↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are computationally expensive, particularly when dealing with long contexts. Existing methods for managing LLM memory, such as those that evict less important tokens, often struggle with the dynamic nature of token importance; tokens deemed unimportant might become crucial later. This leads to both decreased efficiency and accuracy.
ARKVALE solves this by using a page-based system that asynchronously saves evicted pages, summarizes their importance using a digest, and then selectively recalls important pages as needed, improving decoding latency up to 2.2× and throughput up to 4.6×, all while maintaining high accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it presents ARKVALE, a novel method for efficiently managing the memory usage of large language models (LLMs) during inference, which is crucial for deploying LLMs on resource-constrained devices and improving the throughput of LLM applications.
Visual Insights#
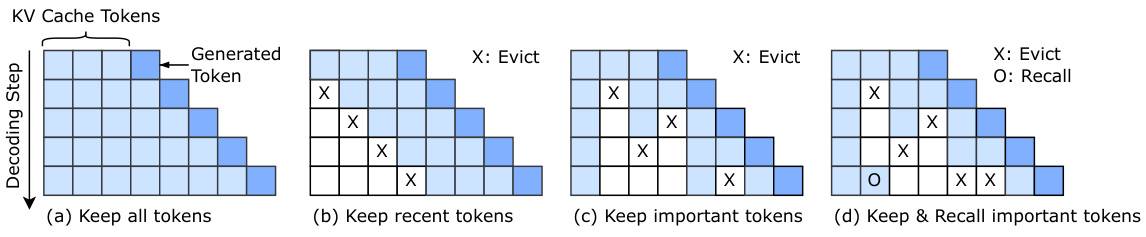
The figure compares four different strategies for managing the key-value cache (KV cache) in large language models (LLMs) during inference. (a) shows a baseline where all tokens are kept in the cache, leading to increased memory usage and latency. (b) illustrates keeping only recent tokens, improving efficiency but potentially losing important information. (c) demonstrates keeping only important tokens, a more advanced approach that reduces memory usage but still might miss crucial information that might become important later. Finally, (d) shows the proposed ARKVALE method, which combines keeping important tokens with the ability to recall previously evicted tokens that regain importance during later decoding steps, aiming for the best balance between memory efficiency and accuracy.

This table presents the accuracy of passkey retrieval tasks for different models (StreamingLLM, H2O, TOVA, and ARKVALE) under varying context lengths (10k, 20k, 30k) and cache budgets (512, 1024, 2048, 4096). The passkey is inserted at different depths within the text (0% to 95%) to simulate long-range dependency scenarios. The results demonstrate the effectiveness of ARKVALE in maintaining high accuracy even with limited cache budgets and long context lengths, unlike the other models which show significant accuracy drops.
In-depth insights#
Dynamic Token Importance#
The concept of “Dynamic Token Importance” highlights a crucial limitation in existing key-value (KV) cache eviction methods for large language models (LLMs). These methods often rely on static measures of token importance, such as recency or historical attention scores, failing to account for the evolving relevance of tokens during decoding. ARKVALE directly addresses this limitation by acknowledging that tokens initially deemed unimportant may later regain significance. This dynamic shift in importance necessitates a more sophisticated approach to KV cache management, moving beyond simple eviction strategies. The paper argues that a page-based system, which can recall previously evicted pages based on their updated importance, offers a more efficient and accurate way to handle long-context scenarios. The dynamic nature of token importance underscores the need for adaptive mechanisms that can effectively track and respond to changes in token relevance throughout the decoding process. This adaptive approach allows for improved accuracy and efficiency in handling long contexts, avoiding the premature discarding of vital information.
Page-Based KV Cache#
A page-based KV cache is a memory management technique designed to enhance the efficiency of handling long contexts in large language models (LLMs). It addresses the challenges posed by the ever-increasing size of key-value caches (KVC) in LLMs that process long sequences. The core idea is to group tokens into pages, allowing for fine-grained management of the cache. This approach offers a trade-off between using the entire KVC (leading to high memory consumption and latency) and using only a subset of recent tokens (potentially sacrificing accuracy). Asynchronous copying of filled pages into external memory (like CPU memory) provides a backup while a summarized digest allows for quick importance assessment and efficient recall of important pages. This approach balances memory efficiency and accuracy by dynamically managing pages based on importance scores and the current query, resulting in significant improvements in decoding latency and throughput. The method’s effectiveness relies heavily on the accuracy of its page importance estimation, making the design of efficient summarization and importance evaluation techniques crucial. The page-based KV cache strategy is a significant advancement in managing long contexts in LLMs, offering a practical solution to the limitations of existing approaches.
Bounding-Volume Summarization#
Bounding-volume summarization is a crucial technique for efficient key-value (KV) cache management in large language models (LLMs). It addresses the challenge of handling extensive context lengths by approximating the importance of a set of key vectors (representing tokens) using a compact geometric representation (the bounding volume). Instead of storing all keys, only the volume’s parameters (e.g., center and radius for a sphere, or min/max vectors for a cuboid) are stored. This significantly reduces memory footprint and speeds up computations. The choice of bounding volume (sphere vs. cuboid) and the method to determine its parameters influence accuracy and efficiency. Spheres offer simplicity, while cuboids capture potentially more precise approximations, though at the cost of increased storage. This trade-off between storage and accuracy is a key consideration. The effectiveness of this summarization depends heavily on how well the bounding volume reflects the distribution of keys and their relevance to subsequent queries. Clever algorithms for selecting parameters are essential to ensure a balance between memory savings and maintaining the accuracy of attention calculations.
Long Context Efficiency#
Large language models (LLMs) are transforming various domains, but their effectiveness is often hampered by limitations in handling long contexts. Long context efficiency focuses on mitigating these limitations, which primarily involve the challenges of increased memory consumption and computational overhead as the context length grows. Strategies to improve efficiency include techniques like sparse attention, which selectively processes only the most relevant parts of the context, and key-value (KV) cache management, which intelligently evicts less important information while retaining crucial data. Recallable key-value eviction is a particularly promising approach, allowing for the retrieval of previously discarded information if it later proves relevant, dynamically adapting to shifting token importance. However, this introduces trade-offs, particularly with regards to memory overhead for storing backups of evicted information. The goal is to find a balance between memory efficiency and accuracy, ensuring LLMs can effectively process extensive contexts without sacrificing performance or exceeding resource limits.
ARKVALE Limitations#
ARKVALE’s primary limitation stems from its reliance on external memory (CPU) for page backups. While asynchronous copying mitigates decoding latency issues, the pre-filling phase remains affected. Insufficient CPU memory could necessitate offloading backups to disk, significantly impacting performance. Furthermore, the summarization technique, while efficient, introduces approximation errors in importance estimation which may affect page recall accuracy. Over-reliance on the accuracy of the bounding volume method for summarization is another potential weakness, as it may not accurately capture the complexity of all key-value relationships. Finally, the effectiveness of ARKVALE heavily depends on the choice of hyper-parameters (page size, cache budget, and number of top-ranked pages), necessitating careful tuning for optimal performance across various tasks and context lengths. A thorough analysis of hyperparameter sensitivity is crucial for wider applicability.
More visual insights#
More on figures
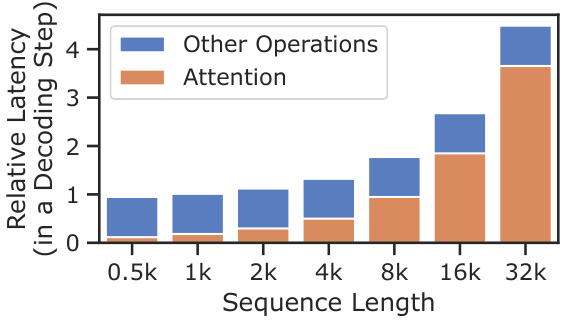
This figure shows the breakdown of latency and memory usage for a single decoding step in the LongChat-7b-v1.5-32k model with a batch size of 8. The x-axis represents different sequence lengths, and the y-axis shows relative latency (left) and memory usage in GB (right). The latency is broken down into the time spent on attention computation and other operations. The memory usage is broken down into the memory used by the KV cache and model parameters. The figure demonstrates how both latency and memory usage increase significantly with longer sequence lengths.
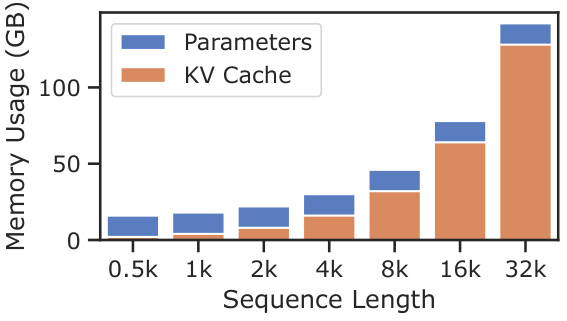
This figure shows the breakdown of latency and memory usage during a single decoding step of the LongChat-7b-v1.5-32k language model. The model uses a batch size of 8 and varies the length of the history sequence (context). The left plot (a) shows latency, broken down into the time spent on attention and other operations. The right plot (b) shows memory usage divided into parameters and KV cache usage. Both plots demonstrate how latency and memory usage increase as the context length increases, highlighting the challenges of handling long contexts in LLMs.

This figure shows the sparsity of the key-value (KV) cache in each layer of a large language model (LLM). The tokens in the KV cache are grouped into pages (32 tokens per page), and these pages are ranked based on their attention scores. The figure plots the ratio of bottom-ranked pages that contribute to 1% and 10% of the total attention scores, demonstrating the sparsity. It also shows the number of top-ranked pages that contribute to 90% and 99% of the total attention scores, highlighting how few pages are actually crucial for attention computation.
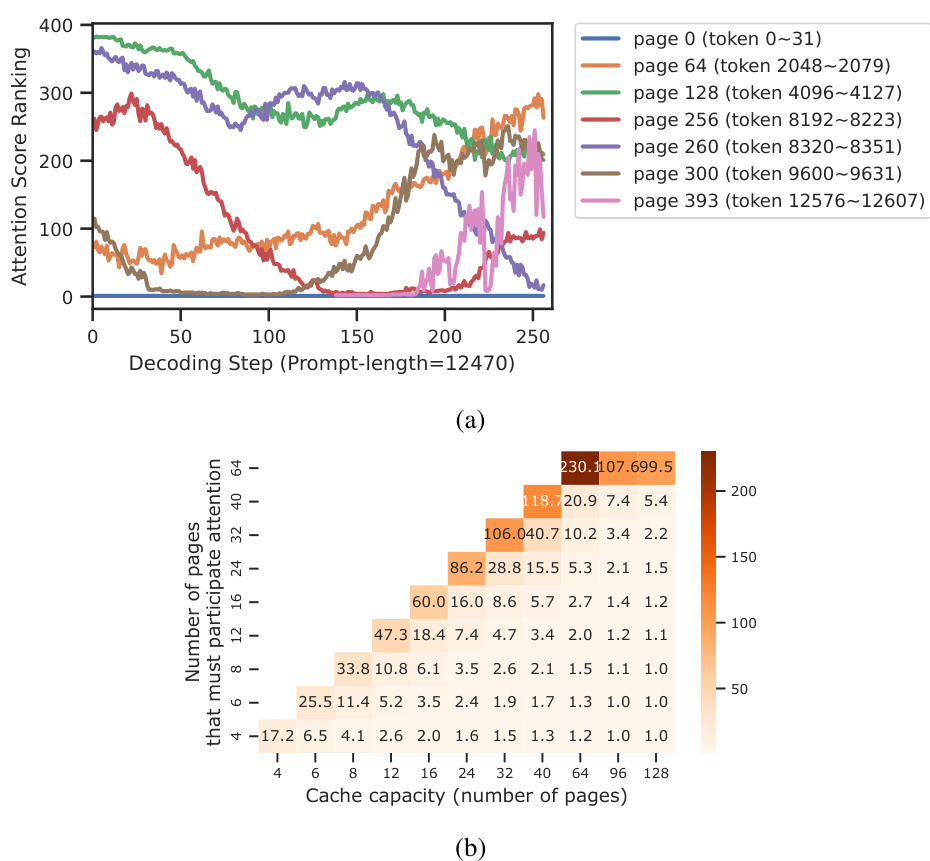
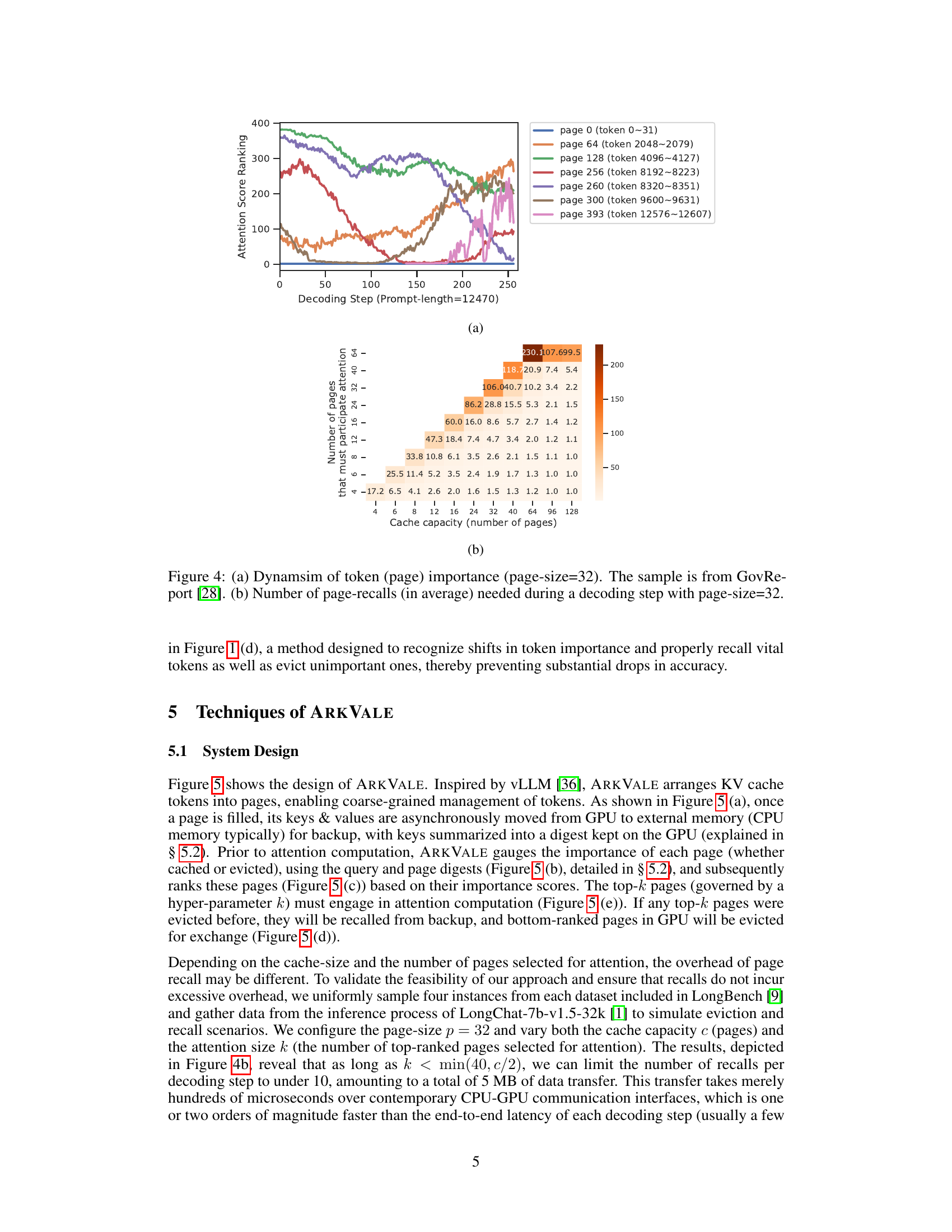
Figure 4(a) shows the dynamic change of token importance over decoding steps. It demonstrates that tokens initially deemed unimportant can regain importance later. This dynamic behavior motivates the need for ARKVALE’s recallable key-value eviction mechanism. Figure 4(b) presents the average number of page recalls needed during a decoding step for various cache capacities. It highlights the relatively low recall overhead, demonstrating the efficiency of ARKVALE’s page-based management approach.
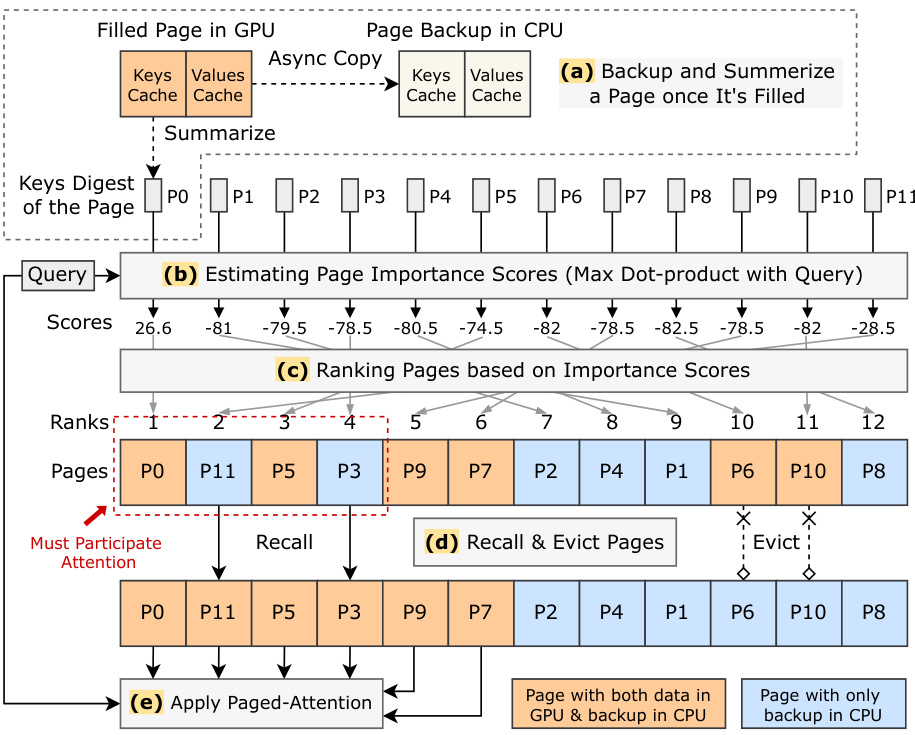
This figure shows the design of ARKVALE, a page-based KV cache manager. It consists of five stages: (a) Backup and Summarize a Page once It’s Filled: Once a page is filled in the GPU, it’s asynchronously copied to CPU memory for backup. Keys are summarized into a digest and stored on the GPU. (b) Estimating Page Importance Scores (Max Dot-product with Query): Before attention computation, ARKVALE estimates the importance of each page using the query and page digests. (c) Ranking Pages based on Importance Scores: Pages are then ranked based on their importance scores. (d) Recall & Evict Pages: Top-k pages are selected for attention. If any were evicted, they’re recalled from CPU memory, and less important pages in GPU are evicted. (e) Apply Paged-Attention: The selected pages participate in attention computation.
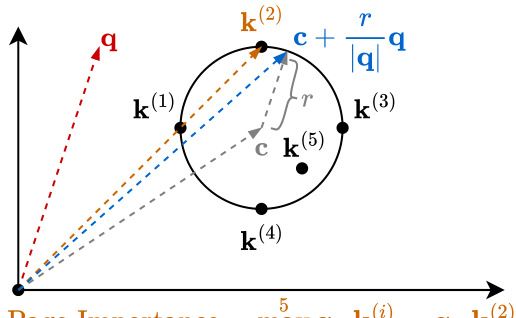
This figure illustrates two methods for summarizing page keys into bounding volumes for efficient importance estimation. (a) shows a bounding sphere method, where keys are enclosed within a sphere. The center (c) and radius (r) of this sphere define the digest. Importance is approximated using the maximum dot product between the query (q) and keys on the sphere’s surface. (b) shows a bounding cuboid method, where keys are enclosed within a cuboid. The maximum (b(2)) and minimum (b(4)) vectors of the cuboid form the digest. Importance is approximated using the maximum dot product between the query (q) and the vertices of the cuboid.
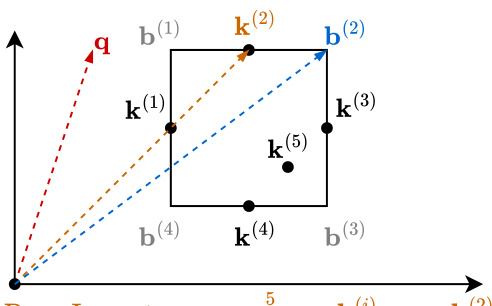
This figure illustrates two methods to approximate the maximum dot product between a query vector and a set of key vectors. The first method uses a bounding sphere, where the maximum dot product is approximated using the sphere’s center and radius. The second method uses a bounding cuboid, approximating the maximum dot product using the maximum and minimum vector of the cuboid. These approximations allow efficient estimation of page importance without needing to compute the dot product for each individual key.
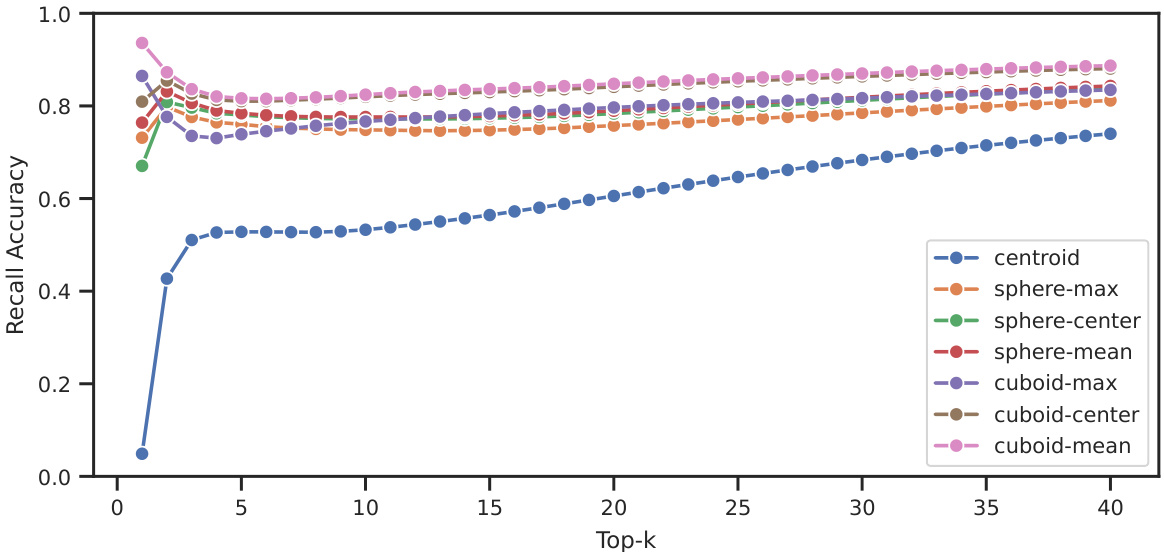
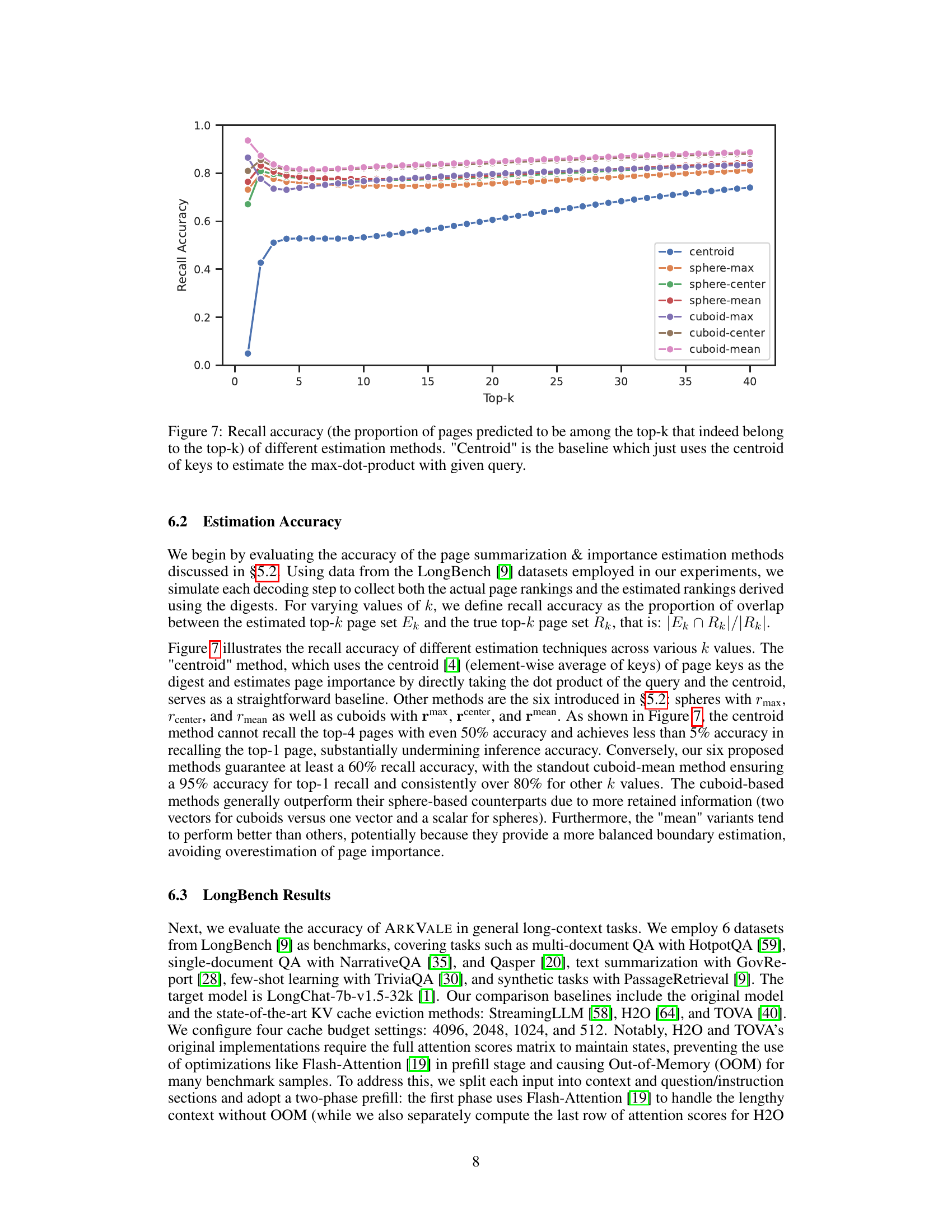
This figure shows the recall accuracy of different page importance estimation methods used in ARKVALE. Recall accuracy is defined as the proportion of pages correctly predicted to be in the top-k most important pages. The x-axis represents the value of k (number of top pages considered), and the y-axis shows the recall accuracy. The plot compares the performance of several methods: centroid (baseline), sphere-based methods (using sphere’s max, center, and mean), and cuboid-based methods (using cuboid’s max, center, and mean). The results demonstrate that the cuboid-based methods, particularly cuboid-mean, significantly outperform the baseline and other methods, achieving high recall accuracy across various values of k.
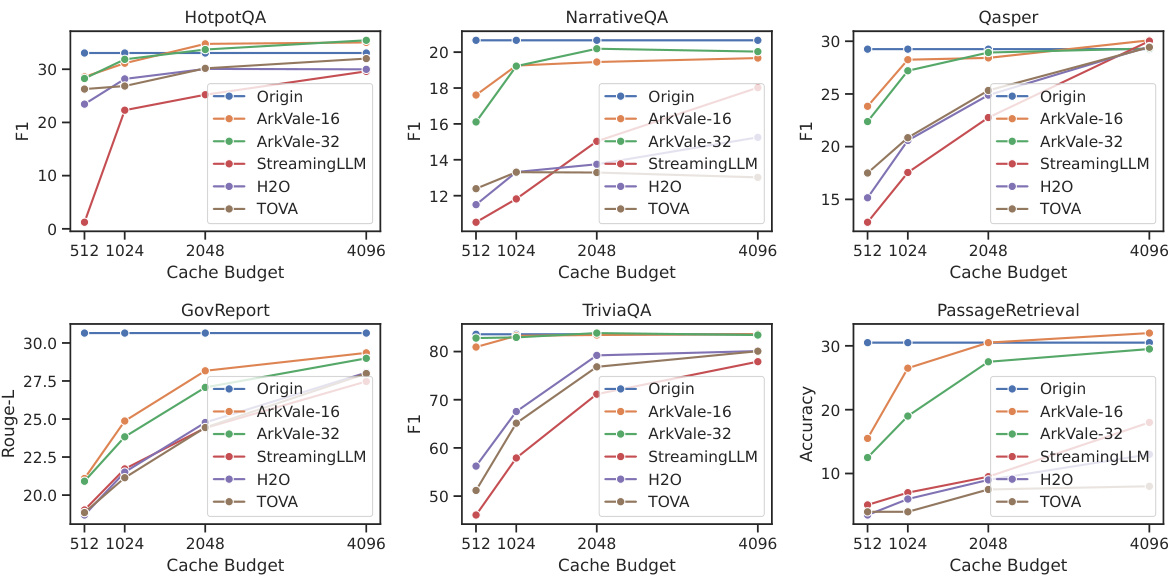
This figure presents the results of evaluating ARKVALE and other methods on six long-context datasets from the LongBench benchmark. It shows the performance (F1 score, Rouge-L score, or Accuracy, depending on the dataset) achieved by different methods (ARKVALE with page sizes of 16 and 32, StreamingLLM, H2O, and TOVA) across various cache budget sizes (512, 1024, 2048, and 4096). The results demonstrate ARKVALE’s superior performance in comparison to the baseline methods, particularly at smaller cache budgets.
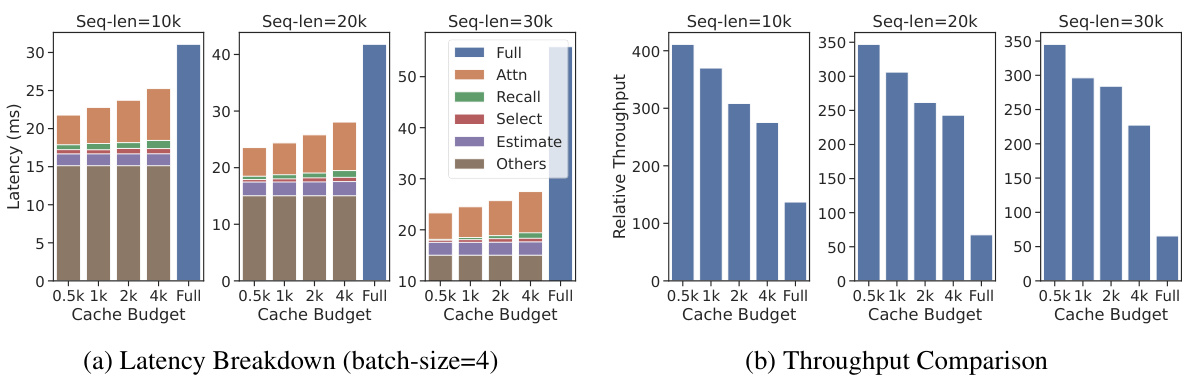
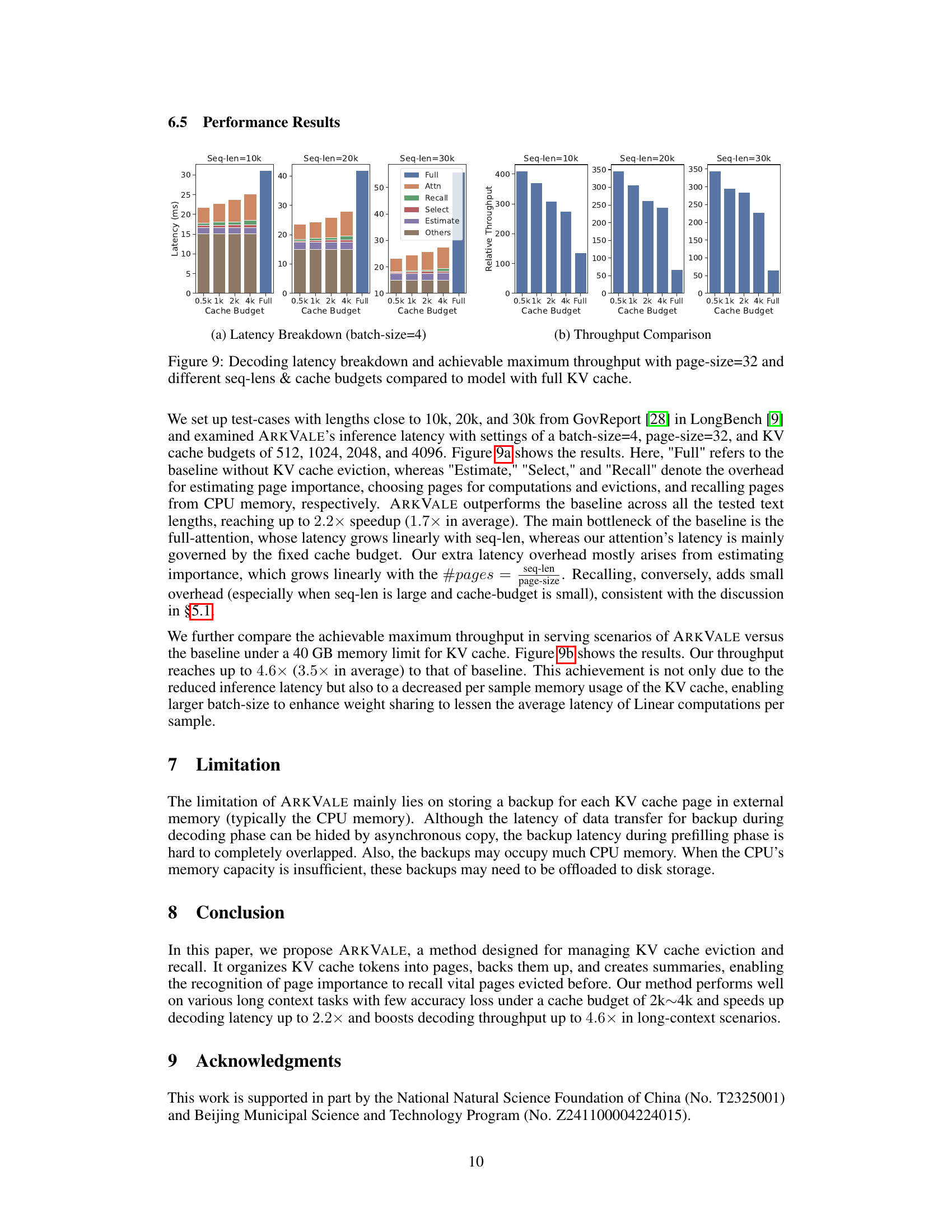
This figure shows two subfigures: (a) Latency Breakdown and (b) Throughput Comparison. Subfigure (a) presents a stacked bar chart illustrating the breakdown of decoding latency for different sequence lengths (10k, 20k, 30k tokens) and cache budget sizes (0.5k, 1k, 2k, 4k, Full). Each bar is segmented into components representing latency from different processes: Full Attention, Recall, Selection, Estimation, and Others. Subfigure (b) presents a bar chart comparing the relative throughput achieved by ARKVALE with various cache budget sizes against the baseline (Full) for different sequence lengths. The charts demonstrate that ARKVALE improves latency and throughput significantly with increasing cache budget, showcasing its efficiency in handling long sequences.
Full paper#