↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-agent reinforcement learning (MARL) often suffers from reduced network expressivity due to the increasing number of inactive neurons, a phenomenon known as “dormant neurons.” This negatively impacts the learning process and overall performance. Existing methods to address this problem using parameter perturbation are ineffective in MARL because they do not consider the learned cooperation knowledge and may lead to forgetting learned knowledge.
The paper introduces ReBorn, a simple yet effective solution. ReBorn periodically identifies dormant and over-active neurons, transferring weights from the latter to the former. This process ensures that the cooperative knowledge remains intact even after weight adjustments. Extensive experiments demonstrate that ReBorn significantly improves the performance of popular MARL value factorization approaches, reducing the number of dormant neurons and enhancing overall learning efficiency. The theoretical analysis of the Knowledge Invariant principle provides a strong foundation for ReBorn’s effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of reduced network expressivity in multi-agent reinforcement learning, a significant hurdle in developing advanced AI systems. By introducing ReBorn and the Knowledge Invariant principle, it offers a practical and theoretically grounded solution, paving the way for more efficient and robust multi-agent systems. Its findings are directly relevant to current research on improving the scalability and generalization capabilities of MARL algorithms, opening new avenues for investigating network expressivity issues and parameter optimization techniques.
Visual Insights#

This figure shows the percentage of dormant neurons in both agent networks and mixing networks across three different SMAC scenarios (3s_vs_5z, MMM2, and 27m_vs_30m) while training with QMIX and QPLEX algorithms. It visually demonstrates the increase in dormant neurons over training steps, especially within the mixing networks, highlighting the dormant neuron phenomenon in MARL value factorization. The x-axis represents the number of environmental steps (training iterations), and the y-axis shows the percentage of dormant neurons.

This table lists four popular value factorization algorithms used as baselines in the paper’s experiments. It includes QMIX, which learns a mixer of individual utilities with monotonic constraints; QPLEX, which learns a mixer of advantage functions and state value functions; DMIX, which integrates distributional reinforcement learning with QMIX; and RMIX, which integrates risk-sensitive reinforcement learning with QMIX. These algorithms are compared against the proposed ReBorn method to demonstrate its effectiveness in improving performance.
In-depth insights#
Dormant Neuron Issue#
The phenomenon of dormant neurons, where many neurons in a neural network remain largely inactive during training, significantly impacts the performance of multi-agent reinforcement learning (MARL). This inactivity reduces network expressivity, hindering the learning process and impacting the ability of the network to effectively learn cooperative strategies. This issue is particularly pronounced in the mixing networks of value factorization methods, where the combination of individual agent utilities into a joint value function is crucial. The dormant neuron issue correlates with the presence of over-active neurons, which dominate the network’s activation. The presence of both dormant and over-active neurons suggests an imbalance in the weight distribution and potentially a suboptimal learning landscape. Addressing the dormant neuron problem necessitates methods that effectively redistribute weights from over-active to dormant neurons while preserving learned cooperative knowledge. Strategies that randomly reset or reinitialize weights can be harmful as they risk discarding valuable learned information. A more sophisticated approach is needed, one that intelligently balances the network activity and ensures continued efficient learning.
ReBorn: Weight Sharing#
The proposed ReBorn method tackles the dormant neuron phenomenon in multi-agent reinforcement learning (MARL) by implementing a weight-sharing mechanism. It cleverly addresses the reduced network expressivity caused by inactive neurons by transferring weights from over-active neurons to dormant ones. This approach is theoretically grounded, satisfying the Knowledge Invariant (KI) principle which ensures that learned cooperative action preferences remain unchanged. ReBorn’s simplicity and effectiveness are highlighted, showing promising results across various MARL value factorization approaches. The method’s impact on improving overall performance by preventing knowledge loss is a significant contribution. The KI principle itself serves as a valuable theoretical framework for developing future parameter perturbation methods in MARL. Further research could explore adaptive thresholding and more sophisticated weight transfer strategies to further refine and enhance ReBorn’s capabilities.
MARL Expressivity#
Multi-agent reinforcement learning (MARL) expressivity, concerning the capacity of MARL networks to represent complex value functions, is crucial for effective learning and decision-making. Insufficient expressivity often leads to suboptimal policies due to the network’s inability to capture the nuances of multi-agent interactions. Dormant neurons, a phenomenon where many neurons remain inactive during training, severely compromise expressivity. The presence of over-active neurons, whose activation scores are disproportionately large, further exacerbates the issue. These phenomena impede the network’s ability to learn effective action preferences, leading to slow or ineffective learning. Effective strategies for enhancing expressivity in MARL must address the dormant and over-active neuron problems, potentially involving weight-transferring mechanisms between them, thereby improving the overall performance of value factorization approaches used in cooperative MARL. The theoretical understanding of how expressivity affects performance and the exploration of parameter-perturbation methods that maintain knowledge invariance are vital for enhancing MARL’s capacity to tackle complex tasks.
Knowledge Invariance#
The concept of “Knowledge Invariance” in multi-agent reinforcement learning (MARL) centers on preserving learned cooperative behaviors even after network parameter adjustments. Existing MARL methods often fail to maintain learned knowledge when using parameter perturbation techniques (like weight resets), disrupting established inter-agent coordination and hindering overall performance. The principle emphasizes the need for algorithms to ensure that previously learned action preferences are not forgotten after such perturbations. This is critical in cooperative settings, where agents must retain and utilize past experience to maintain effective teamwork. The Knowledge Invariance principle provides a crucial benchmark for evaluating MARL algorithm robustness and avoiding catastrophic forgetting. Successful methods must ensure that learned knowledge is not lost, even with significant changes to neural network weights, highlighting the importance of sophisticated perturbation strategies that carefully preserve key information about learned cooperative actions.
Future Research#
Future research directions stemming from this dormant neuron phenomenon study in multi-agent reinforcement learning could explore several promising avenues. Developing adaptive methods for identifying dormant and overactive neurons is crucial, moving beyond simple activation thresholds to incorporate gradient information and weight dynamics for more robust detection. Investigating the interplay between network architecture and dormant neuron emergence is vital, potentially leading to designs that inherently mitigate this issue. Expanding the research to continuous action spaces and different MARL algorithm classes would further establish the generalizability of the findings. Furthermore, developing a theoretical framework that comprehensively captures the dynamics of dormant and overactive neurons and their impact on network expressivity will be highly valuable. Finally, rigorous investigation into the connection between dormant neurons and the generalization performance of MARL agents warrants further study.
More visual insights#
More on figures
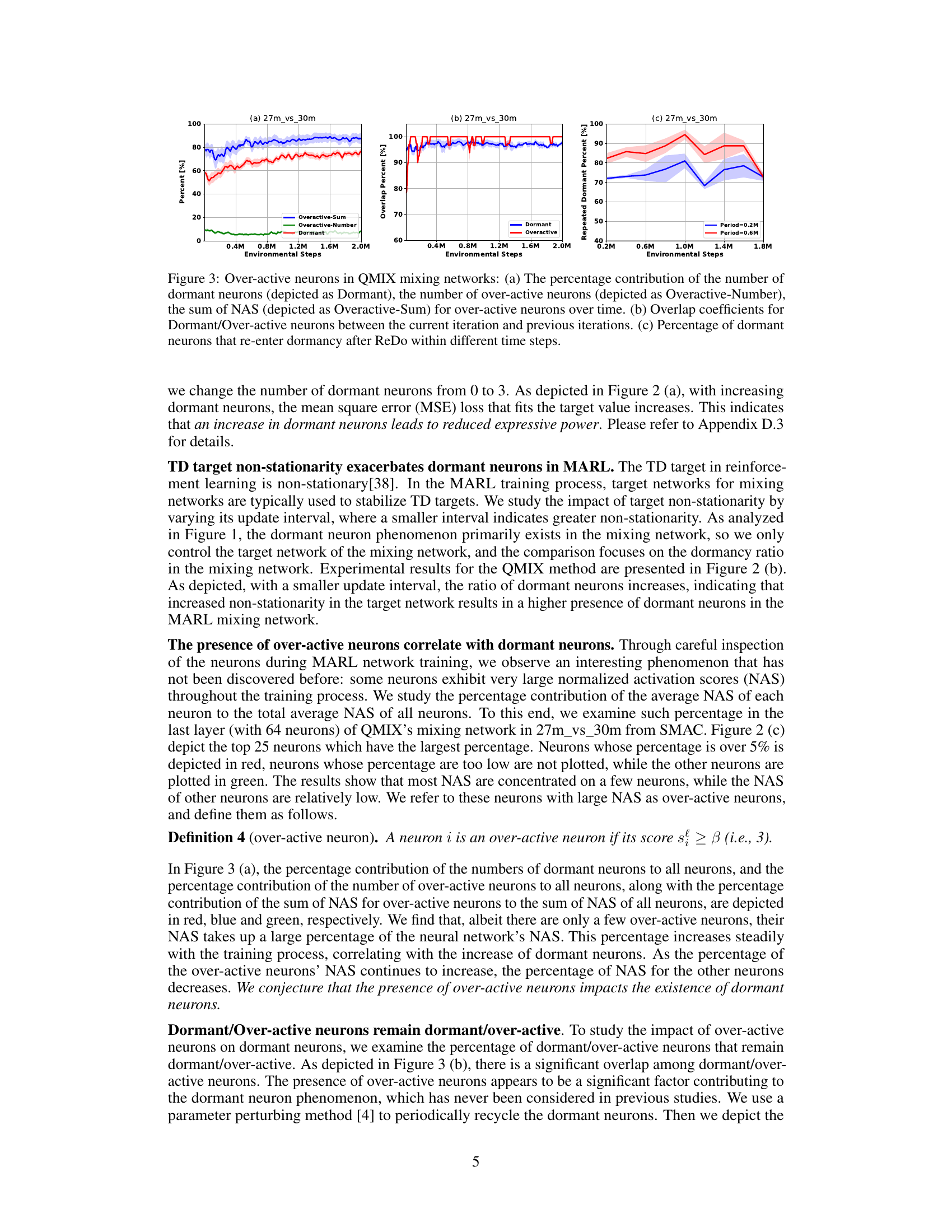
This figure demonstrates three key findings related to dormant neurons in multi-agent reinforcement learning. (a) shows that as the number of dormant neurons in a simple mixing network increases, the mean squared error (MSE) loss also increases, indicating a negative impact on network expressivity. (b) illustrates how the percentage of dormant neurons in a QMIX mixing network changes with varying target network update intervals; smaller intervals (more non-stationarity) lead to higher dormant neuron percentages. Finally, (c) shows the distribution of normalized activation scores (NAS) for the top 25 most active neurons, highlighting the existence of over-active neurons with significantly larger scores than the rest.
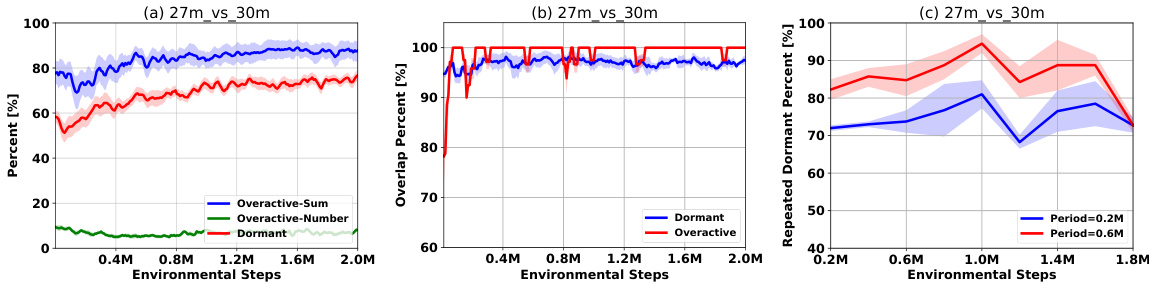
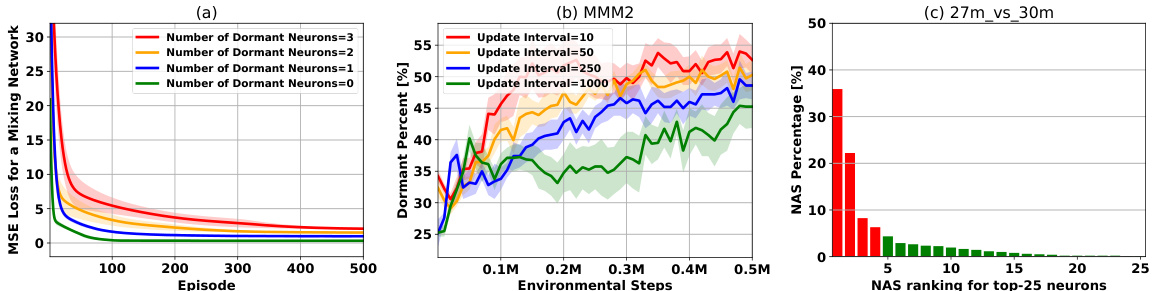
This figure analyzes over-active neurons in the QMIX mixing network. Subfigure (a) shows the percentage contribution of dormant neurons, over-active neurons, and the sum of normalized activation scores (NAS) of over-active neurons over time. Subfigure (b) illustrates the overlap between dormant and over-active neurons across different training iterations. Subfigure (c) shows the percentage of dormant neurons that become dormant again after applying the ReDo method.

The figure illustrates the ReBorn mechanism. It shows an over-active neuron (orange) whose weights (win, wout, bx) are redistributed to M randomly selected dormant neurons (grey). The dormant neurons become ‘reborn neurons’ (yellow). The weights of the reborn neurons are adjusted using αi and βi, which are randomly sampled from specified ranges to introduce variation. This weight transfer aims to alleviate the dormant neuron phenomenon by balancing neuron activity.
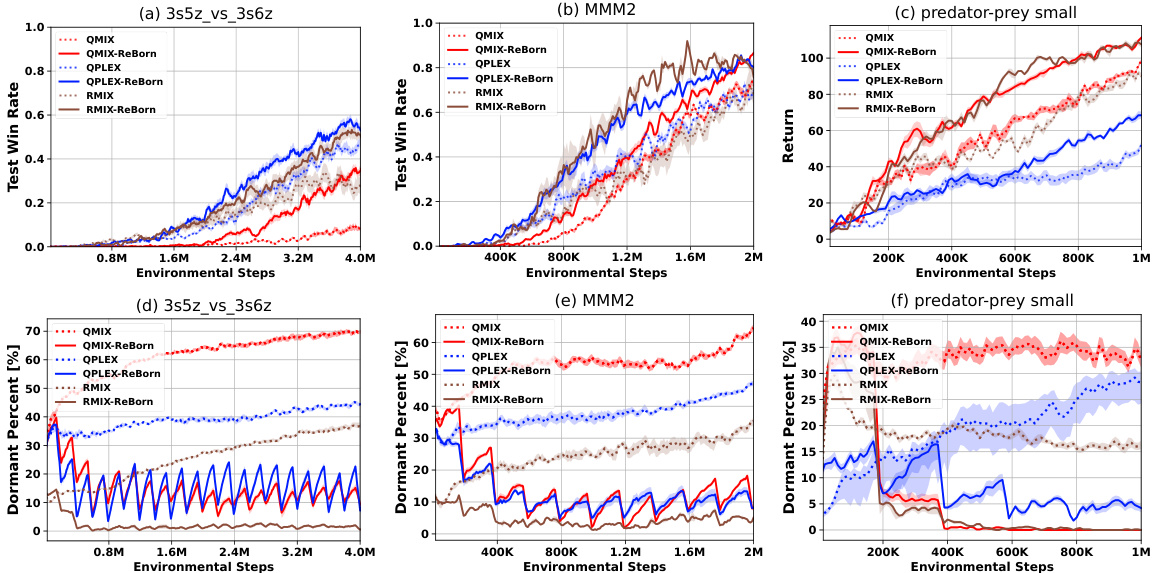
This figure shows the results of applying the ReBorn method to various value factorization algorithms (QMIX, QPLEX, RMIX) in different environments. The plots show the test win rate (a, b) and return (c) for three different environments: 3s5z_vs_3s6z, MMM2, and predator-prey small. Additionally, the plots demonstrate the percentage of dormant neurons over time for each algorithm in the same three environments (d, e, f). The results illustrate that ReBorn improves the performance and reduces the number of dormant neurons across various algorithms and environments.
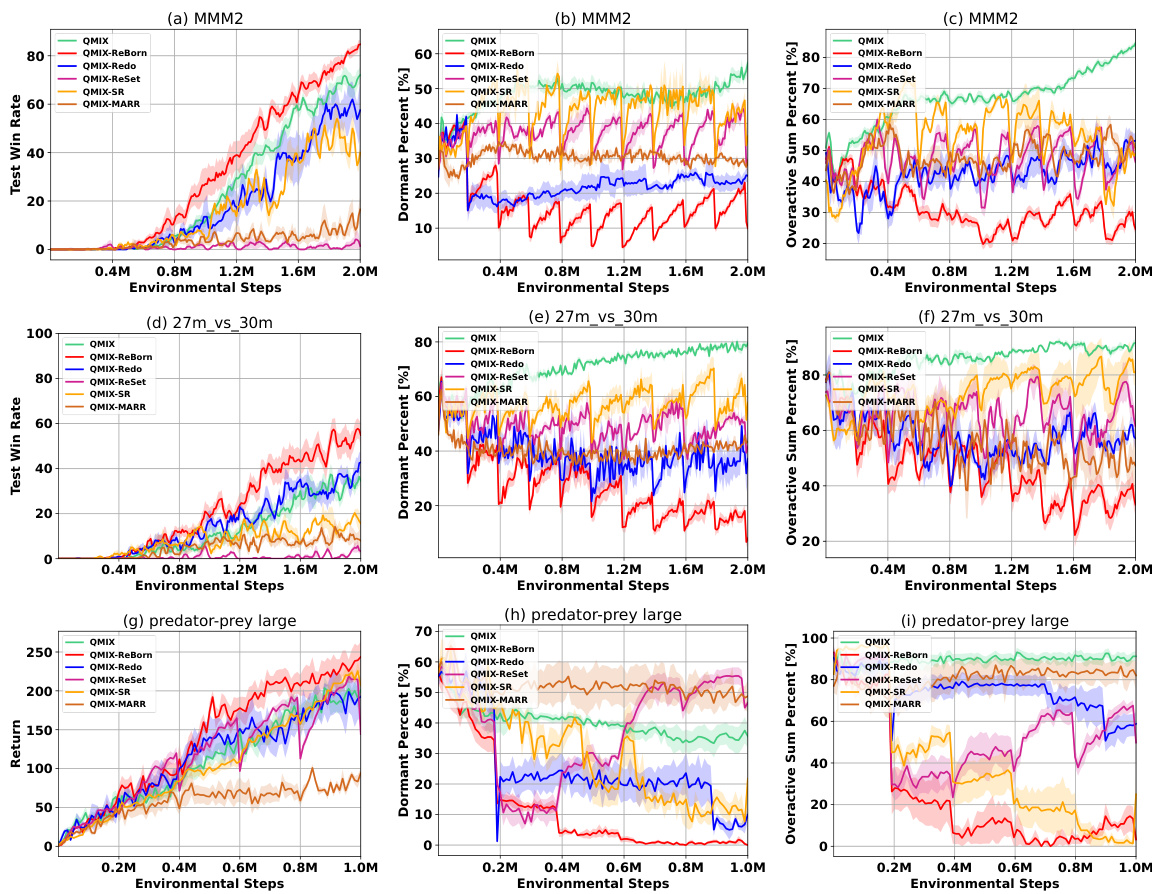
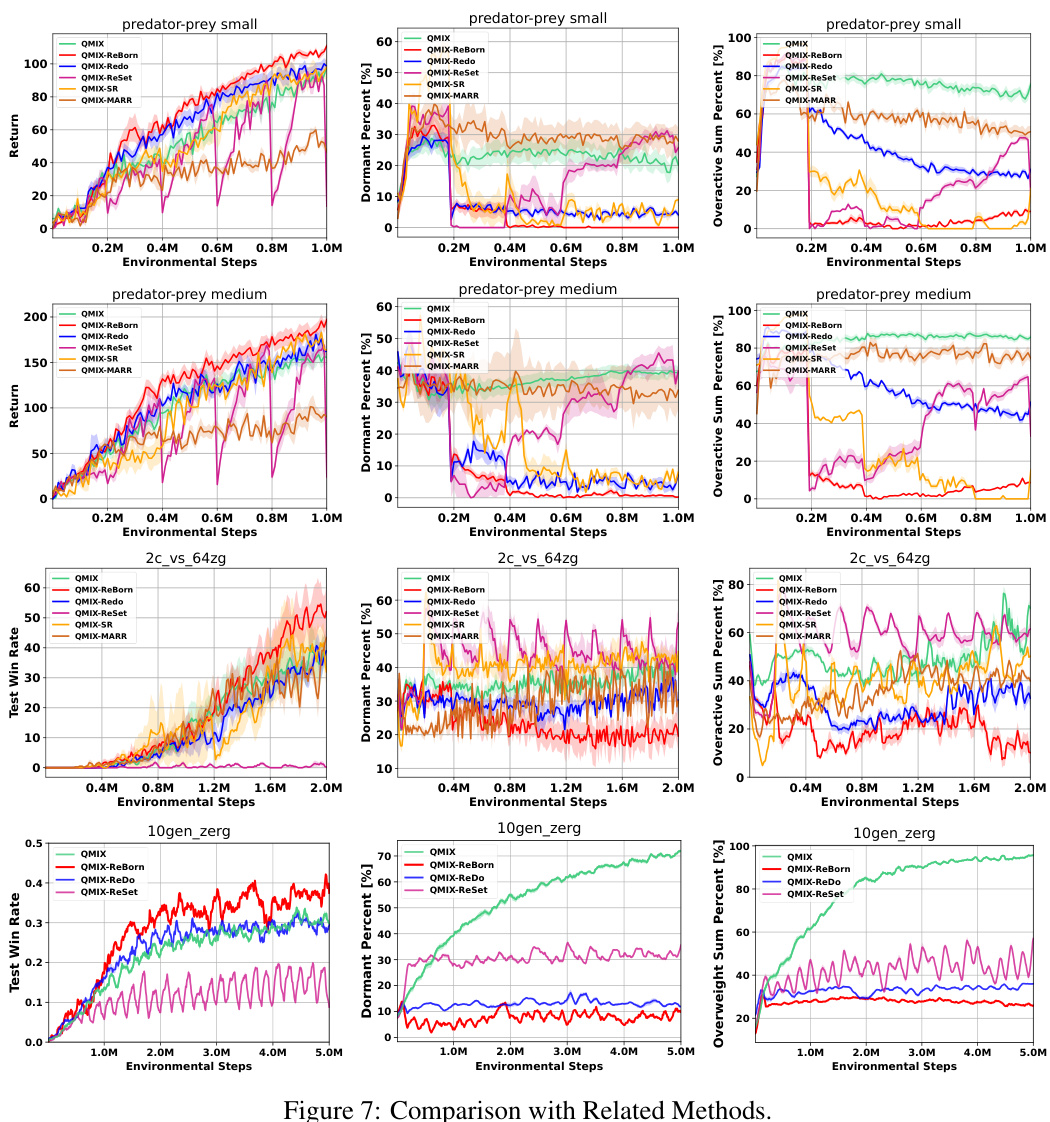
The figure compares the performance of ReBorn against other parameter perturbation methods (ReDo, ReSet, SR, MARR) that satisfy the Knowledge Invariant (KI) principle across various MARL value factorization algorithms (QMIX, QPLEX, RMIX) and environments (MMM2, 27m_vs_30m, predator-prey large). The results demonstrate that ReBorn consistently outperforms other methods in terms of win rate, dormant neuron ratio, and over-active neuron sum ratio, highlighting its effectiveness in addressing the dormant neuron phenomenon while preserving learned cooperation knowledge.

The figure demonstrates the importance of adhering to the Knowledge Invariance (KI) principle in the ReBorn method. It shows the test win rate for three different MARL algorithms (QMIX, QPLEX, RMIX) in the MMM2 scenario of the StarCraft Multi-Agent Challenge (SMAC) environment. Each algorithm is tested with and without the KI principle being satisfied. Results indicate that adhering to the KI principle significantly improves performance, while violating it leads to performance drops. This highlights the importance of the KI principle for effective MARL.

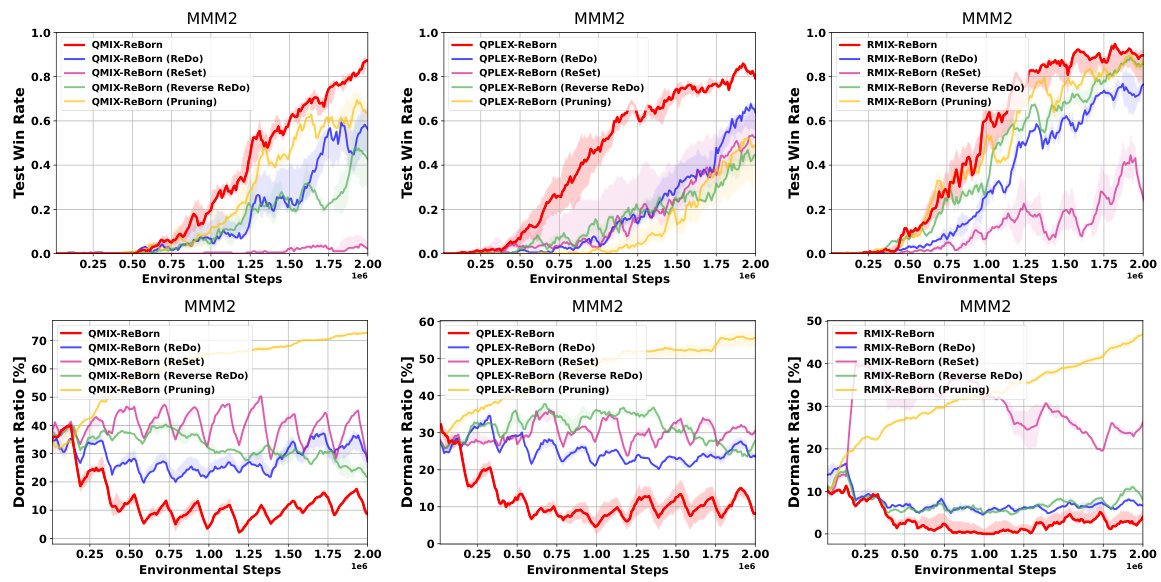
This figure compares the performance of ReBorn against other methods that also satisfy the Knowledge Invariant principle on three different MARL value factorization algorithms (QMIX, QPLEX, RMIX). Each subplot shows the test win rate over environmental steps. The comparison demonstrates the effectiveness of ReBorn, which outperforms alternative KI-satisfying methods in improving the performance of these algorithms. The different variants of ReBorn (ReDo, ReSet, Reverse ReDo, Pruning) are compared to the baseline ReBorn method to highlight the impact of different weight-sharing strategies.
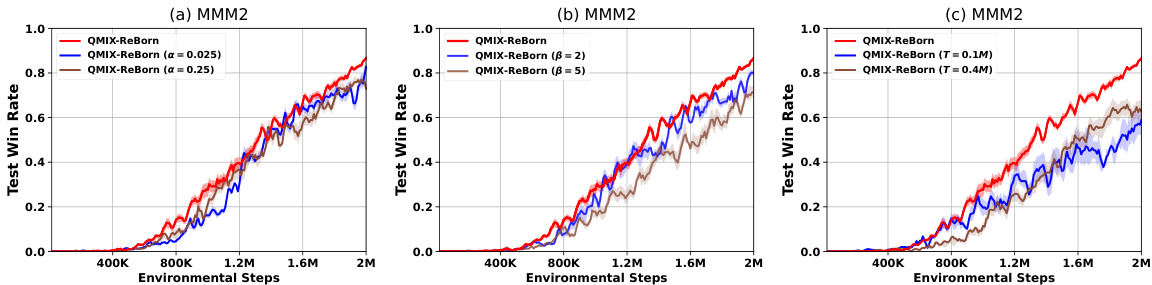
This figure presents an ablation study on the hyperparameters of the ReBorn algorithm. It shows the impact of varying the dormant neuron threshold (α), the over-active neuron threshold (β), and the ReBorn interval (T) on the algorithm’s performance. The results illustrate the sensitivity of the ReBorn algorithm to these hyperparameters and suggest that appropriate settings are essential for optimal performance. Specifically, it demonstrates how finding the right balance in identifying dormant and over-active neurons and their weight redistribution frequency affects the overall performance and the reduction of dormant neurons.

This figure illustrates an example demonstrating that the ReDo method fails to satisfy the Knowledge Invariant (KI) principle. It shows a three-layer mixing network before and after applying the ReDo parameter perturbation method. The network processes a joint state-action history (τ) and joint actions (u), producing a joint state-action value function Q(τ, u). The weights of the network are shown, and the left side depicts the network before ReDo, while the right side displays it after ReDo. Importantly, ReDo modifies the weights of dormant neurons (represented in blue), and the optimal joint action changes after the application of ReDo, violating the KI principle which mandates that learned action preferences remain unchanged after parameter perturbation. The figure uses a simplified example to clearly showcase this violation.

This figure illustrates how the ReSet method, a parameter perturbation technique, fails to satisfy the Knowledge Invariant (KI) principle in the context of multi-agent reinforcement learning (MARL). The left side shows the initial state of a simple mixing network with weights assigned to neurons, while the right side depicts the network after ReSet’s application. The transformation highlights changes in optimal actions due to the weight re-initialization, specifically that the re-initialization process in ReSet does not preserve previously learned knowledge.

This figure shows the percentage of dormant neurons in the agent and mixing networks of QMIX and QPLEX across three different SMAC scenarios: 3s_vs_5z, MMM2, and 27m_vs_30m. The x-axis represents environmental steps, and the y-axis represents the percentage of dormant neurons. The figure demonstrates that the dormant neuron phenomenon, where an increasing number of neurons become inactive during training, is more prominent in the mixing network than in the agent network, and that this phenomenon is more severe in scenarios with a larger number of agents.
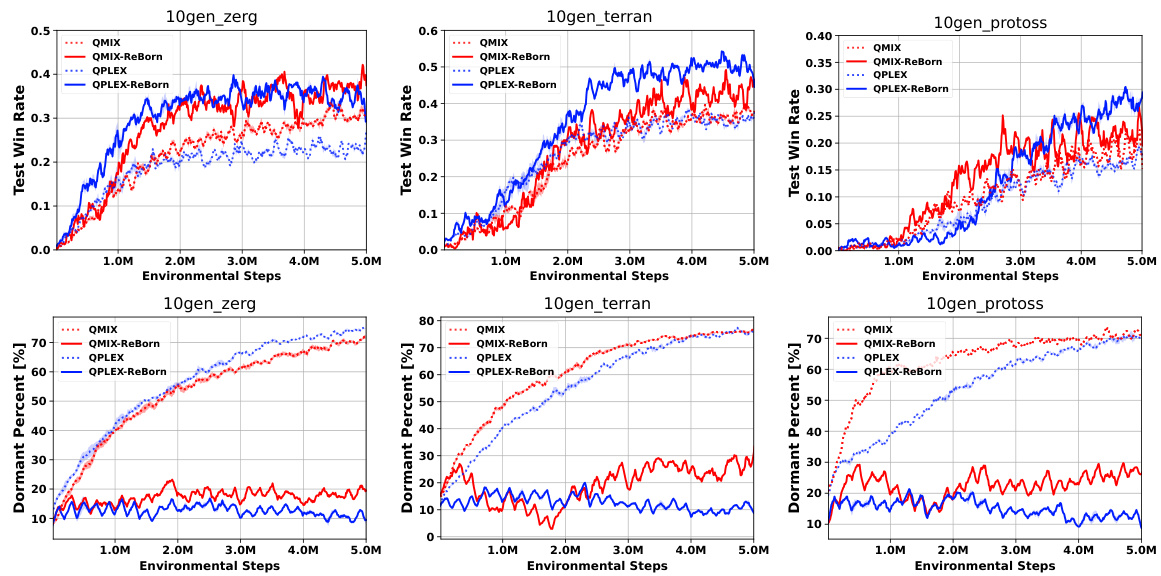
This figure displays the results of applying the ReBorn algorithm to various value factorization algorithms within the SMACv2 environment. It showcases the impact of ReBorn on the test win rate and dormant neuron percentage across three different SMACv2 scenarios: 10gen_zerg, 10gen_terran, and 10gen_protoss. Each subfigure presents the performance of QMIX and QPLEX, both with and without ReBorn, demonstrating how the algorithm affects the test win rate and reduces the number of dormant neurons. The results illustrate that ReBorn improves performance in various scenarios by addressing the dormant neuron phenomenon in multi-agent reinforcement learning value factorization.

This figure analyzes over-active neurons in the QMIX mixing network. Subfigure (a) shows the contribution of dormant and over-active neurons to the total activation over time. Subfigure (b) illustrates the overlap between dormant and over-active neurons across different training iterations, showing persistence. Subfigure (c) shows the percentage of dormant neurons that remain dormant after applying the ReDo method (a parameter perturbation technique), highlighting the persistence of dormant neurons.
This figure displays the results of the ReBorn algorithm on three different environments: 3s5z_vs_3s6z, MMM2, and predator-prey small. For each environment, it shows the test win rate (a-c) and the percentage of dormant neurons over time (d-f) for four different value factorization algorithms (QMIX, QPLEX, RMIX) with and without the ReBorn method. The results demonstrate that ReBorn improves the performance of various value factorization algorithms by reducing the percentage of dormant neurons.
The figure displays the percentage of dormant neurons in agent networks and mixing networks for different MARL algorithms (QMIX, QPLEX) across three SMAC scenarios (3s vs 5z, MMM2, 27m vs 30m). It visually demonstrates the increase in dormant neurons over environmental steps, particularly within the mixing network, and how this increase correlates with the number of agents involved in the scenario. The graphs highlight that the dormant neuron phenomenon is more pronounced in the mixing network compared to the agent networks across different scenarios and algorithms.

This figure demonstrates that ReBorn enhances the performance of multiple value factorization algorithms (QMIX, QPLEX, RMIX) across different environments (3s5z_vs_3s6z, MMM2, predator-prey small). Specifically, it shows the test win rate and return improvements in (a), (b), and (c) respectively, and illustrates the reduction in dormant neurons’ percentage for each environment in (d), (e), and (f).
More on tables
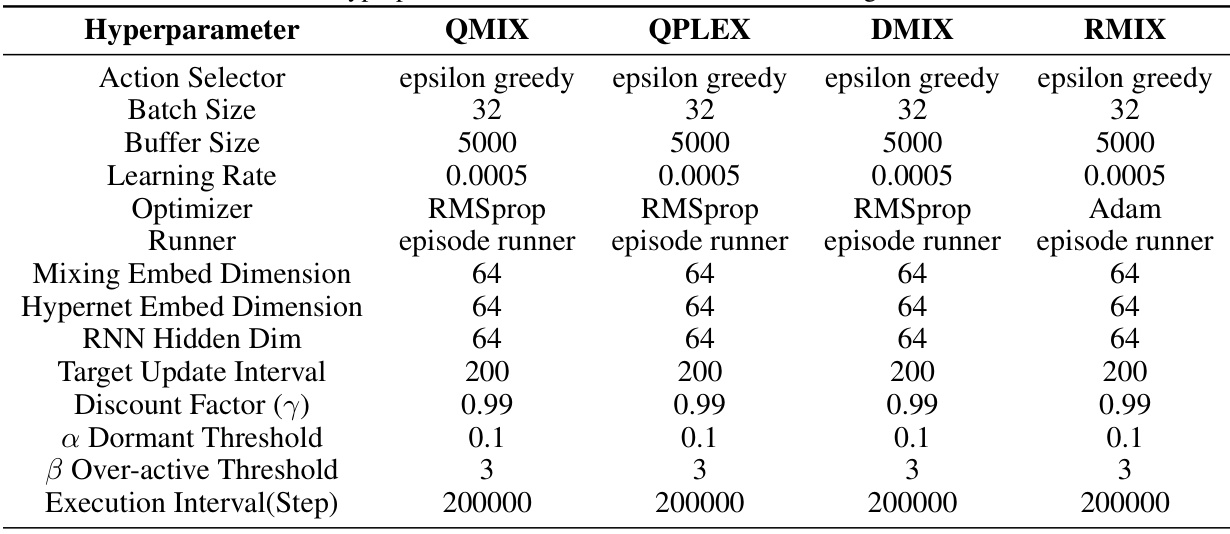
This table lists the hyperparameters used for four different value factorization algorithms (QMIX, QPLEX, DMIX, and RMIX) in the experiments. These hyperparameters control various aspects of the training process, including the exploration strategy (epsilon greedy), batch size, buffer size, learning rate, optimizer, runner type, mixing network dimensions, target update interval, discount factor, dormant neuron threshold, over-active neuron threshold, and the execution interval. The values provided represent the settings used in the experiments reported in the paper.

This table summarizes the different methods used in the experimental section. It shows the application of ReBorn, ReDo, and ReSet to different parts of the algorithms (Mixing Network vs. Whole Network) and whether the Knowledge Invariant principle is satisfied.

This table shows different configurations used in the Predator-prey environment. Each configuration varies in the number of predators, the number of preys, the map size, and the reward given for capturing a prey. This allows researchers to test the algorithms in different levels of complexity.
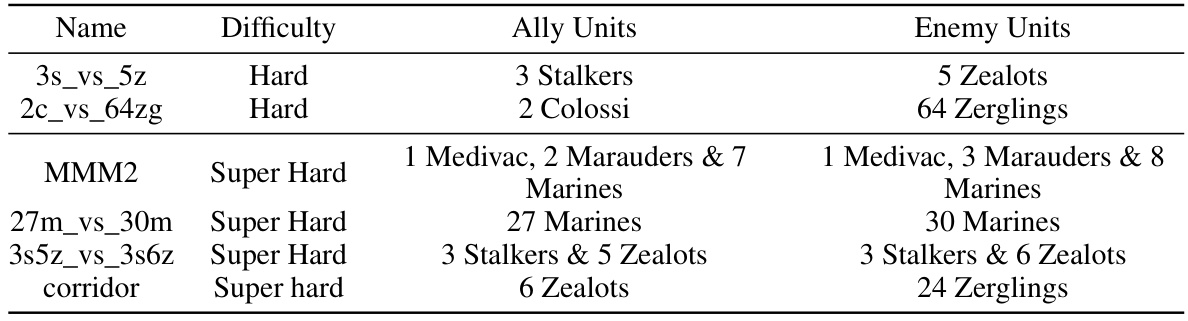
This table lists five scenarios from the StarCraft Multi-Agent Challenge (SMAC) used in the paper’s experiments. For each scenario, it provides the difficulty level, the types and number of allied units controlled by the MARL agents, and the types and number of enemy units controlled by the game’s built-in AI.

This table lists the configurations of three different scenarios from the SMACv2 environment used in the paper’s experiments. Each scenario involves 10 allied units and 11 enemy units. The ‘Unit Types’ column indicates the types of units included in each scenario: Zerglings, Hydralisks, and Banelings for the Zerg scenario; Marines, Marauders, and Medivacs for the Terran scenario; and Stalkers, Zealots, and Colossi for the Protoss scenario. These variations are intended to test the robustness and generalizability of the proposed ReBorn method.
Full paper#