↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning (CL) faces the challenge of catastrophic forgetting, where models forget previously learned tasks when learning new ones. A key factor causing this is interference between gradients from different tasks. This paper investigates this interference and finds that correlations between data representations, and correlations between class vectors, are major contributors.
The researchers propose a novel method, which they call “global alignment,” to address the issue. This method learns data representations as a task-specific composition of pre-trained token representations, which are shared across all tasks. This ensures that correlations between tasks’ representations are grounded by correlations between pre-trained tokens. Three different transformer-based models are explored to implement this. The method also incorporates a “probing first” strategy that reduces interference from destructive correlations between class vectors. Experimental results demonstrate that their method significantly improves continual learning performance, achieving state-of-the-art results on several benchmarks without experience replay.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the critical problem of catastrophic forgetting in continual learning, a major hurdle in developing AI systems that can learn continuously from streams of data. The proposed global alignment method offers a novel solution by aligning data representations across tasks using pre-trained token representations, resulting in state-of-the-art performance without the need for experience replay. This opens exciting new avenues for research in more efficient and robust continual learning models. The findings are also relevant to researchers working on parameter-efficient fine-tuning, as the global alignment approach shares similarities with recent adaptation methods.
Visual Insights#

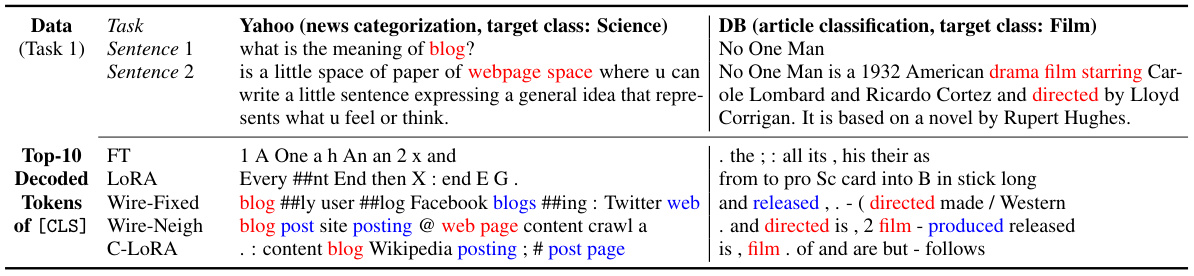
This figure illustrates the proposed continual learning method using global alignment. It shows how task-specific data representations (hᵢ) are created as compositions of pre-trained token representations (grey dots). The alignment of these representations across tasks is grounded by the correlations between the pre-trained tokens. The ‘Class Vectors’ block highlights how a probing strategy helps to reduce interference from overlapping representations by allowing different classes to focus on different aspects of the data representation.
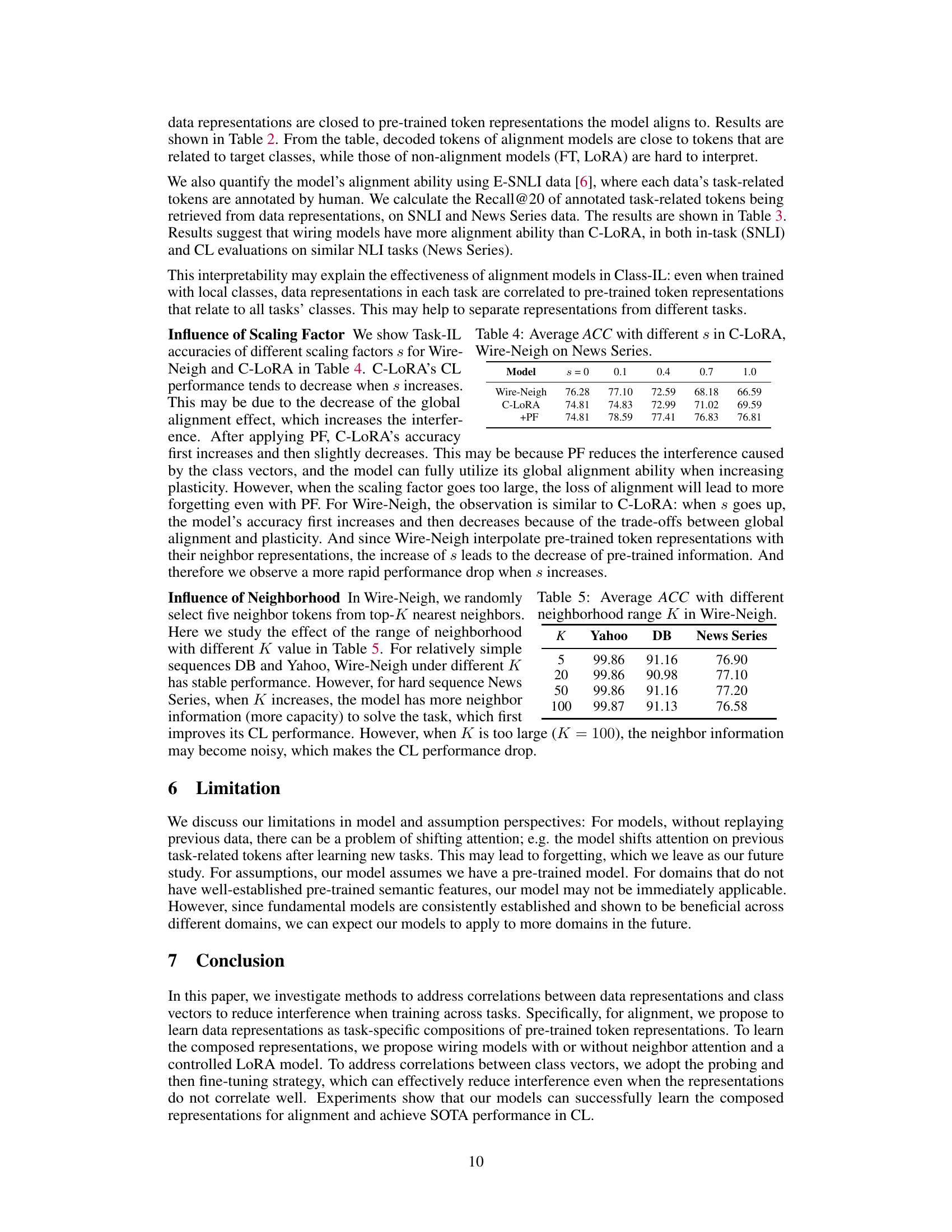
This table presents the results of task-incremental learning experiments using a BERT-base encoder. It compares various continual learning (CL) methods across four datasets: Yahoo, DB, News Series, and an aggregate of all three. For each method and dataset, the table shows the average accuracy (ACC) and forgetting (FGT) across five runs, along with standard deviations. Higher ACC indicates better performance, while lower FGT suggests less catastrophic forgetting. Bold values represent the best performance, and underlined values indicate the second best. ‘OOT’ indicates that the experiment ran out of time.
In-depth insights#
Global Alignment CL#
The concept of “Global Alignment CL” suggests a continual learning approach that emphasizes aligning data representations across different tasks. This contrasts with methods that treat each task in isolation. Global alignment aims to create a shared representation space where the features learned for one task are relevant and beneficial to subsequent tasks. This is achieved by leveraging pre-trained models or establishing correlations between task-specific representations and a shared, global representation. The method prevents catastrophic forgetting by promoting appropriate correlations between tasks. It might involve using pre-trained embeddings as a base, interpolating them to create task-specific representations, or employing techniques that encourage alignment during the learning process. Key advantages are reduced catastrophic forgetting and improved performance, potentially eliminating the need for experience replay which can be computationally expensive. A key challenge is finding the right balance between task-specific adaptation and maintaining alignment with the global representation to avoid losing task-specific information.
Task Interference#
Task interference, a critical challenge in continual learning, arises when the gradients of a new task’s loss oppose those of previously learned tasks. This leads to catastrophic forgetting, where the model’s performance on old tasks degrades significantly. The paper’s analysis suggests that interference’s severity stems from correlations between hidden data representations across tasks, and from correlations between class vectors. Destructive correlations in hidden representations hinder task differentiation, causing the model to confuse or forget older tasks’ characteristics. Similarly, high correlations between class vectors lead to interference, exacerbating the forgetting problem. The paper proposes to mitigate this interference by promoting appropriate correlations between tasks’ data representations and class vectors through global alignment and a probing-first strategy. Global alignment ensures that data representations remain distinguishable across tasks even when learning new ones, thereby reducing interference. The probing-first strategy helps by first training the classifier when switching tasks and then fine-tuning the entire model, enabling class vectors to focus on task-specific features, and further reducing destructive correlations and improving performance.
Alignment Models#
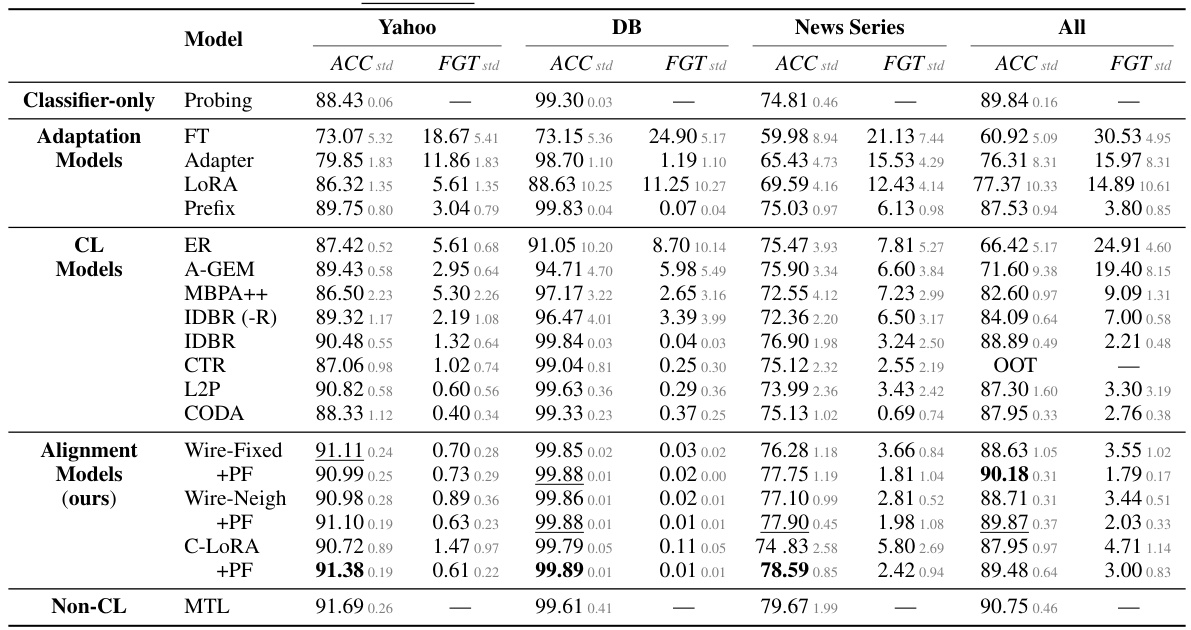
The core concept of “Alignment Models” revolves around reducing catastrophic forgetting in continual learning by aligning data representations across different tasks. This is achieved by leveraging pre-trained token representations as a foundation, allowing the model to learn task-specific compositions of these shared features. This approach ensures that correlations between tasks’ data representations are grounded in inherent relationships within the pre-trained embeddings, reducing destructive interference. Three distinct model architectures are proposed—Fixed Wiring, Wiring with Neighbor Attention, and Controlled LoRA—each offering different levels of flexibility and capacity in achieving this alignment, allowing for investigation of the trade-off between model complexity and alignment fidelity. Probing then fine-tuning is used to further reduce interference by initializing classifiers only when switching tasks, leading to improved performance.
Class Vector Init#
Effective initialization of class vectors is crucial for continual learning, especially when dealing with overlapping data representations from different tasks. Poor initialization can lead to catastrophic forgetting, as the model’s updates for new tasks negatively impact performance on previously learned tasks. A promising strategy is to incorporate a probing-then-fine-tuning approach. This involves first training only the classifier (class vectors) on the new task, allowing it to identify task-specific features in the shared data representation. Subsequently, the entire model is fine-tuned, integrating the task-specific knowledge into the feature representations. This method helps prevent destructive interference by allowing class vectors to focus on distinct feature sets, rather than competing for the same features. Furthermore, aligning data representations from different tasks via global alignment strategies, such as task-specific composition of pre-trained token representations, can improve class vector initialization effectiveness. Careful initialization, coupled with global alignment, is key to reducing catastrophic forgetting and improving continual learning performance.
Future of CL#
The future of continual learning (CL) is bright, but challenging. Addressing catastrophic forgetting remains a key hurdle; current methods often rely on complex mechanisms like regularization or replay, which can be computationally expensive and may not generalize well. Future research should focus on developing more elegant and efficient techniques, potentially inspired by biological learning mechanisms. Understanding the interplay between representation learning and task learning is critical. Methods that effectively learn task-specific features while preserving generalizable knowledge are needed. Developing more robust evaluation benchmarks that assess generalization to unseen tasks and data distributions is crucial. This includes investigating more diverse task sequences and data modalities beyond the currently popular benchmarks. Finally, the field must grapple with the practical challenges of deploying CL systems in real-world applications. This involves considering factors such as data scarcity, computational constraints, and the need for robust and explainable models. Addressing these challenges will unlock CL’s transformative potential across numerous domains.
More visual insights#
More on figures

This figure shows t-SNE plots visualizing the data representations learned by a model without global alignment (a) and a model with global alignment (b). The plots compare the representations after learning the first task and after learning the last task in a continual learning scenario. The model without global alignment shows significant overlap in representations from different tasks after the first task, leading to interference and indistinguishable representations after the last task. In contrast, the model with global alignment maintains distinct representations for different tasks even after learning all tasks, showcasing the effectiveness of the proposed global alignment method.
This figure compares three different alignment models: Fixed Wiring, Wiring with Neighbor Attention, and Controlled LoRA. It illustrates how each model uses pre-trained (blue) and learnable (orange) components to generate task-specific data representations (grey). Fixed wiring directly adapts pre-trained representations for the [CLS] token, while Wiring with Neighbor Attention incorporates contextual information from neighboring tokens. Controlled LoRA adjusts pre-trained representations through low-rank updates applied to all tokens. The models aim to balance learning task-specific features with maintaining alignment to pre-trained representations to prevent catastrophic forgetting.
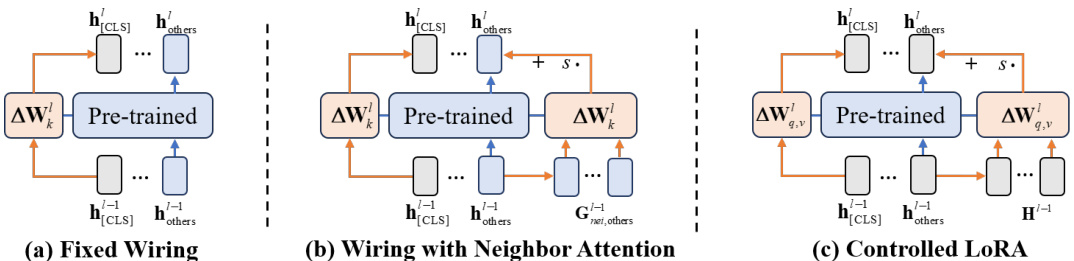
This figure shows the results of class-incremental learning experiments. Subfigure (a) presents a bar chart comparing the classification accuracy after the final task for different continual learning methods, with and without the probing-then-fine-tuning (PF) strategy. Subfigure (b) displays line graphs illustrating the average class-incremental learning accuracy across multiple tasks. The results highlight the performance of the proposed alignment models in both scenarios, particularly in comparison to methods using experience replay like ERACE.
More on tables
This table presents the results of task-incremental learning experiments using a BERT-base encoder. It compares various continual learning (CL) methods across three datasets (Yahoo, DB, and News Series) and an aggregate of all datasets. The metrics reported are average accuracy (ACC) and forgetting (FGT), each with standard deviations calculated across five random seeds. The best and second-best results are highlighted in bold and underlined, respectively. Results exceeding the allotted time are noted as ‘OOT’.

This table presents the Recall@20 scores for four different models (FT, C-LoRA, Wire-Fixed, and Wire-Neigh) on two datasets (SNLI and News Series). Recall@20 measures the proportion of correctly identified task-related tokens among the top 20 predicted tokens, assessing the models’ ability to align data representations. The results show that the proposed alignment models (Wire-Fixed and Wire-Neigh) significantly outperform the baseline models (FT and C-LoRA) in terms of Recall@20, demonstrating the effectiveness of their alignment approach.
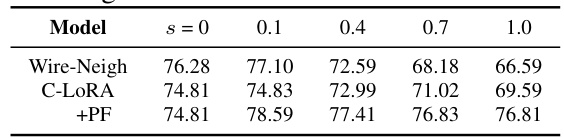
This table presents the average accuracy (ACC) results obtained from experiments on the News Series dataset using different scaling factors (s) for two alignment models: Wire-Neigh and C-LORA, with and without the probing-first (PF) strategy. The scaling factor (s) controls the balance between using pre-trained and task-specific information for generating data representations. The table shows how the average accuracy changes with various scaling factors and how the probing-first strategy affects the performance.
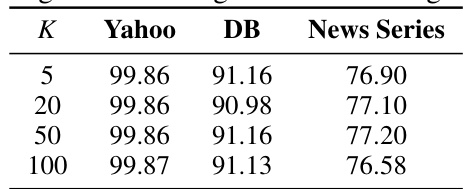
This table presents the results of task-incremental learning experiments using a BERT-base encoder. It compares various continual learning methods across three datasets (Yahoo, DB, News Series) and an aggregate of all three. For each method, the average accuracy (ACC) and forgetting (FGT) are reported along with standard deviations across five random seeds. The best and second-best results are highlighted in bold and underlined, respectively. ‘OOT’ indicates that the experiment did not complete within the allocated time.
Full paper#