↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current unsupervised 3D keypoint detection methods struggle with deformable objects, failing to maintain semantic consistency. This paper introduces Key-Grid, an innovative unsupervised keypoint detector that addresses this limitation. It uses an autoencoder framework where the encoder predicts keypoints, and the decoder reconstructs the object using these keypoints and a novel 3D grid feature heatmap. This heatmap represents latent variables for grid points sampled uniformly in 3D space, reflecting the shortest distance to the ‘skeleton’ formed by keypoint pairs.
Key-Grid achieves state-of-the-art results on benchmark datasets, demonstrating superior performance in semantic consistency and positional accuracy compared to existing methods. Importantly, it shows robustness to noise and downsampling and can be generalized to achieve SE(3) invariance, showcasing its adaptability for real-world applications involving deformable objects and challenging conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in 3D computer vision and robotics because it presents Key-Grid, a novel unsupervised keypoint detector that outperforms existing methods for both rigid and deformable objects. This advancement is important due to the increasing need for robust and consistent 3D keypoint detection in various applications like pose estimation and object manipulation. The introduction of the grid heatmap feature and its application in the decoder provides a significant contribution and will likely shape the future of unsupervised 3D keypoint detection research. The robustness of Key-Grid to noise and downsampling also makes it a practical and reliable tool for real-world applications.
Visual Insights#

This figure showcases the robustness of the Key-Grid model in detecting 3D keypoints across various object shapes and deformations. The top row displays rigid objects with significant intra-class shape differences, while the bottom row demonstrates the model’s ability to maintain keypoint consistency even under extreme deformations of soft objects like clothing.
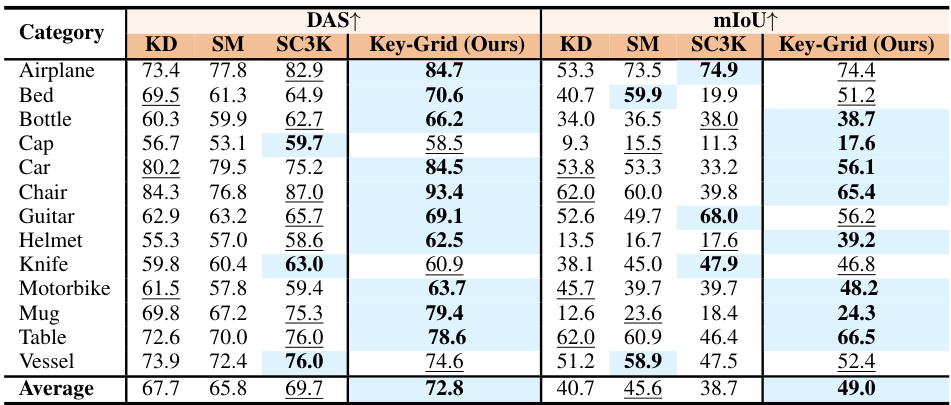
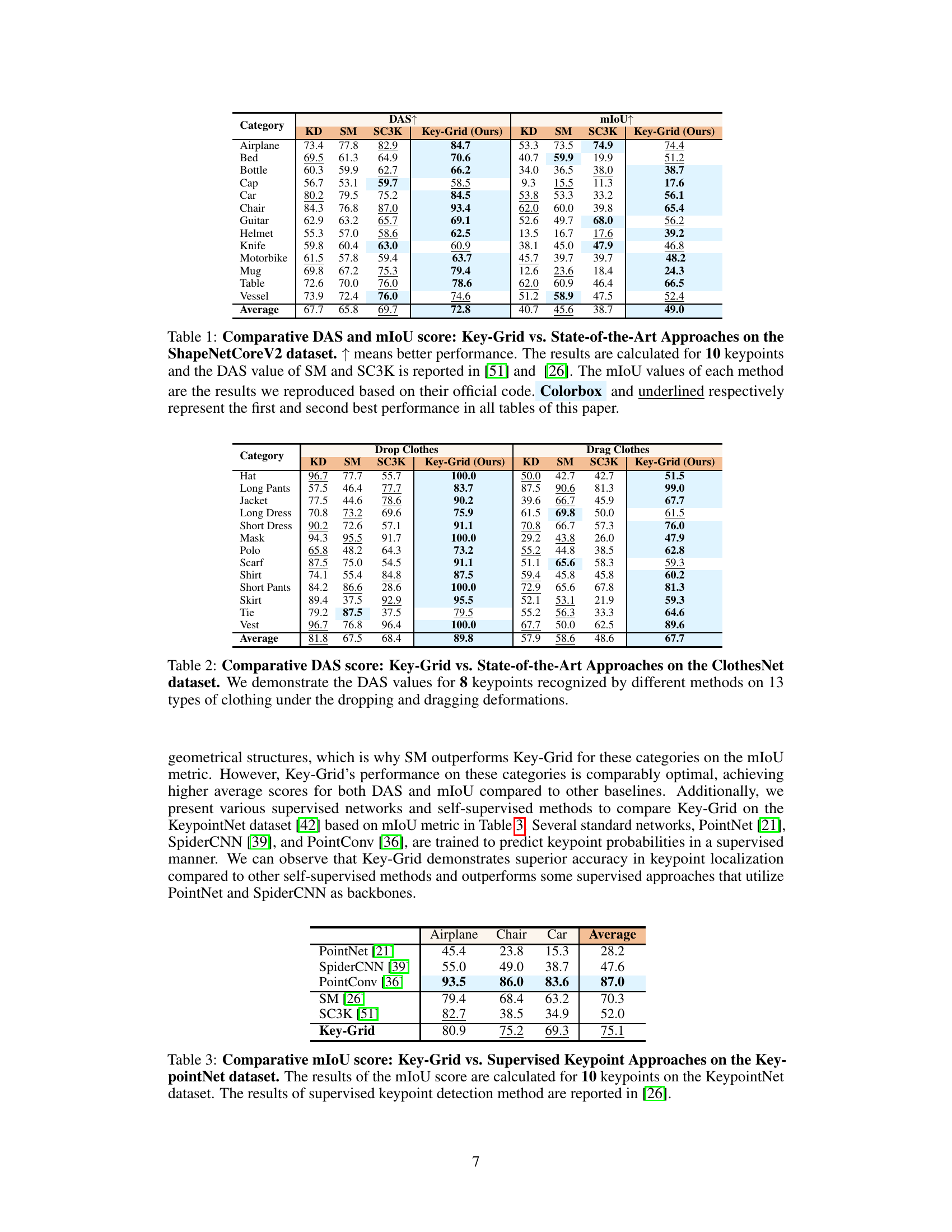
This table compares the performance of Key-Grid against other state-of-the-art (SOTA) approaches on the ShapeNetCoreV2 dataset for 3D keypoint detection. It shows the Dual Alignment Score (DAS) and mean Intersection over Union (mIoU) for 10 keypoints across 13 object categories. Higher DAS and mIoU values indicate better performance, reflecting both semantic consistency (DAS) and localization accuracy (mIoU). The results highlight Key-Grid’s superior performance compared to existing methods.
In-depth insights#
3D Keypoint Consistency#
3D keypoint consistency is crucial for reliable 3D object understanding and downstream tasks. Inconsistent keypoint detection across different instances of the same object category, or even across different views of the same object, severely hinders applications such as pose estimation, shape matching, and robotics. Ensuring consistency necessitates robust methods that are invariant to various transformations like viewpoint changes, object deformations, and noise. This involves developing techniques to identify semantically meaningful keypoints—points that consistently correspond to specific object parts regardless of shape variations. Achieving this requires sophisticated algorithms that can learn both local and global object features, possibly by leveraging deep learning architectures. Furthermore, evaluation metrics must focus on capturing semantic correspondence rather than just positional accuracy. Benchmark datasets with consistent keypoint annotations are vital for developing and evaluating such methods. The challenge lies in creating algorithms that are both accurate and generalizable, capable of handling complex variations and noisy data. Ultimately, robust keypoint consistency is essential for enabling advanced 3D object understanding and manipulation.
Grid Heatmap Encoding#
Grid Heatmap encoding represents a novel approach to encode 3D shape information using a dense feature map. Unlike traditional methods relying on sparse keypoints, this method leverages keypoint relationships to create a continuous feature field. Uniformly sampled grid points in 3D space are assigned features based on their proximity to the ‘skeleton’ formed by connecting keypoint pairs. This approach is particularly beneficial for deformable objects, where the geometric structure changes significantly during deformations. The grid heatmap implicitly represents the object shape, allowing the decoder to reconstruct the shape from a rich geometric description rather than just a set of keypoints. This method’s strength lies in its ability to handle the challenging shape variations encountered in deformable object analysis, resulting in better semantic consistency and accuracy in keypoint localization, even in the presence of noise or downsampling. The use of a dense feature map is a crucial advantage, offering resilience and robustness to variations that affect sparse methods.
Deformable Object Focus#
A dedicated focus on deformable objects within a 3D keypoint detection framework presents unique challenges and opportunities. Deformable objects lack the rigid structure assumed by many existing methods, making consistent keypoint identification across varying poses and shapes difficult. A successful approach would need to go beyond rigid-body assumptions, potentially incorporating techniques sensitive to the changing geometric and topological properties of the object. This might involve learning latent representations that capture the underlying shape dynamics or developing new loss functions that emphasize semantic consistency even when the object is significantly deformed. Furthermore, a robust system must account for occlusions and noise often present in real-world data. Successful handling of these challenges would advance the field significantly, paving the way for more sophisticated applications in areas like robotics and computer vision where interacting with deformable objects is prevalent.
SE(3) Equivariance#
SE(3) equivariance, a crucial concept in geometric deep learning, ensures that a model’s output transforms predictably under rigid body transformations (rotation and translation). In the context of 3D keypoint detection, SE(3) equivariance guarantees that if the input point cloud is rotated or translated, the detected keypoints will undergo the same transformation, maintaining consistent spatial relationships. This property is particularly important for robust keypoint detection in scenarios involving varying viewpoints or object poses. Achieving SE(3) equivariance often involves using specialized neural network architectures that incorporate geometric information explicitly, such as employing group convolutions or other symmetry-aware layers. A key benefit is improved generalization ability and robustness, reducing reliance on extensive data augmentation strategies to cover various orientations during training. Furthermore, SE(3) equivariance can simplify downstream tasks that utilize these keypoints, as consistent transformations reduce the need for extra pose-correction steps.
Future: Adaptive K#
The heading ‘Future: Adaptive K’ suggests a direction for future research focusing on the dynamic adjustment of the number of keypoints detected. Current methods often require pre-defining ‘K’, limiting adaptability to diverse object shapes and levels of detail. An adaptive approach would allow the model to intelligently determine the optimal number of keypoints based on the input data’s complexity and features. This could significantly improve performance on objects with varying levels of detail or those experiencing substantial deformations, enhancing the model’s robustness and generalization capabilities. This would address limitations of existing approaches which may struggle to generalize across various object categories and shapes due to the fixed ‘K’ constraint. Further research in this area could explore techniques like attention mechanisms or hierarchical clustering to achieve dynamic keypoint selection.
More visual insights#
More on figures
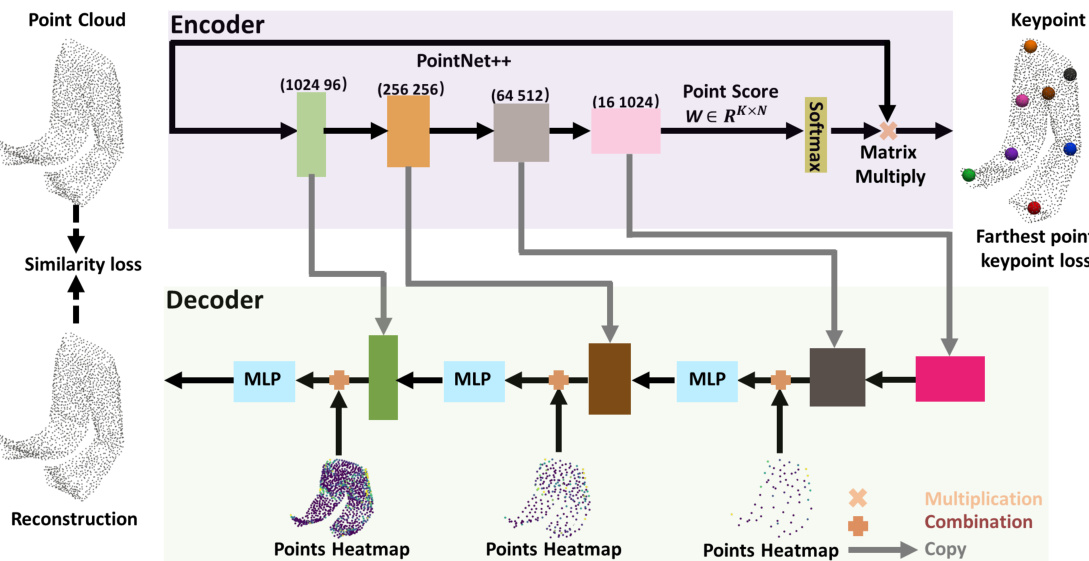
This figure illustrates the overall architecture of the Key-Grid model. The encoder uses PointNet++ to predict keypoints and their corresponding weights, while the decoder utilizes these keypoints and their associated features to reconstruct the 3D point cloud. The key innovation is the use of a grid heatmap, which encodes the keypoint relationships in a dense 3D feature map that helps the decoder reconstruct the shape, especially when dealing with deformable objects.
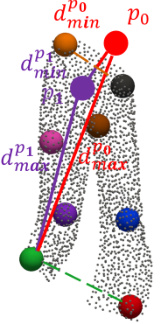
The figure illustrates the concept of using maximum distance instead of minimum distance to compute features in the grid heatmap. It highlights that using minimum distance may not effectively distinguish between points inside and outside an object, whereas maximum distance provides a clearer distinction. Specifically, it shows that the minimum distance between a grid point (p1) inside the pants and the skeleton is the same as that between a grid point (p0) outside the pants and the skeleton. However, using maximum distance, the value for p1 is less than the value for p0, clearly differentiating their positions relative to the object.
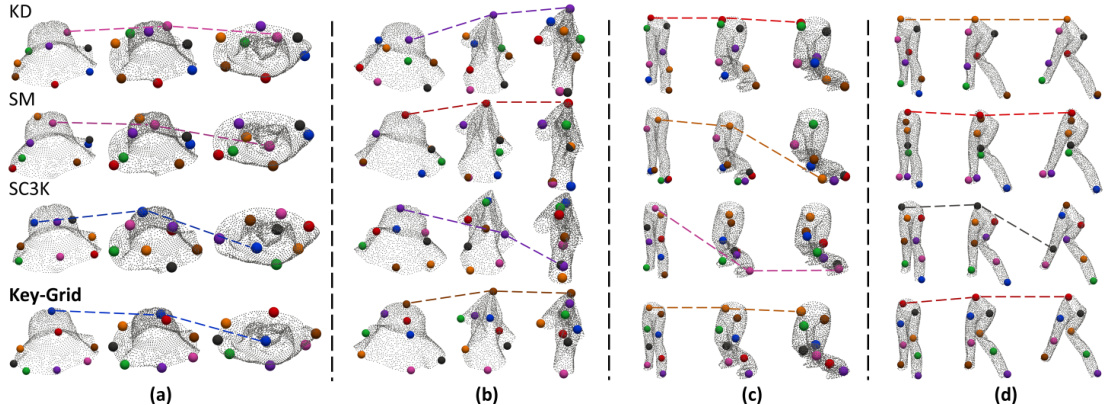
This figure compares the performance of four different keypoint detection methods (KD, SM, SC3K, and Key-Grid) on two clothing items (Hat and Long Pant) undergoing dropping and dragging deformations. The images show the detected keypoints on the objects at various stages of deformation. Lines connect corresponding keypoints across different deformation stages to highlight their movement and preservation of semantic meaning.
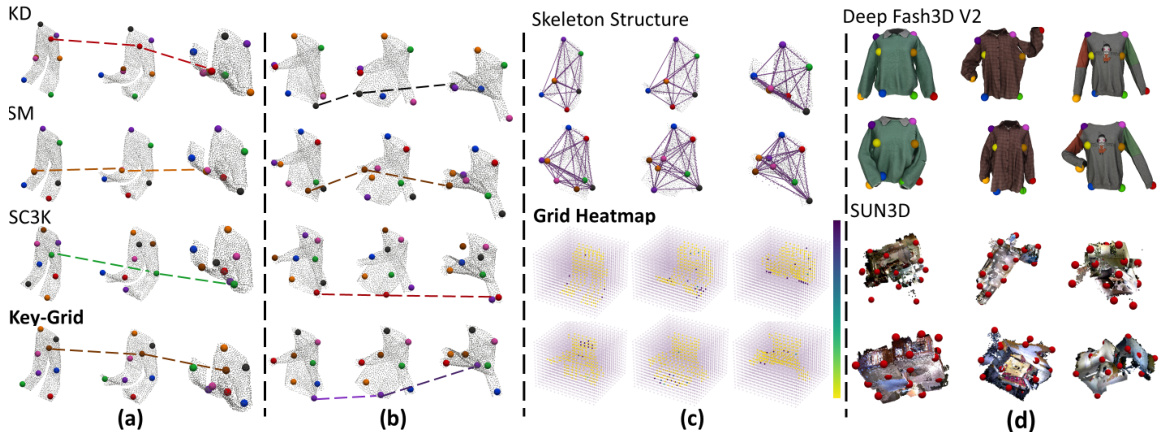
This figure visualizes keypoint detection results on folded clothes using different methods, including Key-Grid, Skeleton Merger (SM), KeypointDeformer (KD), and SC3K. Subfigures (a) and (b) compare the keypoint locations across methods during a folding deformation. (c) shows a comparison of the grid heatmap and skeleton structure representations used by Key-Grid and SM, respectively. Finally, (d) displays keypoint detection on more complex datasets (DeepFashion3D V2 and SUN3D).
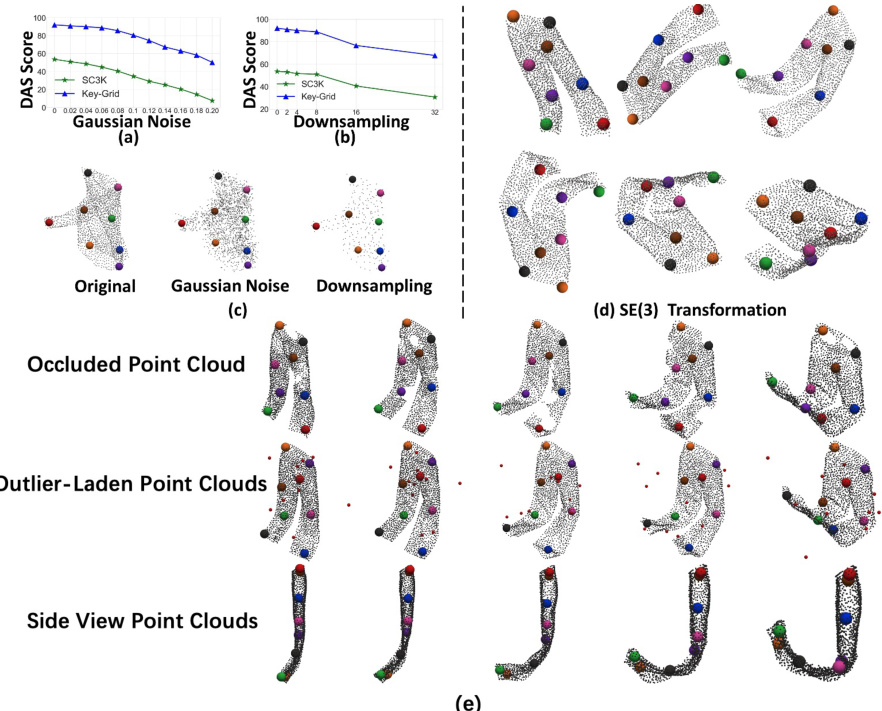
This figure demonstrates the robustness of the Key-Grid model to various types of noise and data corruptions. Subfigures (a) and (b) show the Dual Alignment Score (DAS) results under increasing levels of Gaussian noise and downsampling, respectively. Subfigure (c) shows visualizations illustrating the keypoint detection performance under these conditions. Subfigure (d) shows the results of SE(3)-equivariant keypoints. Subfigure (e) visualizes the impact of occlusions, outliers, and different viewpoints.
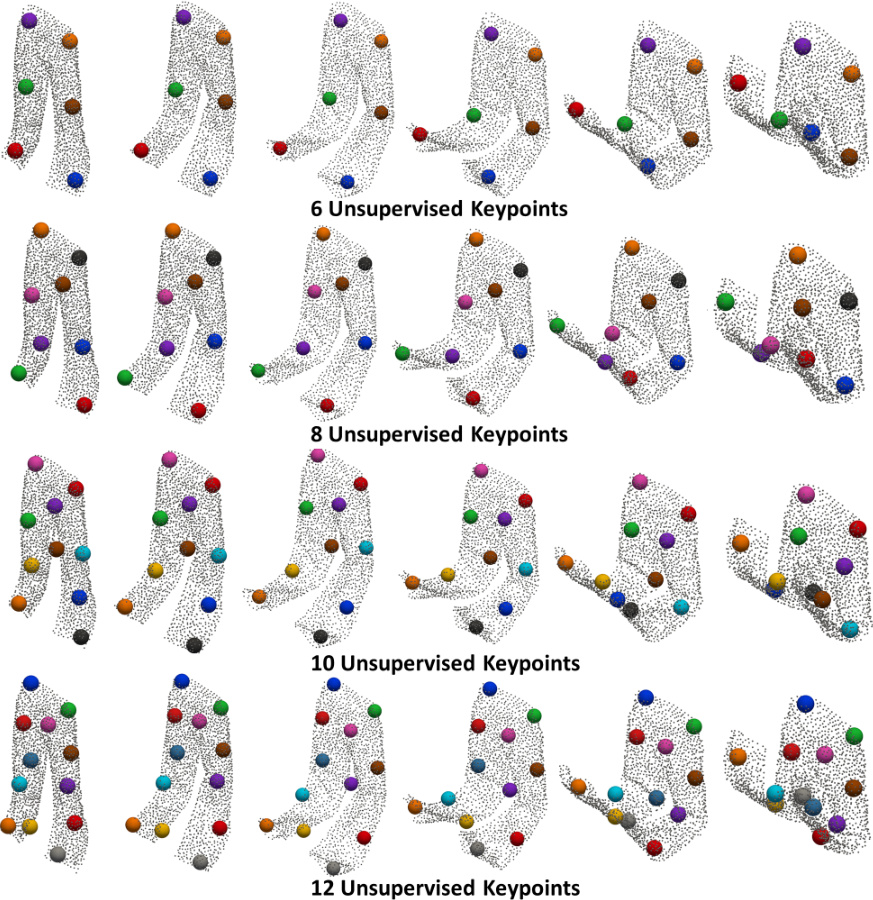
This figure shows the results of Key-Grid’s keypoint detection on folded pants with varying numbers of keypoints (6, 8, 10, and 12). Each row displays the detected keypoints on multiple instances of folded pants, demonstrating that the keypoints consistently locate at semantically meaningful positions across different folding configurations. The consistent keypoint positions, even with shape variations, showcase the method’s robustness and ability to capture meaningful structural information about deformable objects.
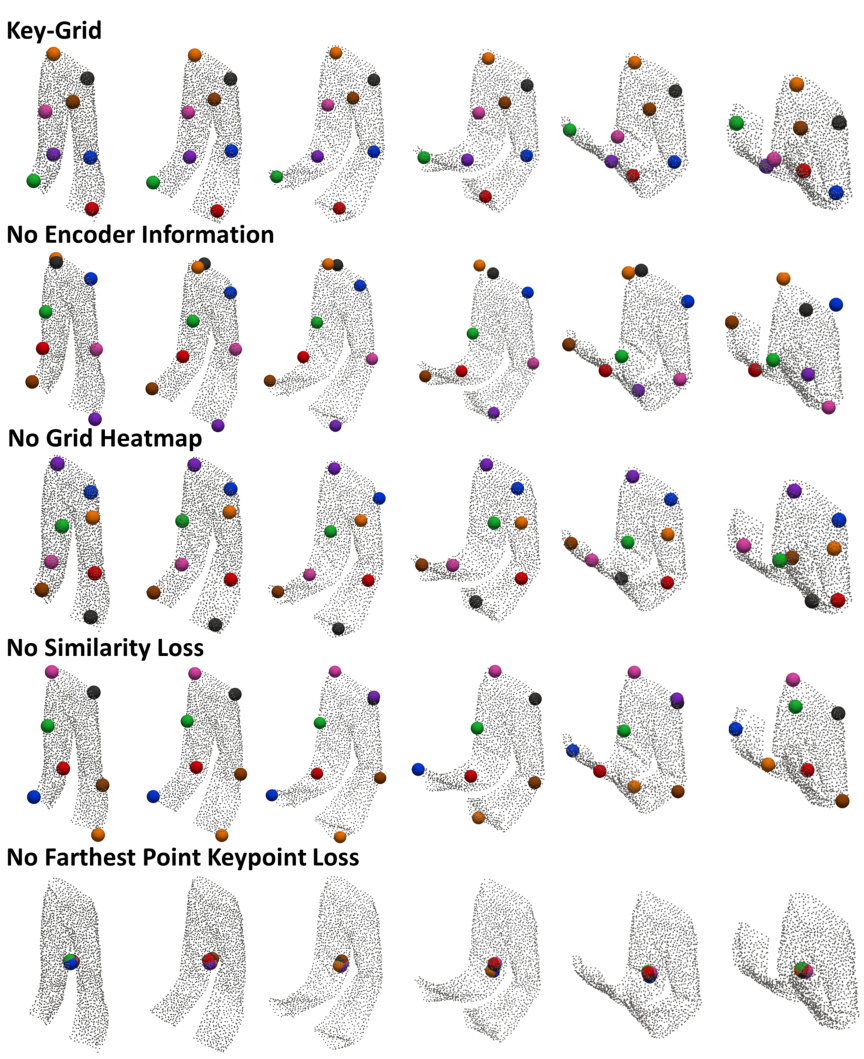
This figure visualizes the results of an ablation study conducted on a folded pants dataset. The study investigated the impact of removing different components of the Key-Grid model, such as encoder information, grid heatmap, similarity loss, and farthest point keypoint loss. Each row shows the keypoint detection results when one component was removed, demonstrating the importance of each part in achieving accurate and consistent keypoint localization.
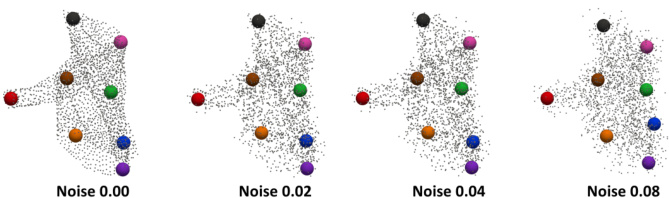
This figure shows the robustness of Key-Grid to Gaussian noise. Four visualizations are presented, each showing the detected keypoints on a point cloud with increasing levels of added Gaussian noise (Noise 0.00, Noise 0.02, Noise 0.04, Noise 0.08). Noise 0.00 represents the original point cloud without added noise. The keypoints maintain their positions despite the presence of increasing noise, illustrating the algorithm’s robustness.
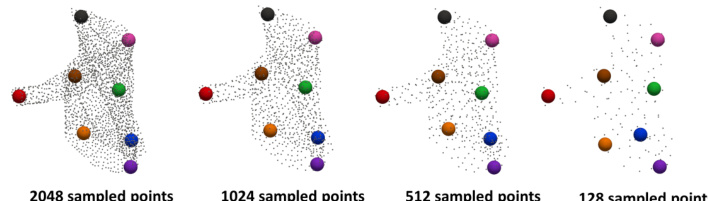
This figure demonstrates the robustness of Key-Grid to downsampling. It shows the detected keypoints on a folded pant point cloud downsampled to 1024, 512, and 128 points. The keypoints maintain reasonable accuracy and consistency even with significant reduction in the number of points.

This figure showcases the robustness of the Key-Grid model in detecting 3D keypoints across various shape variations and deformations. The top row shows examples of rigid-body objects from the ShapeNetCoreV2 dataset, demonstrating consistent keypoint detection despite significant shape differences within the same object category. The bottom row displays examples of deformable objects from the ClothesNet dataset, highlighting the model’s ability to maintain semantic consistency even with significant deformations. The consistent keypoint locations across different poses illustrate the method’s effectiveness.
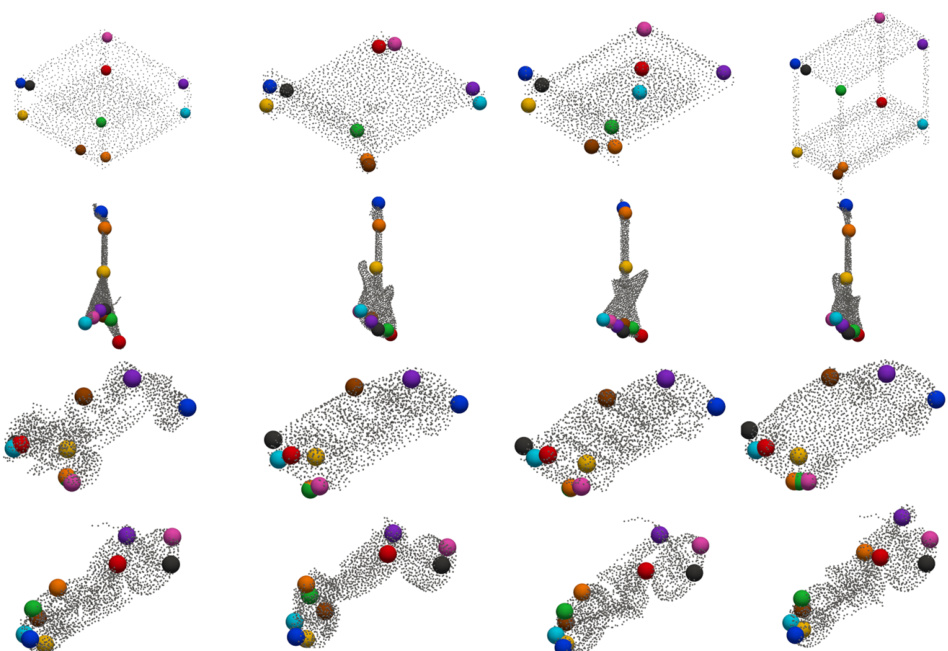
This figure compares the keypoint detection results of the Skeleton Merger (SM) method and the proposed Key-Grid method on four different categories of objects from the ShapeNetCoreV2 dataset: Bed, Guitar, Car, and Motorcycle. Each category shows four different instances or viewpoints of the object, demonstrating the ability of each method to locate keypoints consistently across variations in shape and orientation. The colored spheres represent the detected keypoints. By comparing the keypoint locations across both methods for each object, one can visually assess the accuracy and consistency of each keypoint detection approach on rigid objects.
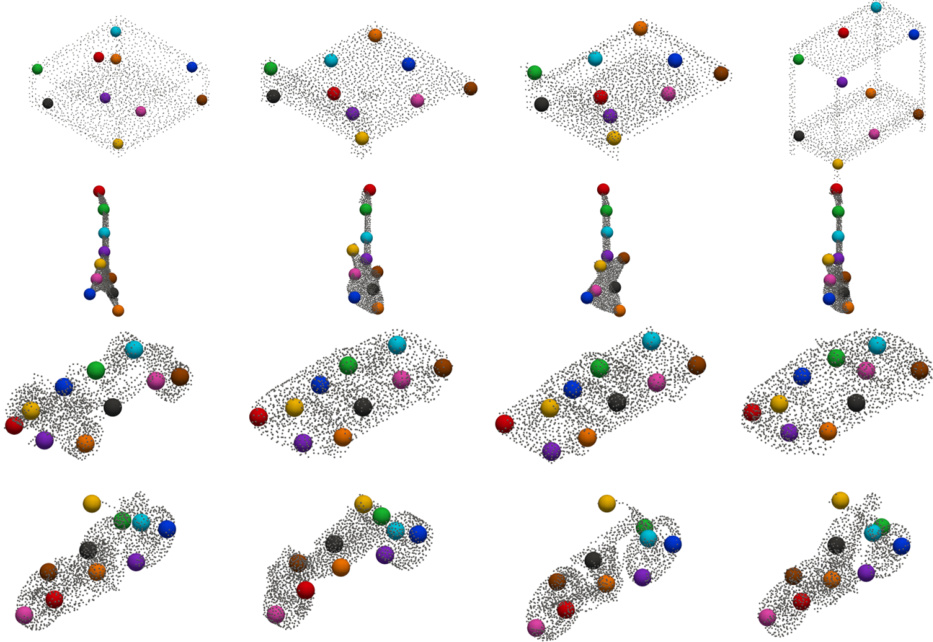
This figure shows examples of 3D keypoint detection results obtained using the proposed Key-Grid method. The top row demonstrates the method’s ability to maintain consistent keypoint locations across various poses of rigid objects (ShapeNetCoreV2 dataset). The bottom row showcases the method’s robustness in handling significant deformations of soft objects (ClothesNet dataset), highlighting the preservation of semantic keypoint consistency even under drastic shape changes.
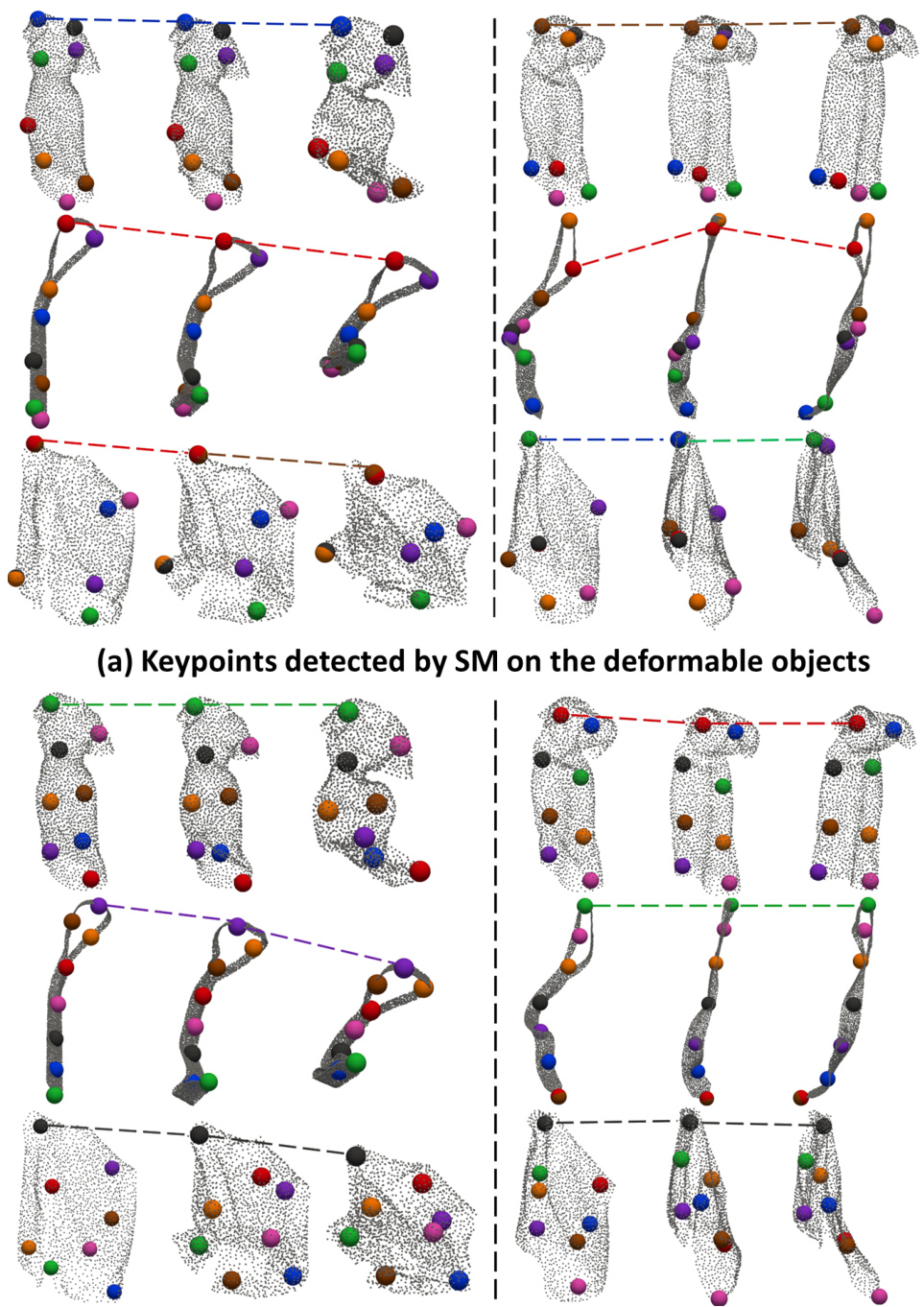
This figure compares the keypoint detection results of Skeleton Merger (SM) and Key-Grid on deformable objects from the ClothesNet dataset. The left column shows results using SM, and the right column shows results using Key-Grid. Both methods are shown for ‘Long Dress’, ‘Tie’, and ‘Vest’ categories under ‘drop’ and ‘drag’ deformations. Lines connect corresponding keypoints across different deformation stages to illustrate their consistency (or lack thereof). The figure highlights Key-Grid’s superior performance in maintaining keypoint semantic consistency during significant shape changes.
More on tables

This table compares the performance of Key-Grid against other state-of-the-art (SOTA) methods on the ClothesNet dataset, focusing on the Dual Alignment Score (DAS) metric for 8 keypoints. It shows the DAS for 13 clothing categories under two types of deformation: dropping and dragging. Higher DAS values indicate better performance in maintaining semantic consistency of keypoints during deformation.
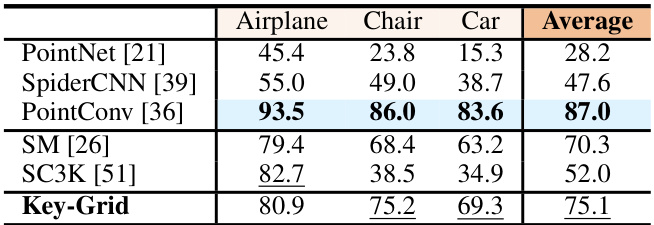
This table compares the mean Intersection over Union (mIoU) scores achieved by Key-Grid and several supervised keypoint detection methods on the KeypointNet dataset. The mIoU metric evaluates the accuracy of keypoint localization. The table shows the performance for three specific categories of objects (Airplane, Chair, Car) and an average across these categories.

This table compares the performance of Key-Grid and other methods on the ClothesNet dataset for folded clothes, under both normal placement and SE(3) transformation. It shows the Dual Alignment Score (DAS) for each method, indicating the semantic consistency of detected keypoints. The results demonstrate that Key-Grid achieves significantly higher DAS values compared to other methods, particularly in cases of significant deformations like folding, highlighting its robustness to shape changes and its ability to maintain semantic consistency of keypoints even under SE(3) transformations.

This table presents the results of an ablation study conducted to evaluate the impact of different components of the Key-Grid model on its performance. The study examines the contribution of the encoder information, grid heatmap, similarity loss, and farthest point loss. Results are shown as DAS scores (Dual Alignment Score) for the ShapeNetCoreV2 and ClothesNet datasets, and for different categories within each dataset (Airplane, Chair, Folded Shirt, Folded Pant). The table helps to demonstrate which component contributes most significantly to the model’s accuracy in keypoint detection.

This table compares the performance of the proposed Key-Grid model against three state-of-the-art (SOTA) methods (KD, SM, SC3K) on the ShapeNetCoreV2 dataset. The evaluation metrics used are Dual Alignment Score (DAS) and mean Intersection over Union (mIoU). DAS measures the semantic consistency of detected keypoints, while mIoU assesses the accuracy of keypoint localization. The table shows that Key-Grid achieves superior performance in both metrics compared to the SOTA methods.
Full paper#