↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Modern recommender systems heavily rely on embedding quality, with related entities ideally having similar representations. However, achieving this while minimizing recommendation loss is challenging, particularly for sequential recommendation scenarios. Existing methods often use Graph Neural Networks (GNNs) as intermediate modules which often introduces extra computational overhead.
This paper introduces Structure-aware Embedding Evolution (SEvo), a novel embedding update mechanism. SEvo directly injects graph structural information into embeddings during training, unlike GNNs. It’s designed to encourage similar evolution for related nodes, improving the smoothness and convergence of the embedding process. SEvo can be easily integrated into existing optimizers, such as AdamW, with minimal computational impact, resulting in consistent performance gains across a range of models and datasets. Experiments show substantial improvements, particularly on large-scale datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in recommender systems. It presents SEvo, a novel embedding update mechanism that significantly improves performance by directly incorporating graph structural information, offering a computationally efficient alternative to traditional GNN methods. This opens new avenues for enhancing recommendation models and is highly relevant to current trends in graph neural networks and sequential recommendation.
Visual Insights#
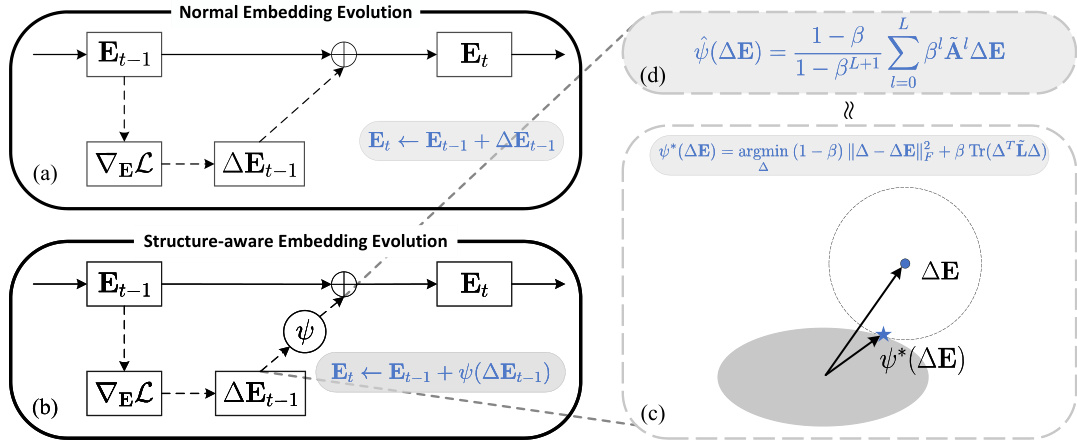
This figure illustrates the core idea of the Structure-aware Embedding Evolution (SEvo) method proposed in the paper. Panel (a) shows a standard embedding evolution process where the embedding is updated using the gradient. Panel (b) introduces SEvo, which incorporates a transformation (ψ) to the gradient update to encourage related nodes to evolve similarly. Panel (c) provides a geometric interpretation of the transformation ψ, showing how it projects the original variation onto a region with improved smoothness. Panel (d) depicts the L-layer approximation of the transformation, demonstrating a way to compute the transformation efficiently with a convergence guarantee.
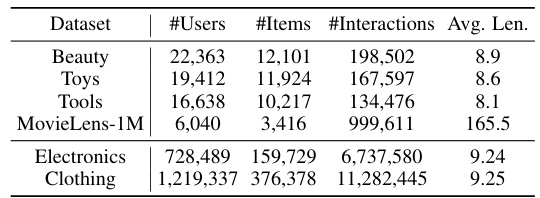
This table presents the statistics of six benchmark datasets used in the paper’s experiments. For each dataset, it lists the number of users, the number of items, the total number of interactions, and the average sequence length (Avg. Len.). The datasets vary significantly in size, ranging from MovieLens-1M with thousands of users and items to Electronics and Clothing with millions.
In-depth insights#
SEvo: Core Idea#
SEvo’s core idea revolves around enhancing embedding evolution in recommender systems by directly injecting graph structural information. Unlike traditional methods that use Graph Neural Networks (GNNs) as intermediate modules, SEvo modifies the embedding update mechanism itself. This direct injection minimizes computational overhead and allows seamless integration with existing optimizers. The key is a novel transformation applied to embedding variations, ensuring both smoothness (related nodes evolve similarly) and convergence. This transformation balances the inherent conflict between minimizing recommendation loss and enforcing graph-based smoothness. SEvo’s effectiveness stems from its ability to subtly guide embedding updates towards a region that is both performant and structurally consistent, leading to improved performance in sequential recommendation tasks. Theoretical analysis supports the design, providing convergence guarantees and justifying the chosen transformation’s properties. The method’s adaptability makes it broadly applicable, demonstrated by its seamless enhancement of existing optimizers such as AdamW.
Graph Reg. Impact#
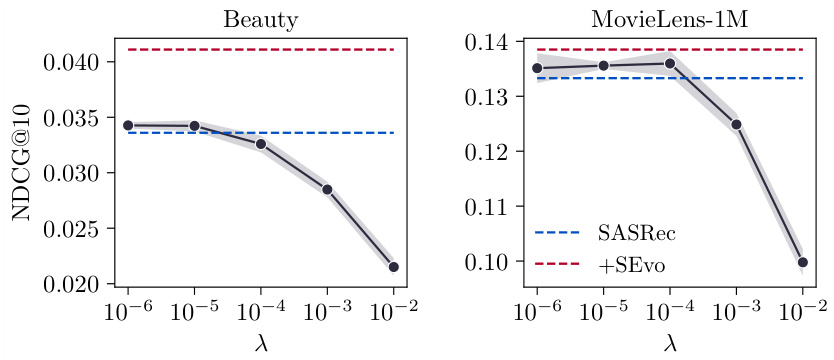
The effectiveness of graph regularization in enhancing recommendation systems is a central theme. The core idea revolves around leveraging graph structures to impose smoothness constraints on embedding evolution, encouraging similar representations for related entities. The impact of this approach is multifaceted. Firstly, it demonstrably improves the quality of embeddings by aligning node representations with the underlying graph structure. This leads to improved performance on downstream tasks such as recommendation and ranking. Secondly, it can be seamlessly integrated into existing optimizers, which enhances its practicality and flexibility. Thirdly, graph regularization enhances the overall smoothness of embedding updates, making the training process more stable and potentially accelerating convergence. However, it is crucial to acknowledge that the effectiveness of graph regularization is highly context-dependent and parameter-sensitive. Carefully choosing the regularization strength (e.g., using a hyperparameter) is essential to avoid over-smoothing or an inadequate improvement in the embeddings.
AdamW Enhancements#
The AdamW optimizer is a popular choice for training recommendation models due to its effectiveness and efficiency. However, the authors identify a potential limitation when applying AdamW to the proposed embedding update mechanism, SEvo. Specifically, the standard moment estimation in AdamW isn’t ideally suited for the smoothed variation produced by SEvo. The authors’ solution involves a moment estimate correction, particularly beneficial when dealing with sparse gradients. This modification enhances the robustness of the SEvo-enhanced AdamW across various models and datasets, demonstrating consistent performance gains. The core idea is to ensure that the moment estimates, which inform the update direction, accurately reflect the smoothed variations, improving convergence and stability of the training process. This enhancement highlights the importance of carefully considering the interplay between the optimizer and the embedding update strategy for optimal performance in recommendation systems. The rigorous empirical analysis and theoretical justification further validate the effectiveness of this correction.
Convergence Analysis#
The convergence analysis section of a research paper is crucial for establishing the reliability and efficiency of proposed methods. A rigorous analysis often involves demonstrating that the algorithm’s iterative process will eventually reach a stable solution. This might involve proving convergence bounds, indicating how quickly the method approaches the solution, or showing the algorithm’s stability under certain conditions. Theoretical analysis often relies on mathematical tools to characterize the behavior of the algorithm, such as analyzing gradients or examining the properties of the objective function. Empirical analysis, on the other hand, involves running experiments to observe the algorithm’s performance in practice. This can include plotting convergence curves, measuring the time taken to converge, or comparing the algorithm’s performance to existing methods. A comprehensive convergence analysis should ideally include both theoretical and empirical components, providing a solid foundation for the algorithm’s validity and practical applicability. Combining theory and experiments offers a robust evaluation of an algorithm’s convergence properties, bolstering confidence in its correctness and effectiveness. Furthermore, identifying potential limitations or factors that influence convergence is important for guiding future research and improvement efforts. This section is also valuable for comparing to state-of-the-art techniques and for making an overall argument for the algorithm’s efficacy.
Future Work#
The authors propose extending SEvo to multiplex heterogeneous graphs, acknowledging that real-world entities often participate in diverse networks. This is a significant direction as it addresses the complexity of modeling relationships beyond simple pairwise interactions. They also highlight the potential application to dynamic graph structures and incremental updates, suggesting a focus on scalability and efficiency. However, they acknowledge challenges: the computational overhead of continuous adjacency matrix normalization and the need to determine how to effectively weaken outdated historical information. These challenges represent important research opportunities that could lead to further improvements in the model’s performance and applicability to larger datasets and evolving contexts. The authors’ recognition of these limitations demonstrates a thoughtful and forward-looking perspective, positioning their work for future advancements in structure-aware recommendation systems. Addressing these challenges will be crucial in realizing SEvo’s full potential for real-world applications.
More visual insights#
More on figures
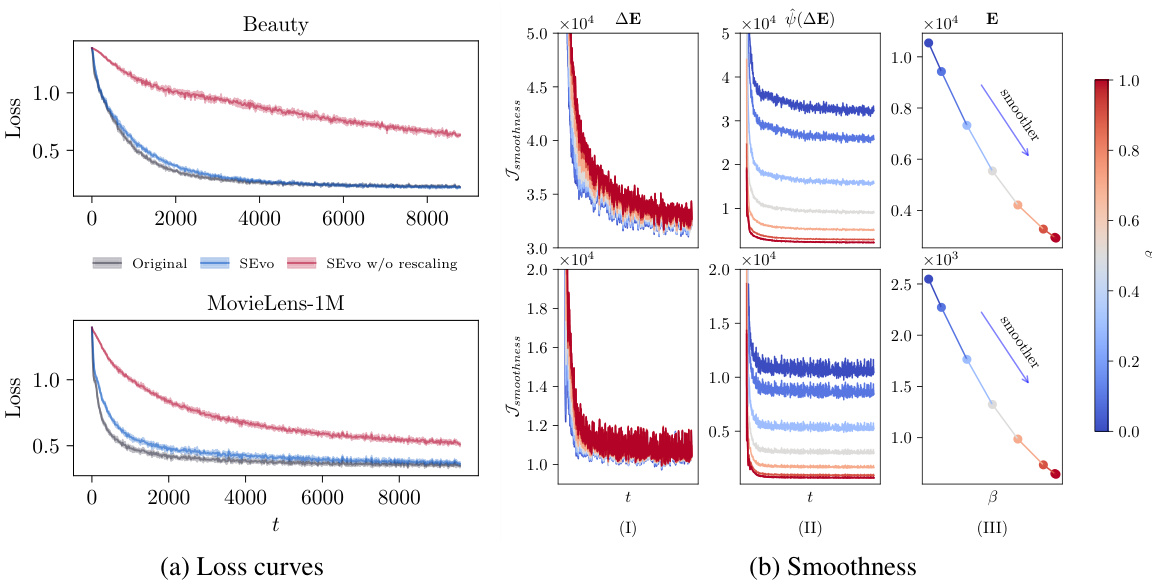
This figure empirically shows the convergence and smoothness of SEvo. The top panel shows the results on the Beauty dataset, while the bottom panel shows the results on the MovieLens-1M dataset. Subfigure (a) compares the loss curves of SASRec enhanced by SEvo with and without rescaling. It demonstrates that rescaling significantly improves convergence. Subfigure (b) shows the smoothness of the original variation, smoothed variation, and optimized embedding. A lower Ismoothness indicates stronger smoothness, demonstrating SEvo’s effectiveness in enhancing smoothness during the training process.
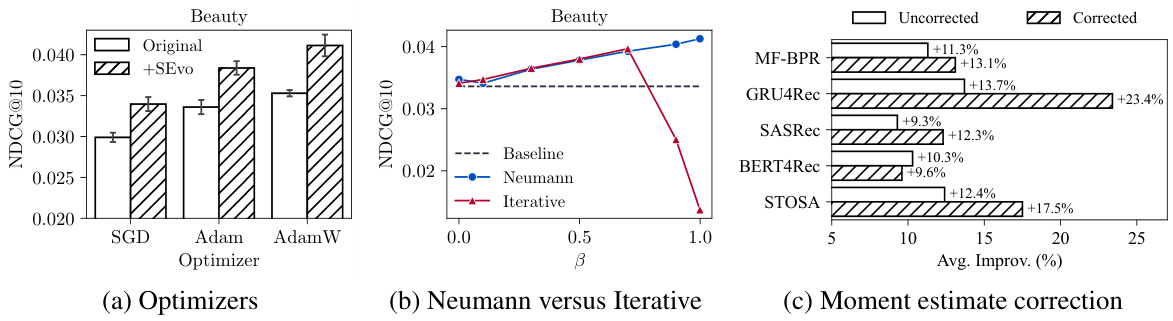
This figure shows the ablation study results for SEvo, comparing its performance across different optimizers (a), different approximation methods for the transformation (b), and with/without moment estimate correction (c). The results highlight the impact of each component of SEvo on its overall effectiveness.

This figure illustrates the core idea of the proposed SEvo method. Panel (a) shows standard embedding evolution, where updates are based solely on the gradient. Panel (b) introduces SEvo, which incorporates graph structural information into the update process. Panel (c) provides a geometric interpretation of the smoothing transformation applied in SEvo, showing how it projects the gradient onto a region of desirable smoothness. Finally, Panel (d) demonstrates the L-layer approximation used to efficiently compute the smoothed updates.
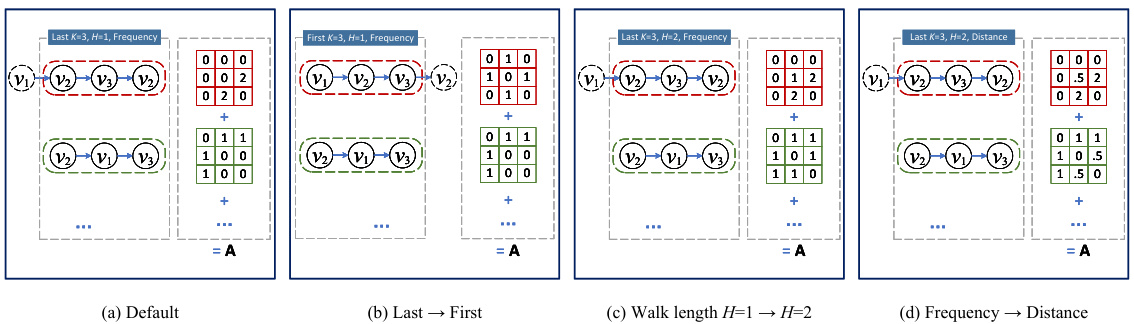
This figure illustrates different methods for estimating pairwise similarity based on interaction data. The default method (a) uses the co-occurrence frequency of items within the last K items of a sequence. Variations explore using only the first K items (b), allowing for a maximum walk length H greater than 1 (c), and comparing frequency-based versus distance-based similarity (d). Each sub-figure shows a sample sequence and the resulting adjacency matrix reflecting the pairwise similarity.
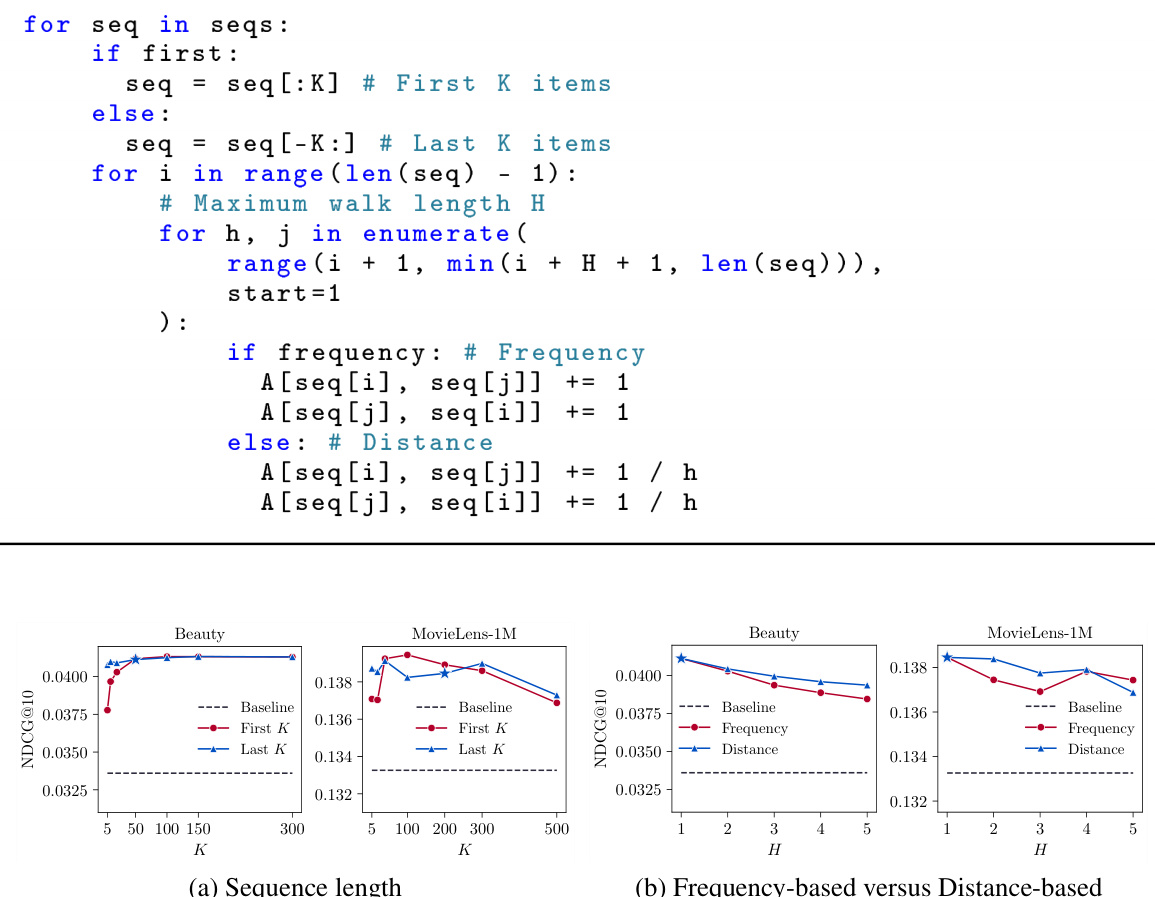
This figure shows the convergence and smoothness of the SEvo algorithm using two datasets, Beauty and MovieLens-1M. The left panel (a) compares the loss curves of SASRec with and without SEvo’s rescaling method applied during training, demonstrating the improvement in convergence when rescaling is used. The right panel (b) illustrates the smoothness of the embedding evolution process, showing the original variation, the smoothed variation using SEvo, and the resulting optimized embeddings. Lower smoothness values indicate greater smoothness of the embeddings. This comparison highlights SEvo’s ability to maintain smoothness while ensuring convergence.

This figure visualizes the movie embeddings using UMAP, a dimensionality reduction technique. The 18 movie genres are grouped into 6 broader categories for easier visualization. Each point represents a movie, and the color indicates its genre category. The figure shows how the movie embeddings cluster based on genre at different epochs during training, demonstrating the effect of the SEvo algorithm on embedding smoothness and intra-class representation proximity.
This figure shows the empirical results of convergence and smoothness using the Beauty and MovieLens-1M datasets. Panel (a) compares the loss curves of SASRec enhanced with SEvo, with and without rescaling of the variation. Panel (b) illustrates the smoothness of three variations: the original variation, the smoothed variation (by SEvo), and the optimized embedding. It shows that SEvo with rescaling achieves smoother embeddings and faster convergence than SEvo without rescaling and the baseline.
More on tables
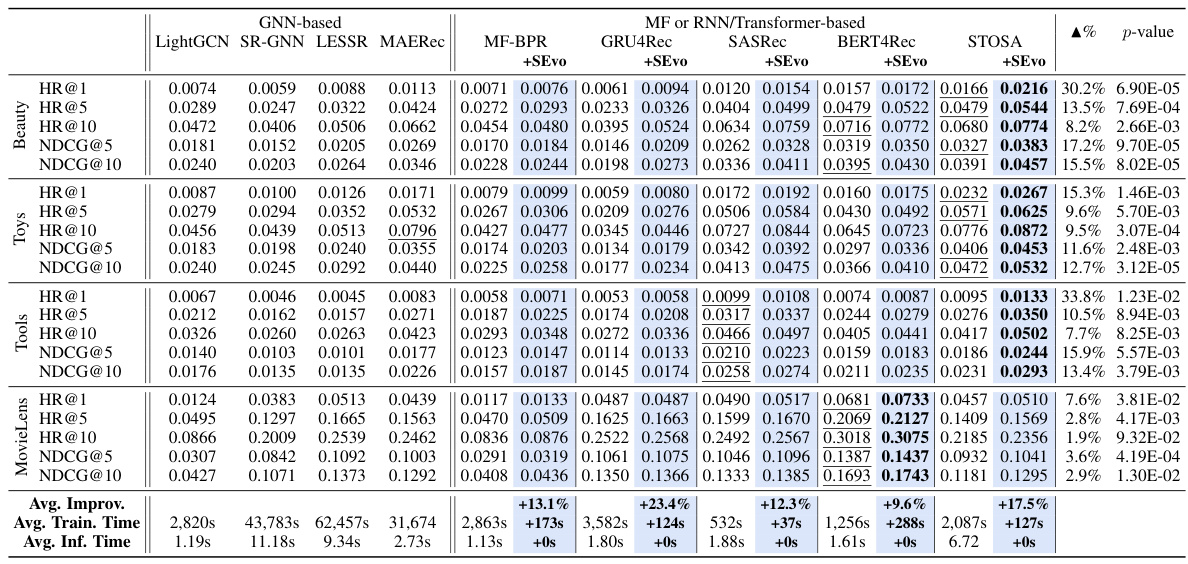
This table presents a comprehensive comparison of the performance of various recommendation models, including both GNN-based and RNN/Transformer-based models, with and without the proposed SEvo enhancement. It shows key metrics (HR@1, HR@5, HR@10, NDCG@5, NDCG@10) for six different datasets (Beauty, Toys, Tools, MovieLens-1M, Electronics, Clothing). The table highlights the relative improvement achieved by incorporating SEvo into the existing models, also including statistical significance (p-value) to indicate if improvement is significant, and the average improvements across all models.

This table presents the results of applying SEvo to the Electronics and Clothing datasets, which are larger datasets with millions of nodes. The results show that SEvo significantly improves the performance of the SASRec model on these datasets, with improvements ranging from 73.9% to 139.1%. The table also shows that SEvo only adds a small amount of computational overhead. The improvements are more significant on the Clothing dataset, which may be because this dataset is more challenging due to its size and sparsity.

This table presents the results of pairwise similarity estimation using two different methods: interaction data and movie genres. It shows how the performance of HR@1, HR@10, and NDCG@10 varies depending on the beta parameter and the method used for similarity estimation. The results are for the MovieLens-1M dataset.
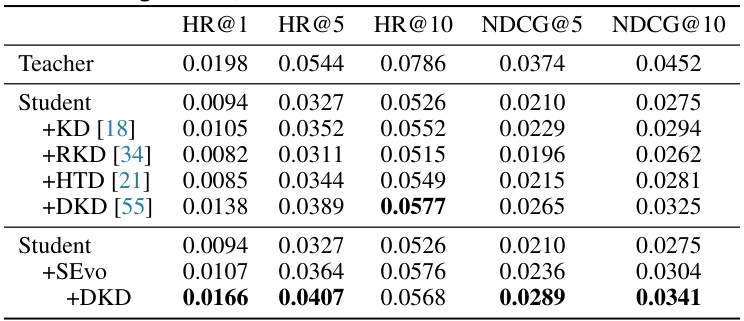
This table presents the knowledge distillation results from a teacher model (SASRec with embedding size 200) to a student model (SASRec with embedding size 20) on the Beauty dataset. It compares the performance of the student model alone against several knowledge distillation methods (KD, RKD, HTD, DKD), and finally with SEvo and DKD combined. The results are averaged across 5 independent runs and show the impact of different knowledge distillation techniques on recommendation performance metrics (HR@1, HR@5, HR@10, NDCG@5, NDCG@10).

This table presents a comprehensive comparison of the performance of various recommendation models, including both GNN-based and RNN/Transformer-based models, with and without the proposed SEvo enhancement. The results are reported across six different datasets using standard metrics such as HR@N and NDCG@N. The table highlights the relative improvement achieved by SEvo compared to the baseline models for each metric, dataset, and backbone model, indicating statistical significance where applicable.

This table presents the performance of SEvo using different numbers of approximation layers (L) for the Beauty and MovieLens-1M datasets. The results show HR@1, HR@10, and NDCG@10 metrics for each layer (L=0 to L=5), indicating how the approximation affects the recommendation performance. The optimal number of layers appears to be around L=3 for both datasets.

This table presents a comparison of the performance of different recommendation models (both GNN-based and RNN/Transformer-based) with and without the proposed SEvo method. It shows key metrics (HR@1, HR@5, HR@10, NDCG@5, NDCG@10) for several datasets, the relative improvement gained by using SEvo, and the p-values from paired t-tests to assess the statistical significance of the improvements. The table highlights the consistent performance gains achieved by integrating SEvo across different models and datasets.
Full paper#



















