TL;DR#
Large Language Models (LLMs) are powerful but computationally expensive. Contextual Sparsity (CS) is a promising technique to improve efficiency but significantly reduces accuracy for complex tasks. This limitation arises because sparse models often fail in the middle of their reasoning process, requiring only a few token corrections to recover full performance.
The paper introduces SIRIUS, a novel correction mechanism designed to efficiently fix these errors. SIRIUS uses a full LLM for infrequent corrections, carefully balancing computational cost and accuracy. Results show that SIRIUS boosts CS model performance on various complex tasks with consistent efficiency gains, demonstrating a significant latency reduction.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical issue of inference efficiency in large language models (LLMs), a major bottleneck hindering their wider adoption. By introducing a novel correction mechanism, SIRIUS, the research opens new avenues for efficient LLM deployment and application, particularly in latency-sensitive settings. Its open-source nature further accelerates progress in the field.
Visual Insights#

🔼 This figure shows the limitations of contextual sparsity in complex reasoning tasks. Panel (a) compares the performance of a contextual sparsity model on tasks requiring prompt understanding (CNN/DailyMail) versus those requiring reasoning (GSM8K), revealing significantly worse performance on the latter. Panel (b) illustrates that applying contextual sparsity to a larger model (Llama-3-70B-Instruct) leads to model crashes at higher sparsity levels, highlighting the inefficiency of this approach for complex tasks. Finally, panel (c) suggests that sparse model failures are not random; by correcting a small percentage (11%) of tokens, the model’s performance can be restored to that of the full model. This observation motivates the development of a correction mechanism.
read the caption
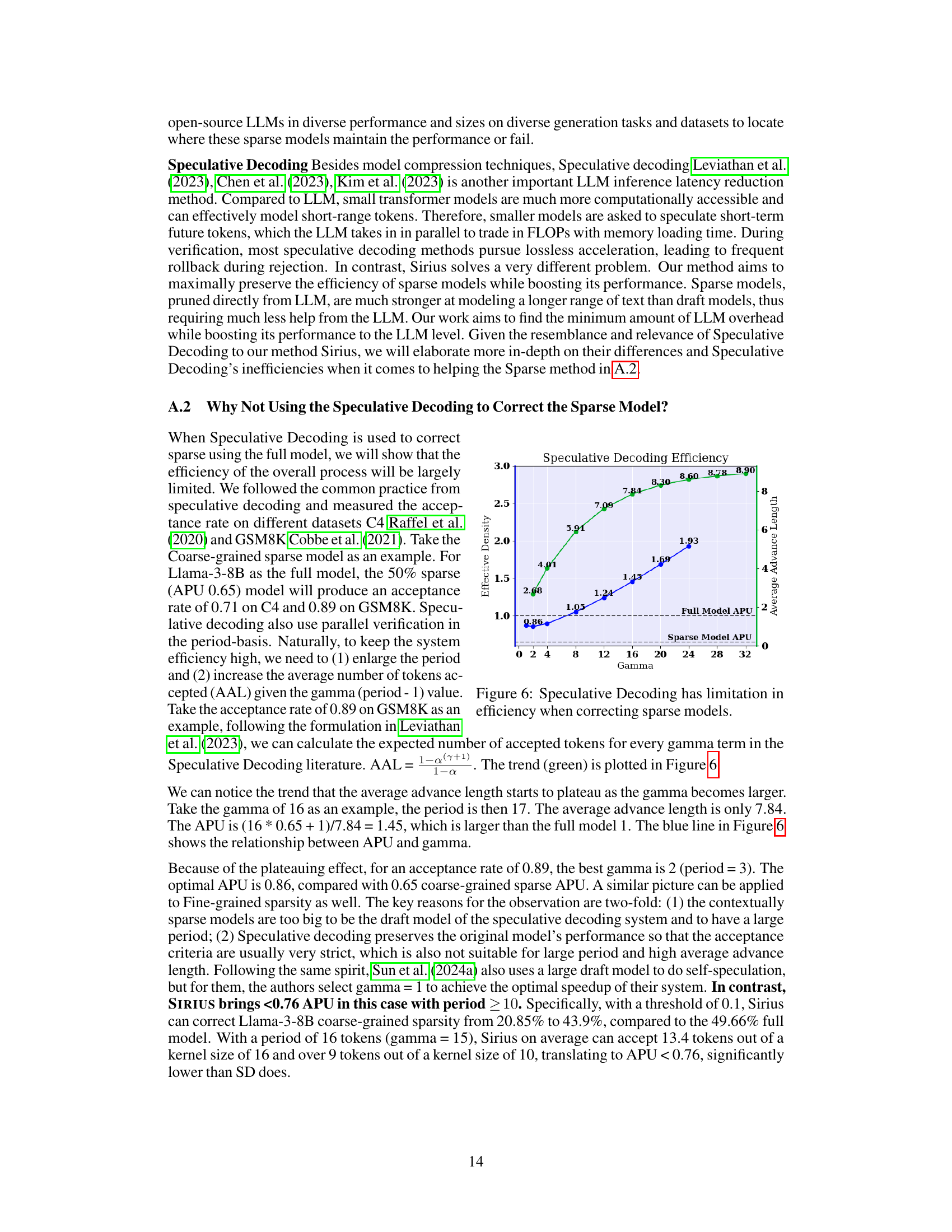
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g. GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.
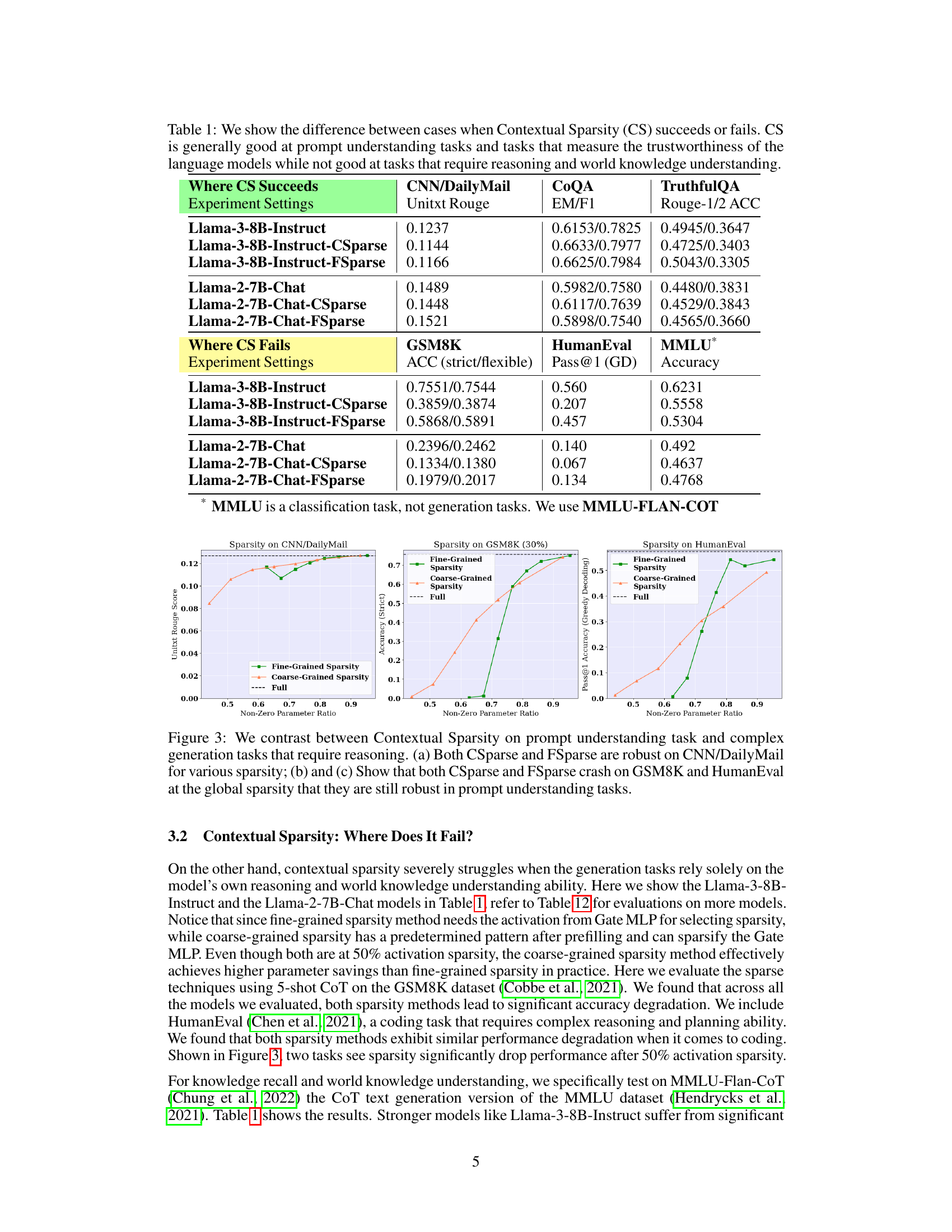
🔼 This table shows the performance of contextual sparsity (CS) methods on various tasks. It highlights that CS methods are effective for tasks involving prompt understanding, such as summarization and question answering, but perform poorly on tasks requiring reasoning and knowledge, such as arithmetic reasoning and code generation. The table compares the performance of full models and CS-sparse models on several benchmark datasets, including CNN/DailyMail, COQA, TruthfulQA, GSM8K, HumanEval, and MMLU.
read the caption
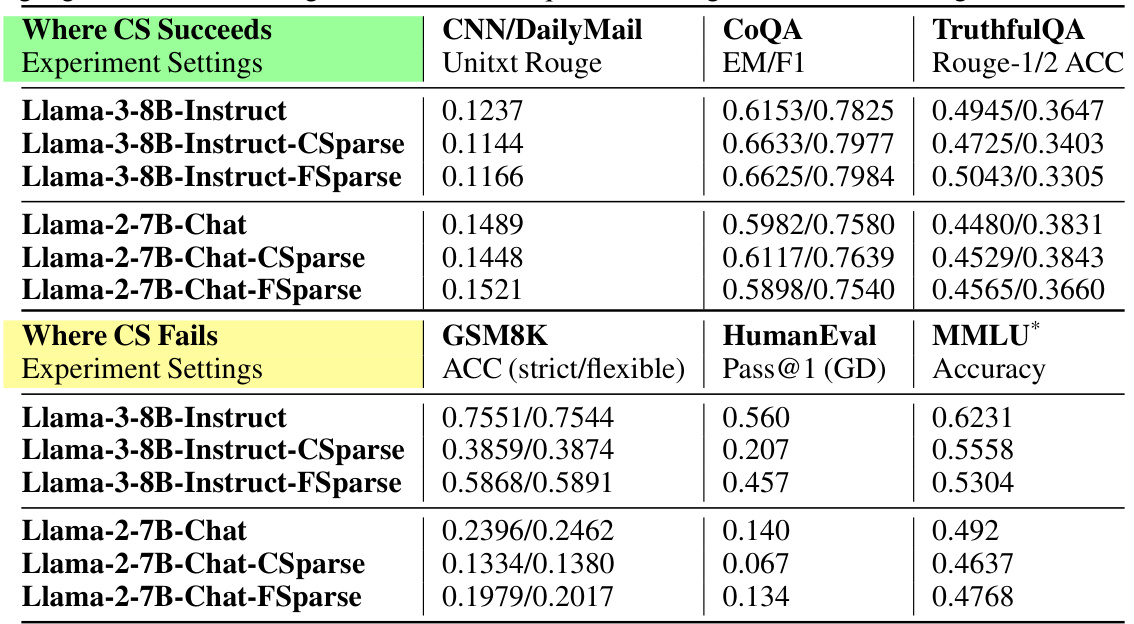
Table 1: We show the difference between cases when Contextual Sparsity (CS) succeeds or fails. CS is generally good at prompt understanding tasks and tasks that measure the trustworthiness of the language models while not good at tasks that require reasoning and world knowledge understanding.
In-depth insights#
Contextual Sparsity#
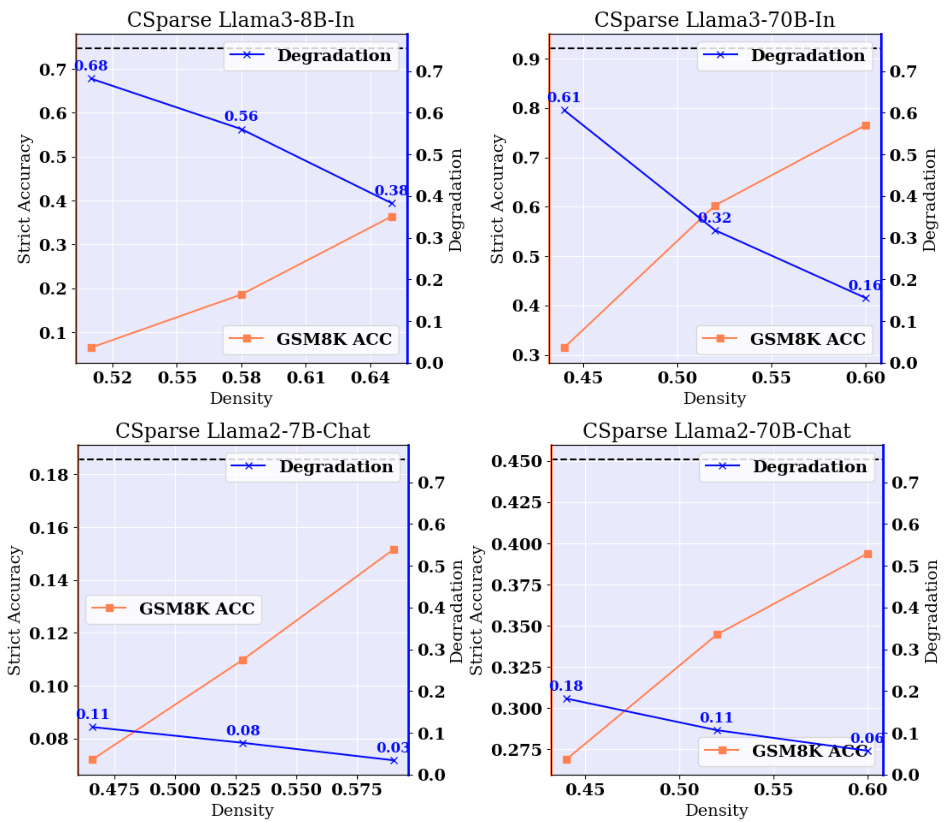
Contextual sparsity, a method for enhancing Large Language Model (LLM) efficiency, selectively removes less-important parameters based on the context. Its training-free nature and high compression ratio are appealing. However, the paper reveals a significant limitation: while effective for prompt-understanding tasks, contextual sparsity considerably degrades performance on complex reasoning and knowledge-based tasks. This suggests a need for techniques beyond simple parameter removal, potentially through correction mechanisms that address the specific failures introduced by sparsity, which is a key focus of the research paper. The effectiveness of contextual sparsity depends on task type and model architecture, highlighting the need for careful evaluation and task-specific approaches.
SIRIUS Correction#
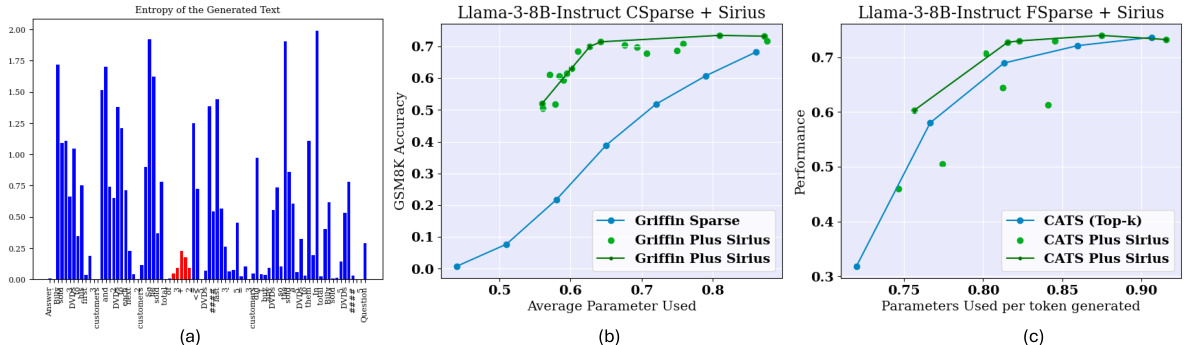
The SIRIUS correction method tackles the performance degradation in Contextual Sparsity (CS) LLMs, particularly on complex reasoning tasks. SIRIUS identifies that sparse models often share the same problem-solving logic as their full-model counterparts, differing only in a few key tokens. It cleverly leverages this insight, employing a correction mechanism that only intervenes when necessary. By strategically identifying and correcting these crucial tokens using infrequent calls to the full model, SIRIUS significantly improves accuracy on reasoning tasks while maintaining CS’s efficiency gains. The method focuses on cost-effective correction, utilizing techniques such as KV Cache direct rewriting and minimal rollbacks to minimize latency and maximize the effective period of full-model correction. The approach is evaluated on various models and datasets, demonstrating consistent improvements across multiple reasoning tasks. The system’s implementation offers demonstrable latency reduction, highlighting SIRIUS’s potential to enhance the practicality of CS LLMs in latency-sensitive settings.
Reasoning Failure#
Large language models (LLMs), despite advancements, exhibit weaknesses in complex reasoning tasks. A crucial failure mode is the inability of contextually sparse LLMs to perform well on tasks requiring high-level reasoning and deduction, unlike their success in simpler tasks like classification or summarization. This performance degradation isn’t merely a minor accuracy drop; it’s a significant failure that can lead to nonsensical outputs or incorrect conclusions. The root cause appears to lie in the way contextual sparsity methods inherently prune important elements of the model’s reasoning pathways. The paper highlights the specific challenge of these sparse models struggling with multi-step reasoning problems, as minor errors during intermediate calculations can propagate to completely wrong final answers. Addressing this failure mode is critical for creating truly effective, efficient LLMs suitable for broader deployment.
Efficiency Metrics#
In evaluating the efficiency of large language models (LLMs), carefully chosen metrics are crucial. Common metrics may include latency, which measures the time taken for inference, and throughput, indicating the number of inferences completed per unit time. However, simply focusing on raw latency or throughput can be misleading. A more comprehensive approach might incorporate effective parameter usage, considering only the activated parameters during inference. This accounts for sparsity techniques, making comparisons between models with different sparsity levels more accurate. Furthermore, accuracy must be a primary concern. The goal isn’t merely efficiency but efficient performance, meaning improved speed without compromising accuracy. Therefore, a balanced approach needs to consider the trade-off between speed and accuracy and could also include metrics like energy consumption and memory footprint for a more holistic assessment of LLM efficiency.
Future Work#
The authors acknowledge that SIRIUS, while effective, still relies on rollbacks for corrections, which is inherently inefficient. Future work should explore alternative correction mechanisms that are more efficient, perhaps by leveraging model self-awareness or developing novel methods that avoid incorrect token generation altogether. Improving the synergy between sparse and full models is also crucial, aiming for systems that achieve strong performance while maintaining the efficiency of sparse models without strictly mimicking full model output distributions. Finally, thorough investigation into the optimal balance between correction efficiency and accuracy across various datasets and model sizes is necessary to enhance SIRIUS’s practical applicability and broaden its impact in real-world applications.
More visual insights#
More on figures
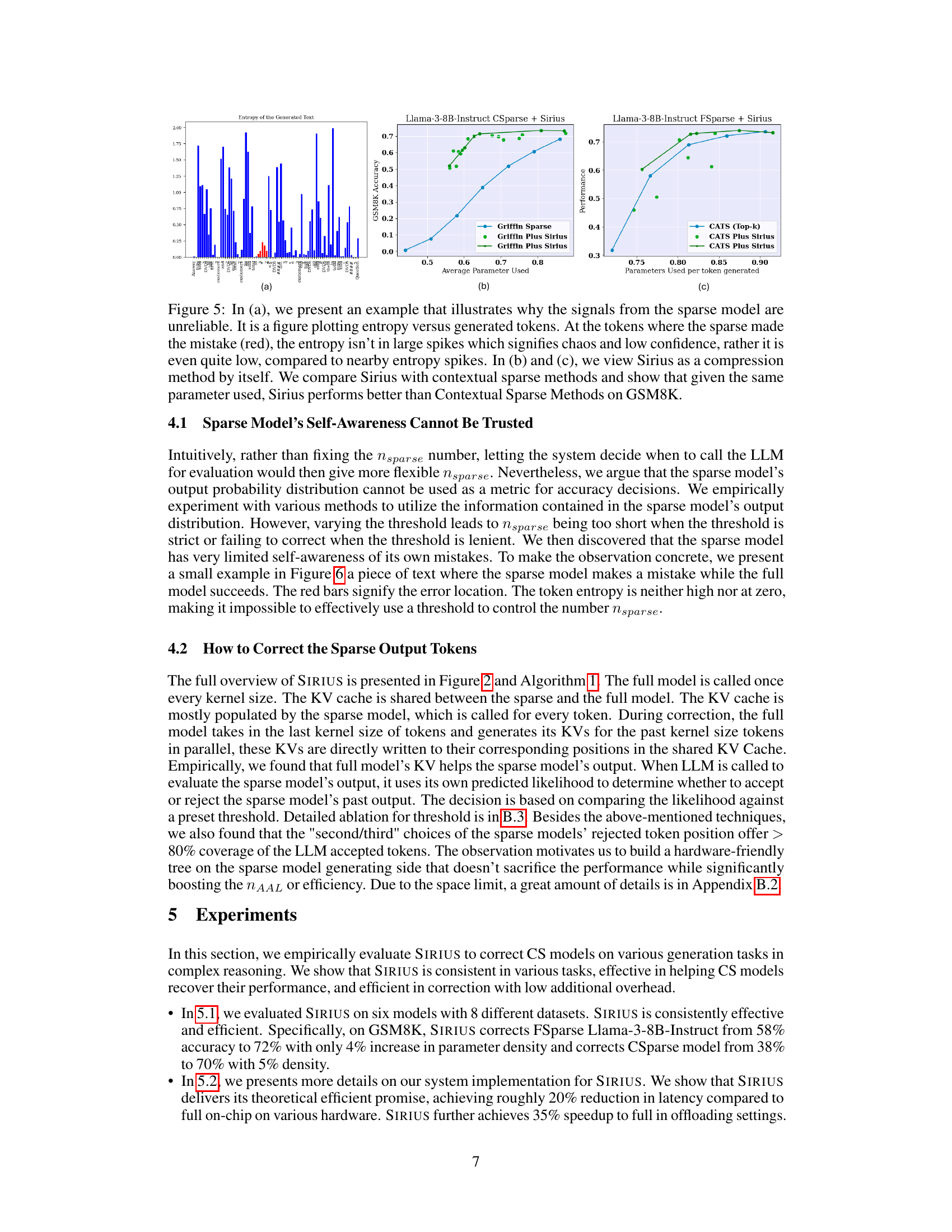
🔼 This figure illustrates the SIRIUS framework for correcting errors in contextual sparsity models. The sparse model generates text, but if errors occur, the full model is called infrequently to correct those errors. The correction process involves rewriting the key-value (KV) cache, interleaving high-quality tokens with the sparse model’s output, and rolling back corrections only if the full model deems them unlikely.
read the caption
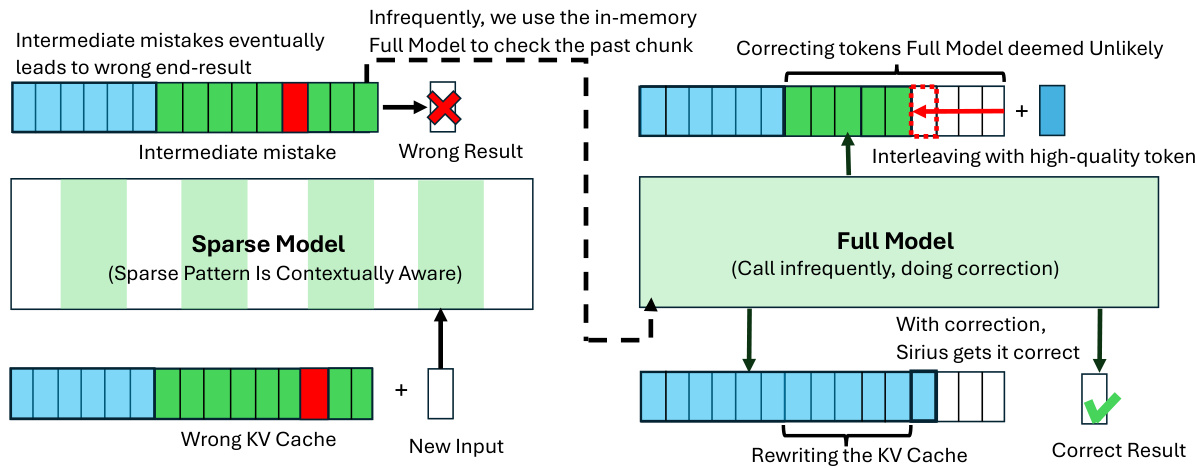
Figure 2: Overview of Sirius. Contextual Sparsity requires full model weights to be placed on the GPU memory. While the sparse model doesn't perform well on complex reasoning tasks, Sirius uses the Full Model to correct the Sparse model. The full model is called fairly infrequently. During the correction, the Full Model will rewrite the KV Cache, interleave with high-quality tokens to the sparse outputs, and then roll back only when the token is deemed extremely unlikely by the Full Model.
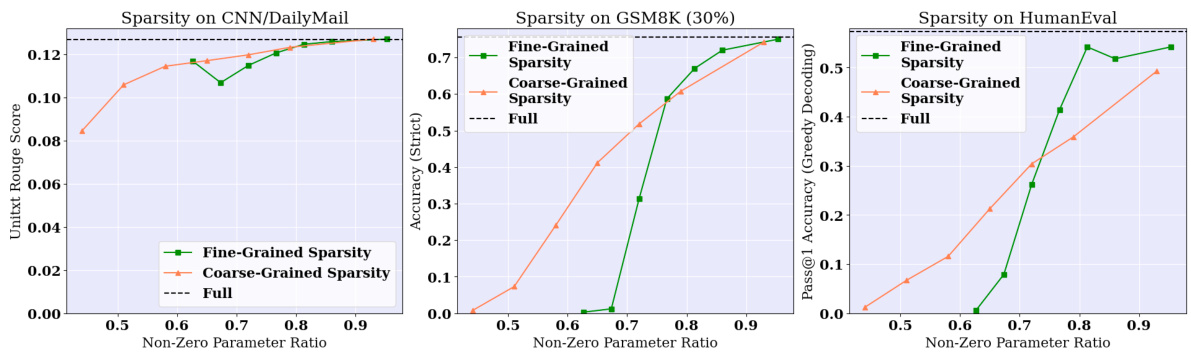
🔼 This figure compares the performance of contextual sparse models against full models on different tasks. Panel (a) shows that contextual sparsity (CS) performs worse on GSM8K (arithmetic reasoning) than on CNN DailyMail (text summarization), highlighting a weakness of CS for complex reasoning tasks. Panel (b) demonstrates that increasing the model size (from Llama-3-8B to Llama-3-70B) while applying CS does not necessarily improve performance and can lead to model crashes. Panel (c) reveals that surprisingly, correcting only a small fraction (11%) of the sparse model’s outputs can fully restore performance, suggesting a potential for efficient correction mechanisms.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g. GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.
🔼 This figure demonstrates the challenges of contextual sparsity (CS) in complex reasoning tasks. Subfigure (a) compares the performance of a contextually sparse Llama-3-8B-Instruct model on GSM8K (a challenging arithmetic reasoning benchmark) and CNN/DailyMail (a relatively easier text summarization task). Subfigure (b) shows that applying contextual sparsity to a larger model (Llama-3-70B-Instruct) leads to model failure at high sparsity levels, highlighting the inefficiency of CS for large models on demanding tasks. Finally, subfigure (c) suggests that the failures are not random; correcting a small fraction (around 11%) of tokens in the sparse model’s output is sufficient to recover its performance to that of the full model.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g., GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.

🔼 This figure demonstrates the challenges of using contextual sparsity (CS) in large language models (LLMs) for complex reasoning tasks. Subfigure (a) compares the performance of a contextually sparse model on two different tasks: text summarization (CNN/DailyMail) and arithmetic reasoning (GSM8K). The results show that CS significantly degrades performance on the reasoning task (GSM8K). Subfigure (b) shows that increasing the model size (70B vs 8B) does not alleviate this performance degradation and may even exacerbate it. Subfigure (c) illustrates that the performance of sparse models can often be recovered by correcting a relatively small percentage of tokens.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g. GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.

🔼 This figure shows the limitations of contextual sparsity (CS) in complex reasoning tasks. Subfigure (a) compares the performance of CS models on two tasks: text summarization (CNN/DailyMail) and arithmetic reasoning (GSM8K). CS models perform well on summarization but poorly on reasoning. Subfigure (b) shows that increasing the size of the model with CS does not improve the results for complex reasoning tasks. Subfigure (c) demonstrates that surprisingly few token corrections are needed to recover full performance on reasoning tasks from CS models. This illustrates the potential of using a correction mechanism to boost the performance of CS models.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g. GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.
🔼 This figure shows the limitations of contextual sparsity (CS) in complex reasoning tasks. Subfigure (a) compares the performance of a contextually sparse model on two different tasks: CNN/DailyMail (a summarization task) and GSM8K (an arithmetic reasoning task). It demonstrates that while CS performs reasonably well on the summarization task, it significantly degrades performance on the reasoning task. Subfigure (b) shows that applying CS to a larger model (Llama-3-70B-Instruct) leads to a performance crash at a 50% sparsity level, highlighting the inefficiency of CS for complex tasks when applied to large models. Finally, subfigure (c) illustrates that even with significant sparsity, surprisingly few tokens need correction to recover the original performance of the model.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g. GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.
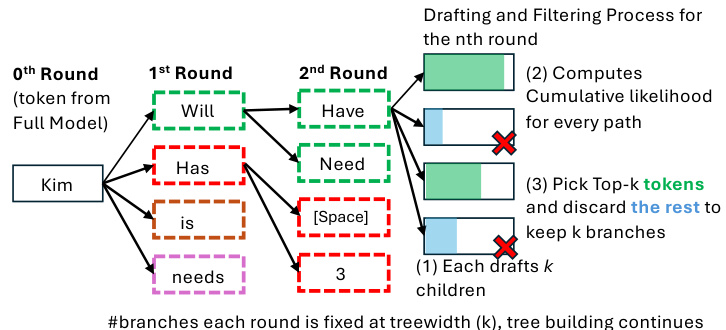
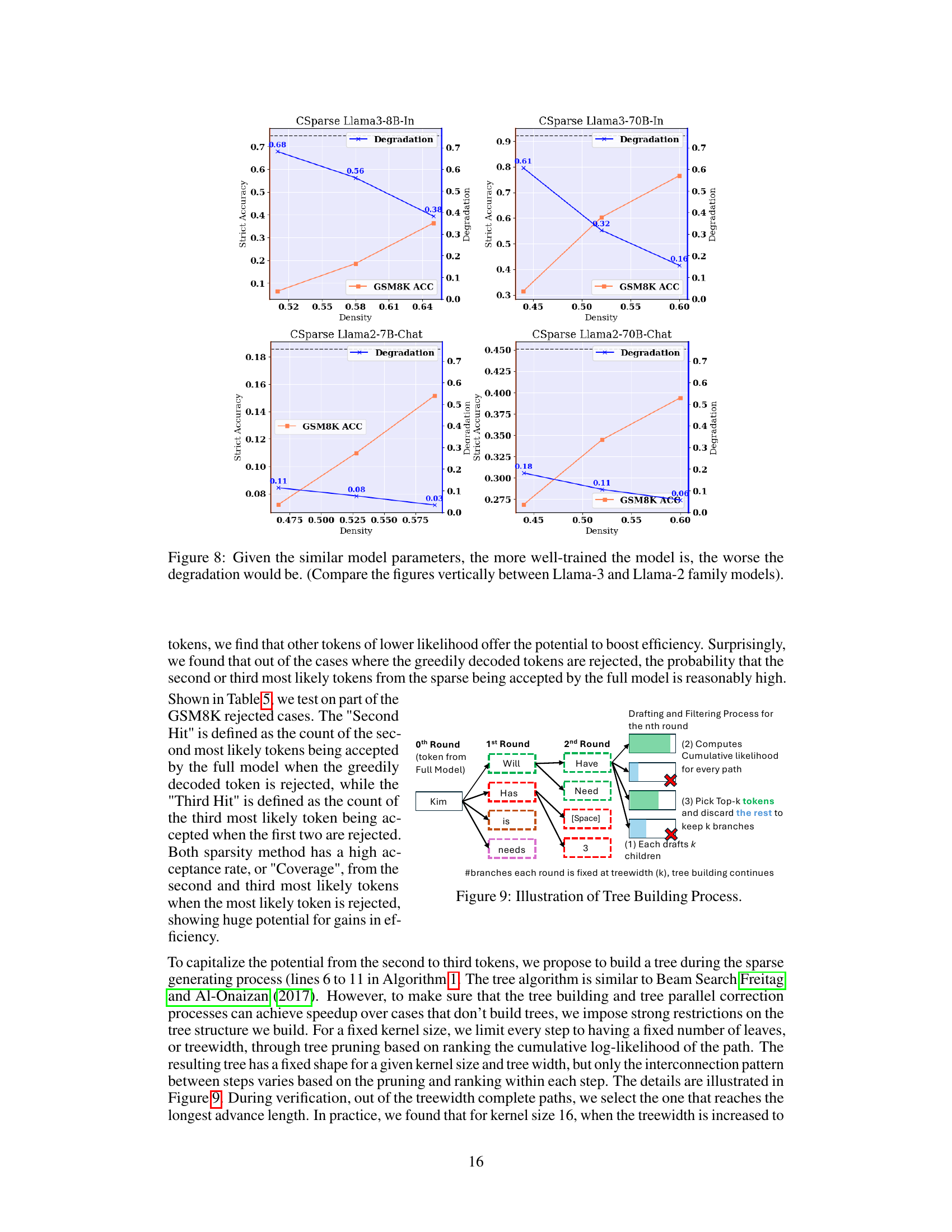
🔼 This figure illustrates the tree building process used in SIRIUS. The process starts with a token from the full model. Each node then generates multiple possible next tokens (children), forming a tree structure where the number of branches at each level is controlled by the treewidth parameter. The likelihood of each path is calculated, and the top-k most likely paths are kept while others are discarded. This process is repeated until the stopping criteria is met, resulting in a set of corrected output tokens.
read the caption
Figure 9: Illustration of Tree Building Process.

🔼 This figure demonstrates the challenges of using contextual sparsity (CS) in large language models (LLMs), especially for complex reasoning tasks. Subfigure (a) compares the performance of a contextually sparse model on two tasks: the CNN/DailyMail summarization task and the GSM8K arithmetic reasoning task. It shows that while CS performs relatively well on summarization, its performance degrades significantly on the more complex reasoning task. Subfigure (b) illustrates that applying CS to a larger model (Llama-3-70B-Instruct) leads to model failure at higher sparsity levels. Finally, subfigure (c) indicates that correcting a small fraction (11%) of tokens in a sparse model is sufficient to recover the original model’s performance, suggesting that an efficient correction mechanism could significantly improve the performance of CS methods.
read the caption
Figure 1: Contextual sparse models struggle at challenging text generation tests that require high-level reasoning and understanding, e.g., GSM8K. On these tasks, contextually sparse models lead to significant quality degradation. In (a), we contrast CS Llama-3-8B-Instruct on GSM8K (green) and CNN DailyMail (coral). (b) Contextual Sparsity Llama-3-70B-Instruct crashes at 50% global sparsity, making the smaller dense model Llama-3-8B-Instruct (green star) a significantly more efficient choice than the sparse 70B model. (c) Sparse model crashing at reasoning tasks has patterns, and ideally only correcting 11% unlikely tokens recovers the sparse model performance fully.
More on tables

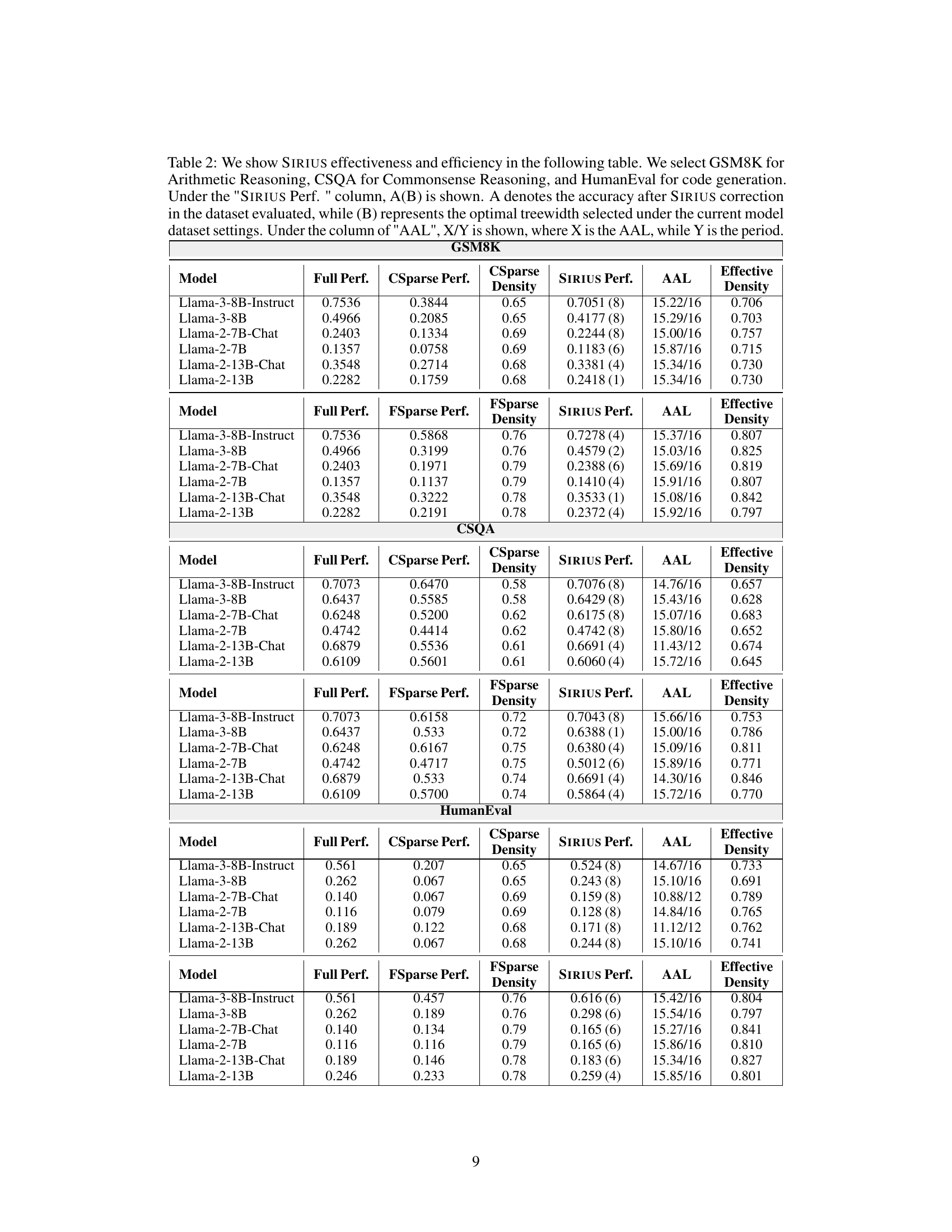
🔼 This table presents the results of the SIRIUS model’s effectiveness and efficiency on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task, it shows the full model performance, the sparse model performance before correction, the performance after correction by SIRIUS, the average advance length (AAL), the sparse model density, and the effective density after correction. The optimal treewidth used for SIRIUS is also indicated.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
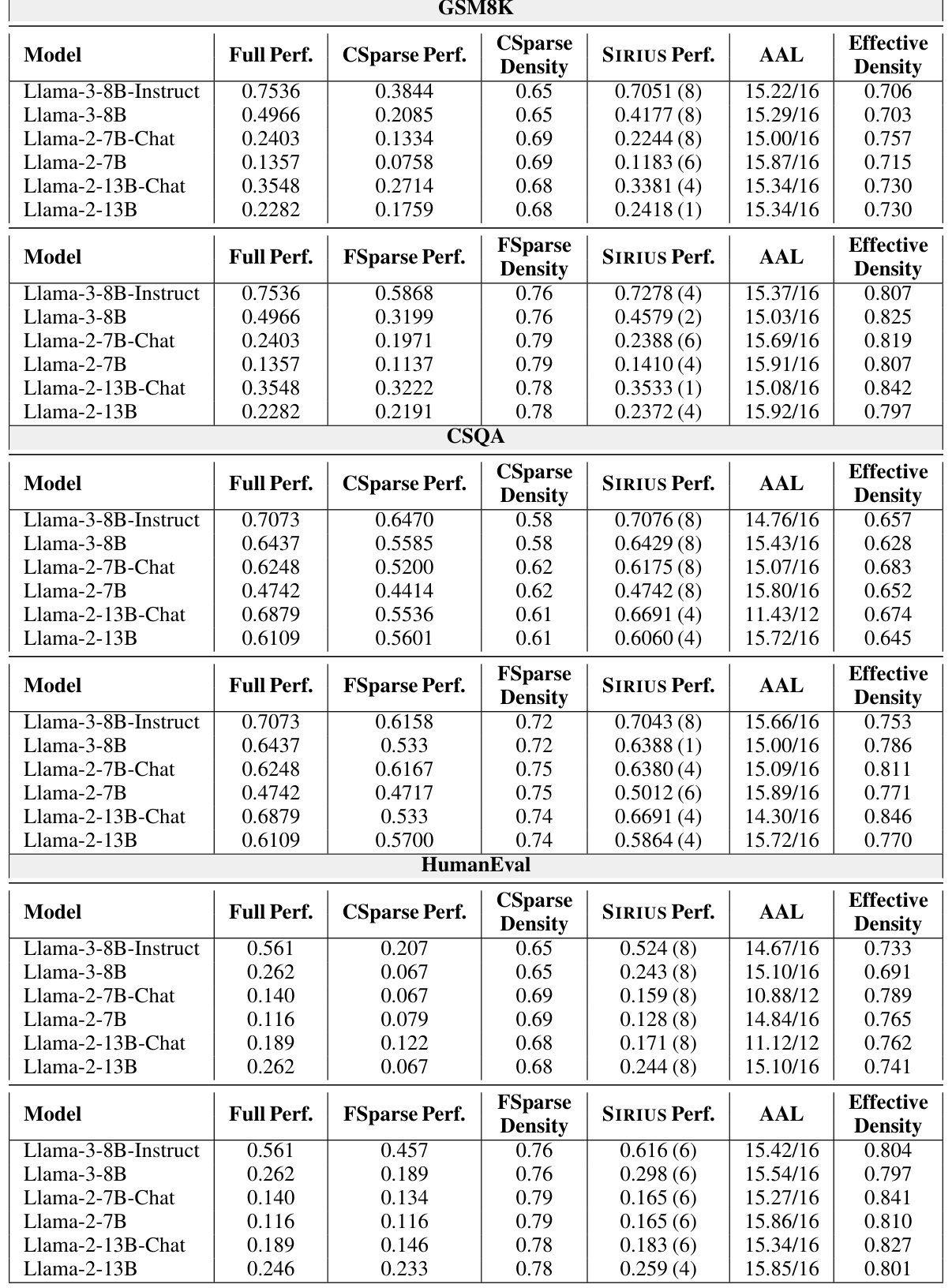
🔼 This table presents a quantitative evaluation of SIRIUS’s performance on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). It shows the full model performance, the performance of contextually sparse models (CSparse and FSparse), and the improved performance after applying SIRIUS. Key metrics include accuracy, sparsity density, average advance length (AAL), and the optimal treewidth used in SIRIUS for each model and dataset combination.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

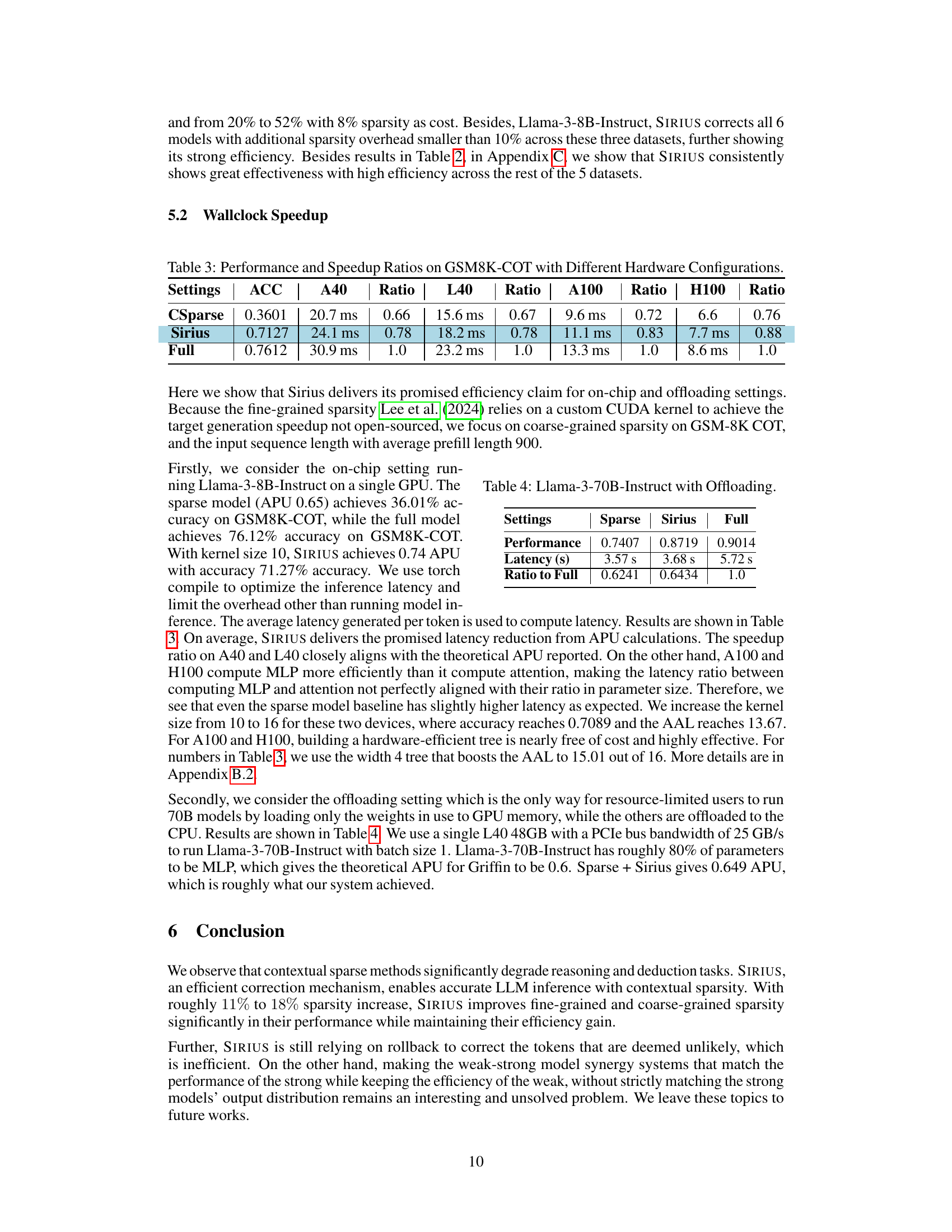
🔼 This table presents the performance and speedup ratios achieved by CSparse, Sirius, and the full model on the GSM8K-COT dataset across various hardware configurations (A40, L40, A100, and H100). The metrics presented include accuracy (ACC) and latency (in milliseconds) for each model and hardware setup. Speedup ratios relative to the full model’s performance are also provided, showcasing the efficiency gains of Sirius.
read the caption
Table 3: Performance and Speedup Ratios on GSM8K-COT with Different Hardware Configurations.
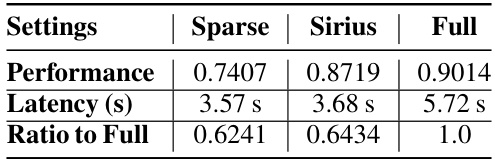
🔼 This table presents the performance, latency, and ratio to full performance for Llama-3-70B-Instruct model with offloading using Sparse, Sirius, and Full methods. It demonstrates the efficiency gains achieved by using SIRIUS, showing that it maintains a significant portion of the accuracy while reducing latency, compared to running the full model.
read the caption
Table 4: Llama-3-70B-Instruct with Offloading.

🔼 This table presents the effectiveness and efficiency of SIRIUS on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and model, it shows the full model performance, the sparse model performance before correction, the performance after applying SIRIUS correction, the average advance length (AAL) which represents the average number of tokens generated before a correction is needed, the sparsity density, and finally the effective density after applying SIRIUS.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf. ' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

🔼 This table presents the performance and speedup ratios achieved by CSparse, Sirius (with and without tree building), and the full model on the GSM8K-COT dataset using different hardware configurations (A40, L40, A100, and H100). It shows the accuracy (ACC), latency in milliseconds, and speedup ratios relative to the full model for each setting and hardware.
read the caption
Table 3: Performance and Speedup Ratios on GSM8K-COT with Different Hardware Configurations.

🔼 This table presents a quantitative evaluation of the SIRIUS model’s performance on three distinct tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and several language models, the table shows the full model’s performance, the performance of the contextually sparse (CS) model, and the performance of the CS model after correction by SIRIUS. Key metrics include accuracy (after correction by SIRIUS), the optimal treewidth used for the correction, the average advance length (AAL), and the effective density. The optimal treewidth is a hyperparameter that determines the frequency of full model calls during the correction process. The AAL indicates how far the model can proceed before requiring a correction, which is related to efficiency. Effective density reflects the balance between sparsity and the cost of using the full model for corrections.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

🔼 This table presents the ablation study on the threshold used in the SIRIUS method for correcting sparse model outputs. It shows how varying the likelihood threshold affects both the accuracy of the corrected outputs and the efficiency (measured by Average Advance Length, AAL). A higher threshold leads to higher accuracy but lower efficiency (shorter AAL), while a lower threshold results in lower accuracy but higher efficiency (longer AAL). The trade-off between accuracy and efficiency is explored by testing various threshold values.
read the caption
Table 8: Ablation on the threshold for correction (FSparse Llama-3-8B-Instruct).

🔼 This table compares the performance of contextual sparsity (CS) models on various tasks, highlighting their strengths and weaknesses. It shows that CS models perform well on prompt understanding tasks (like summarization and question answering) but poorly on reasoning and knowledge-based tasks. The table presents accuracy results across different models and tasks, demonstrating the limitations of CS in complex reasoning scenarios.
read the caption
Table 1: We show the difference between cases when Contextual Sparsity (CS) succeeds or fails. CS is generally good at prompt understanding tasks and tasks that measure the trustworthiness of the language models while not good at tasks that require reasoning and world knowledge understanding.

🔼 This table presents the results of the SIRIUS model on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and model, it shows the full model performance, the sparse model performance, the performance after correction using SIRIUS, the average advance length (AAL) which shows the efficiency of correction, and the effective density, which represents the efficiency of parameter usage. The optimal treewidth used for SIRIUS correction is also indicated.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf. ' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
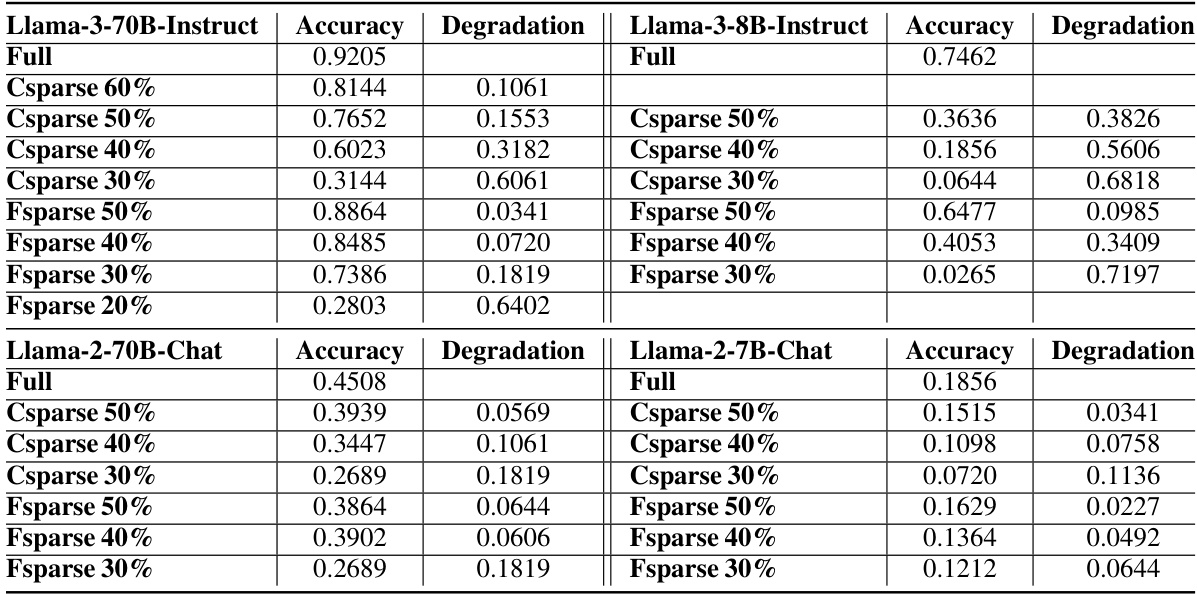
🔼 This table shows the performance of contextual sparsity (CS) models on various tasks. It highlights that CS methods perform well on prompt understanding tasks (e.g., summarization, question answering) but struggle with reasoning, deduction, and knowledge-based tasks. The table provides accuracy scores for different models and tasks, illustrating the effectiveness of CS where it succeeds and where it fails.
read the caption
Table 1: We show the difference between cases when Contextual Sparsity (CS) succeeds or fails. CS is generally good at prompt understanding tasks and tasks that measure the trustworthiness of the language models while not good at tasks that require reasoning and world knowledge understanding.
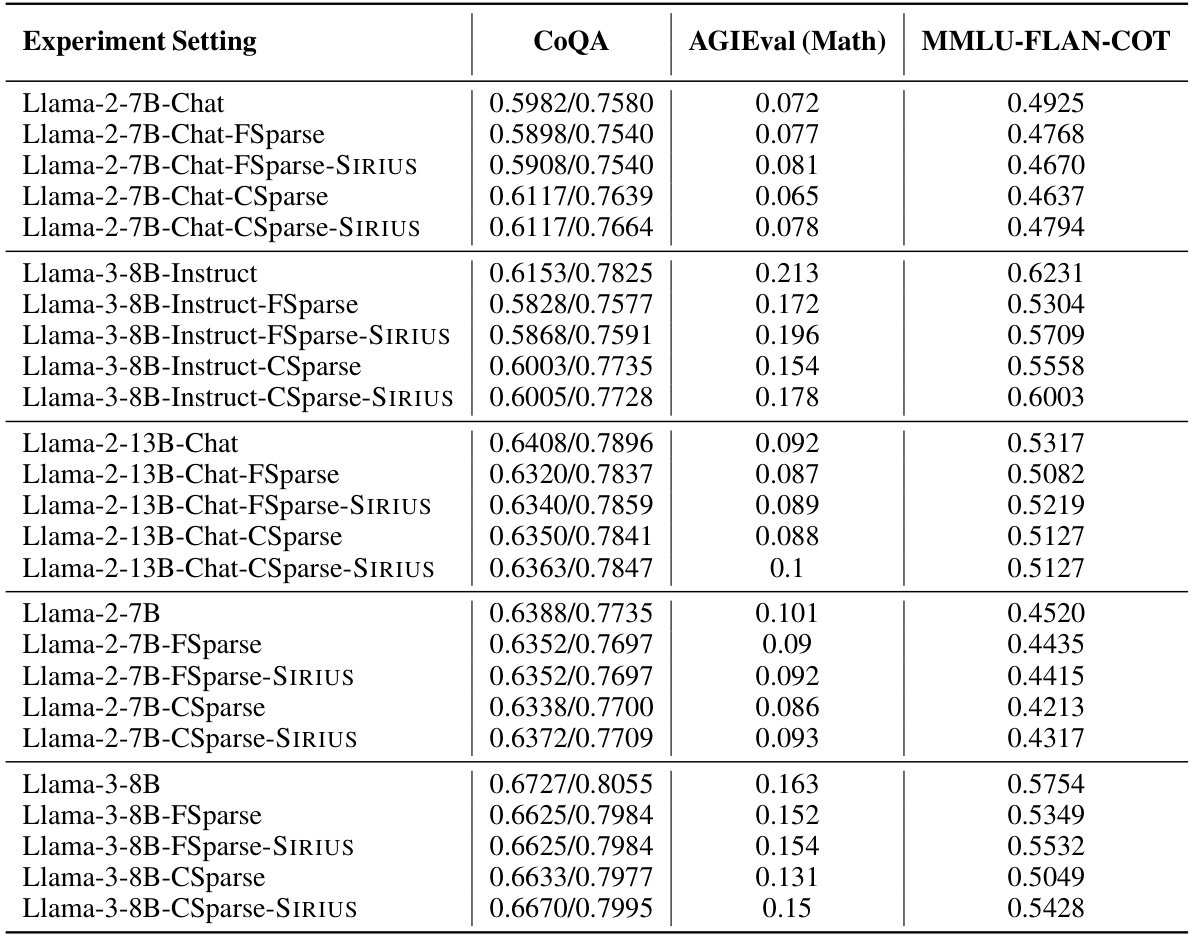
🔼 This table shows the performance comparison of different models on various tasks, highlighting the strengths and weaknesses of contextual sparsity. It demonstrates how contextual sparsity methods perform well on prompt understanding and tasks assessing the trustworthiness of language models but struggle on reasoning and knowledge-based tasks. The table contrasts the performance of full models with contextual sparsity variants (CSparse and FSparse) across a variety of tasks.
read the caption
Table 1: We show the difference between cases when Contextual Sparsity (CS) succeeds or fails. CS is generally good at prompt understanding tasks and tasks that measure the trustworthiness of the language models while not good at tasks that require reasoning and world knowledge understanding.
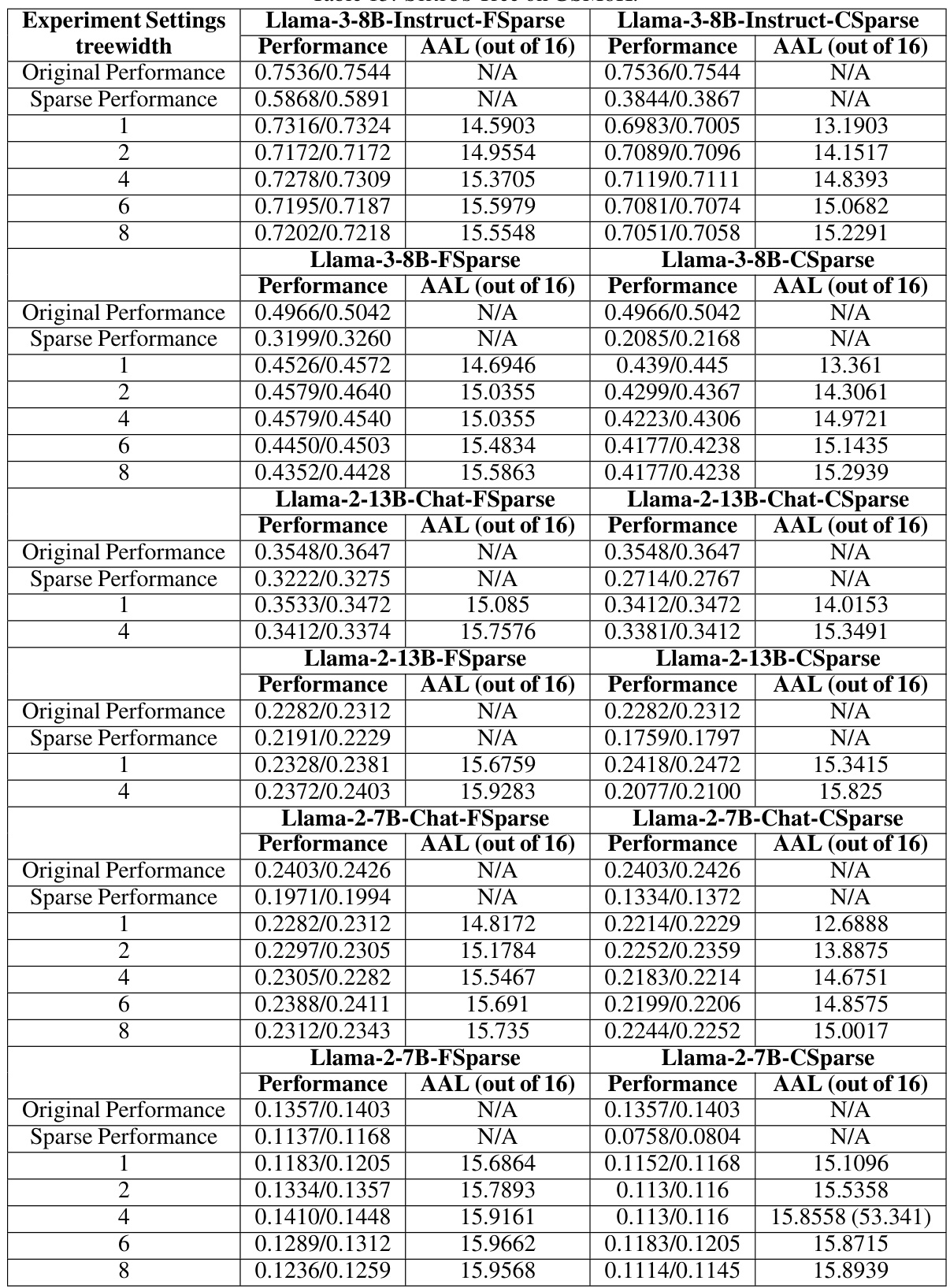
🔼 This table presents the performance and efficiency gains of the SIRIUS model on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task, and for both fine-grained and coarse-grained sparsity, it shows the original performance of the sparse models, the improved performance after applying SIRIUS, and the optimal treewidth (a hyperparameter of SIRIUS). Additionally, it provides the effective density and average advance length (AAL), metrics used to evaluate the efficiency and effectiveness of SIRIUS.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
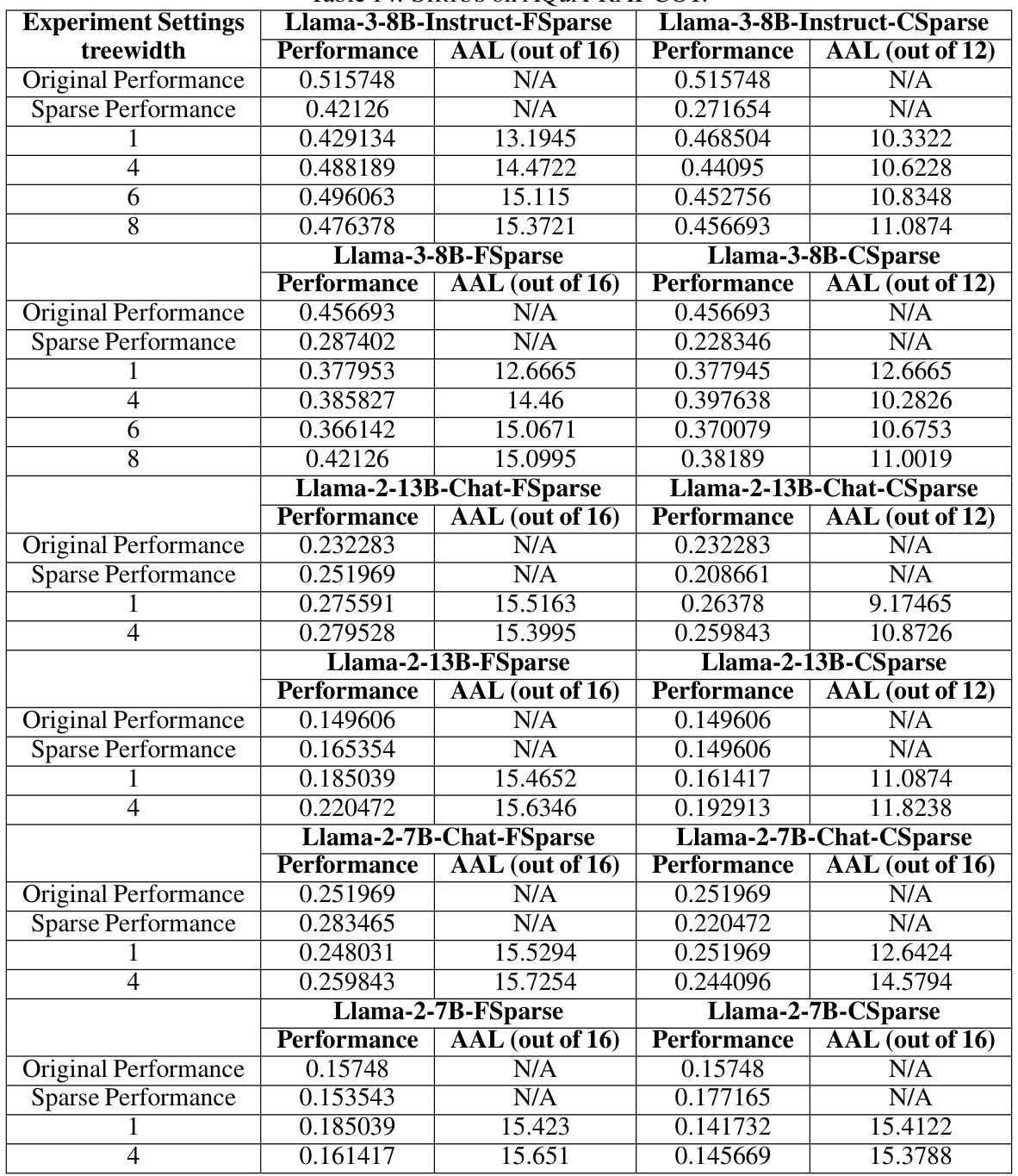
🔼 This table presents a quantitative evaluation of SIRIUS’s performance on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and several different language models, the table shows the original performance, the performance with contextual sparsity (CSparse and FSparse), the performance after applying SIRIUS, the average advance length (AAL), and the effective density. The optimal treewidth used in each setting is also indicated. The results demonstrate the effectiveness and efficiency gains achieved by SIRIUS in improving the performance of contextually sparse models on complex reasoning tasks.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf. ' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
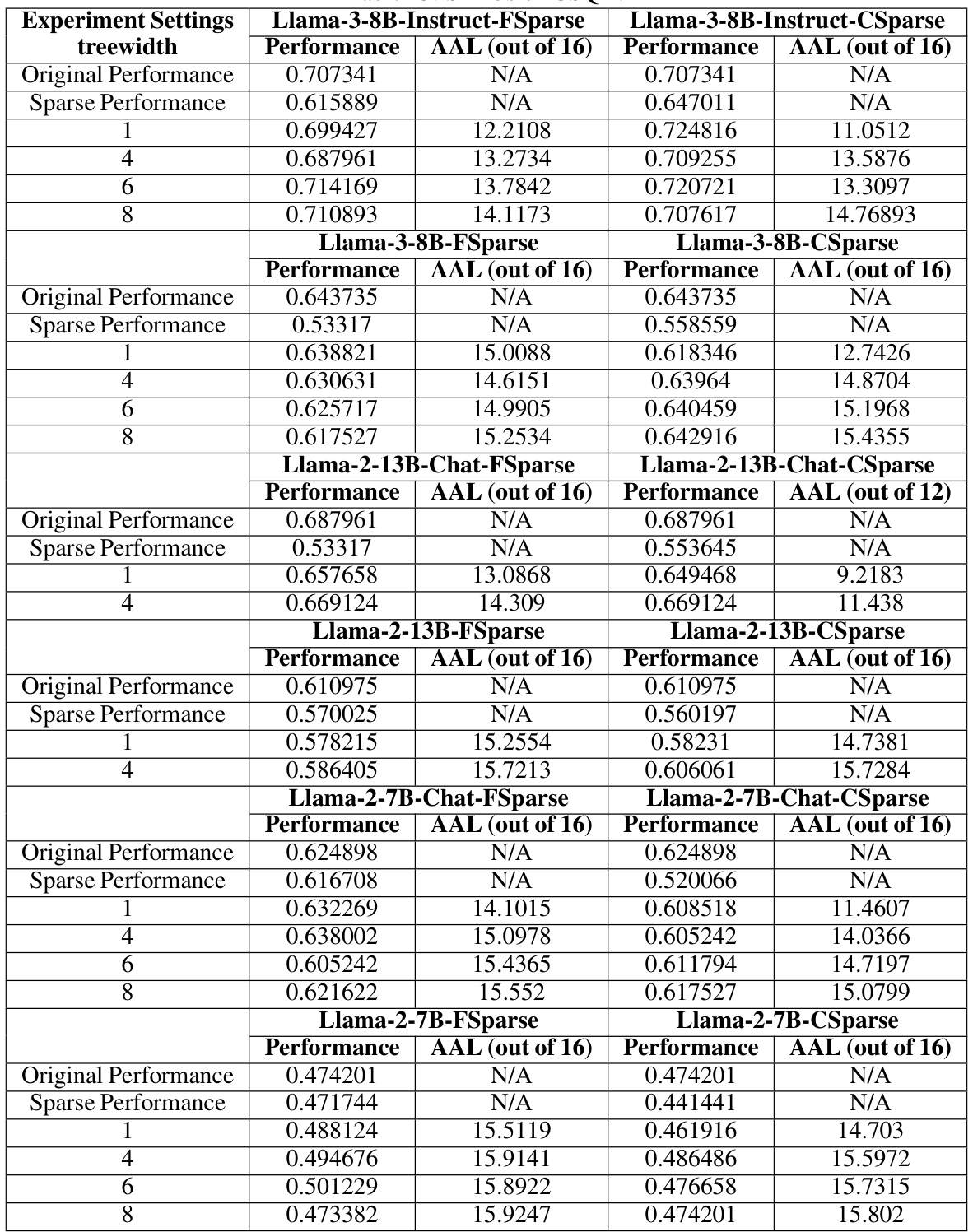
🔼 This table presents the results of the SIRIUS model on three different tasks: GSM8K (arithmetic reasoning), CSQA (commonsense reasoning), and HumanEval (code generation). For each task and model, the table shows the full model performance, the sparse model performance, the SIRIUS-corrected performance, the average advance length (AAL), the sparse density, and the effective density. The AAL value indicates the efficiency of the correction mechanism, with higher values indicating greater efficiency. The optimal treewidth used for each model and task is shown in parentheses. The table highlights SIRIUS’s ability to significantly improve the performance of sparse models while maintaining efficiency.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

🔼 This table presents the results of the SIRIUS model on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and model, it shows the full model performance, the performance of the contextual sparsity model alone, the performance after correction by the SIRIUS model, the average advance length (AAL) which represents the efficiency of the correction process, and the effective density which is the ratio of parameters used per token. The optimal treewidth used for each model and task is also reported.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf. ' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

🔼 This table presents a quantitative evaluation of SIRIUS on three tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task, the table shows the full model performance, the performance of the sparse model without correction, and the performance of the sparse model after correction with SIRIUS. The optimal treewidth used for SIRIUS is specified for each model and dataset combination. Key metrics include accuracy, sparsity density, average parameter used per token (APU), and average advancement length (AAL), providing a comprehensive view of SIRIUS’s effectiveness and efficiency.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
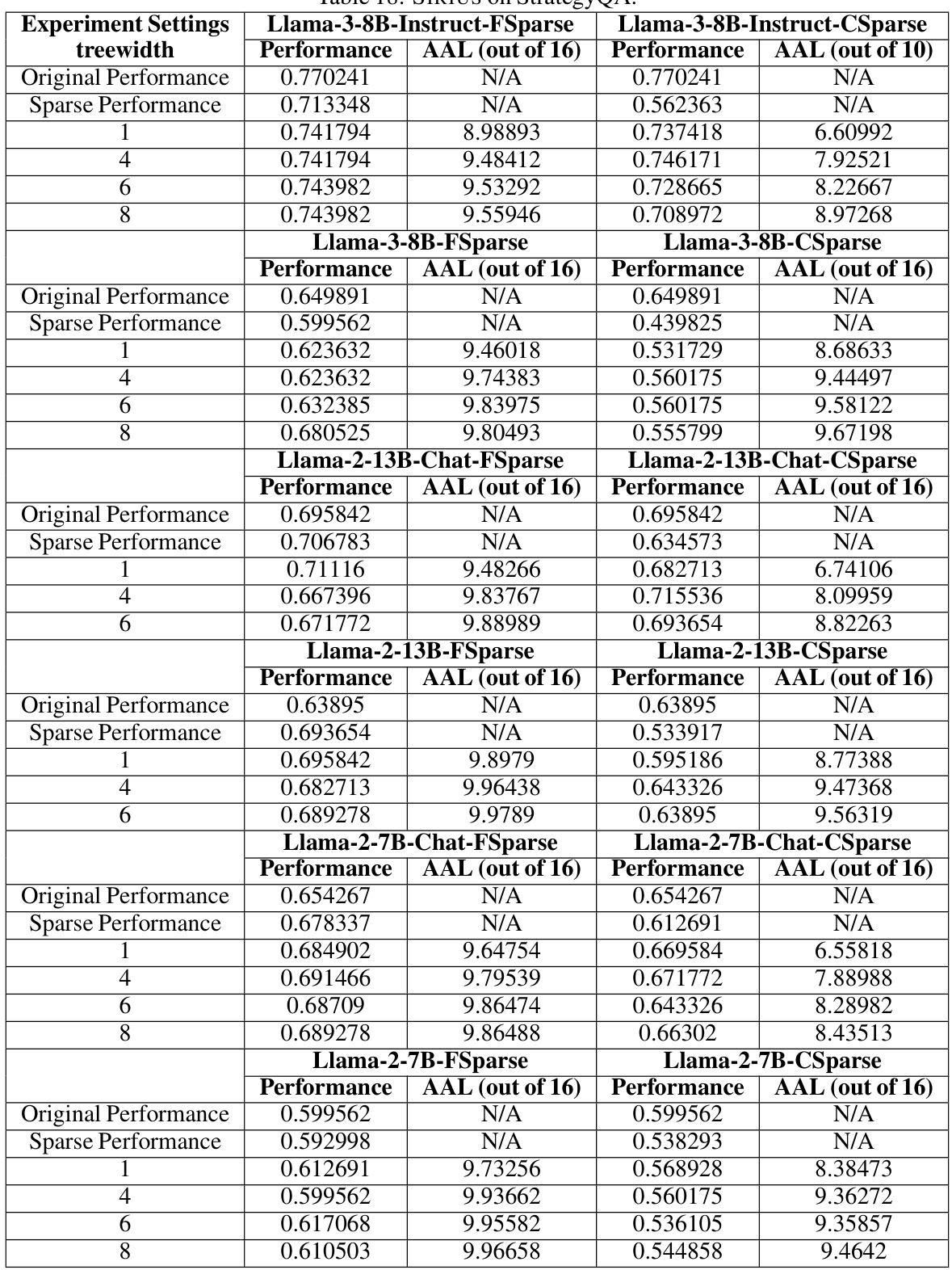
🔼 This table presents the effectiveness and efficiency of SIRIUS on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and model, the table shows the full model performance, the sparse model performance, the performance after SIRIUS correction, the average advance length (AAL) and its corresponding period, and the effective density. The optimal treewidth used for SIRIUS is also indicated.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf. ' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.

🔼 This table presents the results of the SIRIUS model on three different tasks: GSM8K (arithmetic reasoning), CSQA (commonsense reasoning), and HumanEval (code generation). For each task, the table shows the full model performance, the performance of the contextual sparsity model, the performance after applying SIRIUS, and the average advance length (AAL) with its corresponding period. The optimal treewidth used for each model and dataset is also specified.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
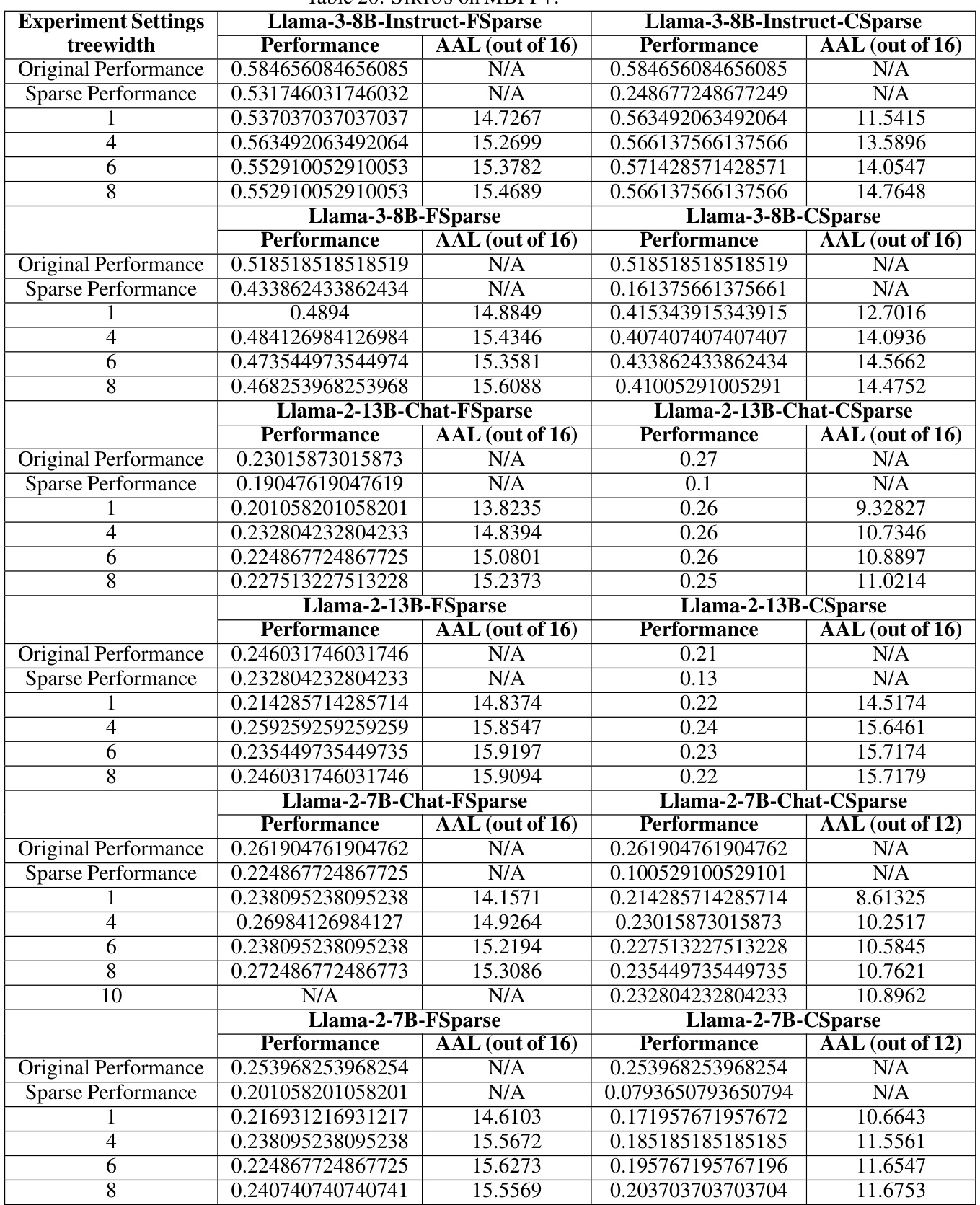
🔼 This table presents a quantitative evaluation of the SIRIUS model’s performance on three different tasks: arithmetic reasoning (GSM8K), commonsense reasoning (CSQA), and code generation (HumanEval). For each task and model, the table shows the full model performance, the sparse model’s performance before correction, the performance after correction with SIRIUS, the average advance length (AAL), the sparsity level and effective density. The optimal treewidth used in SIRIUS for each model and task is also indicated.
read the caption
Table 2: We show SIRIUS effectiveness and efficiency in the following table. We select GSM8K for Arithmetic Reasoning, CSQA for Commonsense Reasoning, and HumanEval for code generation. Under the 'SIRIUS Perf.' column, A(B) is shown. A denotes the accuracy after SIRIUS correction in the dataset evaluated, while (B) represents the optimal treewidth selected under the current model dataset settings. Under the column of 'AAL', X/Y is shown, where X is the AAL, while Y is the period.
Full paper#