↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Radar semantic segmentation (RSS) plays a crucial role in various applications, but existing methods often struggle to effectively use temporal information present in radar data. This leads to less accurate and robust scene understanding, hindering progress in autonomous driving and other relevant fields. The temporal information, a key clue for analyzing radar data, is often underutilized in current RSS frameworks.
To overcome this limitation, the researchers introduce TARSS-Net, a novel RSS network that incorporates a Temporal Relation-Aware Module (TRAM). TRAM cleverly learns relationships between radar scans over time, improving the network’s ability to capture temporal dynamics. Their experiments on publicly available datasets showcase that TARSS-Net significantly outperforms existing methods in terms of accuracy and efficiency. This new approach sets a standard for future RSS research, potentially revolutionizing autonomous driving and related technologies.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the limitations of current radar semantic segmentation (RSS) methods by effectively incorporating temporal information. This is crucial for improving the accuracy and robustness of autonomous driving, UAV surveillance, and other applications that rely on radar data. The proposed Temporal Relation-Aware Module (TRAM) offers a flexible and efficient way to learn and aggregate temporal information, opening new avenues for research in radar signal processing and deep learning. The use of real-measured datasets also strengthens the paper’s impact, providing practical relevance to real-world applications.
Visual Insights#

This figure illustrates three different temporal modeling paradigms: (a) Causal temporal relation modeling, which includes Hidden Markov Models (HMMs) and Recurrent Neural Networks (RNNs); (b) Parallelized sequence representation modeling, which includes Convolutional Neural Networks (CNNs) and Transformers; and (c) the proposed Target-History Relation Modeling (TRAM) paradigm. HMMs model temporal dependencies probabilistically using hidden states. RNNs use learnable vectorized dependencies between hidden states. Convolution uses local contextual learning, while self-attention models dense pair-wise relations. The TRAM paradigm focuses on data-driven aggregation of temporal information with learned target-history relations, addressing limitations of previous methods.
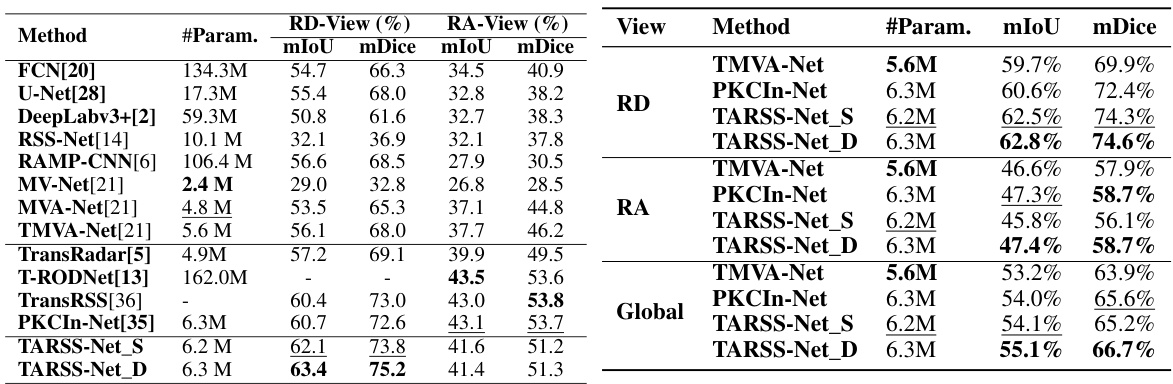
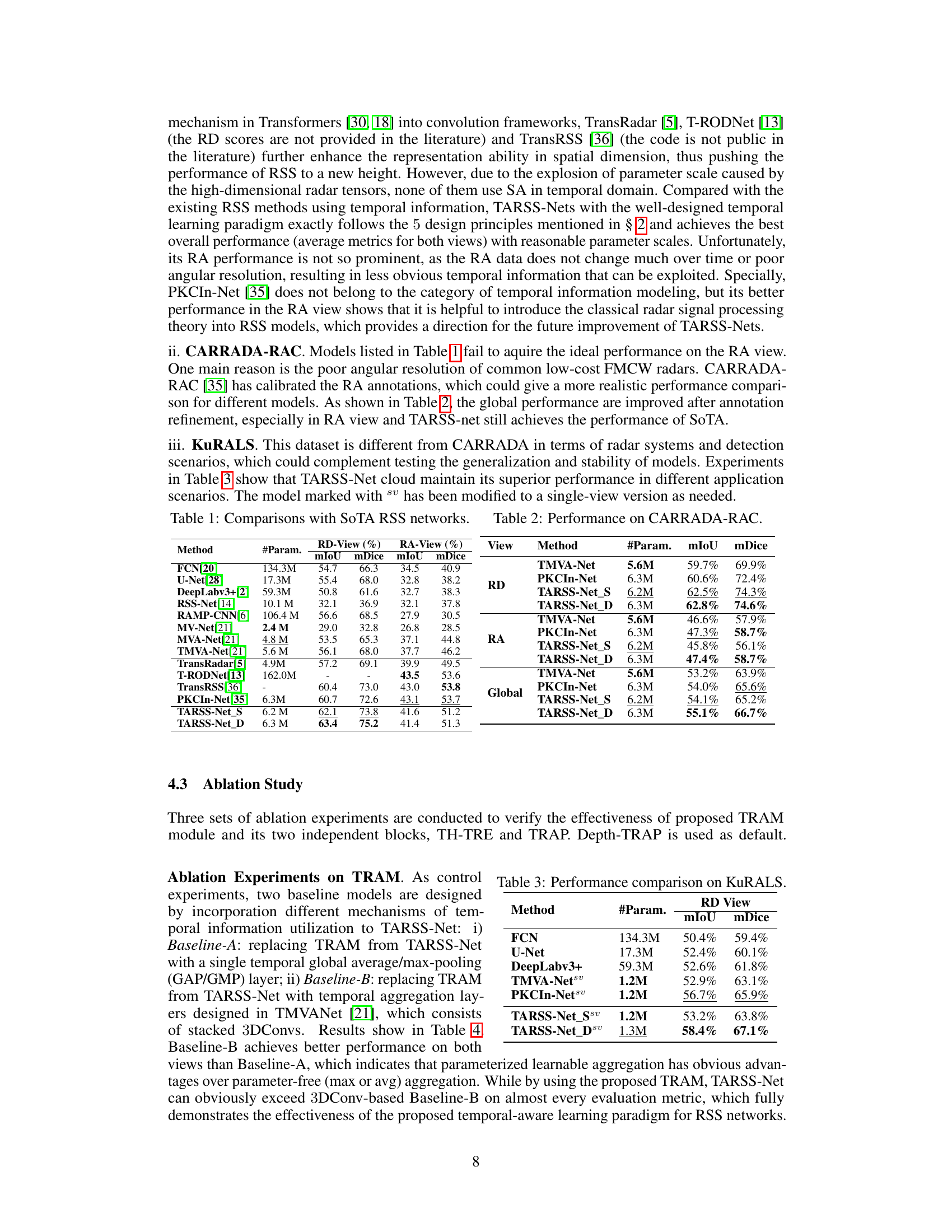
This table presents a comparison of the performance of the proposed TARSS-Net model with other state-of-the-art (SoTA) radar semantic segmentation (RSS) networks on the CARRADA dataset. The comparison includes metrics such as mean Intersection over Union (mIoU) and mean Dice coefficient (mDice) for both range-Doppler (RD) and range-angle (RA) views, as well as a global average. The number of parameters (#Param.) for each model is also provided, giving an indication of model complexity.
In-depth insights#
Temporal Modeling#
The paper delves into temporal modeling for radar semantic segmentation (RSS), highlighting the underutilization of temporal information in existing RSS frameworks. It introduces a novel paradigm: data-driven temporal information aggregation with learned target-history relations. This approach contrasts with traditional methods like HMMs and RNNs which rely on causal relationships, and parallelized methods like 3D convolutions which lack long-term dependency modeling. The core contribution is the Temporal Relation-Aware Module (TRAM), which effectively encodes target-history temporal relations and aggregates temporal information via attentive pooling. The design principles emphasize parameter efficiency, parallel processing, and robustness to noisy radar data. The effectiveness of TRAM is demonstrated through experiments showcasing state-of-the-art performance, underscoring the importance of integrating temporal context in RSS for enhanced accuracy and efficiency.
TRAM Module Design#
The core of the proposed approach lies in the Temporal Relation-Aware Module (TRAM), a flexible and efficient learning module designed to capture and aggregate temporal information in radar data. TRAM cleverly addresses the limitations of existing methods by focusing on data-driven temporal information aggregation with learned target-history relations. This innovative paradigm is realized through two key components: the Target-History Temporal Relation Encoder (TH-TRE), which captures temporal relations between the target frame and its history using a novel temporal relation-inception convolution (TRIC), and the Temporal Relation-Aware Pooling (TRAP), which leverages a learnable mechanism to aggregate the temporal information effectively. TH-TRE’s efficiency stems from its parallel processing capability and shared weights, while TRAP ensures robustness by considering the contribution of each historical frame differentially and allowing for flexibility in input time lengths. This design prioritizes computational efficiency and scalability, making it particularly well-suited for high-dimensional radar data while preserving temporal context crucial for accurate semantic segmentation.
Real-time Performance#
The real-time performance analysis of the TARSS-Net model reveals a crucial trade-off between accuracy and speed. While achieving state-of-the-art accuracy on the challenging CARRADA dataset, the model’s computational demands are significantly higher than simpler methods like TMVA-Net. The introduction of the Transformer-based architecture, though improving accuracy, significantly impacts the processing time, underscoring the need for careful consideration when deploying such models in resource-constrained environments. The analysis highlights the impact of model size on inference speed; therefore, optimizations are crucial to bring the model closer to real-time applicability. Despite not reaching the speeds of simpler models, TARSS-Net demonstrates sufficient real-time capability (23 FPS) for many applications, suggesting that the balance between accuracy and speed is manageable with careful consideration of the computational requirements and available resources. Future work should focus on further optimization to improve inference efficiency without sacrificing accuracy.
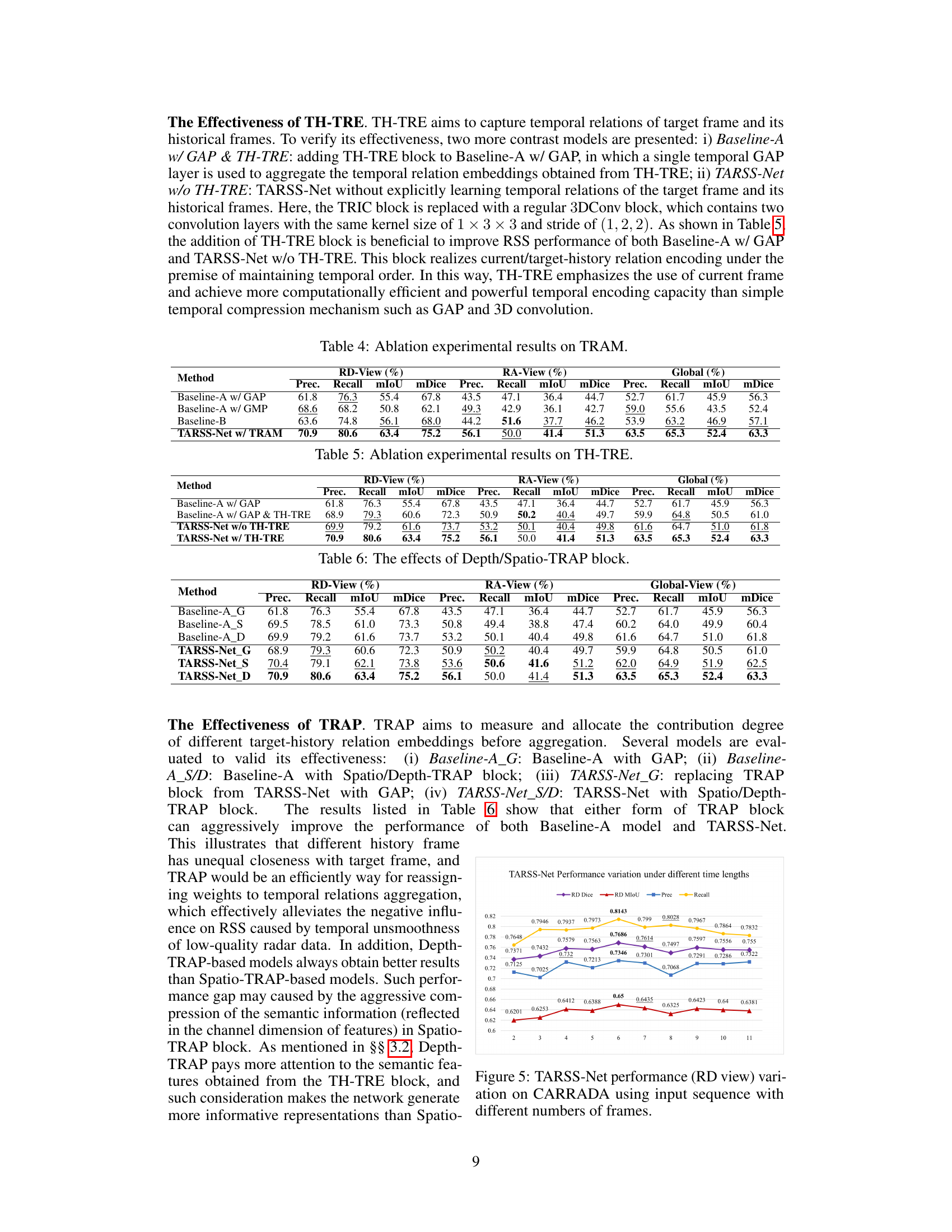
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a machine learning model. In the context of a radar semantic segmentation model, such a study might involve removing or altering parts of the network (e.g., the temporal relation-aware module, specific layers, or attention mechanisms) and measuring the impact on performance metrics like mIoU and mDice. The goal is to isolate the effects of each component and demonstrate its necessity or value. A well-designed ablation study helps justify design choices, identify critical elements, and provides a deeper understanding of the model’s behavior. By comparing the performance of the full model against its ablated versions, the authors can quantify the contribution of each module. This is crucial in assessing the model’s effectiveness and potential for improvement. It also helps highlight unexpected interactions between components, which may require further investigation or adjustments in the model’s architecture. The results of this experiment usually inform design choices, architecture improvements, and enhance our understanding of which components are most impactful.
Future Work#
Future research directions stemming from this radar semantic segmentation work could explore several promising avenues. Improving the performance of Spatio-TRAP is crucial, possibly by incorporating more semantic information to enhance its discriminative ability. The integration of advanced temporal modeling techniques, such as those found in Transformers, should be investigated to further enhance the handling of temporal dependencies in radar data. Addressing the challenges of limited angular resolution in radar data is also important, as this can impact segmentation accuracy. This might involve exploring data augmentation techniques or developing novel network architectures specifically designed for low-resolution radar inputs. Finally, the work could be extended to incorporate more diverse and challenging real-world datasets, pushing the boundaries of model generalizability and robustness. Addressing the computational limitations of the current model to enable real-time applications in resource-constrained scenarios, like autonomous driving, would be another beneficial pursuit. Investigating energy-efficient architectures and techniques is key to achieving this goal.
More visual insights#
More on figures
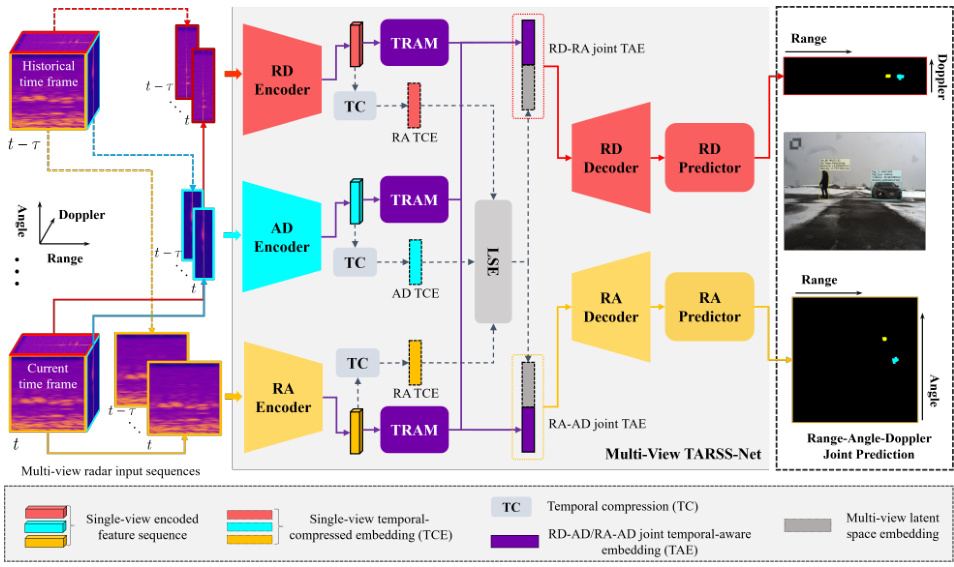
This figure shows the architecture of the proposed multi-view TARSS-Net. It illustrates the flow of data through the network, starting with multi-view radar input sequences (RD, AD, RA). Each view is processed by an encoder, a temporal relation-aware module (TRAM), and a temporal compression (TC) module. The resulting single-view temporal-compressed embeddings are then fused in a latent space encoder (LSE) before being passed to the decoders that generate segmentation results for the RD and RA views. The figure also includes example segmentation outputs for the radar data alongside corresponding camera images for visual comparison and intuitive understanding.
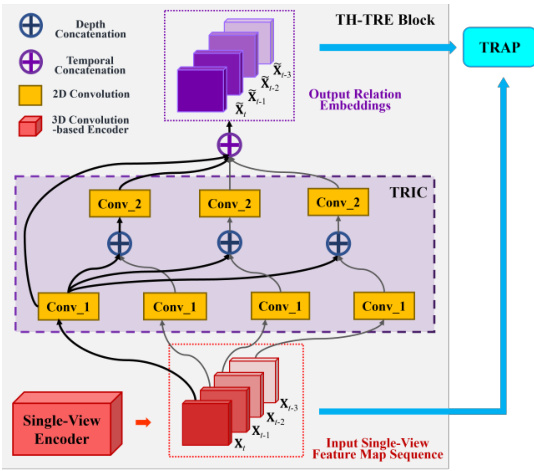
This figure shows the architecture of the Target-History Temporal Relation Encoding (TH-TRE) block, a key component of the Temporal Relation-Aware Module (TRAM). The TH-TRE block takes as input a sequence of feature maps representing the current frame and its adjacent historical frames. It uses a Temporal Relation Inception Convolution (TRIC) block to capture the relationships between these frames. The TRIC block employs two convolutional layers (Conv_1 and Conv_2), which are shared across time to ensure efficiency. The output of the TH-TRE block is a set of relation embeddings that capture the temporal relationships between the current frame and its history.

This figure provides a visual comparison of different temporal modeling paradigms used in time series analysis. It showcases three main approaches: (a1) Hidden Markov Models (HMMs), which utilize hidden states and probabilistic transitions to model temporal dependencies; (a2) Recurrent Neural Networks (RNNs), which use a continuous vector representation of hidden states and learnable connections to model dependencies; (b1) Convolutional methods, which focus on local contextual learning; (b2) Self-attention mechanisms, which create dense pair-wise relations between sequence elements; and (c) the proposed Target-History Relation-Aware Module (TRAM), which captures target-history temporal relations and utilizes data-driven temporal information aggregation with learned relations. The figure visually compares these methods using graphs to represent the flow of information and dependencies.

This figure illustrates the core idea and implementation details of the Temporal Relation Aware Module (TRAM). The left part shows the basic learning paradigm, which involves capturing target-history relations and aggregating the whole sequence using weighted relations to enhance the target frame representation and prediction. The right side details the TRAM implementation, highlighting the Target-History Temporal Relation Encoder (TH-TRE) blocks, the Temporal Relation Importance Measurement (attention mechanism), and the Relation Aggregation (weighted summation and skip connection).

This figure illustrates the architecture of the multi-view TARSS-Net, a deep learning model for radar semantic segmentation. It shows how the model processes radar data from multiple views (Range-Doppler (RD), Angle-Doppler (AD), and Range-Angle (RA)) to generate segmentation maps. The figure highlights the key components of the model: basic encoders for each view, the temporal relation-aware module (TRAM) for incorporating temporal information, the latent space encoder (LSE) for fusing information across views, and decoders for generating the final segmentation predictions in RD and RA views. The inclusion of camera images helps to contextualize and visually validate the radar-based segmentation results.
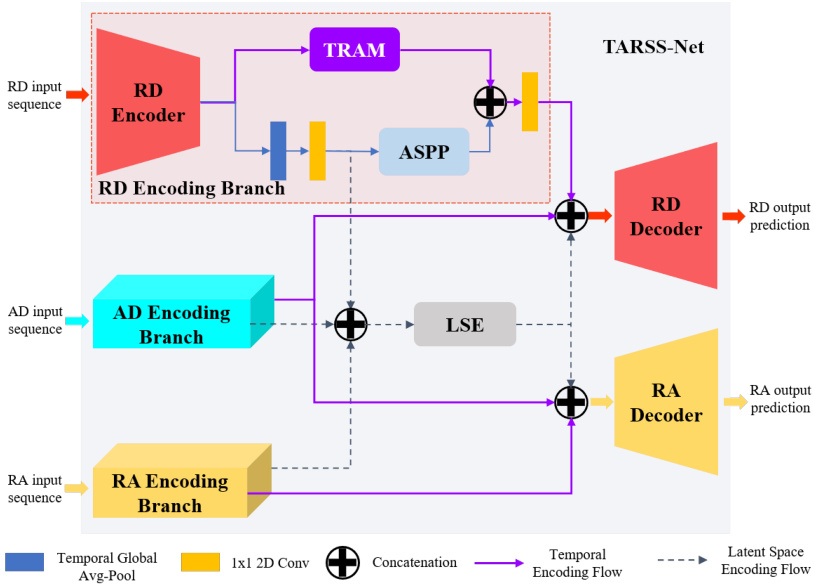
This figure presents a detailed illustration of the TARSS-Net architecture, focusing on the RD-view encoding branch as an example. It shows the flow of data through the different components: Three separate encoding branches (RD, AD, and RA) process input radar sequences. Each branch utilizes an encoder, a Temporal Relation Aware Module (TRAM), and an atrous spatial pyramid pooling (ASPP) module. The outputs of these branches are then combined using a Latent Space Encoder (LSE). Finally, the combined features are passed to RD and RA decoders to generate the output segmentation predictions.

This figure shows an improved implementation of the TRIC (temporal-relation-inception convolution) block, a key component of the TH-TRE (Target-History Temporal Relation Encoding) module within the TARSS-Net architecture. The original TRIC implementation used a sequential approach, processing target-history feature pairs one at a time. This modified version leverages temporal cross-reorganization of target-history feature pairs and employs a 3D convolution with 2x3x3 kernels and a temporal stride of 2. This parallel design speeds up processing and improves efficiency compared to the original implementation while maintaining the same parameter scale.

This figure compares the class-wise performances (IoU and Dice scores) of different methods including TARSS-Net_D, TARSS-Net_S, TMVA-Net, RAMP-CNN, and RSS-Net for both RD and RA views. The results show the performance differences between the models for different object classes (global, background, vehicle, cyclist, pedestrian).
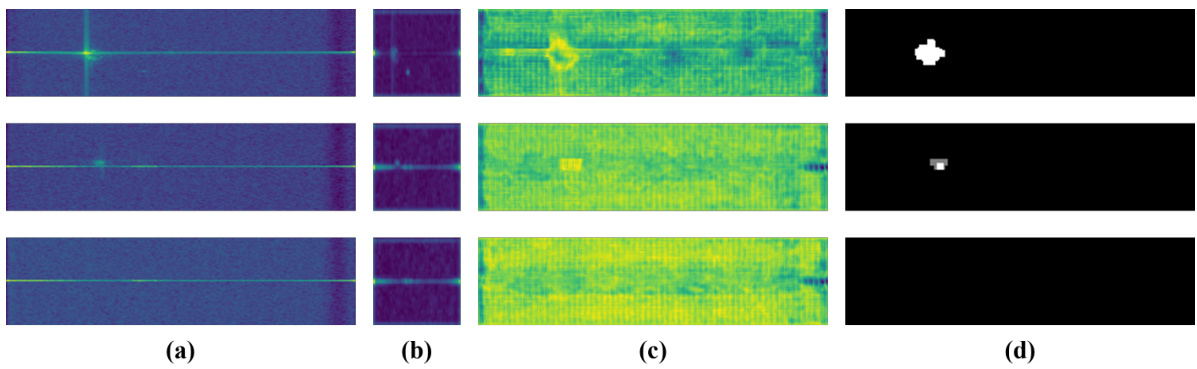
This figure visualizes the feature maps at different stages of the TARSS-Net model for a single RD-view frame. (a) shows the input RD-view frame. (b) shows the activation response heatmaps of the TRAM outputs, highlighting which parts of the input the model is focusing on. (c) shows the TARSS-Net outputs before the softmax activation, representing the model’s raw predictions. (d) shows the ground truth mask for comparison.

This figure visualizes some examples of the semantic segmentation results obtained by the proposed TARSS-Net. For each scenario (pedestrian & vehicle, pedestrian only, and bicycle), the figure shows (a) synchronized camera images, (b) annotated radar RD representation, and (c) RD predictions by TARSS-Net. The visualization helps to illustrate the model’s performance on different objects and weather conditions.
More on tables
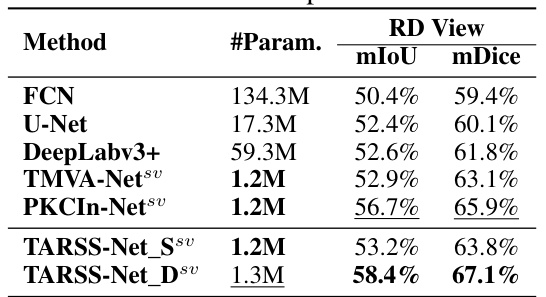
This table presents a comparison of the performance of several models on the KuRALS dataset. The models are evaluated using mIoU and mDice metrics for the RD and RA views, as well as a global average. The table shows that TARSS-Net_D achieves the best overall performance, outperforming other methods in both views and globally.

This table presents the ablation study results focusing on the effectiveness of the TRAM module. It compares the performance of TARSS-Net with different temporal modeling methods, including using global average pooling (GAP), global max pooling (GMP), and a temporal aggregation layer from TMVA-Net, against the proposed TRAM. The results are presented in terms of precision, recall, mIoU, and mDice for the RD-view, RA-view, and global view.

This table presents the ablation study results focusing on the TH-TRE (Target-History Temporal Relation Encoding) block within the TARSS-Net architecture. It compares the performance of several model variations: Baseline-A with GAP (global average pooling), Baseline-A with GAP and TH-TRE, TARSS-Net without TH-TRE, and TARSS-Net with TH-TRE. The comparison is made across metrics for RD (Range-Doppler) view, RA (Range-Angle) view and a global average. This allows assessment of the impact of the TH-TRE module on the overall performance of the radar semantic segmentation.

This table presents the ablation study results on the Temporal Relation-Aware Module (TRAM). It compares the performance of different model variations: a baseline using global average pooling (GAP), a baseline using global max pooling (GMP), a baseline using the temporal aggregation layers from TMVA-Net, and the full TARSS-Net model with TRAM. The results are shown in terms of precision, recall, mean Intersection over Union (mIoU), and mean Dice coefficient (mDice) for the RD view, RA view, and globally.

This table compares the real-time performance of several temporal relationship learning models, including TMVA-Net, Vit-based-Net, TARSS-Net_S, and TARSS-Net_D, in both multi-view and single-view settings. The metrics presented are the number of parameters (Params), multiply-accumulate operations (MACs), frames per second (FPS), mean Intersection over Union (mIoU), and mean Dice coefficient (mDice). It highlights the trade-off between model complexity, speed, and accuracy for different approaches to temporal modeling in radar semantic segmentation.
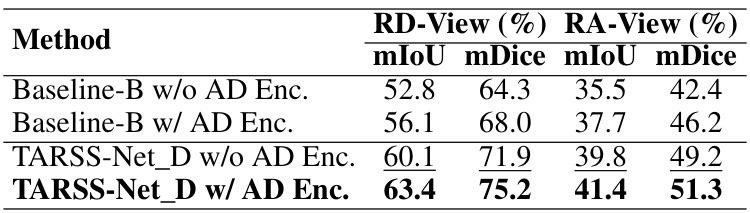
This table presents the ablation study results on the impact of adding the AD encoding branch to the model. It compares the performance (mIoU and mDice scores) of two models, Baseline-B and TARSS-Net_D, both with and without the AD encoding branch, on the RD and RA views. The results show that incorporating the AD view consistently improves the performance of both models, demonstrating the benefits of utilizing multi-view information.
Full paper#