TL;DR#
Large language models (LLMs) rely heavily on key-value (KV) caches to store intermediate states, but these caches consume massive memory, especially for long sequences. Adaptive KV cache compression aims to reduce memory footprint by discerning the importance of tokens, preserving crucial information while aggressively compressing less significant ones. However, existing methods often suffer from significant performance degradation at high compression ratios due to inaccurate saliency identification and excessive overhead.
ZipCache tackles these challenges with a novel approach. It leverages a channel-separable tokenwise quantization for efficient compression and a normalized attention score as a precise metric for identifying salient tokens. This method decouples the saliency calculation from full attention scores, allowing compatibility with fast attention implementations. Experiments demonstrate ZipCache’s superior compression ratios, faster generation speed, and minimal performance losses, showcasing its effectiveness in addressing the memory bottleneck of LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) because it introduces an efficient and accurate method for compressing KV cache, a significant memory bottleneck in LLMs. The proposed ZipCache method offers superior compression ratios, faster generation speed, and minimal performance losses compared to existing techniques. This is important because it directly addresses a critical scalability challenge, enabling more efficient deployment of LLMs for various applications. Moreover, ZipCache opens up new avenues for investigating mixed-precision quantization and adaptive compression strategies in LLMs, further enhancing their efficiency and performance.
Visual Insights#
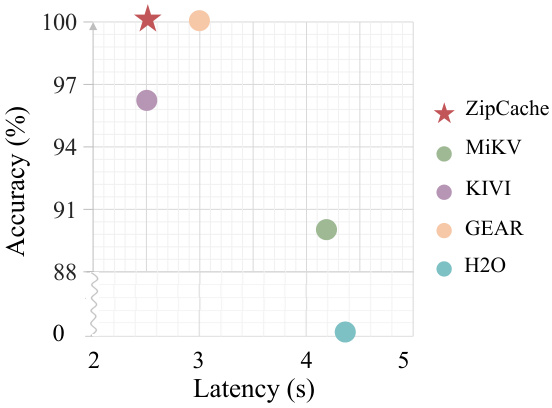
🔼 This figure compares the accuracy and latency of various KV cache compression methods, namely ZipCache, MiKV, KIVI, GEAR, and H2O. The data was collected using the LLaMA3-8B model on the Line Retrieval dataset. The plot shows that ZipCache achieves the best balance of high accuracy and low latency, outperforming the other methods.
read the caption
Figure 1: Accuracy and efficiency comparisons across various KV cache compression methods. Data is collected with LLaMA3-8B model on Line Retrieval dataset. Among these methods, ZipCache achieves the highest accuracy, generation speed and compression ratio. Details can be found in the supplementary material.

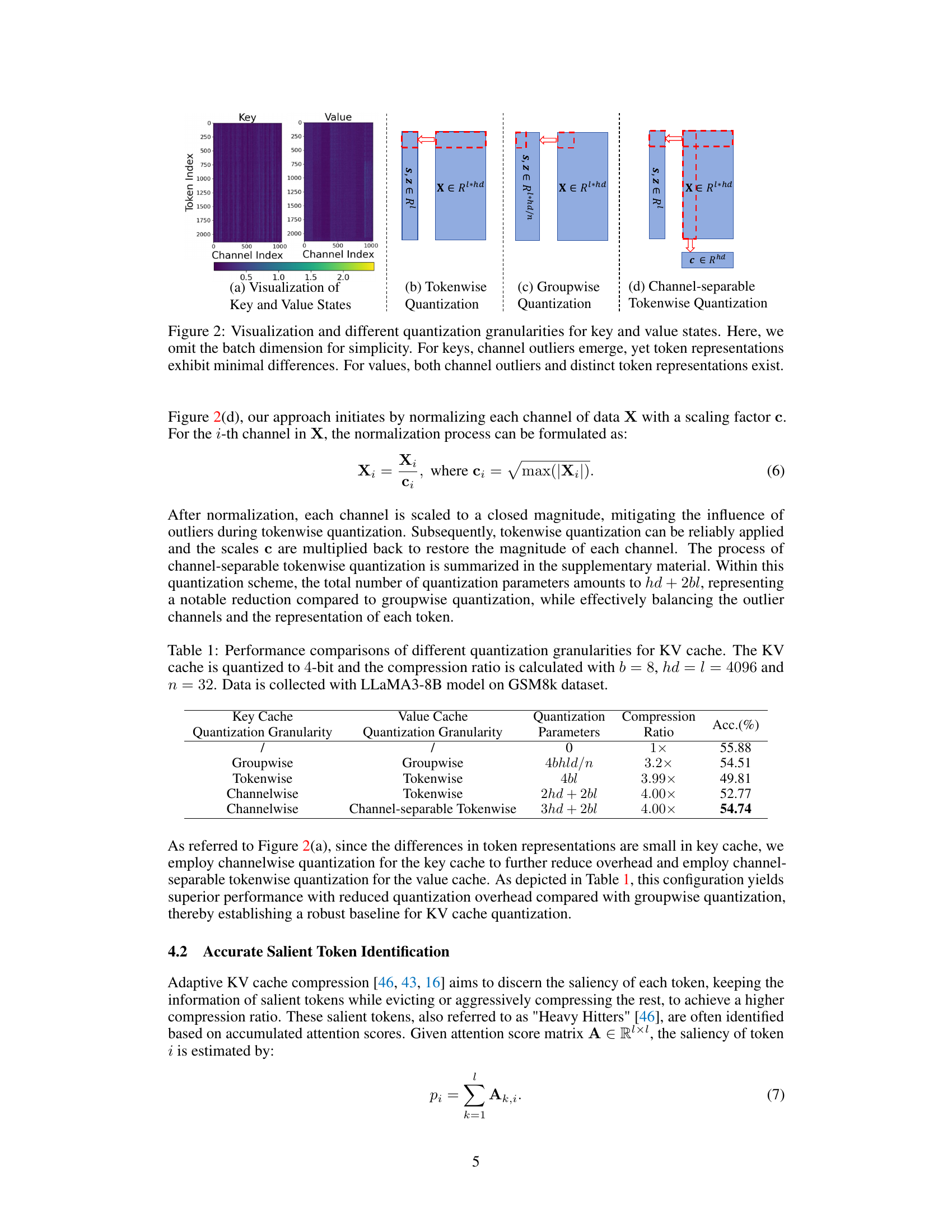
🔼 This table compares the performance of different KV cache quantization methods: groupwise, tokenwise, channelwise, and channel-separable tokenwise quantization. It shows the number of quantization parameters, the compression ratio achieved, and the accuracy obtained for each method using the LLaMA3-8B model on the GSM8k dataset. The table highlights the trade-off between reducing the number of parameters (and thus memory usage) and maintaining accuracy.
read the caption
Table 1: Performance comparisons of different quantization granularities for KV cache. The KV cache is quantized to 4-bit and the compression ratio is calculated with b = 8, hd = l = 4096 and n = 32. Data is collected with LLaMA3-8B model on GSM8k dataset.
In-depth insights#
Adaptive KV Quantization#
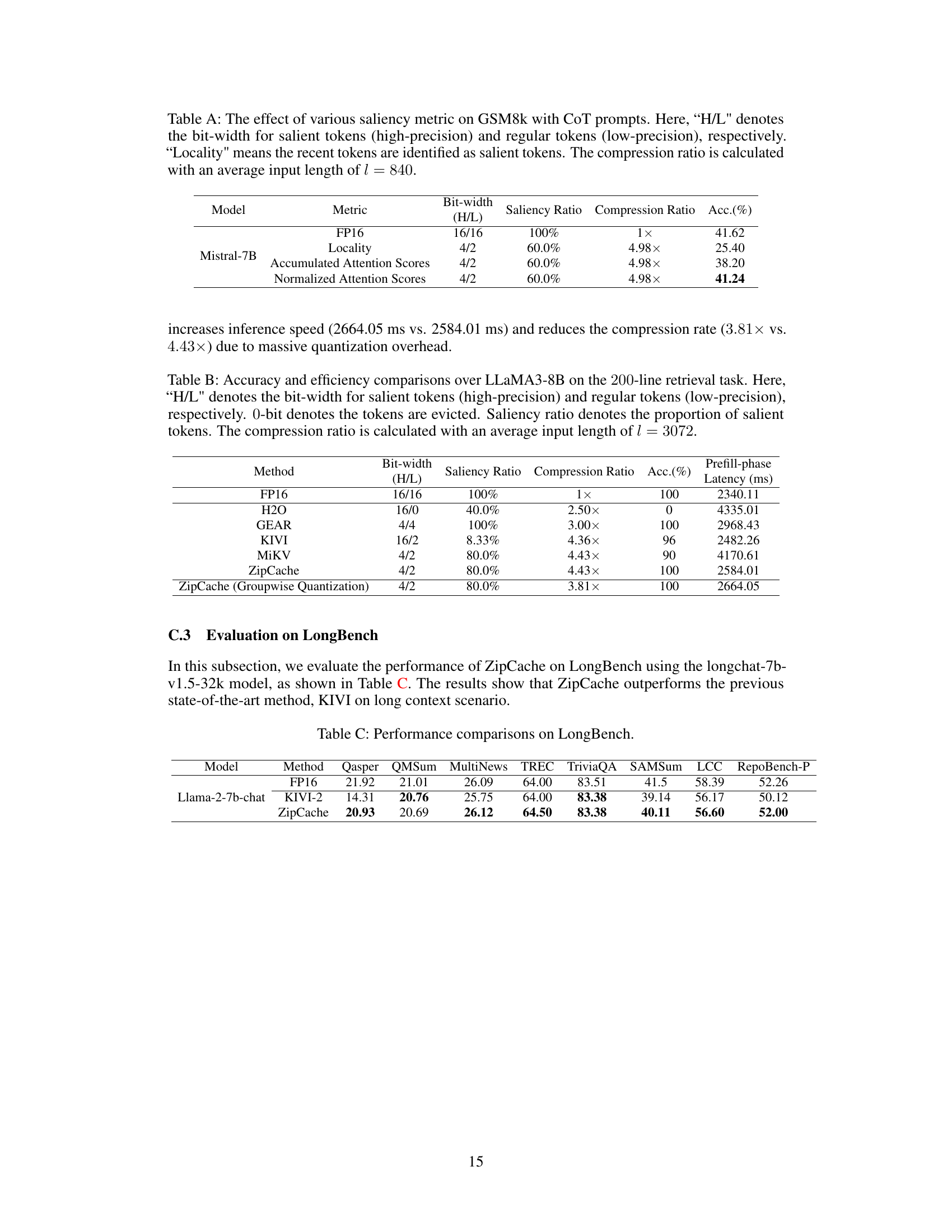
Adaptive KV quantization is a crucial technique for optimizing large language models (LLMs). It addresses the challenge of efficiently managing the key-value (KV) cache, which stores intermediate activations to accelerate inference but can consume significant memory. The core idea is to selectively quantize different tokens based on their importance. Tokens deemed crucial for accurate predictions, often identified through attention mechanisms or other saliency metrics, are preserved with higher precision. Conversely, less significant tokens can be aggressively quantized or even dropped, thus achieving significant compression. Effective adaptive quantization requires robust saliency identification, which is often the most computationally intensive part of the process. Additionally, the methods used to decouple the saliency estimations from the attention calculations themselves are critical for compatibility with high-performance attention implementations. This is an active area of research, and further improvements in saliency estimation and efficient quantization techniques will be key to realizing the full potential of LLMs in terms of both speed and memory efficiency.
Saliency Metric#
The effectiveness of adaptive KV cache compression hinges on accurately identifying salient tokens. A robust saliency metric is crucial for this task, as it dictates which tokens receive higher precision and thus consume more memory. Previous methods often relied on accumulated attention scores, a flawed approach susceptible to bias towards earlier tokens due to the lower triangular nature of the attention matrix. This bias unfairly favors initial tokens, potentially masking the true importance of later tokens. ZipCache addresses this by introducing a normalized attention score, which mitigates this positional bias and provides a more accurate representation of token saliency. By normalizing the accumulated scores, ZipCache ensures that the saliency metric is not unduly influenced by the token’s position within the sequence. This improvement leads to more effective compression by focusing resources on truly critical tokens while aggressively compressing less important ones.
Efficient Approximation#
The heading ‘Efficient Approximation’ suggests a crucial optimization within the paper’s methodology. It likely addresses the computational cost associated with calculating a precise saliency metric for each token in a large language model (LLM). The core idea is to avoid computing the full attention matrix, a computationally expensive operation, particularly for long sequences. Instead, the proposed approximation technique likely focuses on a subset of tokens (perhaps randomly sampled or strategically selected) and uses their attention scores to infer the saliency of the remaining tokens. This approach significantly reduces the computational complexity, making the algorithm faster and more memory-efficient. The trade-off lies in the accuracy of the approximation; it would be interesting to investigate how the performance varies with different sampling strategies and the choice of the subset of tokens. A critical aspect is the performance analysis - demonstrating that the approximation maintains the accuracy of the original method while achieving significant speed improvements. The effectiveness of the approximation likely hinges on the appropriate choice of the subset of tokens and the algorithm used for inferring saliency from that subset, hence a detailed explanation of those is critical to understanding the full impact of the ‘Efficient Approximation’ section.
ZipCache Framework#
The ZipCache framework introduces a novel approach to efficiently managing key-value (KV) caches in large language models (LLMs). Its core innovation lies in adaptive quantization, intelligently compressing less important tokens while preserving crucial information for optimal performance. This is achieved through normalized attention scores, a superior metric for identifying salient tokens, avoiding the biases of previous methods. Further enhancing efficiency, ZipCache employs channel-separable tokenwise quantization, drastically reducing memory overhead without compromising accuracy. The framework’s integration with fast attention implementations like FlashAttention minimizes performance loss, speeding up generation significantly. Ultimately, ZipCache delivers substantial improvements in both compression ratios and generation speed, setting a new state-of-the-art in LLM KV cache compression.
Future Directions#
Future research could explore adaptive quantization schemes that dynamically adjust bit-widths based on real-time token saliency, rather than pre-defined ratios. Investigating novel saliency metrics beyond normalized attention scores, potentially incorporating other contextual factors like token type or position, could further enhance accuracy. Efficient approximation techniques for saliency calculation are crucial, especially for extremely long sequences. The integration of ZipCache with other LLM optimization techniques, such as pruning or parameter-efficient fine-tuning, warrants investigation to maximize overall performance gains. Finally, a broader evaluation across a wider range of LLMs and downstream tasks is needed to assess the generalizability and robustness of the proposed method. The exploration of these areas would solidify ZipCache’s position as a leading approach for efficient and accurate KV cache compression.
More visual insights#
More on figures

🔼 This figure illustrates different quantization approaches for key and value states in LLMs. It highlights the existence of channel outliers and differences in token representations. (a) shows a visualization of key and value states, demonstrating the presence of outliers and variations. (b), (c), and (d) compare tokenwise, groupwise, and channel-separable tokenwise quantization, respectively, showing how each method handles these characteristics. The channel-separable tokenwise quantization is proposed as a more efficient method to address the challenges posed by outliers and variations.
read the caption
Figure 2: Visualization and different quantization granularities for key and value states. Here, we omit the batch dimension for simplicity. For keys, channel outliers emerge, yet token representations exhibit minimal differences. For values, both channel outliers and distinct token representations exist.
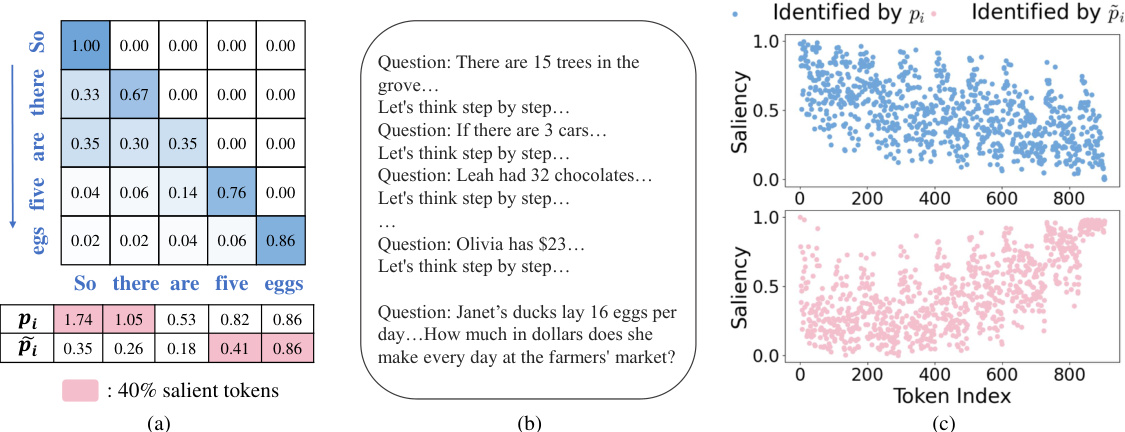
🔼 This figure illustrates the differences between accumulated attention scores and normalized attention scores in identifying salient tokens. Panel (a) uses a toy example to show how earlier tokens accumulate more attention scores due to the lower triangular nature of the attention matrix, leading to a bias towards earlier tokens. Panel (b) shows a real example from the GSM8k dataset, highlighting that important tokens (i.e., the final question) might not be identified as salient using accumulated attention scores. Panel (c) compares the probability of a token being selected as salient using both methods. This figure is key in supporting the paper’s claim that accumulated attention scores are inaccurate for identifying salient tokens, whereas normalized attention scores provide a more accurate representation.
read the caption
Figure 3: (a) A toy example to illustrate accumulated attention scores and normalized attention scores. Initial tokens have larger attention scores and more values to be accumulated. (b) A sample from GSM8k dataset with chain-of-thoughts (CoT) prompting. (c) The probability of each token being selected as a salient token, measured by both accumulated and normalized attention scores. Tokens correspond to the final question are identified as low saliency by accumulated attention scores.
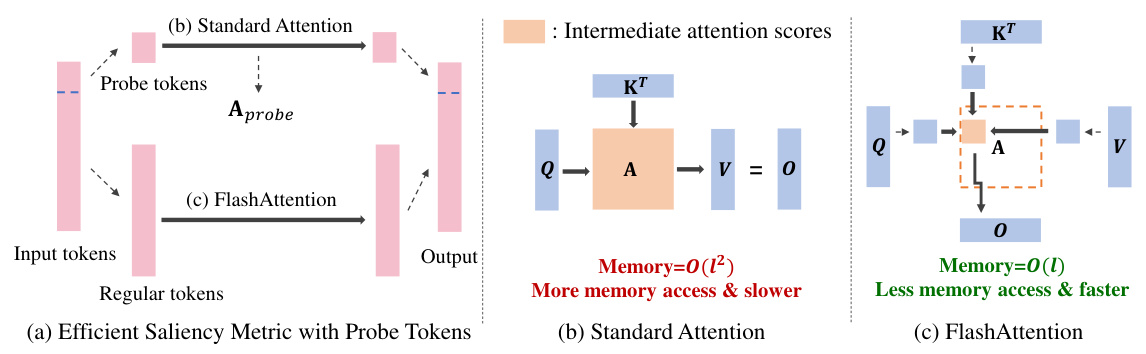
🔼 This figure illustrates the efficiency improvements achieved by ZipCache’s efficient saliency metric which uses probe tokens for faster computation. Panel (a) shows how ZipCache only computes attention scores for a subset of tokens (probe tokens), enabling the use of FlashAttention for faster computation of the remaining tokens. Panels (b) and (c) show the differences between standard attention and FlashAttention in terms of memory access and computational speed. FlashAttention’s block-wise computation significantly reduces the memory usage compared to standard attention.
read the caption
Figure 4: (a): Efficient saliency metric only requires attention scores of probe tokens through standard attention, enabling fast computation for the majority of tokens through FlashAttention. (b): In standard attention, full attention scores are computed before deriving the attention output. (c): FlashAttention avoids large attention matrix memory transfers by partitioning input matrices into blocks for incremental computation.
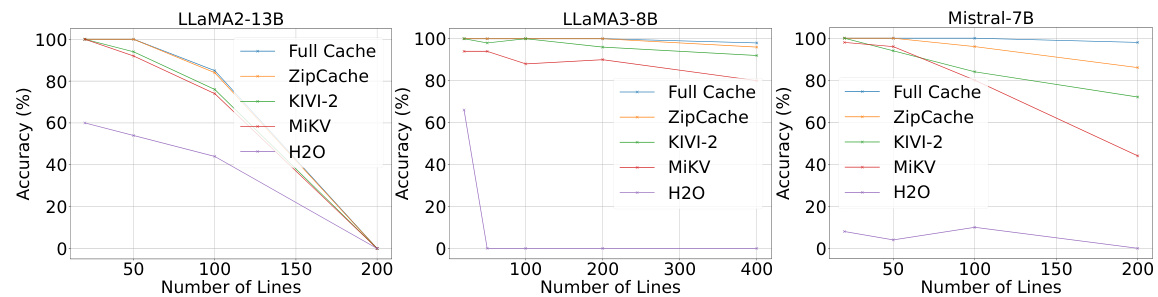
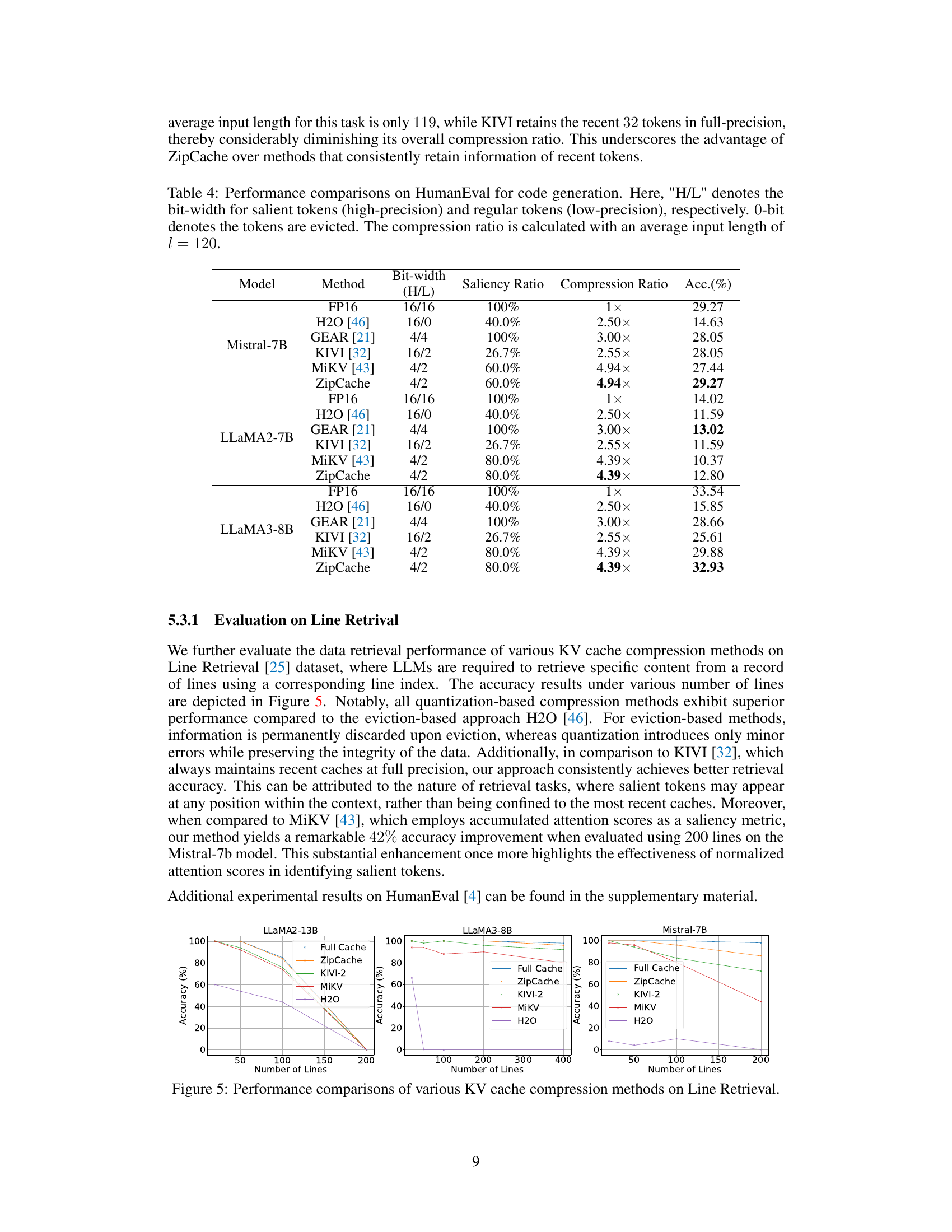
🔼 This figure compares the accuracy of various KV cache compression methods (ZipCache, KIVI-2, MiKV, H2O) against the full cache baseline on the Line Retrieval dataset. The x-axis represents the number of lines in the dataset, and the y-axis represents the accuracy achieved by each method. The results are shown for three different LLMs: LLaMA2-13B, LLaMA3-8B, and Mistral-7B. The figure visually demonstrates how ZipCache maintains high accuracy even at a high compression ratio, compared to other methods, particularly as the number of lines increases. This highlights the effectiveness of ZipCache in balancing accuracy and compression for retrieval tasks.
read the caption
Figure 5: Performance comparisons of various KV cache compression methods on Line Retrieval.
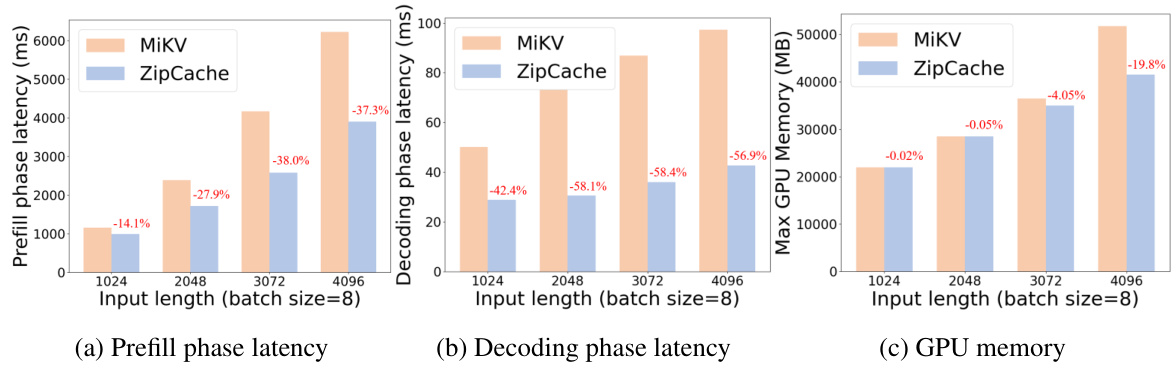
🔼 This figure shows a comparison of the prefill-phase latency, decoding-phase latency, and maximum GPU memory usage between MiKV and ZipCache across various input lengths (with a batch size of 8). The results demonstrate that ZipCache significantly reduces latency and memory usage compared to MiKV, highlighting the efficiency gains achieved by the proposed method.
read the caption
Figure 6: Comparisons of prefill-phase, decoding-phase latency and memory consumption between MiKV and ZipCache.
More on tables

🔼 This table presents the results of an experiment comparing different strategies for selecting ‘probe tokens’ in the ZipCache algorithm. The goal is to find the most efficient way to approximate the saliency of all tokens using only a small subset of probe tokens. The experiment uses the LLaMA3-8B model and the GSM8k dataset. The table shows that using a hybrid approach, combining random and recent tokens, yields the best performance in terms of accuracy.
read the caption
Table 2: Performance comparisons of various probe strategies. Data is collected from LLaMA3-8B model on GSM8k dataset. We quantize 40% salient tokens to 4-bit and the remaining 60% tokens to 2-bit. The proportion of probe tokens is 10%.
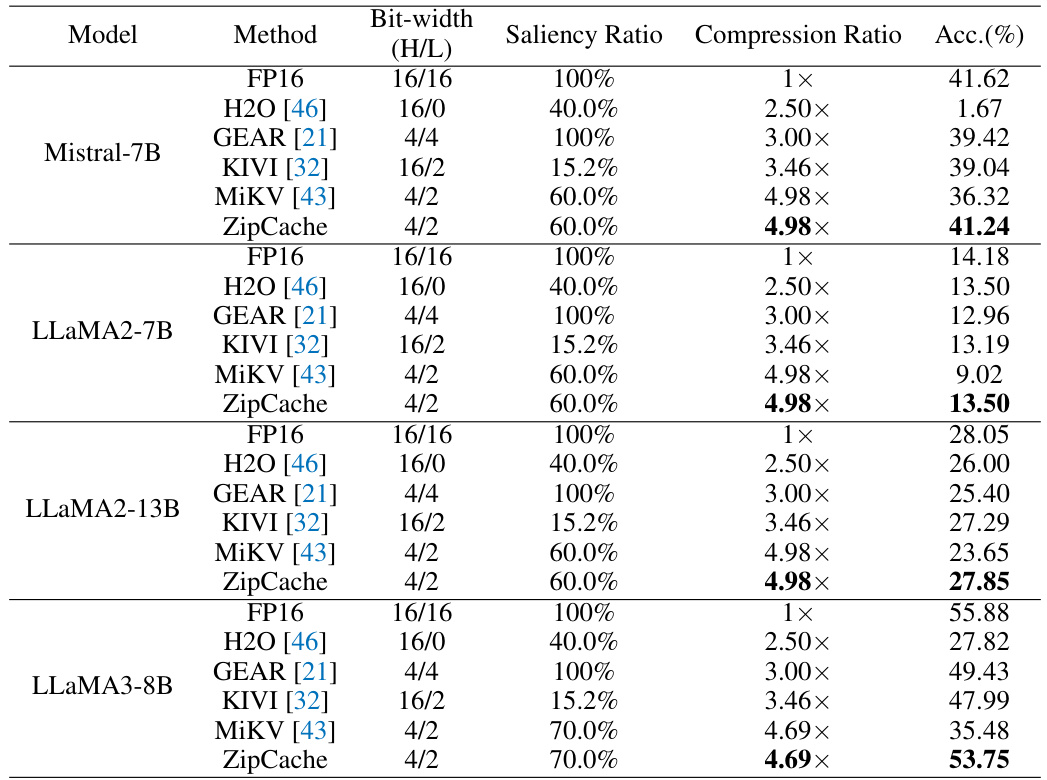
🔼 This table presents the performance comparison results of different KV cache compression methods on the GSM8k dataset using chain-of-thought (CoT) prompting. It shows the accuracy and compression ratio achieved by each method across various models (Mistral-7B, LLaMA2-7B, LLaMA3-8B), varying bit-widths for salient and regular tokens, and different saliency ratios. The results highlight ZipCache’s superior performance in terms of both accuracy and compression.
read the caption
Table 3: Performance comparisons on GSM8k with CoT prompts. Here, 'H/L' denotes the bit-width for salient tokens (high-precision) and regular tokens (low-precision), respectively. The compression ratio is calculated with an average input length of l = 840.
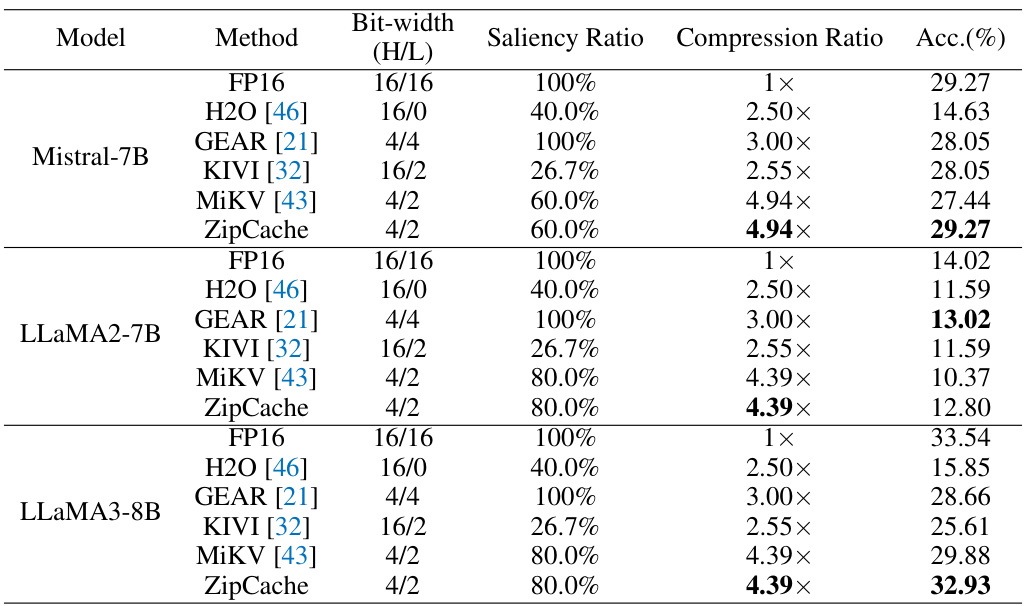
🔼 This table compares the performance of various KV cache compression methods on the GSM8k dataset using chain-of-thought prompting. It shows the accuracy and compression ratio achieved by each method, varying the bit-width and proportion of salient tokens quantized to higher precision. The results highlight the trade-offs between compression and accuracy.
read the caption
Table 3: Performance comparisons on GSM8k with CoT prompts. Here, 'H/L' denotes the bit-width for salient tokens (high-precision) and regular tokens (low-precision), respectively. The compression ratio is calculated with an average input length of l = 840.

🔼 This table compares the performance of different KV cache quantization methods: groupwise, tokenwise, and channel-separable tokenwise quantization. It shows the impact of each quantization method on the number of quantization parameters, compression ratio, and accuracy. The experiment is performed using the LLaMA3-8B model on the GSM8k dataset with specific hyperparameters (b=8, hd=l=4096, n=32).
read the caption
Table 1: Performance comparisons of different quantization granularities for KV cache. The KV cache is quantized to 4-bit and the compression ratio is calculated with b = 8, hd = l = 4096 and n = 32. Data is collected with LLaMA3-8B model on GSM8k dataset.

🔼 This table compares the performance of different KV cache quantization granularities (groupwise, tokenwise, and channel-separable tokenwise). It shows the number of quantization parameters, compression ratio, and accuracy achieved by each method using the LLaMA3-8B model on the GSM8k dataset. The comparison highlights the efficiency of the proposed channel-separable tokenwise quantization.
read the caption
Table 1: Performance comparisons of different quantization granularities for KV cache. The KV cache is quantized to 4-bit and the compression ratio is calculated with b = 8, hd = l = 4096 and n = 32. Data is collected with LLaMA3-8B model on GSM8k dataset.

🔼 This table presents an ablation study comparing different methods for identifying salient tokens in the GSM8k dataset using chain-of-thought prompting. It compares the accuracy achieved using three different saliency metrics: using the most recent tokens, accumulated attention scores, and the normalized attention scores proposed in the paper. The results demonstrate the superior performance of the proposed normalized attention scores method.
read the caption
Table A: The effect of various saliency metric on GSM8k with CoT prompts. Here, 'H/L' denotes the bit-width for salient tokens (high-precision) and regular tokens (low-precision), respectively. 'Locality' means the recent tokens are identified as salient tokens. The compression ratio is calculated with an average input length of l = 840.
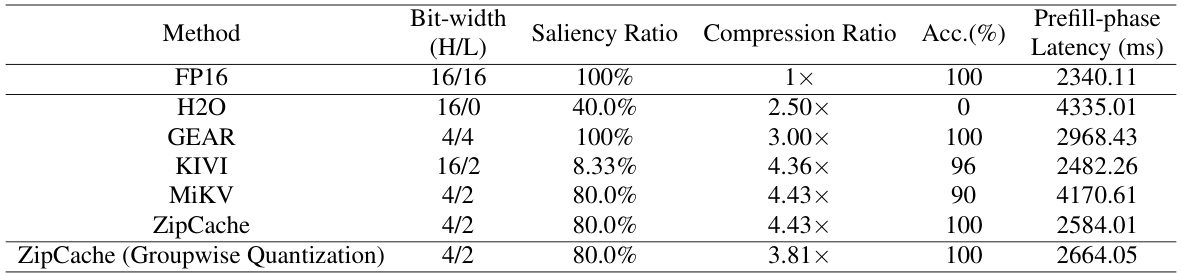
🔼 This table compares the performance of different KV cache compression methods on the GSM8k dataset using chain-of-thought prompting. It shows the accuracy, compression ratio, and prefill-phase latency for each method, varying the bit-width and the proportion of salient tokens compressed at higher precision. The table highlights the trade-off between compression and accuracy.
read the caption
Table 3: Performance comparisons on GSM8k with CoT prompts. Here, 'H/L' denotes the bit-width for salient tokens (high-precision) and regular tokens (low-precision), respectively. The compression ratio is calculated with an average input length of l = 840.

🔼 This table presents a comparison of the performance of different methods (FP16, KIVI-2, and ZipCache) on the LongBench benchmark using the Llama-2-7b-chat model. The benchmark includes various tasks like Qasper, QMSum, MultiNews, TREC, TriviaQA, SAMSum, LCC, and RepoBench-P. The results show the accuracy of each method on these tasks.
read the caption
Table C: Performance comparisons on LongBench.
Full paper#