↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current language model alignment via finetuning on pairwise preferences faces challenges due to the inherent ambiguity and inconsistency of human feedback, especially in multidimensional contexts. Direct preference feedback is difficult to interpret and often inconsistent.
This paper introduces a two-step context-aware preference modeling approach. It first resolves the under-specification by selecting a context, and then evaluates preference with respect to that context. This decomposition clarifies the alignment problem, enabling more robust adaptation to diverse user preferences and offering enhanced flexibility for principled aggregation. The researchers contributed context-conditioned preference datasets and demonstrated that their context-aware model outperforms other leading models in aligning with diverse human preferences.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on preference modeling for language models as it directly addresses the ambiguity and inconsistency issues in current approaches. By introducing a novel two-step context-aware framework, it provides a more robust and flexible way to align language models with human preferences. The open-sourced datasets and improved models significantly advance the field, offering new avenues for research on contextual understanding and pluralistic alignment.
Visual Insights#

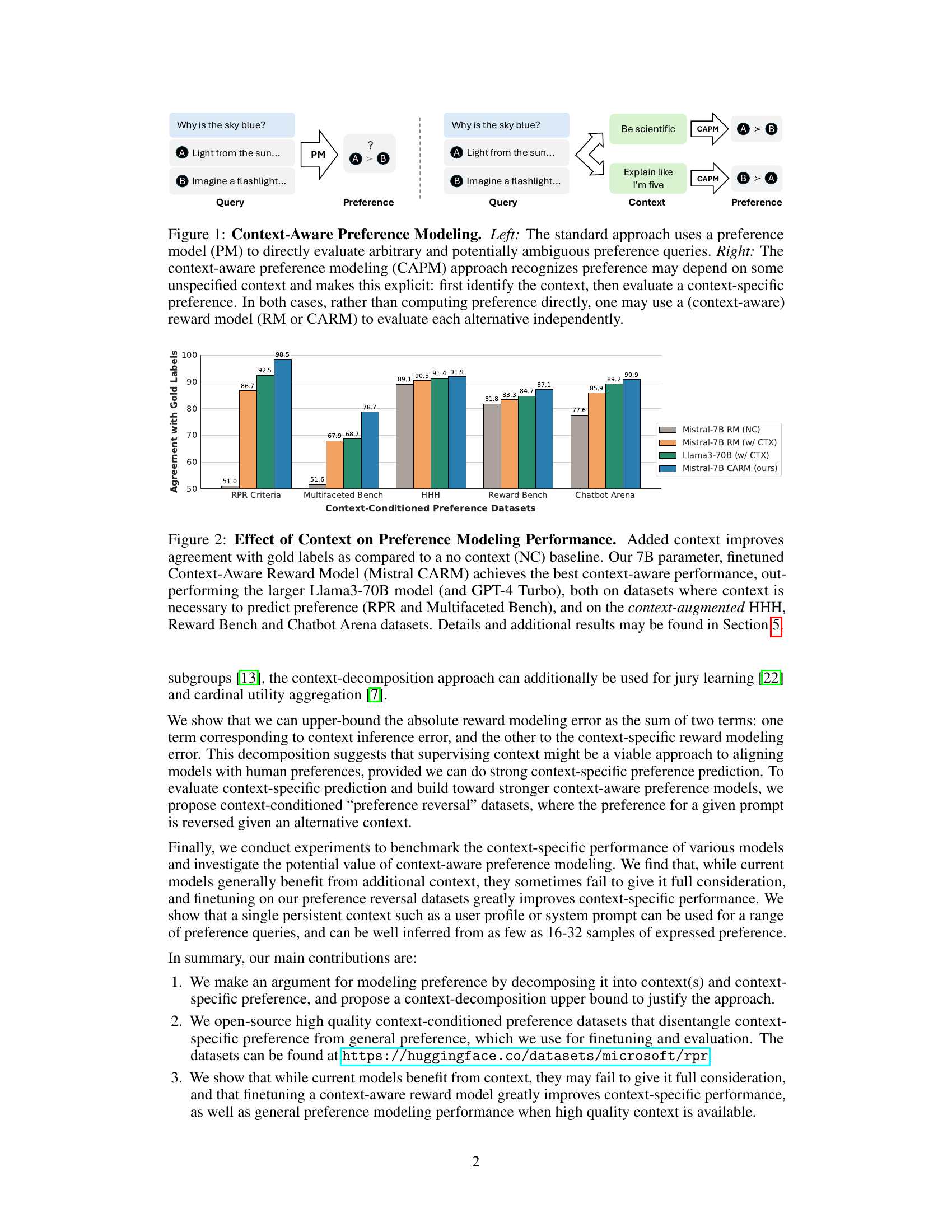
This figure illustrates two approaches to preference modeling. The left side shows the standard approach where a preference model directly evaluates preferences from ambiguous queries. The right side shows a two-step context-aware approach. First, a context is identified, then a context-specific preference is evaluated. Both approaches can utilize reward models to independently evaluate alternatives.

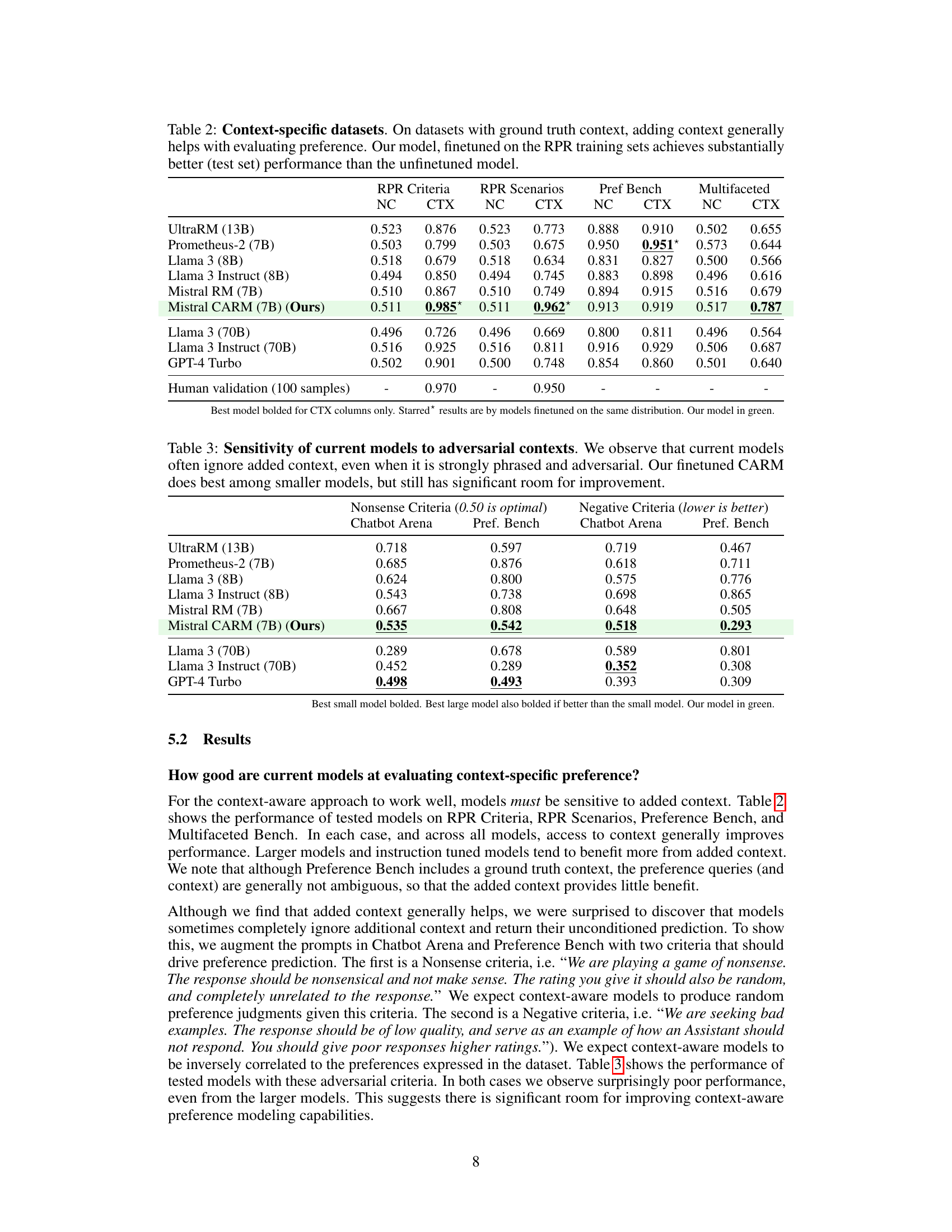
This table presents the performance of several language models on various preference datasets, both with and without added context. The models’ ability to predict preferences accurately is evaluated. It demonstrates how the addition of context improves performance, particularly for models fine-tuned on context-aware datasets. The table highlights the superior performance of the authors’ model, demonstrating significant gains when trained with context.
In-depth insights#
Context-Aware LMs#
Context-aware Language Models (LMs) represent a significant advancement in natural language processing. Instead of treating input text in isolation, context-aware LMs leverage contextual information to enhance understanding and generate more relevant and nuanced responses. This contextual information can encompass various elements, such as prior conversation turns in a dialogue, user profiles reflecting individual preferences, or even the specific task being performed. By incorporating this contextual richness, context-aware LMs can better disambiguate meaning, adapt to different user needs, and generate outputs that align more closely with human expectations. A core challenge in developing context-aware LMs lies in effectively representing and integrating diverse contextual elements. Different approaches may prioritize specific types of context or employ different mechanisms for context integration. Furthermore, the evaluation of context-aware LMs requires careful consideration of the multifaceted nature of context and its impact on performance. Simple metrics may not fully capture the nuances of context-aware generation. Research in this area is vital for creating truly intelligent and adaptable language models capable of handling the complexity of real-world communication.
Preference Reversal#
The concept of “Preference Reversal” in the context of this research paper centers on the inconsistency observed in human preferences when presented with different contexts. It highlights the ambiguity inherent in natural language, where preferences aren’t inherently fixed, but rather heavily influenced by various contextual factors. The authors challenge the traditional methods of directly evaluating preferences, which often produce unreliable and inconsistent results due to this inherent ambiguity. Instead, they propose a two-step process that separates context selection from preference evaluation, creating a more robust and accurate way of understanding how context shapes human judgment and modeling this phenomenon.
Dataset Creation#
The creation of a robust and reliable dataset is crucial for evaluating context-aware preference models. The paper highlights the need for datasets that explicitly disentangle context from preference, addressing the ambiguity inherent in natural language. Synthetic data generation is employed, leveraging a powerful language model like GPT-4 to create controlled scenarios and responses, ensuring consistency and minimizing annotation bias. The use of multiple prompt structures helps in capturing diverse contextual influences. The iterative refinement process emphasizes quality control, with human validation playing a key role in identifying and correcting errors or inconsistencies. This meticulous approach underscores the authors’ commitment to developing high-quality data that accurately reflects the complexities of human preferences and their contextual nuances, ultimately leading to more reliable model evaluation.
Model Finetuning#
Model finetuning in the context of large language models (LLMs) is a crucial process for aligning model outputs with human preferences. The provided text highlights the challenges inherent in directly finetuning models based on pairwise preferences, citing issues of ambiguity, inconsistency, and multidimensional criteria. The authors propose a two-step context-aware approach, where a context is first selected to address underspecification, followed by preference evaluation specific to that context. This decomposition of the reward modeling error into context selection and context-specific preference highlights the potential of context supervision alongside preference supervision to improve model alignment with diverse human preferences. The paper introduces novel datasets to facilitate the evaluation of context-aware preference models, demonstrating that context is critical, but existing models often fail to fully utilize it. Finetuning on these datasets significantly improves context-specific performance, surpassing the capabilities of even powerful models such as GPT-4 and Llama 3 70B in specific test scenarios. This research underscores the importance of explicitly modeling context in LLM training for achieving better alignment and robustness to diverse user intents.
Future Directions#
Future research could explore several promising avenues. Improving context inference is crucial; current models struggle to fully utilize provided context, and creating more robust methods for context disambiguation is key. High-quality, diverse datasets are also needed, ideally sourced from real human preferences, to improve generalizability and address biases. Exploring alternative aggregation methods beyond the Borda rule could further enhance context-aware preference modeling. Finally, researching more principled approaches to handling diverse user intents is vital. This might involve developing better methods for uncertainty quantification and incorporating explicit modeling of human diversity and disagreement into the preference modeling process itself. Investigating the interplay between context-aware preference modeling and other alignment techniques (such as Constitutional AI or Debate) would also be valuable.
More visual insights#
More on figures

The figure shows the performance comparison of different language models on various preference prediction datasets. The models are evaluated with and without additional context. The results demonstrate that incorporating context significantly improves the models’ agreement with gold labels, and the proposed context-aware reward model outperforms other models on most datasets.

This figure displays the performance of different language models on various preference prediction tasks. It shows that adding context significantly improves the models’ accuracy. The authors’ model, Mistral CARM, achieves the highest accuracy across multiple benchmarks, demonstrating the effectiveness of their context-aware approach.

This figure illustrates two approaches to preference modeling: the standard approach and the context-aware approach. The standard approach directly evaluates preferences using a preference model without explicitly considering the context. The context-aware approach, however, first identifies a relevant context and then uses a context-specific preference model to evaluate the preferences. Both approaches can utilize reward models to independently evaluate alternatives before making a final preference judgment.

The figure illustrates two approaches to preference modeling. The left side shows the standard approach where a preference model directly evaluates preferences from queries. The right side introduces a context-aware approach where the model first identifies the context and then evaluates preferences with respect to that context. Both approaches use reward models to evaluate alternatives, and the context-aware method is highlighted as a way to handle ambiguities in preference queries.

This figure illustrates two approaches to preference modeling. The standard approach uses a preference model to directly evaluate preferences, which can be ambiguous when the context is unspecified. The proposed context-aware approach involves a two-step process: (1) identifying the context and (2) evaluating the context-specific preference using a reward model. This approach is designed to address ambiguity and improve alignment with human preferences by making contextual assumptions explicit.
More on tables
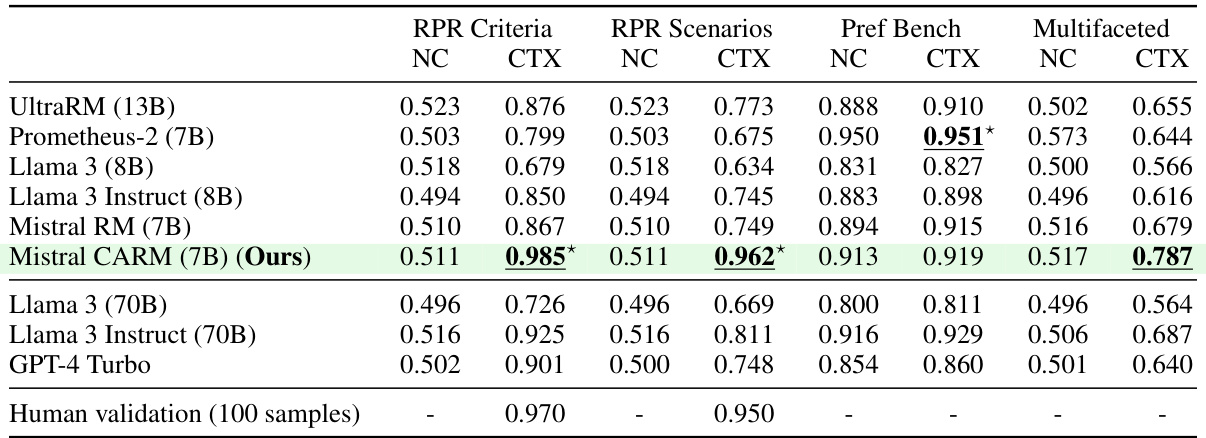
This table presents the performance of various models on four different datasets: RPR Criteria, RPR Scenarios, Preference Bench, and Multifaceted Bench. For each dataset, the model’s performance is shown with and without the addition of context. The results demonstrate that adding context generally improves the model’s performance. Notably, the authors’ model, which was finetuned on the RPR datasets, significantly outperforms the unfinetuned version. The table highlights the importance of context in accurate preference prediction.
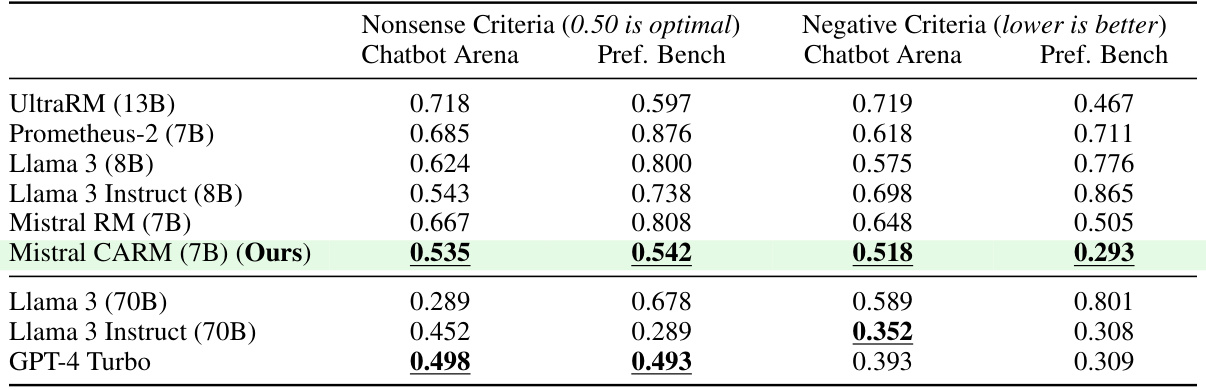
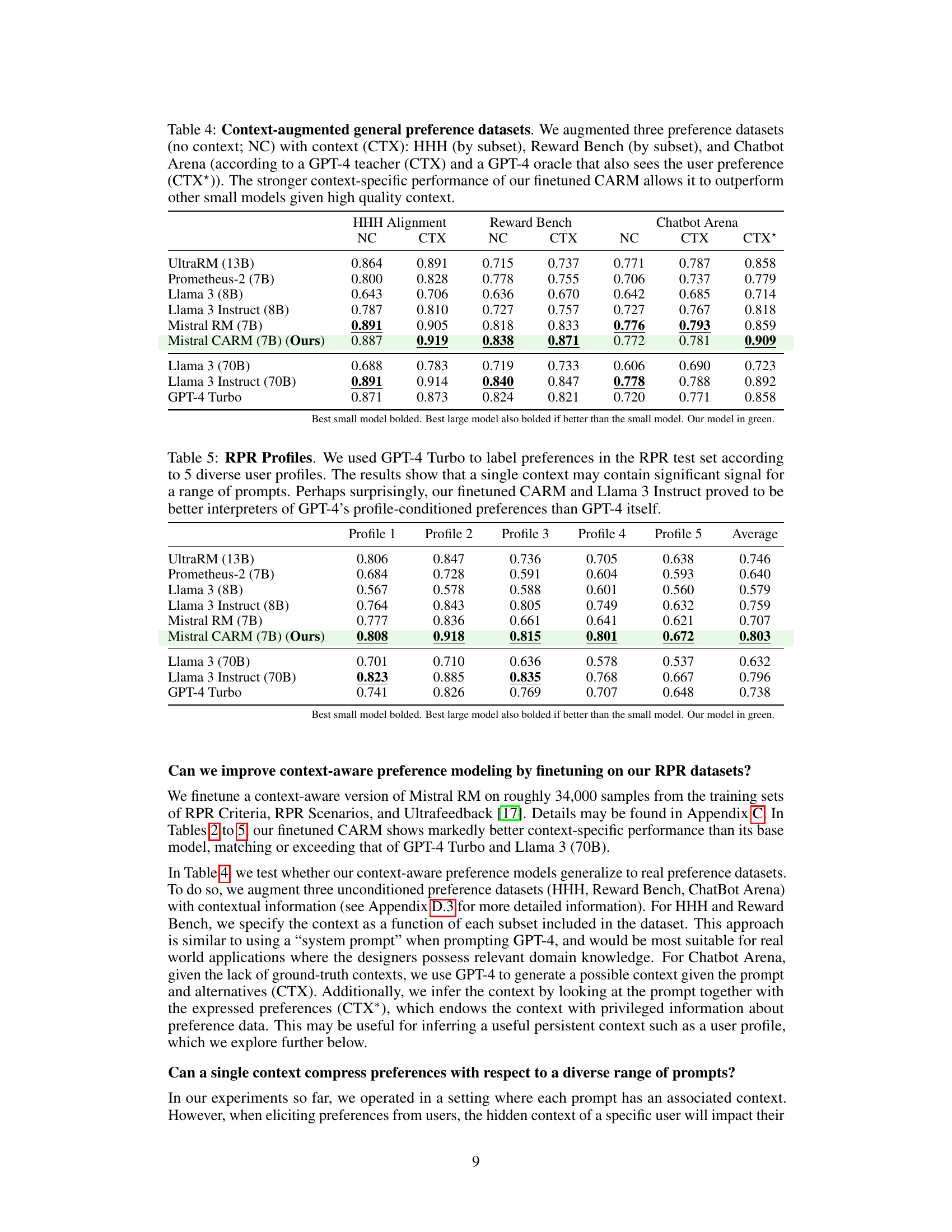
This table presents the results of evaluating several language models’ performance on adversarial contexts. The models were tested on two types of adversarial contexts: nonsense criteria (where the ideal response is nonsensical) and negative criteria (where the ideal response is of low quality). The table shows that most models struggle with these adversarial contexts, often ignoring the context and producing responses similar to those generated without context. The authors’ fine-tuned context-aware reward model (Mistral CARM) performs better than other smaller models but still has room for improvement.
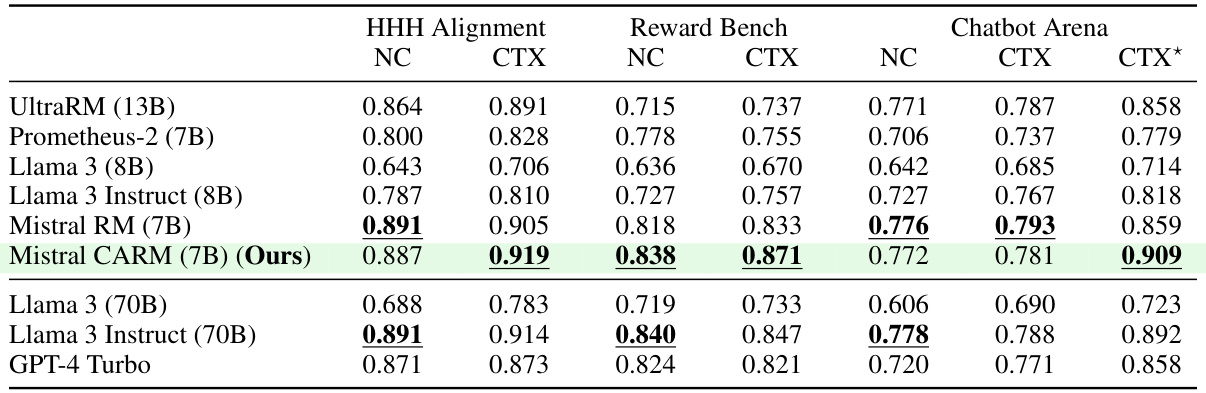
This table presents the performance of various language models on three general preference datasets (HHH, Reward Bench, and Chatbot Arena) with and without added context. The models are evaluated on their ability to predict human preferences. The table shows that adding context generally improves performance, especially for the authors’ model (Mistral CARM). The performance is broken down by dataset, with and without context and with different levels of context provided (teacher or oracle context).
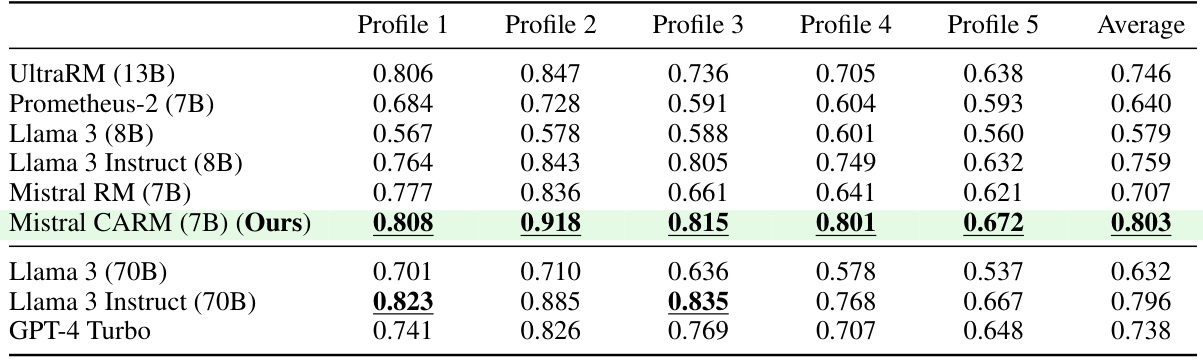
This table presents the results of an experiment where five different user profiles were used to label preferences in the RPR test set. The goal was to determine if a single context (user profile) could effectively capture preference across a range of prompts. The table shows the performance of several language models, including the authors’ finetuned CARM model, on this task. The results suggest that a single context can be quite effective, and that the authors’ model performs better than even GPT-4 in interpreting profile-based preferences.
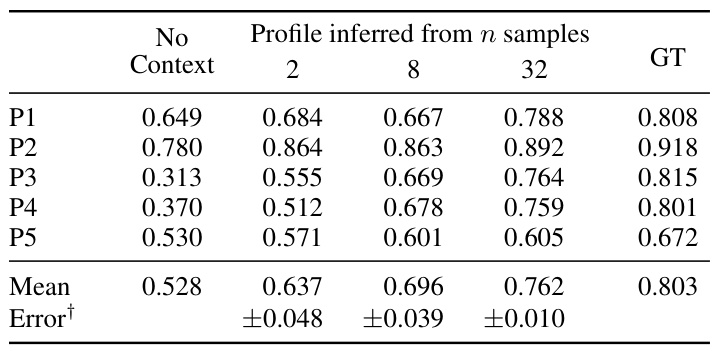
This table presents the results of an experiment where five different user profiles were used to annotate a dataset of preferences. The goal was to see how well a model could infer a user’s preferences from a small number of samples. The table shows that even with only two samples, the model could make reasonably accurate predictions, and accuracy increased as the number of samples increased. The results suggest that a single, well-defined context can be sufficient to capture a wide range of user preferences.

This table presents the performance of several language models on various context-specific datasets. The ‘NC’ column shows performance without using any context, while the ‘CTX’ column shows performance with context. The table highlights the improvement in performance when context is added, especially for the authors’ fine-tuned model (Mistral CARM) which significantly outperforms the other models on the test set.
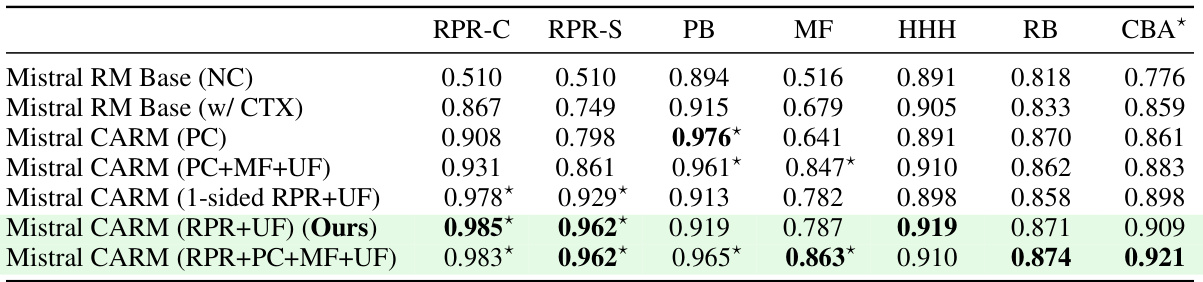
This table presents the performance of several models on various datasets that evaluate preference with and without context. The results show that adding context generally improves the model’s performance and demonstrates the impact of finetuning on a new dataset (RPR) in enhancing the context-aware preference modeling capabilities.
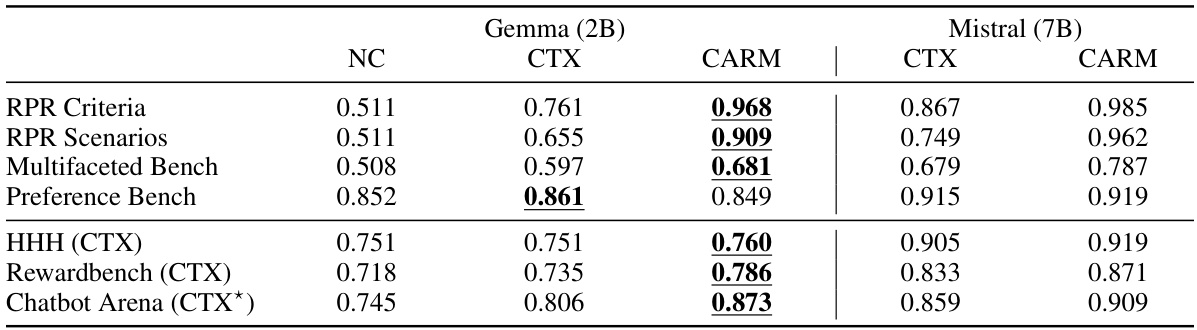
This table presents the performance of various language models on several context-specific datasets. The ‘NC’ column represents the performance without using any context, while the ‘CTX’ column indicates the performance with context. The results show that adding context generally improves the models’ performance in evaluating preference, especially in datasets where context is essential. This table also highlights that the model finetuned using the Reasonable Preference Reversal (RPR) datasets significantly outperforms the unfinetuned model on these datasets.
Full paper#