↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current world models struggle with scalability and interactivity, hindering their use in real-world applications. While recurrent models are interactive, they lack scalability, and generative models are scalable but not interactive enough for complex tasks such as robotic manipulation. This paper introduces a novel approach by integrating multimodal signals (visual, action, reward) into an autoregressive transformer framework, called iVideoGPT.
The proposed iVideoGPT uses a novel compressive tokenization technique to efficiently discretize high-dimensional visual data, making it suitable for training on millions of human and robot manipulation trajectories. This pre-trained model provides a versatile foundation for various downstream tasks, including video prediction, visual planning, and model-based reinforcement learning, demonstrating significant improvements in performance over current state-of-the-art methods. The authors provide open access to the code and pre-trained models, encouraging further research and development in this field.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI, robotics, and reinforcement learning. It introduces iVideoGPT, a scalable and interactive world model, bridging the gap between video generation and model-based RL. Its scalable architecture and compressive tokenization technique enable pre-training on massive datasets, leading to significant performance gains in downstream tasks. This work opens avenues for developing more effective interactive world models, advancing the field of model-based RL and impacting various applications.
Visual Insights#

The figure illustrates the applications of iVideoGPT. iVideoGPT is pre-trained on a large dataset of human and robot manipulation trajectories, creating a scalable and versatile world model. This model can then be applied to a variety of downstream tasks, including video prediction, visual planning, and model-based reinforcement learning. The figure shows example videos from each of these downstream applications.
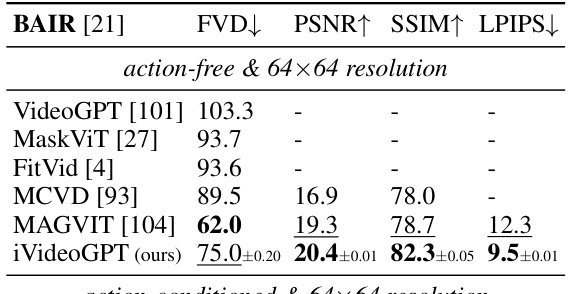
This table presents a quantitative comparison of iVideoGPT’s video prediction performance against several state-of-the-art methods on two benchmark datasets: BAIR robot pushing and RoboNet. The metrics used for comparison include Fréchet Video Distance (FVD), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Results are shown separately for action-free and action-conditioned video prediction, and for different resolutions (64x64 and 256x256). The table highlights iVideoGPT’s competitive performance, especially in terms of FVD, indicating its ability to generate realistic and temporally consistent videos.
In-depth insights#
iVideoGPT Overview#
iVideoGPT is presented as a scalable and interactive video generation model, addressing limitations of previous approaches. Its core innovation lies in a novel compressive tokenization technique that efficiently handles high-dimensional visual data, enabling the integration of multimodal information (visuals, actions, rewards) into a sequence of tokens. This approach facilitates interactive agent experiences through next-token prediction within a GPT-like autoregressive transformer framework. The model’s scalability is demonstrated through pre-training on millions of human and robotic manipulation trajectories, creating a versatile foundation for various downstream applications, including video prediction, visual planning, and model-based reinforcement learning. Key advantages highlighted include efficient training, improved video quality due to the decoupling of context and dynamics, and competitive performance compared to existing state-of-the-art methods. The architecture’s flexibility is also showcased through its adaptability to different tasks via pre-training and fine-tuning procedures.
Compressive Tokenization#
The concept of “Compressive Tokenization” presents a novel approach to handling high-dimensional visual data in video prediction models. Instead of independently tokenizing each frame, which leads to exponentially increasing sequence lengths, this method leverages a conditional VQGAN to efficiently discretize future frames based on contextual information from prior frames. This conditional approach is crucial; it addresses the inherent redundancy present in consecutive video frames by focusing only on essential dynamic information. By decoupling context from dynamics, the model learns a more compact representation, significantly reducing token sequence lengths, and making the model more scalable and computationally efficient. The use of a conditional VQGAN enables the model to maintain temporal consistency, focusing on predicting motion and changes while keeping context stable, leading to a more accurate and efficient generation of high-quality videos. This technique’s core innovation lies in its effectiveness at compressing high-dimensional data without sacrificing temporal information or model performance, ultimately bridging a key gap between generative video models and scalable world models.
Interactive Prediction#
Interactive prediction, in the context of a research paper on video generation and world modeling, signifies a paradigm shift from traditional video prediction methods. Instead of simply predicting a future video sequence based on past observations, interactive prediction allows for real-time interventions and adjustments during the prediction process. This often involves incorporating user input, agent actions, or reward signals as the prediction unfolds. This creates a dynamic, evolving prediction rather than a static forecast. A key challenge is to design an architecture that efficiently handles the dynamic flow of information and maintains a coherent model of the world. Autoregressive transformer models are often well-suited for this task because of their inherent ability to process sequential information and the ease of integrating multimodal signals. The ability of an interactive prediction system to incorporate real-time feedback also enables powerful applications in model-based reinforcement learning, providing agents with a way to plan actions within imagined environments and rapidly improve their skills.
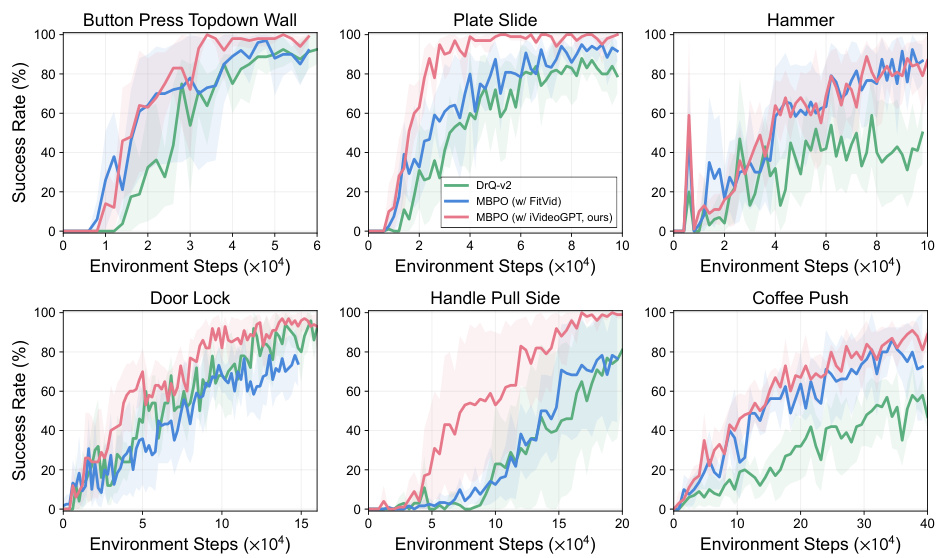
MBRL Experiments#
In the hypothetical “MBRL Experiments” section of a research paper, a thorough analysis of model-based reinforcement learning (MBRL) would be expected. This would likely involve a detailed description of the experimental setup, including the specific MBRL algorithm used, the environment(s) chosen for evaluation (likely simulated robotics environments given the paper’s context), and the metrics used to assess performance. Key results, such as success rates on various tasks or comparisons against state-of-the-art methods, should be presented with error bars or statistical significance measures to demonstrate the reliability and robustness of the findings. The discussion should analyze these results in detail, identifying any limitations or unexpected outcomes. The impact of hyperparameter tuning on performance should also be evaluated, and there should be an examination of computational costs and scalability of the MBRL approach. A critical assessment of the chosen experimental setup, including the representativeness of the environment and the suitability of the evaluation metrics, is crucial. The analysis should compare and contrast the proposed MBRL system with other relevant baselines, providing valuable insights into the strengths and weaknesses of the proposed method.
Future Work & Limits#
The authors acknowledge several limitations and promising avenues for future research. Scalability remains a key challenge, with the current model’s performance potentially limited by the dataset size and computational resources. Generalization to unseen environments and tasks beyond robotic manipulation requires further investigation, especially considering the diversity of real-world scenarios. Improving the model’s ability to handle more complex visual inputs, such as higher-resolution videos and varied viewpoints, is crucial for broader applicability. Addressing the inherent uncertainties in real-world scenarios through more robust and less brittle prediction methods, like improving temporal consistency, is vital for safe and reliable deployment. Investigating new tokenization techniques and model architectures that can efficiently handle long video sequences will improve performance and scalability. Finally, exploring how to more effectively incorporate other modalities (e.g., proprioception and other sensor readings) in a multimodal setting offers a promising area for future research.
More visual insights#
More on figures
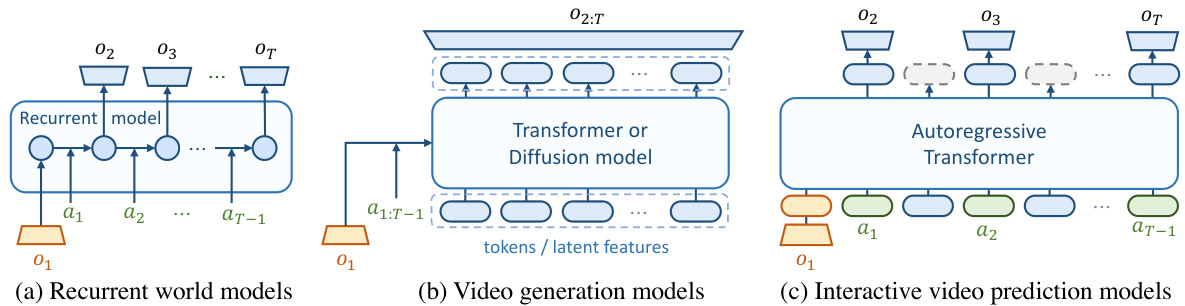
This figure compares three different architectural approaches for world models: recurrent models, video generation models, and interactive video prediction models. Recurrent models, like Dreamer and MuZero, offer step-level interactivity but struggle with scalability. Video generation models, such as VideoGPT and Stable Video Diffusion, use non-causal temporal modules, limiting interactivity to trajectory-level. In contrast, the proposed iVideoGPT utilizes an autoregressive transformer, achieving both scalability and step-level interactivity by mapping each step to a sequence of tokens.
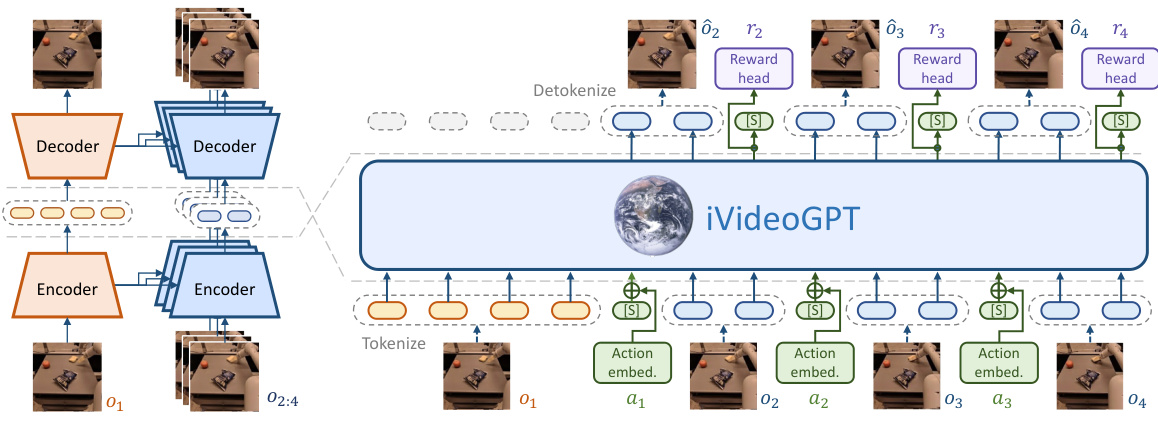
This figure shows the architecture of iVideoGPT. The left panel (a) illustrates the compressive tokenization method, which uses a conditional VQGAN to efficiently encode visual information. The right panel (b) illustrates how the model processes multimodal signals (visual observations, actions, rewards) using an autoregressive transformer. This enables interactive prediction of the next token, which is crucial for model-based reinforcement learning applications.

This figure shows the qualitative results of the iVideoGPT model on three different video datasets: Open X-Embodiment, RoboNet, and VP2. Each dataset represents different types of videos, with Open X-Embodiment showing robot manipulation trajectories, RoboNet showing a variety of robotic arm movements, and VP2 showcasing both robotic and human interactions. For each dataset, the figure displays the ground truth video sequence and iVideoGPT’s predictions side-by-side for comparison. The results demonstrate the model’s capability to accurately predict future frames based on provided context frames.
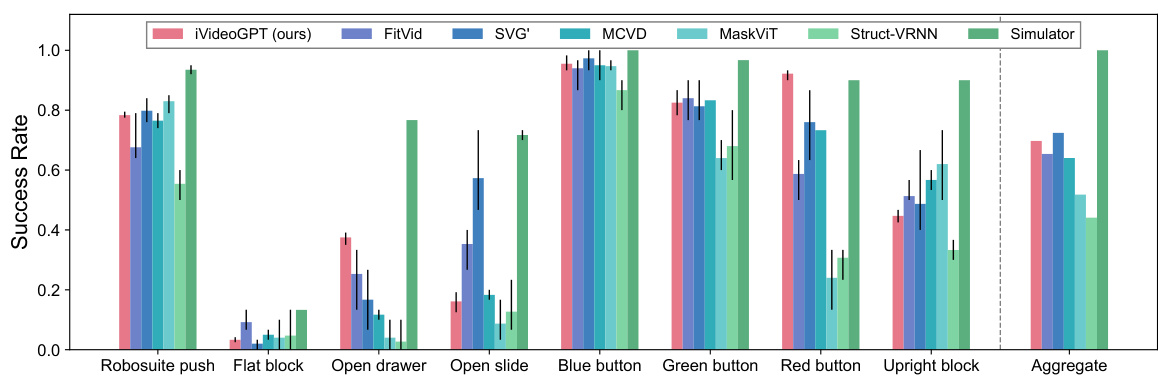
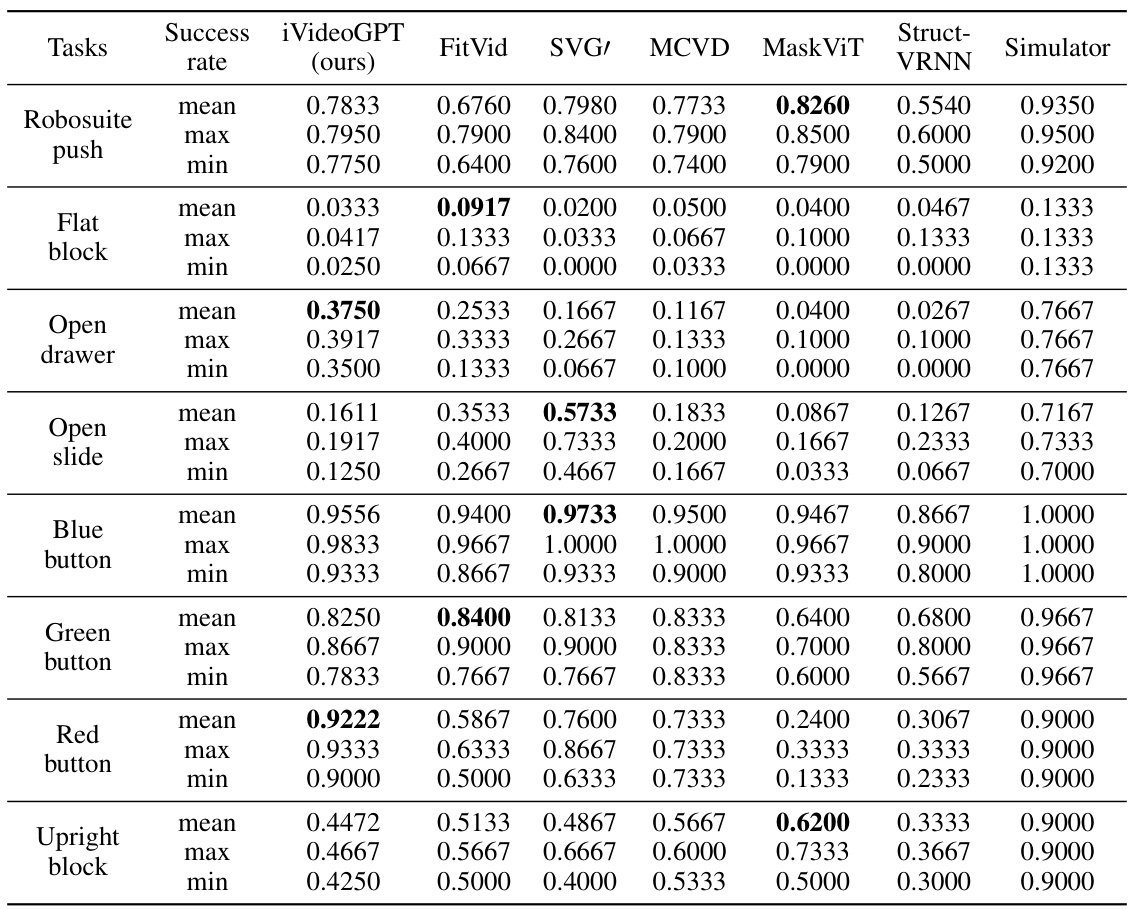
The figure shows the success rates of iVideoGPT and other visual predictive control models on various tasks from the VP2 benchmark. It compares the performance across multiple tasks, illustrating the effectiveness of iVideoGPT and highlighting its strengths and weaknesses relative to other models. The right side shows normalized mean scores, which account for differences in task difficulty and simulator performance.

This figure compares three different types of architectures for world models: recurrent models, video generation models, and the proposed interactive video prediction model. Recurrent models offer step-level interactivity but suffer from scalability issues. Video generation models, on the other hand, provide trajectory-level interactivity but are not designed for interactive scenarios. The proposed model combines scalability and interactivity by using an autoregressive transformer that integrates multimodal signals (visual observations, actions, and rewards) into a sequence of tokens, allowing for interactive agent experiences via next-token prediction.
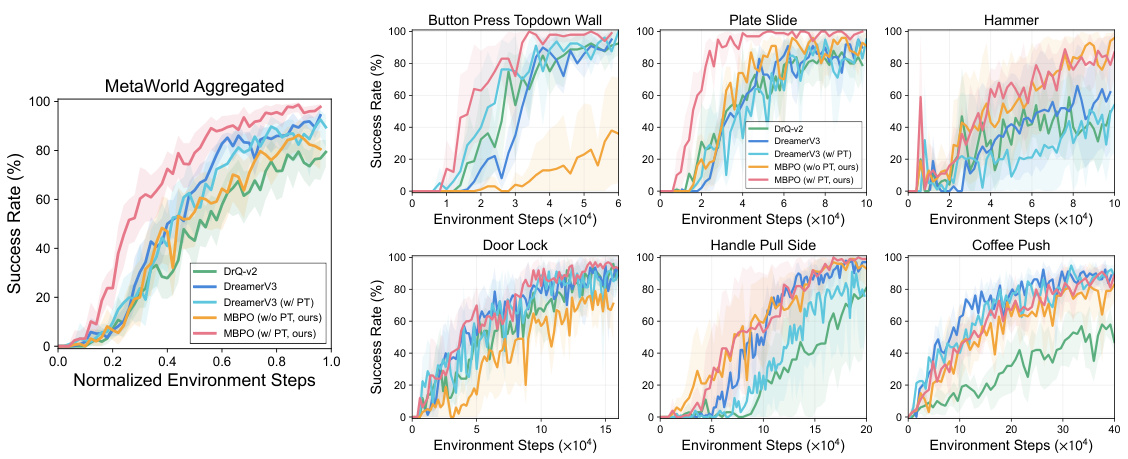
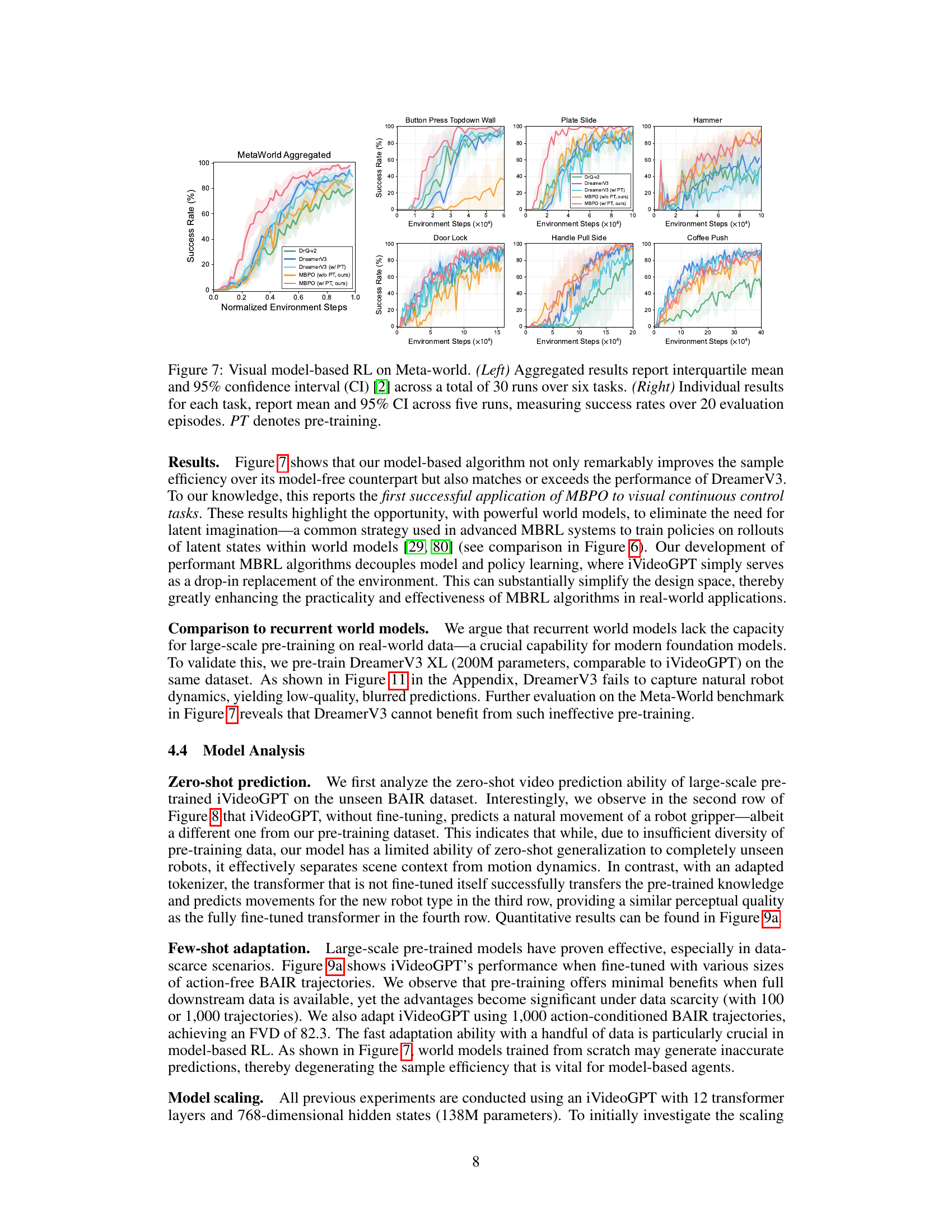
This figure shows the results of visual model-based reinforcement learning experiments conducted on six robotic manipulation tasks from the Meta-World benchmark. The left panel presents aggregated results across all six tasks, illustrating the success rate of different model-based RL approaches (DrQ-v2, DreamerV3, and MBPO with and without pre-training using iVideoGPT) over the course of environment steps. The right panel displays the individual results for each of the six tasks, showing success rates with confidence intervals. The results highlight the superior sample efficiency of the model-based methods, particularly when using iVideoGPT for world model pre-training.

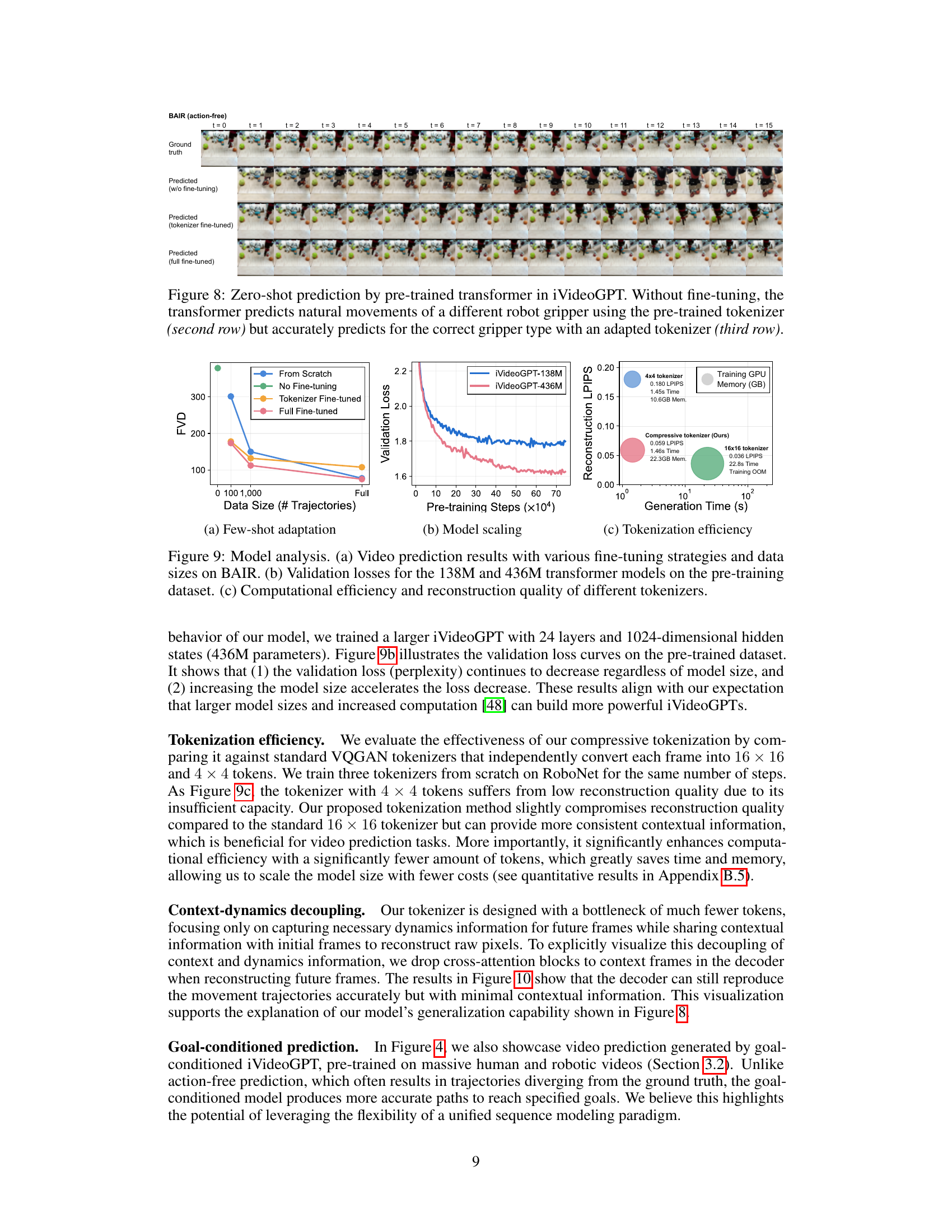
This figure demonstrates the zero-shot prediction capability of the pre-trained transformer in iVideoGPT. The first row shows the ground truth video of a robot manipulating objects. The second row shows the prediction results without fine-tuning. The pre-trained tokenizer is used and predicts a natural movement, although with a different robot gripper than the training set. The third row shows the results with fine-tuning on the tokenizer only. Here, the model accurately predicts the correct gripper movements from the training set. The fourth row shows the prediction using a fully fine-tuned model for comparison. This experiment highlights the model’s ability to transfer knowledge and adapt to new situations with minimal fine-tuning.
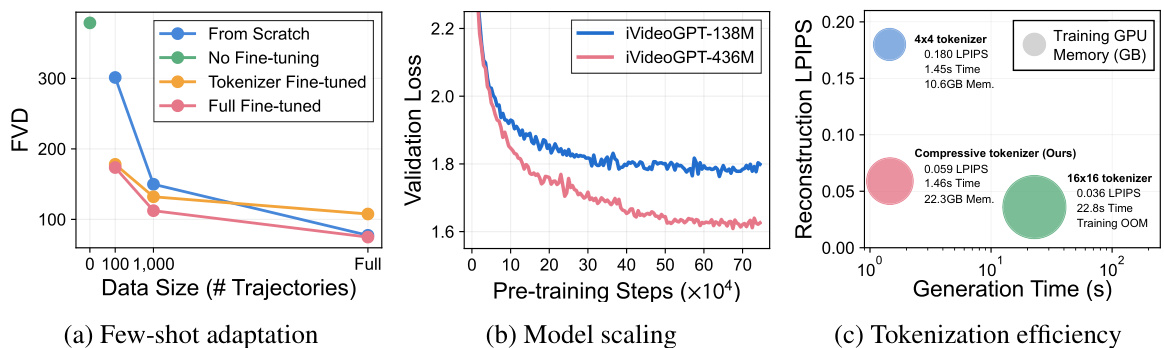
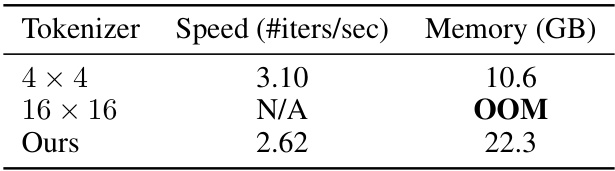
This figure shows the results of model analysis experiments. (a) demonstrates the performance of few-shot adaptation on the BAIR dataset with different fine-tuning strategies (from scratch, no fine-tuning, tokenizer fine-tuned, full fine-tuned) and varying dataset sizes. (b) illustrates the model scaling behavior by comparing the validation losses of 138M and 436M transformer models during pre-training. (c) presents a comparison of the tokenization efficiency and reconstruction quality among different tokenizers (4x4, 16x16, and the proposed compressive tokenizer).

This figure demonstrates the effectiveness of the proposed compressive tokenization method in separating contextual information from dynamic information. By removing the cross-attention mechanism between the context frames and future frames in the decoder, the reconstruction still captures the dynamic motion of objects but loses the detailed visual context from the original sequence. This highlights the ability of the model to efficiently focus on the essential motion information while compressing the amount of information needed to be processed, which is a crucial component for scalability and efficiency.

This figure compares the qualitative video prediction results of iVideoGPT and DreamerV3-XL. Both models were pre-trained on the Open X-Embodiment dataset. The figure shows that iVideoGPT generates significantly more realistic and coherent video predictions compared to DreamerV3-XL, especially in terms of object motion and interaction. This highlights iVideoGPT’s superior performance in capturing and generating complex spatiotemporal dynamics.

This figure shows additional qualitative results of action-free video prediction on the Open X-Embodiment dataset. It provides a visual comparison between ground truth video frames and those predicted by the iVideoGPT model. Multiple examples across various scenarios are shown to illustrate model performance on a variety of actions.
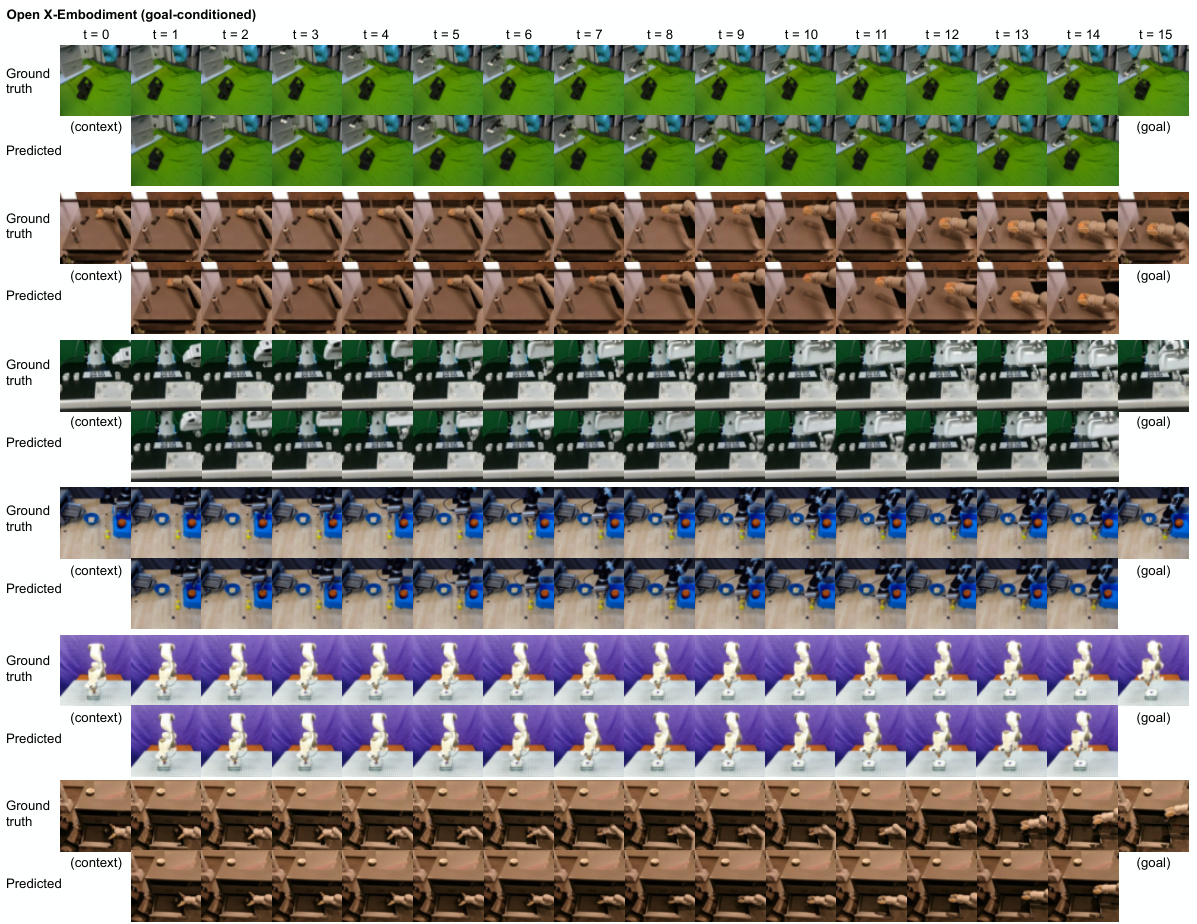
This figure shows the qualitative results of video prediction using iVideoGPT on three different datasets: Open X-Embodiment, RoboNet, and VP2. It compares the model’s predictions against ground truth videos for action-free and goal-conditioned settings. Each dataset shows example trajectories where the video model predicts a sequence of frames from initial context frames. The results visually demonstrate the iVideoGPT model’s ability to generate realistic and accurate video predictions for robotic manipulation.

This figure demonstrates the zero-shot prediction capability of the pre-trained iVideoGPT transformer. The first row shows the ground truth video frames of a robot manipulating objects. The second row shows the model’s predictions without any fine-tuning; while it predicts a plausible movement, the gripper type is incorrect. The third row showcases the predictions after only fine-tuning the tokenizer (the part of the model responsible for converting images into tokens) with the data for the correct gripper type. This achieves more accurate predictions with only partial model retraining. The final row provides predictions after fine-tuning the entire model, showing the performance improvement resulting from full retraining.

This figure demonstrates the zero-shot prediction capabilities of the pre-trained iVideoGPT transformer on the unseen BAIR dataset. The top row shows the ground truth video frames. The second row displays the model’s predictions without any fine-tuning, revealing its ability to predict natural movements even with a different robot gripper than those seen during pre-training. This highlights the separation of scene context and motion dynamics in the model. The third row showcases the results after adapting the tokenizer for the unseen gripper, leading to more accurate predictions. Finally, the bottom row illustrates the results with full fine-tuning, demonstrating that only the tokenizer needs adapting for excellent zero-shot performance.

The figure shows different applications of the iVideoGPT model. The model is pre-trained on a large dataset of human and robot manipulation videos. This allows it to be used as a foundation for various downstream tasks, such as video prediction, visual planning, and model-based reinforcement learning. The scalability of the iVideoGPT model is highlighted, showing its adaptability to different applications.

This figure displays several examples of video prediction results from the iVideoGPT model on the RoboNet dataset. It specifically showcases the model’s performance at a higher resolution (256x256 pixels) compared to some of the other results shown in the paper. The figure is arranged in rows, with each row representing a different video sequence. Each row shows the ground truth frames (labeled ‘Ground truth’) next to the frames generated by iVideoGPT (labeled ‘Predicted’). This allows for a direct visual comparison of the model’s predictions to the actual video footage, highlighting the model’s ability to generate high-resolution videos that accurately depict the robotic manipulation tasks shown.

The figure shows how iVideoGPT, a scalable interactive world model, is trained on a large dataset of human and robot manipulation trajectories. This pre-training allows iVideoGPT to be used for a variety of downstream tasks, such as video prediction, visual planning, and model-based reinforcement learning. The versatility is highlighted by showing examples of human manipulation, robotic manipulation, video prediction, visual planning, and model-based reinforcement learning applications.

This figure illustrates the architecture of iVideoGPT. Panel (a) shows the compressive tokenization process using a conditional VQGAN to efficiently represent video frames by encoding only essential dynamics information in future frames, conditioned on the context frames from the past. Panel (b) depicts the autoregressive transformer that processes visual observations, actions (optional), and rewards (optional) as a sequence of tokens to produce interactive video predictions. This architecture enables scalable interactive prediction.

This figure shows the results of a human evaluation comparing video prediction results from three different models: VideoGPT, MCVD, and iVideoGPT. Human participants were shown videos generated by each model and asked to rate their preference based on how natural and feasible the robot-object interactions looked. The results are presented as percentages showing which model was preferred more often in pairwise comparisons.
This figure shows the results of visual model-based reinforcement learning experiments conducted on the Meta-world benchmark. The left panel presents an aggregated view of the success rates across six different tasks, showing the interquartile mean and 95% confidence intervals over 30 runs. The right panel provides a more detailed breakdown of the performance for each task individually, displaying the mean success rate and 95% confidence intervals over 5 runs with each run consisting of 20 episodes. The results are compared between different model-based RL algorithms, including one that leverages the pre-trained iVideoGPT world model.

This figure shows a qualitative comparison of video prediction results between iVideoGPT and DreamerV3-XL. Both models were pre-trained on the same Open X-Embodiment dataset, allowing for a fair comparison of their performance. The figure showcases sample video predictions generated by both models, enabling visual inspection of their respective strengths and limitations. The goal is to visually demonstrate the superiority of iVideoGPT in generating realistic and coherent video predictions, compared to DreamerV3-XL.
This figure compares three different architectures for world models: recurrent models, video generation models, and the proposed interactive video prediction model. Recurrent models, while interactive, lack scalability. Video generation models are scalable but only offer trajectory-level interactivity. The proposed model uses an autoregressive transformer to achieve both scalability and step-level interactivity.
More on tables
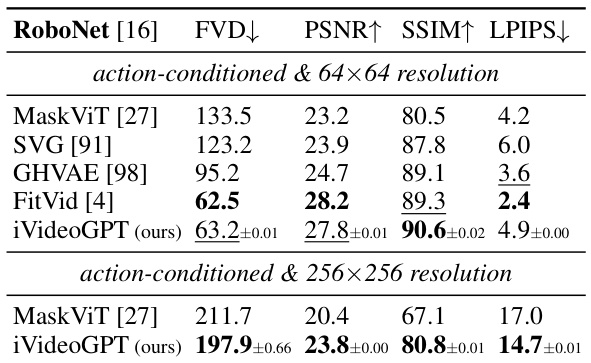
This table presents a comparison of the iVideoGPT model’s performance on video prediction tasks against other state-of-the-art methods. The results are shown for two datasets: BAIR robot pushing and RoboNet. Metrics used for comparison include FVD (Fréchet Video Distance), PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Results are provided for both 64x64 and 256x256 resolutions and with and without action conditioning.
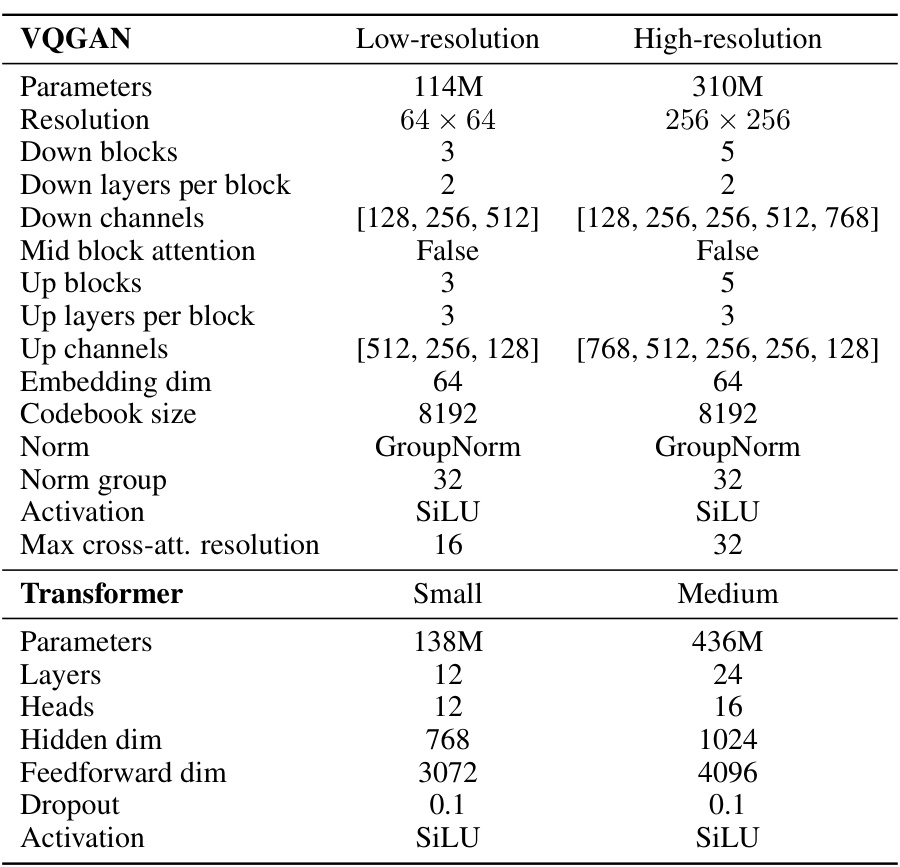
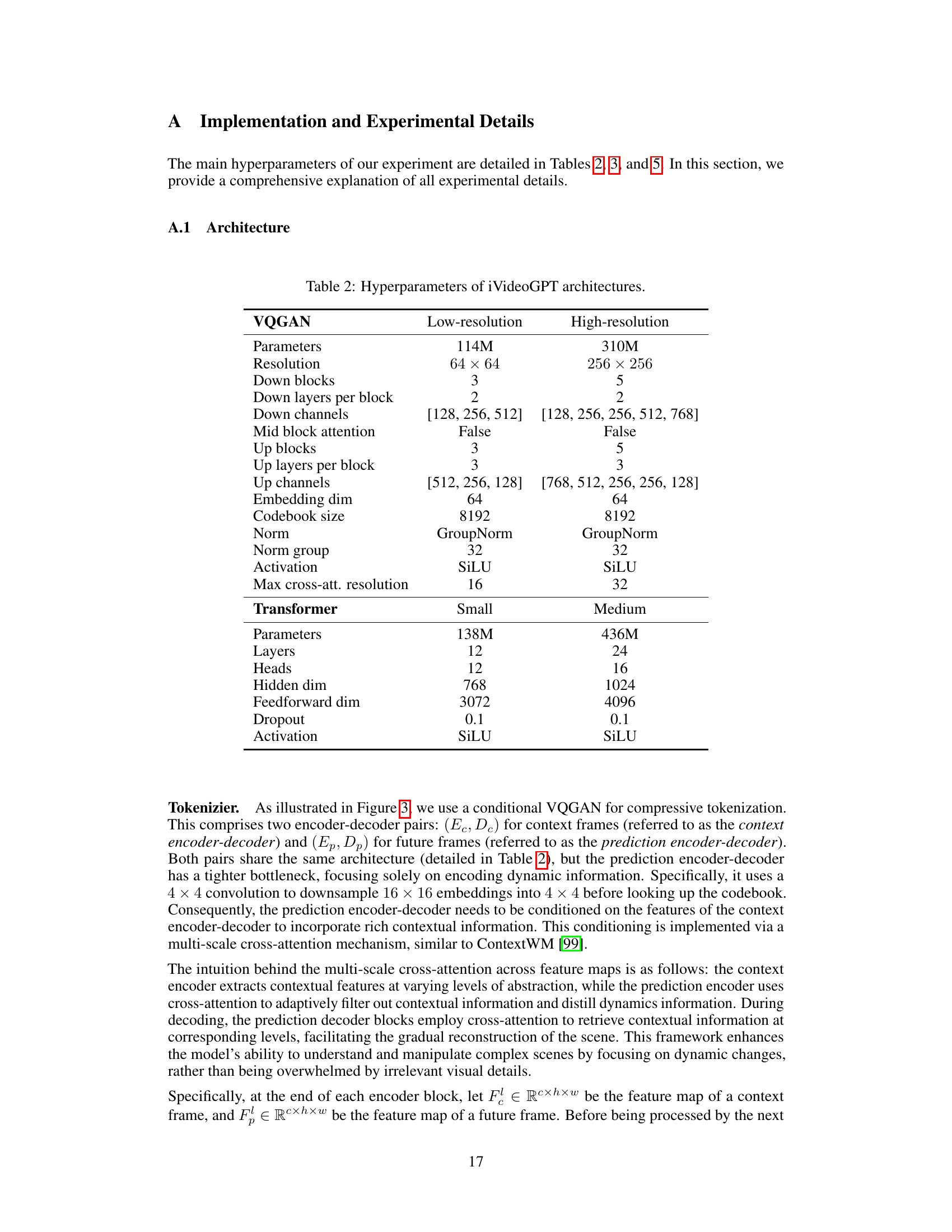
This table details the hyperparameters used in the architecture of the Interactive VideoGPT model. It is broken down into two sections: VQGAN and Transformer. The VQGAN section lists parameters such as resolution, the number of down and up blocks and layers, channel dimensions, embedding size, codebook size, normalization method and group size, and activation function. The Transformer section lists the parameters such as number of layers, number of heads, hidden dimension, feedforward dimension, dropout rate, and activation function. The table shows separate specifications for low-resolution (64x64) and high-resolution (256x256) model variations.
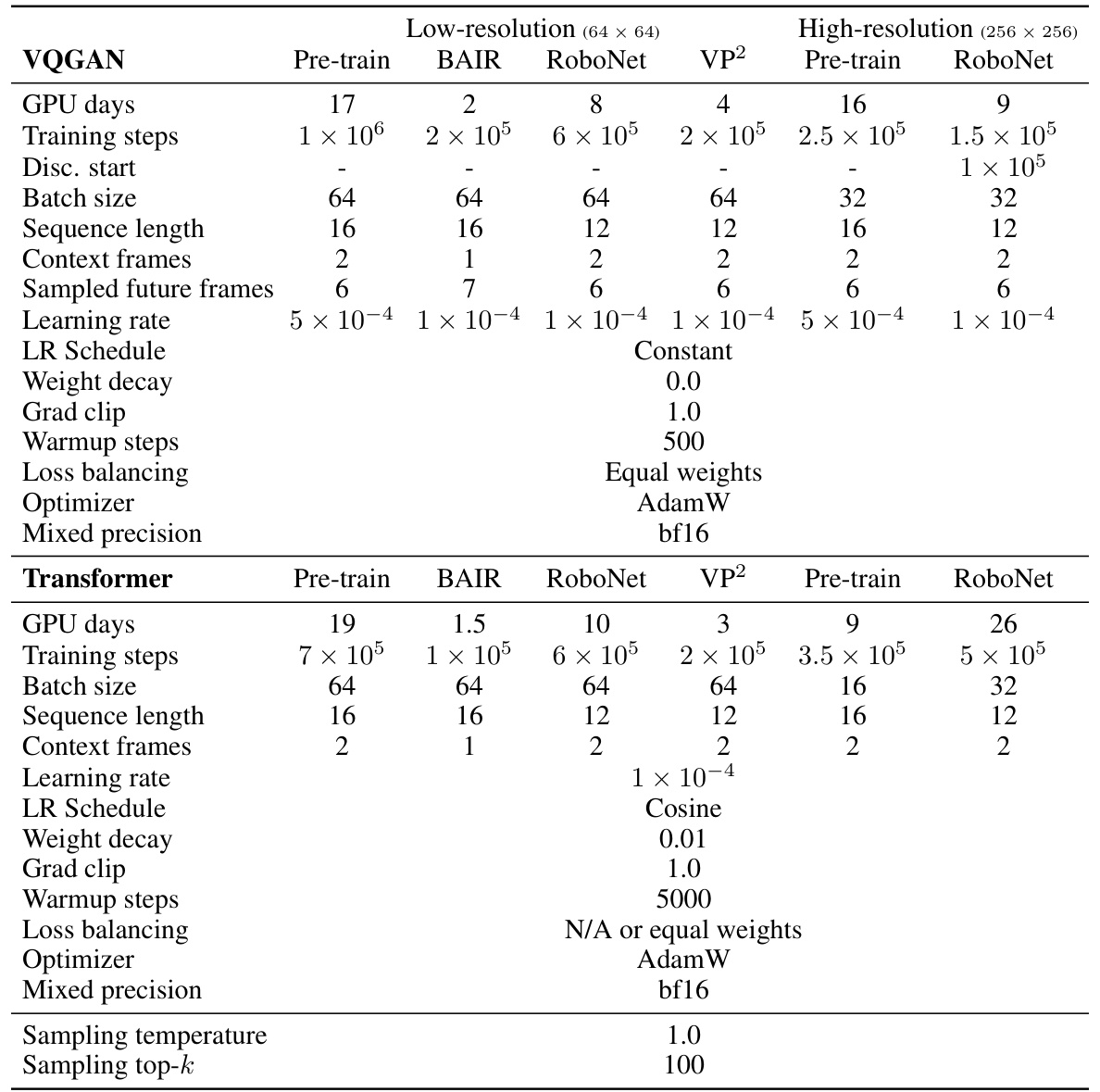
This table details the hyperparameters used for training and evaluating the iVideoGPT model. It is broken down by model resolution (low and high), training phase (pre-training and fine-tuning), and dataset (BAIR, RoboNet, and VP2). Specific hyperparameters listed include GPU training days, training steps, discriminator start point, batch size, sequence length, number of context frames, number of sampled future frames, learning rate, learning rate scheduling method, weight decay, gradient clipping value, warmup steps, loss balancing method, optimizer, mixed precision, and sampling parameters (temperature and top-k).
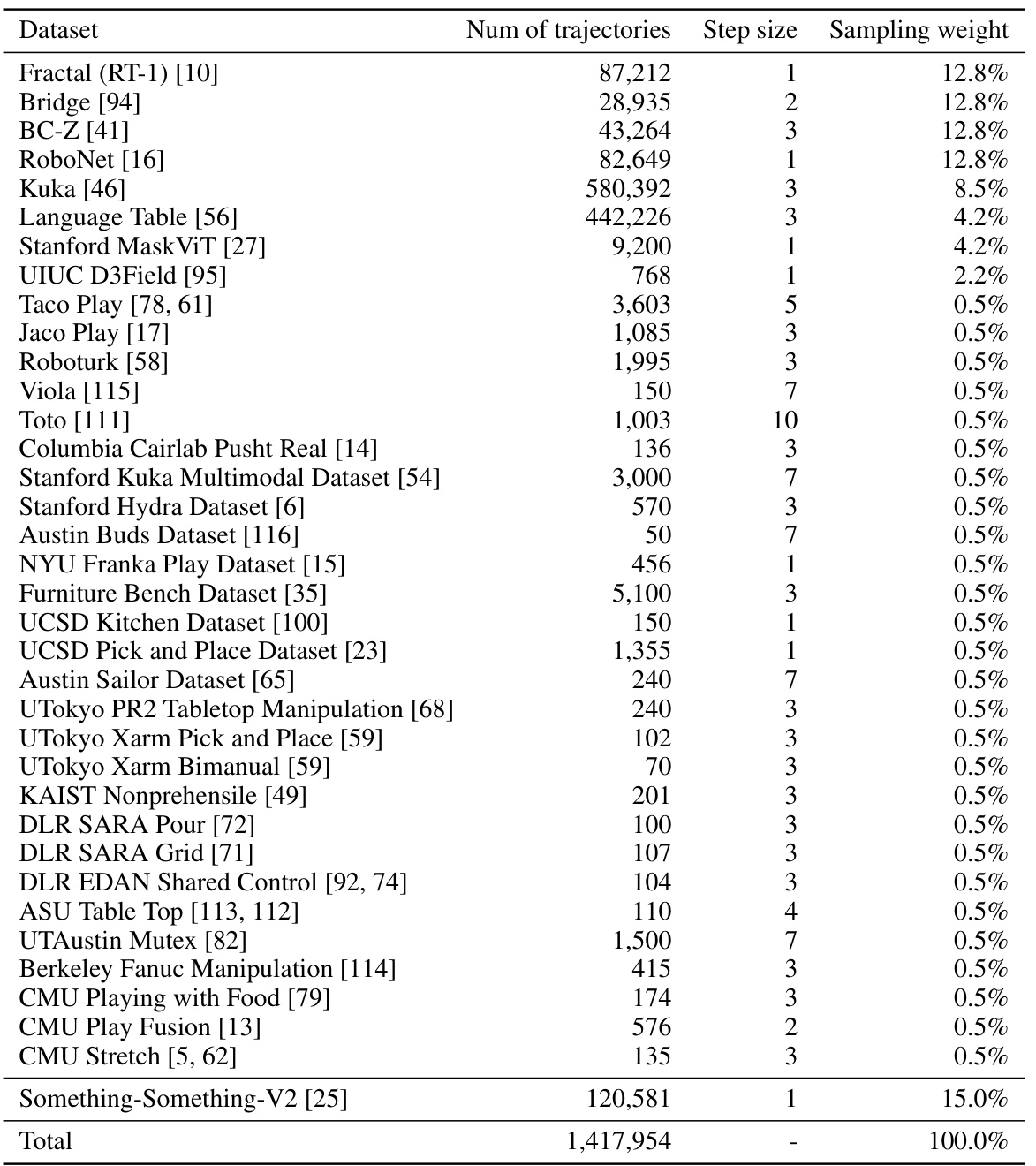
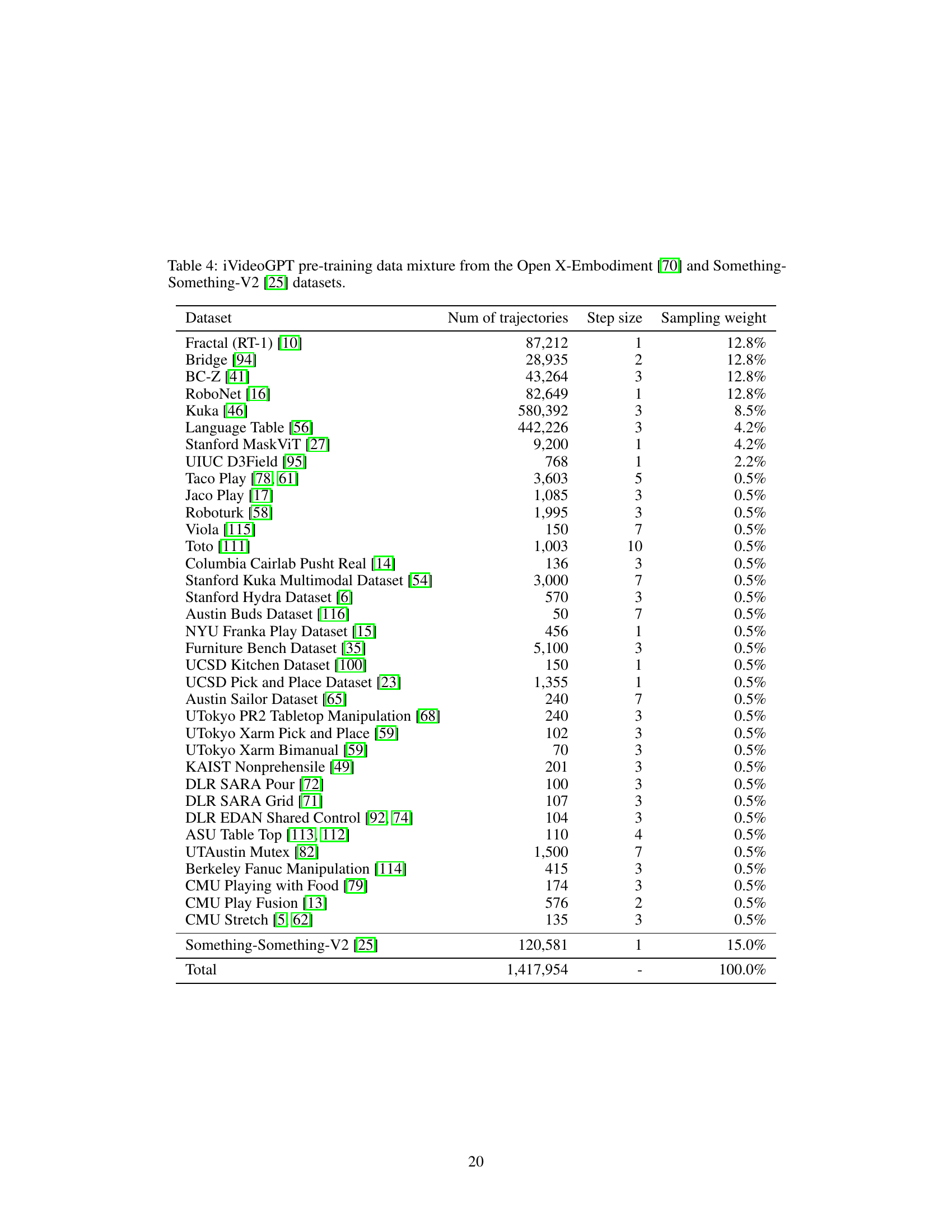
This table details the composition of the pre-training dataset for the iVideoGPT model. It lists various datasets used, the number of trajectories from each, the step size used when sampling frames from those trajectories, and the weighting assigned to each dataset in the overall training mixture. The datasets represent a diverse range of robotic and human manipulation tasks, aiming to provide comprehensive coverage of various scene dynamics and object interactions.

This table lists the hyperparameters used for the model-based reinforcement learning experiments in the paper. It breaks down the settings for both the model rollout phase and the model training phase. Specific hyperparameters include the batch size, horizon, training intervals, sequence length, and learning rate, amongst others. The table shows that the real data ratio was set to 0.5.
This table presents a comparison of video prediction results on two datasets (BAIR and RoboNet) using several different methods, including iVideoGPT. Metrics used to evaluate performance are FVD (lower is better), PSNR (higher is better), SSIM (higher is better), and LPIPS (lower is better). The table shows the mean and standard deviation of results from three runs for each method.
This table presents the results of visual model-based reinforcement learning experiments conducted on six robotic manipulation tasks from the Meta-World benchmark. The left side shows aggregated results (interquartile mean and 95% confidence interval across 30 runs), while the right side details individual task performance (mean and 95% confidence interval across 5 runs) in terms of success rate over 20 evaluation episodes. The impact of pre-training (PT) on model performance is also highlighted.

This table shows the computational efficiency of different tokenization methods (4x4, 16x16, and the proposed method) for video generation. It reports the time taken for tokenization, generation, and detokenization steps, as well as the GPU memory usage for each method. The results highlight the computational efficiency of the proposed compressive tokenization method.
Full paper#