↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current video frame interpolation methods often struggle with computational cost or limited receptive fields, especially for high-resolution videos. This necessitates more efficient and adaptable models that can capture long-range dependencies. The paper addresses this by using Selective State Space Models (S6), which offer a balance of efficiency and modeling power for long sequences.
The proposed VFIMamba method introduces the Mixed-SSM Block which combines adjacent frames in an interleaved fashion, enhancing information transmission between frames while maintaining linear complexity. Additionally, a curriculum learning strategy is implemented to improve the model’s ability to handle varying motion magnitudes. Experiments show VFIMamba achieves state-of-the-art results, particularly for high-resolution video, demonstrating the effectiveness of the proposed approach.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to video frame interpolation using state-space models, achieving state-of-the-art performance, especially in high-resolution scenarios. It opens new avenues for research by applying advanced NLP models to low-level vision tasks and offers insights into efficient inter-frame modeling techniques. The curriculum learning strategy proposed is also a significant contribution, improving model generalization and robustness.
Visual Insights#
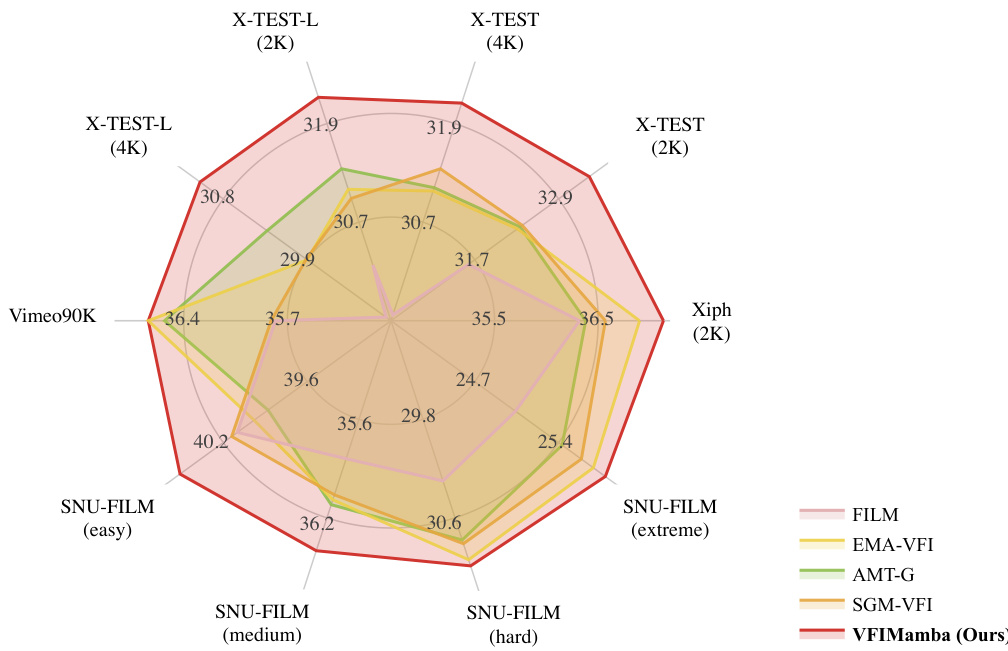
This radar chart visualizes the performance of VFIMamba and other state-of-the-art video frame interpolation methods across various benchmark datasets with different resolutions (2K and 4K). Each axis represents a different dataset, and the values on the axes show the performance scores. VFIMamba consistently outperforms other methods, especially in the high-resolution X-TEST datasets.

This table compares VFIMamba’s model design with existing methods for inter-frame modeling in video frame interpolation. It highlights key characteristics such as whether the model is data-dependent, has linear complexity, and possesses a global receptive field. The table shows that VFIMamba uniquely combines all three of these advantages, unlike other methods.
In-depth insights#
S6 in Video Frame Interpolation#
This paper explores the application of the Selective State Space Model (S6), a novel sequence modeling approach, to the task of video frame interpolation. The core idea is to leverage S6’s capability for efficient and dynamic long-sequence modeling to improve the accuracy and speed of intermediate frame generation. A key component is the proposed Mixed-SSM Block (MSB) which efficiently merges information from adjacent frames for effective processing by the S6 model. The MSB is crucial in capturing inter-frame dependencies while maintaining linear complexity, a significant advantage for high-resolution video. Furthermore, a curriculum learning strategy is introduced to improve the model’s performance on various motion magnitudes, training it progressively on datasets with increasing motion complexity. Experimental results confirm that this method achieves state-of-the-art performance, especially in high-resolution scenarios, demonstrating the potential of S6 for low-level vision tasks and offering a compelling alternative to traditional convolutional or attention-based approaches.
Mixed-SSM Block Design#
The core of VFIMamba lies in its novel Mixed-SSM Block (MSB). This design cleverly addresses the challenge of efficiently integrating the S6 model, inherently designed for single sequence processing, into the inter-frame modeling task crucial for video frame interpolation. The MSB first interleaves tokens from adjacent frames, creating a unified representation that transcends the limitations of individual frame processing. Subsequently, it leverages the power of multi-directional S6 modeling on this combined sequence, effectively propagating inter-frame information. This innovative approach provides the significant benefits of linear complexity and a wide receptive field, a crucial advantage over traditional convolutional or attention-based methods that often struggle with computational cost or limited context at high resolutions. The ingenuity of the MSB design is further highlighted by its ability to overcome the limitations of the original S6 model, leading to the improved efficiency and superior performance of VFIMamba in modeling intricate inter-frame dynamics.
Curriculum Learning Strategy#
The paper introduces a novel curriculum learning strategy to enhance the performance of their video frame interpolation model, VFIMamba. Instead of directly training on high-resolution, high-motion datasets, which can lead to instability, the model is gradually exposed to increasingly complex data. Initially, it trains on Vimeo-90K, a dataset with relatively low motion complexity. Then, data from X-TRAIN, a dataset containing high-resolution and high-motion videos, is incrementally introduced, starting with smaller motion magnitudes and progressively increasing the difficulty. This approach is inspired by the concept of curriculum learning, where the model learns easier concepts first before tackling more challenging ones. This incremental training approach allows the model to effectively adapt to various motion magnitudes, improving its generalization ability. The authors demonstrate the effectiveness of this strategy, achieving state-of-the-art performance across various benchmarks, especially those involving high-resolution videos with large motions. Curriculum learning prevents the model from getting overwhelmed by high-complexity data early in the training process, ultimately leading to a more robust and versatile VFIMamba model.
High-Resolution VFI#
High-resolution video frame interpolation (VFI) presents significant challenges due to increased computational demands and the complexity of modeling intricate motion patterns across high-resolution frames. Existing methods often struggle to maintain sufficient receptive fields while ensuring efficiency, leading to performance degradation in high-resolution scenarios. State-of-the-art approaches often rely on computationally expensive attention mechanisms or sophisticated convolutional architectures that may not scale well to 4K or higher resolutions. The development of efficient and accurate inter-frame modeling techniques is crucial. This includes exploring innovative architectures like state space models to better represent long-range dependencies and incorporating advanced motion estimation strategies. A curriculum learning approach, progressively training models on increasingly complex motion patterns, shows promise in enhancing performance on high-resolution data. Successfully tackling high-resolution VFI requires addressing both computational constraints and the need for detailed motion representation, while achieving an acceptable inference speed for real-time applications.
Future of SSM in VFI#
The integration of state space models (SSMs) into video frame interpolation (VFI) represents a significant advancement, offering the potential for improved efficiency and performance. Future research should explore the optimization of SSM architectures specifically tailored for VFI tasks, including the development of more sophisticated mixed SSM blocks. Addressing computational limitations remains a priority, particularly concerning high-resolution scenarios. Exploring diverse training strategies including curriculum learning and investigating the effect of model size and depth will be crucial. Further research can study the interaction between SSMs and other VFI components such as motion estimation and appearance refinement. Finally, assessing the robustness and generalization capabilities of SSM-based VFI across diverse video content and motion types is important. This multi-faceted approach will pave the way for state-of-the-art VFI systems leveraging the strengths of SSMs.
More visual insights#
More on figures
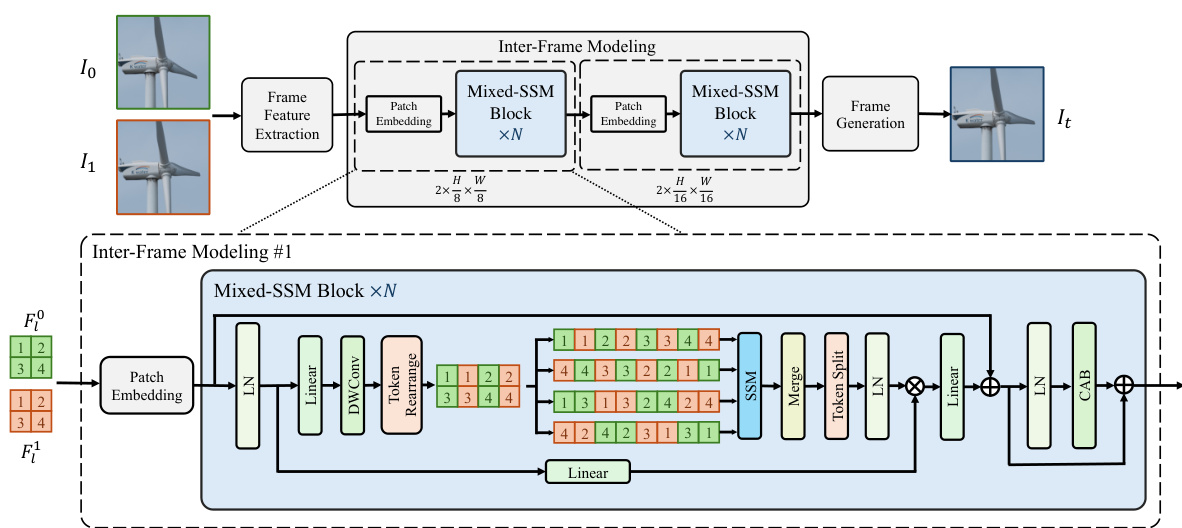
This figure illustrates the overall architecture of VFIMamba, a video frame interpolation model. It consists of three main stages: feature extraction, inter-frame modeling, and frame generation. The feature extraction stage uses a lightweight network to extract shallow features from input frames. The inter-frame modeling stage uses Mixed-SSM Blocks (MSBs), which leverage the S6 model for efficient and dynamic inter-frame modeling. This stage is repeated N times at each scale. Finally, the frame generation stage takes the inter-frame features and generates the intermediate frame.

This figure compares two methods for rearranging tokens from consecutive frames before processing with the S6 model: sequential and interleaved rearrangement. It shows how each method affects the flow of information between tokens when using horizontal and vertical scans. Interleaved rearrangement is shown to better preserve the spatiotemporal relationships between tokens, which is advantageous for video frame interpolation.

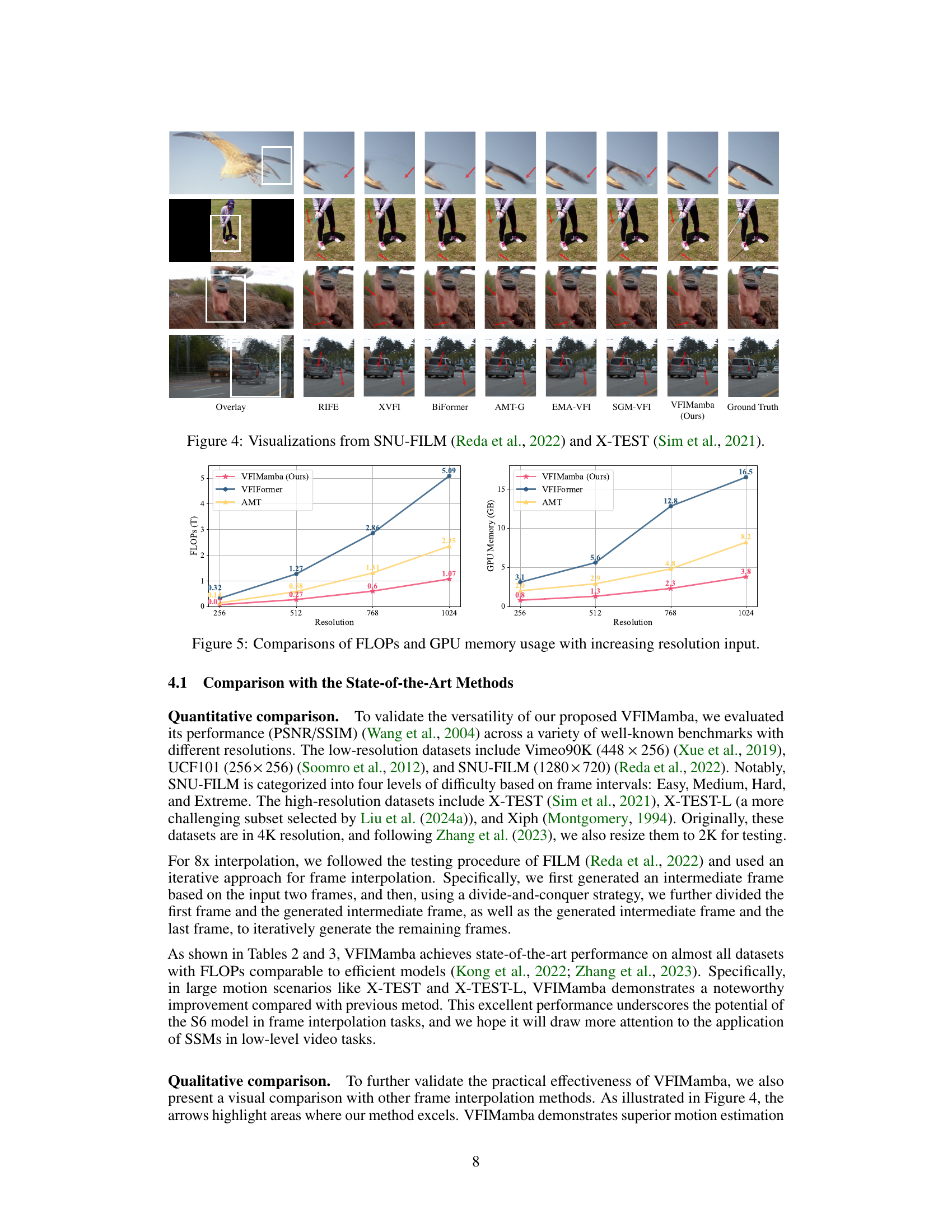
This figure shows a visual comparison of video frame interpolation results from different methods on two datasets: SNU-FILM and X-TEST. Each row represents a different video sequence, showing the input frames (Overlay), and the intermediate frames generated by various methods (RIFE, XVFI, BiFormer, AMT-G, EMA-VFI, SGM-VFI, VFIMamba) along with the ground truth. Arrows indicate areas where VFIMamba performs better than other methods, showcasing its superior motion estimation and detail preservation, especially in high-motion scenarios.

The figure shows a comparison of the computational cost (FLOPs) and GPU memory usage of VFIMamba against VFIFormer and AMT for different input resolutions (256, 512, 768, 1024). It demonstrates that VFIMamba is significantly more efficient than the other two methods, particularly at higher resolutions.
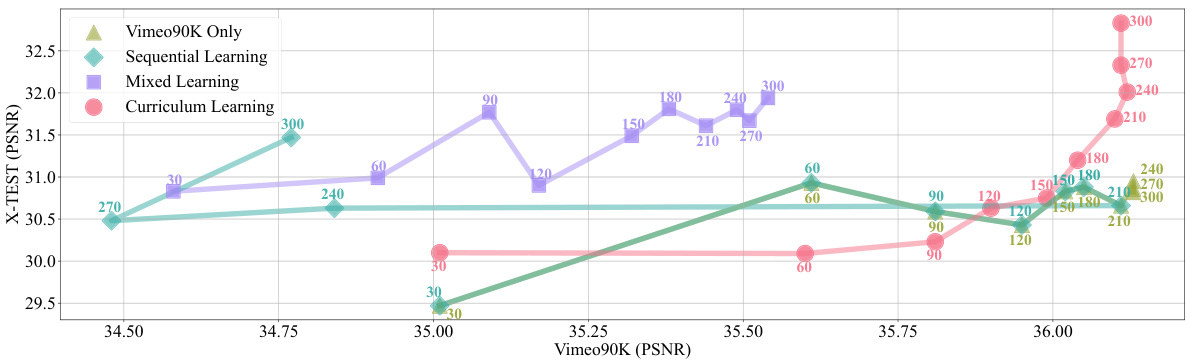
This figure shows a comparison of four different learning strategies for video frame interpolation: Vimeo90K Only, Sequential Learning, Mixed Learning, and Curriculum Learning. The performance is measured using PSNR on the Vimeo90K and X-TEST datasets, recorded every 30 epochs. The graph demonstrates that the Curriculum Learning strategy outperforms the other three methods, achieving the highest PSNR on both datasets at the end of training. This highlights the effectiveness of the proposed curriculum learning approach in improving model performance for video frame interpolation tasks.

This figure visualizes the effective receptive fields (ERFs) of different models for video frame interpolation, before and after training. The red box on the left image (I0) indicates the area of interest. The subsequent images display the corresponding ERFs in the next frame (I1) for three different models: Convolution, Local Attention, and the authors’ proposed S6 model. The visualization shows that the S6 model has a significantly larger ERF than the other two models, and that the ERF becomes more focused and accurate after training, suggesting better performance.

This figure displays visual comparisons of video frame interpolation results from several state-of-the-art methods (RIFE, XVFI, BiFormer, AMT-G, EMA-VFI, SGM-VFI) and VFIMamba on two datasets: SNU-FILM and X-TEST. The results show that VFIMamba produces sharper and more accurate intermediate frames, especially in challenging scenarios with large motion. The red arrows highlight areas where VFIMamba excels.
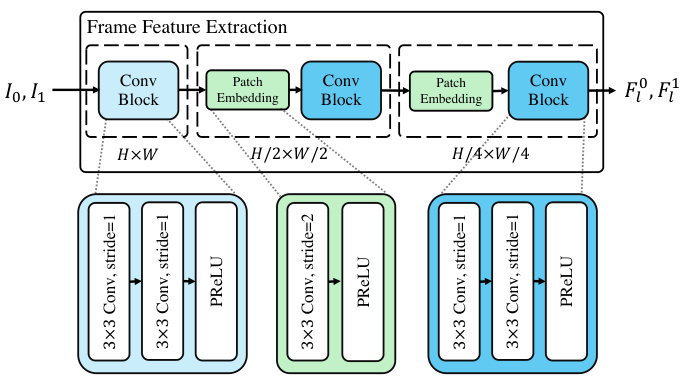
This figure shows the detailed architecture of the frame feature extraction module used in VFIMamba. It consists of three stages, each containing a convolutional block, a patch embedding layer, and another convolutional block. The resolution of the feature maps is progressively reduced (H×W, H/2×W/2, H/4×W/4) through the use of strided convolutions. Each convolutional block utilizes 3x3 convolutions with stride 1, followed by a prelu activation. The same color blocks represent identical structures across different scales. This design is intended to efficiently extract relevant features for subsequent inter-frame modeling.

This figure details the frame generation process of VFIMamba. It shows how the intermediate flow is estimated using features from the inter-frame modeling block (MSB), and then refined using a residual estimation module. The IFBlock is then used to enhance the local details before a backward warp operation is performed to generate the intermediate frame. The final frame is then produced using a RefineNet to refine the appearance.
More on tables
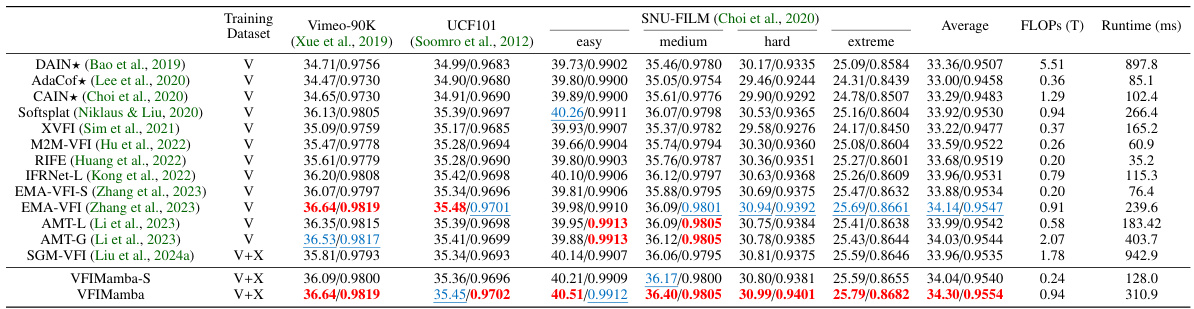
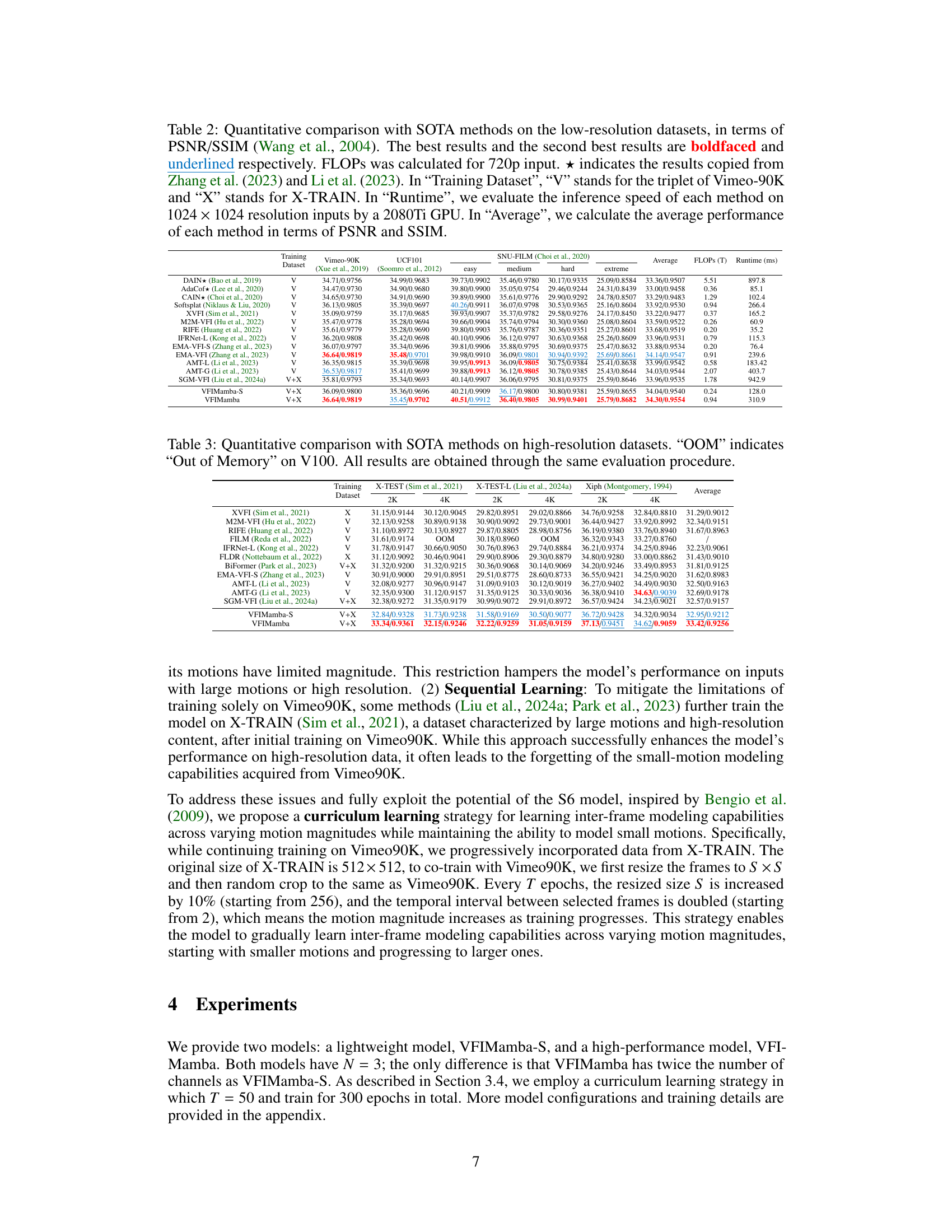
This table provides a quantitative comparison of VFIMamba and other state-of-the-art (SOTA) video frame interpolation (VFI) methods on low-resolution datasets. It shows the performance (PSNR and SSIM) of each method, the number of floating-point operations (FLOPs), the runtime on a 2080Ti GPU, and the training datasets used (Vimeo-90K and X-TRAIN). The table also includes the average performance across different datasets.
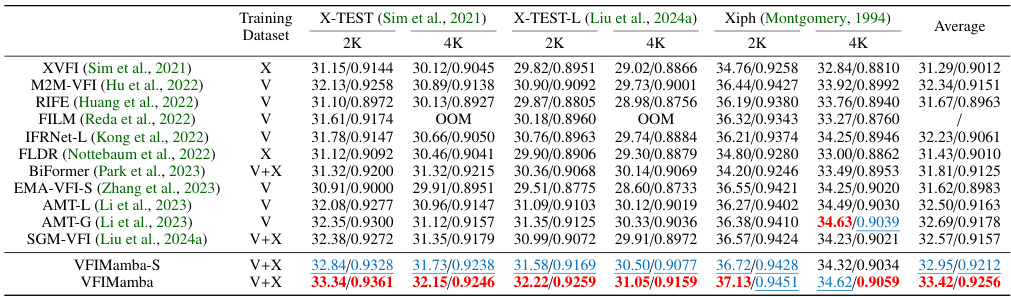
This table presents a quantitative comparison of VFIMamba against other state-of-the-art (SOTA) methods on high-resolution datasets. The datasets used are X-TEST, X-TEST-L, and Xiph. Results are presented in terms of PSNR and SSIM for 2K and 4K resolutions. ‘OOM’ indicates that the model ran out of memory on a V100 GPU. All models were evaluated using the same process for consistent comparisons.

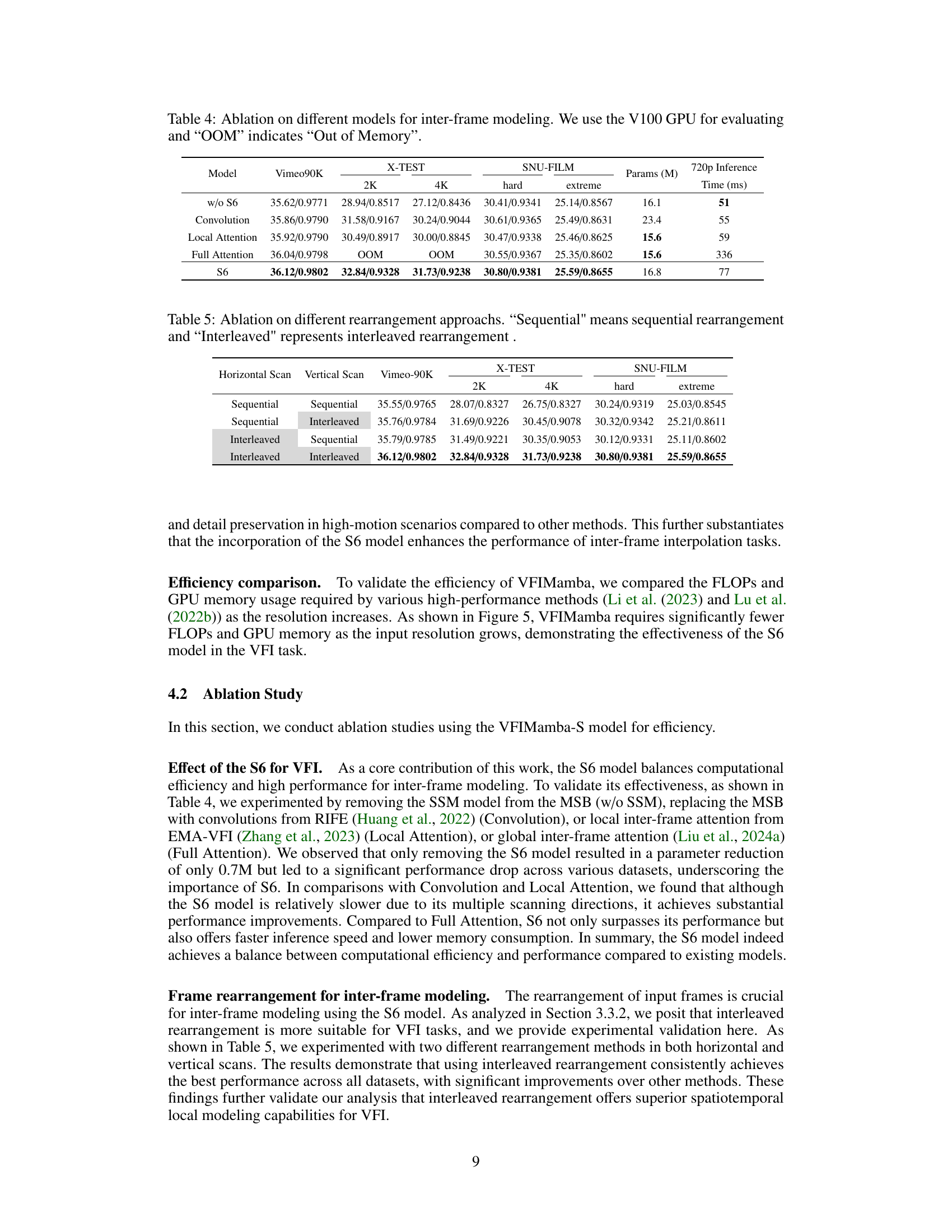
This table presents an ablation study comparing different models for inter-frame modeling within the VFIMamba framework. It shows the performance (PSNR/SSIM) on the Vimeo90K, X-TEST (2K and 4K), and SNU-FILM datasets (hard and extreme difficulty levels). The models compared include variations without the S6 model, using convolutions, local attention, full attention, and the full S6 model. The table also indicates the number of parameters (in millions) and the inference time in milliseconds for 720p resolution. ‘OOM’ signifies that the model ran out of memory on the V100 GPU.
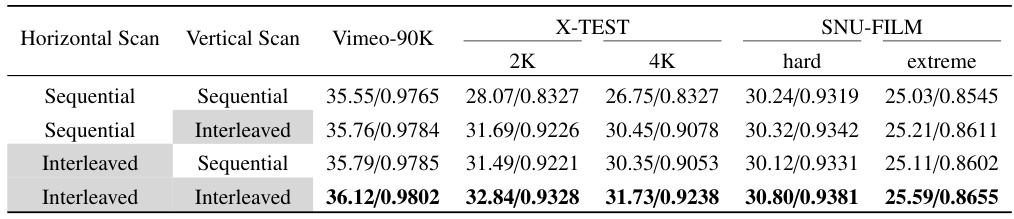
This table presents the ablation study on different rearrangement strategies for inter-frame modeling using the S6 model in the VFIMamba architecture. It compares the performance of using sequential versus interleaved token rearrangement for both horizontal and vertical scans in the Mixed-SSM Block (MSB). The results demonstrate that the interleaved rearrangement consistently achieves better performance across various datasets, highlighting the effectiveness of this approach for spatiotemporal local processing in video frame interpolation.
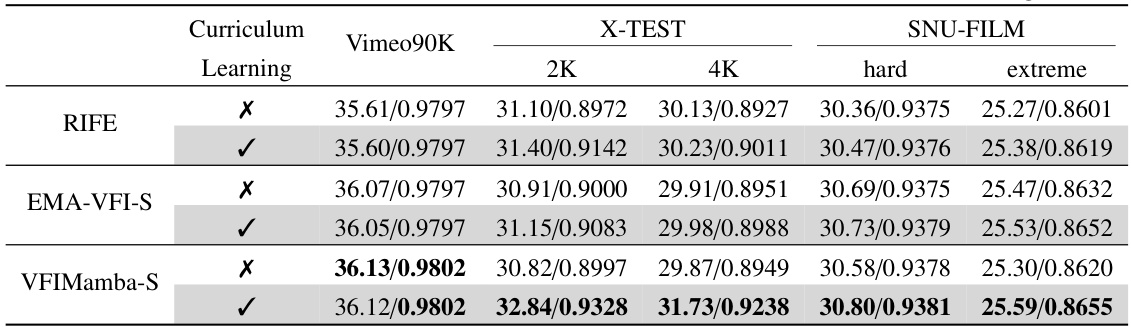
This table presents a quantitative comparison of the performance of three different video frame interpolation methods (RIFE, EMA-VFI-S, and VFIMamba-S) with and without curriculum learning. The performance is evaluated using PSNR and SSIM metrics across several datasets (Vimeo90K, X-TEST 2K, X-TEST 4K, SNU-FILM hard, SNU-FILM extreme). The results show the impact of curriculum learning on improving the models’ performance, particularly on higher-resolution and more challenging datasets.

This table compares the model design of VFIMamba with existing methods for inter-frame modeling in video frame interpolation. It highlights VFIMamba’s unique combination of a large receptive field (allowing it to capture long-range dependencies between frames) and linear complexity (meaning its computational cost scales linearly with the input size, unlike many other methods that scale quadratically or worse). The table shows that existing methods based on CNNs or attention mechanisms often lack either a sufficiently large receptive field or linear complexity. In contrast, VFIMamba’s use of the S6 model provides both.
Full paper#