TL;DR#
Large-scale sequence processing is computationally expensive, particularly for Transformer-based models. Existing efficient methods often compromise performance or limit input modality. This necessitates the development of novel architectures that balance computational efficiency with performance and generality.
The paper introduces BiXT, a novel bi-directional cross-attention Transformer architecture. BiXT leverages a naturally emerging attention symmetry between input tokens and latent variables for efficient information exchange, reducing computational cost and memory consumption. It achieves competitive performance on various tasks, outperforming larger competitors and achieving linear scaling with input size, demonstrating its effectiveness and generality across different input modalities and task types.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large-scale sequence data because it introduces BiXT, a novel Transformer architecture that scales linearly with input size, outperforming existing models on various tasks. Its efficiency and generality open exciting new avenues of research in areas such as vision and language processing, enabling the development of faster and more powerful AI systems.
Visual Insights#

🔼 The figure shows how different attention mechanisms focus on different parts of an image. (a) shows the input image. (b) demonstrates the areas that four different latent vectors attend to, while (c) shows which image areas attend to each of these latents. Finally, (d) presents the symmetric attention pattern resulting from the authors’ proposed bidirectional cross-attention. This illustrates the more efficient attention that arises by considering a more balanced approach between the latents and input tokens.
read the caption
Figure 1: Emerging patterns when attending both ways. (a) Input image. (b) depicts the areas of the image that 4 different latents attend to, while (c) inversely shows which image regions attend to these latents (transformed into the same coordinate system for ease of interpretation). (d) displays which areas & latents are symmetrically attended to using our proposed bi-directional cross-attention.
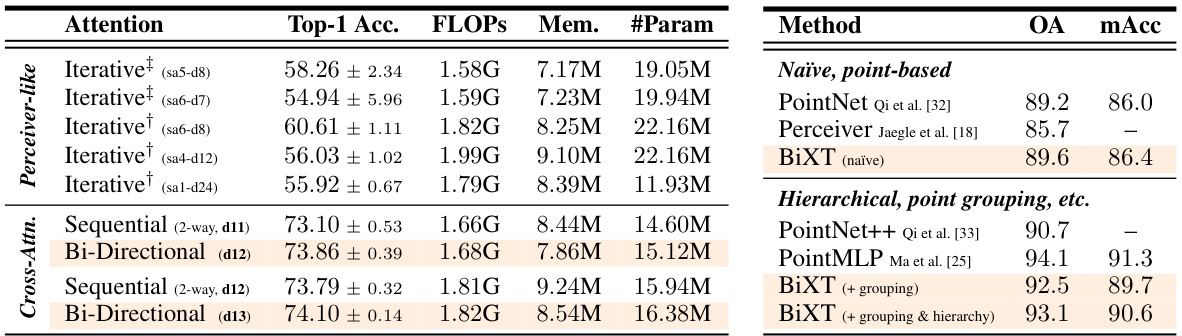
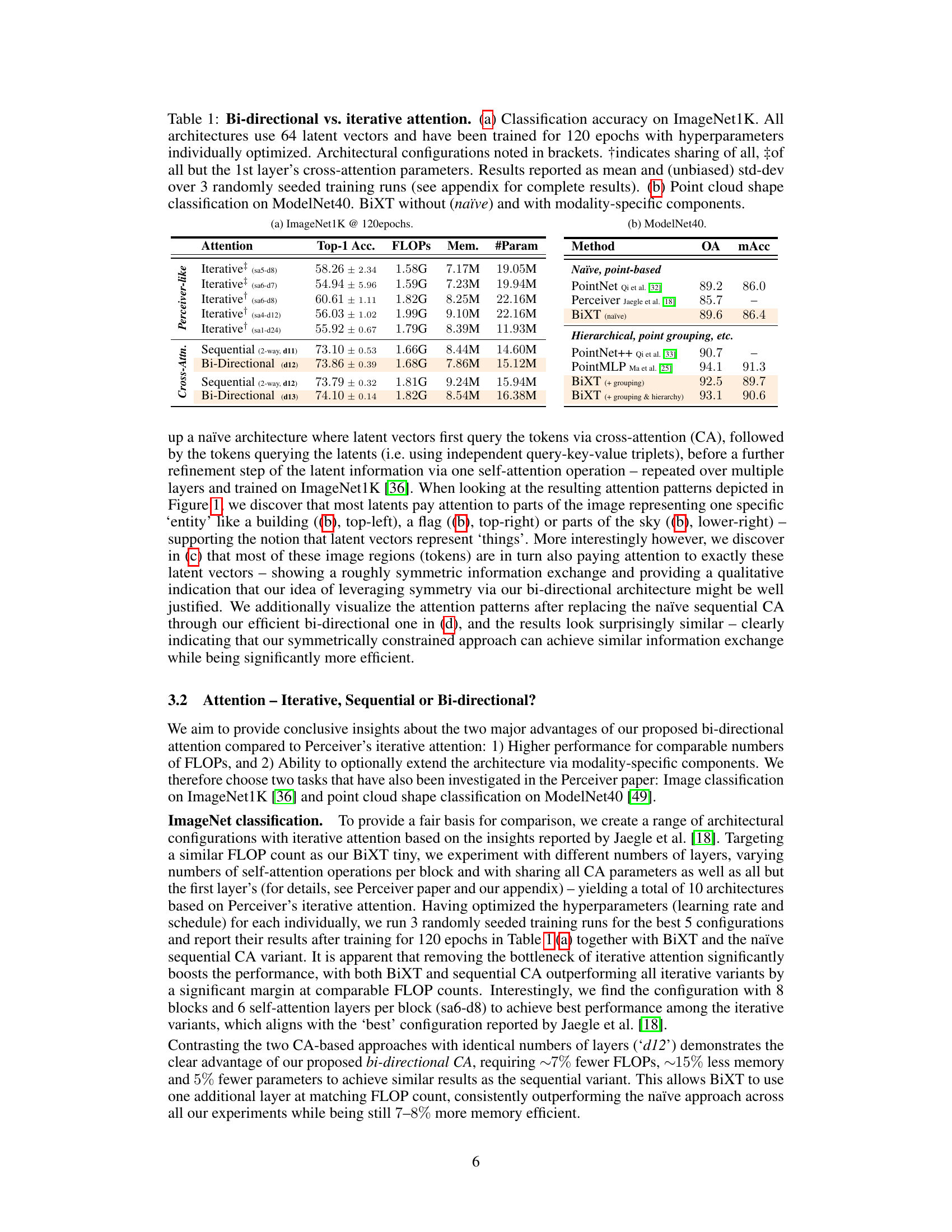
🔼 This table compares the performance of different attention mechanisms (iterative, sequential, and bi-directional) on two tasks: ImageNet classification and ModelNet40 point cloud shape classification. It shows that the bi-directional approach achieves competitive accuracy using fewer FLOPs and parameters. The table also demonstrates the effect of adding modality-specific components to the BiXT architecture on the point cloud task.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
In-depth insights#
BiXT Architecture#
The BiXT architecture is a novel approach to Transformer networks designed for processing long sequences efficiently. It cleverly combines the strengths of Perceiver-like architectures (linear scaling with input size) and full Transformers (high performance). The core innovation is the bi-directional cross-attention module, which simultaneously refines both input tokens and latent variables through a single attention matrix computation. This eliminates the iterative attention bottleneck found in Perceivers, enabling a significant speedup. The resulting architecture is symmetric and efficient, leveraging a naturally emerging attention symmetry between latents and tokens. It’s designed as a ladder-like structure, allowing ‘what’ (latent vectors) and ‘where’ (input tokens) to develop simultaneously across layers, making it suitable for various tasks like classification and segmentation. The BiXT architecture’s modularity allows for the flexible integration of task-specific components, further enhancing its applicability to diverse modalities. Overall, it demonstrates a promising approach to handle longer sequences efficiently, and outperforms larger competitors on various vision and sequence modeling tasks.
Cross-Attention#
Cross-attention, a mechanism allowing interaction between two different sets of data, plays a crucial role in many modern deep learning architectures. It’s particularly vital in scenarios involving multimodal data or sequences of varying lengths, where self-attention’s quadratic complexity becomes prohibitive. Cross-attention elegantly addresses this challenge by enabling efficient comparison and information exchange between the two input sequences (tokens and latents, in this case). This efficiency is key to processing longer sequences effectively. However, typical implementations often involve iterative attention, which, while linear in computational cost, can still introduce bottlenecks. The use of a bi-directional cross-attention mechanism enhances efficiency further by leveraging the naturally emergent attention symmetry, which reduces computational costs and the number of parameters required. This bi-directional approach effectively allows the simultaneous refinement of both ‘what’ (semantic information) and ‘where’ (location) aspects, leading to improved performance in various tasks involving dense and instance-based data.
Efficiency Analysis#
An efficiency analysis of a deep learning model like the one presented would involve a multifaceted approach. It should begin by quantifying the computational cost, often measured in floating point operations (FLOPs), comparing it to existing models with similar performance. Memory usage, another crucial aspect, should be analyzed, considering both parameters and activations. The scaling behavior of the model with respect to input size is key; ideally, a linearly scaling model is preferred over quadratically scaling ones. The inference speed during runtime should also be evaluated and compared. The analysis must extend beyond raw metrics to consider architectural choices that affect efficiency. For instance, the choice of attention mechanism (e.g., linear attention versus quadratic attention) significantly influences the efficiency. Finally, the study should investigate the potential for model compression techniques without compromising accuracy, such as pruning, quantization, or knowledge distillation. The combination of these factors provides a complete picture of the model’s efficiency.
Future Directions#
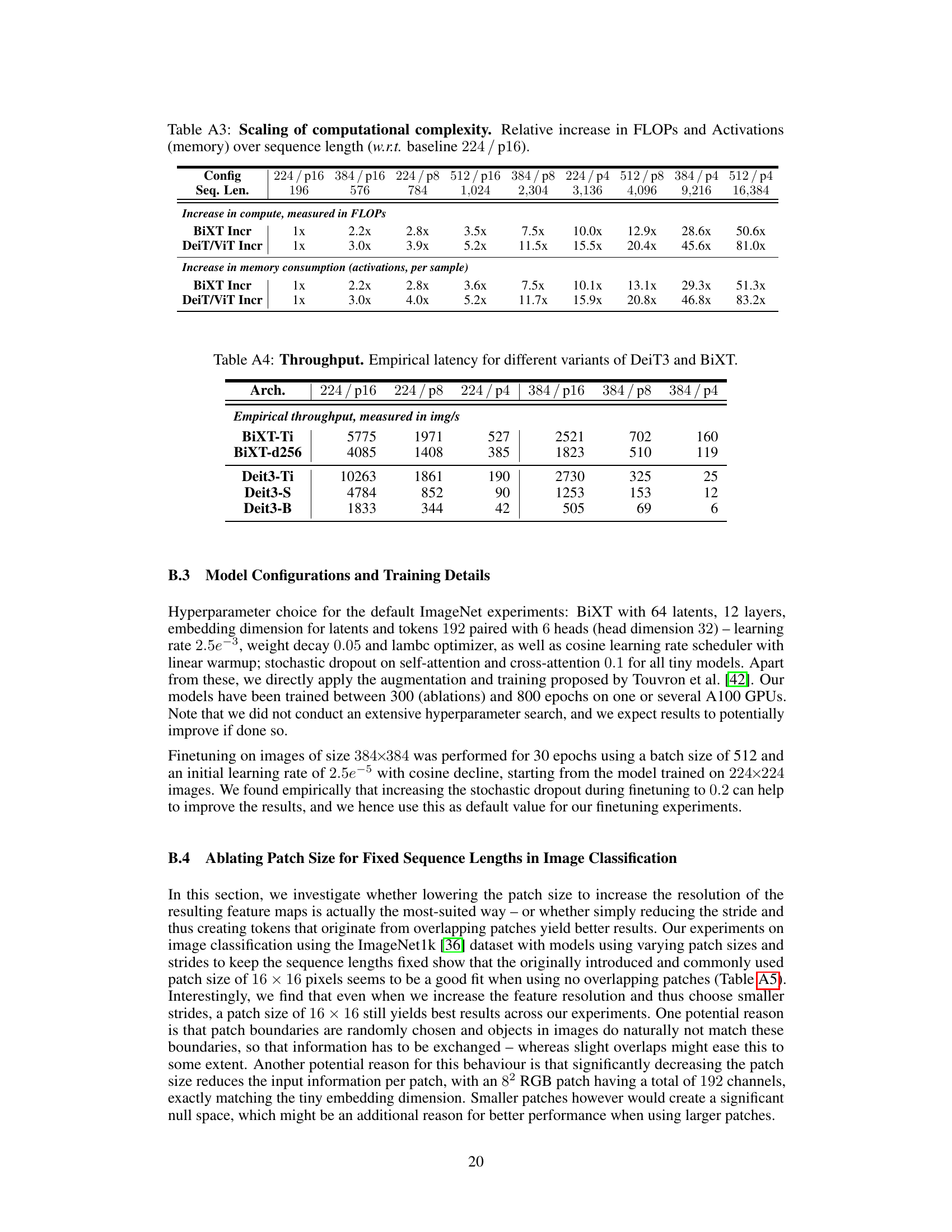
Future research could explore extending BiXT’s capabilities to handle even longer sequences, perhaps through hierarchical architectures or more sophisticated attention mechanisms. Investigating the impact of different tokenization strategies across various modalities would also be valuable. Furthermore, a deeper understanding of the interplay between the number of latents and the model’s performance is needed. Exploring the use of BiXT in diverse application domains, beyond those studied in this paper, is crucial to demonstrate its generalizability. Finally, in-depth analysis of the computational complexity across different hardware platforms would enhance BiXT’s practical applicability.
Limitations#
The study’s limitations center on the inherent constraints of the proposed BiXT architecture and the scope of experiments conducted. BiXT’s performance might not scale as efficiently to extremely long sequences compared to Perceiver-like models, particularly in resource-constrained scenarios. The investigation primarily focuses on image classification and related vision tasks, potentially limiting the generalizability of the findings. Further investigation is needed to understand how BiXT performs in other domains that demand processing extended sequences, such as natural language processing. Although BiXT’s architecture is designed for flexibility and modularity, integrating specialized components could compromise the method’s generality. The reliance on limited, ImageNet-centric evaluations and ablation studies could restrict the wider applicability and robustness of BiXT. Additional testing across diverse modalities and datasets would be crucial to validate the effectiveness more broadly. Finally, the empirical observation of symmetric attention patterns, which underpins BiXT’s efficiency, may not hold consistently across all data types and model configurations.
More visual insights#
More on figures

🔼 This figure illustrates the BiXT architecture, showing how input data is processed through a layer of the Bi-Directional Cross-Attention Transformer. The left panel displays the overall architecture, showing the flow of data through the latent self-attention, bi-directional cross-attention, and optional token refinement modules. The right panel provides a detailed view of the efficient bi-directional cross-attention module, highlighting how latent vectors and input tokens attend to each other simultaneously, resulting in a reduction in computational cost.
read the caption
Figure 2: BiXT architecture. (left) Input data passing through one layer of our Bi-Directional Cross-Attention Transformer. (right) Internal structure of proposed efficient bi-directional cross-attention.
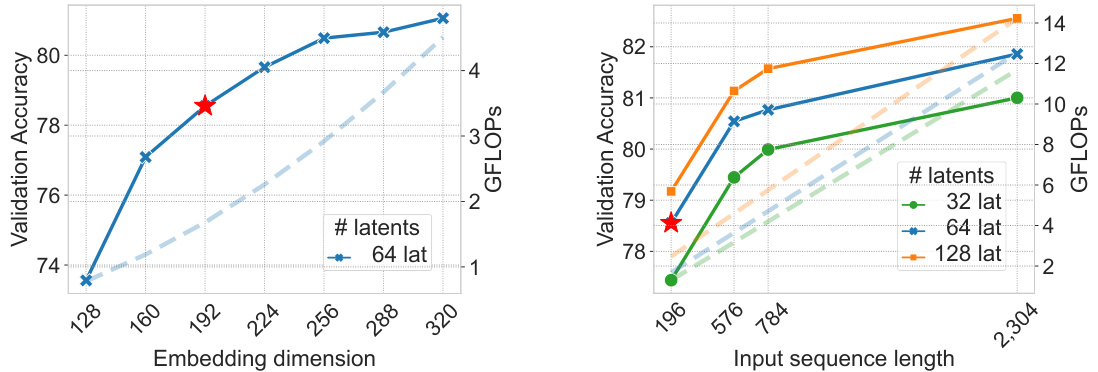
🔼 This figure shows how the validation accuracy of the BiXT model changes when varying the embedding dimension and the number of latents. It also shows the effect of changing the input sequence length on both accuracy and computational resources (GFLOPs). The results indicate that increasing embedding dimension and the number of latents leads to higher accuracy but also higher computational cost. The relationship between input sequence length and computational resources is linear.
read the caption
Figure 3: Scaling trends. Ablating the influence of embedding dimension, varying numbers of latents and sequence lengths for ImageNet1K classification. All models trained with shorter schedule (only 300 epochs) to save computational resources, and comparisons should therefore be performed relative to each other. Red star-markers correspond to BiXT-Ti/16 (Acc. 80.1) from Table 2. Validation accuracy represented through solid lines, while dashed lines indicate the computational resources.

🔼 This figure shows the BiXT architecture, illustrating how input data is processed through a layer of the Bi-Directional Cross-Attention Transformer. The left side displays the overall architecture, showing how latent vectors and input tokens are processed through self-attention and cross-attention modules. The right side details the internal workings of the efficient bi-directional cross-attention module, illustrating how latent vectors and tokens simultaneously attend to and refine each other, enabling efficient information exchange. The approximate symmetry in the attention patterns between latents and tokens allows computation of the attention matrix only once.
read the caption
Figure 2: BiXT architecture. (left) Input data passing through one layer of our Bi-Directional Cross-Attention Transformer. (right) Internal structure of proposed efficient bi-directional cross-attention.

🔼 This figure illustrates the BiXT architecture, showing how input data (images, point clouds, or text) is processed through a layer of the Bi-Directional Cross-Attention Transformer. The left panel shows the overall architecture: Input data is tokenized, then passed through a bi-directional cross-attention module where latent vectors and input tokens interact simultaneously. The latents are further refined through self-attention. Optionally, the tokens can also undergo additional refinement. The right panel provides a detailed view of the efficient bi-directional cross-attention module, illustrating how computations are performed to refine both latents and tokens efficiently using a shared attention matrix.
read the caption
Figure 2: BiXT architecture. (left) Input data passing through one layer of our Bi-Directional Cross-Attention Transformer. (right) Internal structure of proposed efficient bi-directional cross-attention.

🔼 The figure illustrates the BiXT architecture, showing how input data is processed through a layer of the bi-directional cross-attention transformer. The left side shows the overall architecture, while the right side zooms in on the efficient bi-directional cross-attention module. This module is designed to enable simultaneous refinement of both input tokens (‘where’) and latent vectors (‘what’) by computing a single attention matrix, leveraging the naturally emerging symmetry between them. This improves efficiency compared to methods using sequential, one-sided cross-attention.
read the caption
Figure 2: BiXT architecture. (left) Input data passing through one layer of our Bi-Directional Cross-Attention Transformer. (right) Internal structure of proposed efficient bi-directional cross-attention.

🔼 This figure shows how the attention mechanism works in different scenarios. (a) shows the input image. (b) and (c) demonstrate the attention patterns in a uni-directional setting, where latent variables attend to input tokens and vice versa, respectively. (d) presents the attention mechanism in the proposed bi-directional model. The symmetry between latent variables and input tokens is highlighted, demonstrating the efficiency of the model.
read the caption
Figure 1: Emerging patterns when attending both ways. (a) Input image. (b) depicts the areas of the image that 4 different latents attend to, while (c) inversely shows which image regions attend to these latents (transformed into the same coordinate system for ease of interpretation). (d) displays which areas & latents are symmetrically attended to using our proposed bi-directional cross-attention.

🔼 This figure shows the attention patterns when using different attention mechanisms in the proposed architecture. The input image is shown in (a). (b) and (c) show the attention patterns using a uni-directional attention mechanism, while (d) shows the attention patterns using the proposed bi-directional cross-attention mechanism. The bi-directional cross-attention mechanism is more efficient and achieves better performance than the uni-directional attention mechanism. The symmetric attention patterns naturally emerge between latents and tokens.
read the caption
Figure 1: Emerging patterns when attending both ways. (a) Input image. (b) depicts the areas of the image that 4 different latents attend to, while (c) inversely shows which image regions attend to these latents (transformed into the same coordinate system for ease of interpretation). (d) displays which areas & latents are symmetrically attended to using our proposed bi-directional cross-attention.

🔼 This figure shows how the attention mechanism works in different approaches. (a) shows the input image. (b) and (c) demonstrate a unidirectional approach where the latent variables attend to specific image areas, and vice versa. (d) illustrates the proposed bidirectional cross-attention, highlighting the symmetrical attention patterns between latents and image areas.
read the caption
Figure 1: Emerging patterns when attending both ways. (a) Input image. (b) depicts the areas of the image that 4 different latents attend to, while (c) inversely shows which image regions attend to these latents (transformed into the same coordinate system for ease of interpretation). (d) displays which areas & latents are symmetrically attended to using our proposed bi-directional cross-attention.
More on tables
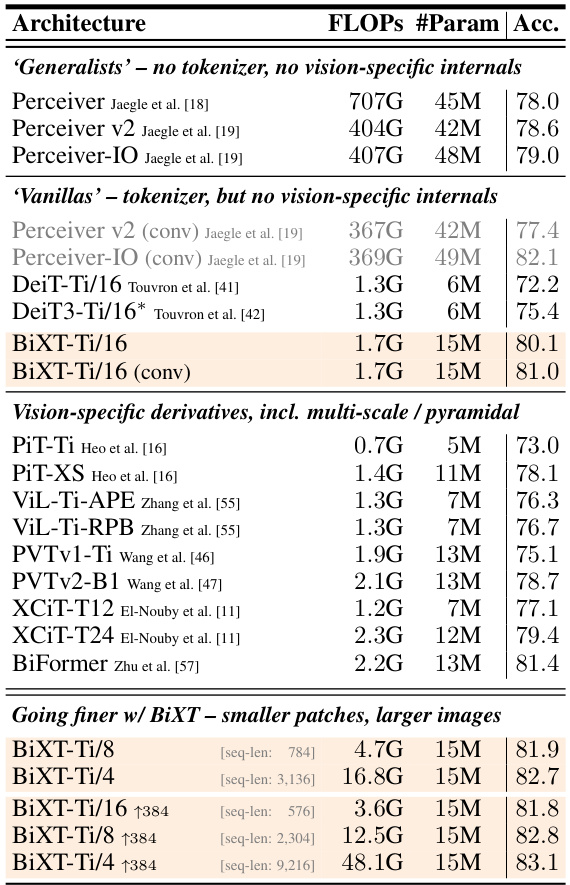
🔼 This table compares the performance of BiXT against other models using different attention mechanisms (iterative, sequential, and bi-directional) on ImageNet1K and ModelNet40 datasets. It shows that the BiXT model, which uses bi-directional cross-attention, achieves higher accuracy and efficiency. The table also demonstrates the impact of adding modality-specific components to the BiXT architecture.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.

🔼 This table compares the performance of BiXT with different attention mechanisms (bi-directional vs. iterative) on ImageNet1K classification and ModelNet40 point cloud shape classification. It shows top-1 accuracy, FLOPS, memory usage, and the number of parameters for various architectures. The ImageNet results highlight the advantage of BiXT’s bi-directional attention. The ModelNet40 results demonstrate BiXT’s adaptability through the addition of modality-specific components.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
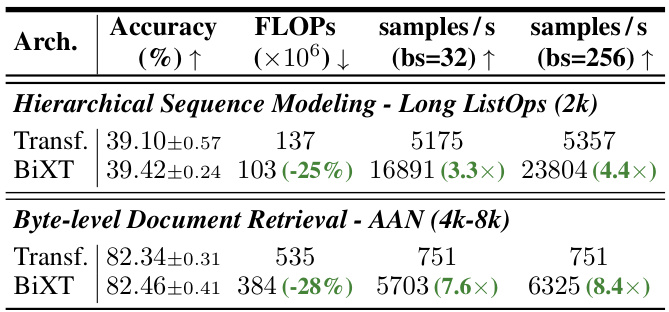
🔼 This table compares the performance of different attention mechanisms on ImageNet1K classification and ModelNet40 point cloud shape classification. It contrasts the performance of bi-directional cross-attention with iterative attention, highlighting the impact of different architectural choices on accuracy, FLOPs, memory usage, and the number of parameters. The ImageNet results show BiXT’s superiority in accuracy at a similar FLOP count compared to iterative methods. ModelNet40 results demonstrate BiXT’s ability to be competitive even without modality-specific components, showing improvement when these are added.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
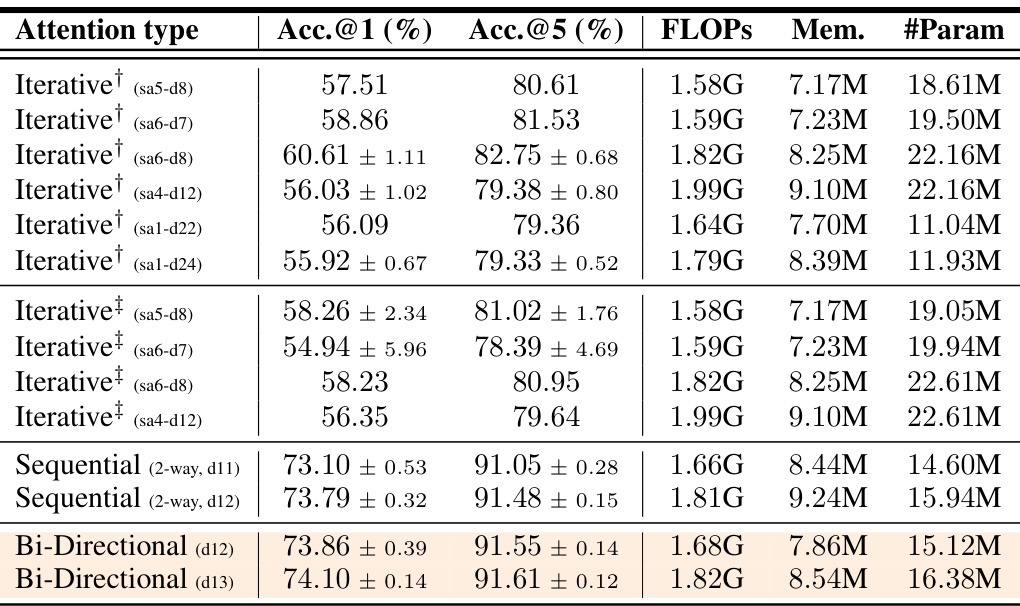
🔼 This table compares the performance of Bi-directional and Iterative attention mechanisms on two tasks: ImageNet1K classification and ModelNet40 point cloud shape classification. It shows the top-1 and top-5 accuracy, FLOPs, memory usage, and number of parameters for various configurations of each attention type. The ImageNet1K results highlight the improvement achieved by Bi-directional attention over iterative methods, even when considering parameter sharing. The ModelNet40 results demonstrate the flexibility of BiXT by showing its performance with and without modality-specific components.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
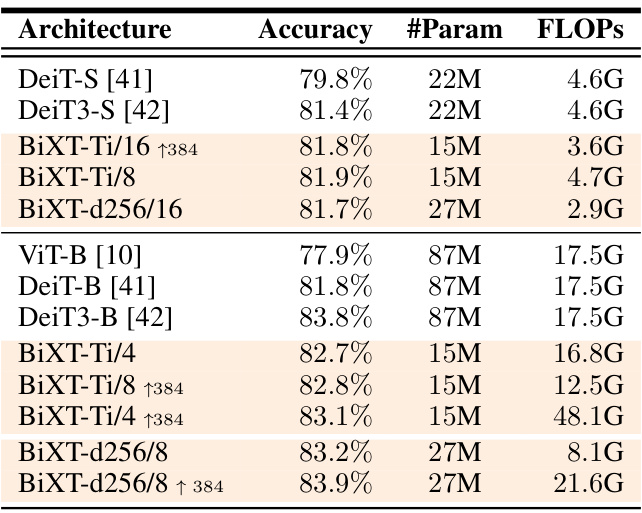
🔼 This table compares BiXT’s performance on ImageNet1K classification against other efficient transformer models, including Perceiver architectures. It highlights BiXT’s accuracy, FLOPs, and parameter counts, showcasing its efficiency compared to other models, especially at higher resolutions (384x384). The table also differentiates between models with and without convolutional tokenizers.
read the caption
Table 2: Classification on ImageNet1K using ‘few-FLOP’ Transformers. Note that we focus here on efficient models in the low FLOP and/or parameter regime. Perceiver architectures are included as contrast to our bi-directional attention. All methods have been trained on input resolutions of 2242, and ↑384 further fine-tuned on 3842. Note that different models may have received a different optimization effort. *result reproduced as not reported in original work. '(conv)' indicates the use of a convolutional tokenizer (see appendix for details).

🔼 This table compares the performance of BiXT with different attention mechanisms (iterative, sequential, and bi-directional) on ImageNet1K classification and ModelNet40 point cloud shape classification. It highlights the impact of bi-directional attention on accuracy and efficiency, showing that BiXT outperforms iterative approaches while being more memory-efficient and faster. The table also presents results with and without modality-specific components for BiXT on point cloud classification.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
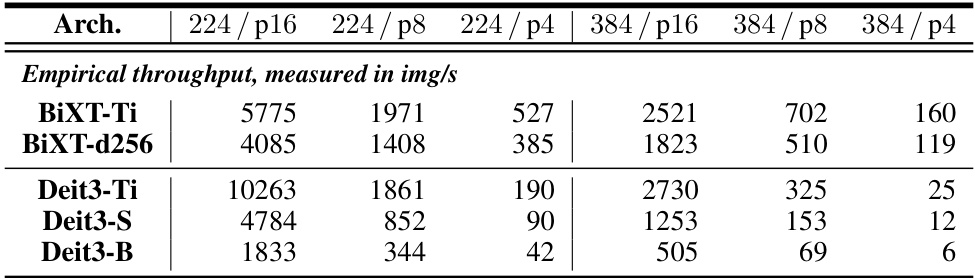
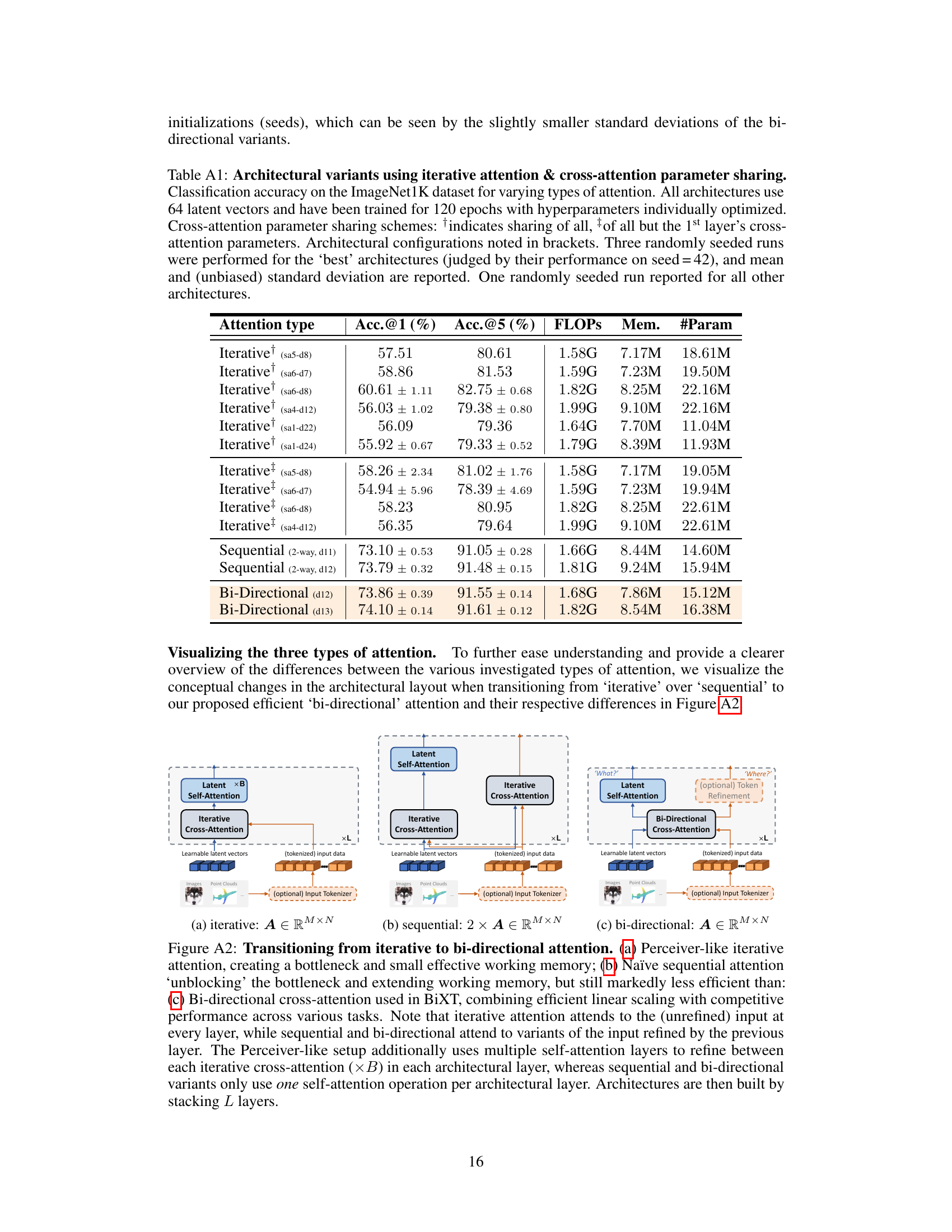
🔼 This table compares different attention mechanisms for image classification on ImageNet. It shows the top-1 and top-5 accuracy, FLOPs, memory usage, and number of parameters for various architectures using iterative, sequential, and bi-directional cross-attention. The results highlight the efficiency and performance gains of the bi-directional cross-attention approach.
read the caption
Table A1: Architectural variants using iterative attention & cross-attention parameter sharing. Classification accuracy on the ImageNet1K dataset for varying types of attention. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Cross-attention parameter sharing schemes: indicates sharing of all, of all but the 1st layer's cross-attention parameters. Architectural configurations noted in brackets. Three randomly seeded runs were performed for the 'best' architectures (judged by their performance on seed = 42), and mean and (unbiased) standard deviation are reported. One randomly seeded run reported for all other architectures.
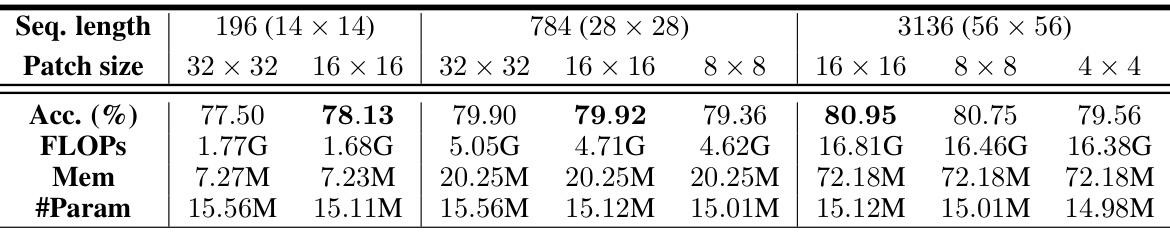
🔼 This table compares different attention mechanisms (iterative, sequential, and bi-directional) used in the ImageNet1K classification task. It shows the top-1 and top-5 accuracy, FLOPs, memory usage, and the number of parameters for various architectural configurations. The results highlight the trade-offs between accuracy, efficiency, and architectural choices.
read the caption
Table A1: Architectural variants using iterative attention & cross-attention parameter sharing. Classification accuracy on the ImageNet1K dataset for varying types of attention. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Cross-attention parameter sharing schemes: indicates sharing of all, of all but the 1st layer's cross-attention parameters. Architectural configurations noted in brackets. Three randomly seeded runs were performed for the 'best' architectures (judged by their performance on seed = 42), and mean and (unbiased) standard deviation are reported. One randomly seeded run reported for all other architectures.
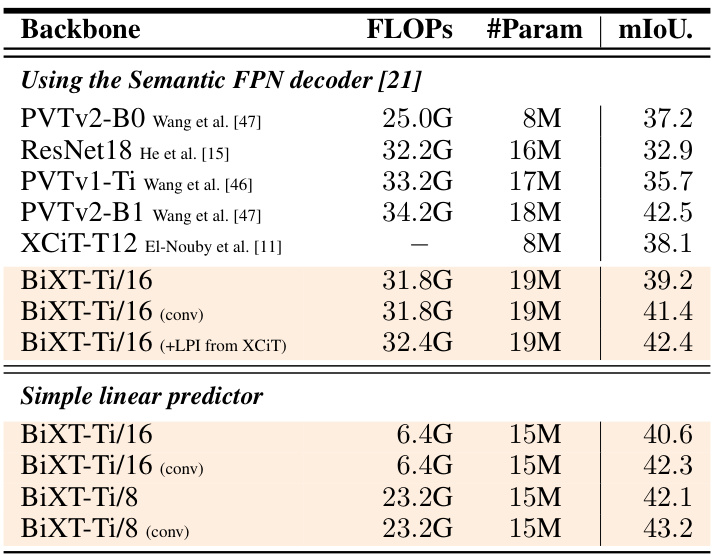
🔼 This table compares the performance of BiXT with iterative and sequential attention methods on ImageNet1k and ModelNet40 datasets. Part (a) focuses on ImageNet1k classification accuracy, comparing different configurations of iterative attention against BiXT’s bi-directional approach, highlighting the impact of FLOPs, memory usage and the number of parameters. Part (b) shows the results on ModelNet40 point cloud shape classification, contrasting the performance of BiXT with and without additional modality-specific components.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.

🔼 This table compares the performance of different attention mechanisms (iterative, sequential, and bi-directional) on image classification (ImageNet) and point cloud shape classification (ModelNet40). It shows that BiXT achieves competitive accuracy with fewer FLOPS and parameters, particularly when incorporating modality-specific components. The table highlights the trade-off between computational efficiency and performance, demonstrating BiXT’s advantage in resource-constrained settings.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
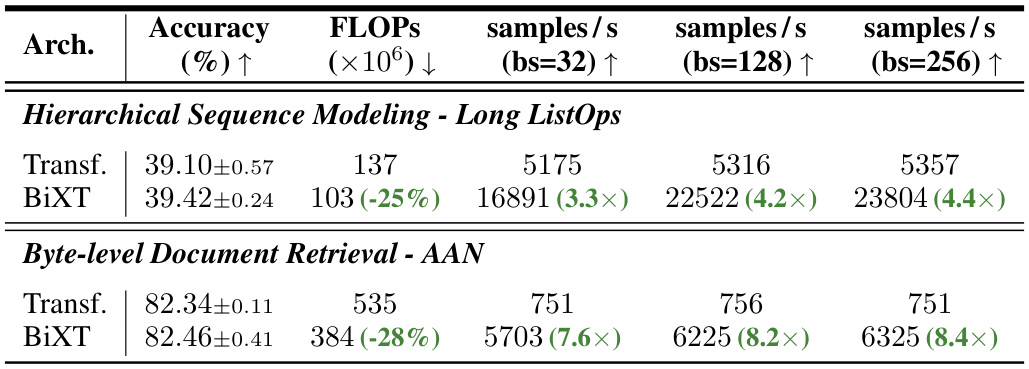
🔼 This table compares the classification accuracy of different attention mechanisms on ImageNet1K and ModelNet40 datasets. It contrasts the performance of bi-directional attention with iterative attention approaches, highlighting the efficiency and accuracy gains achieved by the proposed bi-directional cross-attention. The table also shows the impact of adding modality-specific components to the BiXT architecture for point cloud data.
read the caption
Table 1: Bi-directional vs. iterative attention. (a) Classification accuracy on ImageNet1K. All architectures use 64 latent vectors and have been trained for 120 epochs with hyperparameters individually optimized. Architectural configurations noted in brackets. †indicates sharing of all, ‡of all but the 1st layer's cross-attention parameters. Results reported as mean and (unbiased) std-dev over 3 randomly seeded training runs (see appendix for complete results). (b) Point cloud shape classification on ModelNet40. BiXT without (naïve) and with modality-specific components.
Full paper#