↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many real-world machine learning applications demand rigorous safety guarantees, especially when dealing with critical risk measures. However, existing methods often fall short, particularly in online/sequential settings where data arrives continuously and labels are costly to obtain. This necessitates risk control in an active learning setting, where you strategically decide which labels to acquire to minimize costs while maintaining safety guarantees.
This research introduces a novel framework that addresses this challenge by extending the concept of risk-controlling prediction sets (RCPS) to anytime-valid and active settings. The method uses a sophisticated betting strategy and incorporates active learning, enabling users to specify a label budget and dynamically decide which data points to label. The use of machine learning models for risk prediction further enhances the method’s efficiency and performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on safe and reliable machine learning models, especially in applications with high-stakes decisions. It provides practical tools and theoretical guarantees for managing risk and reducing the need for labels in sequential settings, bridging theory and practice in a significant way. It opens new avenues for research in active learning and risk-aware prediction sets, impacting various fields from healthcare to autonomous systems.
Visual Insights#

This figure illustrates the active learning setup used for anytime-valid risk control. Data points (Xt, Yt) arrive sequentially. A labeling policy q(Xt) determines whether to query the true label Yt for each data point. If the label is queried (Lt = 1), the incurred risk r(Xt, Yt, β) is calculated for each candidate β; otherwise, the risk is treated as 0. A risk estimate 𝑟̃(Xt, β) is optionally used to reduce risk variance. The threshold βt-1 is updated based on the incurred risk, aiming for a sequence of safe β values such that p(βt) ≤ θ (risk control guarantee). The final βt is deployed with risk control.
In-depth insights#
Anytime-Valid RCPS#
The concept of “Anytime-Valid RCPS” suggests a significant advancement in risk-controlling prediction sets. Traditional RCPS methods often rely on batch data, limiting their applicability to real-world scenarios with continuous data streams. Anytime-valid functionality addresses this by providing risk guarantees that hold at every time step, not just after a fixed amount of data. This is crucial for ensuring continuous safety in applications like medical diagnosis or autonomous driving where risk must be managed at all times. The integration of active learning further enhances the framework’s efficiency by allowing the model to intelligently query labels only when needed, optimizing both utility and cost of labeling. This intelligent labeling strategy, driven by the covariates, is likely to be highly impactful in resource-constrained environments. The combination of anytime-validity and active learning within the RCPS framework represents a powerful tool for deploying reliable, safe machine learning models in real-world applications.
Active Learning RCPS#
Active Learning RCPS combines risk control and active learning, offering a powerful approach to sequential prediction. Risk Controlling Prediction Sets (RCPS) provide statistically guaranteed low-risk predictions, but traditionally require all data to be labeled upfront. Active learning addresses this limitation by strategically selecting which data points to label, thereby reducing labeling costs. By integrating these two concepts, Active Learning RCPS provides anytime-valid risk control; risk guarantees hold at every time step, even with adaptive data collection. This framework is especially valuable in resource-constrained settings or when labeling is expensive, making it efficient and practical for real-world applications. The theoretical analysis further enhances its utility by providing optimal strategies for labeling and leveraging predictor estimates to improve efficiency and reduce uncertainty. The practical implementation demonstrates the effectiveness of this approach across various real-world datasets and scenarios, confirming its potential to enhance safety and efficiency in machine learning systems.
Optimal Policies#
The concept of ‘Optimal Policies’ within a research paper likely delves into finding the most effective strategies to achieve specific goals under defined constraints. This could involve mathematical optimization, where algorithms seek to maximize a utility function (representing the desired outcome) subject to limitations on resources or other factors. For example, in a machine learning context, this might mean determining the optimal way to label data in an active learning setting (where labels are expensive) to minimize labeling effort while maintaining high prediction accuracy. Alternatively, it could explore optimal decision-making policies under uncertainty, using techniques from reinforcement learning or decision theory. The analysis would ideally involve characterizing the optimal policy (e.g., mathematically), demonstrating its properties (e.g., convergence, optimality), and assessing its performance in simulations or real-world data. The presence of ‘Optimal Policies’ suggests a strong theoretical and quantitative component within the paper, focusing on efficiency and performance.
Empirical Results#
An effective ‘Empirical Results’ section would meticulously detail experimental setup, datasets, metrics, and results. It should clearly present the model’s performance against baselines, highlighting both strengths and weaknesses. Statistical significance of findings must be established, preferably with error bars or confidence intervals. The results should not only be presented numerically but also visually using clear and informative figures, such as plots showcasing performance trends and tables summarizing key statistics. A robust section would also discuss unexpected or intriguing results, offering plausible explanations or suggesting directions for future work. Reproducibility is paramount: the description should be comprehensive enough to allow readers to replicate the experiments. Finally, it should directly address the claims made in the abstract and introduction, providing compelling evidence to support those claims.
Future Work#
The authors mention several promising avenues for future work. Extending the anytime-valid RCPS framework to handle non-i.i.d. data is crucial for real-world applications where data distribution shifts are common. This would require developing new theoretical tools and potentially adapting existing techniques like empirical Bernstein supermartingales to account for distributional changes. Another critical direction is to relax the bounded label policy assumption. The current theoretical guarantees depend on a lower bound on the labeling probability. Removing this restriction would broaden the applicability and improve the practical utility of the proposed methods. Finally, the authors highlight the need for a more thorough analysis of the optimal labeling policy and predictor, potentially leading to more efficient and accurate label acquisition strategies. This could involve exploring alternative optimization techniques or developing novel theoretical bounds on the regret for suboptimal policies. Further investigation into how the methods scale to larger datasets and more complex models is necessary. Evaluating the performance of these methods in various real-world applications, such as natural language processing or autonomous driving, would validate their practicality and offer crucial insights into their robustness and limitations.
More visual insights#
More on figures
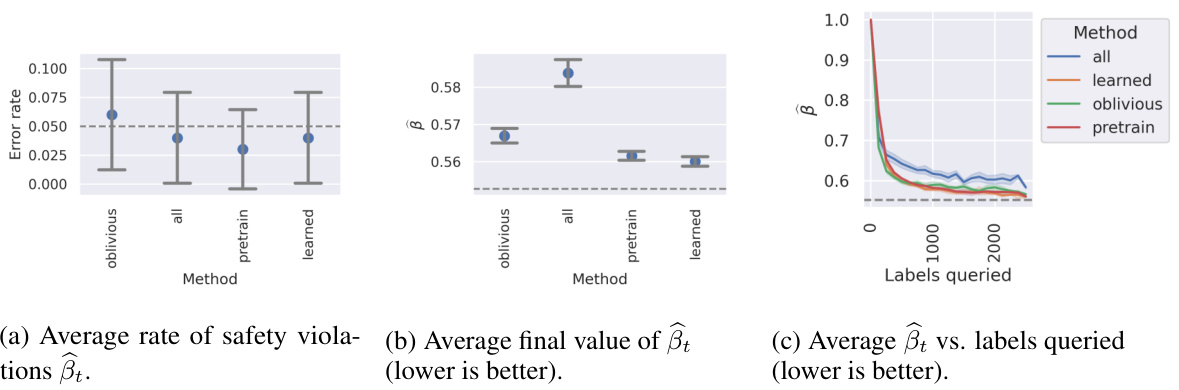
This figure presents the results of numerical simulations comparing four different methods for active learning in a risk-control setting. The methods are compared in terms of their label efficiency, measured by the average value of beta_t (βt) after a given number of labels are queried, and the average rate of safety violations. The results show that the ‘pretrain’ and ‘learned’ methods outperform the ‘all’ and ‘oblivious’ strategies, achieving similar levels of safety while using fewer labels. This highlights the effectiveness of using pretrained models to estimate the optimal labeling policies and predictors in this framework.

The figure shows the results of numerical simulations comparing four methods for active, anytime-valid risk control. The ‘pretrain’ and ’learned’ methods outperform the baseline ‘all’ and ‘oblivious’ methods, achieving lower average values of β̂t (a measure of risk) over time. The figure demonstrates that all methods maintain the desired safety violation rate, indicating effective risk control.
Full paper#



















