178 (maximum number of facts), and the F1 score calculated at both K values. The best performing models for each metric are highlighted in bold.

This table presents the results of benchmarking thirteen large language models on a subset of LongFact-Objects prompts. It shows the performance of each model in terms of raw metrics (number of supported, not-supported and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 score at K=64 and K=178). The raw metrics are obtained using the Search-Augmented Factuality Evaluator (SAFE) method described in the paper. K represents the median and maximum number of facts found in human-preferred responses, respectively. The bold numbers highlight the best performing models for each metric.

This table presents the results of benchmarking thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. The models’ responses were evaluated using the Search-Augmented Factuality Evaluator (SAFE). The table shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1 scores at K=64 and K=178, where K represents the human-preferred number of facts). The F1 score combines precision and recall to give an overall measure of factuality, and the bold numbers highlight the best performance for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. For each model, it shows raw metrics (number of supported, not-supported, and irrelevant facts) calculated using the SAFE evaluation method, along with aggregated metrics such as precision, recall at two different recall thresholds (K=64 and K=178), and the F1 score (combining precision and recall) at those thresholds. The bold numbers highlight the best performance for each metric, offering a direct comparison of models based on their long-form factuality performance.
This table presents a comprehensive benchmark of thirteen large language models across four families (Gemini, GPT, Claude, and PaLM-2) on a subset of prompts from the LongFact-Objects dataset. It shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1@K for K=64 and K=178) derived from the SAFE evaluation method. The F1@K score balances precision and recall, considering both the factual accuracy and the length of the response. The table helps assess the long-form factuality performance of various models, indicating which achieve better precision, recall, or an overall F1 score.
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects dataset. It shows the raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1 scores at K=64 and K=178) calculated using the SAFE evaluation method. The F1 score balances the precision (accuracy of the facts) and recall (completeness of the factual information provided, considering a human-preferred length) of the model’s responses. The bold numbers indicate the best performance for each metric.
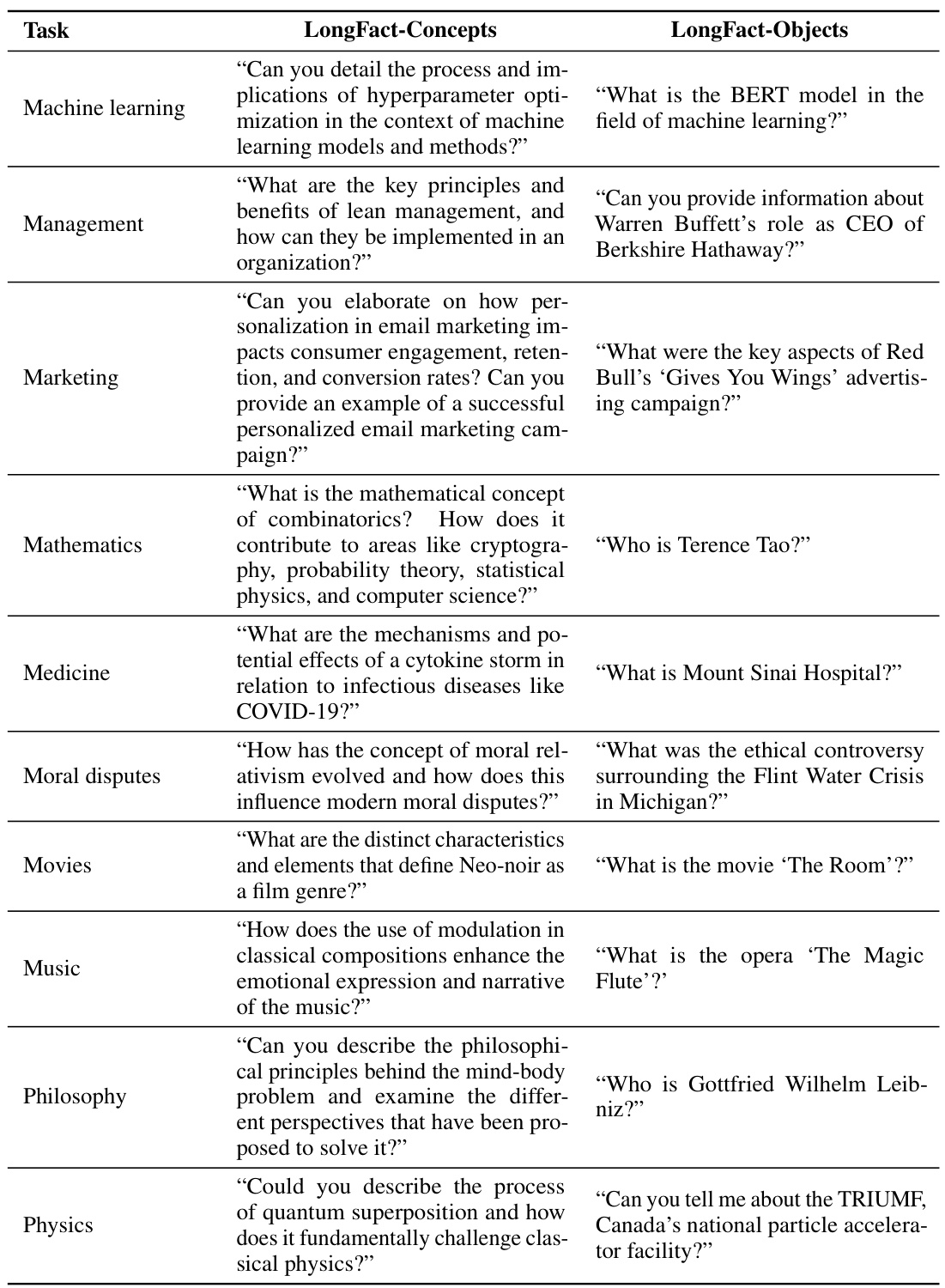
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. It provides both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 scores at K=64 and K=178) for each model’s performance. The bold numbers highlight the best performance for each metric across all models.
This table presents the results of benchmarking thirteen large language models on a subset of LongFact-Objects prompts. The models are evaluated using the SAFE method, and the results are aggregated using different metrics. The table displays both the raw metrics and the aggregated metrics, showing performance in terms of supported, not-supported, and irrelevant facts for each model. The best-performing model for each metric is highlighted.

This table presents a comprehensive evaluation of thirteen large language models across four families (Gemini, GPT, Claude, and PaLM-2) using the LongFact-Objects dataset. It shows both raw metrics (number of supported, not-supported, and irrelevant facts in model responses) and aggregated metrics (precision, recall at K=64 and K=178, and F1 scores at K=64 and K=178). The raw metrics provide a detailed breakdown of the model’s factual accuracy, while the aggregated metrics offer a summarized view of the overall long-form factuality performance. Bold numbers highlight the best performance for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. For each model and each prompt, the evaluation metrics from SAFE (Search-Augmented Factuality Evaluator) are calculated. Raw metrics include the number of supported facts (S), not-supported facts (NS), and irrelevant facts (I). Aggregated metrics show precision (Prec), recall at K=64 (R64) and K=178 (R178), and the F1 score at K=64 (F1@64) and K=178 (F1@178). The F1 score, incorporating both precision and recall, measures the long-form factuality, and different K values represent different lengths of ideal responses. The bold numbers highlight the best performance for each metric.

This table presents a comprehensive evaluation of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects benchmark. It shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1 scores at two different recall thresholds (K=64 and K=178)). The F1 score incorporates both precision and recall to provide a more holistic measure of long-form factuality. Bold numbers highlight the best-performing model for each metric.
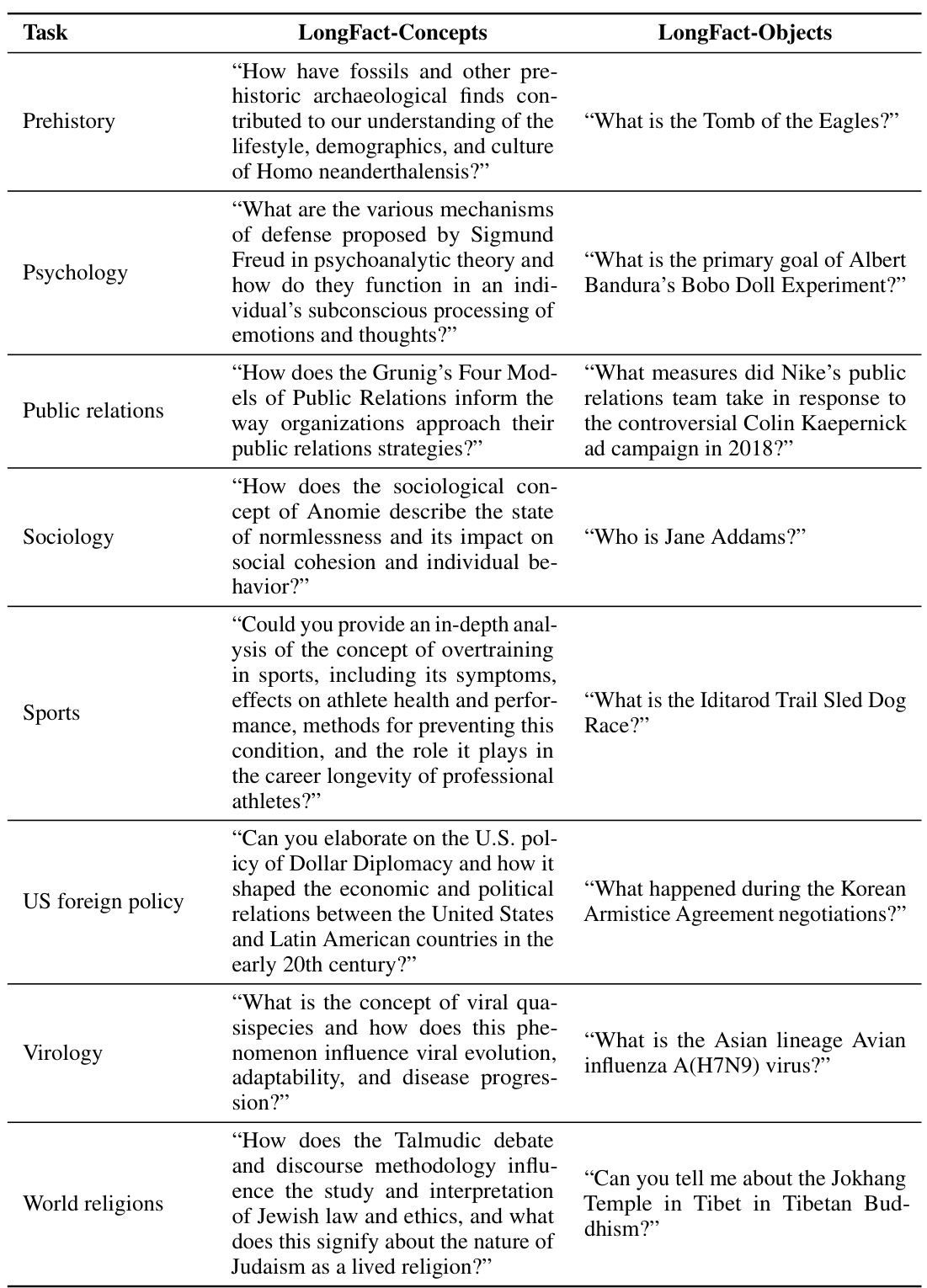
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of LongFact-Objects prompts. It shows raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1@K, calculated at K=64 and K=178, representing median and maximum number of facts respectively). The F1@K score balances precision and recall in evaluating long-form factuality, combining accuracy and completeness of information provided. Bold values highlight the best performance for each metric across all models.

This table presents a comprehensive evaluation of thirteen large language models across four families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects benchmark. It shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 score at K=64 and K=178). The raw metrics reflect the individual fact-level assessments from the SAFE evaluation method. Aggregated metrics provide a holistic view of the models’ performance considering both the accuracy (precision) and completeness (recall) of their long-form responses. The bolded numbers highlight the top performers for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. For each model, it shows raw metrics (number of supported, not-supported, and irrelevant facts) obtained using the SAFE evaluation method. It further provides aggregated metrics, including precision, recall at different response lengths (K=64 and K=178), and the F1 score (F1@K), reflecting the balance between precision and recall. The bold numbers highlight the best performance across each metric.
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from LongFact-Objects. It details raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F1@K at K=64 and K=178). The F1@K score combines precision and recall, incorporating a user’s preferred response length. Bold numbers highlight the best performance for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects dataset. It shows the raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 score at K=64 and K=178) for each model’s performance on 250 randomly selected prompts. The bold numbers indicate the best performance for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of LongFact-Objects prompts. It shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 score at K=64 and K=178) for each model’s performance. The bold numbers highlight the top performers for each metric.
This table presents a comprehensive benchmark of thirteen large language models across four families (Gemini, GPT, Claude, and PaLM-2) on a subset of LongFact-Objects prompts. It shows both raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall, and F₁@K, calculated at median and maximum numbers of facts). The F₁@K score combines precision and recall, considering the number of supported facts relative to a chosen threshold (K). The results indicate the long-form factuality performance of each model. Bold numbers highlight the best performance for each metric.
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from LongFact-Objects. For each model and prompt, it shows raw metrics (number of supported, not-supported, and irrelevant facts), and aggregated metrics (precision, recall at K=64 and K=178, and F1-score at K=64 and K=178). The metrics are averaged over all prompts, allowing for a comparison of model performance in terms of factual accuracy and completeness of responses. Bold numbers highlight the best performance for each metric.

This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects dataset. It shows the performance of each model in terms of raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics (precision, recall at K=64 and K=178, and F1 scores at K=64 and K=178). The raw metrics are obtained using the Search-Augmented Factuality Evaluator (SAFE) method. The table helps to compare the long-form factuality performance of different models and model families.
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on the LongFact-Objects dataset. For each model, it shows raw metrics (number of supported, not-supported, and irrelevant facts), and aggregated metrics (precision, recall at K=64 and K=178, and F1 scores at K=64 and K=178). The F1 scores combine precision and recall to provide a holistic measure of long-form factuality. Bold numbers highlight the best performance for each metric.
This table presents a comprehensive benchmark of thirteen large language models across four families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. The evaluation uses the Search-Augmented Factuality Evaluator (SAFE) method described in the paper. For each model, the table shows raw metrics (number of supported, not-supported, and irrelevant facts) and aggregated metrics calculated using the F1@K metric (precision, recall at K=64 and K=178). The F1@K metric balances precision and recall by considering human preferred response length (K). The best performing model for each metric is highlighted in bold.
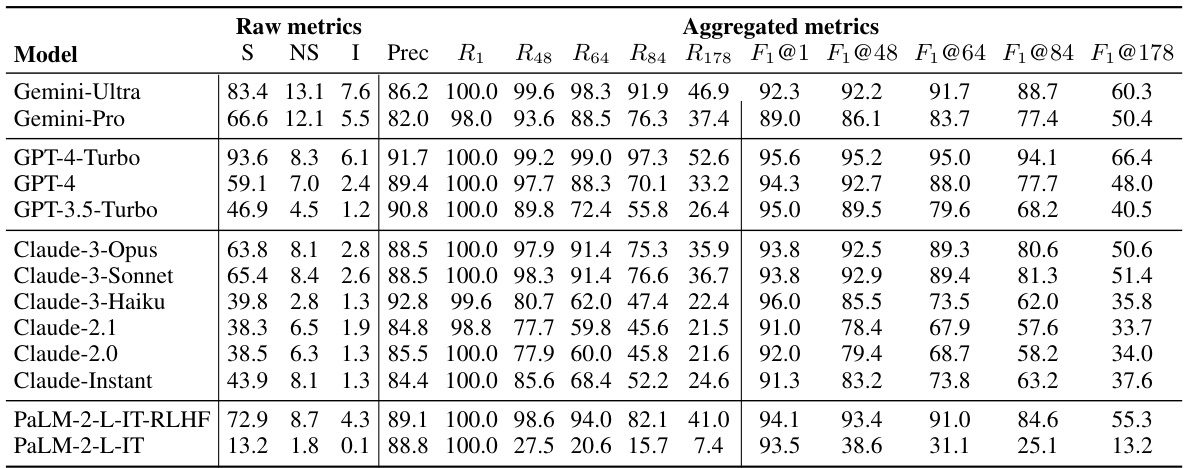
This table presents a comprehensive benchmark of thirteen large language models across four model families (Gemini, GPT, Claude, and PaLM-2) on a subset of 250 prompts from the LongFact-Objects dataset. For each model and prompt, it shows raw metrics (number of supported facts (S), not-supported facts (NS), and irrelevant facts (I)), and aggregated metrics (precision (Prec), recall at K=64 (R64) and K=178 (R178), and F1 score at K=64 and K=178 (F1@64, F1@178)). The K values (64 and 178) represent the median and maximum number of facts across all model responses, respectively. The bold numbers highlight the best performance for each metric.
Full paper#