↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Prior research on enhancing large language models’ (LLMs) reasoning capabilities has heavily relied on prompting techniques, often involving manual prompt engineering. These methods, while effective, obscure the LLMs’ intrinsic reasoning abilities and introduce human biases. This limits our understanding of LLMs’ true potential and hinders efforts to improve their reasoning capabilities without relying on extensive, task-specific training.
This study introduces a novel approach called CoT-decoding which elicits CoT reasoning paths by simply altering the decoding process, bypassing prompting altogether. The research finds that CoT paths are frequently inherent in LLMs’ decoding sequences and that the presence of a CoT path correlates with a higher confidence in the model’s answer. The proposed CoT-decoding method effectively extracts these paths, demonstrating substantial performance improvements on various reasoning benchmarks without any additional training or prompting.
Key Takeaways#
Why does it matter?#
This paper is crucial because it challenges the common belief that large language models (LLMs) cannot reason without prompting. By demonstrating that inherent reasoning capabilities can be unlocked simply by altering the decoding process, it opens exciting avenues for improving LLMs and understanding their inner workings. This research also provides a more effective method for evaluating LLMs’ reasoning abilities.
Visual Insights#
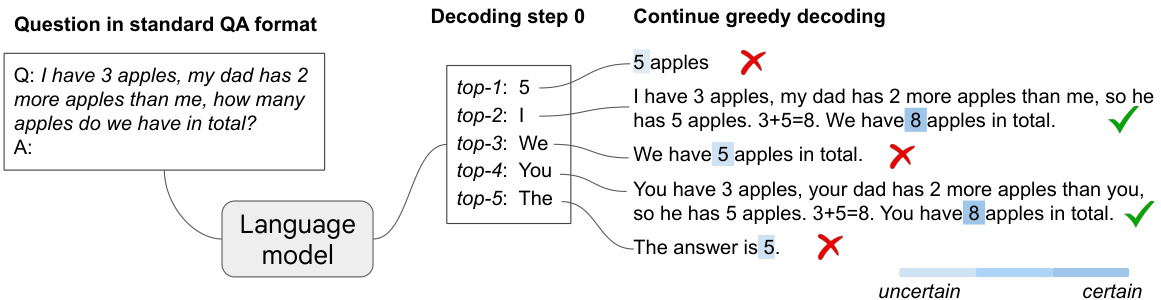
This figure illustrates the concept of CoT-decoding. A question is given to a language model, and the model’s response is analyzed using both standard greedy decoding (only considering the most likely next word at each step) and CoT-decoding (considering multiple alternative next words). The figure shows that while greedy decoding may lead to an incorrect answer, the alternative decoding paths often contain chain-of-thought (CoT) reasoning, which is a step-by-step logical progression leading to the correct answer. The model’s confidence in the answer is also higher when a CoT path is present.

This table compares the performance of different methods for extracting chain-of-thought (CoT) paths from the top 10 decoded paths of a language model. The methods compared are greedy decoding, ranking by the model’s highest log-probability, ranking by the model’s highest length-normalized log-probability, and CoT-decoding (ranking by the model’s answer confidence). The results are shown for two datasets: GSM8K (top 100) and Year Parity. CoT-decoding demonstrates significantly better performance in identifying CoT paths compared to the other methods.
In-depth insights#
Promptless CoT#
The concept of “Promptless CoT” presents a significant advancement in large language model (LLM) reasoning. Traditional chain-of-thought (CoT) prompting relies on carefully crafted prompts to guide the model’s reasoning process. Promptless CoT aims to eliminate this manual engineering, instead leveraging inherent reasoning capabilities within pre-trained LLMs. This is achieved by strategically altering the decoding process, moving beyond standard greedy decoding to explore alternative token sequences. The core insight is that CoT reasoning paths are often present in these alternative sequences, revealing the model’s intrinsic ability to reason without explicit prompting. This approach not only bypasses the limitations of prompt engineering but also offers a more direct assessment of the model’s underlying reasoning abilities. A key finding is the strong correlation between the presence of a CoT path in the decoding sequence and higher model confidence in the final answer. This confidence metric becomes a crucial tool for identifying and selecting reliable CoT paths. The implications of promptless CoT are substantial, potentially leading to more robust and efficient LLM reasoning systems, and offering a deeper understanding of how LLMs reason intrinsically.
CoT-Decoding#
The concept of “CoT-Decoding” presents a novel approach to eliciting chain-of-thought (CoT) reasoning in large language models (LLMs) without explicit prompting. Instead of relying on traditional prompting techniques, CoT-Decoding focuses on manipulating the decoding process itself, examining alternative top-k tokens beyond the standard greedy decoding path. This method reveals that CoT reasoning paths are often inherent within these alternative sequences, suggesting that LLMs possess intrinsic reasoning capabilities that are masked by standard decoding methods. The presence of a CoT path correlates with higher model confidence in the generated answer, providing a reliable mechanism for identifying successful CoT reasoning. By bypassing the need for prompt engineering, CoT-Decoding enables a more objective assessment of LLM reasoning abilities and offers a potentially more efficient and task-agnostic approach to leverage these capabilities. The authors propose a confidence metric to differentiate CoT and non-CoT paths, further solidifying the effectiveness of this decoding modification. This innovative method could significantly advance our understanding and harnessing of LLM reasoning potential.
Intrinsic Reasoning#
Intrinsic reasoning, the inherent capacity of a model to reason without explicit prompting, is a crucial theme. The paper challenges the common assumption that large language models (LLMs) lack this ability, demonstrating that intrinsic reasoning exists but is obscured by standard decoding methods. By analyzing alternative decoding paths, the authors reveal that chain-of-thought (CoT) reasoning is frequently present, even in pre-trained models. This suggests that LLMs possess a latent capacity for reasoning that isn’t fully leveraged by conventional greedy decoding. The study further introduces CoT-decoding as a novel approach, significantly enhancing the elicitation of these inherent reasoning capabilities. This method surpasses traditional prompting techniques, offering a more direct assessment of a model’s intrinsic reasoning abilities. The increased confidence associated with the presence of CoT paths in the decoding sequences further supports this conclusion. Overall, the paper makes a significant contribution by highlighting the untapped potential of LLMs for intrinsic reasoning and proposing a new method to unlock this potential.
Model Scaling#
Model scaling in large language models (LLMs) explores how increasing model size impacts performance. Larger models generally exhibit better performance on various benchmarks, but this improvement isn’t always linear. A key question is whether scaling brings truly novel capabilities or merely amplifies existing ones. The relationship between model size, computational cost, and performance gains needs careful consideration. Diminishing returns are often observed at a certain scale, raising the question of optimal model size versus cost-effectiveness. The paper’s findings likely show whether CoT decoding, their proposed method, continues to improve performance as model size increases, offering insights into whether inherent reasoning abilities are better unlocked with scaling, or if prompting techniques are still crucial at larger scales. Understanding these scaling behaviors is crucial for responsible development and deployment of LLMs, balancing performance gains with the considerable increase in resource requirements.
Future Work#
Future research directions stemming from this work could explore several promising avenues. Improving efficiency is crucial; the computational cost of exploring alternative decoding paths needs to be addressed, perhaps through more efficient search algorithms or leveraging the identified CoT paths to fine-tune models for improved reasoning. Extending CoT-decoding to more complex tasks is also vital. While this method shines on mathematical and commonsense reasoning, its application to highly synthetic or nuanced tasks requires further investigation, especially concerning scenarios where inherent reasoning paths are less prevalent. Investigating the relationship between model size and CoT path emergence is another key area. Although larger models often demonstrate superior performance, understanding how the abundance of CoT paths correlates with model scale is important. Finally, a detailed investigation of the model’s intrinsic reasoning mechanisms via analyzing the internal representations is necessary to unlock deeper insights into this surprising ability of LLMs to perform reasoning without explicit prompts.
More visual insights#
More on figures

This figure illustrates the concept of CoT-decoding. It shows that a pre-trained large language model (LLM), when using a standard question-answer format, may produce an incorrect answer using greedy decoding (only considering the most likely next token at each step). However, by examining alternative top-k tokens (the k most likely tokens), the figure reveals that the model actually generates several different decoding paths. Some of these paths incorporate a chain-of-thought (CoT) reasoning process, leading to the correct answer. The figure highlights that the model often displays higher confidence (represented by darker shading) when a CoT path is present, suggesting that this method can effectively identify and utilize a model’s intrinsic reasoning abilities.

This figure illustrates the concept of CoT-decoding. It shows that pre-trained large language models (LLMs) can exhibit chain-of-thought (CoT) reasoning even without explicit prompting. By examining the top-k most likely token sequences during decoding (instead of only the single most likely token), the authors found that CoT reasoning paths are frequently present. The figure uses an example question to show how greedy decoding leads to an incorrect answer, while alternative paths reveal a correct CoT reasoning process. The darker shading indicates higher model confidence in answers found via CoT paths.

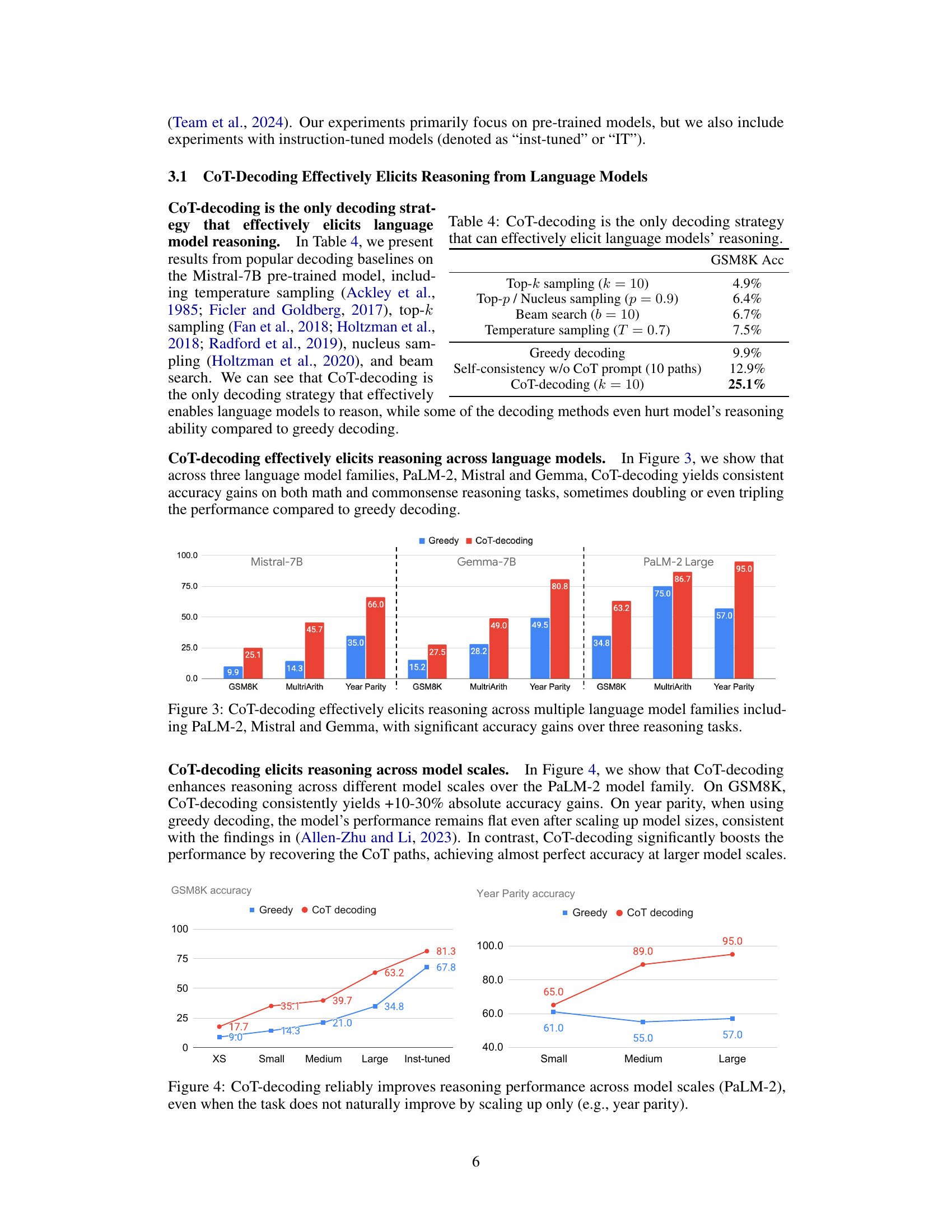
This figure compares the performance of greedy decoding and CoT-decoding across three different large language model families (PaLM-2, Mistral, and Gemma) on three reasoning tasks: GSM8K (a math reasoning benchmark), MultiArith (another math reasoning benchmark), and Year Parity (a commonsense reasoning task). The results show that CoT-decoding consistently outperforms greedy decoding, achieving significant accuracy improvements across all three model families and tasks.
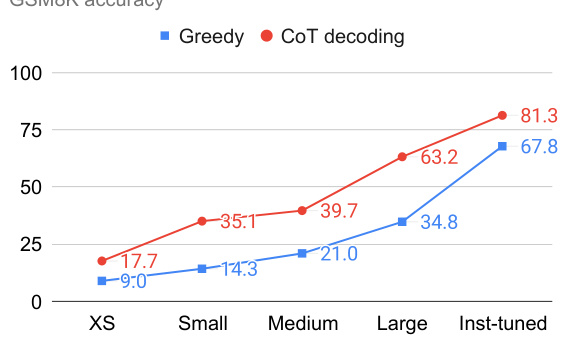
This figure demonstrates the impact of CoT decoding on reasoning performance across various scales of the PaLM-2 model family. The x-axis shows different model sizes (XS, Small, Medium, Large) and an instruction-tuned version. The y-axis represents the accuracy achieved on two reasoning tasks (GSM8K and Year Parity). Notably, CoT decoding consistently leads to substantial accuracy improvements across all model sizes, particularly pronounced in the year parity task where standard greedy decoding shows no significant improvement with larger models.
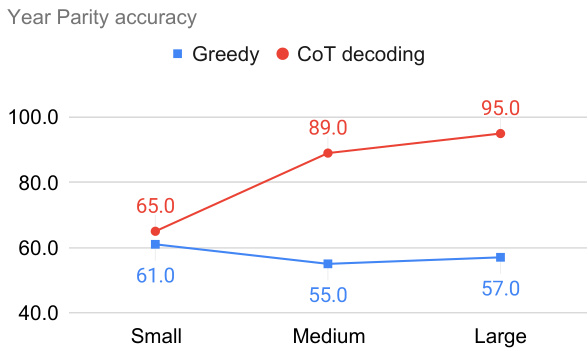
This figure demonstrates the effectiveness of CoT-decoding across different scales of the PaLM-2 language model family on two reasoning tasks: GSM8K (mathematical reasoning) and Year Parity (commonsense reasoning). The results show that CoT-decoding consistently yields significant accuracy gains compared to greedy decoding on the GSM8K task, with improvements ranging from 10% to 30%. Notably, on the Year Parity task, where greedy decoding performance remains stagnant even with larger models, CoT-decoding substantially boosts accuracy, nearly reaching perfect performance with the largest model. This highlights the ability of CoT-decoding to effectively elicit reasoning capabilities even when simple scaling does not suffice.
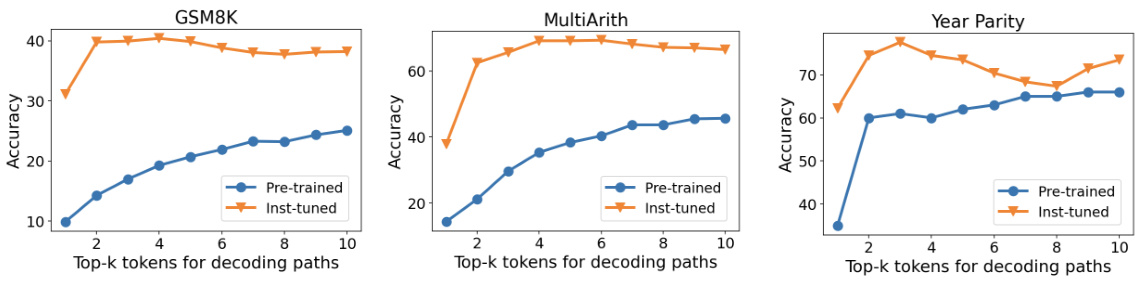
The figure shows that CoT-decoding consistently improves the accuracy of three different large language models (LLMs) across three distinct reasoning tasks: GSM8K (a grade-school mathematics dataset), MultiArith (a multi-step arithmetic reasoning dataset), and Year Parity (a commonsense reasoning task). The improvements are substantial, often doubling or tripling the accuracy compared to using standard greedy decoding. This demonstrates that CoT-decoding is effective across various LLMs and tasks.
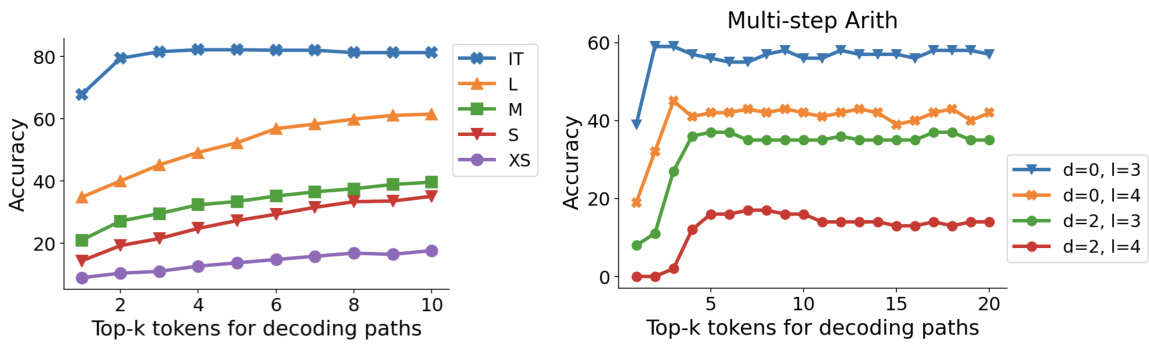
This figure shows how CoT-decoding improves the reasoning performance of different sizes of PaLM-2 models on three different reasoning tasks: GSM8K, MultiArith, and Year Parity. The x-axis represents the number of top-k tokens considered during decoding, and the y-axis represents the accuracy. The key finding is that CoT-decoding consistently improves accuracy across all model sizes, especially on GSM8K, demonstrating its effectiveness in eliciting reasoning capabilities from language models regardless of their scale. The Year Parity task highlights that CoT-decoding improves performance even when simply increasing the model size does not naturally lead to better results.
More on tables

This table compares the performance of greedy decoding, self-consistency without CoT prompting, and CoT-decoding on the GSM8K dataset. It highlights the superior performance of CoT-decoding in eliciting chain-of-thought reasoning without relying on explicit prompting techniques. The results demonstrate that CoT-decoding significantly improves accuracy compared to the other methods.

This table compares the performance of various decoding strategies on the GSM8K benchmark. The strategies include several sampling methods (Top-k, Top-p/Nucleus, Temperature), beam search, greedy decoding, and self-consistency (without CoT prompting). The key finding is that CoT-decoding significantly outperforms all other methods, demonstrating its effectiveness in eliciting reasoning capabilities from language models.
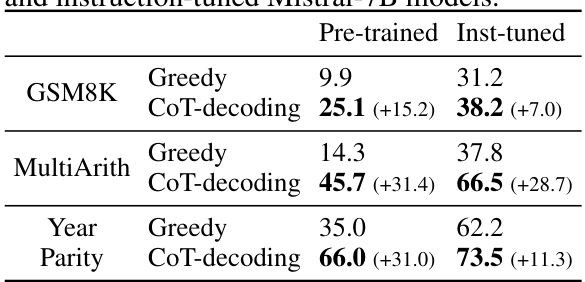
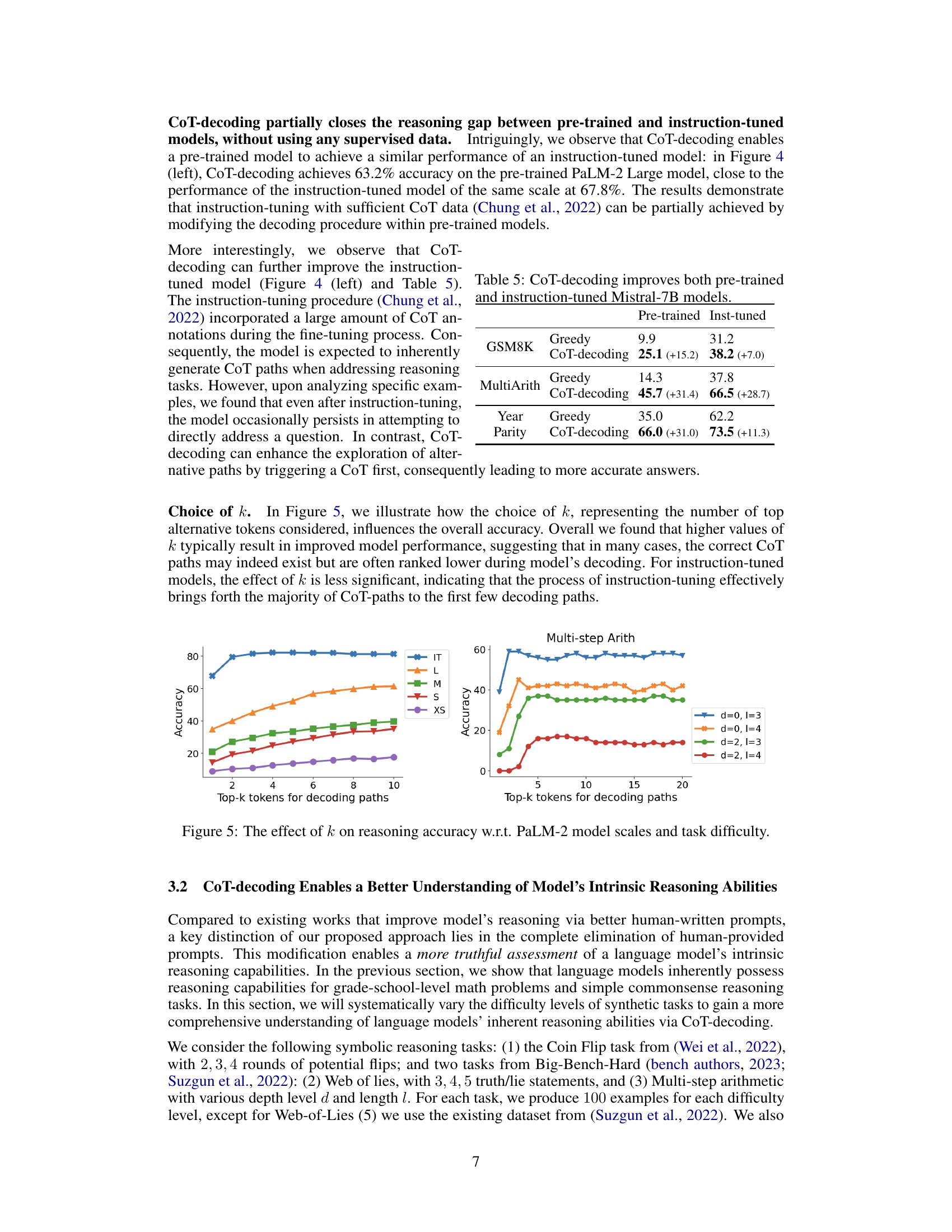
This table presents the accuracy results of different decoding methods on three reasoning tasks: GSM8K, MultiArith, and Year Parity. It compares the performance of greedy decoding and CoT-decoding on both pre-trained and instruction-tuned Mistral-7B models. The results show that CoT-decoding significantly improves the accuracy of both types of models on all three tasks, highlighting the effectiveness of the proposed method in eliciting reasoning capabilities from language models.

This table shows the accuracy of the greedy decoding method and the CoT-decoding method on various reasoning tasks with different difficulty levels. The tasks are categorized into Coin Flip (with varying rounds of flips), Web of Lies (with varying numbers of statements), Multi-step Arithmetic (with varying depth and length), Sports Understanding, and Object Count. The results demonstrate that CoT-decoding generally improves accuracy compared to greedy decoding, but the degree of improvement varies depending on the complexity of the task.

This table compares the performance of different decoding methods on the GSM8K dataset, both with and without zero-shot CoT prompting. It shows that combining CoT-decoding (either max or aggregated path) with zero-shot CoT prompting significantly improves accuracy compared to using either method alone. The computational complexity of each method is also indicated.

This table compares the effectiveness of different decoding strategies (greedy decoding, top-k sampling, top-p sampling, beam search, temperature sampling, self-consistency without CoT prompting, and CoT-decoding) on the GSM8K accuracy. It highlights that CoT-decoding is the only method that substantially improves the reasoning capabilities of language models, while other strategies either yield minimal gains or even hurt performance compared to greedy decoding.

This table shows examples of greedy decoding paths and alternative top-k paths for two reasoning tasks: GSM8K (math reasoning) and Year Parity (commonsense reasoning). The model’s confidence in each answer is shown in parentheses; higher confidence is represented by a bolder font. The table highlights that simply altering the decoding process (from greedy to top-k) can reveal inherent chain-of-thought (CoT) reasoning paths, which are often absent in the greedy approach.

This table compares the effectiveness of different decoding strategies in eliciting reasoning capabilities from language models. It shows that only CoT-decoding consistently achieves high accuracy, while other methods like top-k sampling, nucleus sampling, beam search, and temperature sampling yield lower accuracy or even hurt the model’s performance. This highlights the unique ability of CoT-decoding to extract the inherent reasoning abilities of LLMs.
Full paper#