↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing dynamics modeling methods in visual reinforcement learning struggle with the complexities of multiple input modalities, often overlooking the interplay between modality-correlated and distinct features. These features, though different, are equally crucial for understanding the environment’s dynamics but are usually treated inconsistently, reducing effectiveness.
The proposed Dissected Dynamics Modeling (DDM) method tackles this issue by explicitly separating and processing modality-consistent and inconsistent features through distinct pathways. This divide-and-conquer strategy provides implicit regularizations during training. Further, a reward prediction function is added to maintain information integrity and reduce distractions. Extensive experiments demonstrate DDM’s superior performance in multi-modal scenarios, showcasing its effectiveness in learning more accurately and robustly.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-modal visual reinforcement learning. It directly addresses the challenge of effective dynamics modeling with multiple modalities, offering a novel solution that significantly improves learning efficiency and robustness. The findings will be highly valuable for developing advanced AI agents capable of complex decision-making in dynamic visual environments and open up new avenues for research in multi-modal representation learning and improved data handling. DDM’s divide-and-conquer strategy and reward predictive function provide valuable techniques for future multi-modal RL research.
Visual Insights#
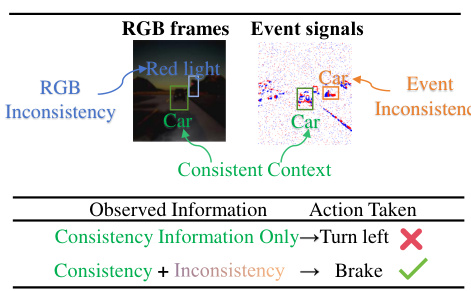
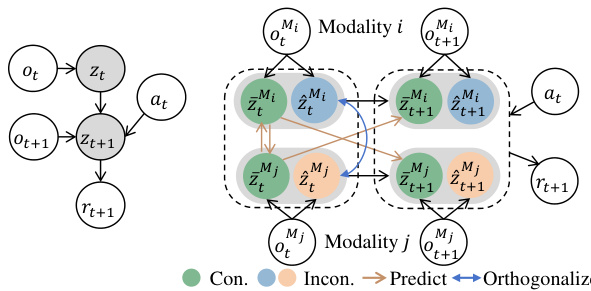
This figure illustrates the core idea behind the proposed Dissected Dynamics Modeling (DDM) method and compares it to the single-modality DeepMDP approach. Panel (a) shows a multi-modal scenario (RGB images and event signals) where different modalities share some consistent information (e.g., presence of a car) but also have unique observations (e.g., a red light visible only in the RGB image, a car in the dark only visible in event signals). These inconsistencies are crucial for effective decision-making. Panel (b) contrasts DDM with DeepMDP; DDM explicitly separates consistent and inconsistent information within each modality, using separate pathways to model environmental dynamics, whereas DeepMDP does not make this distinction.
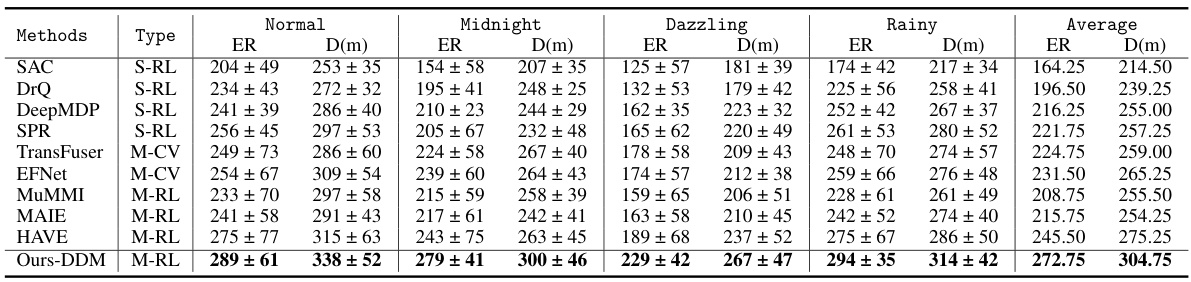
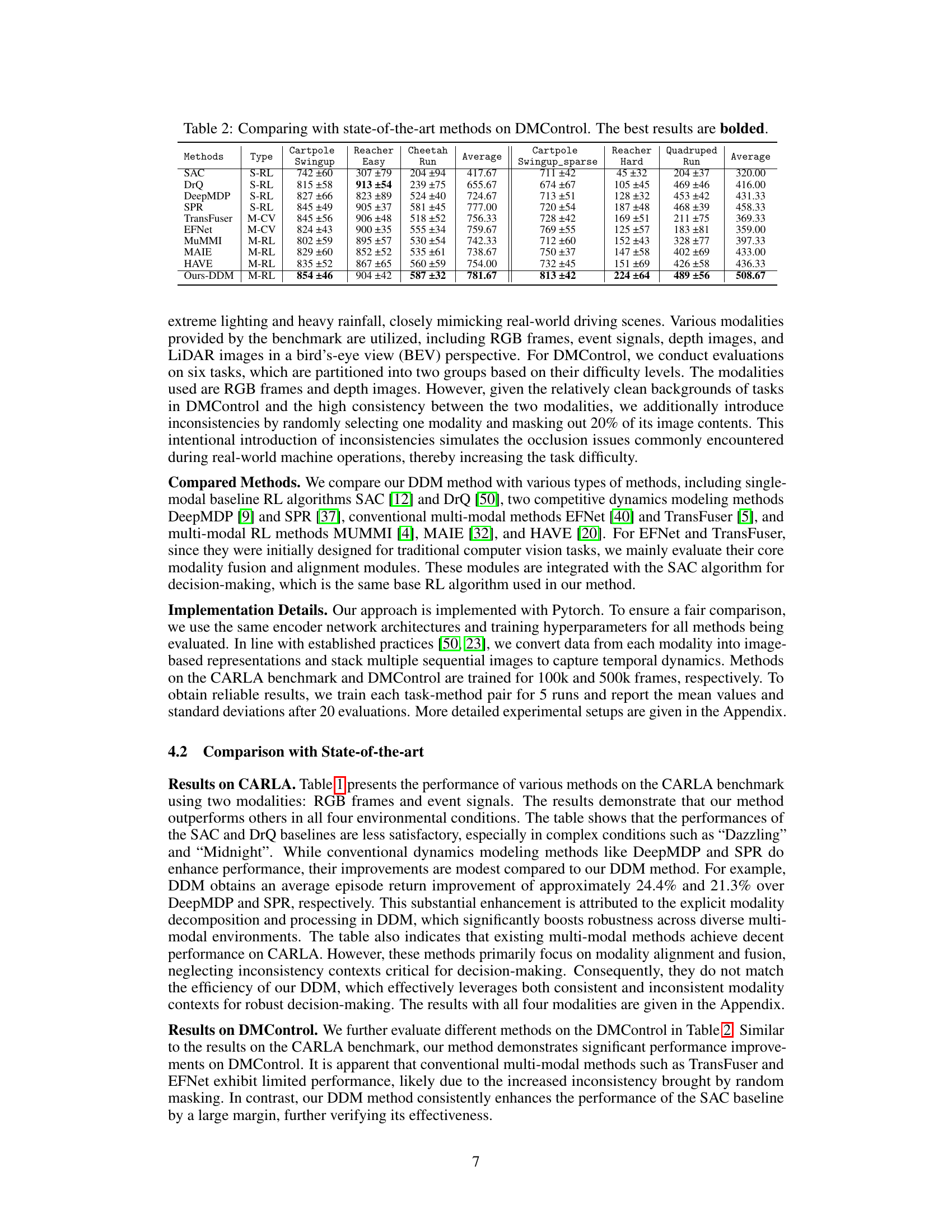
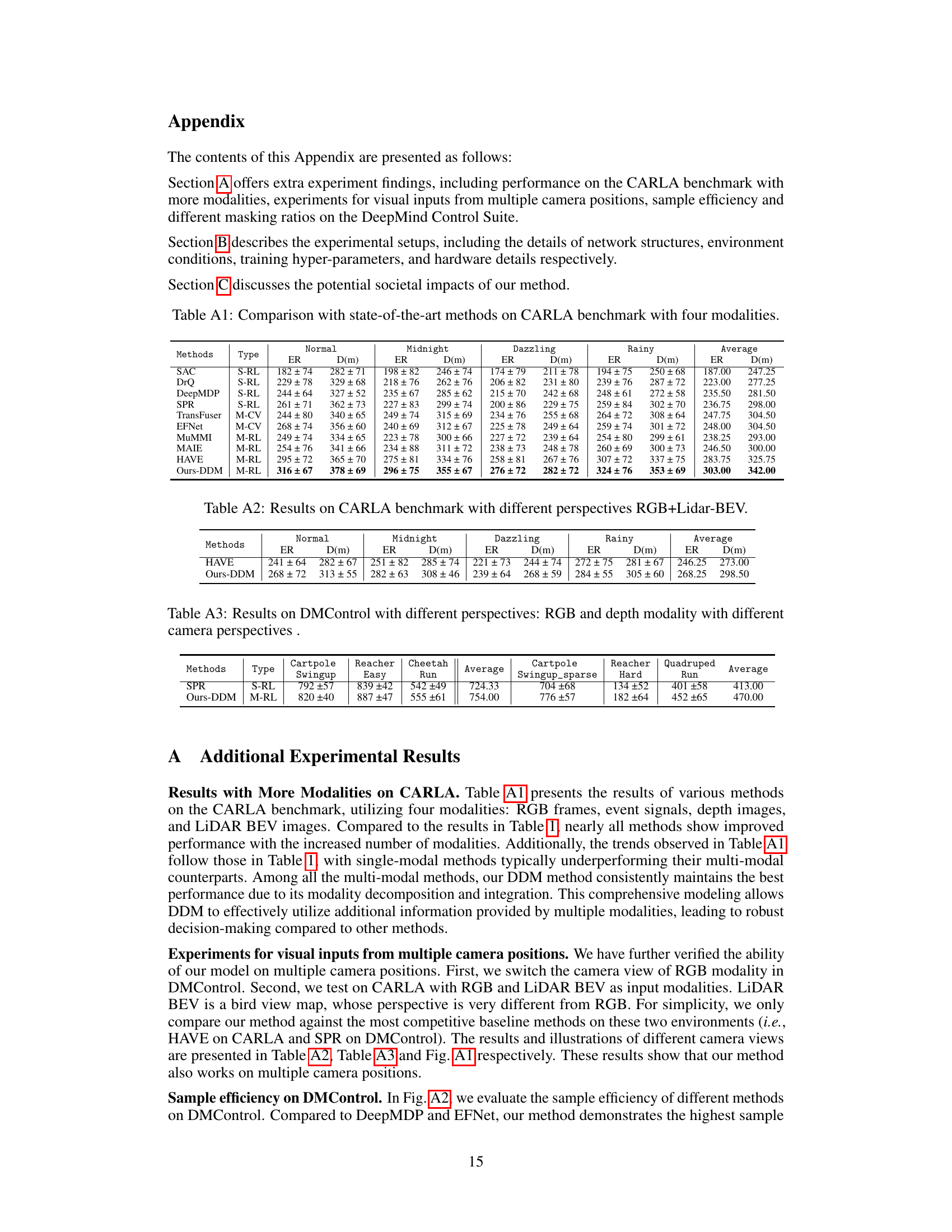
This table compares the performance of the proposed DDM method against various state-of-the-art single-modality and multi-modal reinforcement learning methods on the CARLA driving simulation benchmark. It evaluates performance across four challenging driving scenarios: Normal, Midnight, Dazzling, and Rainy. The results show episode return (ER) and driving distance (D(m)), with the best performance in each condition shown in bold. The table helps illustrate the improved performance of the proposed method over existing techniques.
In-depth insights#
Multimodal Dynamics#
Multimodal dynamics modeling in reinforcement learning (RL) presents a significant challenge due to the complex interplay between different modalities. Successfully integrating information from various sources (e.g., RGB images, event cameras, LiDAR), while accounting for their inherent heterogeneity, is crucial for effective state representation and decision-making. A key aspect is addressing the variability and volatility of relationships between modalities, which often evolve dynamically within the environment. Strategies to capture both commonalities and differences across modalities are necessary, recognizing that consistent and inconsistent information play distinct yet equally important roles in reflecting environmental dynamics. Effectively disentangling these aspects through techniques like feature decomposition or attention mechanisms can improve model accuracy and robustness. A promising approach involves explicitly modeling consistent and inconsistent information along separate pathways, utilizing methods like mutual prediction and orthogonality constraints to refine feature representations and reduce interference. Finally, the integration of a reward predictive function helps filter task-irrelevant information, improving decision-making accuracy and overall RL performance.
DDM Methodology#
The Dissected Dynamics Modeling (DDM) methodology, as described in the provided text, presents a novel approach to multi-modal visual reinforcement learning (RL). DDM’s core innovation lies in its ability to disentangle consistent and inconsistent information across different modalities. Unlike traditional methods that struggle with modality heterogeneity, DDM explicitly separates these components, routing them through distinct processing pathways. This divide-and-conquer strategy facilitates a more precise understanding of environmental dynamics. The consistent information, indicative of shared scene descriptions, is used to build a cohesive environmental model, while inconsistent information, representing unique observations from each modality, is used to refine modality-specific state changes. Further enhancing DDM’s effectiveness is the integration of a reward predictive function, which filters out irrelevant information, ensuring that both consistent and inconsistent features are task-relevant. This approach achieves competitive performance in challenging multi-modal visual RL environments by leveraging the complementary strengths of shared and unique information, a key improvement over prior methods.
Modality Deconstruction#
Modality deconstruction, in the context of multi-modal visual reinforcement learning, involves intelligently separating and analyzing individual modalities within a complex data set. This goes beyond simple concatenation; it requires understanding the interplay between consistent and inconsistent information across different sensory inputs (e.g., RGB images, event data). Consistent information represents shared contextual features, providing a cohesive view of the environment. Inconsistent information, however, offers unique, modality-specific insights, which are often crucial for task completion but easily overlooked in standard fusion techniques. Effective deconstruction necessitates the development of methods that isolate and leverage both aspects, enabling the model to build a more comprehensive understanding than if the modalities were simply merged. This approach is particularly valuable in dynamic environments where the relationships between modalities might be volatile and non-linear.
Ablation Experiments#
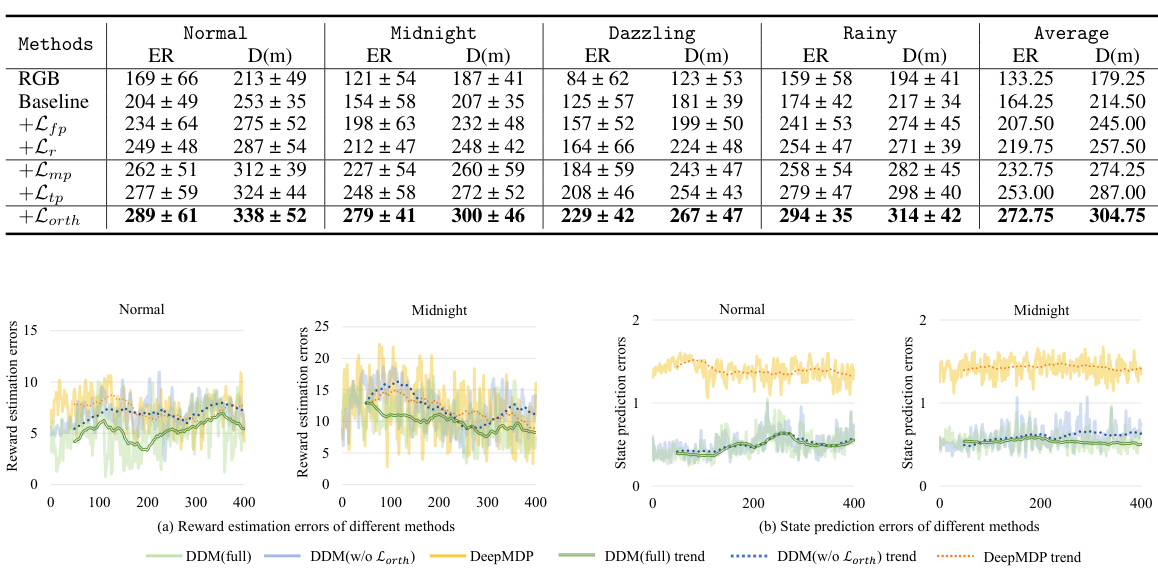
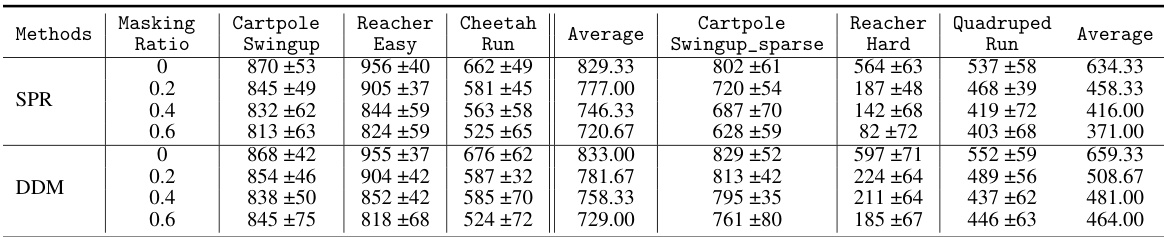
Ablation experiments systematically investigate the contribution of individual components within a complex model. By progressively removing or altering parts of the model, researchers can isolate the impact of specific features, techniques, or modules. In the context of a research paper, ablation studies are crucial for demonstrating the efficacy of novel components by showing a performance drop when those components are removed. A well-designed ablation study should systematically remove or modify individual parts to avoid confounding factors. For example, in a multi-modal model, the impact of each modality can be separately assessed by removing the modality and observing the performance change. Such results are vital for confirming that the proposed improvements are not simply due to other parts of the model or dataset. Ablation studies are valuable to determine the impact of each component and overall model architecture, strengthening the overall conclusions and showing the relative importance of different components, allowing for more informed design choices and refinements in future work.
Future Directions#
The paper’s ‘Future Directions’ section would ideally explore several key areas. Extending DDM to handle more complex scenarios is crucial; this includes handling noisy or incomplete data, as well as incorporating more diverse modalities (e.g., audio, textual information) beyond RGB and event signals. Addressing the limitations of the current method, such as the lack of integrated planning mechanisms, is important. Incorporating such mechanisms would enhance performance in complex environments. A significant improvement would involve creating more robust state representations that are less sensitive to noise and variations in the environment. This section could also discuss the scalability of the DDM model, particularly for high-dimensional inputs or a very large number of modalities. Finally, a thorough exploration of the potential societal impacts of DDM, including both positive and negative implications, is essential. This should discuss potential mitigation strategies for negative impacts, and propose guidelines for ethical considerations in future research and development.
More visual insights#
More on figures
This figure illustrates the architecture of the proposed Dissected Dynamics Modeling (DDM) method. It shows how multiple input modalities (e.g., RGB images and event camera data) are first processed by separate observation encoders. These encoders extract both modality-consistent and modality-inconsistent features. The consistent features, representing shared information across modalities, are used in a mutual predictive process to refine feature quality and ensure consistency across time steps. The inconsistent features, which capture modality-specific information, are processed separately to model the unique dynamics of each modality. Finally, the refined consistent and inconsistent features are combined to form the state representation used for robust policy learning.
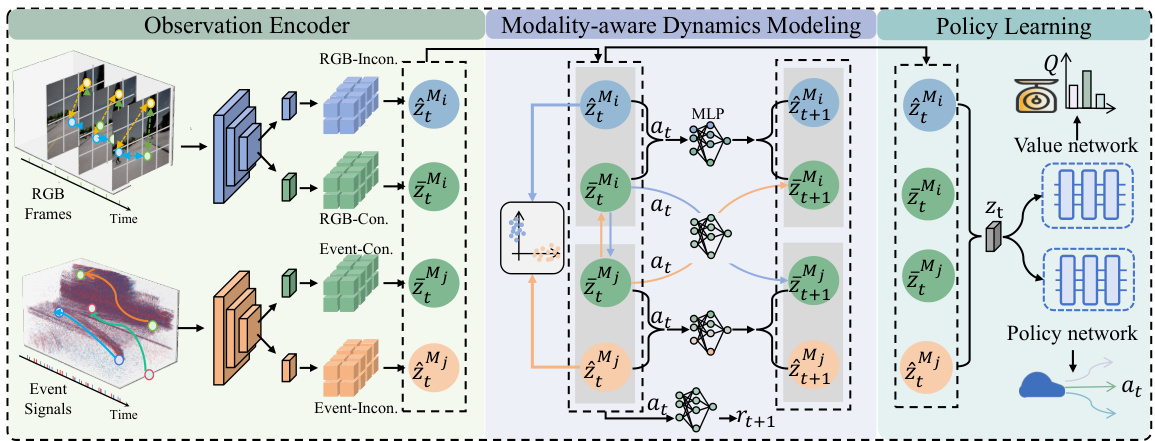
This figure illustrates the architecture of the Dissected Dynamics Modeling (DDM) method. It shows how multiple input modalities (e.g., RGB frames and event signals) are first processed by separate observation encoders to extract both modality-consistent and modality-inconsistent features. These features are then fed into distinct pathways within the modality-aware dynamics modeling component, where consistent features are used to predict future states and inconsistent features contribute to modality-specific dynamics. Finally, the processed features are combined to form state representations, which are used for policy learning in a reinforcement learning context. The figure highlights the method’s unique approach of separating consistent and inconsistent information across modalities to improve the accuracy and robustness of the dynamics model.
This figure illustrates the DDM method’s architecture. Visual input modalities (e.g., RGB frames and event signals) are initially processed through separate observation encoders. These encoders extract both modality-consistent (common across modalities) and modality-inconsistent (unique to each modality) features. These features are then fed into distinct dynamics modeling pathways. Consistent features undergo mutual predictive constraints to ensure information coherence across modalities and over time. Inconsistent features undergo orthogonalization to highlight their unique information. Finally, a reward predictive function filters task-irrelevant information from both consistent and inconsistent features. The resulting combined features, representing the state, are used for policy learning.
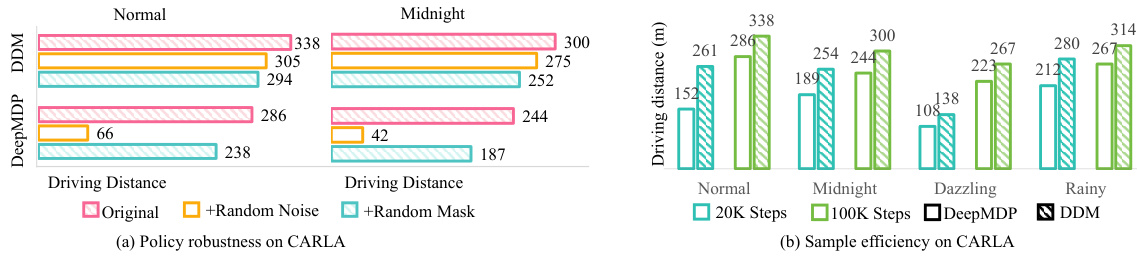
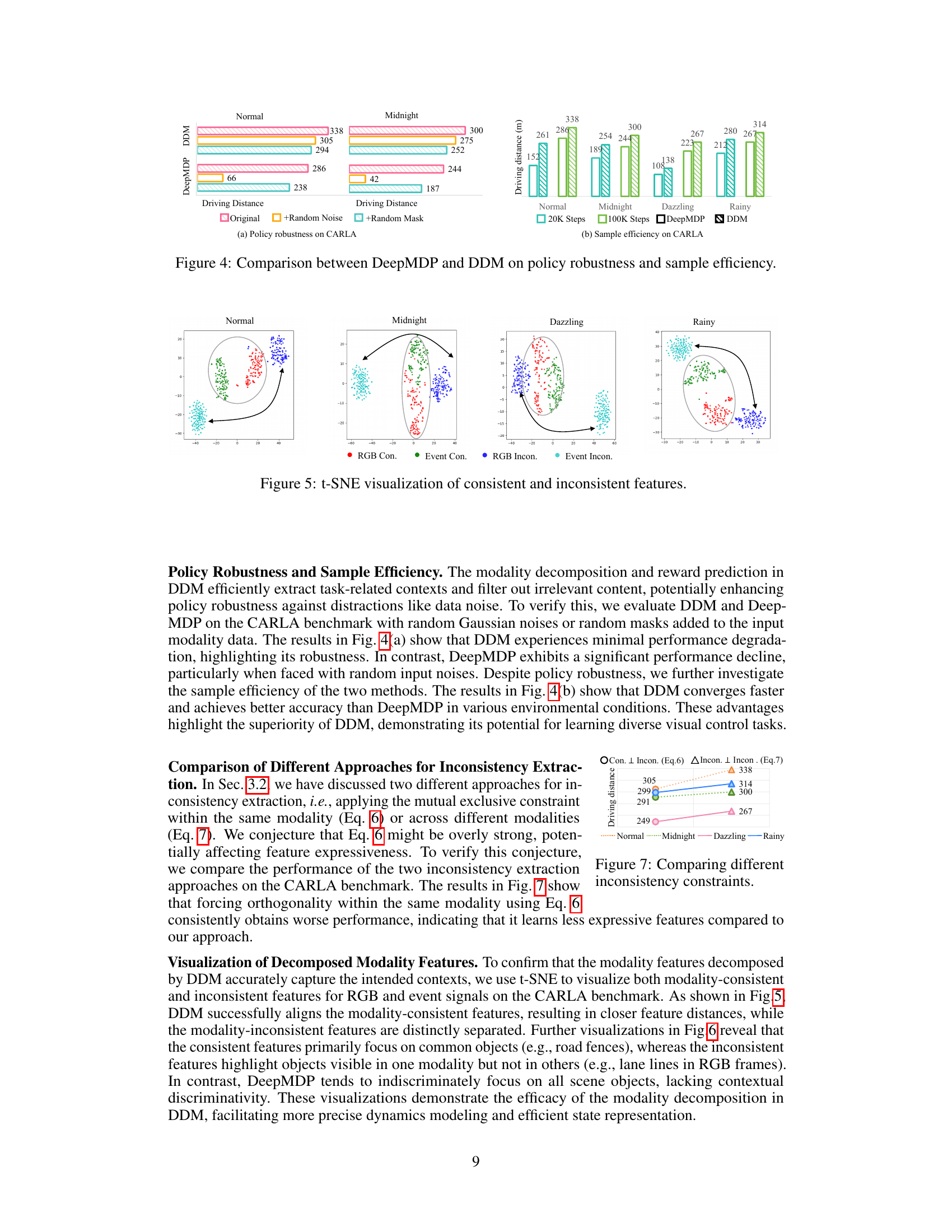
This figure compares the performance of DeepMDP and DDM in terms of policy robustness and sample efficiency under various conditions on the CARLA benchmark. The left panel (a) shows the driving distance achieved by each method under normal conditions, as well as when random noise and random masks are added to the input data. This demonstrates the robustness of DDM against these distractions. The right panel (b) illustrates the sample efficiency, showing that DDM converges faster and achieves better driving distance with fewer training steps compared to DeepMDP, particularly in more challenging conditions like ‘Midnight’, ‘Dazzling’, and ‘Rainy’.
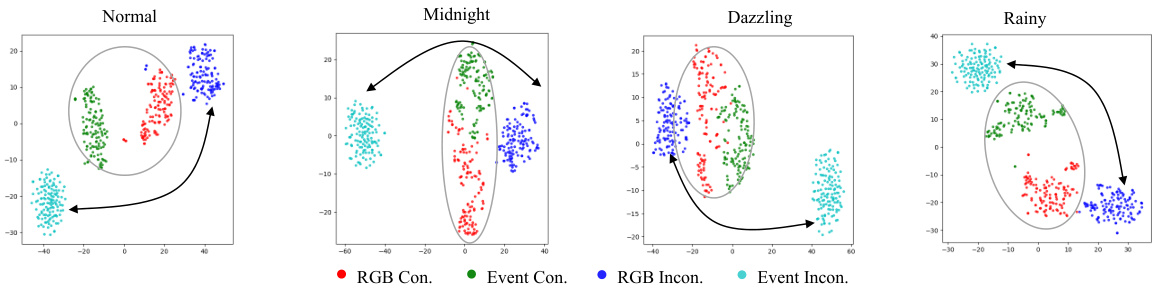
This figure visualizes the results of t-SNE dimensionality reduction applied separately to the consistent and inconsistent features extracted by the DDM method for RGB and event modalities under four different weather conditions in the CARLA driving simulator. Each point represents a feature vector. The clustering of points within each modality suggests that DDM effectively separates features representing shared information across modalities (consistent) from those representing modality-specific information (inconsistent). The separation of consistent and inconsistent features highlights DDM’s ability to disentangle shared and unique information from different sensory inputs, thereby enhancing the accuracy of the environmental dynamics model.
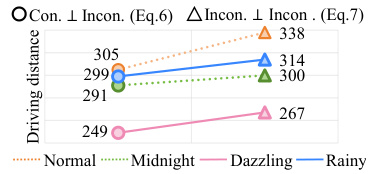
This figure compares the performance of two different methods for handling inconsistencies between modalities in multi-modal visual reinforcement learning. The x-axis represents different weather conditions (Normal, Midnight, Dazzling, Rainy) in the CARLA driving simulator, and the y-axis represents the driving distance achieved. Two approaches are compared: one enforcing mutual exclusivity between consistent and inconsistent features within the same modality (Con. ⊥ Incon. (Eq.6)), and the other enforcing orthogonality between inconsistent features across different modalities (Incon. ⊥ Incon. (Eq.7)). The results show that the latter approach generally achieves better performance across varying conditions. This demonstrates that the proposed orthogonality constraint (Eq.7) is more effective at extracting unique information from each modality while avoiding over-regularization and decreased feature expressiveness.
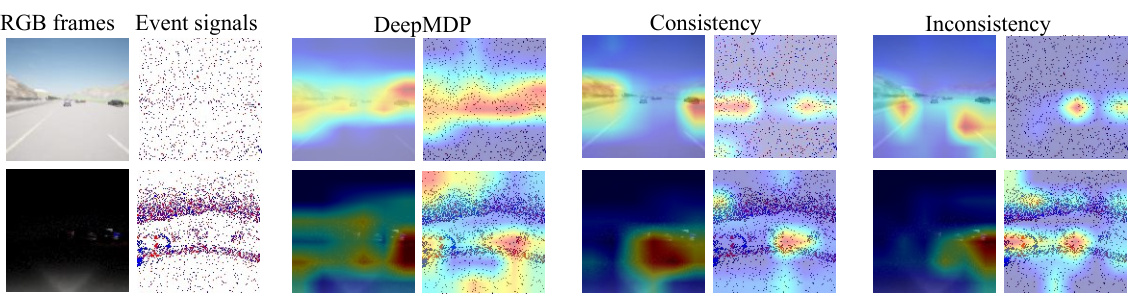
This figure visualizes feature heatmaps generated by the Dissected Dynamics Modeling (DDM) method under normal and midnight driving conditions in the CARLA simulator. The heatmaps illustrate the learned feature representations for RGB frames and event signals, showing how DDM separates consistent and inconsistent information across modalities. The top row represents a scene during the day, while the bottom row displays the same scene at night. The figure highlights how DDM effectively extracts common features across modalities (consistency) while also identifying modality-specific features (inconsistency). This ability to disentangle shared and unique information across different sensor inputs is a key contribution of the DDM method.

This figure illustrates the architecture of the Dissected Dynamics Modeling (DDM) method. Visual modalities (e.g., RGB frames and event signals) are first processed by separate observation encoders. These encoders partition the features into modality-consistent and modality-inconsistent components. The consistent features, representing shared information, undergo a modality-aware dynamics modeling process to capture common scene dynamics. In contrast, the inconsistent features, which contain modality-specific information, are processed through separate dynamics modeling pathways. Finally, these optimized consistent and inconsistent features are merged to create a robust state representation, used for policy learning in reinforcement learning.
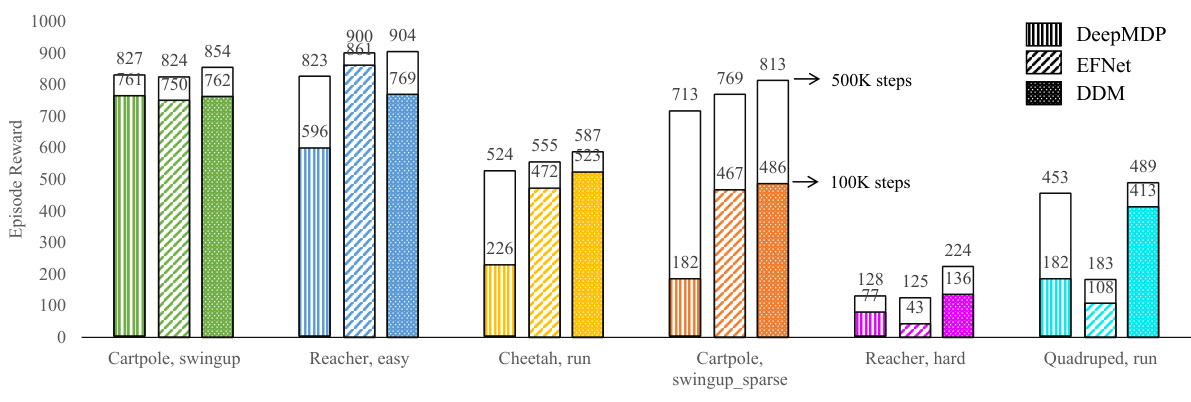
This figure demonstrates the sample efficiency of three different methods (DeepMDP, EFNet, and DDM) on six different tasks within the DMControl environment. Each bar represents the average episode reward achieved by each method after training for either 100,000 or 500,000 steps. The results show that DDM generally requires fewer training steps to achieve high rewards compared to the other two methods.

This figure shows a comparison of RGB frames and event signals under four different weather conditions in the CARLA driving simulator. The top row displays RGB images, showcasing the visual scene under normal daylight, nighttime (Midnight), strong sunlight (Dazzling), and heavy rain. The bottom row shows corresponding event camera data, which highlights changes in brightness and motion in a distinctive visual representation.
More on tables
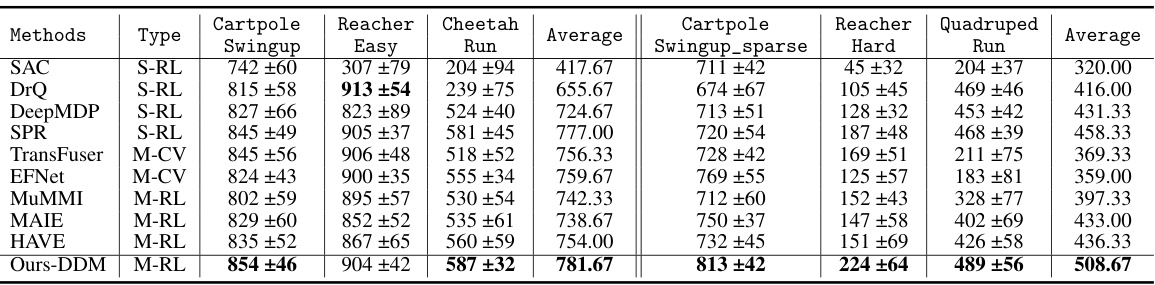
This table presents a comparison of the proposed DDM method against several state-of-the-art methods on the DeepMind Control Suite benchmark. It shows the average performance across six different control tasks (three easy and three hard) for each method, including SAC, DrQ, DeepMDP, SPR, TransFuser, EFNet, MuMMI, MAIE, HAVE, and the authors’ DDM method. The results are reported as mean ± standard deviation, with the best performance for each task bolded. The table demonstrates the superior performance of the DDM method across all tasks, especially on more challenging tasks.
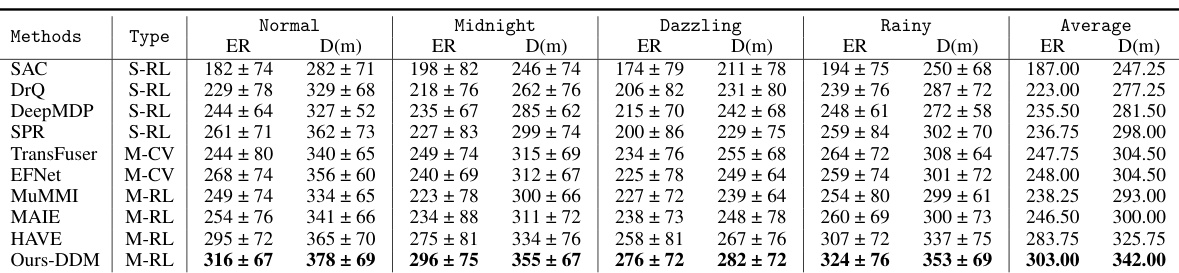
This table compares the performance of the proposed Dissected Dynamics Modeling (DDM) method against several state-of-the-art single-modality and multi-modality reinforcement learning methods on the CARLA autonomous driving benchmark. The comparison is done under four different driving conditions (Normal, Midnight, Dazzling, Rainy). The results are presented as the average episode return (ER) and the average driving distance (D(m)) in meters. The best performance in each condition is highlighted in bold.

This table presents a comparison of the performance of different methods on the CARLA benchmark using two modalities: RGB frames and LiDAR BEV images. The results demonstrate the effectiveness of the proposed method (Ours-DDM) in achieving higher episode return (ER) and driving distance (D(m)) across various driving conditions compared to other state-of-the-art methods. The experiment demonstrates improved results over using single-modality or multi-modality approaches that do not explicitly model environmental dynamics.

This table presents a comparison of the proposed Dissected Dynamics Modeling (DDM) method with several state-of-the-art methods on the DeepMind Control (DMControl) suite. The comparison is performed across six robotic control tasks, divided into two groups based on difficulty level (easy and hard). For each task, the table shows the average performance of each method in terms of episode reward, broken down by modality and task type. The best performing method for each task and modality is highlighted in bold.
This table compares the performance of the proposed DDM method against several state-of-the-art single-modality and multi-modal reinforcement learning methods on the CARLA autonomous driving benchmark. It evaluates performance across four challenging driving scenarios (Normal, Midnight, Dazzling, Rainy) using two metrics: episode return (ER) and driving distance (D(m)). The table distinguishes between single-modality reinforcement learning (S-RL), multi-modal computer vision (M-CV), and multi-modal reinforcement learning (M-RL) methods. The best results for each metric and scenario are highlighted in bold.

This table compares the proposed Dissected Dynamics Modeling (DDM) method against various state-of-the-art methods on the CARLA autonomous driving benchmark. The comparison includes single-modality reinforcement learning (S-RL) methods, multi-modal computer vision (M-CV) methods, and multi-modal reinforcement learning (M-RL) methods. The performance is evaluated under four different weather conditions (Normal, Midnight, Dazzling, Rainy). The metrics used are episode return (ER) and driving distance (D(m)). The best performance for each metric and condition is highlighted in bold.
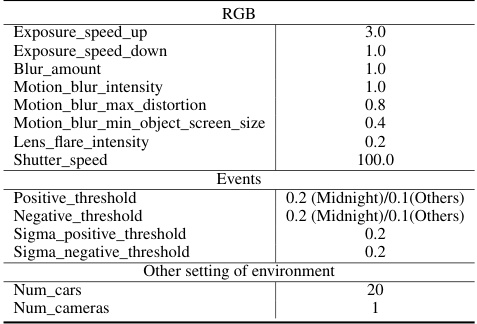
This table compares the performance of the proposed DDM method against several state-of-the-art single-modality and multi-modal reinforcement learning methods on the CARLA benchmark for autonomous driving. The comparison is made across four different driving scenarios (Normal, Midnight, Dazzling, Rainy) and evaluates two key metrics: episode return (ER) and driving distance (D(m)). The table categorizes methods by type (single-modality RL, multi-modal computer vision, and multi-modal RL) and highlights the best performance for each scenario and metric in bold.

This table compares the proposed Dissected Dynamics Modeling (DDM) method with several state-of-the-art methods on the CARLA autonomous driving benchmark. The comparison includes single-modality reinforcement learning (RL) methods, multi-modal computer vision methods, and multi-modal RL methods. The performance metrics are episode return (ER) and driving distance (D(m)), evaluated under various driving conditions (Normal, Midnight, Dazzling, Rainy) to assess robustness. The best results for each metric and condition are highlighted in bold.
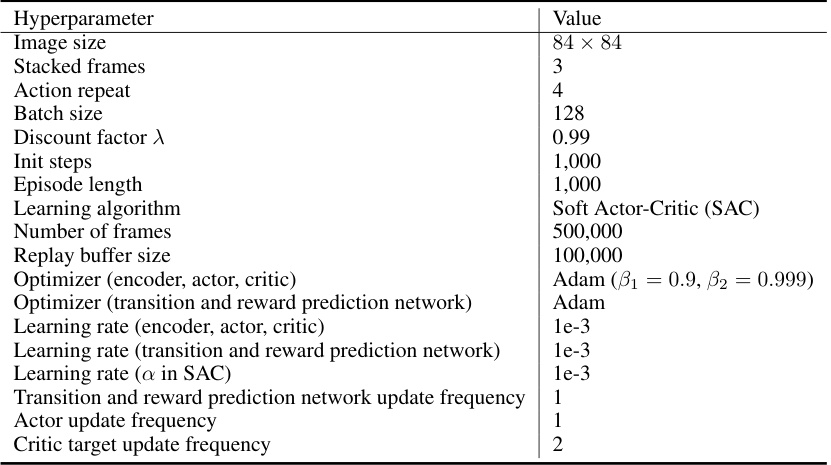
This table compares the performance of the proposed Dissected Dynamics Modeling (DDM) method against several state-of-the-art single-modality and multi-modal reinforcement learning methods on the CARLA driving simulation benchmark. The comparison is made across four challenging driving scenarios: Normal, Midnight, Dazzling, and Rainy. The metrics used for comparison are episode return (ER) and driving distance (D(m)). The best performance for each metric and scenario is highlighted in bold.
Full paper#