↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current text-to-video (T2V) models struggle with slow sampling speeds and subpar video quality, especially for fast inference consistency models. While consistency models enable faster inference, they compromise quality, leading to a quality bottleneck. Existing approaches that use reward feedback often face memory limitations due to backpropagation through the iterative sampling process.
T2V-Turbo tackles this problem by integrating feedback from multiple differentiable reward models during consistency distillation. This bypasses the memory constraints and directly optimizes rewards associated with single-step generations, resulting in significantly faster and higher-quality video generation. The results show the 4-step generations from T2V-Turbo outperforming state-of-the-art methods on benchmarks, achieving both speed and quality simultaneously.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in text-to-video generation because it presents T2V-Turbo, a novel approach that significantly improves the speed and quality of video generation. It offers a solution to the existing quality bottleneck in video consistency models, a major challenge in the field. The mixed reward feedback method introduced is highly innovative and paves the way for more efficient and high-quality T2V models. The benchmark results and human evaluation strongly support the method’s effectiveness. This work will likely shape future research directions in this rapidly developing area.
Visual Insights#

This figure shows a comparison of video quality generated by a Video Consistency Model (VCM) and the proposed T2V-Turbo model. The top row displays the results from a VCM using 4 and 8 inference steps, showcasing the quality limitations of this faster approach. In contrast, the bottom row demonstrates the improved video quality generated by T2V-Turbo using the same 4 and 8 inference steps. The improved quality is attributed to the integration of reward feedback during training. Appendix F of the paper provides further details and associated text prompts.
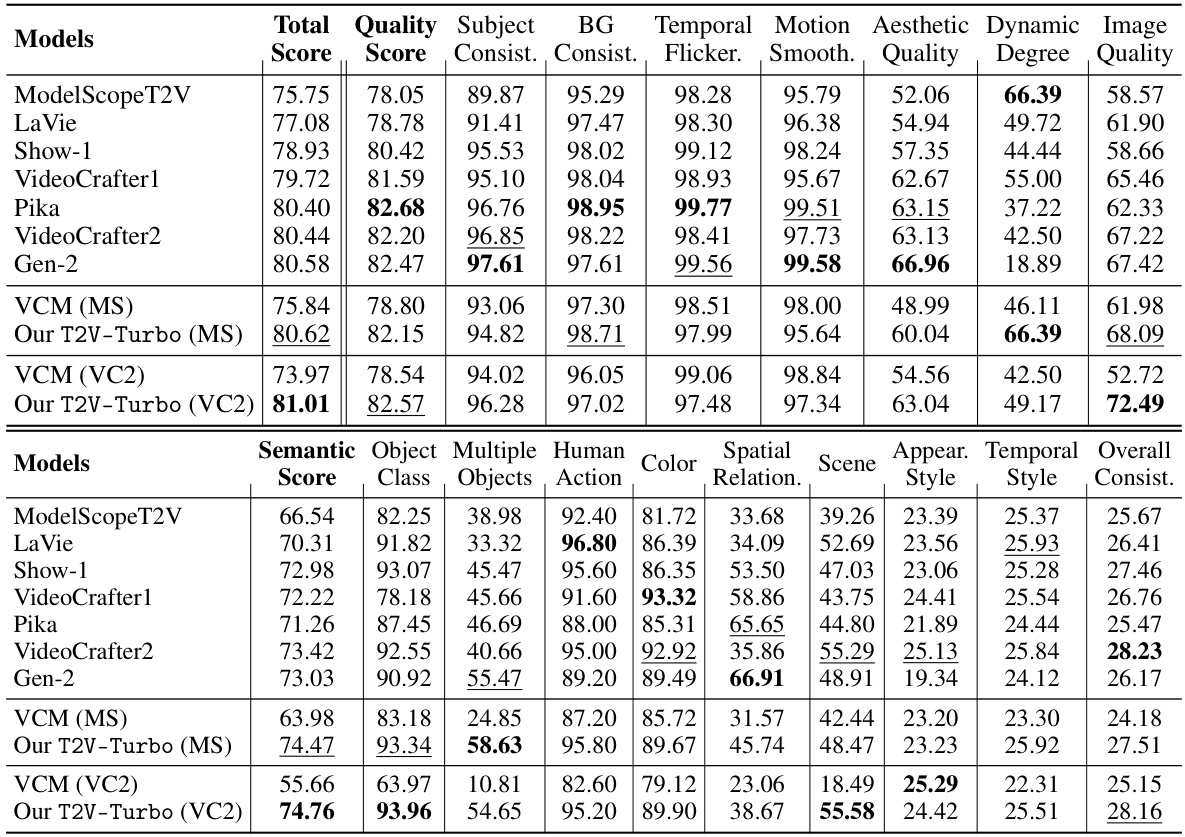
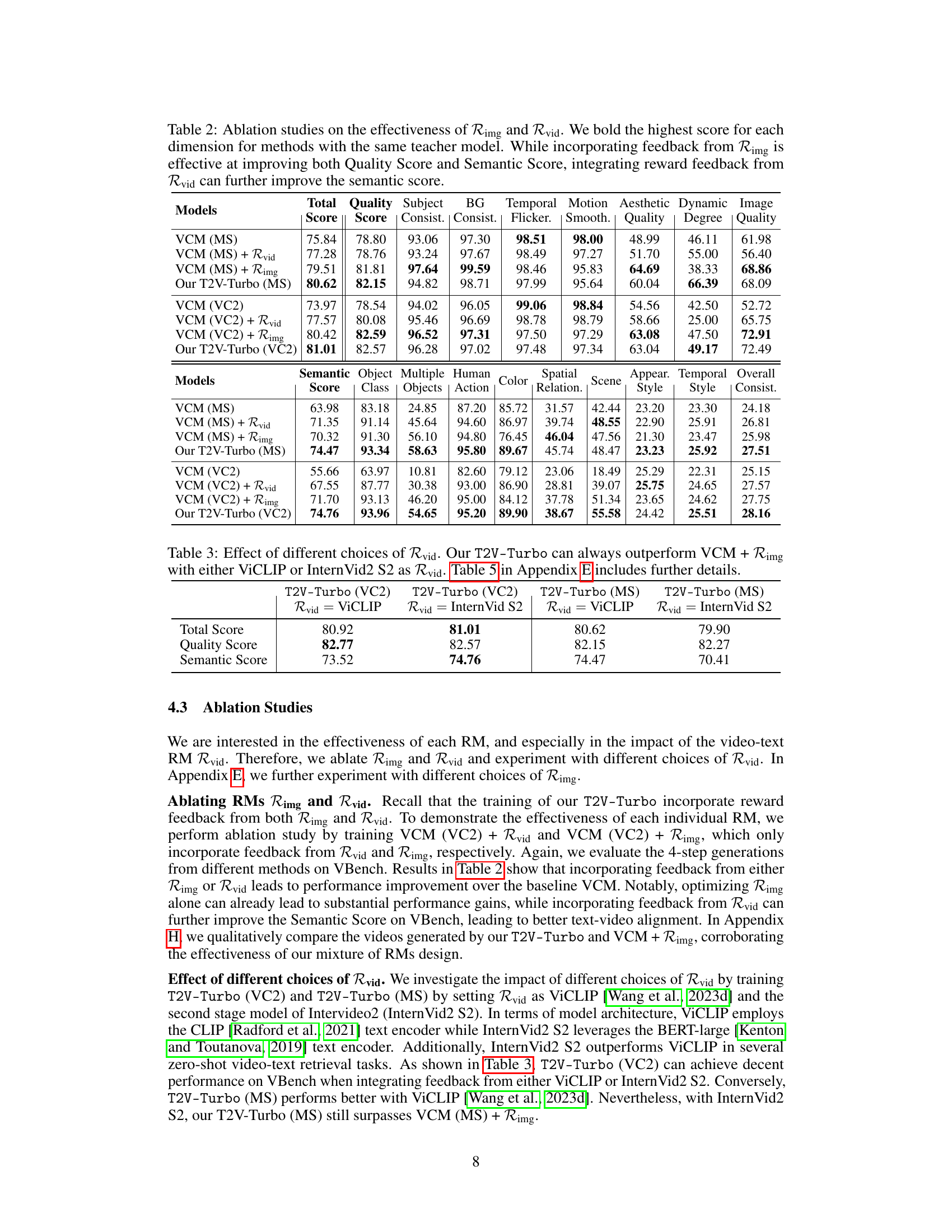
This table presents a quantitative comparison of the proposed T2V-Turbo model against various state-of-the-art (SOTA) methods on the VBench benchmark. It shows the performance across 16 different dimensions of video quality, categorized into Quality Score and Semantic Score, with a final Total Score combining both. The results highlight that T2V-Turbo significantly outperforms other models, especially considering its much faster inference speed of only 4 steps.
In-depth insights#
T2V Quality Boost#
A hypothetical research paper section titled “T2V Quality Boost” would likely explore methods for improving the quality of text-to-video (T2V) generation. This could involve investigating novel architectures that better capture temporal dynamics and visual consistency. The paper might delve into advanced training techniques, such as incorporating multi-modal feedback (e.g., image-text and video-text), or using reinforcement learning to optimize for specific aesthetic criteria. Addressing the quality bottleneck of current video consistency models would be a central theme, potentially through novel distillation methods or the introduction of more sophisticated loss functions. Furthermore, evaluating the impact of various design choices on video realism, temporal coherence, and alignment with text prompts would likely be a significant component, including comparisons with state-of-the-art techniques and possibly user studies to assess subjective quality. Ultimately, the “T2V Quality Boost” section would aim to present a compelling case for its proposed methods by demonstrating a significant improvement in the quality of generated videos compared to existing approaches.
Mixed Reward CD#
The concept of “Mixed Reward CD,” likely referring to a method combining consistency distillation (CD) with multiple reward signals, presents a powerful approach to enhance training in text-to-video (T2V) models. CD itself is a technique to accelerate the inference process by distilling knowledge from a slower teacher model to a faster student model. However, CD often sacrifices video quality. Integrating mixed reward signals, potentially including image-text and video-text rewards, addresses this limitation. The image-text reward helps align individual frames with the text prompt, ensuring visual fidelity, while the video-text reward evaluates the temporal coherence and transitions within the generated video, enhancing overall quality and narrative flow. This combined approach bypasses the memory constraints of directly backpropagating gradients through iterative sampling, offering a more efficient and effective training strategy. The effectiveness of such a method hinges on the careful selection and weighting of the different reward signals, potentially requiring experimentation to optimize their contributions to the overall training loss. Ultimately, this “Mixed Reward CD” approach holds the potential to achieve a desirable balance of speed and quality in T2V models.
VBench SOTA#
A hypothetical ‘VBench SOTA’ section in a research paper would analyze the state-of-the-art (SOTA) performance on the VBench benchmark. This involves a detailed comparison of the proposed model’s performance against existing SOTA models, highlighting improvements in key video generation metrics. Key aspects would include quantitative results, such as total scores, quality scores, and semantic scores across various dimensions, presenting these findings visually via tables and charts. Qualitative analyses might involve visual comparisons of generated videos, showcasing the relative strengths and weaknesses in terms of visual quality, realism, coherence, and adherence to prompts. The analysis should discuss the reasons for improved performance, potentially attributing it to novel architectural designs, training techniques, or dataset improvements. It should also address limitations, acknowledging any aspects where the proposed model may underperform compared to other methods. Overall, a strong ‘VBench SOTA’ section would provide compelling evidence supporting the proposed model’s advancement in video generation technology.
Human Eval Data#
A robust evaluation of any text-to-video (T2V) model demands both quantitative and qualitative assessments. While quantitative metrics offer objective scores, human evaluations provide crucial insights into subjective aspects like visual appeal and alignment with user intent. A hypothetical ‘Human Eval Data’ section in a research paper would detail the methodology for collecting human perception data, including the number of participants, their demographic diversity, the specific tasks given (e.g., rating video quality, assessing text-video consistency), and the interface used for data collection. Transparency is key, so this section should also describe how bias was mitigated (e.g., through careful prompt selection, diverse participant demographics, and well-defined evaluation criteria). The section must also describe how the data was analyzed, including any statistical methods used and any limitations inherent in the collection process. Finally, the limitations of human evaluation, such as inherent subjectivity and potential for biases, should be clearly stated. A thorough ‘Human Eval Data’ section would strengthen the paper’s credibility, providing strong evidence that supports the main claims and providing a complete picture of the research limitations.
Future of T2V#
The future of text-to-video (T2V) synthesis is bright, driven by advancements in both diffusion models and reward feedback mechanisms. High-fidelity video generation at unprecedented speeds will likely be achieved through continual improvements in consistency distillation techniques, which enable faster inference without sacrificing quality. The incorporation of diverse reward models, including image-text and video-text models, promises enhanced alignment between generated videos and user prompts, leading to significantly improved semantic coherence. Furthermore, ongoing research into more sophisticated video-text representations, coupled with the development of more robust and differentiable reward models will enable more nuanced control over video generation style, tempo, and content. Ultimately, the integration of human feedback loops into the training process will be crucial for aligning generated videos with actual human preferences, ushering in an era where T2V systems become intuitive, interactive tools for creative expression and communication.
More visual insights#
More on figures
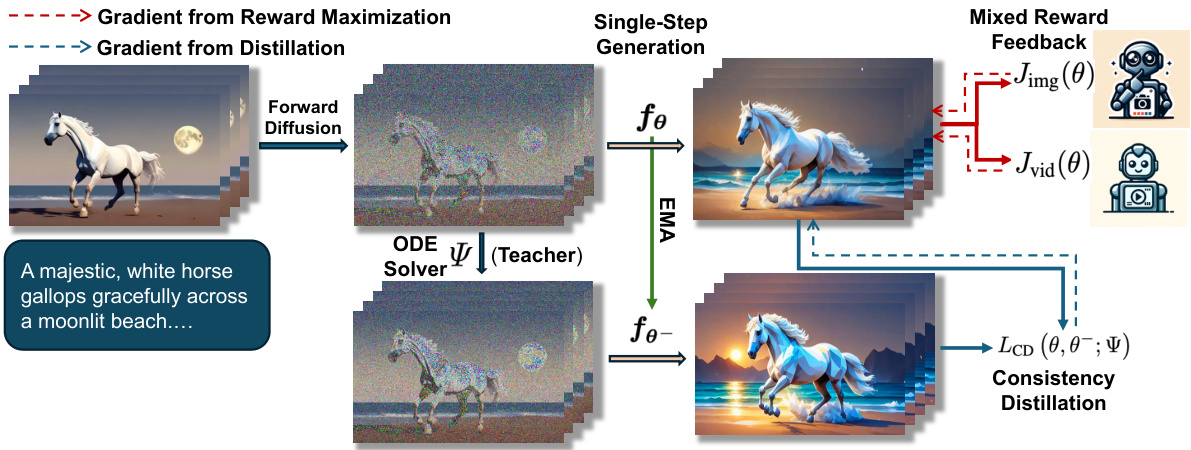
The figure illustrates the training process of T2V-Turbo. It shows how mixed reward feedback from both image-text and video-text reward models is integrated into the consistency distillation process. The gradient from reward maximization and the gradient from distillation are shown separately. A single-step generation is used, and the overall process aims to improve the video generation quality by optimizing for both visual appeal and text alignment.
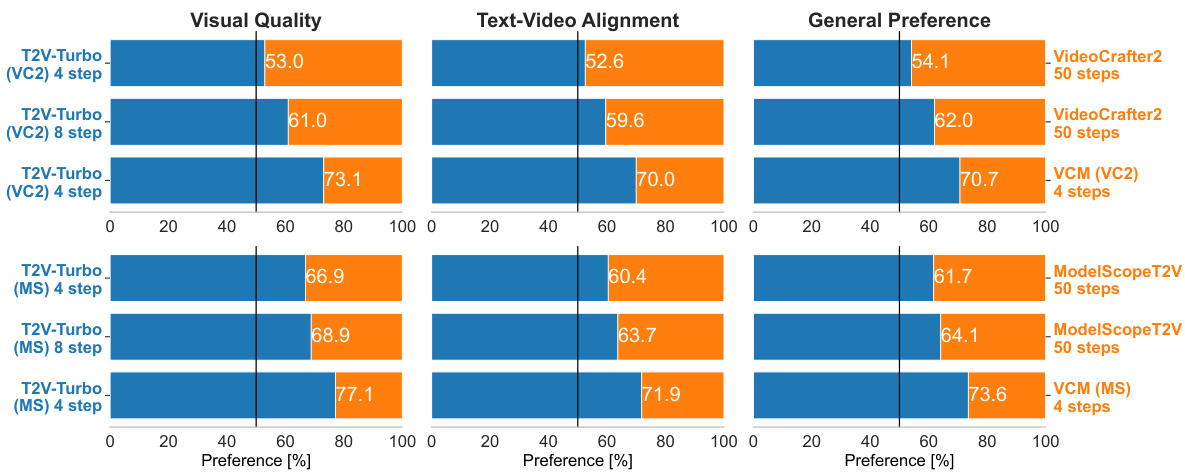
This figure shows the results of human evaluation comparing the 4-step and 8-step generations of T2V-Turbo with their respective teacher models (50-step DDIM samples) and baseline VCMs (4-step). The evaluation used 700 prompts from the EvalCrafter benchmark, assessing visual quality, text-video alignment, and overall preference. The top half displays results for T2V-Turbo (VC2), and the bottom half shows results for T2V-Turbo (MS). Each bar graph shows the percentage of human preferences for each model, broken down by the three evaluation metrics.

This figure presents a qualitative comparison of video generations from four different models: a baseline Video Consistency Model (VCM) with 4 inference steps, the teacher T2V model with 50 inference steps, and the proposed T2V-Turbo model with both 4 and 8 inference steps. The left column shows results from distilling the T2V-Turbo model from VideoCrafter2, while the right column displays results from distilling it from ModelScopeT2V. Each row shows a different video generation task, with each column demonstrating the differences in video quality between the four models. The image aims to visually showcase the improved video quality of the T2V-Turbo model over the baseline VCM and teacher model, especially within the fewer steps.

This figure illustrates the training process of the T2V-Turbo model. It shows how reward feedback from both image-text and video-text reward models is integrated into the consistency distillation (CD) process. Instead of backpropagating gradients through the entire iterative sampling process, T2V-Turbo directly optimizes rewards associated with single-step generations, thereby improving efficiency and video quality.

This figure presents an ablation study on the impact of different image-text reward models (Rimg) on the quality of video generation. Four sets of video frames are shown for the same prompt: a baseline VCM (VC2), and three versions of the VCM with added reward feedback from three different Rimg models: HPSv2.1, PickScore, and ImgRwd. The results illustrate that integrating any of these reward models improves the generated video quality compared to the baseline VCM. The visual differences highlight how each Rimg model affects the visual details and consistency of the generated video frames.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) when integrated into a video consistency model (VCM). Four different versions of the VCM are shown: one baseline VCM and three versions where different Rimg models (HPSv2.1, PickScore, and ImgRwd) are incorporated. Each model generates a sequence of video frames depicting a dog wearing sunglasses. The results demonstrate that adding any of the reward models improves the generated video’s quality compared to the baseline VCM. The specific improvements are visually apparent in the frames.

This figure shows an ablation study on the choice of image-text reward models (Rimg) used in the T2V-Turbo model. It compares the video generation quality of four models: a baseline VCM (Video Consistency Model), and three variations of the VCM that incorporate feedback from three different Rimg models (HPSv2.1, PickScore, and ImgRwd). The results indicate that incorporating reward feedback from any of these Rimg models leads to improved video generation quality compared to the baseline VCM.

This figure shows a comparison of video quality generated by the T2V-Turbo model and a Video Consistency Model (VCM). The left side shows videos generated by a VCM using 4 and 8 steps inference while the right side shows videos generated by T2V-Turbo. The T2V-Turbo model achieved significantly better video quality than the VCM model, demonstrating the effectiveness of the proposed approach.

This figure shows the results of video generation using T2V-Turbo and a baseline Video Consistency Model (VCM). The top row displays results from a Video Consistency Model, demonstrating lower image quality. The bottom row shows T2V-Turbo’s significantly improved video quality with only 4-8 inference steps, in comparison to VCM’s 8-step approach. The text prompts used to generate the videos are provided in Appendix F.
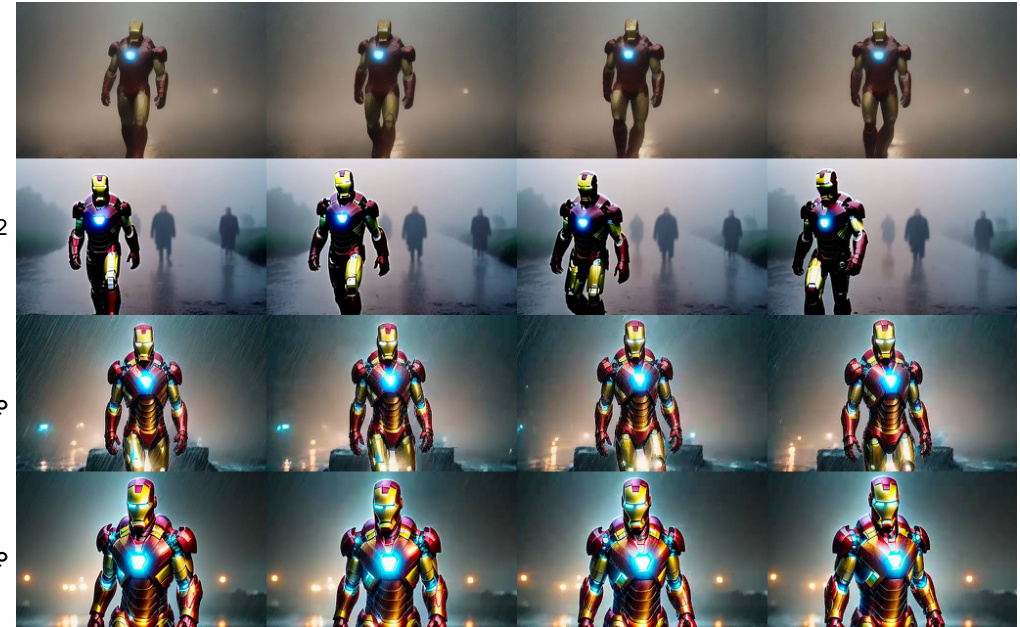
This figure shows a qualitative comparison of video generations from four different models using two different prompts. The models compared are a 4-step Video Consistency Model (VCM), a 50-step teacher T2V model, a 4-step T2V-Turbo model, and an 8-step T2V-Turbo model. The left side shows results for the VC2 variant of T2V-Turbo, while the right side shows results for the MS variant. Each row represents the outputs from the different models for a specific prompt.

This figure illustrates the training process of the T2V-Turbo model. It highlights the integration of reward feedback from both image-text and video-text reward models. Instead of backpropagating gradients through the entire iterative sampling process, T2V-Turbo directly optimizes rewards associated with single-step generations, making the training process more efficient and memory-friendly. The diagram shows how gradients from reward maximization and distillation are combined and used to optimize the single-step generation within the consistency distillation process.

This figure showcases a qualitative comparison of video generation results from four different methods: a baseline Video Consistency Model (VCM) with 4 inference steps, the original teacher T2V model with 50 steps, and the proposed T2V-Turbo method with both 4 and 8 steps. The left side shows results when using VideoCrafter2 as the teacher model, and the right side uses ModelScopeT2V. The comparison highlights the visual quality improvements achieved by T2V-Turbo, demonstrating its ability to match or even surpass the quality of the 50-step teacher model while significantly reducing computational cost.

This figure shows a qualitative comparison of video generations from four different models using two example prompts. The models compared are a 4-step Video Consistency Model (VCM), a 50-step teacher text-to-video (T2V) model, a 4-step T2V-Turbo model, and an 8-step T2V-Turbo model. The left side shows results using the VideoCrafter2 teacher model, while the right side shows results using the ModelScopeT2V teacher model. The image visually demonstrates the improvements in video quality achieved by T2V-Turbo, especially considering its significantly faster inference speed.

This figure showcases the results of using the T2V-Turbo model to generate videos. The top row shows videos generated using VideoCrafter2, a model known for generating high-quality videos but requiring many inference steps (8-step). The bottom row shows videos produced by T2V-Turbo, demonstrating that it can generate comparable quality with fewer inference steps (4-step). This highlights T2V-Turbo’s ability to maintain high-quality video generation despite significantly faster inference times. The examples illustrate the impact of the mixed reward feedback integrated into the T2V-Turbo training process.

This figure shows a qualitative comparison of video generation results from four different methods. The first column shows videos generated by a baseline Video Consistency Model (VCM) using only 4 inference steps. The second column shows videos generated by the teacher model (a pre-trained text-to-video diffusion model) using 50 inference steps. The third and fourth columns show the results from the proposed T2V-Turbo method using 4 and 8 steps respectively. Two different versions of T2V-Turbo are compared, (VC2) and (MS). The left half of the figure shows the VC2 results and the right shows the MS results. The purpose is to visually demonstrate the quality improvement and speedup achieved by T2V-Turbo compared to the baseline VCM and the teacher model.

This figure shows additional qualitative comparison results for T2V-Turbo (MS) model. It presents visual comparisons of video generation outputs for two different prompts: ‘Mickey Mouse is dancing on white background’ and ‘a man looking at a distant mountain in Sci-fi style’. The comparison includes outputs from the ModelScopeT2V (50-step), VCM (MS, 4-step), T2V-Turbo (MS, 4-step), and T2V-Turbo (MS, 8-step) models. The purpose is to visually demonstrate the improvements in video quality and coherence achieved by the T2V-Turbo approach compared to baseline VCM and the teacher model.

This figure provides additional qualitative comparisons of video generation results from different models. It specifically compares the 4-step and 8-step generations from T2V-Turbo (MS), the 50-step generations from its teacher model (ModelScopeT2V), and the 4-step generations from the baseline VCM (MS). Two video prompts are used: ‘Mickey Mouse is dancing on white background’ and ‘a man looking at a distant mountain in Sci-fi style’. The image shows several frames from the resulting videos, allowing for a visual comparison of video quality and fidelity across the different methods.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) when incorporated into the training process of a Video Consistency Model (VCM). Three different Rimg models were tested: HPSv2.1, PickScore, and ImageReward, and their outputs compared against the baseline VCM. The results demonstrate that all three Rimg models improve the video generation quality compared to the baseline VCM.

This figure illustrates the training process of T2V-Turbo. It highlights the integration of reward feedback from both image-text and video-text reward models. Instead of backpropagating gradients through the entire iterative sampling process, T2V-Turbo optimizes rewards directly associated with single-step generations, thus overcoming memory constraints.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) when integrated into the video consistency model (VCM). Three different models (HPSv2.1, PickScore, and ImageReward) were tested, and the results were compared to the baseline VCM and the proposed T2V-Turbo. Each image shows a sequence of four frames generated for a given prompt.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) when integrated into a video consistency model (VCM). The baseline VCM is compared to three variations incorporating HPSv2.1, PickScore, and ImageReward models. The results demonstrate that integrating any of these three models improves the video generation quality compared to the baseline VCM.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) when combined with a video consistency model (VCM). Three different Rimg models (HPSv2.1, PickScore, and ImageReward) were tested and compared to a baseline VCM without an added Rimg. The results show that adding any of the three Rimg models improved the generated video quality compared to the baseline VCM, suggesting that incorporating feedback from an image-text reward model enhances the video generation process.

This figure shows an ablation study comparing the performance of different image-text reward models (Rimg) in improving the quality of video generation. The results demonstrate that using any of the three tested Rimg models (HPSv2.1, PickScore, and ImageReward) results in higher-quality video generation compared to the baseline Video Consistency Model (VCM).

This figure presents an ablation study comparing the performance of different image-text reward models (Rimg) in improving video generation quality when integrated into a Video Consistency Model (VCM). Three different Rimg models (HPSv2.1, PickScore, and ImageReward) are compared against a baseline VCM without any Rimg. The results showcase that incorporating any of the tested Rimg models leads to a significant improvement in the quality of 4-step video generations compared to the baseline VCM.

This figure shows an ablation study on the effect of different image-text reward models (Rimg) on video generation quality. Three different Rimg models (HPSv2.1, PickScore, and ImageReward) are compared against a baseline video consistency model (VCM). The results demonstrate that incorporating feedback from any of these Rimg models improves the quality of the generated 4-step videos compared to the baseline VCM.
More on tables

This table presents a quantitative comparison of the proposed T2V-Turbo model against various state-of-the-art (SOTA) methods on the VBench benchmark. The benchmark consists of 16 dimensions evaluating different aspects of video quality. The table highlights the superior performance of T2V-Turbo across multiple dimensions, achieving the highest total score despite using significantly fewer inference steps (4) compared to other models. Quality and Semantic scores are also shown, along with a breakdown of individual dimension scores.

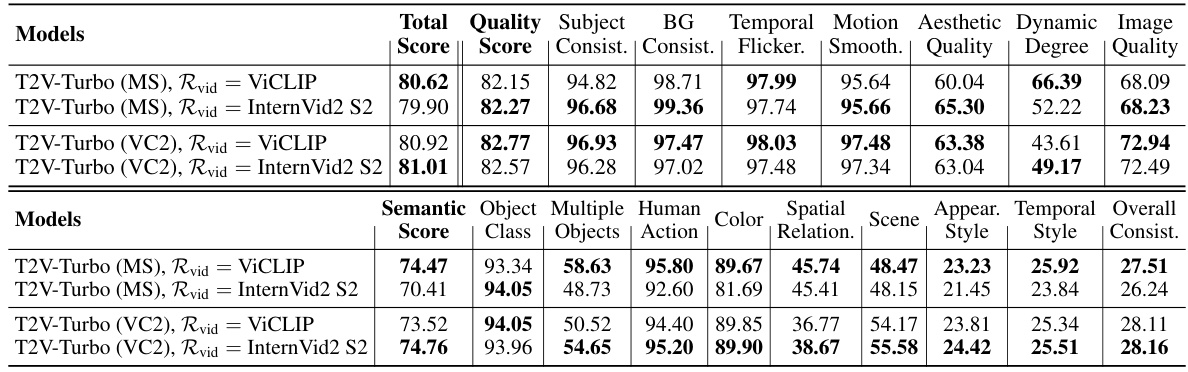
This table presents an ablation study comparing different choices for the video-text reward model (Rvid) within the T2V-Turbo framework. It shows the impact of using either ViCLIP or InternVid2 S2 on the overall performance, measured by total, quality, and semantic scores on the VBench benchmark. The results demonstrate that T2V-Turbo consistently outperforms a baseline VCM+Rimg model, regardless of the Rvid chosen.

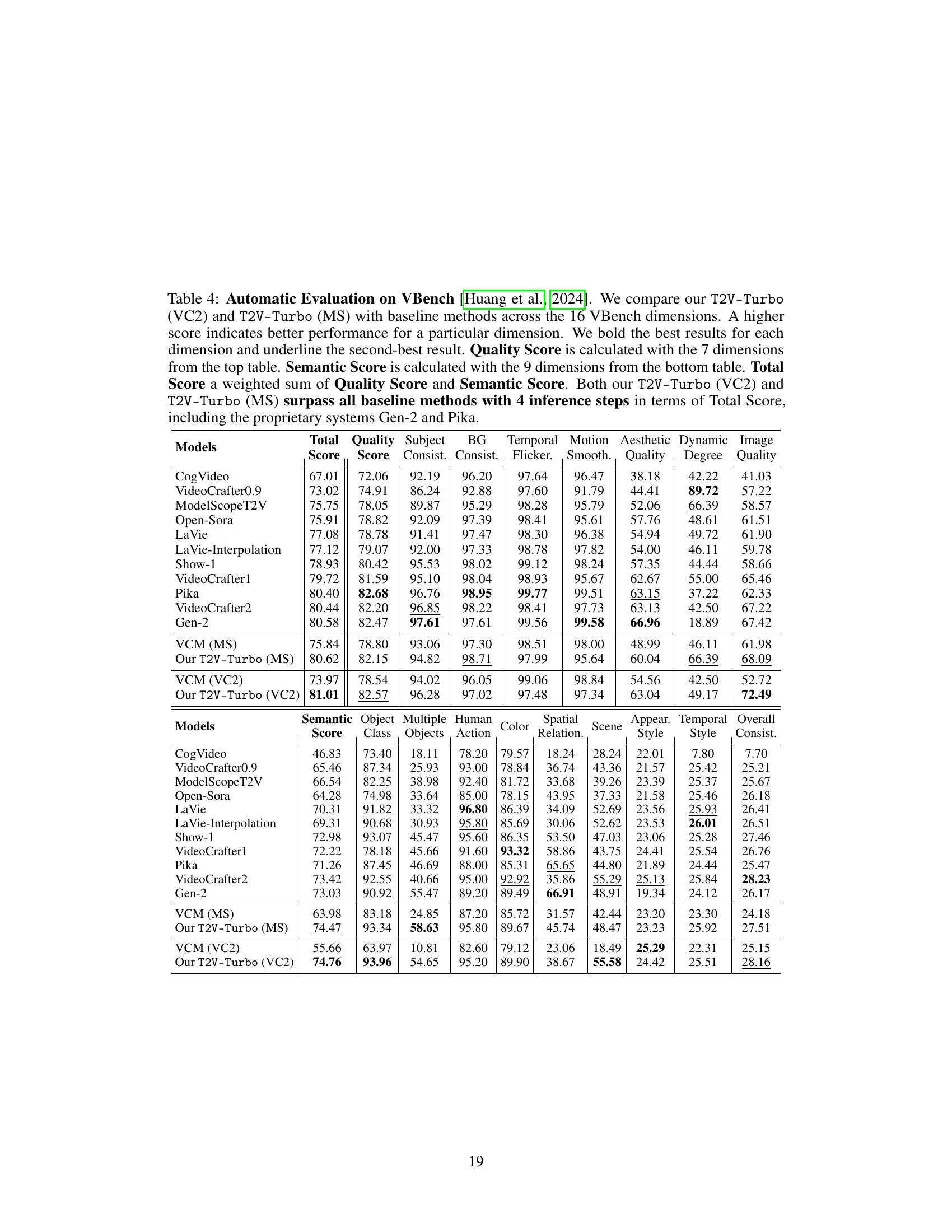
This table presents a quantitative comparison of the proposed T2V-Turbo model against various baseline models on the VBench benchmark. The comparison is across 16 different video quality dimensions, categorized into Quality and Semantic scores which are then combined into a Total Score. The table highlights that T2V-Turbo outperforms existing methods, even proprietary ones, in terms of overall quality despite using significantly fewer inference steps.
This table presents a quantitative comparison of the proposed T2V-Turbo model against several state-of-the-art (SOTA) text-to-video (T2V) models. The evaluation is performed using the VBench benchmark, which assesses T2V models across 16 different dimensions related to video quality, semantics, and consistency. The table shows that T2V-Turbo outperforms existing models, even those from proprietary systems, by a significant margin in the overall quality score, achieving this with far fewer inference steps.
Full paper#