↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Aligning large language models (LLMs) with human preferences is crucial for building safe and reliable AI systems. Current contrastive preference optimization methods, while promising, often focus on relative reward differences and ignore the actual reward values, resulting in suboptimal alignment. This leads to issues like decreased likelihood of choosing the best response. Furthermore, the scale of implicit reward is also not necessarily consistent with the ground truth reward.
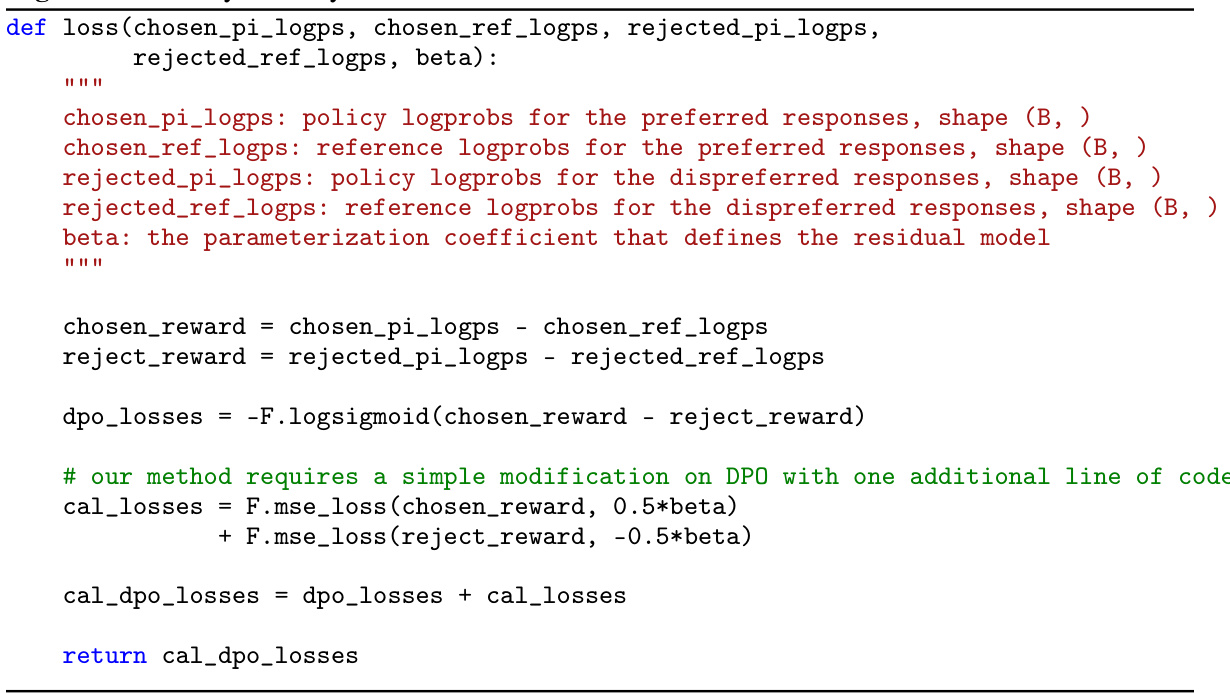
Cal-DPO addresses these issues with a simple yet effective calibration technique. By calibrating the implicit reward scale to match ground-truth rewards, Cal-DPO ensures that the learned implicit rewards are comparable in scale to ground truth rewards. This leads to substantial improvements in aligning LLMs with human preferences. The paper demonstrates Cal-DPO’s effectiveness through theoretical analysis and experiments on a variety of standard benchmarks, showing significant performance improvements compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on language model alignment because it introduces a novel and effective method, Cal-DPO, to address the limitations of existing contrastive preference learning methods. Cal-DPO significantly improves the alignment of LLMs with human preferences, leading to more reliable and human-aligned AI systems. This work opens up new avenues for research in preference learning and has implications for a broad range of applications, particularly in safety-critical domains.
Visual Insights#
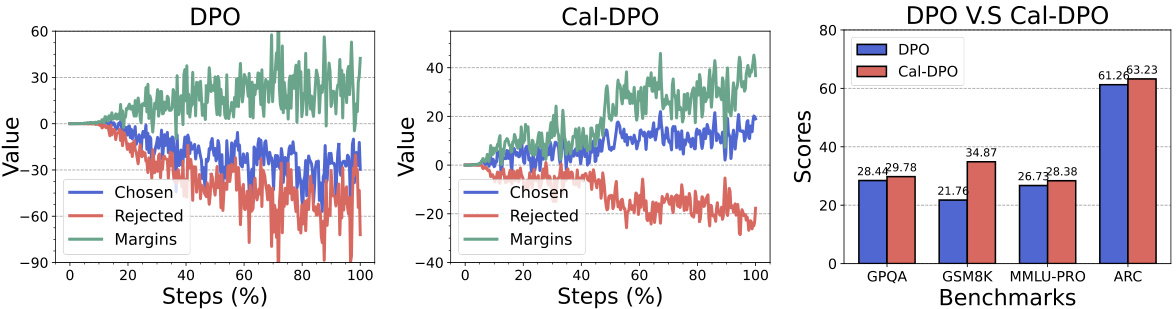
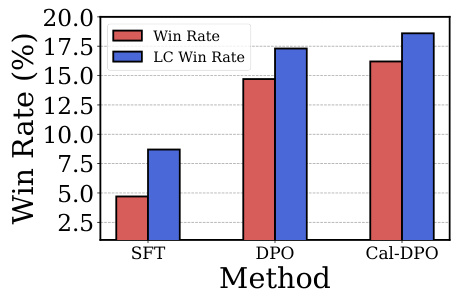
The figure shows the training dynamics of DPO and Cal-DPO algorithms on the UltraFeedback dataset. It illustrates how the implicit rewards for chosen and rejected responses change during training. DPO shows a decrease in rewards for chosen responses, even while maintaining a margin over rejected responses. In contrast, Cal-DPO maintains positive rewards for chosen responses while still increasing the margin. The bar chart shows that Cal-DPO significantly outperforms DPO on several reasoning benchmarks.

This table compares several methods for aligning large language models (LLMs) with human preferences. It shows whether each method is efficient for offline learning, if it calibrates rewards, if it uses negative gradients, and whether its objective function optimizes the reverse KL-divergence (which tends to encourage mode-seeking behavior). MLE and RLHF are included for comparison but are not considered preference optimization methods in the same sense as the others.
In-depth insights#
Calibrated Reward#
The concept of a “Calibrated Reward” in reinforcement learning, especially within the context of aligning large language models (LLMs) with human preferences, is crucial. A calibrated reward accurately reflects the true value or desirability of an LLM’s response, enabling effective training and alignment. Improperly calibrated rewards can lead to suboptimal or even counter-intuitive behavior, where the LLM prioritizes relative rankings over absolute values, potentially decreasing the quality of preferred responses. Calibration ensures that the learned implicit rewards from human feedback are comparable in scale to the ground truth rewards. This prevents issues like the continuous decrease of rewards for chosen responses, while ensuring that the learned policy consistently increases the likelihood of generating desirable outputs. A well-calibrated reward system is essential for training LLMs to reliably follow human preferences and produce high-quality, safe, and beneficial responses. Calibrating rewards is a key step towards creating effective and ethical AI systems, as it directly addresses the challenge of aligning AI behavior with human values.
DPO Enhancement#
The concept of “DPO Enhancement” in the context of large language model (LLM) alignment focuses on improving the performance and stability of Direct Preference Optimization (DPO). DPO’s core strength lies in using the likelihood of a model’s policy to implicitly define a reward function, circumventing the need for explicit reward modeling, thus enhancing efficiency. However, DPO suffers from issues such as suboptimal calibration and a tendency for the reward of chosen responses to decrease, resulting in inconsistent improvements. Enhancements would likely address these shortcomings, potentially through techniques like reward calibration, ensuring that the learned implicit rewards align with ground-truth values. Furthermore, enhancements might involve modifying the loss function to prevent the undesirable decrease in reward scores for chosen actions. Theoretical analysis of enhanced DPO methods would be crucial to prove properties like convergence to an optimal policy and mode-seeking behavior. Ultimately, effective DPO enhancement results in significantly improved LLM alignment with human preferences, leading to more dependable and beneficial AI systems.
Theoretical Advance#
A theoretical advance section in a research paper would delve into the mathematical underpinnings and formal proofs supporting the proposed method. It would likely demonstrate the method’s convergence properties, showing it reaches an optimal or near-optimal solution under specific conditions. Crucially, it would establish the method’s advantages over existing techniques, perhaps by proving a tighter bound on error or faster convergence rate. The analysis might also involve exploring the method’s robustness to noise or distribution shifts in the input data, providing a measure of reliability. Finally, generalization bounds and considerations of computational complexity could provide a complete theoretical picture, enabling a comparison based on both accuracy and efficiency. A rigorous theoretical foundation strengthens the overall impact and credibility of the paper’s claims.
Empirical Robustness#
An ‘Empirical Robustness’ section in a research paper would rigorously examine the reliability and generalizability of the study’s findings. This would involve exploring the model’s performance across various datasets, evaluating its sensitivity to hyperparameter choices, and assessing its robustness to different types of noise or variations in the input data. It could include ablation studies to isolate the impact of specific components, demonstrating the model’s resilience even when certain features are removed or altered. A robust empirical evaluation should also analyze how the method performs under conditions of distribution shift, where the test data differs substantially from the training data. Furthermore, a comprehensive robustness analysis might include error analysis, identifying and categorizing the types of errors made by the model, along with the identification of failure modes, where the model consistently performs poorly under specific circumstances. Finally, the section might touch upon the computational cost and scalability of the methods, providing insight into their practical applicability.
Future Alignments#
Forecasting future research directions in AI alignment necessitates considering several crucial factors. Scaling current methods like reinforcement learning from human feedback (RLHF) and direct preference optimization (DPO) to increasingly powerful language models (LLMs) is paramount, but scalability challenges remain. Addressing the limitations of current techniques, such as calibration issues in DPO and the instability of RLHF, requires further investigation. Exploring alternative alignment strategies, potentially beyond reward-based methods, may yield more robust solutions. Formal verification of aligned LLMs will become increasingly crucial, yet developing effective verification methods presents significant challenges. Finally, addressing the societal implications of aligned LLMs, including fairness, bias, and misuse, should be a primary focus to ensure beneficial development.
More visual insights#
More on figures

This figure shows the training dynamics of DPO and Cal-DPO on the UltraFeedback dataset using the Zephyr-7b-sft model. It illustrates that DPO’s rewards for chosen responses decrease below zero, whereas Cal-DPO’s chosen rewards remain positive and increase. The margins (difference between chosen and rejected rewards) also increase substantially in Cal-DPO. The results highlight Cal-DPO’s improved performance on various reasoning benchmarks over DPO.
This figure shows a comparison of the training dynamics of DPO and Cal-DPO on the UltraFeedback dataset using the Zephyr-7b-sft model. It highlights how Cal-DPO maintains positive rewards for chosen responses, unlike DPO which shows decreasing rewards, even falling below zero. This difference demonstrates Cal-DPO’s improved performance, particularly in reasoning tasks, which is further elaborated in section 5.
This figure shows the training dynamics of both DPO and Cal-DPO on the UltraFeedback dataset using the Zephyr-7b-sft base model. It demonstrates that while DPO’s rewards for chosen responses decrease below zero, Cal-DPO’s rewards remain positive and continue to increase. This difference in reward dynamics contributes to Cal-DPO’s superior performance across reasoning benchmarks.

This figure displays the training dynamics of DPO and Cal-DPO on the UltraFeedback dataset using the Zephyr-7b-sft model. It shows that while both methods increase the margin between chosen and rejected responses, DPO’s rewards for chosen responses fall below zero, whereas Cal-DPO keeps them positive. Cal-DPO demonstrates superior performance across various reasoning benchmarks, highlighting the effectiveness of reward calibration.

The figure shows the implicit reward dynamics during training of DPO and Cal-DPO. It reveals that DPO’s rewards for chosen responses decrease below zero while Cal-DPO’s rewards remain positive and increase. Cal-DPO significantly outperforms DPO across reasoning benchmarks, demonstrating the effectiveness of reward calibration.
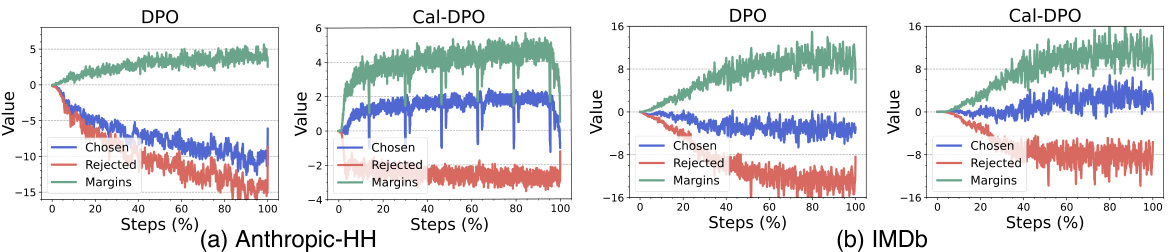
This figure shows the reward dynamics during the training process of DPO and Cal-DPO algorithms. The results show that while DPO’s rewards for chosen responses decrease below zero, Cal-DPO keeps increasing and remains positive. This difference highlights the effectiveness of Cal-DPO in maintaining positive rewards for correct responses which ultimately improves its performance. The figure also demonstrates Cal-DPO’s superior performance across reasoning benchmarks compared to DPO.
More on tables

This table compares the performance of Cal-DPO against other methods (DPO, f-DPO, SLIC, IPO, CPO) on the UltraFeedback Binarized dataset across eight reasoning benchmarks. The results are reported as scores from the Open LLM Leaderboards using the Language Model Evaluation Harness. The base model used is zephyr-7b-sft-full, and the same chat templates were used for all methods.
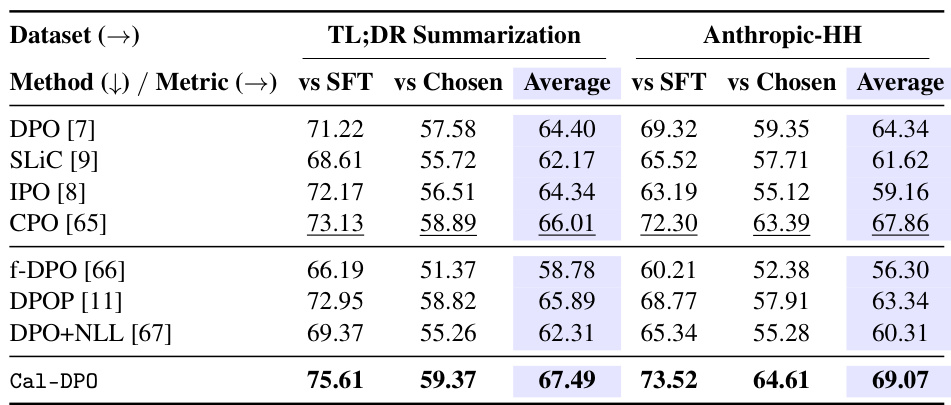
This table compares the performance of Cal-DPO against other methods (DPO, f-DPO, SLIC, IPO, CPO) on the UltraFeedback Binarized dataset across multiple reasoning benchmarks. The benchmarks include MMLU-PRO, IFEval, BBH, GPQA, MATH, and GSM8K. The results show Cal-DPO’s performance relative to various baselines, demonstrating its effectiveness in improving upon existing preference optimization methods for LLM alignment.

This table presents a comparison of the performance of Cal-DPO against other preference optimization methods on the UltraFeedback Binarized dataset. The results are shown across multiple reasoning benchmarks, using the zephyr-7b-sft-full model and the chat templates from the alignment-handbook. The benchmarks assess performance on various reasoning tasks. The table allows for a comparison of Cal-DPO’s effectiveness relative to existing approaches.

This table compares the performance of Cal-DPO against other methods (DPO, f-DPO, SLIC, IPO, CPO) on the UltraFeedback Binarized dataset across several reasoning benchmarks. The performance is measured using the Language Model Evaluation Harness (v0.4.0) and reported for various benchmarks including MMLU-PRO, IFEval, BBH, GPQA, MATH, and GSM8K. The base model used is zephyr-7b-sft-full, and the same chat templates from the alignment handbook were employed for all methods.

This table compares the performance of Cal-DPO against other preference optimization methods (DPO, f-DPO, SLIC, IPO, CPO) on the UltraFeedback Binarized dataset across multiple reasoning benchmarks. It shows the scores achieved on benchmarks like MMLU-PRO, IFEval, BBH, GPQA, MATH, GSM8K, and ARC, demonstrating the improvement of Cal-DPO over existing methods.

This table presents a comparison of the performance of Cal-DPO against other methods on the UltraFeedback Binarized dataset across various reasoning benchmarks. The results are obtained using the zephyr-7b-sft-full model and standardized chat templates. The benchmarks used are MMLU-PRO, IFEval, BBH, GPQA, MATH, GSM8K, and ARC. The table shows the scores achieved by each method on each benchmark, allowing for a direct comparison of their relative performance.

This table presents a comparison of the performance of Cal-DPO against other methods on the UltraFeedback Binarized dataset across multiple reasoning benchmarks. It shows the scores achieved by different methods (DPO, f-DPO, SLIC, IPO, CPO, Cal-DPO) on benchmarks like MMLU-PRO, IFEval, BBH, GPQA, MATH, GSM8K, and ARC. The scores reflect the effectiveness of each method in aligning a language model with human preferences on various reasoning tasks. The base model used is zephyr-7b-sft-full, ensuring consistency with prior research.

This table compares the performance of Cal-DPO against other preference optimization methods on the UltraFeedback Binarized dataset across several reasoning benchmarks. It shows the scores achieved by different methods on various benchmarks, highlighting Cal-DPO’s improved performance compared to baselines such as DPO, f-DPO, SLIC, IPO, and CPO.

This table compares the performance of Cal-DPO against other preference optimization methods across various reasoning benchmarks. The benchmarks used are MMLU-PRO, IFEval, BBH, GPQA, MATH, GSM8K, and ARC. The base model used is zephyr-7b-sft-full, and the same chat templates were used for all methods to ensure a fair comparison. The table shows the scores achieved by each method on each benchmark, allowing for a direct comparison of their relative performance in different reasoning tasks.

This table presents a comparison of the performance of Cal-DPO against other preference optimization methods (DPO, f-DPO, SLIC, IPO, CPO) on the UltraFeedback Binarized dataset across several reasoning benchmarks. The benchmarks used are MMLU-PRO, IFEval, BBH, GPQA, MATH, GSM8K, and ARC. The table shows the scores achieved by each method on each benchmark, allowing for a direct comparison of their performance.
Full paper#



















