↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for novel view acoustic synthesis (NVAS) often suffer from low efficiency and limited scene understanding. They struggle to accurately capture room geometry, material properties, and the spatial relationships between listener and sound source, resulting in less realistic audio reproduction. These limitations hinder the creation of truly immersive AR/VR experiences.
To overcome these limitations, this paper introduces AV-GS, a novel model that efficiently learns a comprehensive 3D scene representation. AV-GS uses audio-guidance parameters to optimize point distribution, addressing the challenges of conventional methods. The results demonstrate significant improvements in audio quality compared to state-of-the-art techniques on both real and simulated datasets, highlighting the potential of AV-GS for creating more realistic and immersive audio experiences.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to novel view acoustic synthesis (NVAS), a problem of significant interest in AR/VR. AV-GS offers a more efficient and accurate method than existing techniques by leveraging both visual and audio cues in a unique way. This opens avenues for more realistic and immersive audio experiences in virtual environments and has implications for various applications such as gaming, teleconferencing, and virtual tourism.
Visual Insights#

This figure shows the distribution of Gaussian points learned by the AV-GS model for sound propagation between a listener and a speaker. The points are color-coded to represent their contribution to the sound propagation, with points closer to the direct path between the listener and speaker having higher contributions. The figure also highlights points outside of the direct sound path, such as those behind the speaker or reflecting off walls, demonstrating AV-GS’s ability to model indirect sound propagation.
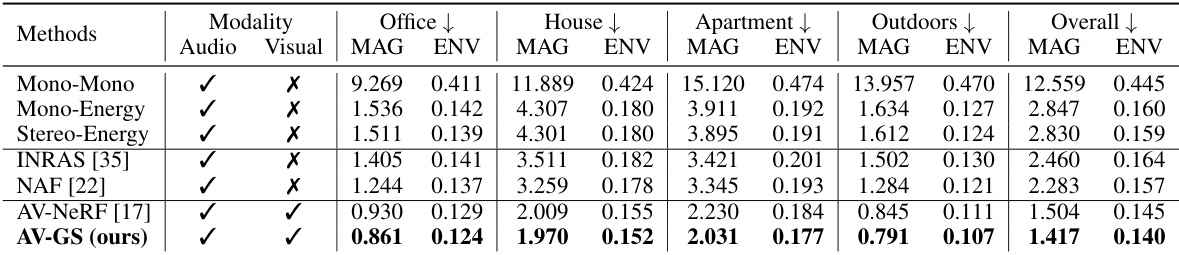
This table compares the performance of AV-GS against other state-of-the-art methods on the RWAVS dataset. The metrics used are MAG (magnitude distance) and ENV (envelope distance), both common metrics for evaluating the quality of binaural audio synthesis. The table shows that AV-GS outperforms all other methods across all scenes in the dataset, demonstrating its effectiveness in generating high-quality binaural audio.
In-depth insights#
AV-GS: A Novel Model#
The proposed AV-GS model presents a novel approach to novel view acoustic synthesis (NVAS) by combining visual and auditory information. Unlike previous methods that rely heavily on inefficient NeRF-based rendering, AV-GS leverages an explicit point-based scene representation. This allows for efficient learning of both geometry and material properties, which are crucial for accurate sound propagation modeling. The model’s audio-guidance parameter further enhances its ability to capture the complex interplay between audio and visual cues. A key innovation is the adaptive point densification and pruning strategy, which ensures that computational resources are focused on the areas most relevant to sound propagation. This results in a significant improvement in efficiency and accuracy compared to existing methods, as demonstrated through extensive experiments on real-world and simulated datasets. The holistic approach of AV-GS, effectively addressing the limitations of previous models by incorporating comprehensive spatial context and material awareness, makes it a promising advancement in the field of NVAS.
Geometry-Aware Priors#
The concept of “Geometry-Aware Priors” in the context of novel view acoustic synthesis (NVAS) suggests incorporating prior knowledge about the 3D environment’s geometry into the synthesis process. This is crucial because sound propagation is highly dependent on the shape and material properties of the surrounding space. Traditional methods often struggle to accurately model these complex interactions, relying on simplified assumptions or limited environmental representations. A geometry-aware approach could leverage techniques like point cloud processing or mesh representations to explicitly capture room geometry, potentially including object placement and material properties. By incorporating this geometric information, the NVAS system can make more informed decisions about sound reflection, diffraction, and reverberation, leading to a more realistic and immersive auditory experience. This approach is particularly valuable for creating high-fidelity binaural audio in complex virtual or augmented reality environments where the environment is not fully captured by visual cues. The effectiveness of this approach would be heavily reliant on the sophistication of the geometric model and its integration with the audio synthesis algorithms. Accurate and efficient geometric modeling is essential to prevent computational overhead while ensuring the resulting audio is perceptually accurate.
Audio-Visual Fusion#
Audio-visual fusion in this research paper seeks to improve the realism and immersive quality of novel view acoustic synthesis (NVAS). By combining visual and auditory data, the model can learn richer scene representations than those relying solely on audio or visual cues. This fusion is key to addressing the limitations of previous methods, especially those based purely on visual data, which cannot fully capture the nuances of sound propagation such as diffraction and reflection. The explicit representation of the 3D scene using Gaussian splatting allows the model to incorporate detailed geometry and material properties, crucial for accurate sound modeling. The integration of audio guidance in the point-based scene representation further refines the acoustic characteristics, allowing for more adaptive and realistic audio generation. The results demonstrate that audio-visual fusion enhances the accuracy of NVAS, generating binaural audio that is more consistent with real-world acoustic phenomena, particularly in complex scenes. This approach tackles the challenge of rendering accurate spatial audio in synthetic or virtual environments, leading to more believable and immersive experiences.
Point Management#
The effective management of points is crucial for the success of Audio-Visual Gaussian Splatting (AV-GS) models. The core challenge lies in balancing point density and computational efficiency. Over-dense point clouds lead to high computational costs, while under-dense clouds compromise the accuracy of the scene representation and sound propagation. The paper proposes an innovative strategy of dynamic point adjustment that combines point densification and pruning. Points deemed significant (based on gradient analysis) are added, and less contributing points are eliminated. This adaptive approach optimizes the point cloud, resulting in a more efficient and effective scene representation that accurately reflects the complex interaction of sound with the environment. The effectiveness of this approach is validated through experiments which demonstrate improved binaural audio synthesis over alternative methods. Further analysis into the parameter selection for densification and pruning thresholds could reveal further optimizations in future research.
Future of NVAS#
The future of Novel View Acoustic Synthesis (NVAS) appears bright, driven by several key factors. Advancements in deep learning will likely lead to more efficient and realistic audio rendering, overcoming current limitations in computational cost and audio quality. Integrating diverse data modalities beyond visual and audio, such as tactile and haptic data, could significantly improve the immersion of virtual and augmented reality experiences. Improved scene representation methods, such as more sophisticated point cloud representations and the incorporation of physics-based simulation, are crucial for handling complex acoustic phenomena. Ultimately, real-time NVAS with high fidelity will enable transformative applications in entertainment, communication, and remote collaboration, opening the door to truly immersive virtual environments.
More visual insights#
More on figures

This figure shows the overall architecture of the proposed AV-GS model. It illustrates the three main components: a 3D Gaussian Splatting model (G) for capturing scene geometry, an acoustic field network (F) for processing audio-guidance parameters, and an audio binauralizer (B) for transforming mono audio into binaural audio. The figure details the flow of information and processing steps, from initial scene representation to final binaural audio output.

This figure compares the performance of AV-NeRF and AV-GS in scenarios with complex geometry and when the listener’s view is uninformative. It shows that AV-NeRF, which relies on the listener’s view, produces errors in these challenging situations, whereas AV-GS, using its learned holistic scene representation, remains accurate. The figure highlights the differences in the generated binaural audio and scene representations between the two methods.
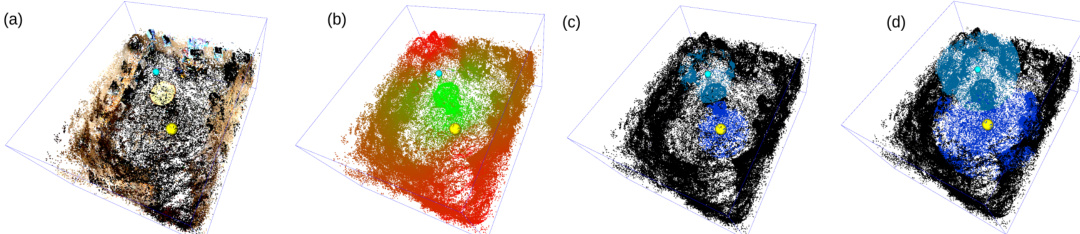
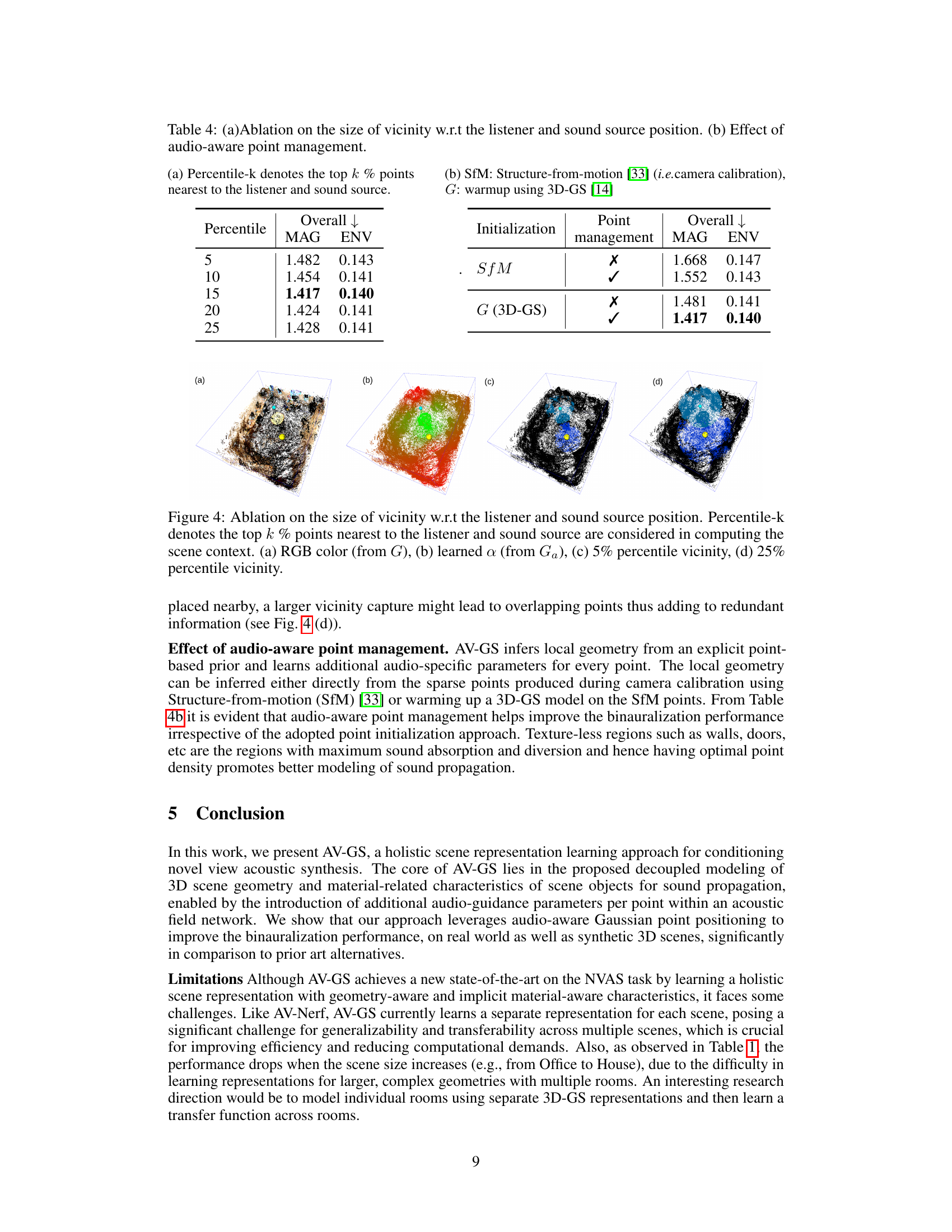
This figure shows the ablation study on the size of vicinity for the listener and sound source. The subfigures (a) to (d) show the effect of different percentile values (5%, 10%, 15%, 20%, 25%) on the selection of points within the vicinity for the listener and speaker. Subfigure (a) displays RGB color from the 3D Gaussian splatting model G (scene geometry). Subfigure (b) illustrates the learned audio-guidance parameters (a) from the audio-focused point representation Ga. Subfigures (c) and (d) represent the 5% and 25% percentile vicinity respectively, visualizing the distribution of points considered for binaural audio synthesis based on proximity to the listener and speaker.

This figure shows how the proposed AV-GS model handles distance awareness in audio synthesis. As the listener (blue sphere) moves further from the sound source (yellow sphere), the amplitude of the generated binaural audio decreases, demonstrating the model’s ability to realistically simulate sound propagation based on distance.
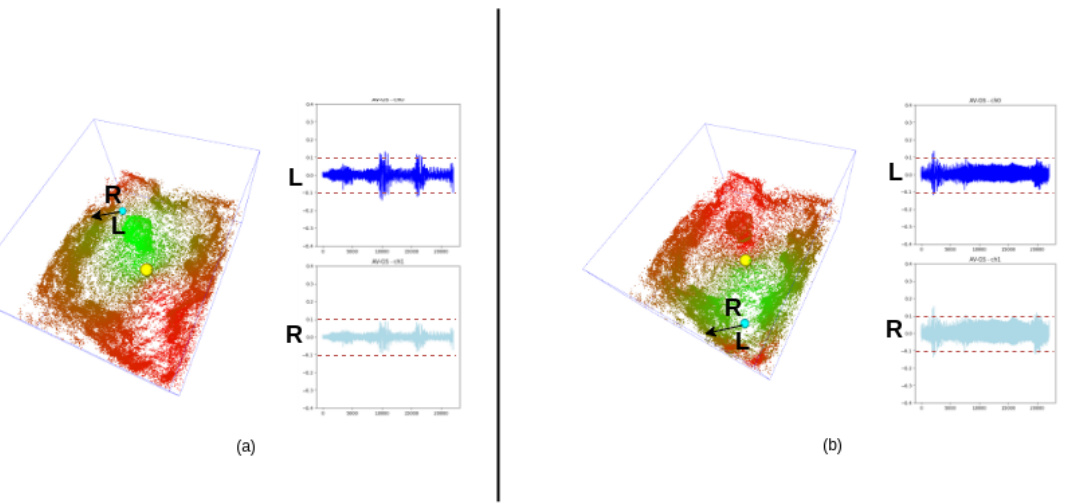
This figure shows how AV-GS handles directionality in audio synthesis. The top row shows the 3D scene representation with the listener’s position, the sound source, and the direction the listener is facing. The bottom row shows the resulting binaural audio waveforms for the left and right channels. In (a), the left channel is louder because the listener is facing towards the source; in (b), the right channel is louder because the sound is to the listener’s right.

This figure shows the architecture of the binauralizer module B, which is a crucial component in the AV-GS model. The binauralizer takes the mono audio and transforms it into binaural audio using learned scene context, listener’s position, and sound source position. It consists of several components, including STFT for short-time Fourier transform, MLPs for multilayer perceptrons, and inverse STFT to generate the final audio output. The figure also includes details on the input and output of each component, making it easier to understand how the module processes the audio signals to produce realistic and immersive sounds.
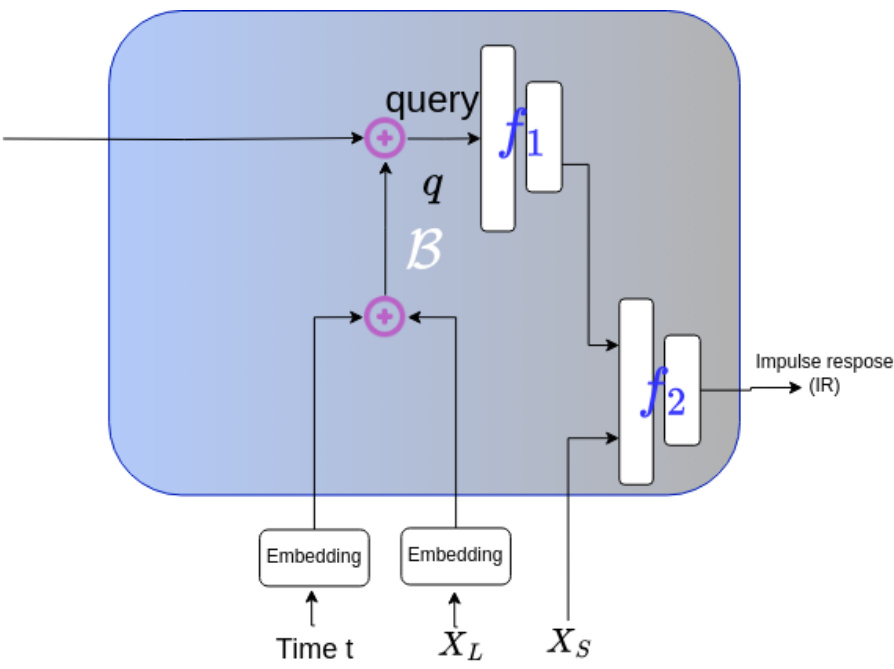
This figure shows the architecture of the binauralizer module B which is adapted from [17] with modifications to input the learned scene context from acoustic field network F. The main components are two Multilayer Perceptrons (MLPs), each having four linear layers with additional residual connections. The width of each linear layer is set to 128 for the RWAVS dataset and 256 for the SoundSpaces dataset. ReLU activation is used for all layers except the last one, which uses a Sigmoid function. The first MLP takes the listener’s position (x, y) and the frequency f as input. A coordinate transformation projects the listener’s direction into a high-frequency space. The output of the second MLP is a mixture mask and a difference mask, both scalars. The process is repeated for all frequencies f ∈ [0, F] to obtain the complete masks mm and md. For the SoundSpaces dataset, the mixture mask is removed, and the impulse response is predicted directly for a corresponding time input.
More on tables
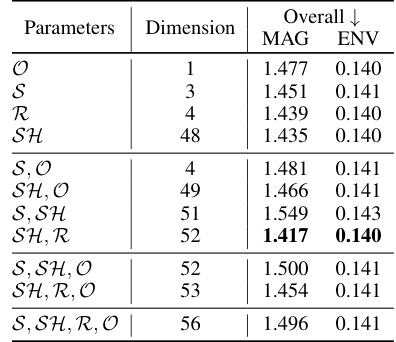
This table presents a comparison of the proposed AV-GS model against other state-of-the-art methods for RIR generation on the SoundSpaces dataset. The comparison uses T60, C50, and EDT metrics, with lower scores indicating better performance. Part (a) shows the comparison with other methods, including open audio codecs. Part (b) is an ablation study showing the effect of using different combinations of physical parameters from the 3D Gaussian Splatting model (G) for initializing the audio-guidance parameter (a) in AV-GS.
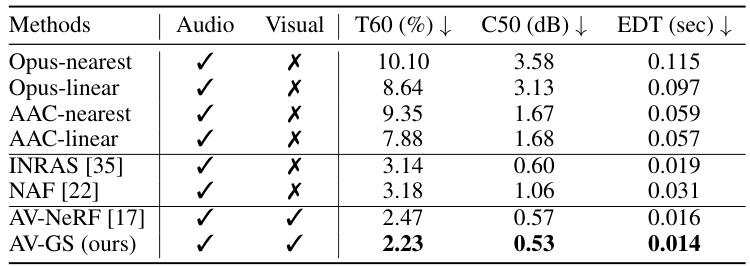
This table presents a comparison of the proposed AV-GS model with other state-of-the-art methods for RIR generation on the SoundSpaces dataset. It uses three metrics (T60, C50, EDT) to evaluate the quality of the generated RIRs. The table also includes an ablation study that investigates the impact of using different physical parameters from the pre-trained 3D Gaussian Splatting (3D-GS) model for initializing the audio-guidance parameters in AV-GS. Lower scores indicate better performance.
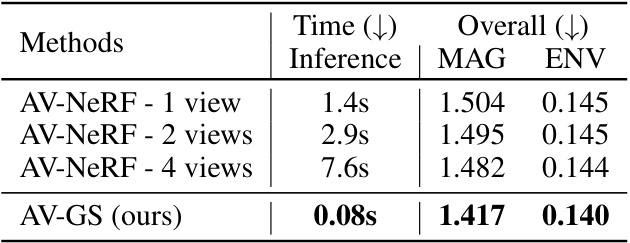
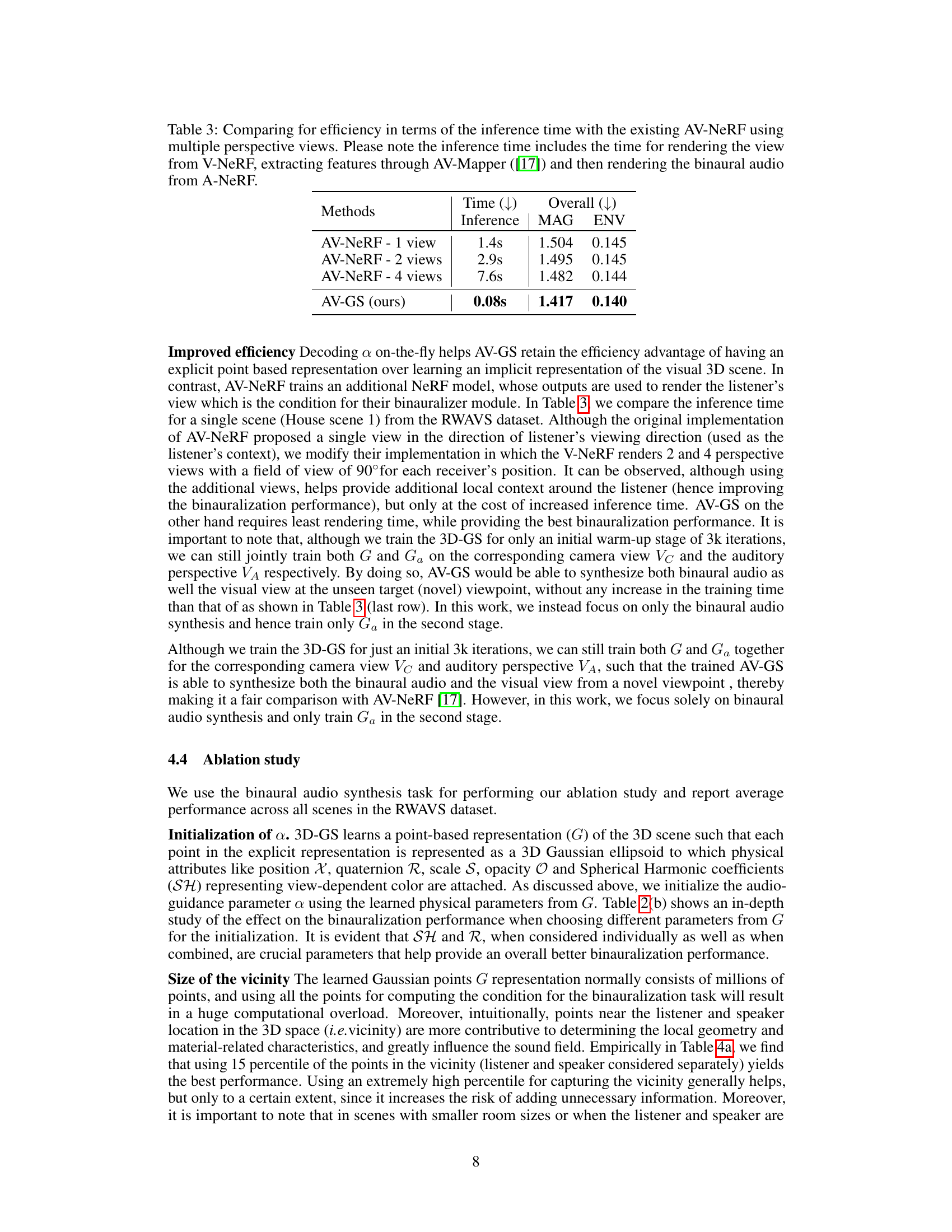
This table compares the inference time of AV-NeRF and AV-GS. AV-NeRF’s inference time increases significantly with the number of views used, while AV-GS maintains high efficiency. The table shows that AV-GS is considerably faster than AV-NeRF while achieving better performance (lower MAG and ENV scores).
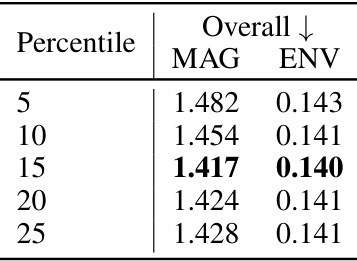
This table presents the results of ablation studies conducted to evaluate the impact of different hyperparameters on the performance of the AV-GS model. Specifically, it investigates the influence of the size of the vicinity (i.e., the number of nearest points considered around the listener and sound source) and the effect of applying an audio-aware point management strategy on the overall model performance, as measured by the MAG and ENV metrics.
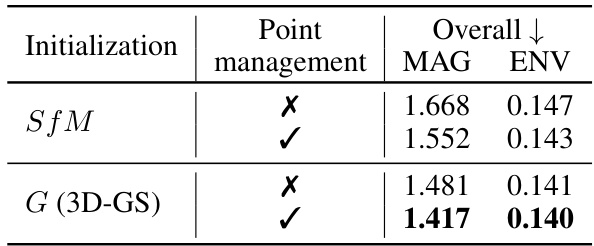
This table presents the ablation study results on the impact of (a) the size of vicinity and (b) the effect of audio-aware point management on the performance of AV-GS. The vicinity refers to the number of nearest points considered for computing the holistic scene context for binaural audio synthesis. Audio-aware point management refers to the proposed strategy of error-based point growing and pruning for sound propagation. The table shows that using a 15% percentile of the nearest points and employing the audio-aware point management technique improves the performance in terms of MAG and ENV.
Full paper#