↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Unsupervised domain adaptation (UDA) for semantic segmentation has primarily focused on image-to-image adaptation, neglecting other valuable visual modalities like depth, infrared, and event data. This limitation restricts real-world applications requiring multimodal data. The lack of labeled data in these modalities poses a significant challenge for training accurate segmentation models.
This paper introduces Modality Adaptation with text-to-image Diffusion Models (MADM) to address these challenges. MADM leverages pre-trained text-to-image diffusion models to enhance cross-modality capabilities, generating high-quality pseudo-labels. The method uses two key components: diffusion-based pseudo-label generation (adding latent noise to stabilize pseudo-labels) and label palette and latent regression (improving label accuracy and resolution). Experiments show that MADM significantly outperforms existing methods across various modality adaptation tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of existing unsupervised domain adaptation (UDA) methods in semantic segmentation. Current UDA methods mainly focus on image-to-image adaptation, ignoring other rich visual modalities like depth or infrared. This research extends UDA to unsupervised modality adaptation, significantly broadening the applicability of semantic segmentation in real-world multimodal scenarios and paving the way for more robust and versatile models. It also introduces novel techniques such as diffusion-based pseudo-label generation and label palette and latent regression, advancing the state-of-the-art in semantic segmentation.
Visual Insights#
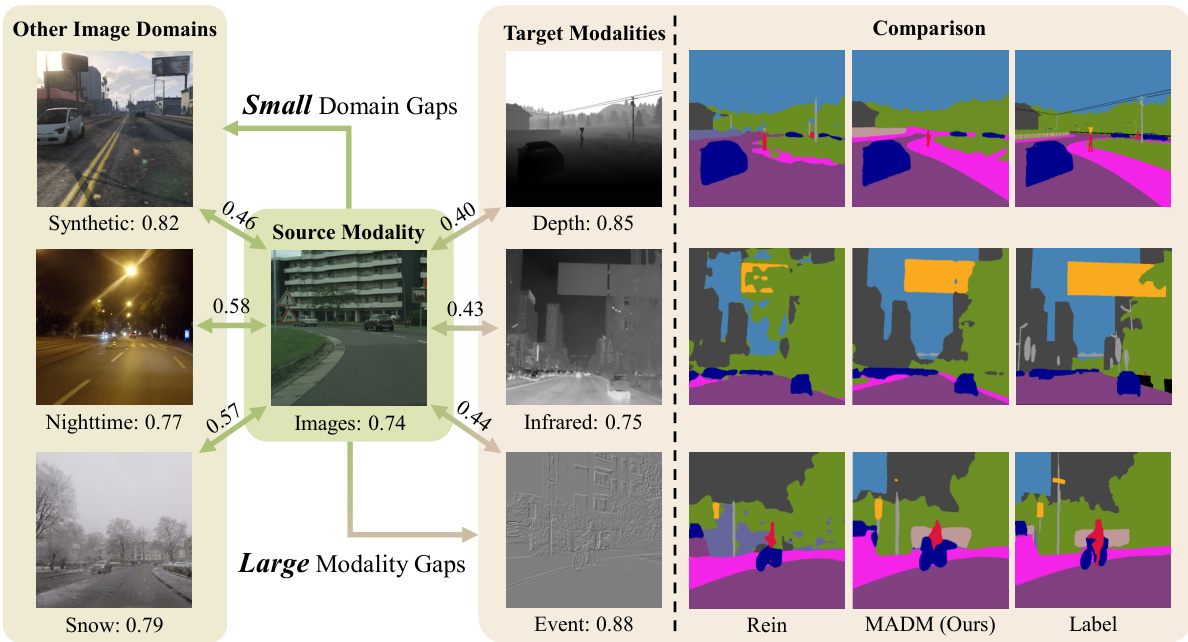
This figure demonstrates the use of ImageBind to measure the similarity between different image domains and modalities (depth, infrared, event). The left side shows the similarity scores, while the right side compares the quantitative segmentation results of the proposed MADM method against a state-of-the-art (Rein) method across three different modalities.

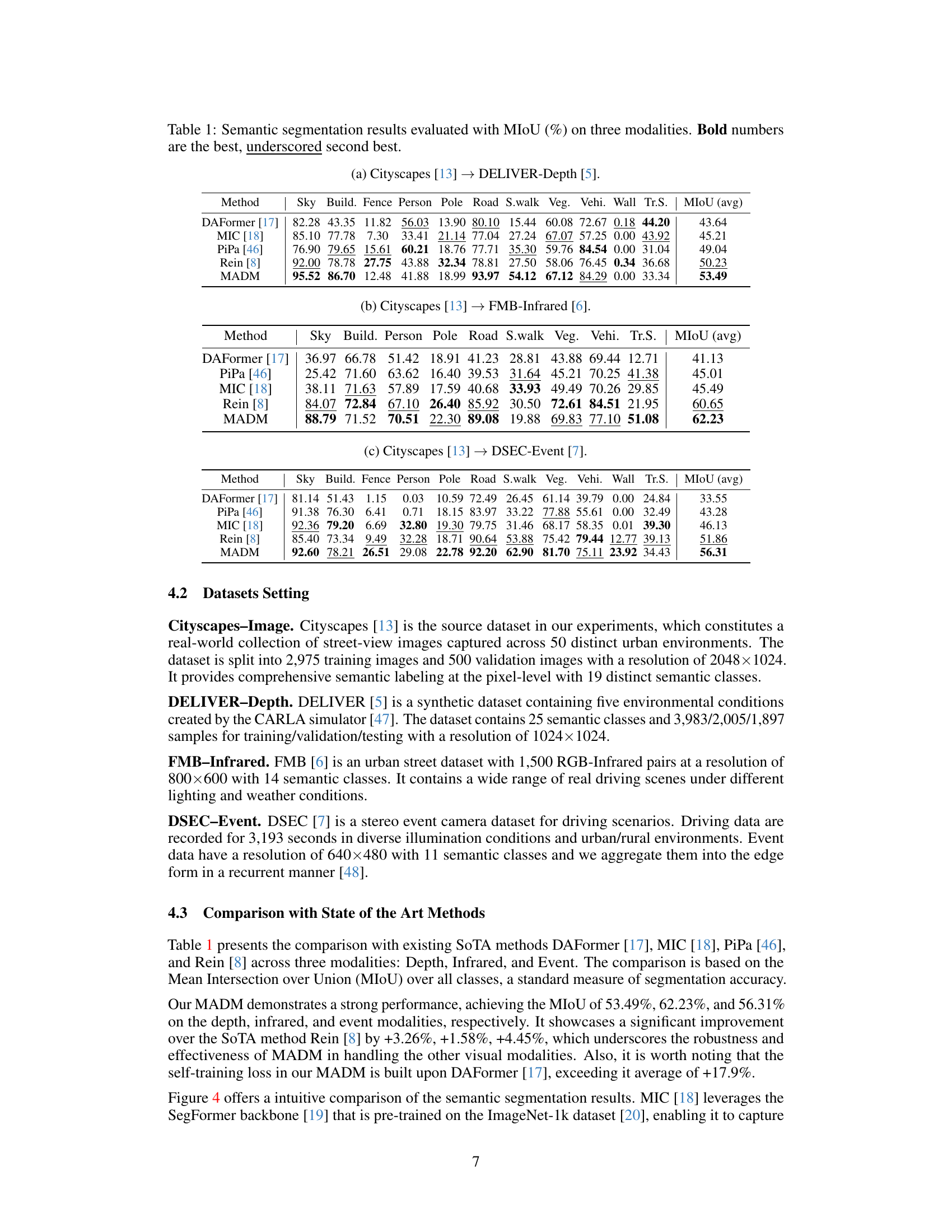
This table presents a comparison of semantic segmentation results using the Mean Intersection over Union (MIoU) metric across three different modalities: depth, infrared, and event. The results are compared for several state-of-the-art (SOTA) methods and the proposed MADM method. The MIoU values are provided for each class within each modality, along with the average MIoU across all classes. The best and second-best performing methods are highlighted in bold and underlined, respectively. This allows for a detailed quantitative comparison of the performance of different methods across various modalities.
In-depth insights#
MADM: Overview#
MADM, or Modality Adaptation with Diffusion Models, offers a novel approach to unsupervised modality adaptation for semantic segmentation. Its core innovation lies in leveraging pre-trained text-to-image diffusion models to bridge the significant modality gap between source (e.g., RGB images) and target (e.g., depth, infrared) data. The method tackles the challenges of unstable pseudo-label generation by introducing diffusion-based pseudo-label generation (DPLG), which adds noise to stabilize the process. Further, to overcome the issue of low-resolution features inherent in diffusion models, MADM employs label palette and latent regression (LPLR) which converts one-hot encoded labels into RGB format for finer-grained feature extraction. This dual approach leads to robust and accurate cross-modality adaptation, outperforming existing methods across diverse modality tasks. The use of pre-trained diffusion models is key to its generalization ability across modalities; however, the model’s computational cost may pose a limitation for wider applications.
Diffusion-Based Labels#
The concept of “Diffusion-Based Labels” in the context of a research paper likely involves leveraging diffusion models, particularly those used in image generation, to create or refine labels for a downstream task such as semantic segmentation. This approach is intriguing because diffusion models excel at generating high-quality, diverse samples based on a learned latent space. By injecting noise into the latent space and then using the model’s denoising capabilities, a diffusion model might probabilistically generate refined labels or pseudo-labels for data points where true labels are scarce or uncertain. This process could be particularly beneficial for tackling issues like class imbalance, where some categories are heavily underrepresented in the training data. The advantages could include improved label quality by smoothing noisy annotations and the ability to generate synthetic labels to augment existing training data, thus boosting overall model performance and robustness. However, challenges might include computational expense associated with the diffusion process and potential biases introduced if the diffusion model’s latent space does not accurately reflect the underlying data distribution for labeling. Therefore, careful consideration of training data and model architecture is crucial to ensure the success of this approach.
Latent Space Regression#
Latent space regression, in the context of a research paper likely focused on deep learning and generative models, involves using a neural network to learn a mapping between a latent space representation and a target space. The latent space, often lower-dimensional, captures essential features extracted by an encoder network from high-dimensional input data (like images). The regression task is to predict the target space variables directly from this latent representation, bypassing the need for a decoder network to reconstruct the original high-dimensional data. This approach is especially useful when the target space has a different nature than the original input space, such as when transforming an image’s latent representation to predict its semantic segmentation mask. This bypasses the complexities of traditional decoder networks, especially beneficial when working with high resolution images or intricate details which are hard to reconstruct. The effectiveness of latent space regression hinges on the quality of the latent space representation and the design of the regression network. If the latent space doesn’t adequately capture essential features, the regression accuracy will be limited. Conversely, a poorly designed regression network may fail to effectively learn the complex mapping between the two spaces. Therefore, careful considerations must be given to both the encoder and regression architectures to achieve optimal results. Success relies on a powerful latent space encoder that captures relevant information and a regression network capable of accurately mapping from this latent space to the target space.
Ablation Experiments#
Ablation experiments systematically evaluate the contribution of individual components within a machine learning model. By removing or modifying parts of the system, researchers can assess the impact on overall performance. This process is crucial for understanding the relative importance of each module and identifying potential bottlenecks. A thoughtful approach involves varying multiple parameters or components, providing a nuanced understanding of their individual and combined effects. For example, if the model includes a feature extraction module and a classification module, ablation studies would compare the model’s performance with each module removed, in addition to assessing its performance when these parameters are altered. The results highlight which components most significantly contribute to the model’s success and which aspects could be improved or re-designed. Analyzing the ablation results often guides further model development, enabling informed decisions about architecture modifications and parameter tuning. Clearly presented ablation experiments are vital for demonstrating the model’s robustness and justifying design choices.
Future Work#
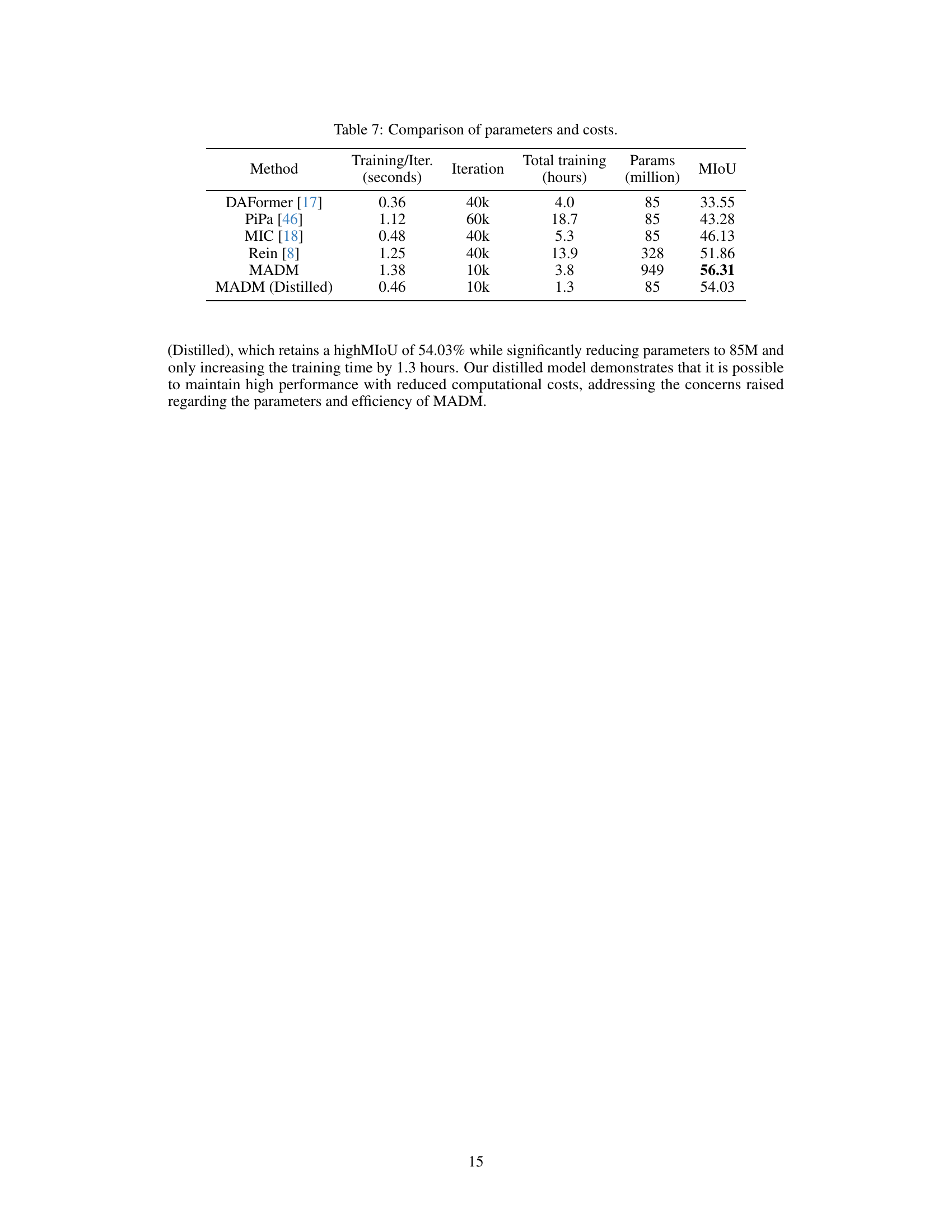
The paper’s ‘Future Work’ section could explore several promising avenues. Extending the modality adaptation to encompass a wider variety of visual modalities, beyond the three explored (depth, infrared, and event), is a natural next step. This would involve evaluating performance on modalities such as lidar, radar, or even multimodal fusion scenarios. Investigating the impact of different diffusion models and their architectural choices on the overall performance of MADM would be insightful, potentially identifying models better suited for modality adaptation. A deeper exploration of the limitations of using pre-trained TIDMs is warranted, such as an analysis of the effects of domain mismatch between the pre-training data and the target modalities. Improving efficiency through model compression or distillation techniques is crucial to make the approach more practical and scalable. Finally, investigating alternative methods for pseudo-label generation that are less reliant on diffusion models is needed. By addressing these directions, future work can solidify and enhance the applicability and robustness of the MADM framework.
More visual insights#
More on figures

This figure illustrates the MADM framework, which consists of three main parts: Self-Training, Diffusion-based Pseudo-Label Generation (DPLG), and Label Palette and Latent Regression (LPLR). Self-Training uses both supervised loss from the source modality and pseudo-labeled loss from the target modality to train the network. DPLG adds noise to the latent representation of target samples to stabilize pseudo-label generation. LPLR converts one-hot encoded labels into RGB form using a palette, encodes them into the latent space, and uses them to supervise the UNet output, resulting in high-resolution features.

This figure visualizes the impact of Diffusion-based Pseudo-Label Generation (DPLG) on the quality of pseudo-labels generated for the event modality at different training iterations (1250, 1750, and 2250). It demonstrates how the addition of noise in DPLG stabilizes the generation of pseudo-labels and improves their accuracy over time, as indicated by a more consistent and detailed representation of the scene compared to pseudo-labels generated without DPLG.

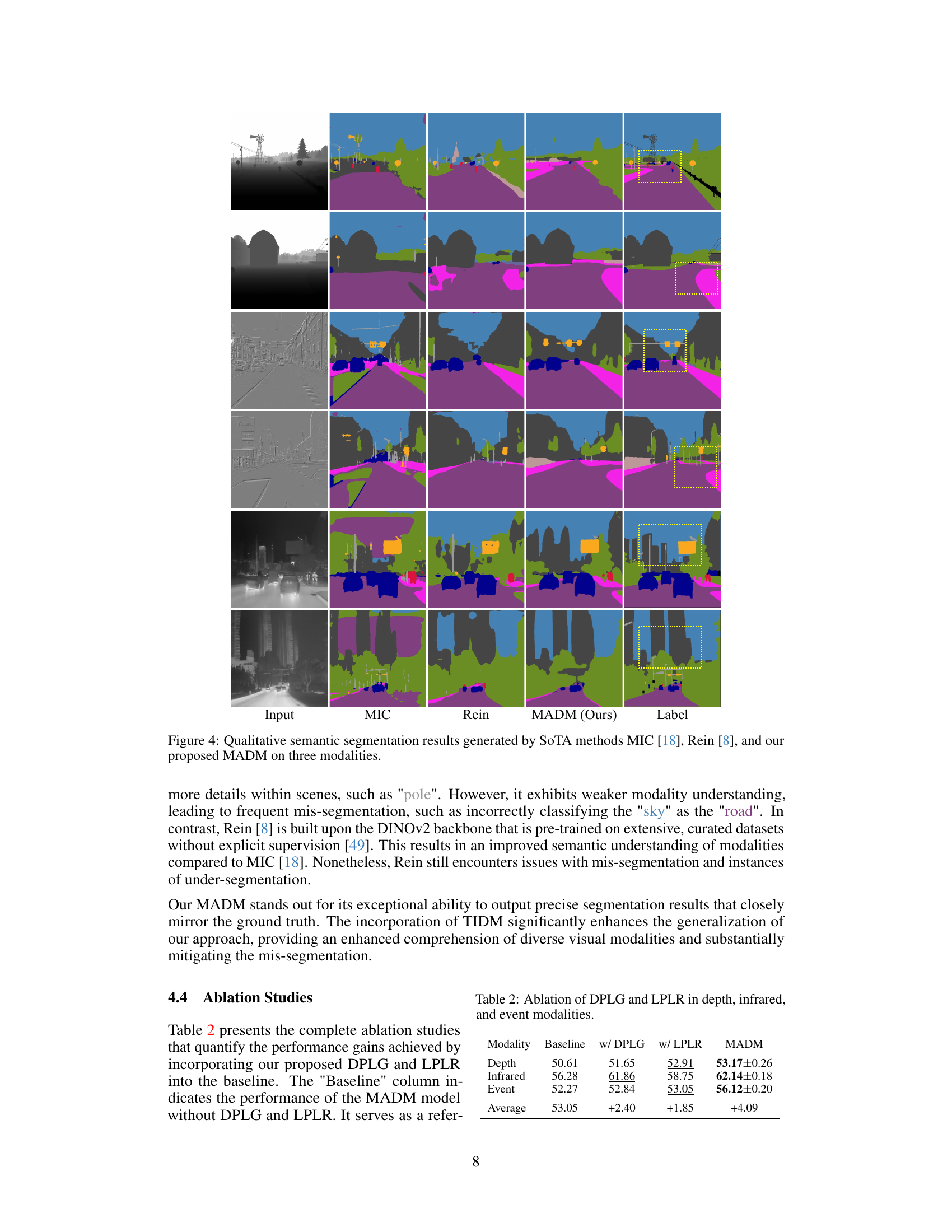
This figure provides a qualitative comparison of semantic segmentation results obtained using three different methods: MIC [18], Rein [8], and the proposed MADM. The results are shown for three different modalities (image, depth, and infrared), with the input image, segmentation results from each method, and the ground truth label displayed side-by-side for comparison. The figure highlights the superior performance of MADM in terms of accuracy and detail preservation, especially in challenging areas (as highlighted by the yellow boxes). The differences in performance demonstrate the effectiveness of MADM’s approach for cross-modality semantic segmentation.

This figure shows a visual analysis of the effect of the diffusion step parameter (k) in the Diffusion-based Pseudo-Label Generation (DPLG) method at iteration 1250. It demonstrates how different noise levels affect the quality of pseudo-label generation during the training process. As k increases, more noise is added to the latent representation of the target sample. The images show the progressive changes in segmentation results as the noise level increases. At k=0, no noise is added, and the segmentation is inaccurate. As k increases, the segmentation becomes more accurate until it reaches an optimal level, after which adding too much noise (high k values) again leads to degraded segmentation results.

This figure visualizes the outputs of the VAE decoder and the segmentation head at different stages of training, showing how the regression results (from the VAE decoder) become progressively clearer and more detailed as the model converges. This improvement in detail helps the segmentation head produce more accurate semantic segmentations. The comparison between regression and classification outputs highlights how LPLR improves the accuracy of semantic segmentation by enhancing the resolution of the features.

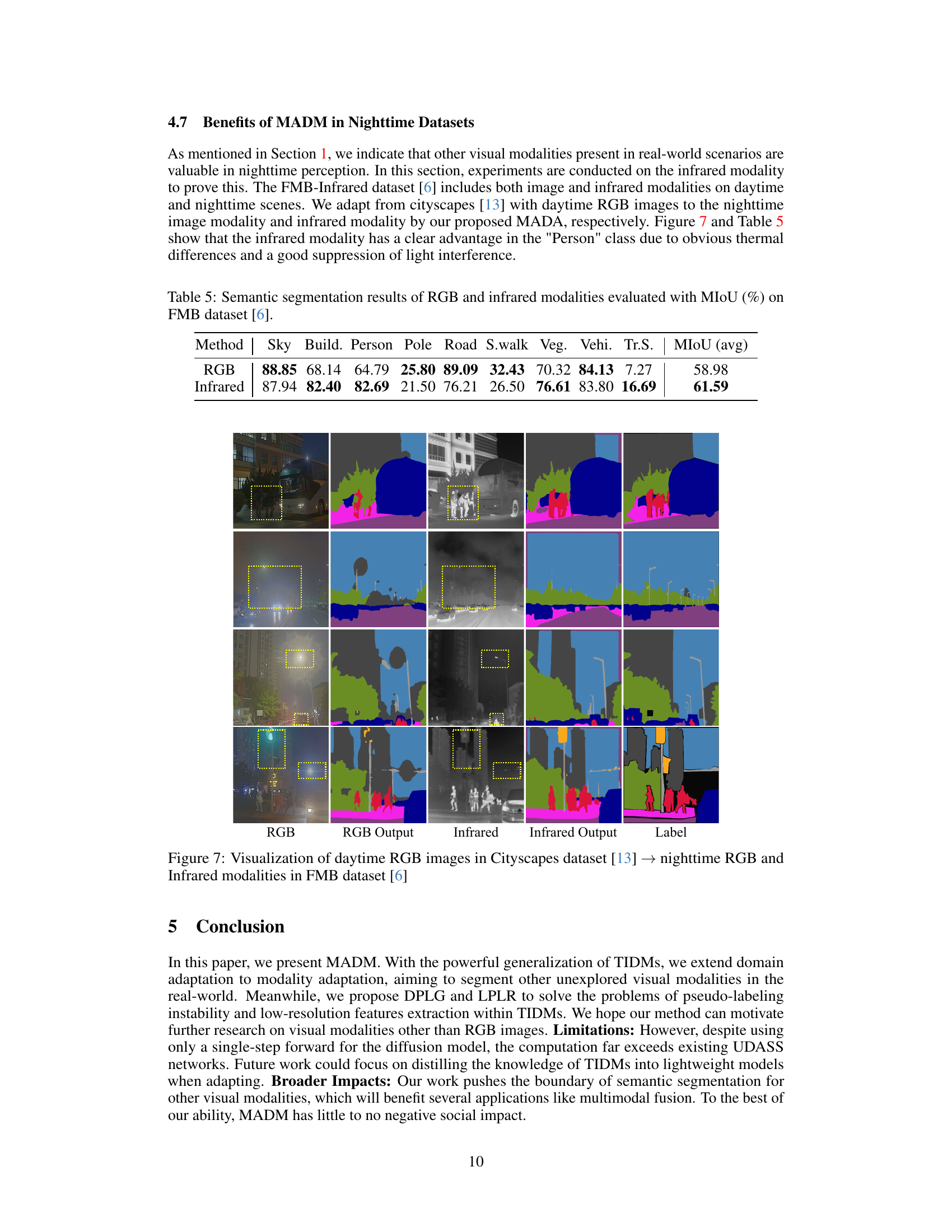
This figure visualizes the performance of the proposed method (MADM) on nighttime images. It compares the segmentation results of daytime RGB images from the Cityscapes dataset with nighttime RGB and infrared images from the FMB dataset. The results show that the infrared modality provides superior performance, particularly in identifying pedestrians, due to the thermal differences highlighted by infrared. This showcases the adaptability of MADM to different visual modalities and its effectiveness in handling low-light conditions.
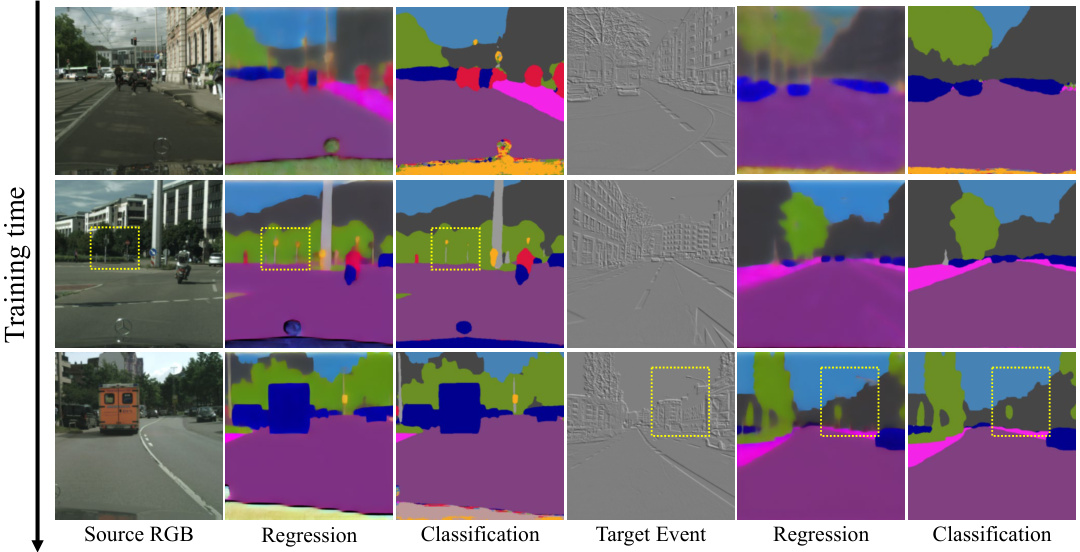
This figure visualizes the results of the VAE decoder (Regression) and the segmentation head (Classification) at different training time steps. It demonstrates how the quality of the regression results improves over time, starting blurry and becoming progressively clearer as the model converges. This shows that the VAE decoder is successfully learning to upsample the latent representation, providing the segmentation head with higher-resolution features for more accurate semantic segmentation.
More on tables

This table presents a comparison of semantic segmentation results obtained using different methods across three different modalities: depth, infrared, and event. The results are evaluated using the mean Intersection over Union (MIoU) metric, a common evaluation metric for semantic segmentation. The table shows the performance of several state-of-the-art (SOTA) methods alongside the proposed method (MADM) to demonstrate its superiority.

This table presents a comparison of semantic segmentation results obtained using different methods across three different modalities: depth, infrared, and event. The performance of each method is evaluated using the mean Intersection over Union (MIoU) metric, a common measure for evaluating the accuracy of semantic segmentation. The table shows the MIoU for each class (e.g., Sky, Building, Person, etc.) as well as the average MIoU across all classes. The best performing method for each modality is shown in bold, while the second best is underlined.
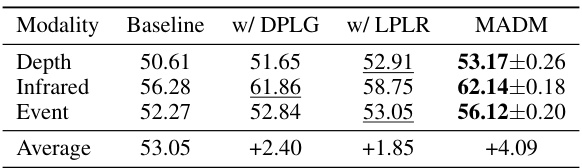
This table presents the results of ablation studies conducted to evaluate the impact of the proposed Diffusion-based Pseudo-Label Generation (DPLG) and Label Palette and Latent Regression (LPLR) components on the overall performance of the MADM model. It shows the mean Intersection over Union (mIoU) scores achieved by the baseline model (without DPLG and LPLR), the model with only DPLG, the model with only LPLR, and the complete MADM model (with both DPLG and LPLR) across three different modalities: Depth, Infrared, and Event. The improvements resulting from the inclusion of DPLG and LPLR are clearly demonstrated, highlighting the synergistic effect of these components in enhancing the model’s performance. The average mIoU improvement across all modalities is also shown.
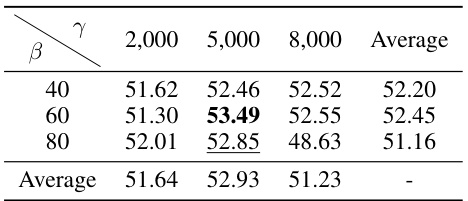
This table presents the ablation study of parameters β and γ in the Diffusion-based Pseudo-Label Generation (DPLG) method, specifically for the depth modality. It shows how changes in these parameters affect the model’s performance (MIoU) under different conditions. The best result is 53.49 MIoU, indicating the importance of parameter tuning in DPLG.

This table shows the ablation study of the effect of different values of the hyperparameter λreg in the Label Palette and Latent Regression (LPLR) module on the event modality. The MIoU (mean Intersection over Union) is used as the evaluation metric, showing that a λreg of 10.0 provides the best performance.

This table presents a comparison of semantic segmentation results using RGB and infrared modalities on the FMB dataset. The MIoU (mean Intersection over Union) metric is used to evaluate the performance of each modality across various classes (Sky, Building, Person, Pole, Road, Sidewalk, Vegetation, Vehicle, Traffic Sign). The table highlights the performance difference between RGB and infrared modalities, showing infrared’s superior performance in certain classes.

This table presents the ablation study on different data volumes for the event modality in the DSEC dataset. It shows the mean Intersection over Union (MIoU) achieved by training the MADM model (with and without DPLG and LPLR) on varying percentages (10%, 25%, 50%, and 100%) of the target dataset. The results demonstrate that the MADM model consistently outperforms the baseline across all data volume settings and maintains robustness even when the training data is limited.

This table presents a comparison of semantic segmentation results using the Mean Intersection over Union (MIoU) metric across three different modalities: depth, infrared, and event. The results are compared for several different methods, including the proposed method (MADM) and several state-of-the-art (SOTA) baselines. The table highlights the best and second-best performing method for each modality, using bold and underlined formatting respectively. This allows for a clear and concise view of the relative performance of MADM in comparison to existing methods on a range of tasks.
Full paper#