↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Text-to-3D models often suffer from the “Janus Problem,” where generated 3D objects exhibit inconsistent viewpoints, such as faces appearing in multiple places. This inconsistency arises from existing methods’ reliance on high-certainty 2D priors, which limits view consistency. The discrete viewpoint encoding and shared 2D priors exacerbate this issue.
The proposed LCGen method tackles this by leveraging low-certainty generation. LCGen guides text-to-3D generation toward different priors with varying certainty from different viewpoints. This approach, tested across several SDS-based text-to-3D models, consistently improves view consistency without sacrificing generation quality or increasing computational costs. LCGen’s effectiveness is demonstrated through both qualitative and quantitative comparisons.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the prevalent “Janus Problem” in text-to-3D generation, offering a novel solution that improves view consistency without significant computational overhead. It opens avenues for enhancing the realism and reliability of 3D models generated from text prompts, which is crucial for various applications like virtual reality and metaverse development. The proposed method’s transferability across different SDS-based text-to-3D models is also a significant contribution.
Visual Insights#

This figure illustrates the core problem that the paper addresses: the Janus Problem. The Janus Problem causes inconsistencies in 3D model generation from text prompts, specifically resulting in multiple views of the same feature (e.g., a head appearing from multiple angles). The figure uses a visual example to demonstrate how the model prioritizes high-certainty areas in 2D representations, leading to the Janus Problem. The solution proposed by the authors, LCGen, is introduced as a way to use low-certainty generation to address this issue by better aligning viewpoints with optimization direction.

This table presents a quantitative comparison of the original methods and LCGen across three different SDS-based text-to-3D baselines. Two metrics are used: Janus Rate (JR), representing the percentage of images with the Janus problem, and CLIP Score (CS), assessing the consistency between the generated image and text prompt. Lower JR values and higher CS values are better. The table shows that LCGen significantly reduces the Janus problem in all three baselines without reducing the quality of generated images.
In-depth insights#
Janus Problem Analysis#
A thorough analysis of the Janus Problem in text-to-3D models reveals its root cause: the reliance on high-certainty 2D priors for 3D representation. This reliance, stemming from discrete viewpoint encoding and shared 2D diffusion priors, leads to view inconsistency, as the model prioritizes locally optimal solutions with high certainty from each perspective. The paper visualizes this issue, demonstrating how probability density peaks at biased positions contribute to the problem. This detailed analysis is crucial, as it moves beyond simply observing the problem and identifies the underlying probabilistic mechanisms. Consequently, it provides a strong foundation for developing effective solutions like Low Certainty Generation (LCGen), which addresses the problem by directly tackling its fundamental cause rather than relying on ad-hoc fixes.
LCGen Methodology#
The LCGen methodology tackles the Janus Problem in text-to-3D generation by decoupling viewpoint data from generation certainty. It addresses the core issue of SDS-based methods relying on high-certainty 2D priors, which leads to inconsistent viewpoints. Instead, LCGen guides the process to generate images with varied certainty levels across different viewpoints. This is achieved by constraining the guidance, not to a single shared prior, but to a certainty-dependent prior specific to each viewpoint. This approach ensures that the 3D model aligns well with the text prompt’s intent across multiple views, mitigating the issue of multiple, conflicting viewpoints. The key innovation lies in leveraging certainty characteristics to decouple data distributions across different views, ultimately improving view consistency. The method is readily adaptable to various existing SDS-based text-to-3D models, offering a significant advance in the field.
Empirical Validation#
An Empirical Validation section in a research paper would rigorously test the study’s hypotheses using real-world data. It should detail the experimental design, including the selection of participants or data points, the methods used for data collection and analysis, and the statistical tests employed. Clear descriptions of the metrics used to measure the key variables are crucial, along with the procedures for handling missing or incomplete data. The results section would present the findings in a clear and concise manner, typically using tables and figures to showcase the data visually. Statistical significance should be assessed and reported, and any limitations of the chosen methods should be acknowledged. Ideally, the findings would be discussed in relation to the existing literature, highlighting the contributions and implications of the research. A robust validation should also include sensitivity analyses to explore how the results might change under different assumptions or parameter values, enhancing the reliability and generalizability of the study’s conclusions. Transparency and reproducibility are paramount, with sufficient detail provided to allow other researchers to replicate the experiments independently.
Limitations and Future#
The research, while effectively addressing the Janus Problem in text-to-3D generation, reveals limitations primarily concerning complex multi-object scenes and unusual object poses. The model struggles with scenarios involving multiple interacting objects or objects in unconventional configurations. Moreover, its success depends heavily on the clarity and specificity of text prompts, making it potentially less robust than other methods. Future research directions should focus on enhancing handling of complex scenes, improving robustness to ambiguous prompts, and exploring integration of more robust 3D priors to overcome current limitations on understanding physical laws and object interactions in 3D space. Investigating the potential impact of different certainty functions and expanding the model’s capabilities to handle diverse and less constrained scenes would also significantly improve its overall effectiveness.
Ablation Study Results#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a text-to-3D model, this might involve removing or modifying elements such as the view encoding scheme, the certainty-based guidance, or specific architectural components. Results would typically show the impact of each ablation on key metrics, such as the frequency of the Janus problem (view inconsistency) and overall generation quality. A successful ablation study will demonstrate the importance of each component to the model’s overall performance and help to justify design choices. Analyzing the results may reveal unexpected interactions between components, highlighting potential areas for further model refinement or future research. For example, removing the certainty component might lead to worse view consistency, while altering the view encoding may impact the quality of generated 3D shapes. A well-designed ablation study provides valuable insights into model functionality and the relationships between its various parts.
More visual insights#
More on figures

This figure analyzes the Janus Problem in text-to-3D models. It demonstrates how discrete viewpoint encoding leads to shared distributions that result in multiple heads appearing at various positions. Panel (a) illustrates the discretization of the sphere representing viewpoints and the resulting shared text guidance. Panel (b) shows how this leads to probability density functions for head positions, with peaks indicating where heads are most likely to appear. Panel (c) expands this to a two-dimensional representation. Panel (d) shows the resulting probability distribution in 3D space, with peaks clearly highlighting the Janus Problem (multiple heads).

This figure illustrates the architecture of the Low Certainty Generation (LCGen) method. LCGen is designed to be integrated into existing SDS-based text-to-3D models. The diagram shows how LCGen takes in a text prompt and camera parameters (c), processes these inputs through a text encoder and LCGen module, and then uses the output to guide a pre-trained diffusion model (Φ). The process generates a 3D representation (Θ), which is then rendered into 2D images from various viewpoints. These images are compared against the diffusion model’s predictions via a Score Distillation Sampling (SDS) loss (LSDS), and the entire system is trained end-to-end. A key aspect is LCGen’s constraint on generation certainty, ensuring that different viewpoints receive appropriately varied guidance, thereby reducing the inconsistencies associated with the Janus Problem.
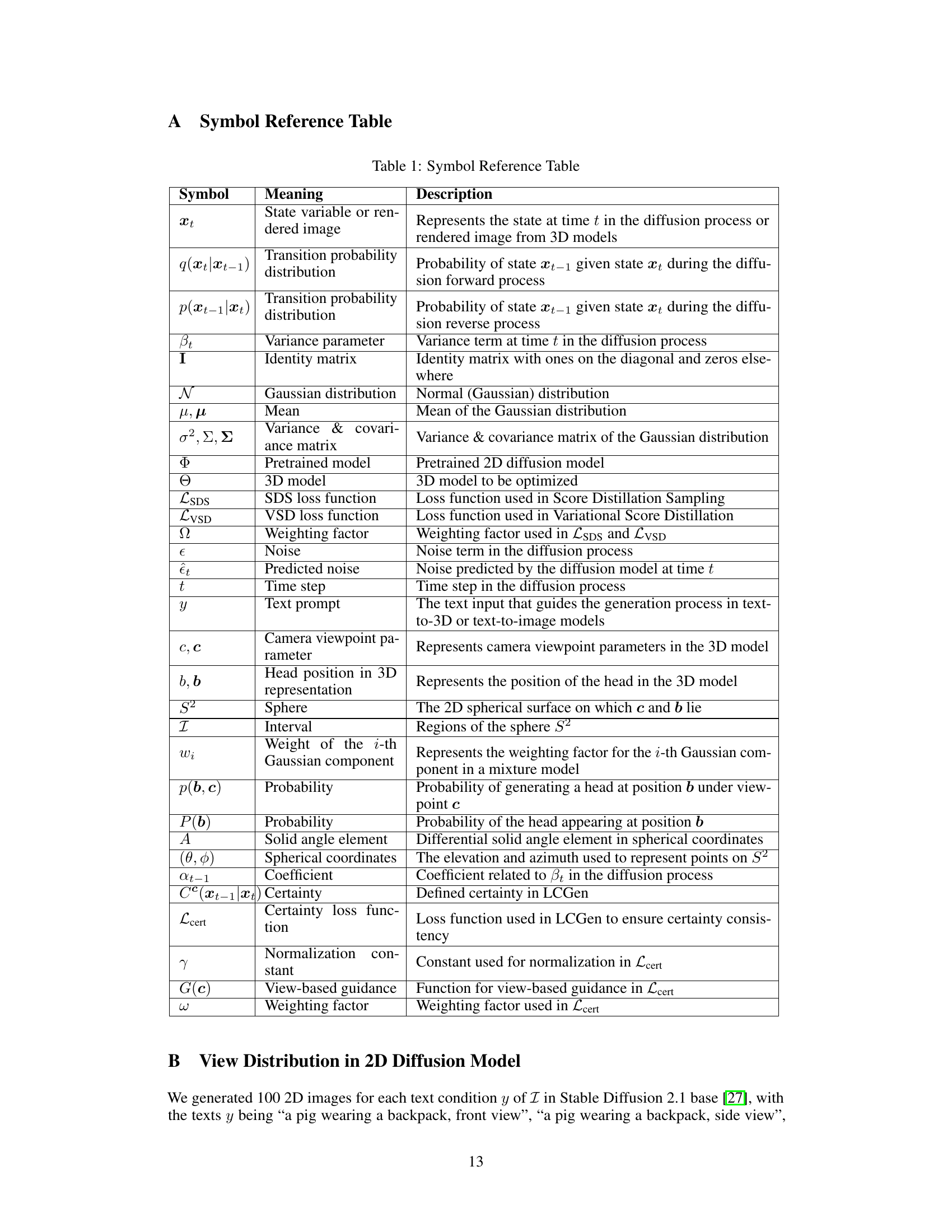
This figure shows a qualitative comparison of the results from three different text-to-3D methods (DreamFusion, Magic3D, and ProlificDreamer) with and without the proposed LCGen method. The images show different views (0°, 90°, 180°, 270°) of 3D models generated from two text prompts: ‘a beagle in a detective’s outfit’ and ‘a fox playing the cello’. Red boxes highlight areas where the Janus Problem (inconsistencies in viewpoints) is present in the original methods. The LCGen method significantly reduces the occurrence of this problem, resulting in more consistent and realistic 3D models.
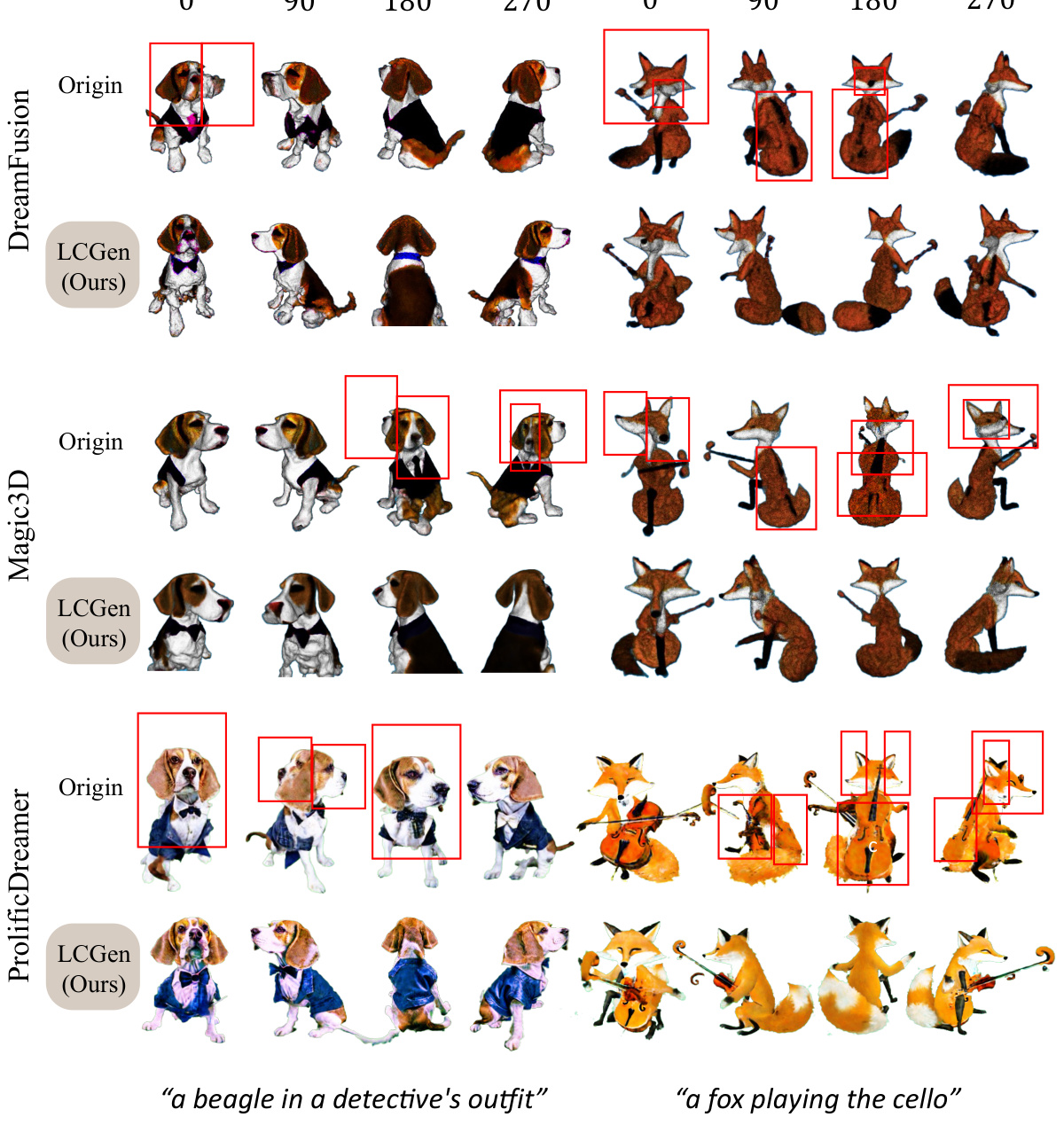
This figure shows the ablation study of the hyperparameter G(c) in LCGen. G(c) controls the preference for low-certainty generation. Three different functions for G(c) are tested: (a) a piecewise function that emphasizes low certainty when the azimuth |φ| is larger than π/6; (b) a function that emphasizes low certainty by squaring the azimuth, (φ/π)²; and (c) a linear function that simply uses |φ|/π. The results show how different choices of G(c) influence the generated images across different steps of the diffusion process.

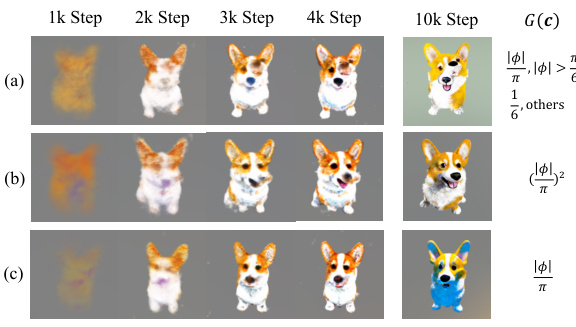
This figure visualizes the effect of LCGen on the certainty of generated images from different viewpoints. The top half shows a 3D scatter plot where the x and y axes represent camera view parameters (azimuth and elevation), and the z-axis represents certainty. The bottom half displays images generated from various viewpoints, color-coded according to their certainty values shown in the scatter plot above. This visualization helps to understand how LCGen influences certainty across different views, aiming to mitigate the Janus problem by ensuring more consistent certainty for various viewpoints of the same object.
This figure visualizes the impact of LCGen on the certainty of generated images from different viewpoints. The top half shows 3D scatter plots illustrating the certainty (z-axis) across different camera views (θ and φ on x and y axes) for both the original method and the LCGen method. The bottom half presents generated images corresponding to various viewpoints, color-coded according to their certainty levels shown in the top half. The visualization highlights how LCGen leads to more consistent certainty across viewpoints, thus improving view consistency of the generated images.

This figure analyzes the Janus Problem, a common issue in text-to-3D methods where multiple heads appear on the same 3D object due to the use of discrete viewpoint encoding and shared priors in 2D lifting. The figure shows how the discrete encoding of viewpoints leads to a high probability of heads appearing at different positions on the sphere, visualized through probability density functions. This problem is related to the reliance on high-certainty 2D priors for 3D representation, leading to inconsistencies in the generated 3D model. The figure illustrates the causes of this problem and how it affects the generation of text-to-3D models.
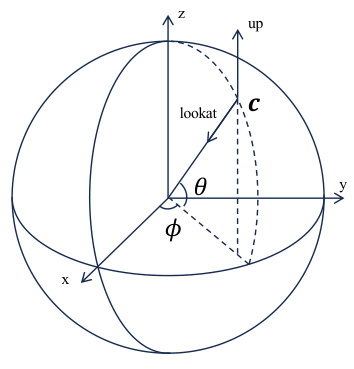
This figure illustrates the camera geometry in 3D space, showing how the camera parameters (lookat, up, and position) are defined on the unit sphere using spherical coordinates. The lookat vector is shown pointing towards the center of the sphere, representing the direction the camera is facing. The up vector is perpendicular to the lookat vector and indicates the camera’s orientation. The position of the camera is represented by the point c on the sphere. The angles θ (elevation) and φ (azimuth) are used to specify the position of the camera on the sphere.
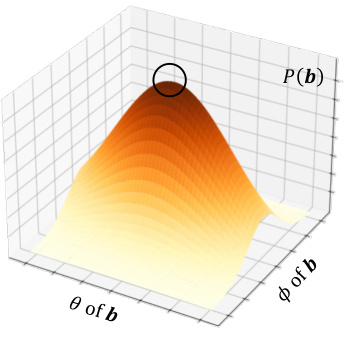
This figure analyzes the Janus Problem, a common issue in text-to-3D methods where multiple heads appear from different viewpoints. It demonstrates how discrete viewpoint encoding leads to shared distributions, increasing the likelihood of the Janus problem. Subfigure (a) illustrates how the sphere of viewpoints is divided into discrete regions, (b) shows probability distributions for head position based on viewpoint, (c) extends the model to a two-dimensional distribution considering both viewpoint and head position, and (d) depicts the resulting probability distribution of head positions, highlighting peaks indicating high probability of multiple heads at different locations.

This figure shows a qualitative comparison of the original methods and the proposed LCGen method on three different SDS-based text-to-3D models (DreamFusion, Magic3D, and ProlificDreamer). The red boxes highlight regions where the Janus Problem (view inconsistency) is present in the original methods, while the LCGen results show improved view consistency and a reduction in the Janus Problem.

The figure illustrates the Janus Problem in Score Distillation Sampling (SDS)-based text-to-3D methods. The problem occurs because these methods rely on high-certainty 2D priors, leading to inconsistencies in the 3D model’s representation from different viewpoints (e.g., a head appearing in multiple places). The proposed LCGen method aims to solve this by utilizing low-certainty generation to better align viewpoints with the optimization direction, thus creating more consistent 3D models.
More on tables

This table compares LCGen with other methods that address the Janus Problem. It highlights key differences in whether additional priors are used, if the method is single-stage or requires multiple stages and fine-tuning, and whether the method is object-specific. The Janus Rate (JR) and CLIP Score (CS) are provided as quantitative metrics for evaluating the effectiveness of each method in mitigating the Janus Problem and maintaining the quality of generated images.

This table compares LCGen with other methods that aim to address the Janus Problem in text-to-3D generation. It contrasts the methods in terms of their approach, whether they utilize additional priors or data, the number of training stages, whether they require fine-tuning, and whether they are object-specific. The table shows that LCGen is unique in its ability to be directly incorporated into existing SDS-based text-to-3D methods without the need for additional priors or fine-tuning.

This table compares LCGen with other methods that aim to address the Janus Problem in text-to-3D generation. It highlights key differences in their approaches, specifically noting whether they use additional priors, employ multiple stages, require fine-tuning, and if they are object-specific. This allows for a clear comparison of LCGen’s unique contribution and advantages compared to existing solutions.
Full paper#