↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The rise of powerful text-to-image models raises concerns about unauthorized use of datasets used in their training. Existing methods like watermarking or introducing perturbations are often easily bypassed. This poses a significant challenge for copyright protection, especially for artists whose style might be replicated without their consent.
This paper presents a new solution, focusing on disentangling style domains. Instead of embedding watermarks directly into images, it generates watermarks from these disentangled style domains, making them more resistant to removal. The use of identifier z and dynamic contrastive learning further strengthens the watermarking process. The method achieves One-Sample-Verification and a watermark distribution approach to handle copyright infringements, even hybrid ones, showcasing its robustness and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on copyright protection in AI-generated content and disentangled representation learning. It directly addresses the critical issue of unauthorized data usage in training AI models, offering a novel and robust solution. The proposed method opens avenues for further research into watermarking techniques and self-generalization within style domains. Its implications extend to broader discussions on AI ethics and ownership of intellectual property in the age of generative AI.
Visual Insights#
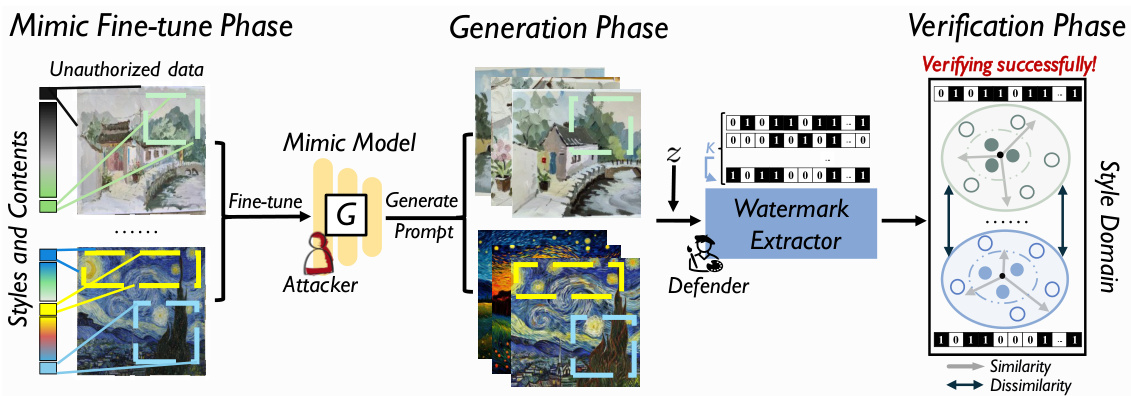
This figure illustrates the three main phases of the proposed dataset copyright verification method: Mimic Fine-tune Phase, Generation Phase, and Verification Phase. In the Mimic Fine-tune Phase, an attacker uses unauthorized data to fine-tune a mimic model. In the Generation Phase, the attacker uses the mimic model to generate images based on a given prompt. The defender then employs a watermark extractor, utilizing specific watermark mapping relationships and an identifier z, to analyze these generated images in the Verification Phase. This process aims to detect unauthorized dataset usage by focusing on the style domain rather than traditional embedding and extraction techniques. The figure shows a clear flow of information and how the watermark extractor identifies similarities and dissimilarities in the style domain between the protected datasets and the images generated by the mimic model.
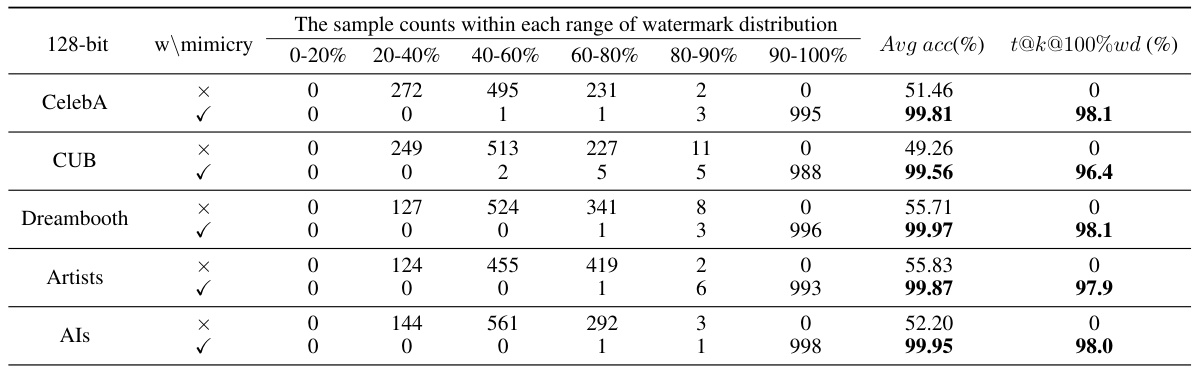
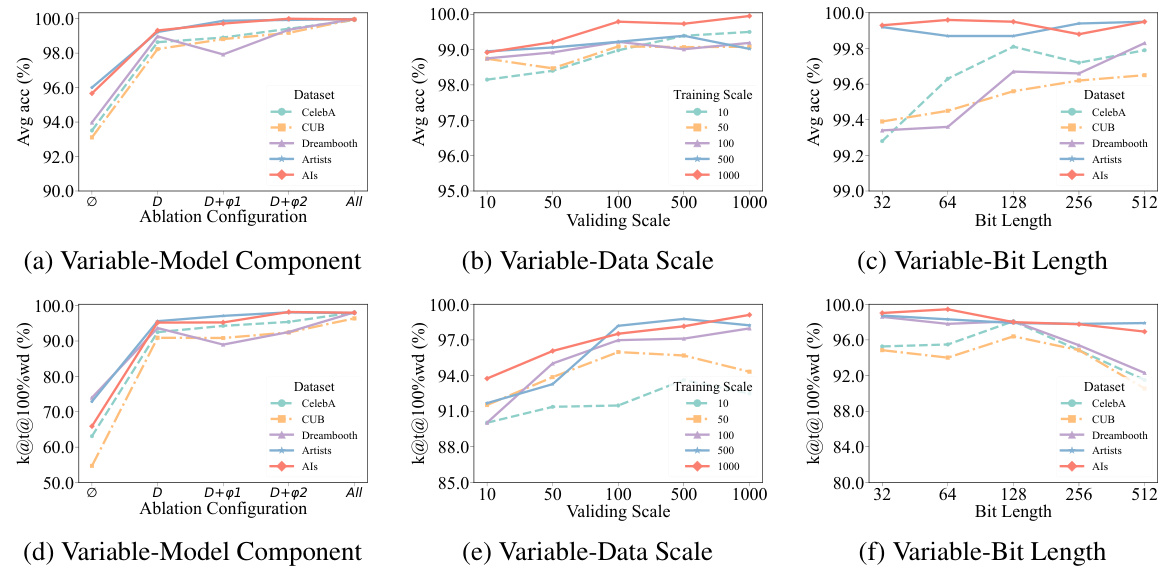
This table presents the results of the watermark distribution experiments. It shows the number of samples in different watermark accuracy ranges (0-20%, 20-40%, …, 90-100%) for both mimic and non-mimic models across five different datasets (CelebA, CUB, Dreambooth, Artists, and Als). The average watermark accuracy (Avg acc) and the percentage of samples with 100% watermark accuracy (t@k@100%wd) are also reported for both cases. The table demonstrates the effectiveness of the proposed z-watermarking method, which achieves significantly higher accuracy for the protected datasets.
In-depth insights#
Style-Based Watermarking#
Style-based watermarking presents a novel approach to copyright protection in AI-generated content, particularly images. Instead of embedding imperceptible data directly into the image, it leverages the inherent stylistic characteristics of the original artwork. The core idea involves extracting a style representation – a kind of ‘fingerprint’ – from the original artwork’s features. This fingerprint acts as a watermark, and any image generated using unauthorized access to the original training data will likely retain traces of this style representation. This approach offers greater resilience against adversarial attacks, as directly altering the image’s style is more noticeable and difficult than subtly modifying embedded data. Furthermore, style-based watermarking potentially enables One-Sample Verification, allowing copyright holders to assert ownership based on a single, potentially publicly available instance, which significantly improves the feasibility of enforcement. However, challenges exist in robustly capturing and comparing styles, requiring sophisticated techniques to account for variations in generation and the effects of different training processes. The effectiveness will depend heavily on the distinctness and generalizability of the extracted style features. Therefore, research into efficient, robust style encoding and comparison methods is critical for the practical application of style-based watermarking.
Zero-Watermark Scheme#
A zero-watermark scheme is a novel approach to copyright protection in the realm of AI-generated images, specifically focusing on protecting the unique style and content of datasets used in training models. Unlike traditional watermarking techniques that embed visible or invisible information directly within the image, a zero-watermark scheme leverages the disentanglement of style and content within the image generation model. This approach is significant because it bypasses vulnerabilities associated with traditional methods, such as adversarial attacks designed to remove embedded watermarks. The core of the scheme lies in the creation of implicit watermarks derived from the disentangled style domain. This means generating a unique watermark, specific to the protected dataset, which is inherently linked to the style of the images generated using it. The watermark’s presence or absence serves as a robust indicator of dataset usage. This method exhibits self-generalization and mutual exclusivity; making unauthorized use detectable even if the AI model is further fine-tuned or adapted. The approach tackles the complex problem of hybrid infringements by introducing a watermark distribution mechanism, enabling the precise determination of the presence and extent of copyright violation, even in instances of partial unauthorized usage.
Copyright Boundary#
The concept of “Copyright Boundary” in the context of AI-generated content is crucial and complex. It speaks to the line between legitimate use of training data and infringement. The paper likely explores how to define this boundary, given that AI models learn from vast datasets often containing copyrighted material. A key challenge is distinguishing between inspired creations and direct copying. The paper’s approach might involve techniques to embed watermarks or other identifiers in training data to track unauthorized usage and demonstrate ownership of unique artistic styles, thus establishing a verifiable copyright boundary. The goal is to enable artists and creators to protect their intellectual property within the context of AI, a rapidly evolving landscape demanding clear legal and technical frameworks. The research likely highlights the difficulties in establishing such boundaries due to the inherent nature of AI’s learning process and the potential for style mimicry, even without direct copying.
AI Mimicry Robustness#
AI mimicry robustness in copyright protection is crucial. Robust watermarking techniques are needed to withstand various attacks. Adversarial attacks, such as fine-tuning on altered datasets or using data augmentation, aim to remove or obfuscate embedded watermarks. The effectiveness of watermarking schemes depends on their ability to resist these sophisticated manipulations. The research needs to investigate the robustness of the proposed method against different classes of attacks. The ability to detect unauthorized data usage under these attacks is vital to safeguarding copyright in the age of AI mimicry. One-sample verification, even under duress, is a significant benchmark for practical application. Finally, generalization across various models and APIs is a key factor determining real-world effectiveness, especially in the face of rapidly evolving AI technologies.
Future Research#
Future research directions stemming from this disentangled style domain watermarking method could explore several key areas. Improving robustness against more sophisticated attacks is crucial; current methods, while effective, might be vulnerable to advanced adversarial techniques. Expanding the scope of supported image generation models beyond the tested diffusion models would broaden applicability. The current method’s reliance on a pre-trained style encoder might limit its generalizability; investigating alternative or self-supervised training methods to enhance universality is warranted. Developing more efficient watermark extraction methods is important, as the computational cost could become a limiting factor at scale. Finally, extending the framework to protect not only styles, but also the content of images to truly address full copyright infringement, is another significant and potentially challenging goal.
More visual insights#
More on figures
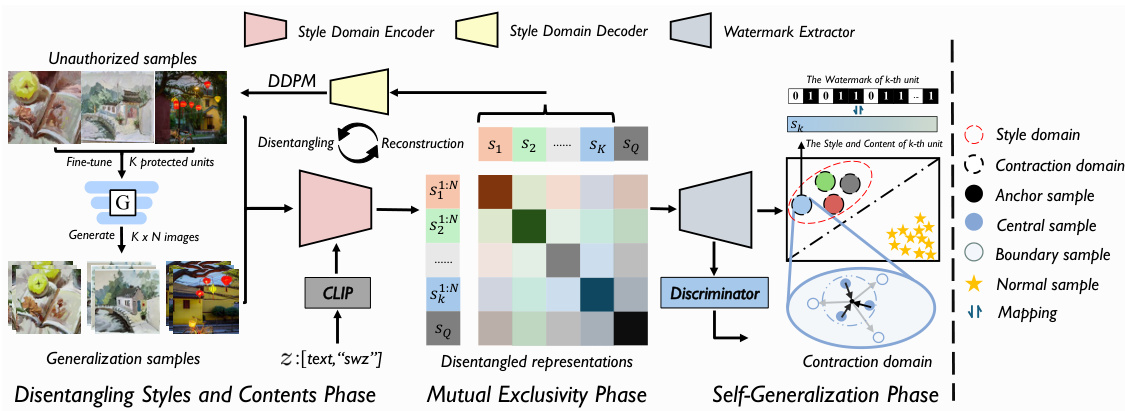
This figure shows the pipeline of the proposed z-watermarking method. The pipeline consists of three phases: Disentangling Styles and Contents, Mutual Exclusivity, and Self-Generalization. In the first phase, the style domain encoder disentangles each protected unit into its style representation, serving as the center anchor of the contraction domain. In the second phase, the contraction domain is generalized by the dynamic contrastive learning between central samples and boundary samples of the specific protected unit. Finally, the domain achieves the maximum concealed offset of probability distribution through both the injection of identifier z and dynamic contrastive learning. This results in an implicit watermark due to the mutual exclusivity of contraction domains, rather than embedding invisible information into datasets.
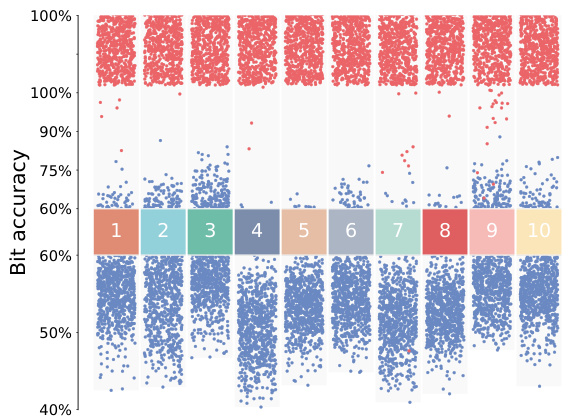
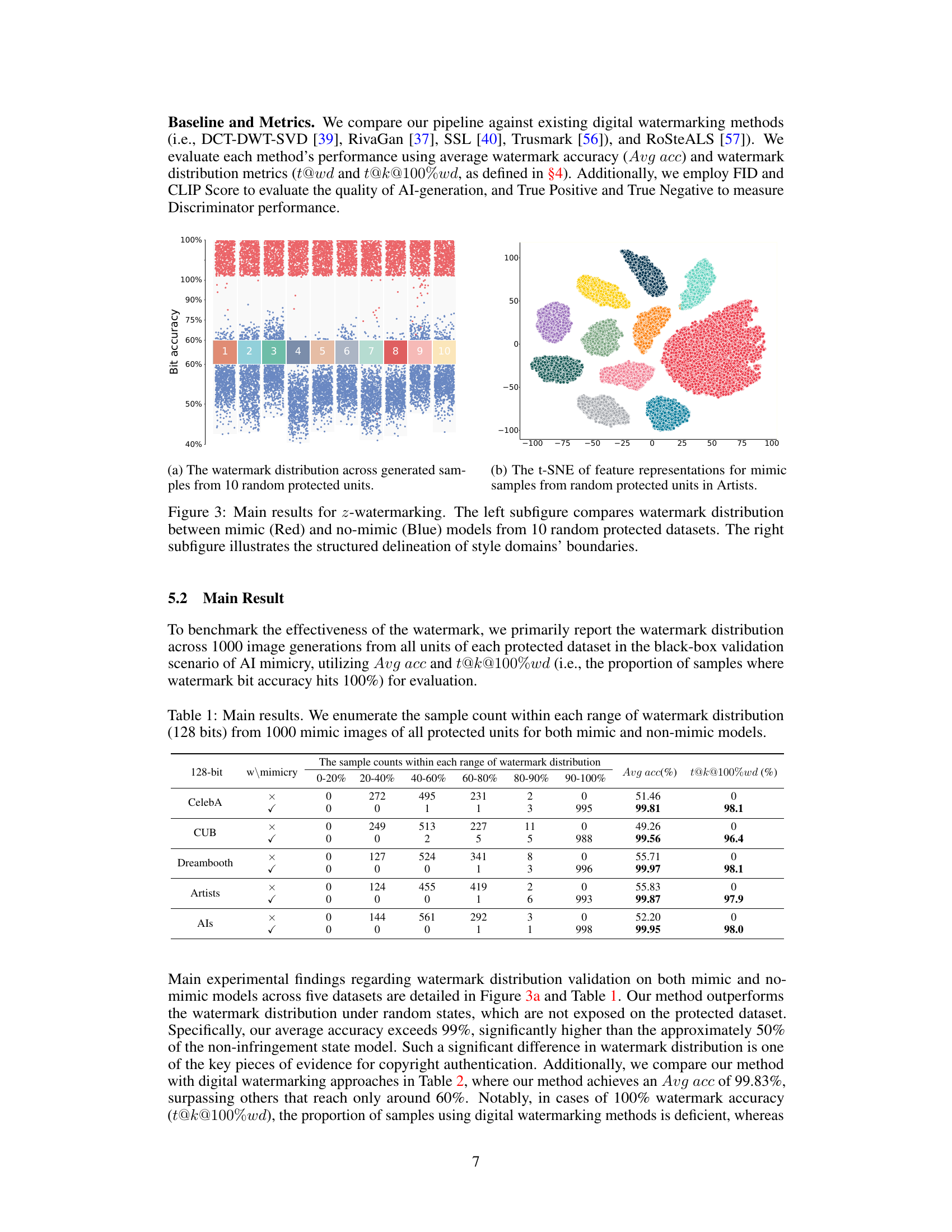
This figure shows the results of the proposed z-watermarking method. The left panel is a visualization of watermark distribution across 1000 generated images from 10 different protected units. Red dots represent mimic samples, while blue dots represent non-mimic samples. A clear separation is observed between the two groups, demonstrating the effectiveness of the method in distinguishing between authorized and unauthorized usage. The right panel uses t-SNE to visualize the feature representations of mimic samples from randomly selected protected units, revealing a structured delineation of style domain boundaries, further supporting the method’s ability to detect unauthorized data usage.
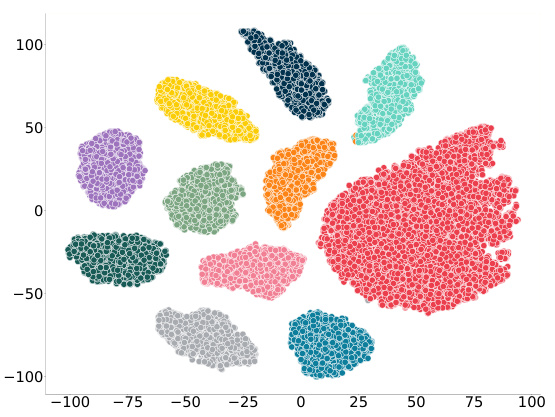
This figure presents the main results of the proposed z-watermarking method. The left part shows the watermark distribution for mimic and non-mimic models generated from 10 randomly selected protected datasets. Red indicates mimic models, and blue indicates non-mimic. The right side uses t-SNE to visualize the feature representations of mimic samples from randomly selected protected units within the ‘Artists’ dataset, showcasing the clear separation and structured delineation achieved by the method between style domains. This visually demonstrates the effectiveness of the method in distinguishing between authorized and unauthorized usage of datasets.

This figure illustrates the three main phases of the proposed z-Watermarking method for dataset copyright verification: Mimic Fine-tune Phase, Generation Phase, and Verification Phase. The Mimic Fine-tune Phase shows an attacker fine-tuning a mimic model on unauthorized data. The Generation Phase depicts the generation of images using a prompt, with a watermark being generated from the disentangled style domain. The Verification Phase demonstrates the verification process which determines whether the generated image uses protected data based on similarity/dissimilarity analysis in the style domain using the watermark extractor and identifier z. The method avoids traditional embedding and extraction by utilizing the disentangled style domain for watermarking.
This figure illustrates the three main phases of the proposed z-Watermarking method for dataset copyright verification. The first phase, ‘Mimic Fine-tune Phase,’ shows an unauthorized attacker fine-tuning a mimic model on protected data. The second phase, ‘Generation Phase,’ depicts the attacker generating images using the mimic model. Finally, the ‘Verification Phase’ demonstrates how the defender uses a watermark extractor and identifier z to successfully verify the copyright ownership by detecting the usage of protected datasets. The method uses disentangled style domains and avoids traditional embedding/extraction techniques, improving robustness.
More on tables
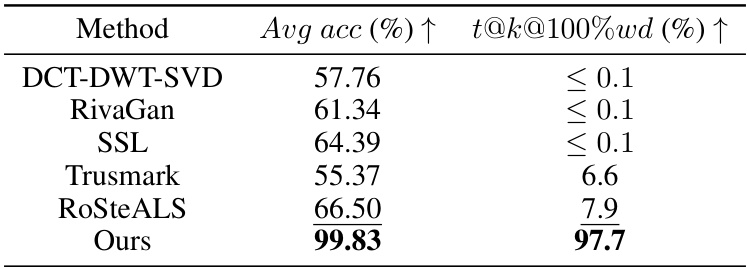
This table compares the performance of the proposed z-Watermarking method against several existing digital watermarking techniques. The comparison focuses on two key metrics: average watermark accuracy (Avg acc) and the percentage of samples achieving 100% watermark bit accuracy (t@k@100%wd). The results highlight the superior performance of the proposed method, particularly in maintaining high watermark accuracy even when traditional methods suffer from watermark removal or dilution during the AI model training process. This indicates that the proposed method is more resilient to attacks that could compromise traditional watermarking schemes.
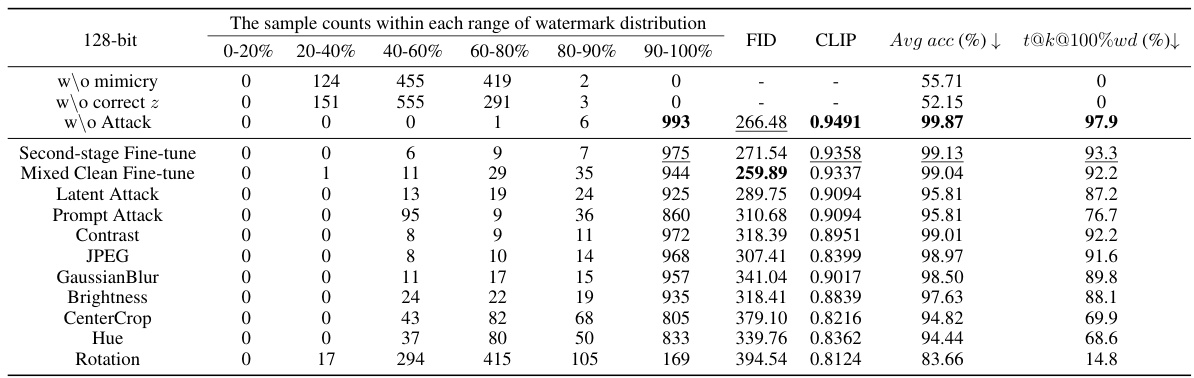
This table presents the results of the watermark distribution experiment. It shows the number of samples falling into different watermark bit accuracy ranges (0-20%, 20-40%, …, 90-100%) for both mimic and non-mimic models across five datasets (CelebA, CUB, Dreambooth, Artists, and ALS). The table also includes the average watermark accuracy (Avg acc) and the percentage of samples achieving 100% watermark accuracy (t@k@100%wd) for each dataset and model type.
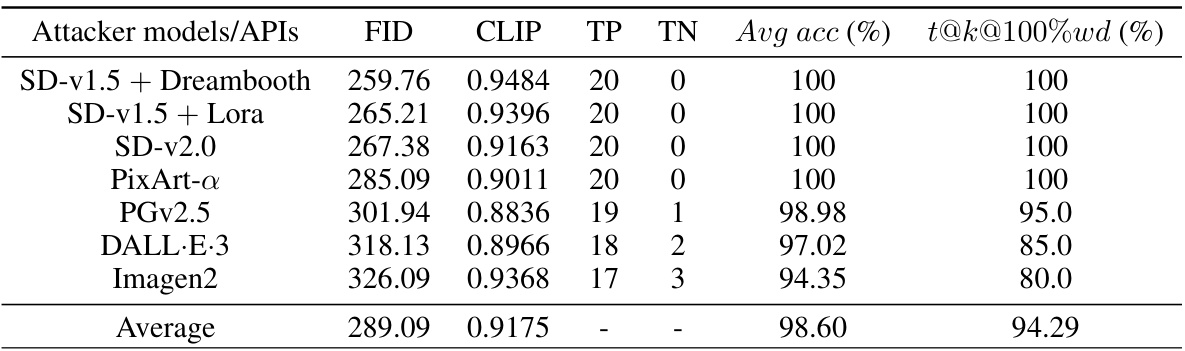
This table presents the results of a generalization study evaluating the performance of the proposed watermarking method against various AI models and APIs. The prompt used was consistent across all models: ‘An art piece resembling the style of ‘Starry Night’’. The table shows the FID and CLIP scores, true positive (TP) and true negative (TN) rates, average accuracy (Avg acc), and the percentage of samples with 100% watermark bit accuracy (t@k@100%wd) for each model. This demonstrates the robustness and generalizability of the watermarking method across different models and APIs.
Full paper#