↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are computationally expensive, making inference on CPUs challenging due to the large number of multiply-add (MAD) operations in attention mechanisms. Existing methods struggle to handle the quadratic computational complexity of attention, and simply relying on GPUs is costly and limits accessibility. This paper aims to improve this situation.
The paper introduces NOMAD-Attention, a novel method that replaces MAD operations with in-register lookups using SIMD registers on CPUs. This is accomplished via Product Quantization (PQ) to estimate dot products, compressing lookup tables into SIMD registers, and reorganizing the key cache layout for parallel processing. Experimental results show that NoMAD-Attention achieves up to 2x speedup on a 4-bit quantized LLaMA-7B model while maintaining performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on efficient LLM inference because it presents a novel approach to significantly speed up LLMs on CPUs, a widely used but computationally limited platform. This work opens new avenues for deploying LLMs on resource-constrained devices, which is a key challenge in expanding the accessibility of LLM applications. The proposed method, which utilizes SIMD registers for optimized calculations, is highly relevant to current research trends focusing on low-latency, hardware-aware algorithms.
Visual Insights#
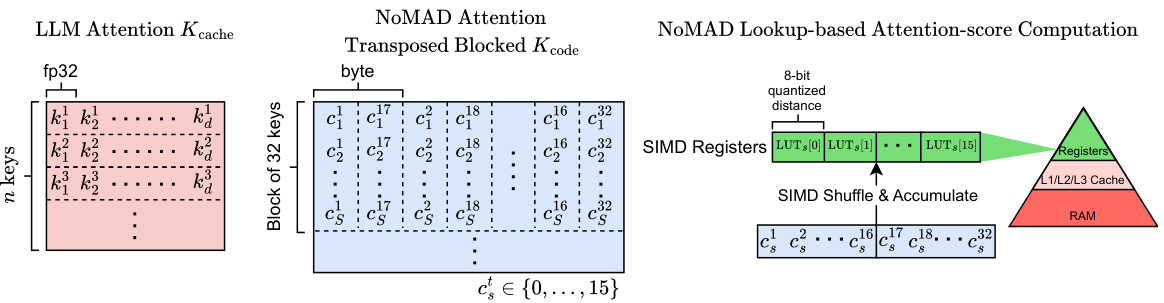
This figure compares the memory layout of the key cache in standard LLM attention with the key-code cache in NOMAD attention. It highlights how NOMAD attention uses transposed and blocked key codes, enabling efficient lookups using SIMD registers. The right side shows how the SIMD registers, LUTs (lookup tables), and memory hierarchy interact to calculate attention scores with ultra-low latency.
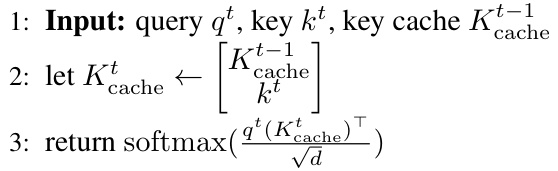
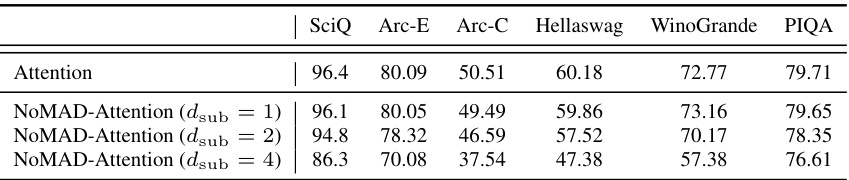
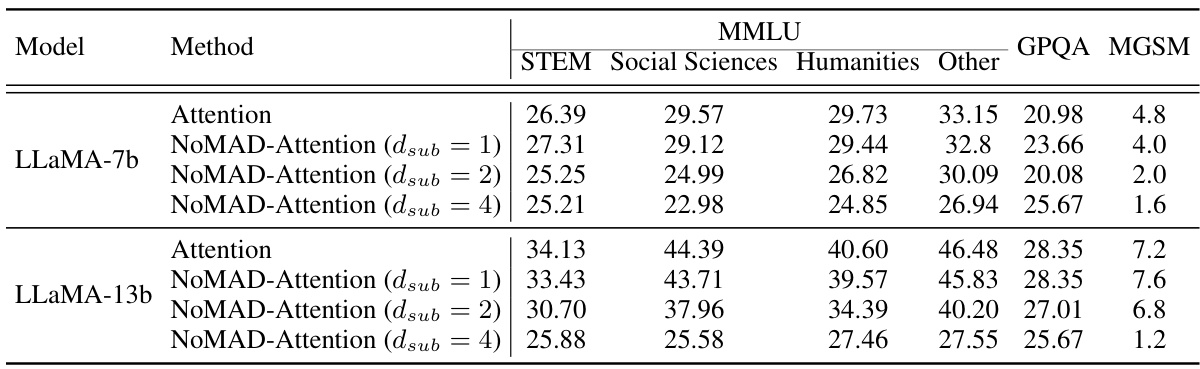
This table presents the results of evaluating the performance of LLMs using both the standard Attention mechanism and the proposed NOMAD-Attention method. It shows the perplexity scores on the WikiText-2 and C4 datasets, as well as accuracy scores across six different benchmark tasks: SciQ, Arc-Easy, Arc-Challenge, HellaSwag, Winogrande, and PIQA. The results are broken down for different LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and varying configurations of NOMAD-Attention (dsub = 1, 2, 4), allowing for a comparison of performance trade-offs between speed and accuracy.
In-depth insights#
CPU-LLM Inference#
CPU-based inference for large language models (LLMs) presents a significant challenge due to the computational demands of the attention mechanism. Traditional attention mechanisms rely heavily on multiply-accumulate (MAD) operations, which are computationally expensive on CPUs. The core bottleneck lies in the quadratic complexity of attention, making it particularly inefficient for longer sequences. However, modern CPUs possess Single-Instruction-Multiple-Data (SIMD) registers capable of ultra-low latency lookups. Efficient algorithms can leverage these registers to replace MAD operations with fast in-register lookups, significantly improving performance. This approach, as demonstrated in research, enables faster inference without sacrificing model quality by cleverly transforming dot-product computations into memory lookups through techniques like product quantization and optimizing data layout within the SIMD registers for efficient batch processing. The potential for improved efficiency is substantial, enabling the deployment of LLMs on resource-constrained devices such as CPUs while retaining accuracy and performance.
NoMAD-Attention#
NoMAD-Attention, as presented in the research paper, proposes a novel approach to significantly enhance the efficiency of large language model (LLM) inference on CPUs. The core innovation lies in replacing computationally expensive multiply-add (MAD) operations, typically dominating attention mechanisms, with ultra-fast in-register lookups. This is achieved by leveraging Single-Instruction-Multiple-Data (SIMD) registers, a commonly available feature in modern CPUs, to store and access pre-computed dot-product lookup tables (LUTs). The method employs product quantization to approximate attention scores, enabling efficient lookup-based computation. NoMAD-Attention demonstrates hardware-aware algorithmic designs to overcome the limitations of SIMD register size, cleverly compressing and reorganizing the data layout for optimal performance. The technique is demonstrated to be compatible with pre-trained models, requiring no fine-tuning, resulting in substantial speed improvements (up to 2x) without compromising LLM quality, particularly with quantized models and longer context lengths. The research highlights the effectiveness of exploiting underutilized CPU capabilities for efficient LLM inference.
SIMD Register Use#
The effective utilization of SIMD registers is a central theme in this research, revolving around the core idea of replacing computationally expensive multiply-add operations with faster in-register lookups. The paper highlights the unique potential of SIMD registers for ultra-low-latency data access, especially within the context of CPU-based LLM inference. Product quantization plays a crucial role, enabling the transformation of dot product computations into efficient table lookups stored within the SIMD registers. This approach is further enhanced by a hardware-aware algorithmic design that cleverly optimizes memory layout and data access patterns to maximize SIMD parallelism. However, the limited capacity of SIMD registers presents a challenge, necessitating techniques such as 8-bit quantization of dot products to effectively fit lookup tables into these limited resources. The success of this method rests heavily on the careful balancing of accuracy and speed, a key focus of the experimental evaluation.
Quantization Methods#
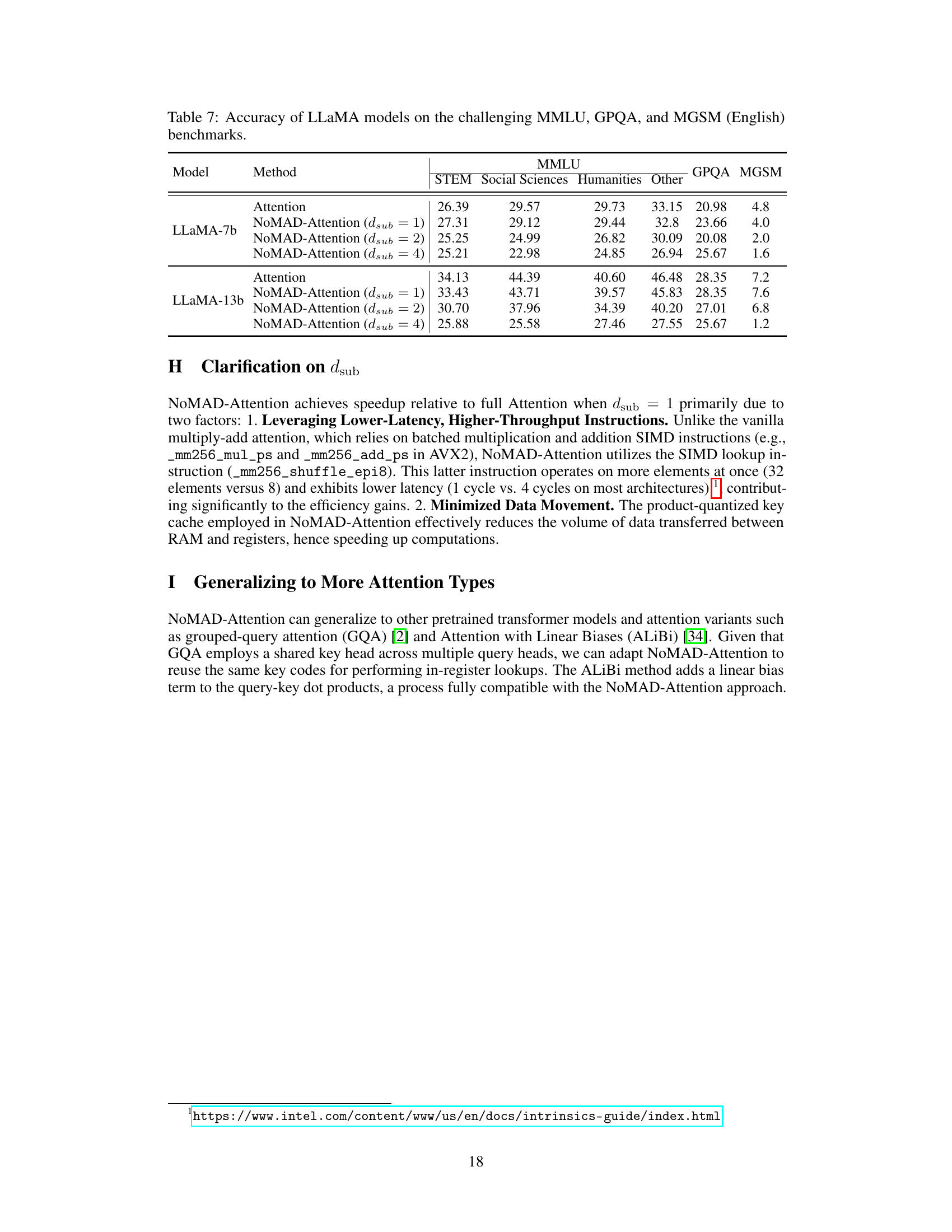
Effective quantization methods are crucial for deploying large language models (LLMs) on resource-constrained devices. Post-training quantization, applied after model training, is particularly attractive due to its simplicity. However, it can lead to accuracy degradation. This necessitates exploring advanced quantization techniques that minimize information loss. Product quantization (PQ), a vector quantization method, emerges as a promising approach for efficient compression and approximation of dot products. This method transforms computationally expensive operations into fast lookups, which is particularly advantageous for CPU-based inference. The choice of bit-depth (e.g., 4-bit, 8-bit) significantly impacts the trade-off between model size, speed, and accuracy. Furthermore, dynamic quantization, adapting the quantization parameters per query, can further improve accuracy. Fisher information matrix (FIM)-informed quantization is another advanced strategy to guide the quantization process based on the importance of different parts of the model, maintaining accuracy even with aggressive compression levels. The selection of optimal quantization methods and bit-depths depends on several factors, including the specific LLM architecture, hardware constraints, and acceptable accuracy loss.
Future Research#
Future research directions stemming from the NoMAD-Attention paper could explore extending its applicability to diverse LLM architectures beyond the tested decoder-only models. Investigating its performance with encoder-decoder models and those using different attention mechanisms (e.g., Longformer, Performer) would broaden its impact. Optimizing the product quantization technique itself is key; exploring alternative quantization methods or adaptive quantization strategies based on token importance could improve accuracy and speed. Furthermore, exploring hardware-specific optimizations tailored to specific CPU instruction sets and memory hierarchies beyond AVX-2 would yield even greater efficiency gains. A crucial area of future work involves thorough analysis of the trade-offs between speed and accuracy for different quantization levels, providing concrete guidelines for selecting optimal parameters based on specific application needs. Finally, researching the potential of integrating NoMAD-Attention with other CPU-oriented optimization strategies (e.g., sparsity techniques) to achieve further efficiency improvements presents a promising avenue.
More visual insights#
More on figures
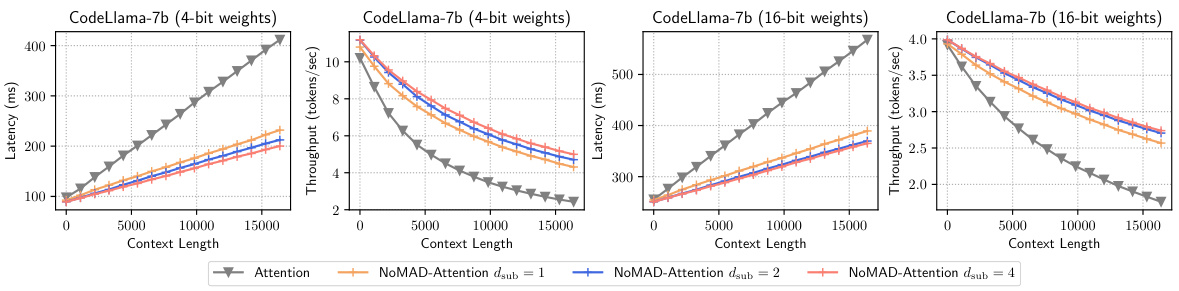
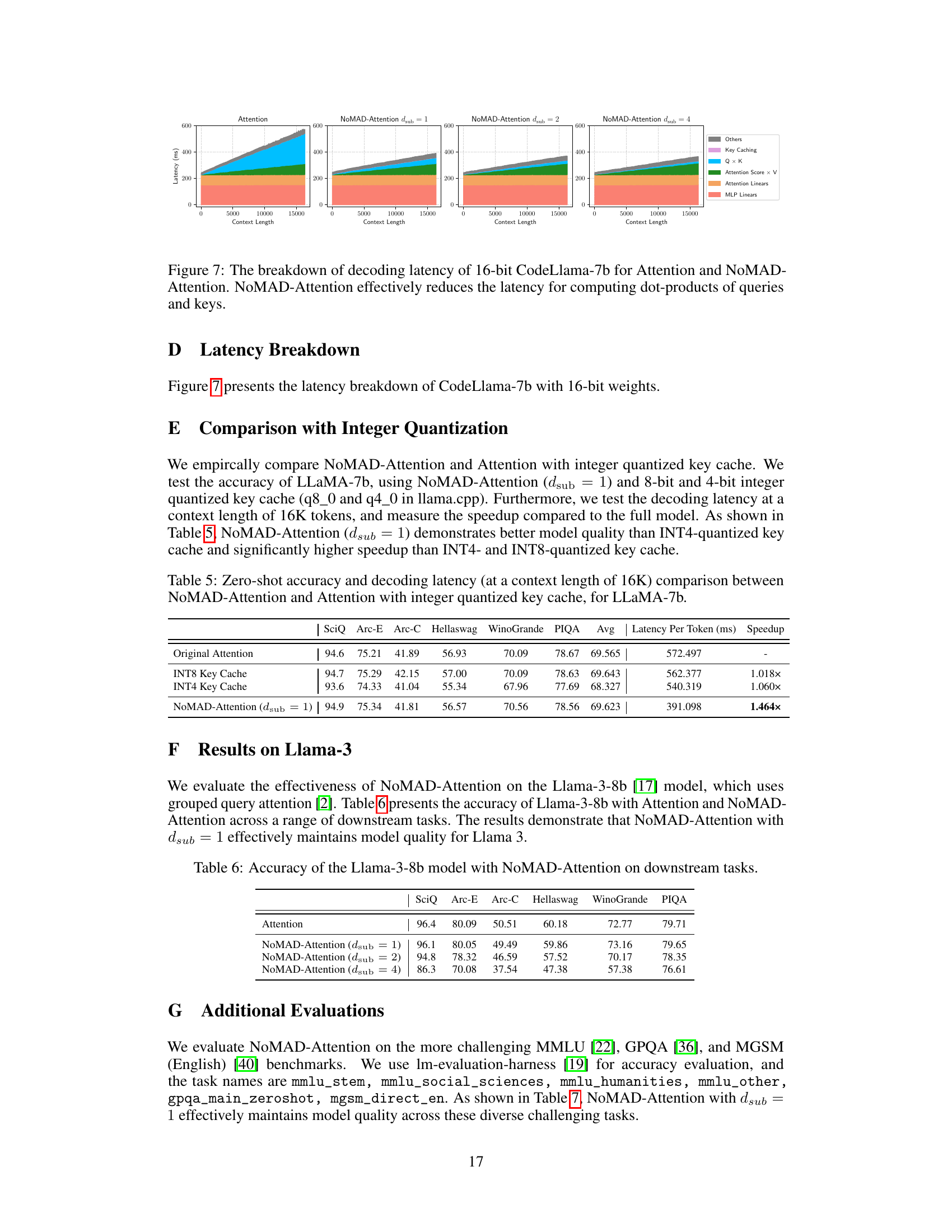
This figure shows the latency and throughput for decoding 16,384 tokens using both Attention and NOMAD-Attention methods on the CodeLlama-7b model, with both 4-bit and 16-bit quantized weights. The results clearly demonstrate that NOMAD-Attention significantly improves the throughput over the traditional Attention mechanism. The improvement is more pronounced with 4-bit quantized weights.
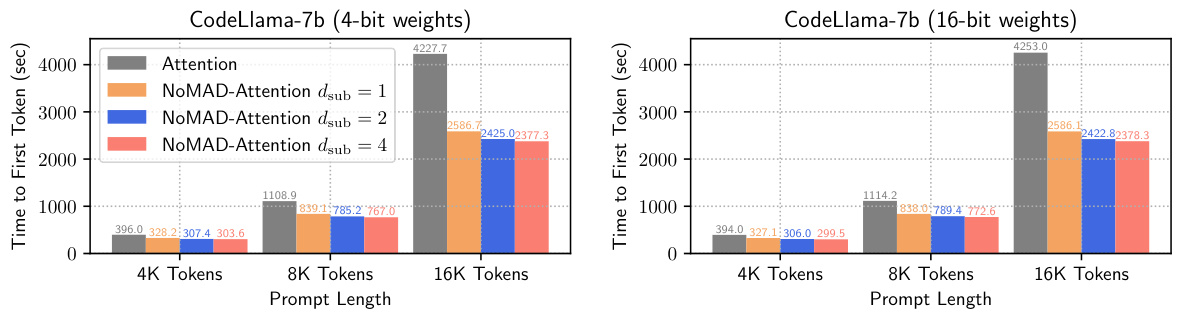
This figure compares the time taken to process prompts of varying lengths (4K, 8K, and 16K tokens) for CodeLlama-7b using both standard Attention and the proposed NoMAD-Attention method. The results show that NoMAD-Attention consistently achieves a significant speedup, particularly noticeable at longer prompt lengths (1.63-1.79x speedup for 16K tokens). Both 4-bit and 16-bit quantized weight versions of the model are shown.

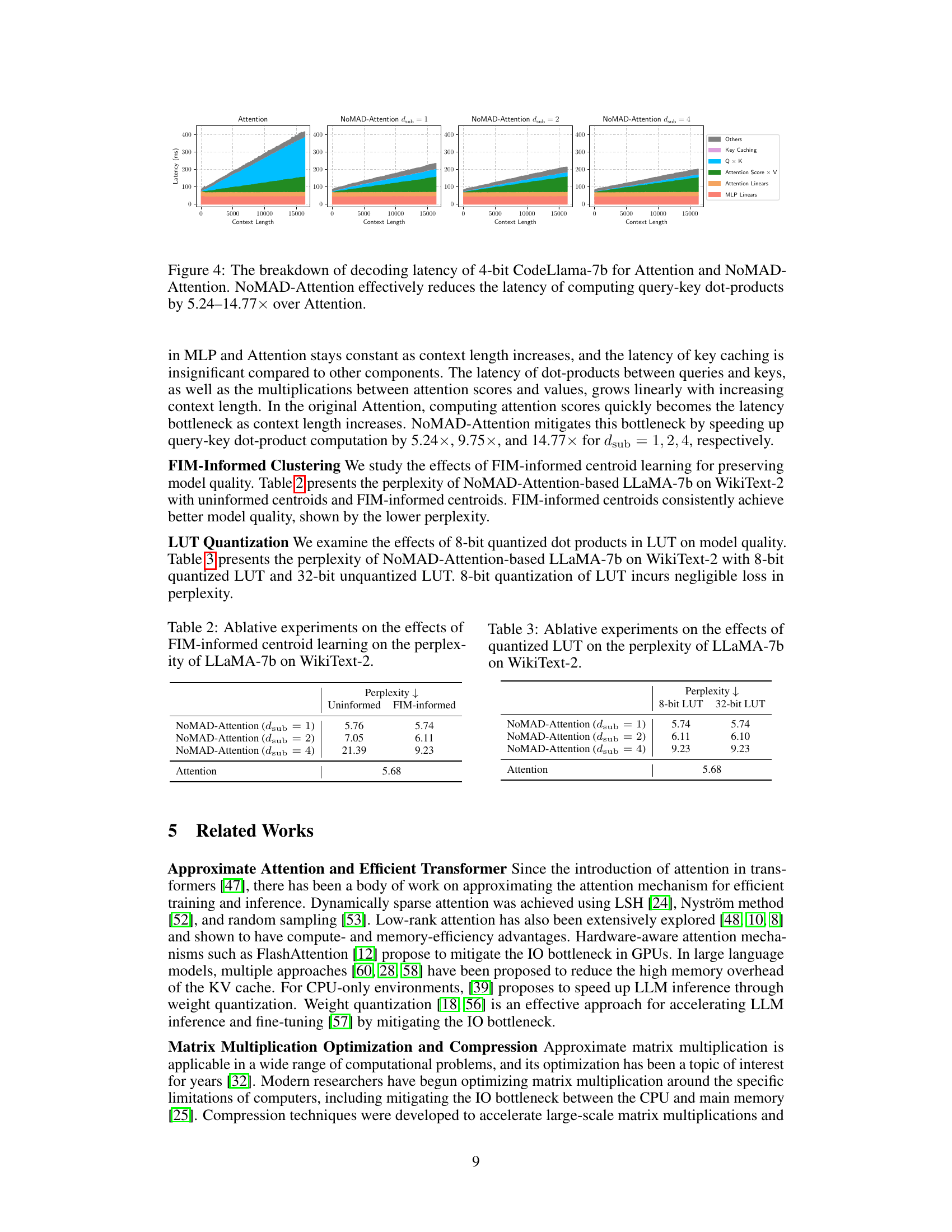
This figure breaks down the latency of decoding for a 4-bit CodeLlama-7b model, comparing the standard Attention mechanism with the proposed NOMAD-Attention method for different levels of sub-quantization (dsub). It visually represents the time spent on various components of the decoding process: - Others (other operations) - Key Caching - Query x Key (Q x K) dot products - Attention Scores x Value (Attention Score x V) multiplication - Attention Linears - MLP Linears The figure demonstrates that NOMAD-Attention significantly reduces the latency of computing the query-key dot products compared to the traditional Attention mechanism. This reduction becomes more significant with higher levels of sub-quantization.
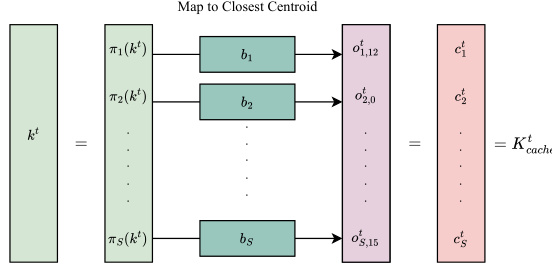
This figure illustrates how a key vector (kt) is processed in the NOMAD-Attention method. First, the key vector is split into sub-vectors using the function πs, one for each sub-quantizer (s = 1…S). Each sub-vector is then mapped to its nearest centroid (bs) within the corresponding codebook. The index of the closest centroid (cts) is then stored in the key cache (Ktcache), which is used for fast lookups later in the process. This product quantization technique converts the computationally expensive dot-product calculation into a simple lookup operation.
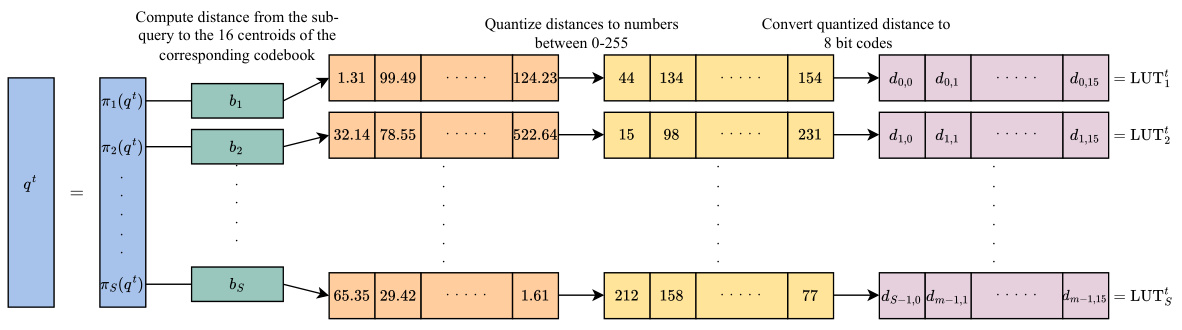
This figure illustrates the process of Product Quantization (PQ) for query vectors. The query vector is split into sub-vectors, and each sub-vector’s distance to 16 centroids (cluster centers) in a codebook is calculated. These distances are quantized to 8-bit codes and stored in a lookup table (LUT) for efficient retrieval during the attention computation. The LUT contains pre-computed dot products, allowing for a faster lookup than traditional multiply-add operations. This method is crucial for NoMAD-Attention’s efficiency.
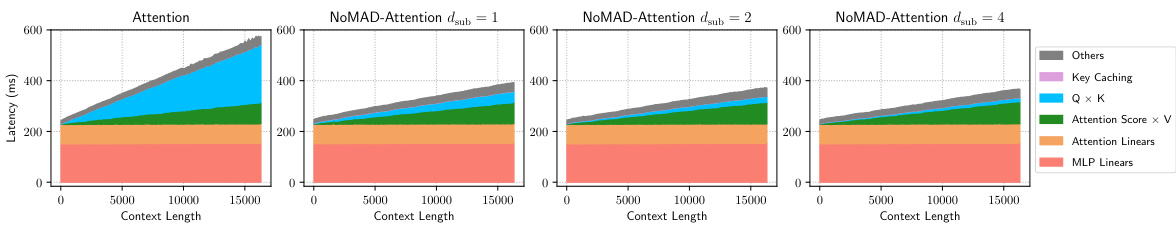
This figure presents a breakdown of the decoding latency for a 4-bit CodeLlama-7b model using both the standard Attention mechanism and the proposed NoMAD-Attention. The breakdown categorizes latency into different components: Others, Key Caching, Query-Key (QxK) dot products, Attention Score x Value (Attention Score x V), Attention Linears, and MLP Linears. The key observation is that NoMAD-Attention significantly reduces the latency associated with computing query-key dot products, leading to a substantial overall reduction in decoding latency. The reduction factor varies depending on the value of
dsubin the NoMAD-Attention algorithm.
More on tables

This table presents the results of evaluating the performance of LLMs using standard attention mechanisms and the proposed NOMAD-Attention method. It shows perplexity scores on the WikiText-2 and C4 datasets, along with accuracy scores on six downstream tasks (SciQ, Arc-E, Arc-C, HellaSwag, Winogrande, and PIQA). The results are broken down for different LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, and LLaMA-2-13B) and different NOMAD-Attention configurations (dsub = 1, 2, and 4). This allows for a comparison of the impact of NOMAD-Attention on both the speed and accuracy of LLM inference, showing whether the speed gains come at the cost of reduced accuracy.

This table presents a quantitative comparison of the performance of Language Models (LLMs) using standard Attention mechanisms against those using the proposed NOMAD-Attention method. The evaluation metrics include perplexity scores on the WikiText-2 and C4 datasets, along with accuracy scores across six benchmark tasks (SciQ, Arc-Easy, Arc-Challenge, HellaSwag, Winogrande, and PIQA). Results are shown for different LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, and LLaMA-2-13B) and variations of the NOMAD-Attention algorithm (dsub=1, 2, and 4). The table allows readers to assess the impact of NOMAD-Attention on both the quantitative performance and the quality of the LLMs.

This table presents the results of ablation studies on the impact of FIM-informed centroid learning on the perplexity of the LLaMA-7b model when evaluated on the WikiText-2 dataset. It compares the perplexity scores achieved using NoMAD-Attention with different sub-quantizer dimensions (dsub = 1, 2, 4) under both uninformed and FIM-informed centroid learning methods. The table also includes the perplexity of the original Attention model for comparison, highlighting the effectiveness of FIM-informed learning in preserving model quality while using NoMAD-Attention.

This table presents a comparison of the performance of LLMs using standard attention mechanisms and the proposed NOMAD-Attention method. The metrics used are perplexity scores on the WikiText-2 and C4 datasets, which measure the model’s ability to predict the next word in a sequence, and accuracy scores on six different downstream tasks (SciQ, Arc-E, Arc-C, Hellaswag, WinoGrande, PIQA). Results are shown for various LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and different configurations of NOMAD-Attention, using different sub-quantizer dimensions (dsub = 1, 2, 4). This allows for an assessment of the trade-off between model accuracy and the efficiency gains achieved through NOMAD-Attention.

This table presents a comparison of the performance of LLMs using standard attention mechanisms versus the proposed NOMAD-Attention, across multiple benchmark datasets. It shows perplexity scores (a measure of how well the model predicts text) on the WikiText-2 and C4 language modeling datasets and accuracy scores on six downstream tasks (SciQ, Arc-Easy, Arc-Challenge, HellaSwag, Winogrande, and PIQA). The results are broken down by LLM size (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and the number of sub-quantizers (dsub) used in NOMAD-Attention (1, 2, and 4). This allows for an assessment of the impact of NOMAD-Attention on both model quality and efficiency.
This table presents a comparison of the performance of LLMs using standard attention mechanisms versus the proposed NOMAD-Attention method. It shows perplexity scores (a measure of how well a model predicts text) on two benchmark datasets (WikiText-2 and C4), and accuracy scores on six other benchmark tasks. The results are broken down for different model sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and different configurations of NOMAD-Attention (varying the value of ‘dsub’). The purpose is to demonstrate the effectiveness of NOMAD-Attention in maintaining model accuracy while potentially improving efficiency.

This table presents the results of experiments comparing the performance of LLMs using standard Attention mechanisms against those using the proposed NOMAD-Attention. It shows perplexity scores on the WikiText-2 and C4 datasets, and accuracy scores across six different benchmark tasks (SciQ, Arc-E, Arc-C, HellaSwag, Winogrande, and PIQA). Results are broken down for different LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and variations of NOMAD-Attention, parameterized by
dsub(which represents the number of sub-quantizers used in the product quantization). This allows for assessing the impact of the proposed method on both model accuracy and performance across various model sizes and configurations.
This table presents the results of the experiments conducted to evaluate the performance of LLMs with both standard Attention and the proposed NOMAD-Attention. It shows the perplexity scores (a measure of how well the model predicts the next word in a sequence) on the WikiText-2 and C4 datasets, as well as accuracy scores across six different downstream tasks (SciQ, Arc-E, Arc-C, Hellaswag, WinoGrande, and PIQA). The results are shown for four different LLMs (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, and LLaMA-2-13B), and for each LLM, results are provided for NOMAD-Attention with varying numbers of sub-quantizers (dsub = 1, 2, and 4). Comparing the results across the different conditions allows for an assessment of the impact of NOMAD-Attention on model performance.
This table presents a comparison of the performance of LLMs using standard Attention mechanisms and the proposed NOMAD-Attention. It shows perplexity scores (a measure of how well the model predicts the next word in a sequence) on two datasets, WikiText-2 and C4. Additionally, it provides accuracy scores on six downstream tasks (SciQ, Arc-Easy, Arc-Challenge, Hellaswag, Winogrande, and PIQA). The results are shown for different LLM sizes (LLaMA-7B, LLaMA-13B, LLaMA-2-7B, LLaMA-2-13B) and different configurations of NOMAD-Attention, denoted by ‘dsub’, representing the number of sub-quantizers used in the product quantization technique. The table allows for an assessment of the impact of NOMAD-Attention on both model quality (perplexity and accuracy) and performance.
Full paper#