↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Pre-training large vision models is computationally expensive and resource-intensive, commonly believed to be essential for achieving high accuracy on downstream tasks. This paper investigates the actual necessity of pre-trained features in vision transformers (ViTs). It challenges the conventional understanding that the effectiveness of pre-training lies solely in learning useful feature representations.
The researchers propose a novel method called “attention transfer.” Instead of transferring all model weights during fine-tuning, they transfer only the attention patterns (information flow) from a pre-trained teacher ViT to a student ViT. Their experiments show that even without feature transfer, this method allows the student model to achieve comparable performance to full fine-tuning. This approach offers a potentially more efficient and secure way of using pre-trained ViTs. The study also analyzes the sufficiency of attention maps under various conditions, including distribution shift settings where attention transfer underperforms fine-tuning.
Key Takeaways#
Why does it matter?#
This paper challenges the prevailing wisdom in vision transformer (ViT) pre-training, demonstrating that transferring only the attention patterns from a pre-trained model is surprisingly effective for downstream tasks. This opens exciting avenues for more efficient and potentially secure transfer learning strategies, reducing reliance on transferring all the heavy weights and potentially mitigating security risks.
Visual Insights#
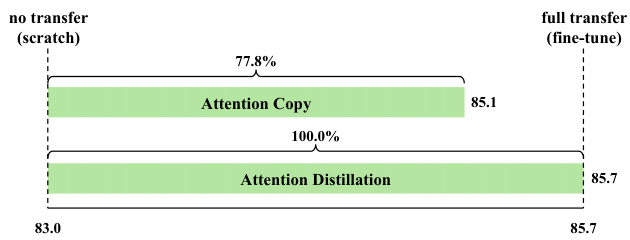
This figure demonstrates the effectiveness of attention transfer in achieving comparable performance to full weight fine-tuning in Vision Transformers. By simply copying or distilling the attention maps from a pre-trained teacher model, a student model can achieve high accuracy on the ImageNet-1K classification task, even when learning features from scratch. The top part shows that copying attention maps recovers 77.8% of the performance gap between training from scratch and fine-tuning. The bottom part indicates that distilling attention maps fully matches the performance of fine-tuning, highlighting the significance of attention patterns in model training.

This table presents the main results of the paper, comparing the performance of different methods on ImageNet-1K classification. It shows that using only the attention patterns from a pre-trained model (Attention Copy and Attention Distillation) is almost as effective as fine-tuning the entire model, demonstrating the sufficiency of attention maps for achieving high accuracy. Ensemble methods combining fine-tuning with attention distillation are also shown to achieve even higher accuracy.
In-depth insights#
Attn Transfer Power#
The concept of “Attn Transfer Power” refers to the surprising efficacy of transferring only attention patterns from a pre-trained Vision Transformer (ViT) model to a student model for downstream tasks. This challenges the conventional wisdom that pre-training’s success stems from learned representations, highlighting the crucial role of attention mechanisms in information flow. The power lies in the student model learning its own features while leveraging the teacher’s learned attention maps to guide the routing of information between tokens. This decoupling of feature learning from attention transfer presents a novel approach to leveraging pre-trained models, potentially offering advantages over traditional fine-tuning. While the authors demonstrate high effectiveness, the approach is not universally robust, being significantly impacted by distribution shifts between pre-training and downstream tasks. This sensitivity reveals a key limitation and underscores the need for further research to fully understand the dynamics of attention transfer and its range of applicability across diverse scenarios.
Beyond Feature Learn#
The concept of “Beyond Feature Learning” in the context of Vision Transformers (ViTs) challenges the conventional wisdom that pre-training’s primary benefit is learning effective feature representations. The core argument is that attention mechanisms, which govern information flow between tokens, are surprisingly sufficient for downstream task success, even if the features learned during pre-training are discarded. This implies that the routing of information, rather than the specific features themselves, is a key transferable aspect of pre-trained ViTs. The research likely explores methods that transfer only attention patterns from a teacher model to a student, allowing the student to learn its own features from scratch. This approach has the potential to significantly decouple feature extraction from information routing, providing a powerful alternative to traditional fine-tuning, especially beneficial in resource-constrained environments or when direct weight transfer poses security risks. However, it’s important to also consider the limitations. The effectiveness of this approach might depend heavily on the similarity between pre-training and downstream tasks; transferring attention without features may not perform as well in domains with significant distribution shifts. Finally, analyzing the results concerning the sufficiency of transferred attention patterns will likely be crucial, possibly unveiling the interplay between attention maps and feature learning in a more nuanced way than is currently understood.
Ablation Studies#
Ablation studies systematically remove components of a model or system to assess their individual contributions. In the context of a vision transformer paper, this could involve removing or altering different parts of the architecture, such as attention heads, layers, or specific activation functions. The core goal is to understand what aspects are crucial for the model’s overall performance and which are less important or even detrimental. By progressively removing parts, researchers can gain insights into the model’s inner workings, such as the importance of different pre-training stages or the effect of transferring only attention patterns. Well-designed ablation studies should consider a variety of scenarios and carefully control for confounding variables to isolate the effects of each component. The results provide evidence to support or refute the paper’s main claims by demonstrating the significance of each design choice and helping in understanding overall effectiveness. It also helps identify potential areas for improvement or simplification of the architecture. Furthermore, a comprehensive set of ablation experiments will show the robustness and generalizability of the model’s performance. The absence of these studies would significantly weaken the paper’s contributions, leaving the findings less convincing and less actionable.
Distribution Shifts#
The concept of distribution shift is crucial in evaluating the robustness and generalizability of machine learning models. A model trained on one data distribution may perform poorly when exposed to a different distribution, even if the task remains the same. This section delves into how distribution shift affects the performance of the proposed attention transfer method. It is likely that the experiments explore scenarios where the training and test data differ significantly in terms of image characteristics, such as style, resolution, or object composition. The results would indicate how well the attention transfer method generalizes across diverse data distributions compared to the standard fine-tuning approach. A key insight would likely be whether attention transfer is more robust or sensitive to distribution shift than fine-tuning. The analysis may also investigate the underlying reasons for any performance differences, potentially linking them to the learned attention patterns or feature representations. Furthermore, it’s possible the paper assesses how various types of distribution shifts affect the method. This could involve analyzing the impact of shifts in label distribution, covariate shift, and concept shift. Ultimately, the findings in this section would enhance our understanding of the attention transfer method’s limitations and its applicability in real-world scenarios where data distributions are rarely static.
Future Directions#
Future research could explore several promising avenues. A deeper investigation into the role of query (Q) matrices in attention mechanisms is warranted, potentially revealing more efficient transfer strategies. The surprising effectiveness of attention transfer raises questions about existing pre-training practices; future work should investigate whether fine-tuning is truly necessary, especially with the rise of large language models where attention maps may be more easily transferable. Exploring the sensitivity of attention transfer to dataset bias and distribution shifts is crucial for understanding its limitations and developing more robust methods. Finally, applying attention transfer to tasks beyond image classification and object detection, such as video understanding and natural language processing, will be vital in determining its broader applicability and impact.
More visual insights#
More on figures
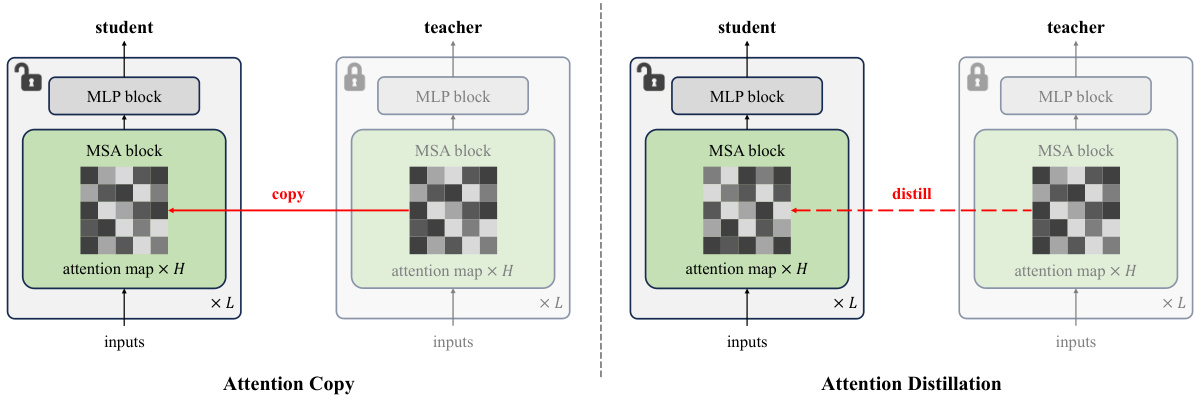
This figure illustrates the two methods for attention transfer proposed in the paper: Attention Copy and Attention Distillation. Attention Copy directly copies the attention maps from a pre-trained teacher network to a randomly initialized student network. The student then learns its own intra-token features while the inter-token interactions are solely determined by the teacher’s attention maps. This method is less practical due to the need for both networks during inference. Attention Distillation allows the student network to learn its own attention maps by distilling the attention patterns from the teacher network using a cross-entropy loss. This makes it more practical as only the student network is needed during inference. The figure visually depicts the architecture and data flow for both methods, highlighting the key differences in how attention maps are handled.
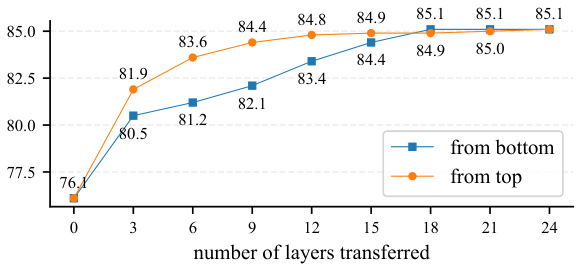
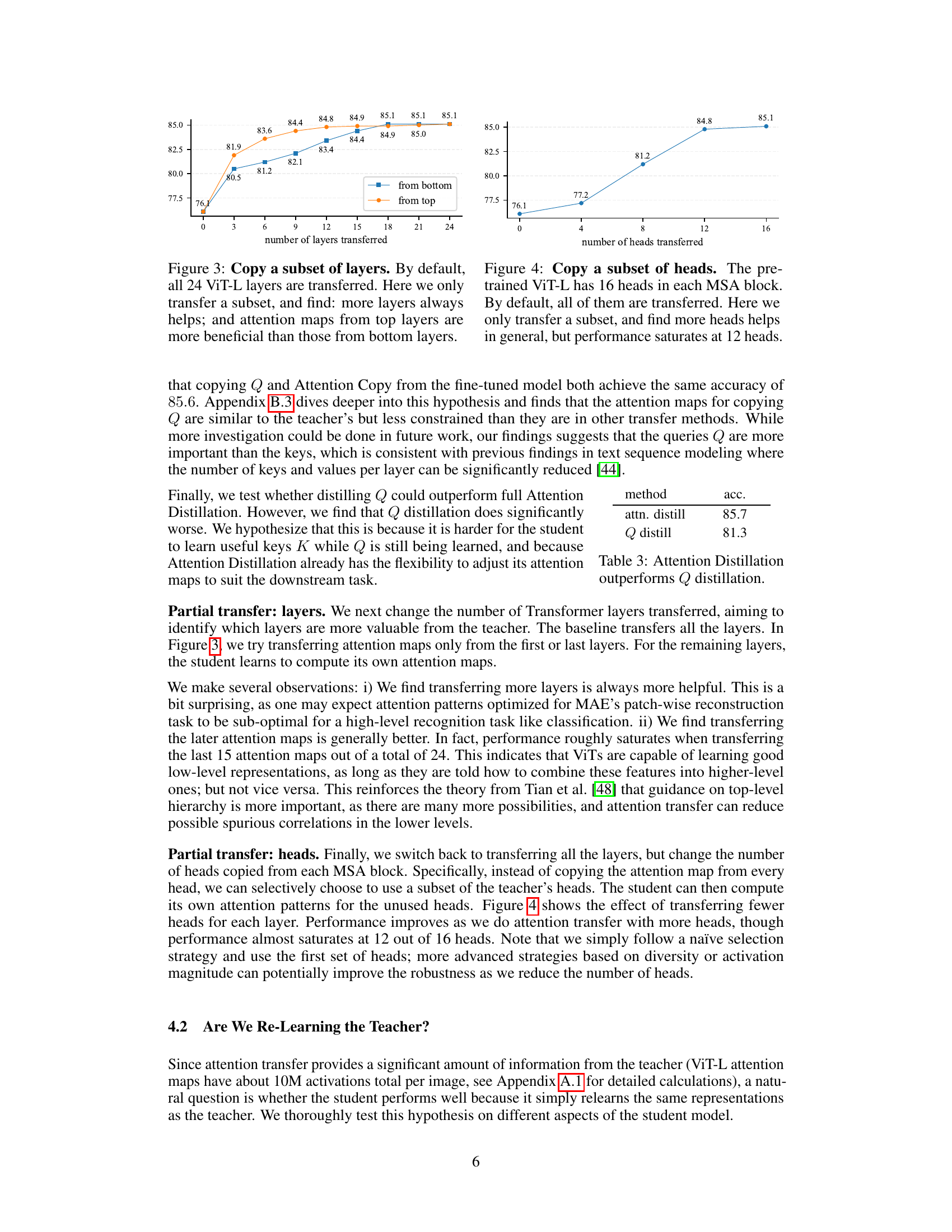
This figure shows the impact of transferring only a subset of layers when using attention transfer. The results indicate that using more layers generally improves performance, and that layers closer to the output of the network (top layers) are more crucial than those at the beginning of the network (bottom layers). It highlights the importance of the higher-level interactions learned during pre-training for downstream tasks.
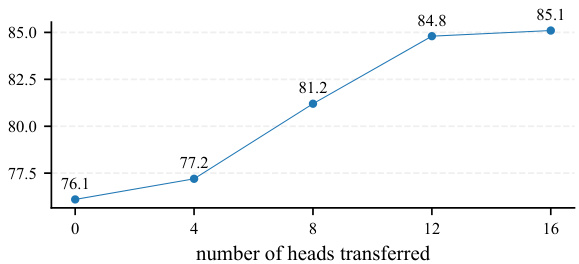
The figure shows the impact of the number of transferred heads on the accuracy of the model. The x-axis represents the number of heads transferred, and the y-axis represents the accuracy. The results indicate that increasing the number of transferred heads generally improves accuracy, but the improvement plateaus after 12 heads. This suggests a point of diminishing returns in using more heads, implying that beyond a certain point, the additional information provided by extra heads does not significantly improve model performance.

This figure demonstrates the effectiveness of attention transfer in Vision Transformers. It shows that using only the attention patterns from a pre-trained model (rather than the full model weights) achieves comparable performance on downstream tasks like ImageNet classification. The top part illustrates ‘Attention Copy,’ where the attention maps are directly copied. The bottom part shows ‘Attention Distillation,’ where the student model learns to mimic the teacher’s attention maps. Both methods significantly outperform training from scratch and nearly match the performance of fine-tuning the entire model.
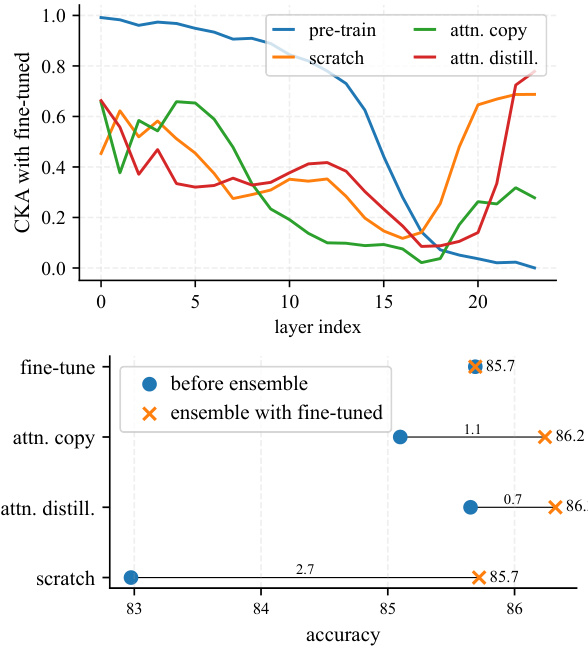
This figure demonstrates the effectiveness of attention transfer for Vision Transformers (ViTs). It shows that using only the attention patterns from a pre-trained teacher ViT is enough to achieve comparable downstream performance to fine-tuning the entire model. The top part illustrates Attention Copy where attention maps are directly copied, while the bottom shows Attention Distillation where the student learns to mimic the teacher’s attention patterns. Both methods significantly reduce the performance gap between training from scratch and full fine-tuning.

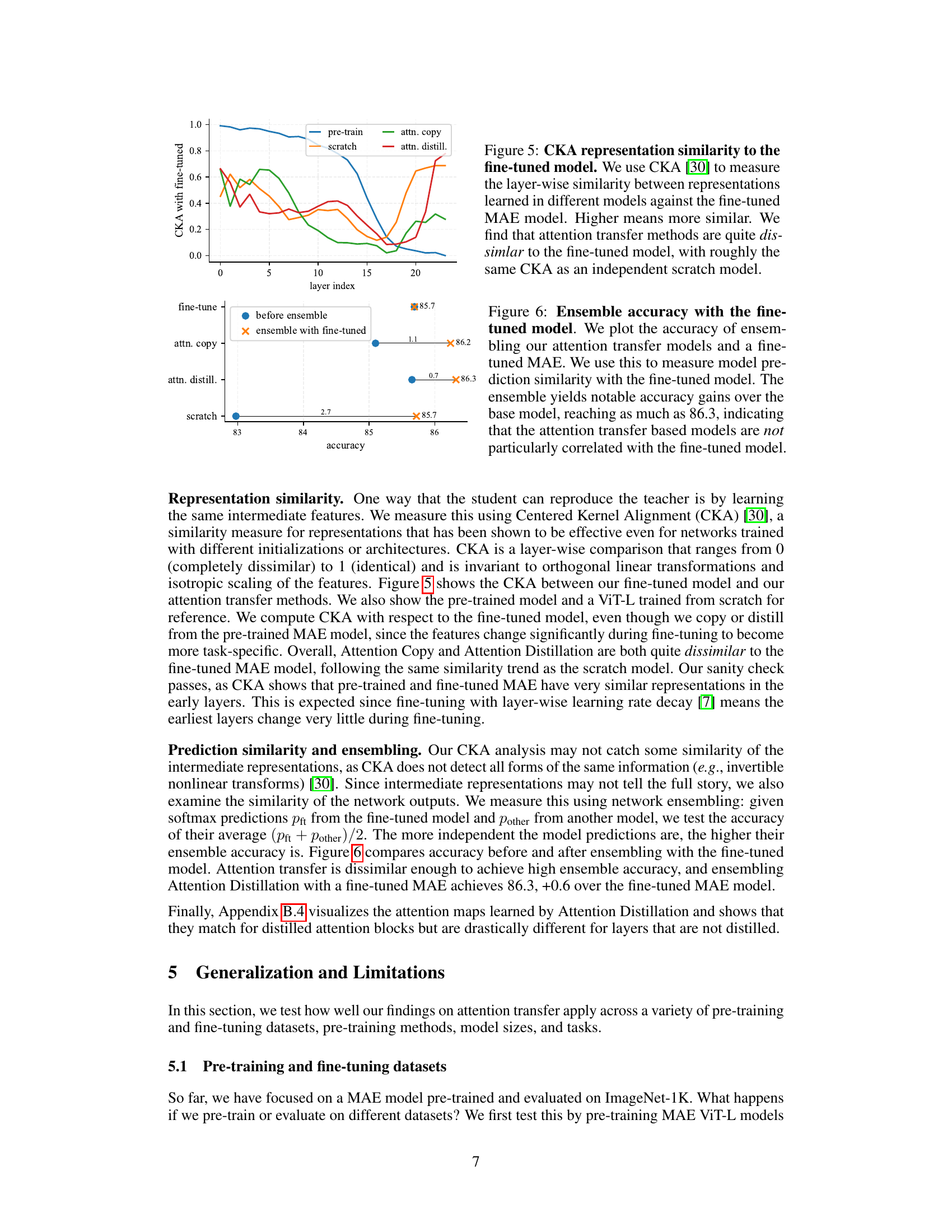
This figure compares the similarity of attention maps from different methods (pre-trained, attention distillation, copy Q, copy K, fine-tuned) to those of the pre-trained and fine-tuned MAE models using Jensen-Shannon Divergence (JSD). Four different head matching methods are shown to illustrate various aspects of the similarity. The results reveal that the copy Q method shows consistently low similarity to both pre-trained and fine-tuned models, despite its strong performance, suggesting potential limitations in the analysis due to the many possible ways to obtain the same layer output.

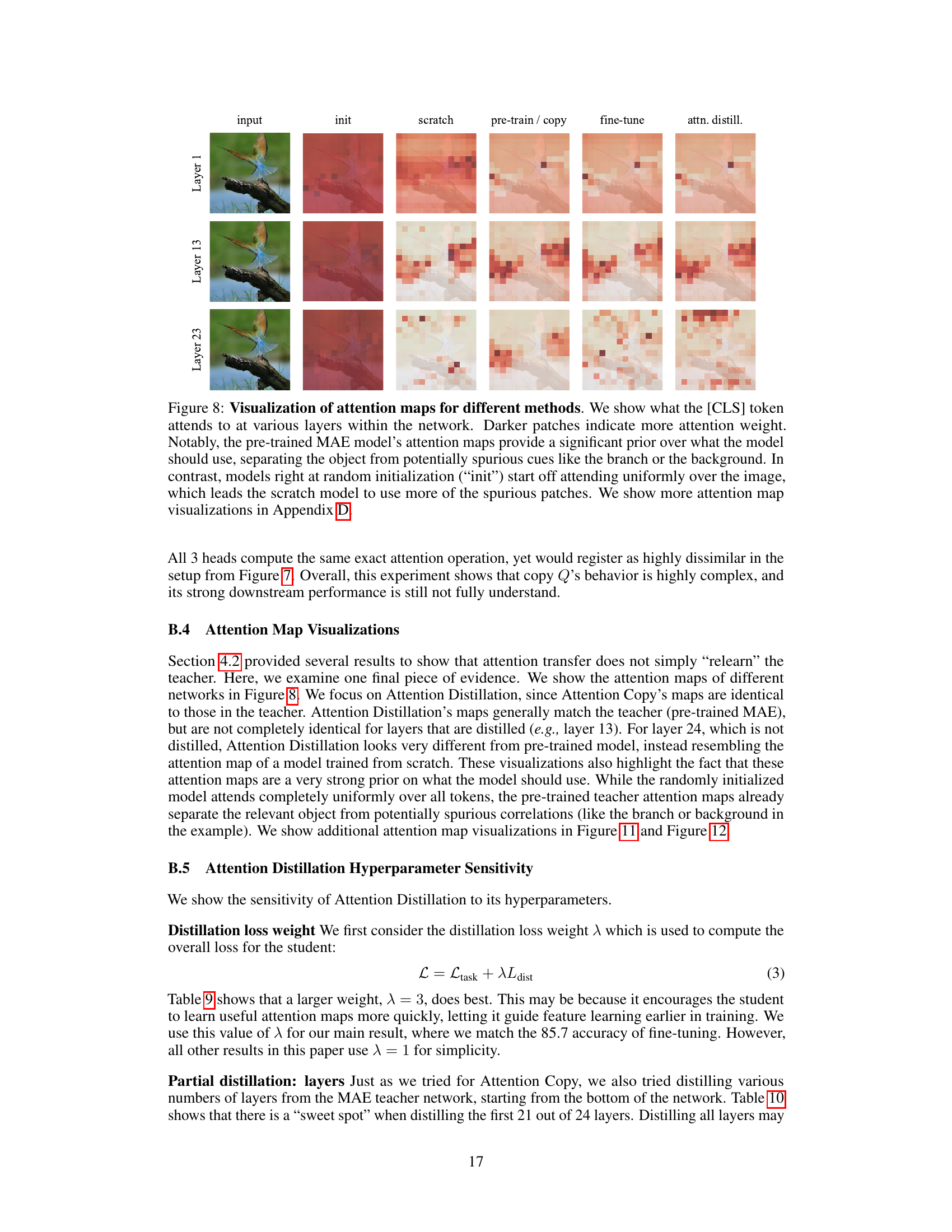
This figure visualizes the attention maps learned by different methods at various layers for a single image. It highlights how the pre-trained model uses attention to focus on the main subject, while the randomly initialized and scratch models attend more to background details. The attention maps from the fine-tuned and attention distillation methods show a combination of these approaches.

This figure visualizes attention maps for different methods (init, scratch, pre-train/copy, fine-tune, attn. distill) across various layers (1, 13, 23) for two different example images. The visualization highlights how attention focuses differently based on the method used. It shows the attention patterns from the pre-trained model providing a significant prior over the model’s attention, while the randomly initialized models start by attending uniformly over the image.

This figure visualizes attention maps for different methods (init, scratch, pre-train/copy, fine-tune, attn. distill) across various layers (Layer 1, Layer 13, Layer 23) for two example images. It demonstrates how different training approaches affect the attention patterns learned by the model. The pre-trained model (pre-train/copy) shows focused attention on relevant parts of the images, whereas the untrained model (init) and the model trained from scratch (scratch) exhibit more diffuse attention patterns. Fine-tuning and attention distillation show results closer to pre-trained model but still differing in their focus.
More on tables

This table presents the results of experiments where different parts of the self-attention mechanism (queries Q, keys K, values V) are transferred from a pre-trained teacher model to a student model during training. The goal is to determine the impact of each component on downstream task performance. The table shows that transferring only the queries Q achieves the best performance, exceeding that of transferring the attention map itself, demonstrating that the queries Q are the most important element in attention transfer for downstream tasks.
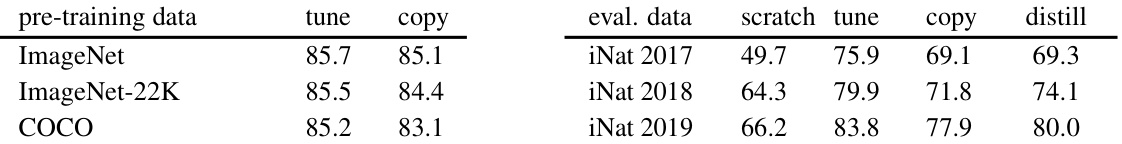
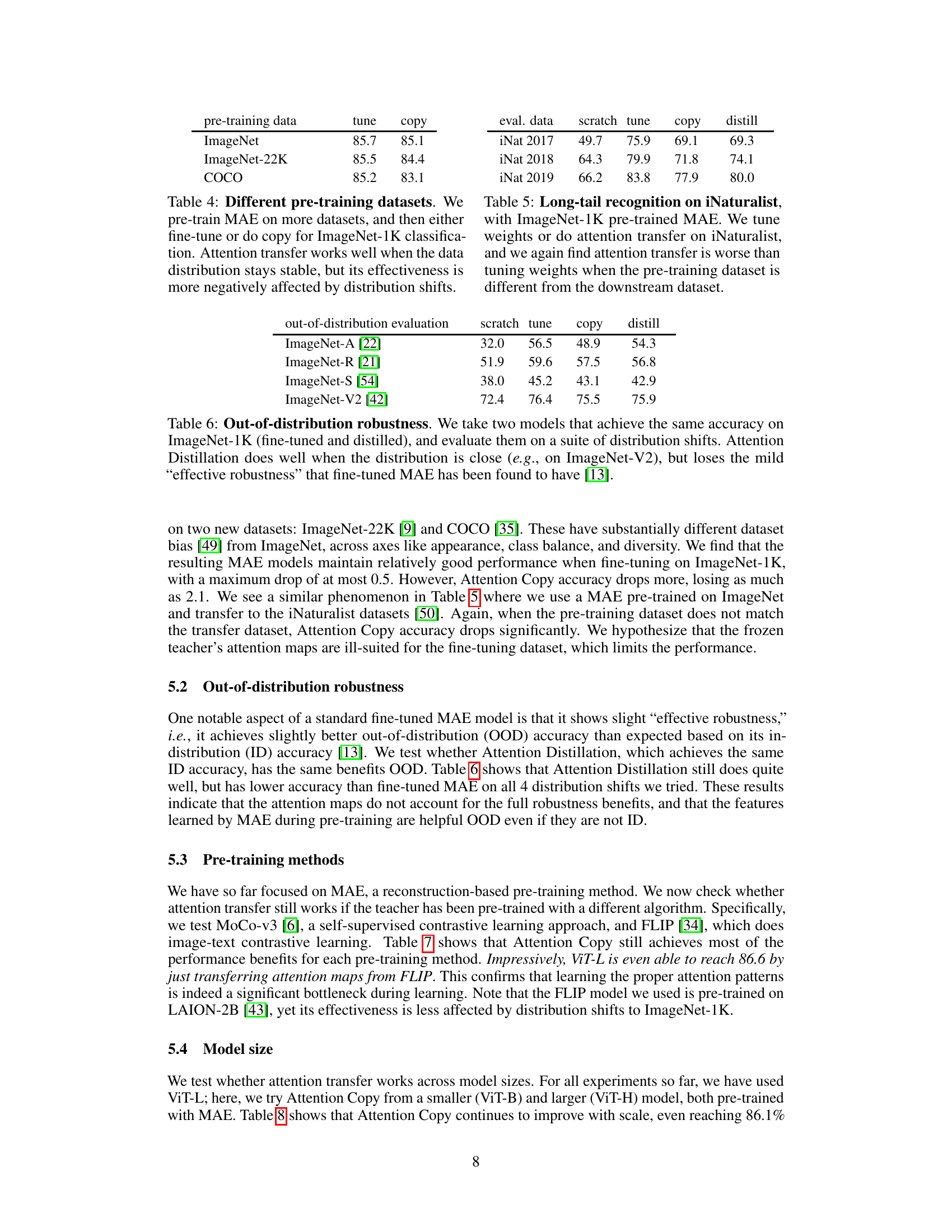
This table presents the ImageNet-1k classification accuracy results using different pre-training datasets (ImageNet, ImageNet-22K, COCO) and evaluation datasets (iNaturalist 2017, iNaturalist 2018, iNaturalist 2019). It compares the performance of fine-tuning and attention transfer methods (copy and distill) against a baseline of training from scratch. The results highlight the impact of distribution shifts between pre-training and downstream tasks on the effectiveness of attention transfer. When the pre-training and evaluation datasets are consistent (e.g., both ImageNet), attention transfer achieves comparable accuracy to fine-tuning. However, when there’s a distribution shift (e.g., pre-training on ImageNet and evaluating on iNaturalist), the effectiveness of attention transfer decreases significantly.
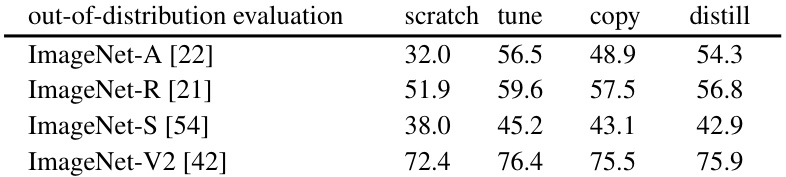
This table shows the out-of-distribution robustness of fine-tuned and distilled models. The models were first trained to achieve the same accuracy on ImageNet-1K, and then tested on four datasets representing different distribution shifts: ImageNet-A, ImageNet-R, ImageNet-S, and ImageNet-V2. The results show that while Attention Distillation performs well on similar distributions (ImageNet-V2), its performance degrades more significantly than the fine-tuned model’s when facing greater distribution shifts.

This table presents the ImageNet-1K classification accuracy results using different sized Vision Transformers (ViT-B, ViT-L, ViT-H). Three different training methods were used: fine-tuning, attention copy, and attention distillation. The results show that attention transfer methods scale effectively with model size, achieving comparable accuracy to fine-tuning, unlike training from scratch which saturates at smaller model sizes.

This table presents the results of object detection experiments on the COCO dataset using a Vision Transformer (ViT-B) model pre-trained with Masked Autoencoding (MAE). It compares the performance of three different training methods: training from scratch, fine-tuning the pre-trained model, and using attention transfer. The results are measured using two metrics: Average Precision (AP) for bounding boxes (bbox) and Average Precision (AP) for segmentation masks (mask). The numbers in parentheses show the improvement over the scratch method for each metric. The table demonstrates that attention transfer achieves a substantial portion of the performance gains obtained by fine-tuning, showcasing its effectiveness even in a more complex task like object detection.
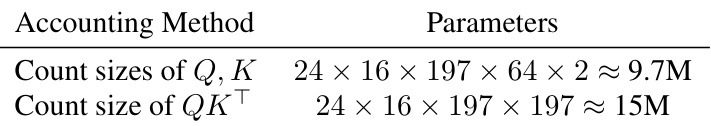
This table presents two different ways to estimate the number of activations transferred during attention transfer in a ViT-L teacher model. The first method considers the dimensions of the query (Q), key (K), and attention map (QKT) to calculate the total number of parameters. The second approach takes into account that QKT is low-rank, resulting in a reduced parameter count. Both methods show a significant number of transferred activations.

This table compares the memory usage and time per iteration for different training methods using a ViT-L model and a batch size of 16 on a 16GB NVIDIA GP100. It shows that weight fine-tuning is the most memory-efficient but also the fastest. Knowledge distillation and attention transfer have similar memory requirements and iteration times, which are slightly higher than fine-tuning.

This table shows the results of experiments where different dimensions of the attention maps are averaged before transfer to the student. Averaging across examples or query tokens significantly reduces performance, highlighting the importance of preserving the per-example, per-token detail in the attention maps.

This table compares the performance of Attention Distillation with a standard knowledge distillation method where the residual stream features are distilled. The results show that Attention Distillation significantly outperforms standard knowledge distillation, achieving an accuracy of 85.7 compared to 81.3. This highlights the importance of transferring attention maps specifically for downstream tasks rather than relying on a general feature distillation approach.

This table presents the main results of the paper, comparing the accuracy of different methods on the ImageNet dataset. It demonstrates that using only the attention patterns from a pre-trained model (Attention Copy and Attention Distillation) achieves comparable accuracy to fine-tuning the entire model. The results highlight the significance of attention mechanisms in Vision Transformers.
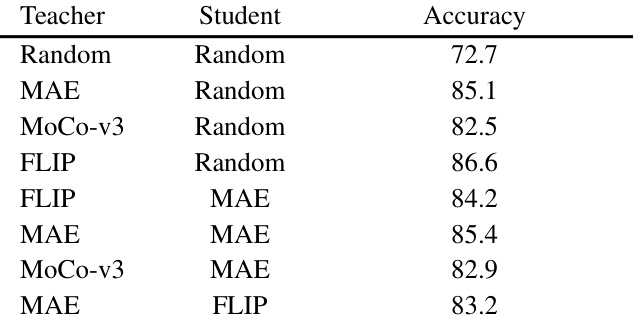
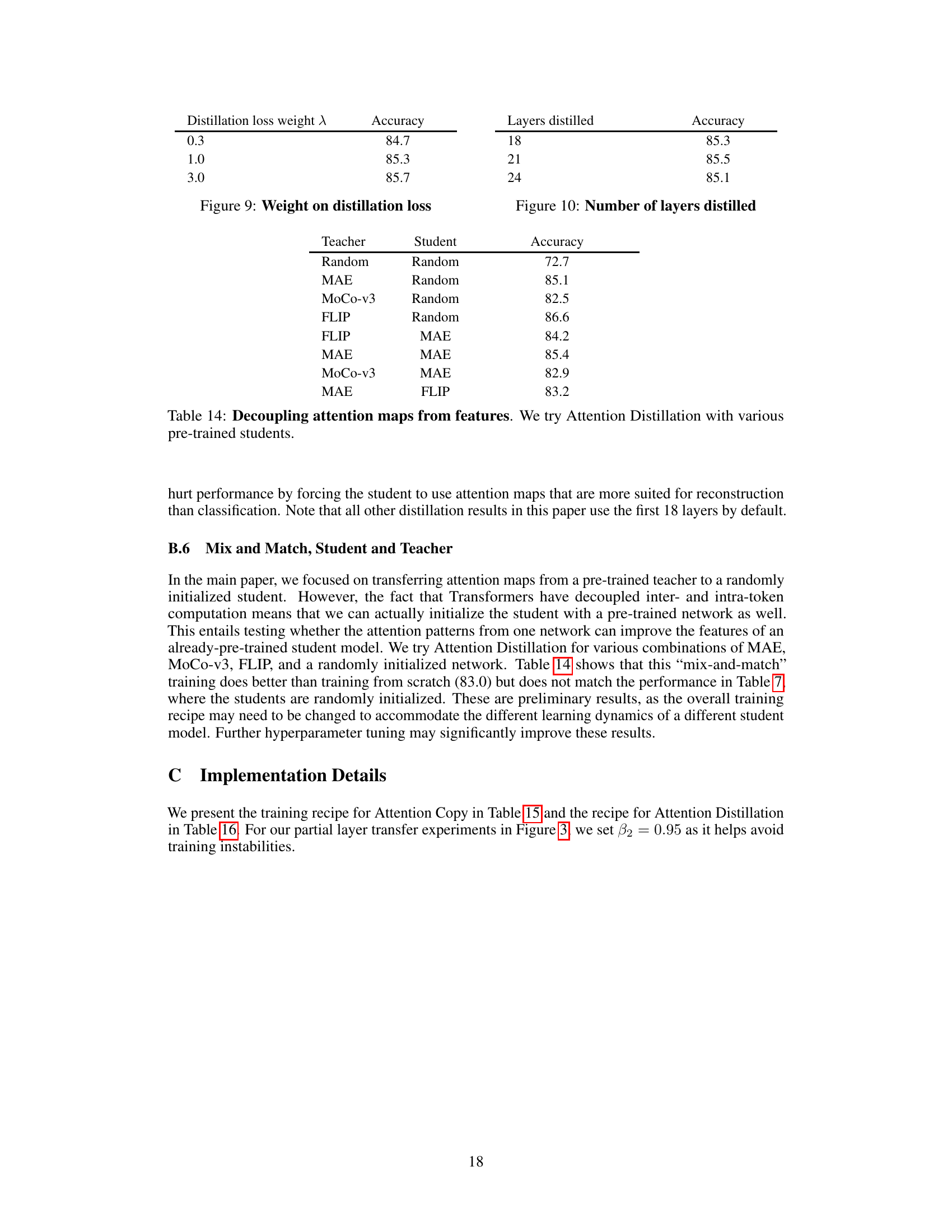
This table presents the ImageNet-1k top-1 accuracy results of using Attention Distillation with different combinations of pre-trained teacher and student models. The results demonstrate that the quality of pre-trained attention maps (from the teacher) significantly impacts performance, regardless of whether the student model is randomly initialized or pre-trained. The best performance is achieved when the teacher is pre-trained with FLIP and the student is randomly initialized, highlighting that the attention maps are the key factor that determines the overall performance.
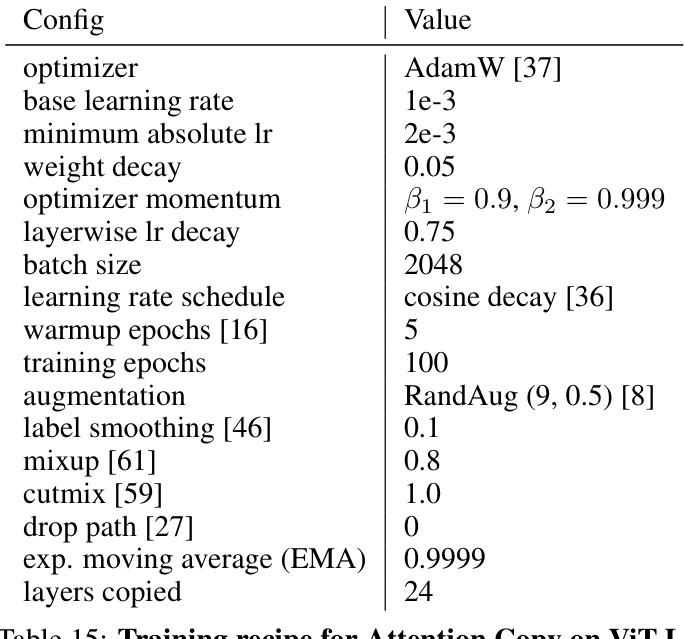
This table presents the hyperparameters used for training the Vision Transformer (ViT-L) model using the Attention Copy method. It details the optimizer, learning rate schedule, weight decay, momentum, batch size, data augmentation techniques (RandAug, Mixup, Cutmix), label smoothing, and other relevant settings. The table provides a comprehensive overview of the training configuration used for this specific experiment in the paper.
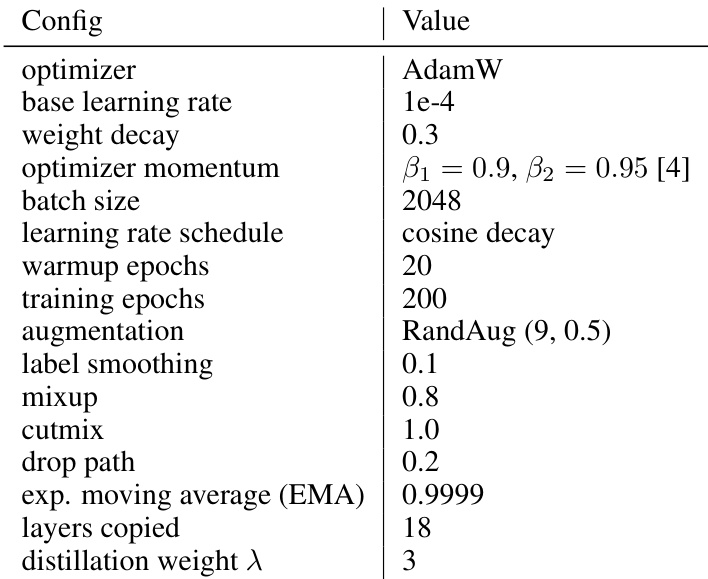
This table details the hyperparameters used for training the Vision Transformer (ViT-L) model using the Attention Distillation method. It includes settings for the optimizer (AdamW), learning rate, weight decay, momentum, batch size, learning rate schedule, warmup epochs, training epochs, data augmentation techniques (RandAug), label smoothing, mixup and cutmix regularization, dropout, exponential moving average (EMA), the number of layers where attention maps are copied, and the weight of the distillation loss.
Full paper#