↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Object-centric learning (OCL) aims to learn representations of individual objects within scenes without manual supervision. Traditional OCL methods primarily use bottom-up approaches, aggregating homogeneous visual features. However, these methods struggle in complex environments with heterogeneous features. This limitation hinders accurate object representation and effective visual reasoning.
This paper proposes a novel OCL framework that addresses these limitations by incorporating a top-down pathway. This pathway first bootstraps object semantics from slot attention outputs and then modulates the model to prioritize relevant features. This dynamic modulation, based on the model’s own output, significantly improves the representational quality of objects. The resulting framework achieves state-of-the-art performance on various benchmarks, demonstrating the effectiveness of integrating top-down information in OCL.
Key Takeaways#
Why does it matter?#
This paper is significant because it tackles the limitations of current object-centric learning (OCL) methods by incorporating top-down information. This is a crucial step towards achieving more robust and accurate object representations in complex visual environments. The proposed approach achieves state-of-the-art results and opens new avenues for research in OCL and related fields, such as visual reasoning and multi-modal learning. The methodology of bootstrapping top-down information without labelled data can inspire development of other unsupervised models.
Visual Insights#

This figure illustrates the architecture of the proposed self-modulating slot attention framework. It shows how a top-down pathway is integrated into the standard slot attention mechanism. The top-down pathway first bootstraps semantic information from the slot attention outputs using a codebook and vector quantization. This semantic information is then used to modulate the slot attention, improving the representation quality of the extracted object slots. The modulation happens both across channels and space, using attention maps. Finally, the modulated slot attention is repeated to refine the slots further.

This table compares the performance of the proposed self-modulating slot attention method with the baseline method, DINOSAUR, on two synthetic datasets, MOVI-C and MOVI-E. The metrics used are FG-ARI, mBO, and mIoU. The table shows that the proposed method outperforms DINOSAUR on all metrics across both datasets.
In-depth insights#
Top-Down OCL#
Top-down approaches in object-centric learning (OCL) offer a compelling alternative to traditional bottom-up methods by incorporating high-level semantic information. Instead of solely relying on low-level visual features, top-down OCL leverages prior knowledge, such as object categories or contextual cues, to guide the learning process. This can significantly improve performance in complex scenes where objects are heterogeneous, occluded, or have high intra-class variance. A key challenge in top-down OCL is bootstrapping this semantic information in an unsupervised setting. Methods may involve predicting object categories from bottom-up features and then using these predictions to modulate the attention mechanism. This dynamic modulation enhances the representational quality of objects by emphasizing relevant visual features and suppressing irrelevant ones. However, effective top-down integration requires careful consideration of how to seamlessly combine high-level semantics with low-level visual information to avoid hindering the model’s ability to learn object representations from data alone. The success of top-down OCL lies in its capacity to strike a balance between leveraging prior knowledge and learning robust object representations from raw visual input. Further research should explore how to robustly acquire, represent and integrate top-down information to further advance the field of unsupervised OCL.
Self-Modulation#
The concept of ‘Self-Modulation’ in the context of the provided research paper is a crucial innovation, enhancing object-centric learning (OCL) by dynamically adapting the model’s attention mechanism. It achieves this through a top-down pathway that bootstraps semantic information directly from the slot attention output, mapping slots to discrete codes in a learned codebook. This bootstrapped semantic knowledge is then used to modulate the slot attention’s inner activations, effectively focusing processing on feature subspaces consistent with the predicted object categories. The self-modulation process is data-driven and unsupervised, requiring no explicit object-level labels, enhancing the robustness and generalizability of the model, especially in complex visual scenarios where object homogeneity often breaks down. Key to its success is the synergistic interplay between top-down semantic and spatial guidance derived from the attention map, enabling more precise feature aggregation and more representative slots. This approach significantly improves performance in discerning objects with diverse appearances and addresses the limitations of purely bottom-up OCL approaches. The self-modulation mechanism adds a layer of sophisticated adaptation and efficiency to the model without increasing computational complexity significantly, highlighting the elegance and effectiveness of this design.
Semantic Bootstrap#
A semantic bootstrap approach in object-centric learning (OCL) would focus on leveraging inherent scene semantics to improve object representation, especially within complex scenes. Instead of relying solely on bottom-up feature aggregation, a semantic bootstrap would initiate the learning process by establishing high-level semantic concepts. This could involve methods such as clustering similar visual features or utilizing external knowledge bases. Once initial semantic categories are identified, the model can then refine object representations by prioritizing relevant features and suppressing irrelevant ones. This iterative process, where semantic understanding informs feature selection and vice-versa, leads to increasingly accurate and robust object representations. A key advantage of this approach is its ability to handle the heterogeneity of visual features within objects, a common challenge for bottom-up approaches in cluttered environments. Furthermore, a semantic bootstrap could reduce reliance on large amounts of labeled data, a significant limitation of current OCL methods, as it leverages inherent scene context for improved generalization. The effectiveness of such an approach would likely depend on the robustness of the initial semantic bootstrapping and the ability of the model to dynamically update its semantic understanding based on refined object representations.
Codebook Learning#
Codebook learning, in the context of object-centric learning, is a crucial technique for bootstrapping high-level semantic information from visual data without explicit annotations. It involves training a codebook, a collection of learned visual embeddings that represent different semantic concepts. The process of mapping continuous slot representations to discrete codes in the codebook is a form of vector quantization. This allows the model to learn abstract semantic categories from the data itself, forming a top-down pathway for guiding subsequent processing. The choice of codebook size is important, and a balance needs to be found. A codebook that is too small limits the expressivity of the model, while one that is too large might introduce noise. The paper demonstrates that dynamically adjusting the codebook size based on perplexity, a measure of how uniformly the codes are used, is effective; allowing the model to adapt to datasets with varying levels of semantic complexity. This resulting top-down knowledge is subsequently integrated to enhance object discovery in slot attention through self-modulation, effectively improving representation quality across diverse datasets.
Future: Code Design#
A future-oriented code design for object-centric learning (OCL) should prioritize modularity and scalability. The current reliance on large, monolithic models hinders both adaptability and efficiency. A modular design would allow for easier integration of new components, such as improved encoders, decoders, or attention mechanisms. Scalability is essential for handling increasingly complex visual scenes and datasets. Furthermore, future-proof design should incorporate mechanisms for incremental learning, enabling the model to adapt to new data without retraining from scratch. Improved code efficiency is crucial for deployment on resource-constrained devices. This necessitates optimizing the computational complexity of existing components, especially the attention mechanism, while maintaining accuracy. Finally, future work should explore novel approaches that integrate top-down information more seamlessly with bottom-up feature extraction. This could involve advanced methods for semantic bootstrapping and more sophisticated attention modulation strategies. Ultimately, the goal is a robust, efficient, and adaptable OCL system capable of handling the complexity of real-world visual data.
More visual insights#
More on figures

This figure visualizes the impact of self-modulation on slot attention. It shows four examples of images from the COCO dataset. For each example, there are three columns. The first column shows the original image. The second column shows the predicted object mask after applying the self-modulating slot attention. The third column shows the slot attention maps before and after self-modulation. This illustrates how the self-modulation process refines the attention maps and highlights objects more precisely. Lighter colors in the attention maps indicate higher attention scores.

This figure visualizes examples from a learned codebook used in the proposed model. Each code in the codebook represents a distinct semantic concept, and the figure shows example images associated with each code, demonstrating that the codebook successfully learns high-level semantic information about different object categories.

This figure shows a qualitative comparison of object segmentation results using slot attention with and without the proposed top-down pathway. The top row displays results obtained using standard slot attention, while the bottom row presents results after incorporating the top-down pathway. The improved segmentation in the bottom row demonstrates the effectiveness of the top-down pathway in refining the attention process.

This figure visualizes the results of the proposed self-modulating slot attention model on the MS COCO dataset. It shows comparisons between the original images, the model’s prediction of object masks, and the slot attention maps before and after the application of self-modulation. The color intensity in the attention maps corresponds to the attention score; lighter colors indicate higher attention scores. This visualization demonstrates the impact of self-modulation on refining the attention maps to more precisely delineate individual objects in complex scenes.
More on tables

This table compares the performance of the proposed method with the DINOSAUR baseline on two real-world datasets: COCO and VOC. It presents results for FG-ARI, mBO (mean best overlap, calculated using both semantic and instance segmentation ground truth), and mIoU (mean Intersection over Union). The table includes both the reported results from the original DINOSAUR paper and the authors’ own reproduction of those results, to ensure a fair comparison.

This table compares the performance of the proposed self-modulating slot attention method with several state-of-the-art object-centric learning methods across four benchmark datasets: COCO, VOC, MOVI-C, and MOVI-E. The metrics used for comparison are FG-ARI, mBO, and mIoU. The results demonstrate the superiority of the proposed method, particularly on the more challenging COCO and VOC datasets.

This table compares the performance of the proposed self-modulating slot attention model with the DINOSAUR baseline model on the COCO dataset. Both models use six iterations of slot attention. The table shows that the proposed model significantly outperforms DINOSAUR in terms of FG-ARI and mBO, demonstrating the effectiveness of the proposed top-down pathway.
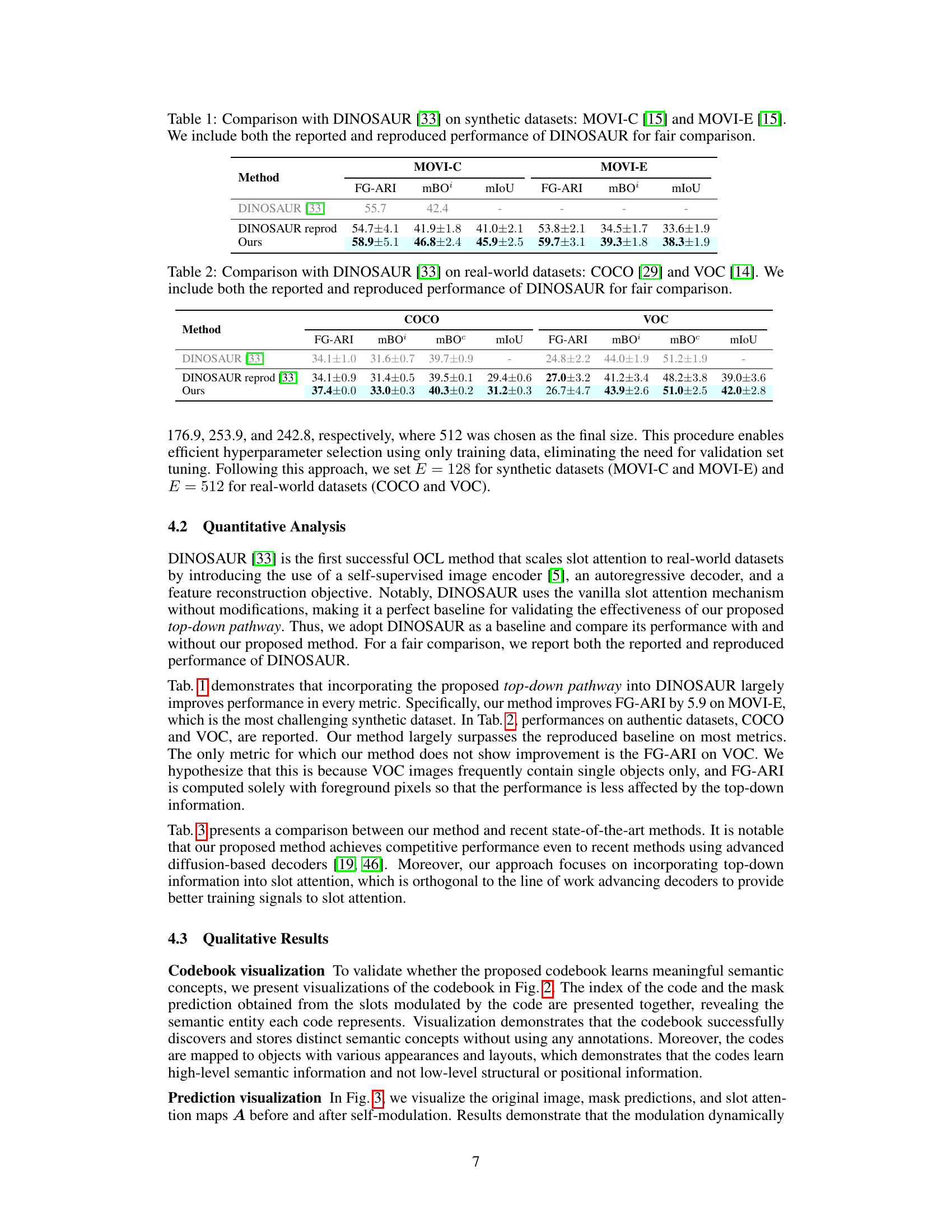
This table shows the performance of the proposed self-modulating slot attention model on the COCO dataset [29] using different codebook sizes (E = 128, 256, 512, 1024). The results are measured using two metrics: FG-ARI and mBO. The best performance is achieved with a codebook size of 512.
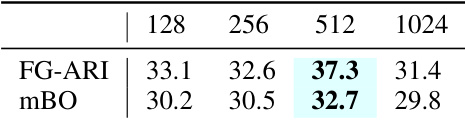
This table presents the ablation study results conducted on the COCO dataset. It shows the performance of the model when different components of the proposed top-down pathway are removed. The columns represent the inclusion (✓) or exclusion of specific modules: channel-wise modulation, vector quantization, spatial-wise modulation, and attention map shifting. The last row shows the full model’s performance, while the others progressively remove components to assess their individual contributions.

This table shows the comparison result between the reproduced slot attention and the proposed method with top-down pathway on CLEVR6 dataset. The metrics used are FG-ARI and mBO. The results show that while FG-ARI decreases, mBO shows significant improvement, which indicates the robustness of the proposed method.

This table compares the performance of the proposed method with the DINOSAUR baseline on two real-world datasets, COCO and VOC. It includes both the originally reported results from the DINOSAUR paper and the authors’ reproduction of those results to ensure a fair comparison. The metrics used are FG-ARI, mBO, and mIoU, providing a comprehensive evaluation of object discovery performance on more complex datasets than the synthetic ones used in Table 1.

This table compares the performance of the proposed self-modulating slot attention method with the DINOSAUR baseline on two real-world object-centric learning datasets: COCO and VOC. It shows the FG-ARI, mBO, and mIoU metrics for both the reported results from the original DINOSAUR paper and reproduced results. The comparison highlights the improvement achieved by incorporating the top-down pathway into the slot attention mechanism.
Full paper#