↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current methods for improving large language models (LLMs) often struggle with reasoning tasks. Iterative preference optimization techniques aim to improve this, but typically yield only modest improvements. Many existing methods also rely on additional data sources. This research explores the challenges of applying preference optimization to reasoning, particularly focusing on Chain-of-Thought (CoT) methods.
This paper proposes ‘Iterative Reasoning Preference Optimization’ which uses a modified loss function to optimize the preference between competing generated CoT candidates. By focusing on reasoning steps, this method achieves substantial gains on reasoning tasks, outperforming Llama-2-based models without additional data. The improvements are demonstrated across GSM8K, MATH, and ARC-Challenge benchmarks, highlighting its effectiveness and potential for broader application in improving LLM reasoning.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel iterative preference optimization method that significantly improves the reasoning ability of large language models. This addresses a key limitation of current preference optimization methods, which often struggle with reasoning tasks. The proposed method is simple, efficient and outperforms existing approaches on several benchmark datasets. This opens new avenues for improving LLMs’ reasoning capabilities and contributes to the broader field of aligning LLMs with human expectations.
Visual Insights#
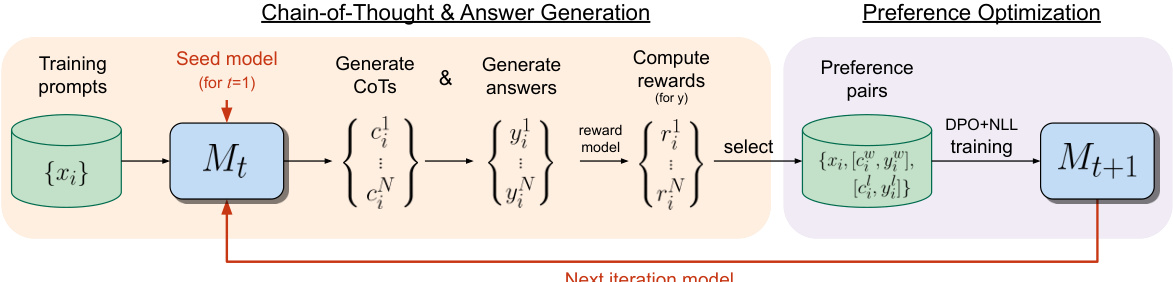
This figure illustrates the iterative reasoning preference optimization method. It involves two main steps: 1) Chain-of-Thought & Answer Generation, where the model generates reasoning steps and answers for given prompts, and these answers are evaluated; and 2) Preference Optimization, where preference pairs are created and used to train the model via DPO+NLL, improving reasoning ability with each iteration.

This table presents the results of the GSM8K experiment, comparing the performance of Iterative RPO against several baselines. The baselines include zero-shot and majority voting using 32 samples, standard DPO with different initializations, SFT on gold and chosen sequences, and STaR with different amounts of training data. The table shows that Iterative RPO significantly outperforms all baselines in terms of exact match accuracy, with further gains achieved through majority voting.
In-depth insights#
Iterative Reasoning#
Iterative reasoning, in the context of large language models (LLMs), represents a powerful paradigm shift from traditional single-pass methods. It leverages the inherent iterative capabilities of LLMs to refine their reasoning process through repeated cycles. Each iteration builds upon the results of the previous one, allowing for increasingly sophisticated and nuanced reasoning. This iterative approach is particularly effective for complex problems that require multiple steps and considerations, as it allows the LLM to gradually approach a solution rather than relying on a single, potentially flawed, attempt. The key to effective iterative reasoning lies in the design of the feedback mechanism, which guides the LLM towards more accurate and complete reasoning. This feedback can take various forms, such as incorporating human preferences or using internal model consistency checks. The iterative nature also facilitates the incorporation of new information or alternative perspectives, enhancing the robustness and overall accuracy of the reasoning process. By breaking down complex tasks into smaller, manageable steps and using feedback to guide its progression, iterative reasoning unlocks LLMs’ potential for solving intricate reasoning challenges more effectively and reliably than traditional approaches.
DPO Loss Function#
The Direct Preference Optimization (DPO) loss function is a crucial component in the iterative reasoning preference optimization method described. DPO directly models the preference between competing generated chain-of-thought (CoT) sequences by comparing winning and losing reasoning steps. This differs significantly from traditional supervised methods which focus on individual answer accuracy. Instead, DPO learns to rank CoT sequences based on their correctness, which is a more nuanced approach for improving reasoning abilities. The paper enhances the standard DPO loss by adding a negative log-likelihood (NLL) term, which proves crucial for performance. The NLL term encourages the model to assign higher probabilities to winning CoT sequences, thus further improving the reliability and accuracy of the overall system. This combined DPO+NLL loss function is iteratively applied, with each iteration refining the model’s preference ranking capabilities and consequently boosting reasoning accuracy on various benchmarks. The results clearly indicate that this iterative refinement process, powered by the unique properties of the DPO+NLL loss, is key to achieving significant improvements in reasoning performance compared to baselines.
Llama-2-70B Results#
A hypothetical section titled ‘Llama-2-70B Results’ would analyze the performance of the Llama-2-70B language model on various reasoning benchmarks. It would likely present quantitative metrics such as accuracy, F1-score, or exact match ratios across different datasets, comparing its performance to other Llama-2 variants and/or alternative models. Key findings would likely center around whether the iterative reasoning preference optimization technique significantly improved performance on tasks demanding complex reasoning steps, such as GSM8K, MATH, or ARC-Challenge. The analysis would ideally dissect performance gains across iterations, examining whether improvement plateaus after a certain point, demonstrating the effectiveness of the proposed method against baselines like zero-shot CoT, supervised fine-tuning (SFT), and standard DPO. The discussion should address any unexpected results and compare Llama-2-70B’s performance to state-of-the-art models. A key aspect would involve exploring the influence of additional components like the NLL loss term on the final accuracy and a nuanced comparison of outcomes for different benchmarks showcasing the strengths and weaknesses of the Llama-2-70B model.
Ablation Studies#
Ablation studies are crucial for understanding the contribution of individual components within a machine learning model. In the context of iterative reasoning preference optimization, such studies would systematically remove or modify parts of the proposed method to isolate their effects on performance. This might involve analyzing the impact of removing the negative log-likelihood term from the loss function, investigating the effect of varying the number of iterations, or assessing the model’s sensitivity to different hyperparameter settings. The results of these experiments would not only validate the design choices but also provide insights into the relative importance of different components of the iterative process. By quantifying the impact of these modifications on key metrics like accuracy, the researchers can confidently assert which elements are essential for achieving high performance, and which might be redundant or even detrimental. A well-designed ablation study demonstrates a deep understanding of the model’s inner workings and increases the reliability and trustworthiness of the reported findings. Ultimately, these analyses are essential for building more robust and efficient reasoning models.
Future Directions#
Future research could explore several promising avenues. Improving the efficiency and scalability of iterative preference optimization is crucial, perhaps through more efficient sampling strategies or alternative optimization techniques. Investigating the impact of different reward models and their interaction with iterative refinement is key; more sophisticated reward functions beyond simple accuracy could significantly impact performance. The interplay between iterative preference optimization and other methods for enhancing reasoning abilities, such as chain-of-thought prompting or curriculum learning, warrants investigation. Extending this approach to other reasoning tasks and different language model architectures would further demonstrate its generalizability and robustness. Finally, a thorough investigation into the theoretical underpinnings of iterative preference optimization, including convergence properties and sample complexity, is necessary to solidify its foundation and guide future improvements.
More visual insights#
More on figures

This figure compares the effect of Supervised Fine-Tuning (SFT) and the proposed DPO+NLL training methods on the log probabilities of chosen and rejected sequences in the Iterative Reasoning Preference Optimization process. It shows that while SFT increases the probabilities of both chosen and rejected sequences, DPO+NLL training is more effective in improving the chosen sequences while decreasing the probability of rejected sequences, which contributes to better performance.
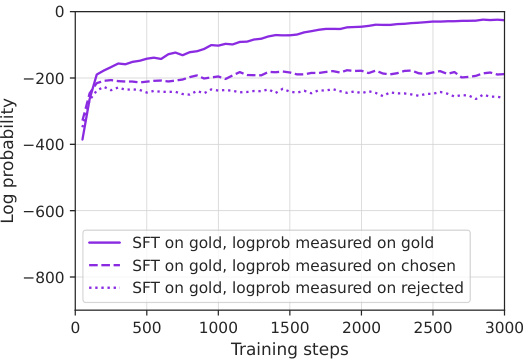
This figure shows the effect of supervised fine-tuning (SFT) training on the performance of the model in terms of log probabilities of chosen and rejected sequences. It compares SFT training with the proposed DPO+NLL training method. The plots indicate that SFT training alone does not effectively distinguish between chosen and rejected sequences, while the DPO+NLL method achieves a better separation, leading to improved performance.
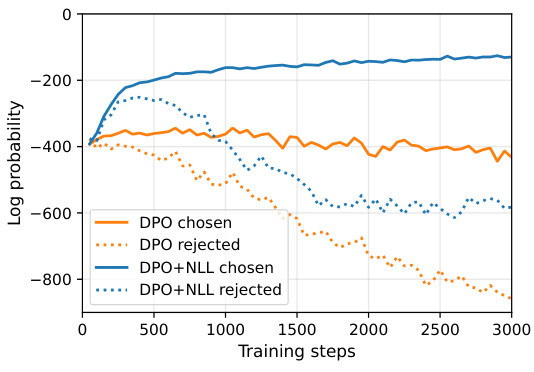
This figure shows the effect of adding a negative log-likelihood (NLL) term to the DPO loss function during training on the GSM8K dataset. It compares the log probabilities of ‘chosen’ (correct) and ‘rejected’ (incorrect) sequences across training steps for both standard DPO and DPO+NLL. The results indicate that including the NLL term leads to a consistent increase in the log probabilities of chosen sequences while decreasing those of rejected sequences, resulting in improved test accuracy.
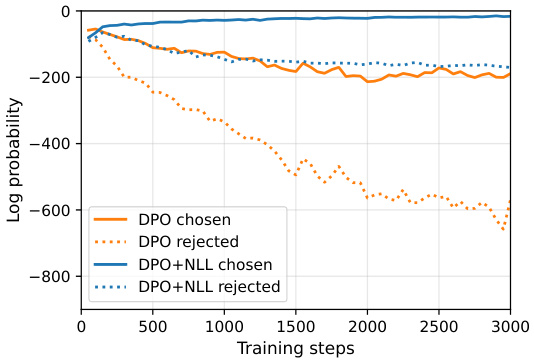
This figure compares the training performance of DPO with and without the NLL loss term on the GSM8K dataset. The plot shows the log probabilities of chosen and rejected sequences over training steps. It demonstrates that adding the NLL loss improves the performance significantly as the log probabilities of chosen sequences increase, while the log probabilities of rejected sequences decrease.
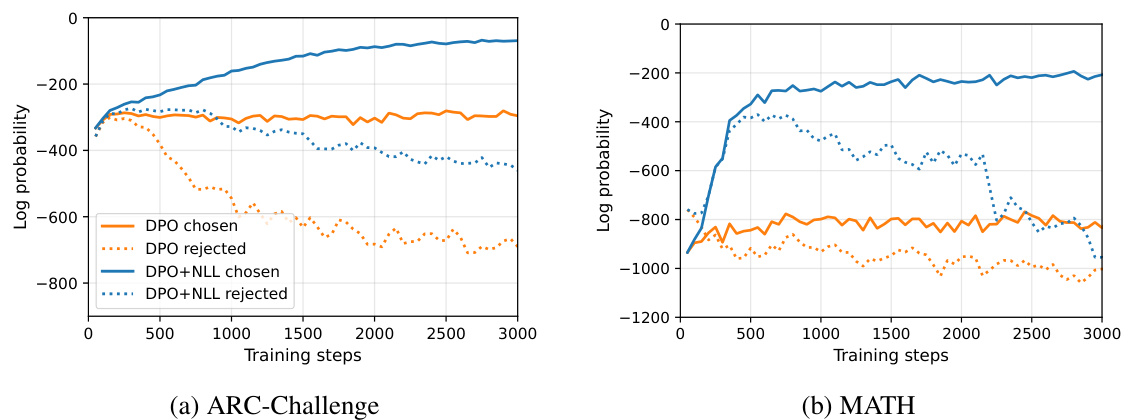
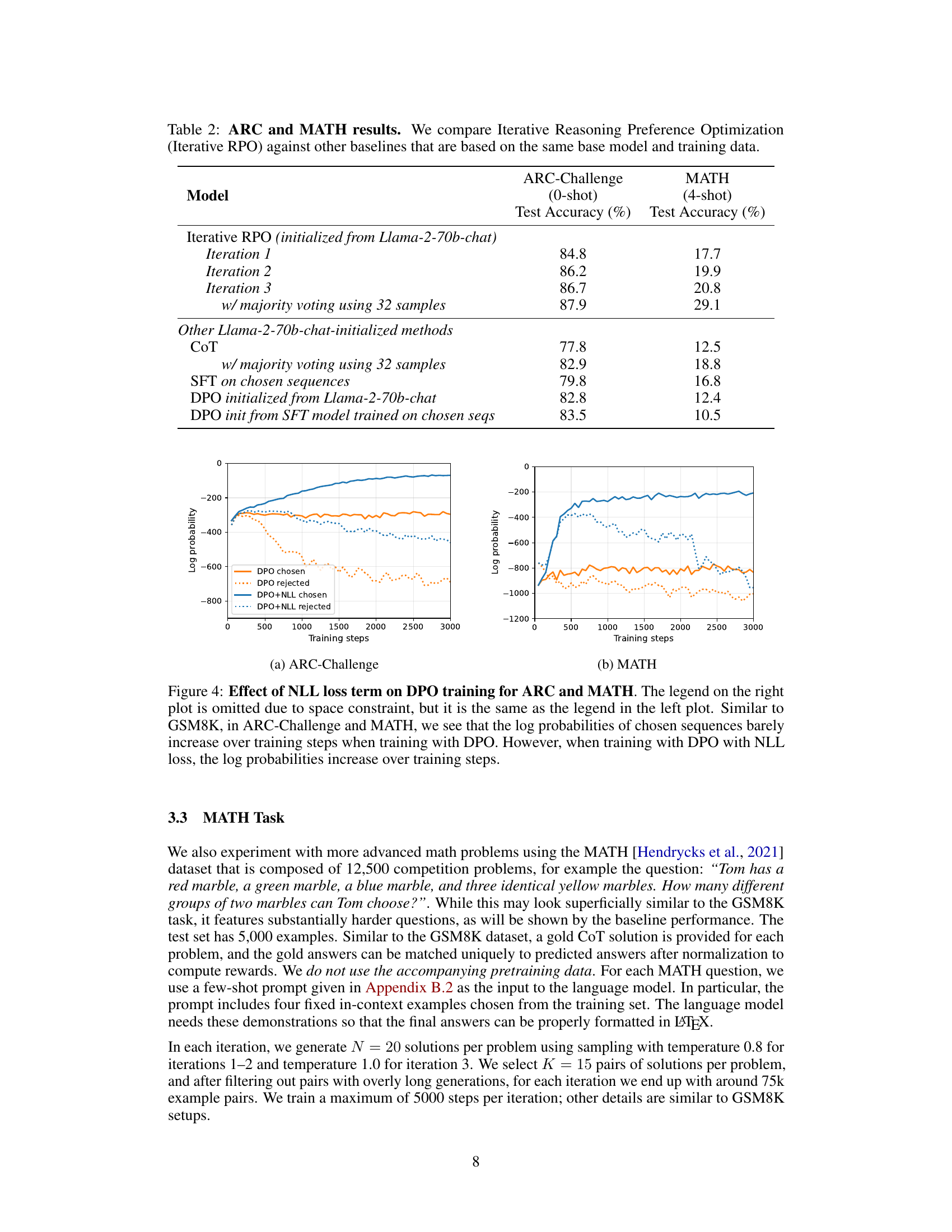
This figure shows the effect of adding the negative log-likelihood (NLL) term to the DPO loss function during training on two datasets: ARC-Challenge and MATH. The plots display the log probabilities of chosen and rejected sequences over training steps for both DPO with and without the NLL term. The results indicate that including the NLL term leads to an increase in the log probabilities of chosen sequences during training for both datasets, suggesting that the NLL term is beneficial for improving the model’s performance on reasoning tasks.
Full paper#